在當今的高并發系統中,分布式鎖是保障數據一致性和系統穩定性的重要手段。今天,我們就來深入探討一下Redis分布式鎖,揭開它神秘的面紗。
1 本地鎖與分布式鎖的區別
在Java開發的早期階段,我們接觸過synchronized和Lock鎖,這些都屬于本地鎖。本地鎖的特點是僅對當前節點有效,舉個例子:假設我們有兩個節點node A和node B,當node A獲取了本地鎖時,node B依然可以獲取相同的鎖。

如果我們的服務僅部署了一個節點,本地鎖是完全能夠滿足需求的。但隨著業務的發展,為了應對高并發、實現高可用和高性能,很多系統會采用多節點(集群部署)的方式。此時,本地鎖就顯得力不從心了,分布式鎖便應運而生。
為什么本地鎖鎖不住?
- 鎖范圍有限:有多個服務實例時,本地鎖只在自己的實例里起作用。像
synchronized,不同實例的鎖對象(字節碼 )不一樣。大量用戶查文章詳情,緩存沒數據時,不同實例的線程都能去連MySQL,本地鎖攔不住。- 跨進程管不了:服務分布式部署,在不同JVM進程里。本地鎖只能管自己進程內的線程,別的進程線程來訪問MySQL ,它管不了。
- 高并發頂不住:高并發時很多請求同時來,本地鎖在單個JVM里搶鎖很厲害,而且它也沒法阻止其他JVM進程的線程訪問MySQL ,數據庫還是可能被大量請求弄“掛” 。
分布式鎖的鎖對象不在服務實例中,而是在服務實例的外部。分布式鎖的核心思想是,當一個節點獲取到鎖后,其他節點無法獲取該鎖,從而保證了在分布式環境下的資源同步訪問。
分布式鎖的多種實現方式:
- Redis分布式鎖;
- Zookeeper分布式鎖;
- MySQL分布式鎖。
2 Redis分布式鎖、Zookeeper分布式鎖與MySQL分布式鎖的差異
談到分布式鎖,就不得不提到CAP理論,即強一致性(Consistency)、可用性(Availability)和分區容錯性(Partition Tolerance),三者只能選其二。
- Redis分布式鎖 :它追求的是高可用性和分區容錯性。Redis在寫入主節點數據后,會立即返回成功,而不關心異步主節點同步從節點數據是否成功。由于Redis是基于內存的,其性能極高,官方給出的指標是每秒可達到10W的吞吐量。適用于對性能要求較高、允許一定數據延遲一致性的場景,比如一般的電商商品瀏覽、秒殺活動中的部分非核心數據校驗等場景。
- Zookeeper分布式鎖 :Zookeeper更側重于強一致性和分區容錯性。在寫入主節點數據后,Zookeeper會等待從節點同步完數據后才返回成功,這在一定程度上犧牲了可用性。常用于對數據一致性要求極高的場景,例如金融行業的賬務處理等場景。
- MySQL分布式鎖 :
- 實現原理:通常利用數據庫自身的事務機制和行鎖、表鎖等特性來實現。比如通過在特定表中插入或更新特定記錄,并利用事務的原子性來獲取鎖。若插入或更新成功則表示獲取鎖成功,否則獲取失敗。
- 性能方面:相比Redis基于內存的操作,MySQL分布式鎖由于涉及磁盤I/O(即使有緩存機制 ),在高并發場景下性能相對較低。例如在大量短時間內的鎖競爭場景中,Redis可能輕松應對每秒數萬甚至數十萬的請求,而MySQL可能每秒只能處理數千請求。
- 一致性與可用性:它在一定程度上能保證數據的強一致性,因為基于事務機制,數據操作要么全部成功,要么全部失敗。但在可用性方面,當數據庫出現故障(如主庫宕機 )時,可能導致鎖服務不可用,且恢復時間相對較長。而且,若鎖表等關鍵資源出現瓶頸,會嚴重影響整個系統的可用性。
- 適用場景:適用于對一致性要求較高,并發量不是特別極端高,且業務邏輯相對復雜,需要借助數據庫事務特性來保證數據完整性的場景,比如一些企業內部的業務流程審批系統,涉及多步驟數據更新和狀態轉換,利用MySQL分布式鎖可以結合事務更好地控制流程順序和數據一致性。
綜合考慮,為了追求更好的用戶體驗度,在高并發且對性能要求較高、對數據一致性有一定容忍度的場景下,很多時候會選擇Redis分布式鎖來實現;而在對一致性要求極高,對性能要求相對沒那么苛刻的場景下,可能會選擇Zookeeper分布式鎖或MySQL分布式鎖。
