文章目錄
- 1、鏈表的概念與分類
- 1.1 鏈表的概念
- 1.2 鏈表的分類
- 2、單鏈表的結構和定義
- 2.1 單鏈表的結構
- 2.2 單鏈表的定義
- 3、單鏈表的實現
- 3.1 創建新節點
- 3.2 頭插和尾插的實現
- 3.3 頭刪和尾刪的實現
- 3.4 鏈表的查找
- 3.5 指定位置之前和之后插入數據
- 3.6 刪除指定位置的數據和刪除指定位置之后的數據
- 3.7 鏈表的銷毀
- 4、單鏈表與順序表的區別
- 5、結語
- 6、 完整實現代碼
- 6.1 頭文件SList.h
- 6.2 SList.c文件
1、鏈表的概念與分類
1.1 鏈表的概念
鏈表是一種在物理結構上不連續、非線性的數據存儲結構,但它在邏輯結構上是線性的,這是通過鏈表中的指針鏈接次序來實現。
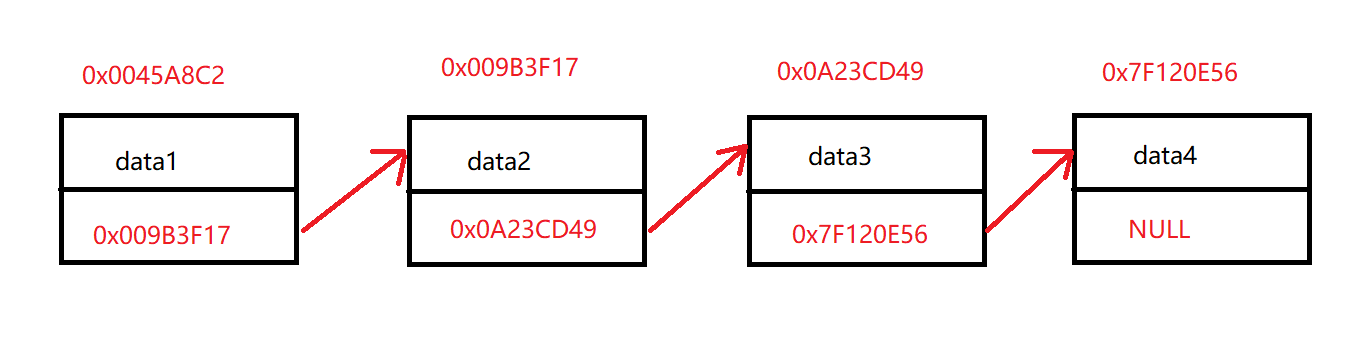
1.2 鏈表的分類
鏈表有很多種結構,分別帶頭和不帶頭,單向和雙向,循環和不循環,以上各種情況組合起來就多達222 = 8種鏈表結構,分別是:
- 不帶頭單向不循環鏈表
- 不帶頭單向循環鏈表
- 不帶頭雙向循環鏈表
- 不帶頭雙向不循環鏈表
- 帶頭雙向循環鏈表
- 帶頭單向循環鏈表
- 帶頭單向不循環鏈表
- 帶頭雙向不循環鏈表
**單向和雙向的區別:**單向的鏈表每個節點只有一個指向下一個節點的指針,而雙向鏈表每個節點有指向下一個節點的指針,也有指向上一個節點的指針。
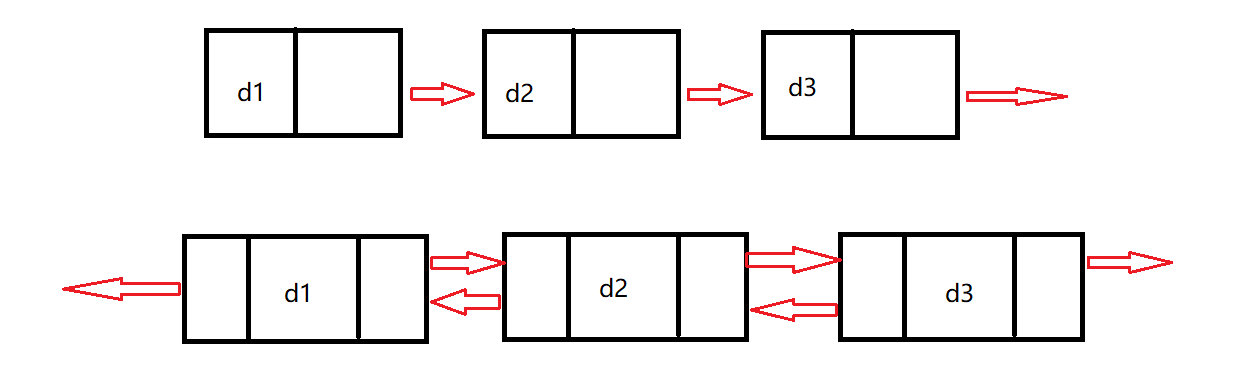
**帶頭和不帶頭的區別:**不帶頭鏈表的第一個節點也就是頭節點,是第一個存儲數據的有效節點,而帶頭鏈表的頭節點則是不存儲數據,也被叫做哨兵位,哨兵位后的第一個節點才開始存儲有效數據。
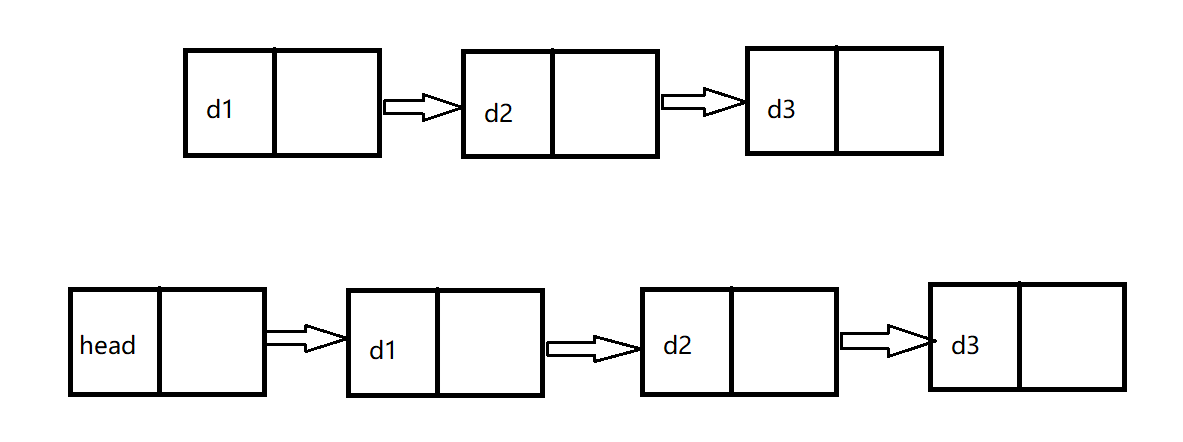
**循環與不循環的區別:**不循環鏈表的尾節點指向NULL,而循環鏈表的尾節點指向鏈表的頭節點,構成環。
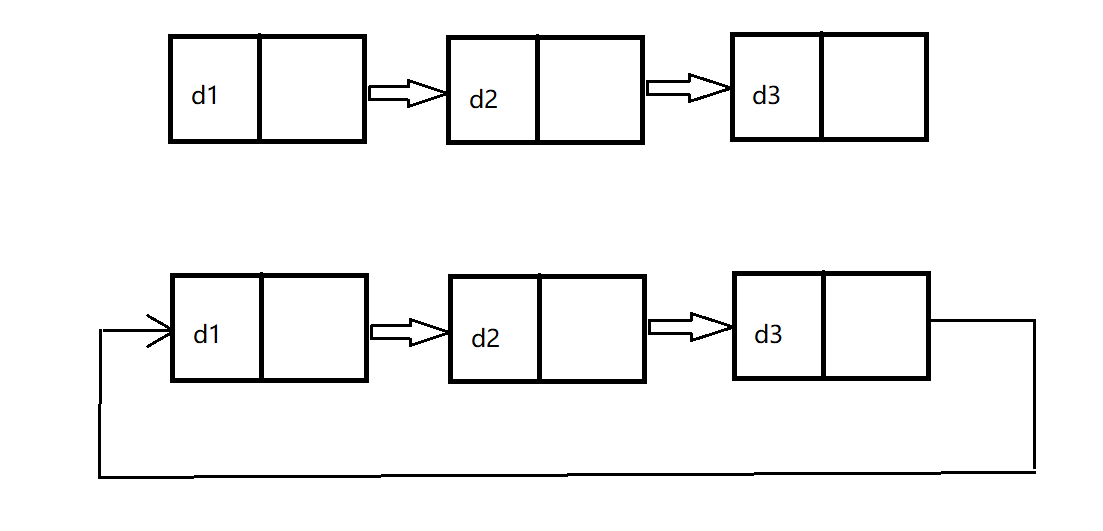
上面這么多種結構中,我們最常用的是不帶頭單向不循環鏈表(簡稱單鏈表)和帶頭雙向循環鏈表。
2、單鏈表的結構和定義
2.1 單鏈表的結構
依據前面所提的關于不帶頭單向不循環鏈表的結構,我們可以得出,單鏈表每個節點有兩個變量,一個用來存放數據,一個用來指向下一節點,那么我們就可以根據這個結構來定義我們的單鏈表。
2.2 單鏈表的定義
typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;
其中,我們將int重定義為SLTDataType,是為了后續方便我們修改整個鏈表的數據類型,將struct SListNode重定義為SLTNode,方便我們后面使用。
3、單鏈表的實現
3.1 創建新節點
因為后續的插入操作都需要創建新節點,為實現代碼復用,避免太多重復代碼,我們封裝一個用于創建新節點的函數。
實現思路:首先創建一個臨時的節點并為其開辟空間(提高代碼健壯性可以判斷是否申請空間成功),然后將傳過來的值賦給創建的節點,再將新節點的指針置空,最后返回這個節點。
具體實現代碼如下:
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}3.2 頭插和尾插的實現
我們給出下面兩個函數的聲明,分別是實現鏈表的頭插和尾插,注意這里傳過去的是二級指針,因為鏈表頭節點本身就是一個一級的結構體指針,我們要修改它的值,就要在這里進行傳址操作。
//鏈表的頭插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
鏈表頭插的實現思路:首先我們要判斷傳進來的指針是否為空,可以使用assert斷言,如果為空則直接異常中止,如果不為空則創建新節點,并將新節點的指針指向頭節點,再將新節點作為新的頭節點。
實現代碼:
void SListPushFront(SLTNode** pphead, SListDataType x)
