目錄
1.數據庫約束
1.1 約束類型
1.2 null約束 — not null
1.3 unique — 唯一約束
1.4 default — 設置默認值
1.5 primary key — 主鍵約束
自增主鍵
自增主鍵的局限性:經典面試問題(進階問題)
1.6 foreign key — 外鍵約束
1.7 check約束(了解)
2. 表的設計
一對一
一對多
多對多
1.數據庫約束
- 約束是數據庫針對里面的數據有一定的要求,有些數據認為是合法數據,有些數據是非法數據。這里給出的一組"檢驗規則”。
- 數據庫自動的對數據的合法性進行校驗檢查的一系列機制。目的是為了保證數據庫中能夠避免被插入/修改一些非法的數據。
1.1 約束類型
- not null — 指示某列不能存儲 NULL 值。 —— 必填項
- unique —?保證某列的每行必須有(是)唯一的值,不能重復。 —— 學號,手機號,身份證號
- default —?規定沒有給列賦值時的默認值。—— 默認值
- primary key —?not null 和 unique 的結合。確保某列(或兩個列多個列的結合)有唯一標識(既不能為空,也不能重復),有助于更容易更快速地找到表中的一個特定的記錄。 —— 主鍵
- foreign key —?保證一個表中的數據匹配另一個表中的值的參照完整性。 —— 外鍵
- check —?保證列中的值符合指定的條件。對于MySQL數據庫,對CHECK子句進行分析,但是忽略 check子句。在mysql 5版本中,不支持,寫了不會報錯,但是沒有實際效果。這里不做過多介紹。
設置約束條件大部分都是在創建表的時候。
1.2 null約束 — not null
創建表時,可以指定某列不為空。未指定:此時表可以隨意插入空值。
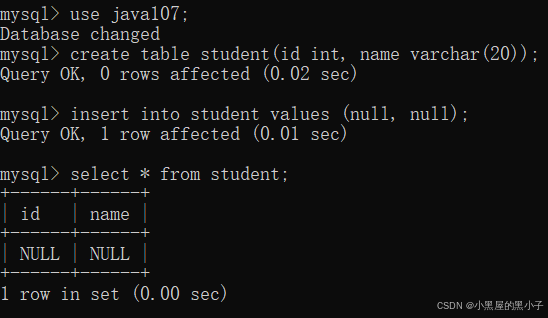
