1. 引言
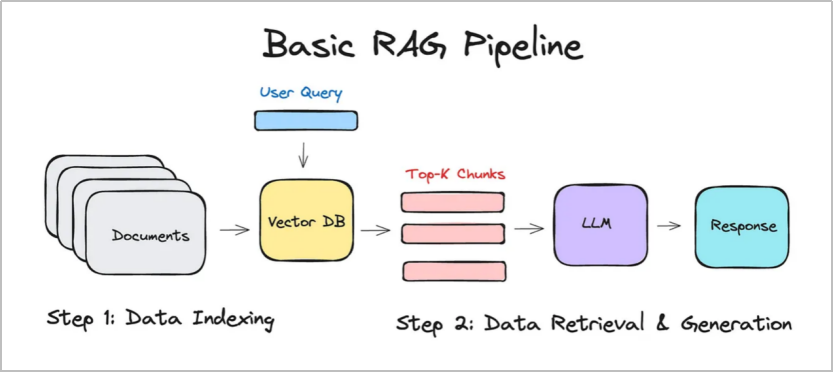
**檢索增強生成(RAG)**是指通過檢索對大模型生成進行增強的技術,通過充分利用信息檢索(尤其是語義檢索)相關技術,實現大模型快速擴展最新知識、有效減少幻覺的能力。主流RAG框架包括問題理解、知識檢索、知識選擇/重排、答案生成等幾個過程,并且通常來說這幾個步驟是順序執行的(pipeline),如下圖(圖片引用自https://medium.com/@mayssamayel4/building-a-rag-system-with-gpt-4-a-step-by-step-guide-291711342f0d)所示:
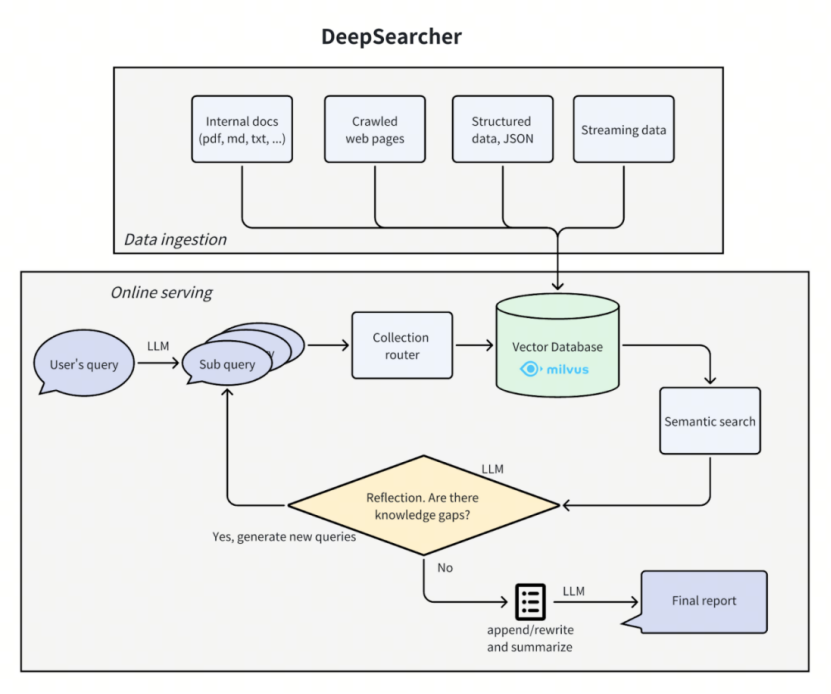
繼RAG之后,研究人員提出了DeepSearch技術,主要是針對RAG的單輪串行流程可能無法進行準確回答的問題,提出通過多輪的問題擴展、檢索、上下文判別的方式,實現對問題更加完整、準確的回答。DeepSearch流程不是順序的pipeline,而是循環流程,如下圖(圖片引用自https://milvus.io/zh/blog/introduce-deepsearcher-a-local-open-source-deep-research.md)所示。
循環流程是指包含重復執行環節的流程。通常來說,普通的數據處理——也就是常見的ETL任務——都是線性流程,包括讀取、轉換、過濾、抽取、入庫等流程節點,他們按照業務要求組合成完整流程,每條數據像水流一樣按照順序“流”經每一個節點。循環流程則能夠基于指定的循環是否終止的判定,對指定的子流程進行重復執行。
SmartETL框架作為一個ETL框架,此前未考慮循環流程。DeepSearch的流程雖然通常是用于問答助手這類應用,但其實也可以用于實現基于大模型的數據處理,例如數據集構造、大模型蒸餾等。因此有必要在框架中增加循環流程的流程控制邏輯。
2.循環流程控制設計
新設計一個特殊的processor組件,命名為While,將可能循環的子流程(對應代碼中的循環體)交給While組件托管,在所給定的條件(匹配或過濾節點)符合時執行子流程。
While組件的構造參數包括:
- 循環子流程,是另一個
Process組件,通常為Chain串聯的一套流程 - 匹配條件,一個函數或函數式對象(實現了
__call__方法的類的對象),或者提供一個字段名,如果這個字段的值不為空,表示條件滿足 - 最大迭代次數,避免進入死循環,且方便評估和控制流程的整體時延。
While組件重寫了__process__方法,這是實現流程循環的關鍵。簡單地說,在每一次迭代中,對每一條輸入數據,檢查匹配條件是否滿足,如果滿足則執行指定的子流程,并收集子流程的輸出數據作為當前迭代的輸出數據(子流程可能產生多條輸出,比如包含Flat操作)。如果匹配條件不滿足,需要注意,這里要將上一次迭代的輸出數據(或整個While循環的輸入)作為整個While循環的輸出,以確保符合循環流程的邏輯。
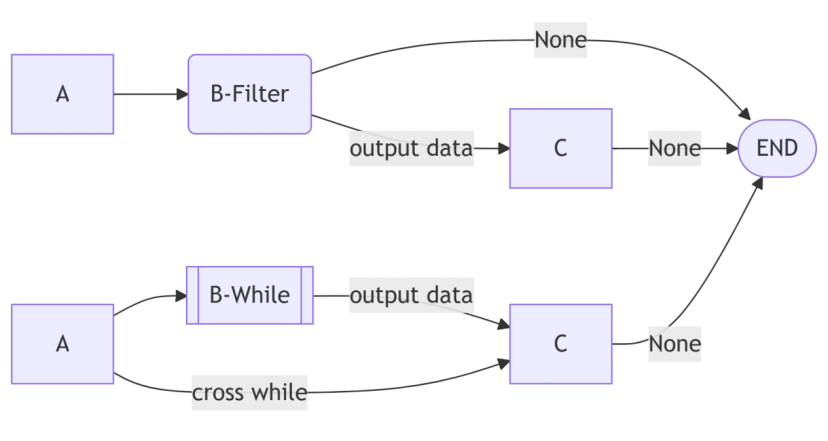
下圖是一個對比普通過濾節點與循環節點的示意圖,流程均為Chain(A, B, C)。在上半部分,數據通過節點B(普通節點或過濾節點)時,如果輸出為None(即沒有輸出),則當前處理流程結束,否則數據傳輸給節點C。在下半部分中,B節點是一個循環節點,如果循環條件不滿足,則數據直接傳輸給節點C,否則將B的子流程的輸出數據傳輸給節點C。
