命名空間:
C++語言是基于C語言的,融入了面向對象編程思想,有了很多有用的庫,所以接下來我們將學習C++如何優化C語言的不足的。
在C/C++語言實踐中,在全局作用域中變量,函數,類會有很多,這就導致總會有名稱沖突,這時候C++就有命名空間的目的是對標識符的名稱本地化(作用在一個新的作用域里),避免名稱沖突或名字沖突。
命名空間的定義:用namespace關鍵字
namespace T
{int j = 10;int add(int i, int b){return i + b;}struct STR{char a;};
}一個命名空間就定義了一個新的作用域 。
命名空間的使用:
namespace T
{int j = 10;int add(int i, int b){return i + b;}struct STR{char a;};
}using namespace T;//將整個命名空間的內容引入展開using T::j;//使用using將指定命名空間的內容展開int main()
{int j = 20;cout << j << endl;cout << T::j << endl;//指定作用域去找,:: 是作用域限定符
}?上述需要注意的是使用 using 將命名空間的內容展開之后,如果有同名變量存在在同一作用域中的話就會報錯,所以一般為了安全我們一般會使用指定作用域限定符。原因:編譯器在編譯時尋找原則為:1.局部2.全局 3.如果指定了直接去指定域。如果說展開了命名空間,則還是遵循 1局部 2全局 3.指定就去指定找。
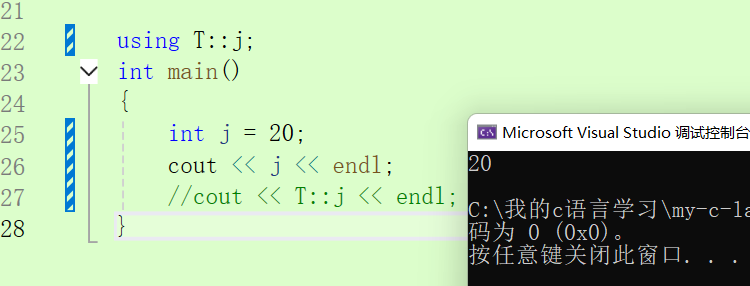
上述就是將命名空間的 j 展開了但是還是會先找局部作用域的。
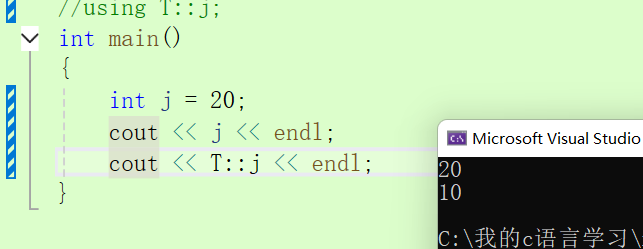
上述就是指定的找。
有時候C語言中變量名字會和庫里面函數的名字沖突無法解決,C++就可以用命名空間解決,也可以解決不同程序員之間命名沖突的問題。
C++輸入和輸出:
#include<iostream>
using namespace std;int main()
{int rand = 20;cout << rand << endl;cin >> rand ;cout << rand << endl;
}如圖上述的代碼,C++ 中一般的輸入和輸出 使用 cin 和 cout 包含在?#include<iostream> 頭文件中,使用命名空間std。當然也可以用C語言中的,因為C++ 兼容C
這里有C++符號的復用(也叫運算符重載),<<? : 1.左移操作符 2.流插入。 >>? : 1.右移 2. 流提取。在C++的輸入輸出中比C更方便,因為會自動識別變量類型。(endl 是特殊符號表示換行相當于 “/n”)。
缺省參數:
缺省參數是聲明或定義函數時為函數的參數指定一個缺省值,調用函數時如果沒有實參,則使用缺省值,有實參就用實參。
//全缺省參數
void Func(int a = 10,int b = 2, int c = 3)
{cout << a + b + c << endl;
}int main()
{Func();