可以使用 alter table給現有的表加約束,但用起來麻煩(支持的功能多),很少會使用。不做過多介紹。在創建表的時候要設計好表的屬性。這里我們為了方便演示每次刪了重新創建。
創建時,指定id 列為not null(不能為空),如果嘗試插入或者修改為空,都會報錯。
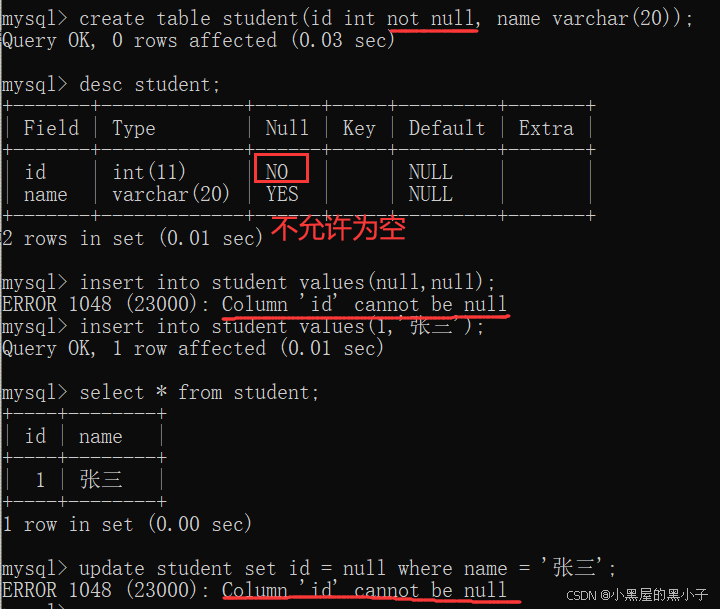
1.3 unique — 唯一約束
唯一:插入/修改數據的時候,會先查詢,看看數據是否已經存在。如果不存在,就能夠插入/修改成功,如果存在,則插入/修改失敗。
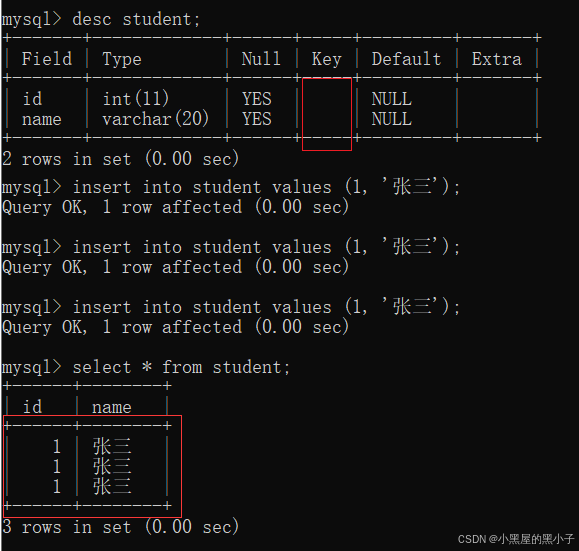
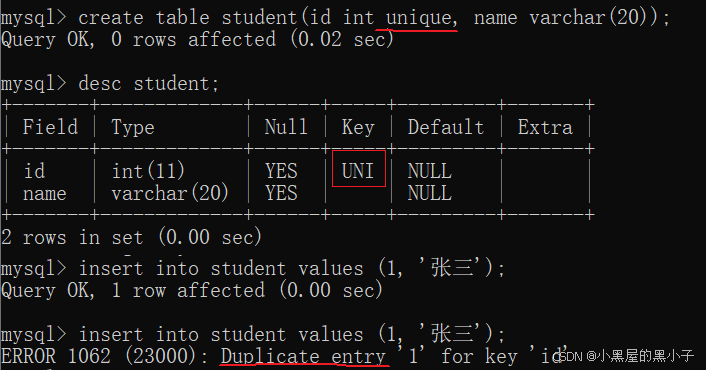
unique沒約束之前,可以插入多條重復的記錄
unique約束之后,指定id列為唯一,不能插入重復記錄
- 報錯:重復條目。數據庫怎么知道的1存在?
- 其實是在插入或者修改之前先觸發一次,查詢操作(正常插入直接插入,添加約束插入需要先查詢一下),這里是多了個查找數據的成本。所以有unique 的約束插入/修改要比沒有unique的約束插入/修改要慢一些。數據庫的查詢操作并不是像線性遍歷的方式,一條一條的查,有更快的方式,但是還是有查詢這個行為。
- 數據庫引入約束之后,執行效率會受到影響,可能會降低很多。
- 意味著數據庫是比較慢的系統,也比較吃資源的系統。在部署數據庫的服務器,它很容易成為整個系統的“性能瓶頸"。
- 可靠數據角度:mysql數據庫處理的數據多,需要更多的時間更可靠的去處理數據。俗話說慢工出細活。
- 性能效率角度:在現在很多高并發、大數據的情況下,mysql數據庫的表現就差強人意了。根據實際情況,可以搭配redis數據庫使用提高數據存儲和訪問。
1.4 default — 設置默認值