3.DeepSearch應用
DeepSearch應用的處理過程可以看成一種對輸入問題進行循環處理,最終輸出問題答案的數據處理流程。利用循環流程機制,SmartETL可以實現DeepSearch應用,下面介紹這個流程是如何設計的。
首先,需要設計一種數據結構,對DeepSearch的各個階段的狀態進行統一表示。因為ETL框架與普通的編程語言或運行時環境不一樣,ETL流程是以數據為驅動的,每個節點除了自身的配置信息(也稱為組件的環境信息)和當前處理數據以外,通常無法獲得全局信息。SmartETL也在考慮加入某種獲取全局信息的機制。數據結構設計如下:
{“original_query”: “user query”, //原始查詢“gap_queries”: [“query1”, “query2”], //當前的差距查詢列表 最初由原始查詢提示生成,后續通過提示大模型基于original_query、all_sub_queries和all_chunks生成“chunks”: [{“text”: “doc1”}], //當前查詢的檢索結果文檔列表 基于當前gap_queries語義化檢索得到“all_chunks”: [{“text”: “doc1”}, {“text”: “doc2”}], //當前已收集的全部相關文檔 持續合并chunks相關的得到“all_sub_queries”: [“sub1”, “sub2”], //當前全部子查詢 不斷合并gap_queries得到“answer”: “xxxx” //最終答案 通過original_query、all_sub_queries和all_chunks提示給大模型進行生成
}
第二,流程設計。將整個流程劃分為3個階段,如下圖所示:
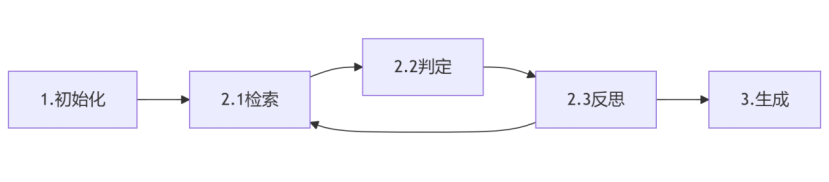
階段1:初始化階段,初始化all_chunks、all_sub_queries字段為空列表,并通過提示大模型生成最初的gap_queries。
階段2:循環流程階段,包括檢索、判定、反思3個具體過程。檢索過程對當前gap_queries進行向量化并檢索,獲得一批候選文檔chunks。判定過程對當前候選文檔進行相關性判定,相關的文檔會合并到all_chunks中。反思過程是基于當前的original_query、all_sub_queries和all_chunks,提示大模型進行推理思考,確定是否還需要進一步搜索,得到的結果作為新的gap_queries字段,但為了保存全部子查詢,這里在生成新的gap_queries之前,將gap_queries合并到all_sub_queries中。
階段3:基于當前的original_query、all_sub_queries和all_chunks,提示大模型進行答案生成。雖然階段2可以執行多次以盡量獲得答案,但是也必須有限制,在達到迭代次數限制或Token超限之后,盡管沒有獲得完全足夠的上下文信息,也需要讓大模型進行生成,避免輸出空的答案。
第三,流程yaml文件編寫。基于已有的數據結構和流程設計,整個流程實現已經變得較為容易了。
不過存在一個問題:在階段2中,需要多次對批量數據進行處理,包括對gap_queries進行向量化、基于向量化結果進行檢索、對檢索結果進行相干性判定。SmartETL框架已有的向量化、大模型調用等組件的設計不支持批量處理,并且這里需要進行邏輯對應,需要逐個gap_query進行向量化、檢索相關文檔,然后對結果文檔逐個進行相關性判定,過濾掉不相關文檔,最后把對應同一個原始查詢的結果進行聚合,以便在階段3進行答案生成。為了實現這個目的,在不增加批量處理算子的情況下,通過扁平化(Flat)、聚合(Group by)、分組收集操作,實現批處理。修改后的數據結果如下所示:
{“original_query”: “user query”, //原始查詢“gap_queries”: [“query1”, “query2”], //當前的差距查詢列表 最初由原始查詢提示生成,后續通過提示大模型基于original_query、all_sub_queries和all_chunks生成“all_chunks”: [{“text”: “doc1”}, {“text”: “doc2”}], //當前已收集的全部相關文檔 持續合并chunks相關的得到“all_sub_queries”: [“sub1”, “sub2”], //當前全部子查詢 不斷合并gap_queries得到“answer”: “xxxx”, //最終答案 通過original_query、all_sub_queries和all_chunks提示給大模型進行生成“sub_query”: “sub1”, //當前的一個子查詢“sub_query_vector”: [0.5, 0.3, .... ], //當前子查詢對應向量 基于sub_query向量化“chunks”: [{“text”: “doc1”}], //當前子查詢的檢索結果文檔列表 基于sub_query_vector的語義檢索“chunk”: {“text”: “doc1”}, //當前的一篇文檔“selected”: true, //當前文檔是否與問題相關 基于提示大模型進行相關性判定“chunks_selected”: [{“text”: “doc2”}] //當前檢索結果中相關的文檔
}
4.總結
本文面向DeepSearch應用的迭代處理需求,基于SmartETL框架設計了循環流程控制,使得支持部分子流程的循環處理。通過設計DeepSearch流程,驗證了循環流程的有效性,并為其他具有循環結構的數據處理流程提供了參考。
附錄
SmartETL項目地址:https://github.com/ictchenbo/SmartETL- 循環流程控制節點代碼:https://github.com/ictchenbo/SmartETL/blob/main/wikidata_filter/iterator/flow_control.py
- 基于
SmartETL的DeepSearch應用流程:https://github.com/ictchenbo/SmartETL/blob/main/flows/agent/deepsearch-v2.yaml - 實現DeepSearch應用的所有大模型提示模板可以在這里找到:https://github.com/ictchenbo/SmartETL/blob/main/config/prompt/deepsearch
- Jina-DeepSearch實施指南:https://jina.ai/news/a-practical-guide-to-implementing-deepsearch-deepresearch/




用法示例(C++和Python))





C++入門教程:前言——你的隨身教程和學習筆記)
重定向 | 時間相關指令 | 文件查找 | 打包與壓縮)
)



)