3 使用Redis分布式鎖的背景
以查詢文章詳情為例:
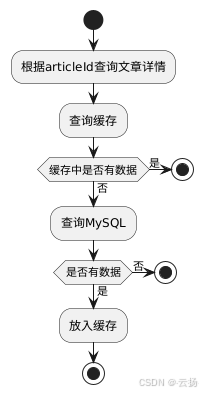
用戶根據articleId查詢文章詳情時,正常流程是先查詢緩存,如果緩存中有數據,直接返回;如果緩存中沒有數據,則需要到MySQL中查詢。在并發量不高的情況下,這個流程沒有問題。但當并發量很高時,就會出現問題。假設緩存中沒有數據,大量用戶會同時訪問DB層的MySQL。而MySQL的資源相對珍貴,且性能不如Redis,很容易導致MySQL被打宕機,進而影響整個服務。
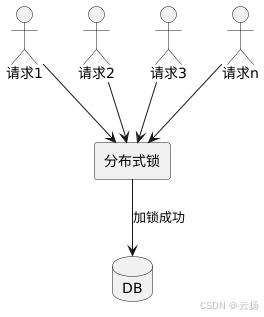
為了解決這個問題,當大量用戶同時訪問同一篇文章時,我們只允許一個用戶去MySQL中獲取數據。由于服務是集群化部署的,所以需要用到Redis分布式鎖。通過加鎖的方式,可以有效地保護DB層數據庫,保證系統的高可用性。
4 Redis分布式鎖的實現方式
4.1 Redis實現分布式鎖
- 項目倉庫(GitHub):https://github.com/itwanger/paicoding
- 項目倉庫(碼云):https://gitee.com/itwanger/paicoding
- 分支:
origin/feature/redis_distributed_lock_20230531
4.1.1 第一種方式:setIfAbsent(key,value,time)
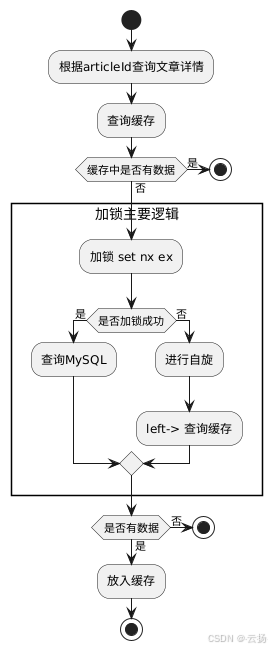
使用redisTemplate.opsForValue().setIfAbsent(key, value, time, TimeUnit.SECONDS),對應的Redis命令是set key value EX time NX。這是一個復合操作,由setNx + setEx組成,底層采用lua腳本來保證原子性,要么全部成功,否則加鎖失敗。其含義是:如果key不存在,則加鎖成功,返回true;否則加鎖失敗,返回false 。
代碼實現:
/*** Redis分布式鎖第一種方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBOne(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;ArticleDTO article = null;// 加分布式鎖:此時value為null,時間為90s(結合自己場景設置合適過期時間)Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, null, 90L);if (isLockSuccess) {// 加鎖成功可以訪問數據庫article = articleDao.queryArticleDetail(articleId);} else {try {// 短暫睡眠,為了讓拿到鎖的線程有時間訪問數據庫拿到數據后set進緩存,// 這樣在自旋時就能夠從緩存中拿到數據;注意時間依舊結合自己實際情況Thread.sleep(200);} catch (InterruptedException e) {e.printStackTrace();}// 加鎖失敗采用自旋方式重新拿取數據this.queryDetailArticleInfo(articleId);}return article;
}
這種方式的主要邏輯是:當緩存中沒有數據時,開始加鎖,加鎖成功則允許訪問數據庫,加鎖失敗則自旋重新訪問。但它存在一個缺點,雖然在setIfAbsent中設置了過期時間,但可能會出現業務執行完之后,鎖還被持有的情況。雖然Redis有淘汰策略,但這種情況還是不建議出現,因為Redis緩存資源非常重要,正確的做法應該是業務執行完后直接釋放鎖。