{assert(pphead);SLTNode* newNode = SLTBuyNode(x);newNode->next = *pphead;*pphead = newNode;
}
//鏈表的尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
尾插的實現思路:同樣,進來先用斷言判斷pphead是否為空,然后創建新節點,再判斷鏈表是否為空,如果為空,則將新創建的節點作為頭節點,然后返回,如果不為空,則需要遍歷當前鏈表,找到尾節點,將尾節點的next指針指向我們的新節點。
代碼實現如下:
//鏈表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//鏈表為空if (*pphead == NULL){*pphead = newnode;return;}//鏈表不為空,找尾節點SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}ptail->next = newnode;
}
3.3 頭刪和尾刪的實現
函數聲明:
//鏈表的頭刪
void SLTPopFront(SLTNode** pphead);
頭刪的實現思路:
頭刪我們要考慮鏈表可能存在為空、只有一個節點、有多個節點三種情況,因此我們在用斷言判斷頭節點指針是否為空后要再判斷頭節點是否為空,再去考慮只有一個節點和多個節點的情況,如果只有一個節點,那么執行完頭刪后鏈表為空,我們需要釋放頭節點的內存,并將頭節點置空,然后返回,如果有多個節點,我們則創建一個新的節點,來存放頭節點的next指針,也就是第二個節點,再釋放頭節點的內存(這里就是頭刪操作),這個時候再將我們創建的新節點賦值給頭節點,此時頭節點就為原來的第二個節點,完成頭刪操作。
代碼實現如下:
void SLTPopFront(SLTNode** pphead) {assert(pphead);assert(*pphead);//鏈表只有一個節點if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}SLTNode* newhead = (*pphead)->next;free(*pphead);*pphead = newhead;}
//鏈表的尾刪
void SLTPopBack(SLTNode** pphead);
尾刪的實現思路:
同樣,我們還是要考慮鏈表為空、鏈表只有一個節點、鏈表有多個節點的情況,鏈表為空則無法刪,鏈表只有一個節點那么就和頭刪一樣的處理方式,釋放頭節點,置空然后返回,如果存在多個節點,我們則需要遍歷鏈表找到為尾節點,不同于頭刪的是,我們在遍歷鏈表找尾節點的時候,要創建一個臨時的變量prev來存放尾節點的前一個節點,然后找到尾節點后釋放尾節點,并將prev的next指針置空,再賦值給尾節點,此時就完成了尾刪操作。
代碼實現如下:
void SLTPopBack(SLTNode** pphead) {assert(pphead);//鏈表不能為空assert(*pphead);//鏈表只有一個節點if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;free(ptail);ptail = NULL;
}
3.4 鏈表的查找
函數聲明:
//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);
查找的實現思路:這個實現的思路比較簡單,首先傳進來的pphead不能為空,然后遍歷整個鏈表,用每個節點的data和x進行比較,如果相同則返回當前節點,如果遍歷完整個鏈表找不到和x相同的data,則說明不存在這個節點,那么就返回一個NULL。
代碼實現如下:
//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{assert(pphead);//遍歷鏈表SLTNode* pcur = *pphead;while (pcur){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}