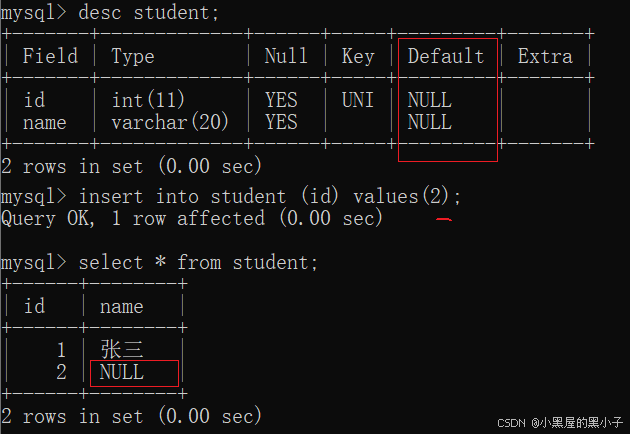
可以通過default 約束,來修改默認值。默認的默認值是空。
在insert 指定列插入的時候,其他未被指定到的列按照默認值來填充。
沒有設置默認值,默認值為null
設置默認值;插入時,name列不做指定,默認值無名氏
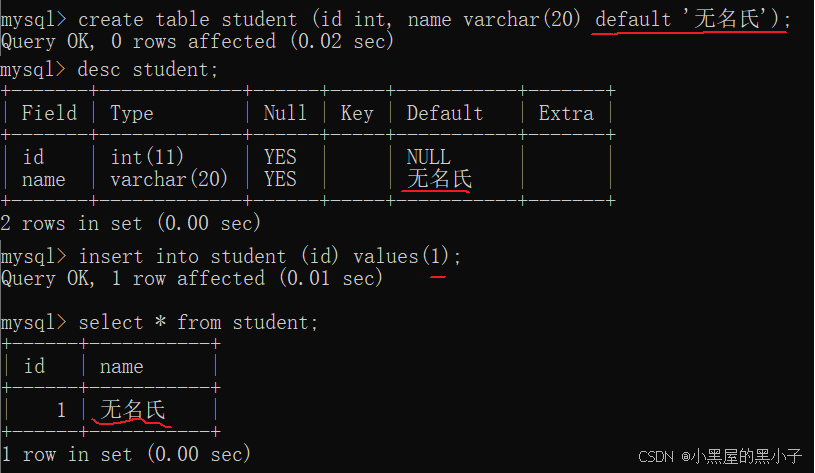
1.5 primary key — 主鍵約束
- 主鍵,一行記錄在表中的"身份標識",手機號碼、身份證號碼、學號等
- 要求唯一且不能為空,主鍵 = unique + not null ,
- 一張表里只能有一個primary key。一個表里的記錄,只能有一個作為身份標識的數據。
- 創建主鍵的時候,可以使用一個列作為主鍵,也可以使用多個列作為主鍵(復合/聯合主鍵,很少用)
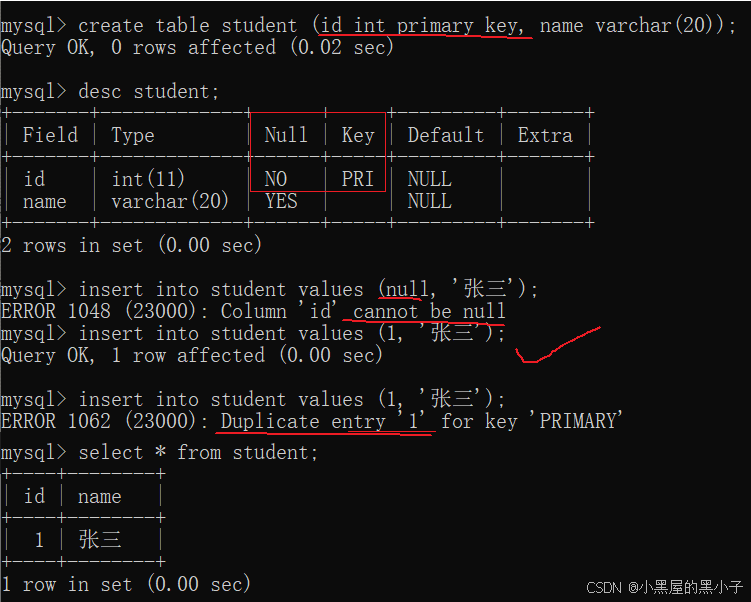
- 看起來和not null + unique是類似的,同樣對于帶有主鍵約束的表,每次插入數據/修改數據之前要都要先查詢操作,空的和重復的不會插入/修改。
- mysql會把帶有unique 和 primary key的列自動生成索引,從而加快查詢速度。(后續會講解)
自增主鍵
如何保證主鍵唯一,mysql提供了一種"自增主鍵"這樣機制。
- 主鍵經常會使用int / bigint類型。對于整數類型的主鍵,常配搭自增長 auto_increment 來使用。插入數據對應字段設置為null,mysql服務器會自動分配。從1開始,依次遞增的分配主鍵的值。
- 自增主鍵 primary key auto_increment。程序猿插入數據的時候,不必手動指定主鍵約束的值了,不用考慮重復的情況了。