4.1.2 第二種方式:setIfAbsent(key,value,time)的優化
為了解決第一種方式中鎖不能及時釋放的問題,我們在業務執行完畢之后(增加finally塊)立即刪除key值。
代碼實現:
/*** Redis分布式鎖第二種方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBTwo(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;ArticleDTO article = null;Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, null, 90L);try {if (isLockSuccess) {article = articleDao.queryArticleDetail(articleId);} else {Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {// 和第一種方式相比增加了finally中刪除keyRedisClient.del(redisLockKey);}return article;}
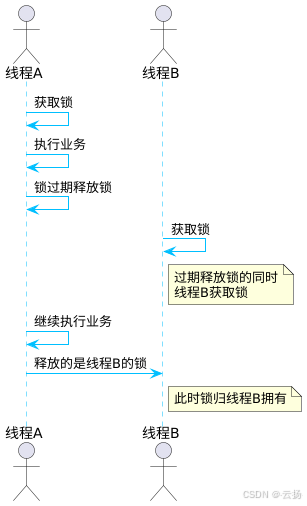
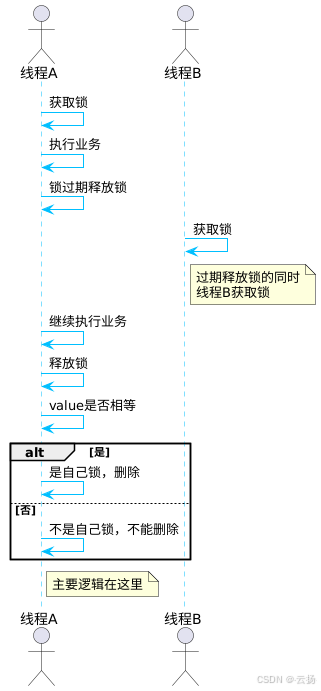
但這種方式也存在問題,比如線程A獲取到鎖并正在執行業務,還未執行完成時,鎖的過期時間到了,該鎖被釋放。此時線程B可以獲取該鎖并執行業務邏輯,而當線程A執行完成后,它釋放的將是線程B的鎖,即釋放了別人的鎖。
4.1.3 第三種方式:改進誤釋放鎖的問題
為了解決誤釋放他人鎖的情況,我們在加鎖時設置一個value值,然后在釋放鎖前判斷給key的value是否和前面設置的value值相等,相等則說明是自己的鎖,可以刪除;否則是別人的鎖,不能刪除。
代碼實現:
/*** Redis分布式鎖第三種方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBThree(Long articleId) {String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;// 設置value值,保證不誤刪除他人鎖String value = RandomUtil.randomString(6);Boolean isLockSuccess = redisUtil.setIfAbsent(redisLockKey, value, 90L);ArticleDTO article = null;try {if (isLockSuccess) {article = articleDao.queryArticleDetail(articleId);} else {Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {// 這種先get出value,然后再比較刪除;這無法保證原子性,為了保證原子性,采用了lua腳本/*String redisLockValue = RedisClient.getStr(redisLockKey);if (!ObjectUtils.isEmpty(redisLockValue) && StringUtils.equals(value, redisLockValue)) {RedisClient.del(redisLockKey);}*/// 采用lua腳本來進行先判斷,再刪除;和上面的這種方式相比保證了原子性Long cad = redisLuaUtil.cad("pai_" + redisLockKey, value);log.info("lua 腳本刪除結果:" + cad);}return article;}
不過,這種方式又帶來了一個新問題,那就是過期時間的值該如何設置呢?