將SLTNode* 類型作為查找函數的返回類型,可以方便我們后續指定位置進行操作。
3.5 指定位置之前和之后插入數據
函數聲明:
//在指定位置之前插入數據
void SLTInsert(SLTNode** pphead,SLTNode* pos, SLTDataType x);
指定位置之前插入數據的實現思路:首先我們要考慮傳進來的pphead是否為空,刪除的節點是否為空,以及鏈表是否為空的情況,所以一開始要有3次斷言,創建一個新節點,然后考慮刪除的節點pos正好是頭節點的情況,以及pos不是頭節點的情況,如果是頭節點則直接進行頭插操作,不是頭節點我們則需要遍歷鏈表找pos節點,這里的循環條件是當前節點prev的下一個節點不為pos,那么循環終止時,當前節點prev就應該是pos的前一個節點,此時我們再讓新節點的next指針指向pos,讓prev的next指針指向新節點,完成pos前插入數據的操作。
代碼實現如下:
//在指定位置之前插入數據
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead);assert(pos);assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos剛好是頭節點if (pos == *pphead){//頭插SLTPushFront(pphead, x);return;}//pos不是頭節點的情況SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;
}
//在指定位置之后插入數據
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
指定位置之后插入數據的實現思路:
可以看到這個函數的參數只有pos節點和插入數據x,也就是說不需要對整個鏈表進行操作,具體是如何實現的呢,同樣的,我們需要先用斷言判斷pos節點是否為空,然后創建一個新節點存放插入數據x,我們要在pos節點之后插入數據,這個操作會同時影響到pos和pos的下一個節點,也就是pos->next,我們只需要讓新節點的next指針指向pos的下一個節點pos->next,再讓pos的next指針指向新節點,即可完成pos后插入數據的操作。
代碼實現如下:
//在指定位置之后插入數據
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);// pos newnode pos->nextnewnode->next = pos->next;pos->next = newnode;
}
3.6 刪除指定位置的數據和刪除指定位置之后的數據
//刪除pos節點
void SLTErase(SLTNode** pphead, SLTNode* pos);
實現思路:首先我們還是要對pphead、*pphead以及pos進行斷言,然后考慮pos節點是否為頭節點的情況,如果為頭節點,那么我們直接進行頭刪操作即可,如果不是,我們就要遍歷鏈表,找到pos的前一個節點prev,讓prev的next指針指向pos的下一個節點pos->next,再釋放pos節點的內存,將pos置空,至此完成刪除pos節點操作。
代碼實現如下:
//刪除pos節點
void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pphead);assert(*pphead);assert(pos);//pos是頭節點if (pos == *pphead){//頭刪SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}//刪除pos之后的節點
void SLTEraseAfter(SLTNode* pos);