給自增主鍵插入數據的時候,可以手動指定一個值,也可以讓mysql服務器自行分配。如果讓mysql服務器自行分配,在insert語句的時候,把id設為null 即可了。

mysql服務器自行分配:在insert語句的時候,把id設為null 即可了。
自增主鍵可以理解為:mysql服務器給每個表維護了一個全局變量,每次自行分配一個id,全局變量自增,下次分配接著上次的繼續分。

手動指定:
- 分配的時候把4-99序號跳過了,浪費了一部分序號,但沒浪費空間。
- 這里手動指定是可以插入4-99序號,但是mysql服務器不能自動分配4-99序號。
- 如果mysql重復利用了中間的值,增長一定數據之后,就可能和100重復,因此mysql就需要時刻記得當前哪些id被分配了,哪些是空閑的,這么搞也能實現,太麻煩,效率也低。
- 自增主鍵,相當于使用了一個變量,來保存了當前表的id的最大值,后續分配自增主鍵都是根據這個最大值來分配的。如果手動指定 id,也會更新最大值。
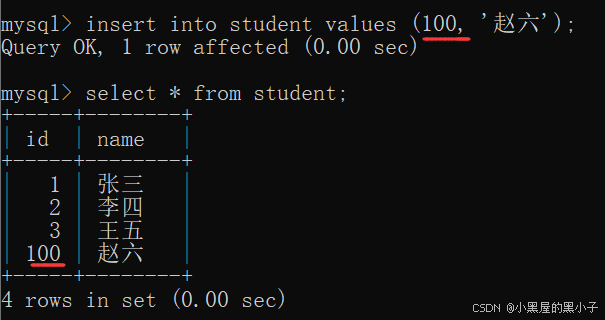
自增主鍵的局限性:經典面試問題(進階問題)
- 此處這里自增主鍵 自動分配 id,是有一定局限性的。
- 自增主鍵在單個mysql服務器,能很好的使用。
- 如果是一個分布式系統,有多個mysql服務器構成的集群,這時依靠自增主鍵就不行了。
- 面臨的數據量大(大數據),客戶端的請求量比較大(高并發),一臺服務器存儲管理不下,需要多臺機器(分布式)。例如某一個表或者某幾個表,數據量特別大。此時來了一個新的商品,進行分庫分表。此時新增商品,id如何分配呢?肯定是要把這個記錄保存在某個數據庫的表中,但是如何保證這里的id和另外兩個數據庫中id不重復呢?
- 分布式系統中生成唯一 id的算法,實現這個算法的具體方式有很多,我們通過下面公式思想實現。
- 分布式唯一id = 時間戳 + 機房編號/主機編號 + 隨機因子?
