目錄
什么是內存接口 ?
為什么需要特別設計“接口”?
什么是 MIPS?為什么它和內存接口有關?
內存接口的兩種訪問方式
串行訪問(Serial Access Model)
并行訪問(Parallel Access Model)
什么是內存接口 ?
我們可以從最直覺的問題入手:
? CPU 要處理數據,那它是怎么和內存溝通、傳輸數據的?
這就像人要和外界溝通,需要“語言”和“通道”,那么 CPU 也需要某種“協議”或“機制”來訪問 memory(內存)。這個“語言和通道”就是:
Memory Interface(內存接口)——它是連接 CPU 和 Memory(內存)之間的通信橋梁。
它解決的本質問題是:
CPU 訪問數據的速度 vs 內存響應的速度 嚴重不匹配,怎么辦?
為什么需要特別設計“接口”?
我們可以回到最基礎的現實限制:
| 組件 | 執行速度(Cycle) |
|---|---|
| CPU | 幾 GHz(1 納秒級) |
| Memory | 100 納秒甚至更慢 |
于是你會發現:
? CPU 每執行一條指令,可能得等幾十個時鐘周期才能從內存中拿到數據!
那么問題來了:
怎么讓 CPU 不至于“餓死在等待內存數據”時鐘周期中?
這就是 Memory Interface(內存接口)設計的出發點。
什么是 MIPS?為什么它和內存接口有關?
我們先解釋這個術語:
MIPS(Million Instructions Per Second)中文叫“每秒百萬條指令數”,是衡量 CPU 執行速度的指標。
BUT? 注意:
MIPS 只反映 CPU 的潛力,不考慮它是否在等待內存!
所以現實中你可能看到:
CPU 有 2 GHz、理應執行 2 Billion 條指令/秒,但實際 MIPS 遠低于理論值。
為什么?因為……
🔁 CPU 經常被 慢速 memory interface 拖慢了節奏。
這就說明:
內存接口的效率,直接影響 CPU 的真實性能表現(有效 MIPS)!
內存接口的兩種訪問方式
什么是 AMAT?
AMAT(Average Memory Access Time):平均內存訪問時間,它是衡量 每一次訪問內存時,CPU 平均等待的總時間。由于內存系統通常是多級的(multi-level memory hierarchy,多級內存層次結構),所以我們需要計算一個綜合延遲。?
這兩種公式,其實對應了兩種不同的層級訪問策略(memory access strategy)
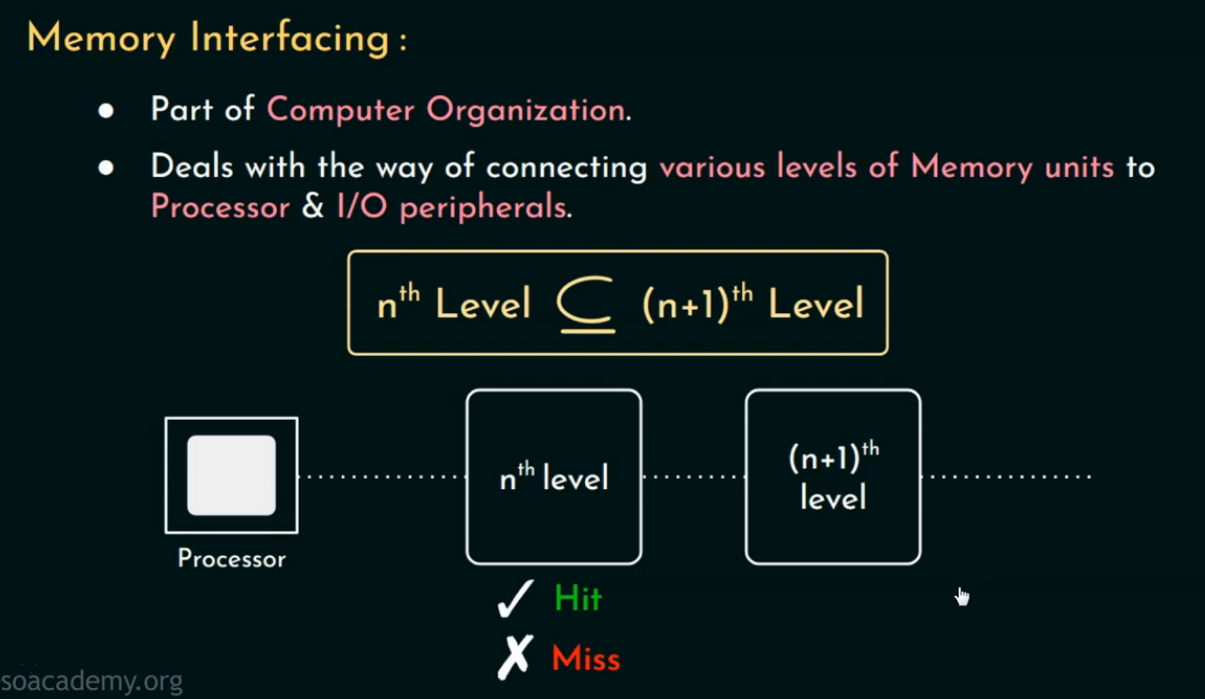
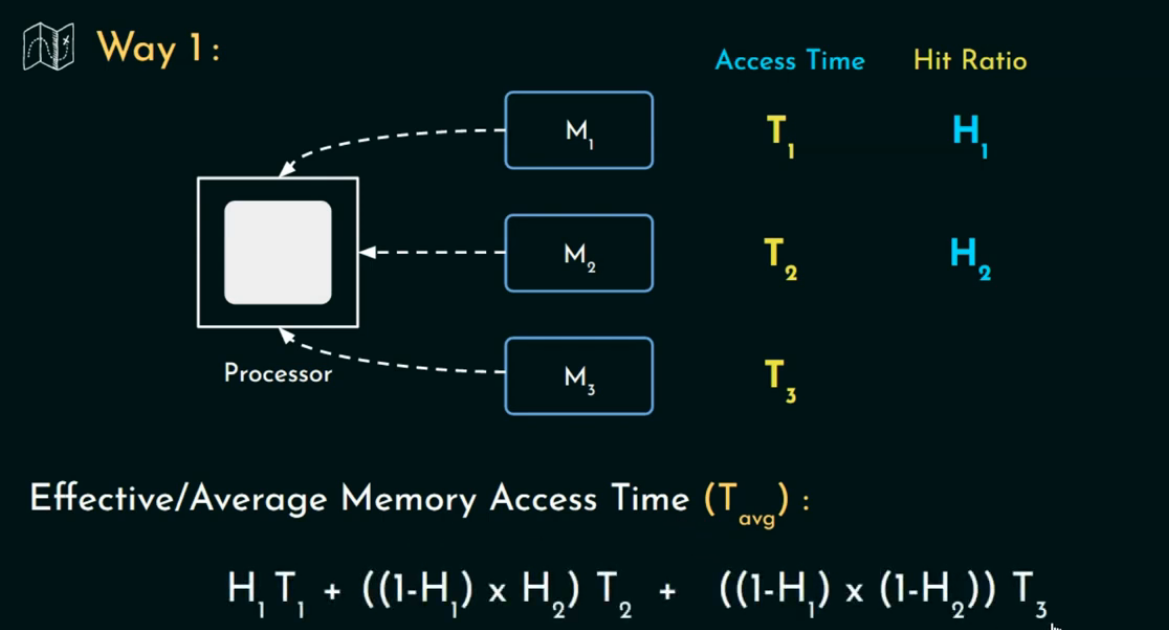
串行訪問(Serial Access Model)
在這種模型下:
-
CPU 一級一級地訪問內存層級:先查 L1 Cache → 如果 Miss 再查 L2 → 如果還 Miss 再查主存(Memory)。
-
每次只訪問一個層次,如果命中了,就不繼續往下找。
-
H1?,H2?:第1、2級緩存的命中率(hit rate)
-
T1?,T2?,T3?:第1、2級緩存和主存的訪問時間(access time)
 ??