實現思路:我們要考慮兩種情況,pos節點是否為空,以及pos是否為尾節點(如果pos是尾節點就沒有刪除pos之后節點的說法了),因此我們需要對pos和pos->next進行斷言。我們創建一個臨時的節點del存放pos的下一個節點,也就是我們要刪除的節點,然后讓pos的next指針指向del的下一個節點,也就是pos的下下個節點,再釋放del,將del置空,這樣就完成對pos后的節點刪除的操作了。
代碼實現:
//刪除pos之后的節點
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;}3.7 鏈表的銷毀
函數聲明:
//銷毀鏈表
void SLTDestroy(SLTNode** pphead);
實現思路:首先還是要對pphead和pphead進行斷言,然后就是遍歷鏈表對每個節點依次釋放內存,最后要將頭節點pphead置空。
代碼實現如下:
//銷毀鏈表
void SLTDestroy(SLTNode** pphead) {assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
4、單鏈表與順序表的區別
單鏈表和順序表都是線性表,但順序表在物理結構上一定連續,因為順序表的底層結構是數組,數組的存儲就是一塊連續的空間,而單鏈表在物理結構上不一定連續,為什么說不一定的,因為每個節點的地址都是隨機分配的,無法確定。順序表相對于單鏈表而言,它因為底層結構是數組,所以能夠做到隨機訪問,而鏈表隨機訪問一個節點都要進行遍歷,效率較低,但順序表插入和刪除數據需要對整個數組的元素進行搬移,而鏈表則只需要修改指針指向,二者各有各的優缺點,這也就給他們帶來了不同的應用場景,但你需要頻繁訪問存儲的數據時,可以考慮順序表作為底層結構,當你需要頻繁的刪除插入操作時,鏈表就更加符合你的需求。所以說存在即合理,每個數據結構都有他們的優勢和缺陷,沒有絕對的誰好誰差的區分。我們要做到的是了解、熟悉每一個數據結構,在未來遇到各種應用場景時,能夠根據不同的需求選擇最合適的數據結構。
5、結語
這篇文章就講到這里了,單鏈表相關功能的測試,大家就自己去嘗試一下,如果存在什么錯誤和紕漏的地方,請及時指出,一定改正,數據結構這部分確實是代碼量最多的一部分,不僅要學數據結構,還有各種各樣的算法,需要不斷地加以練習,后面會開個新專欄用來記錄我的刷題,努力學習,共同進步。最后附上完整的代碼,希望這篇文章能夠給你帶來幫助。
6、 完整實現代碼
6.1 頭文件SList.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//鏈表節點結構typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;//打印鏈表
void SLTPrint(SLTNode* phead);//鏈表的頭插和尾插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
void SLTPushBack(SLTNode** pphead, SLTDataType x);//鏈表的頭刪和尾刪
void SLTPopFront(SLTNode** pphead);
void SLTPopBack(SLTNode** pphead);//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);//在指定位置之前插入數據
void SLTInsert(SLTNode** pphead,SLTNode* pos, SLTDataType x);//刪除pos節點
void SLTErase(SLTNode** pphead, SLTNode* pos);//在指定位置之后插入數據
void SLTInsertAfter(SLTNode* pos, SLTDataType x);//刪除pos之后的節點
void SLTEraseAfter(SLTNode* pos);//銷毀鏈表
void SLTDestroy(SLTNode** pphead);
6.2 SList.c文件
#include"SList.h"//打印鏈表