- +是指字符串拼接,不是算術相加。拼出來的結果是一個比較長的字符串。
公式解讀:
- 時間戳:如果添加商品的速度比較慢,直接使用時間戳表示就夠了,
- 機房編號/主機號:但如果一個時間戳內,添加了多個商品,添加的多個商品,是要落到不同的主機上的。保證同一時間之內,添加到不同主機上的商品的編號,是不同的了。
- 隨機因子:同一個ms之內,給同一個機器上添加的多個數據。隨機因子這里有一定概率生成相同的因子,但是概率比較小,可以忽略不計。
1.6 foreign key — 外鍵約束
描述兩張表之間相互關聯,這個關聯就是外鍵約束。外鍵用于關聯其他表的主鍵或唯一鍵。
- 保證指定父表的列是帶索引的。創建主鍵約束(PRIMARY KEY)、唯一約束(UNIQUE)、外鍵約束(FOREIGN KEY)時,會自動創建對應列的索引。
- 外鍵約束位置是在描述完,全部列之后寫的。前面其他約束則是緊跟對應列的后面。

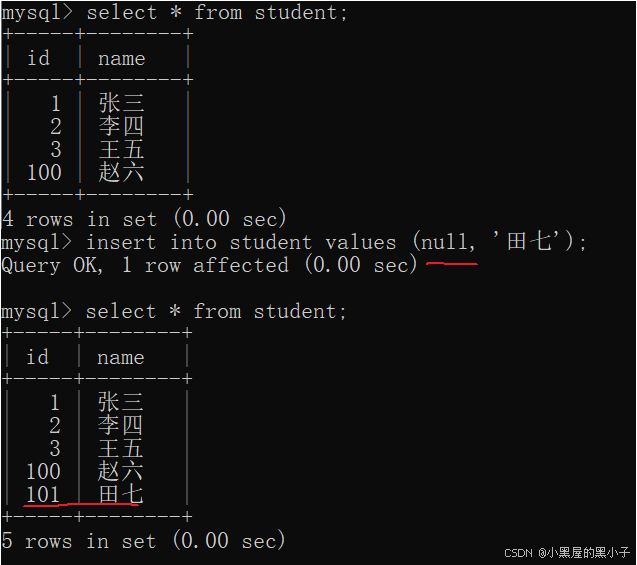
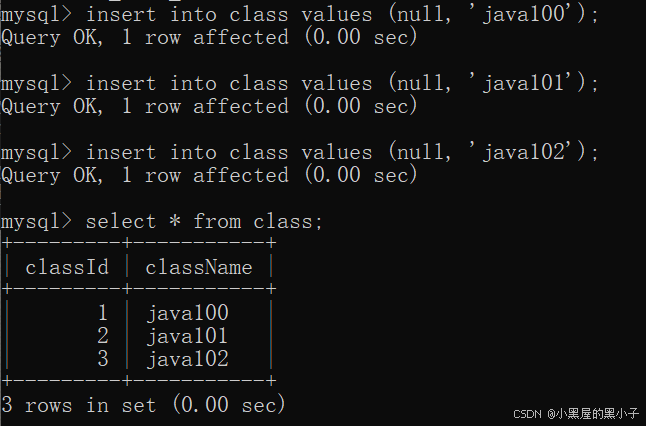
先創建兩張表,class、student。
- 如果不寫外鍵約束,此時student中的classId列與class中的classId列將沒有任何關聯。
- references,JavaSE中引用(類型),此處表示了當前這個表的這一列中的數據,出自于另一個表的哪一列。
- 此時student表中classId列的每行記錄,都在class表的classld列中存在。
- class表中的數據,約束了 student表中的數據。
- 把class表稱為“父表”(parent),約束其它表的表。
- 把student表稱為“子表”(child),被其它表約束的表。
- 指定外鍵約束的時候,要求父表中被關聯的這一列,是主鍵或者是unique約束的。否則子表不能關聯到該列,會報錯。