- 如果時間設置過短,可能業務還未執行完畢,鎖就已經過期被釋放,其他線程可以拿到鎖去訪問DB,這就違背了我們加鎖的初衷;
- 如果時間設置過長,可能在加鎖成功后還未執行到釋放鎖時,節點宕機了,那么在鎖未過期的這段時間,其他線程無法獲取鎖。
- 針對這個問題,我們可以寫一個守護線程,每隔固定時間查看業務是否執行完畢,如果沒有執行完畢,則延長其過期時間,即為鎖續期。
4.2 Redission實現分布式鎖
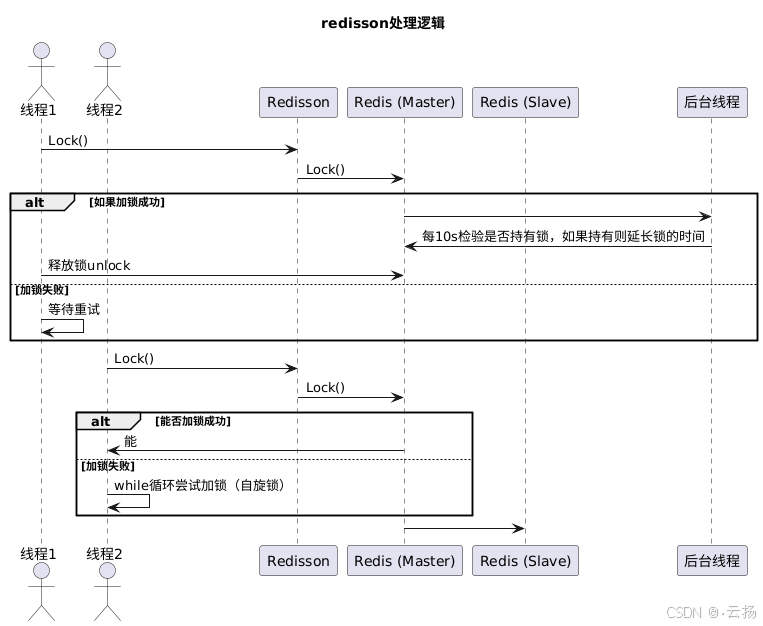
Redission實現分布式鎖的流程是:首先獲取鎖(get lock()),然后嘗試加鎖,加鎖成功后執行下面的業務邏輯,執行完畢之后釋放該分布式鎖。
代碼實現:
/*** Redis分布式鎖第四種方法** @param articleId* @return ArticleDTO*/
private ArticleDTO checkArticleByDBFour(Long articleId) {ArticleDTO article = null;String redisLockKey =RedisConstant.REDIS_PAI + RedisConstant.REDIS_PRE_ARTICLE + RedisConstant.REDIS_LOCK + articleId;RLock lock = redissonClient.getLock(redisLockKey);//lock.lock();try {//嘗試加鎖,最大等待時間3秒,上鎖30秒自動解鎖if (lock.tryLock(3, 30, TimeUnit.SECONDS)) {article = articleDao.queryArticleDetail(articleId);} else {// 未獲得分布式鎖線程睡眠一下;然后再去獲取數據Thread.sleep(200);this.queryDetailArticleInfo(articleId);}} catch (InterruptedException e) {e.printStackTrace();} finally {//判斷該lock是否已經鎖 并且 鎖是否是自己的if (lock.isLocked() && lock.isHeldByCurrentThread()) {lock.unlock();}}return article;
}
Redission解決了Redis實現分布式鎖中出現的鎖過期問題和釋放他人鎖的問題。它還是可重入鎖,內部機制是默認鎖過期時間是30s,然后會有一個定時任務每10s去掃描一下該鎖是否被釋放,如果沒有釋放則延長至30s,這就是看門狗機制。如果請求沒有獲取到鎖,那么它將通過while循環繼續嘗試加鎖。
5 總結
通過本文,我們從原理到實踐,詳細介紹了Redis分布式鎖的相關知識。我們了解了本地鎖與分布式鎖的區別,Redis分布式鎖、Zookeeper分布式鎖、MySQL分布式鎖的差異,以及Redis分布式鎖的幾種實現方式。雖然Redission實現分布式鎖基本解決了大部分問題,但當Redis是主從架構時,它也存在一些問題,比如線程A在master節點加鎖后還未同步到slave節點,此時master節點掛了,線程B仍可以加鎖,這涉及到高一致性問題,Redission無法解決。
如果想要解決高一致性問題,可以使用紅鎖或者zk鎖,它們保證了高一致性,但不建議使用,因為為了保證高一致性,它們丟失了高可用性,對用戶體驗感不好,而且上述問題出現的幾率不大,我們不能因為很小的問題而舍棄其高可用性。
希望本文能幫助大家更好地理解和應用Redis分布式鎖,在實際項目中根據具體需求選擇合適的分布式鎖實現方式。
6 參考鏈接
- 技術派Redis分布式鎖







![Python 趣味學習 -數據類型脫口秀速記公式 [特殊字符]](http://pic.xiahunao.cn/Python 趣味學習 -數據類型脫口秀速記公式 [特殊字符])