void SLTPrint(SLTNode* phead) {SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}//創建新節點
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}//鏈表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//鏈表為空if (*pphead == NULL){*pphead = newnode;return;}//鏈表不為空,找尾節點SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}ptail->next = newnode;
}//鏈表頭插
void SLTPushFront(SLTNode** pphead, SLTDataType x) {assert(pphead);SLTNode* newnode = SLTBuyNode(x);//鏈表為空//鏈表不為空newnode->next = *pphead;*pphead = newnode;
}//鏈表的頭刪和尾刪
void SLTPopFront(SLTNode** pphead) {assert(pphead);assert(*pphead);//鏈表只有一個節點if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}SLTNode* newhead = (*pphead)->next;free(*pphead);*pphead = newhead;}
void SLTPopBack(SLTNode** pphead) {assert(pphead);//鏈表不能為空assert(*pphead);//鏈表只有一個節點if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;free(ptail);ptail = NULL;
}//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{assert(pphead);//遍歷鏈表SLTNode* pcur = *pphead;while (pcur){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}//在指定位置之前插入數據
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead);assert(pos);assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos剛好是頭節點if (pos == *pphead){//頭插SLTPushFront(pphead, x);return;}//pos不是頭節點的情況SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;
}//刪除pos節點
void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pphead);assert(*pphead);assert(pos);//pos是頭節點if (pos == *pphead){//頭刪SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}//在指定位置之后插入數據
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}//刪除pos之后的節點
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;}//銷毀鏈表
void SLTDestroy(SLTNode** pphead) {assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}










:基于架構的軟件設計方法ABSD)