- 班級表為空,插入學生記錄不會成功,報錯;要插入的外鍵在關聯表中沒有。
- 這里不僅對插入有約束,還有修改也有約束
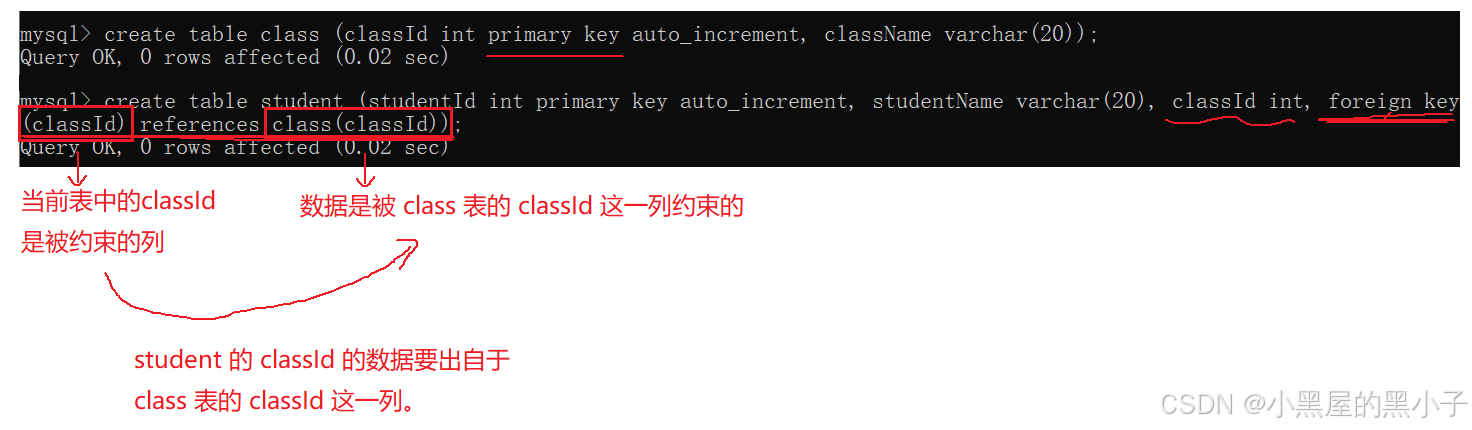
- 插入記錄到班級表中
- 插入記錄到學生表中,mysql會先拿著這個記錄的classld(外鍵約束)1,查看class表中classId有沒有,有則完成后續的插入,沒有插入失敗。
這里注意,studentId 為 2 ,是因為前面嘗試插入了一次,沒成功,但是自增主鍵增了。
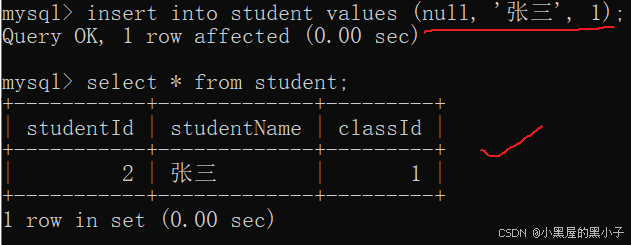
- 修改學生表中記錄,mysql會先拿著這個記錄的classld(外鍵約束)10,查看class表中classId有沒有,有則完成后續的插入,沒有插入失敗。要修改的外鍵在關聯表中沒有。
- 針對子表進行插入/修改操作,會先查看當前插入/修改的被約束的值,是否在父表中存在,有則完成后續的插入/修改,沒有插入/修改失敗。但可以修改其它沒有約束的列。
- 外鍵約束始終要保持,子表中的數據在對應的,父表的列中要存在。

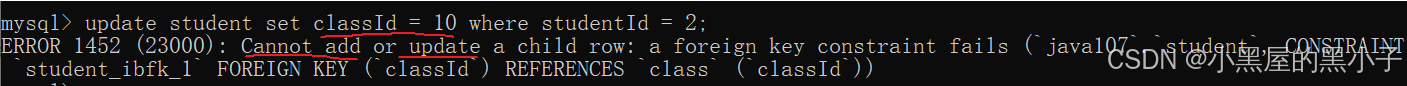
父表在約束子表,子表也反向的約束了父表
- 針對父表進行修改/刪除操作,如果當前被修改/刪除的值,已經被子表引用了,這樣的操作也會失敗。但可以修改該記錄其它列。或者也可以修改/刪除其它沒有被反向約束的記錄。外鍵準確來說,是兩個表的列產生關聯關系。其他的列是不受影響的。
- 例如:嘗試刪除班級表里面的classld為1的記錄,發現刪除失敗。但可以修改該記錄的className。或者可以修改/刪除其它沒有被反向約束的記錄。
報錯原因:要刪除的記錄關聯到了其他表作為了外鍵,不能刪除。