??
通俗解釋:
就像你要在一個大圖書館找一本書:
-
你先去最近的書架(L1)找;
-
找不到再去二樓(L2);
-
如果還找不到,才去圖書館最深處(Memory)。
每次你只動一步,只有沒找到才走下一步。
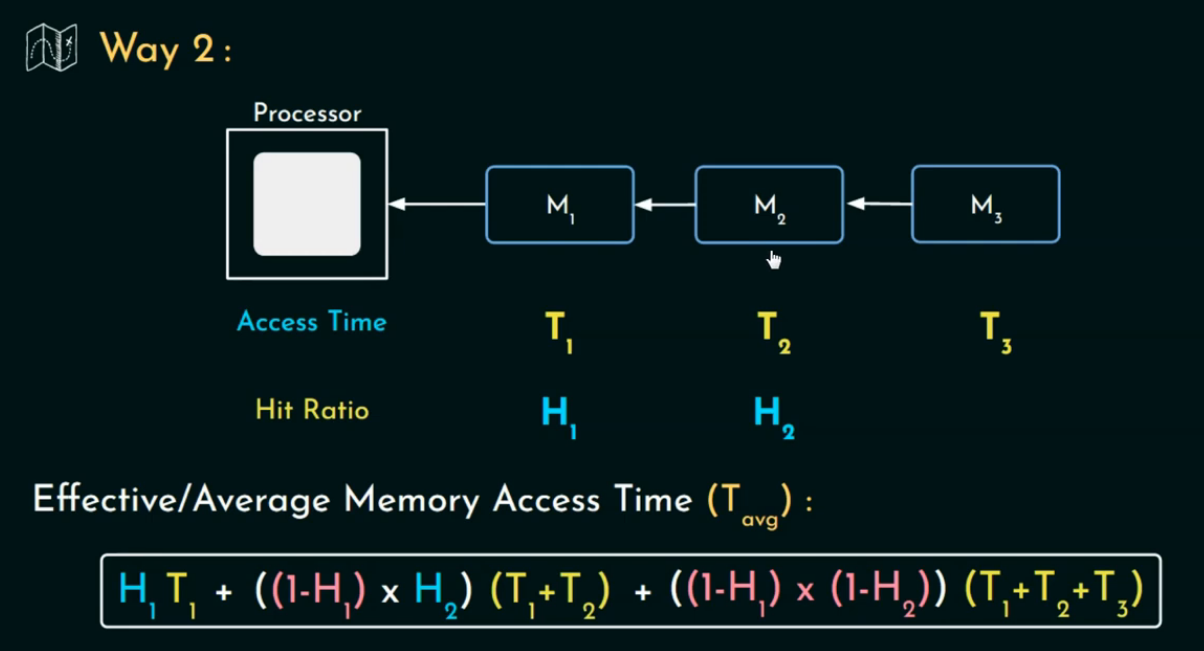
并行訪問(Parallel Access Model)
在這個模型下:
-
所有層級同時開始訪問(look-through),但只有命中最低層才使用它的數據。
-
每次你 miss 上一層,就會把前面“浪費掉的等待時間”也算上。
注意這里每層訪問時間是累加的,因為所有層是并發啟動的,miss 時你還得等前面那幾層“白白等的時間”。?
?
通俗解釋:
你像是在同時發送3個郵件請求給不同的圖書管理員:
-
如果第一個管理員(L1)找到了,他最快回你;
-
如果他沒找到,而第二個找到了,你要等 L1 的時間 + L2 的時間;
-
如果前兩個都沒找到,那你得等 L1 + L2 + 內存 的時間。
每一層你都等了一遍,結果可能還是沒拿到你要的書。
?
?
串行模型(Serial) 更接近實際硬件層級 Cache 的使用方式(大多數 CPU 是這樣設計的);
并行模型(Parallel) 更適合某些流水線處理場景或預測式 prefetch 架構。
?
—— Spring MVC)



_54)








)