}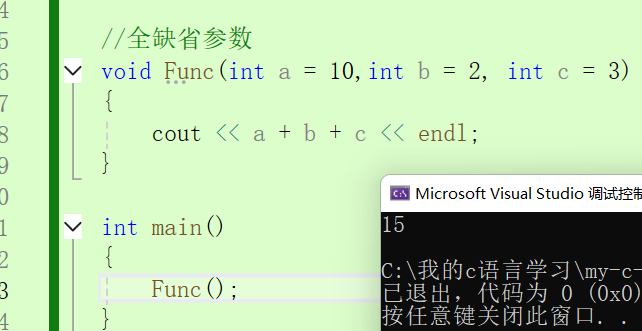 使用了缺省參數。
使用了缺省參數。
還有半缺省參數:
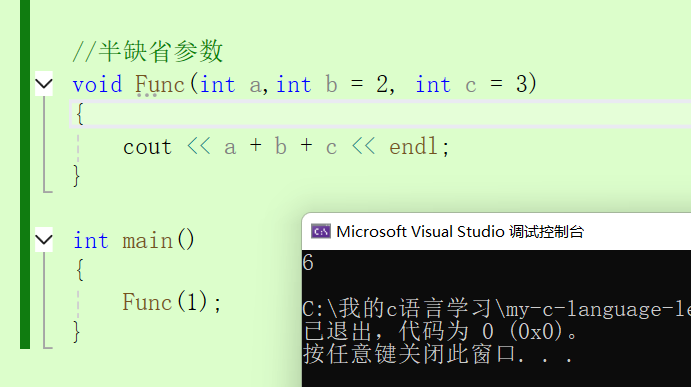
注意:1.半缺省參數只能從右往左依次來給,不能有間隔。2.缺省參數不能同時在聲明和定義中同時存在。3.缺省值必須是常量活著全局變量。4. C語言不支持
函數重載:
C++允許在同一個作用域中聲明幾個功能類似的同名函數,這些函數的區別為他們的形參列表(參數個數,參數類型,或者類型順序)不同。常用來解決功能類似,類型不同的函數問題。
//參數類型不同
int add(int a, int b)
{cout << "int add(int a, int b) :" << a + b << endl;return 0;
}
double add(double a, double b)
{cout << "double add(double a, double b) :" << a + b << endl;return 0;
}//參數個數不同
void F(int i, int j)
{cout << "void F(int i, int j) :" << i << " " << j << endl;
}
void F(int i)
{cout << "void F(int i) :" << i << endl;
}//參數類型順序不同
void F(int a, char b)
{cout << "void F(int a, char b) :" << a << " " << b << endl;
}
void F(char a, int b)
{cout << "void F(char a, int b) :" << a << " " << b << endl;
}
int main()
{//參數類型不同add(10,20);add(1.1, 2.2);//參數個數不同F(10, 20);F(10);//參數類型順序不同F(10, 'I');F('I', 10);
}?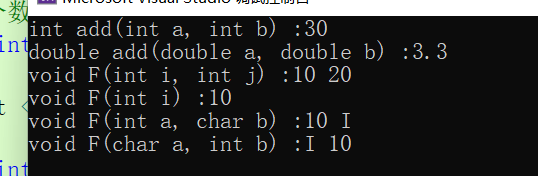
這就是函數重載。很方便。
注意:返回值不同不能構成函數重載,編譯器無法識別。
為什么可以函數重載------原理:名字修飾
首先我們了解到一個程序走起來,需要四個階段:1.預處理 2.編譯 3.匯編 4.鏈接
在實踐中,聲明和定義一般是分開的,編譯器編譯時會拿到函數的聲明這時沒有定義就沒有函數的地址,但是會先過掉,因為有聲明在。之后就是匯編形成符號表。
最后鏈接時,看到調用了某個函數但是沒有函數的地址,就會在其他文件的符號表中去找函數的地址,那鏈接器根據什么去找呢?
在C語言中:鏈接時,直接用函數名去找地址,如果有同名函數,編譯器區分不開,就會報錯。
C++支持函數重載:會有一套函數名字修飾規則,在函數名字中引入參數類型之類的填入符號表,這樣子編譯器尋找時就可以精確找到對應函數地址。
所以只要參數不同,修飾的名字就不同,就支持了重載。








)

)



)


![[BUG]Cursor C++擴展不支持](http://pic.xiahunao.cn/[BUG]Cursor C++擴展不支持)