- 直接嘗試drop table class 來刪除表,也是不行的。要想刪除表,也需要先刪除記錄。
- 正確的做法:先刪除子表,然后再刪除父表。



關于外鍵約束生活中的問題:
現在有一個電商網站,有個商品表(父表),訂單表(子表),其中關于goodsId列外鍵約束關聯。
有下面情景:一段時間后,商家想把這個襯衫給下架(刪除掉),要如何完成刪除。嘗試刪除父表數據的時候,如果父表的數據被子表引用,是不能刪除的,會報錯。電商網站如何做到,保證外鍵約束存在的前提下,實現"商品下架"功能的。

解決方法:
給商品表新增一個單獨的列,表示是否在線。(不在線就相當于下架了)
如果需要下架商品,使用update把 isOk 從1 修改為 0即可。此時實現下架并非是delete 而是 update 把是否下架字段進行修改。
查詢商品的時候,都加上where isOk = 1這樣的條件。如果為0,就間接實現了商品下架。
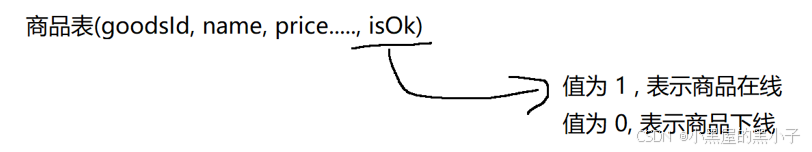
了解:
- 我們在這里刪除都是邏輯刪除,把這個數據標記成無效,而不是直接把數據抹掉。
- 電腦上刪除文件,也是通過邏輯刪除的方式實現的。這樣的刪除數據還在硬盤上,只不過是被標記成無效了。后續其他文件是可以重復利用這塊硬盤空間的。
- 通過扔進回收站,清空回收站是不能把電腦的某個文件徹底刪除的。硬盤上數據徹底消亡,需要時間等待后續有文件把這塊標記無效的空間重復利用了才會真正消失。
- 如何才是正確的徹底刪除數據的方式,通過物理刪除 -》把硬盤砸了。
- 所以按照邏輯刪除的思路,表中的數據是否會無限的擴張,是否就會導致硬盤空間被占滿。當然會有的。通過添加硬盤(比較便宜)、增加主機(分布式)等的方式,來進一步的擴充存儲空間。
1.7 check約束(了解)
MySQL使用時不報錯,但忽略該約束:

2. 表的設計
根據實際的需求場景,明確當前要創建幾個表,每個表的結構以及屬性,這些表之間是否存在一定聯系。
設計表,分兩步走:
1、梳理清楚需求中的 "實體"
例如:
一般來說每個實體,都需要安排一個表,表的列就對應到實體的各個屬性。


2、梳理清楚實體之間的關系,按照關系,帶入到既定的公式中。
實體之間的關系,主要有三種(嚴格的說是四種) 一對一, 一對多 , 多對多 , 沒關系。都屬于設計數據庫表結構的固定套路。
三大范式:
一對一
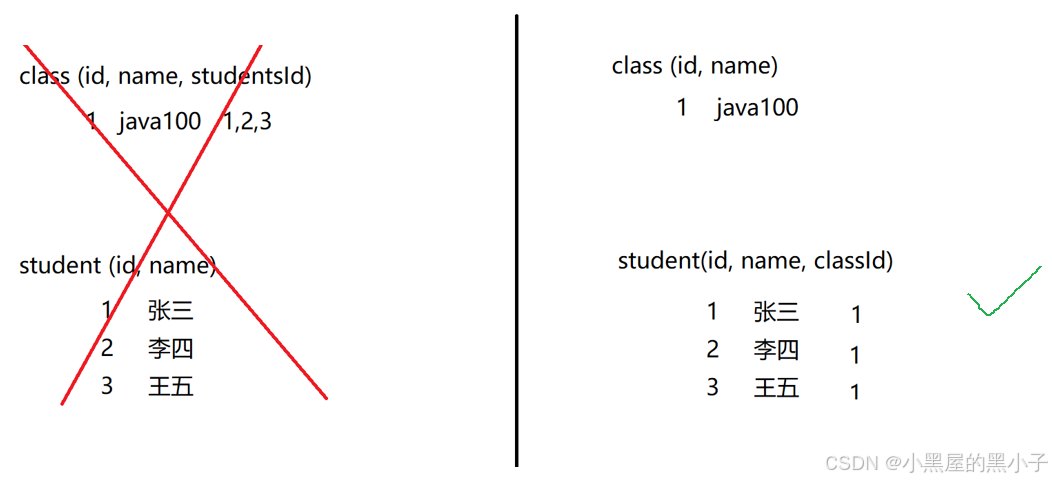
一個學生,只能有一個賬號。一個賬號,只能供一個學生所有。—— 1、創建一個大表,包含全部列。2、創建兩個表、相互關聯。


一對多
一個班級可以包含多個學生。一個學生只能處于一個班級。—— 通過外鍵關聯,要注意誰為父表,誰為子表。
- mysql不支持數組類型,使用mysql時是用第二種方式來實現的。
- 第一種寫法,可以在redis這樣能夠支持數組類型的數據庫中使用。

多對多
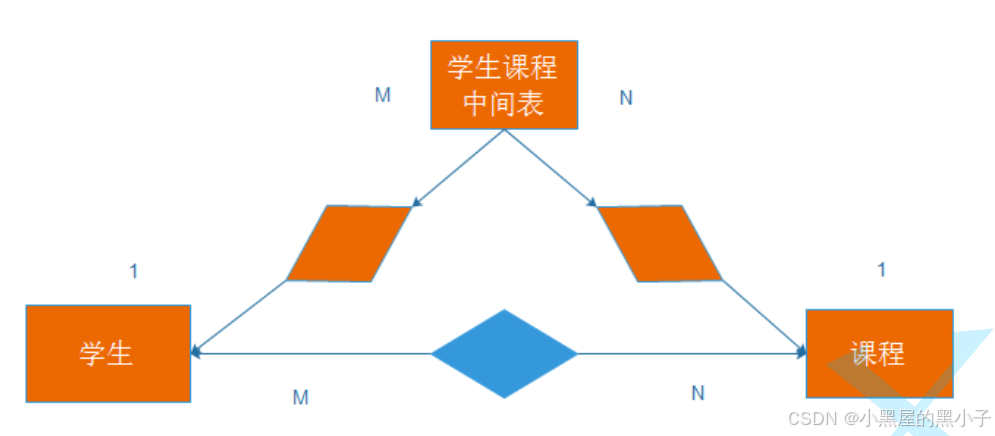
一個學生可以選擇多個課程。一個課程也可以提供給多個學生。—— 借助關聯表

- 沒關系:上述三種關系都無法套入進去。此時這樣的表就完全沒有關系,各自獨立設計即可,不必考慮對方。
- 一般來說,只要實體和關系都明確了,此時表的設計就基本差不多了。如果實體比較多,關系比較復雜,可以畫一個"實體關系圖"(ER圖),來表示這個關系。
- 實際開發中,很少會畫ER圖。即使畫也不必嚴格的遵守ER圖的語法,大概畫一下就行。
好啦Y(^o^)Y,本節內容到此就結束了。下一篇內容一定會火速更新!!!
后續還會持續更新MySQL方面的內容,還請大家多多關注本博主,第一時間獲取新鮮的知識。
如果覺得文章不錯,別忘了一鍵三連喲!?
棧)





)





與學習路徑)






