一、核心技術差異
1、?百度文小言?
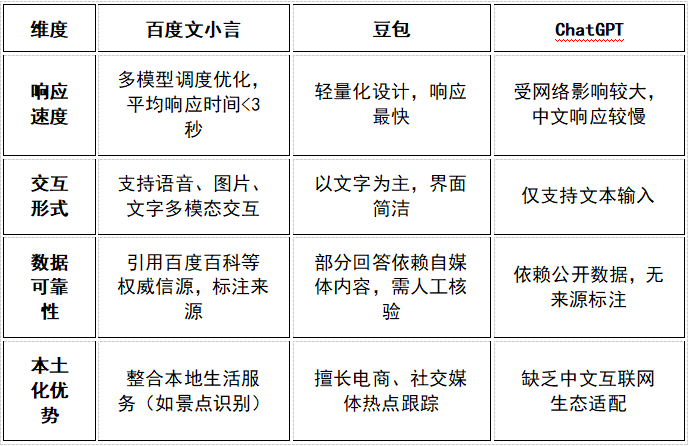
基于文心大模型4.0升級,主打“新搜索”能力,支持多模態輸入(語音、圖片、視頻)和富媒體搜索結果?。
獨有的“記憶個性化”功能可結合用戶歷史行為優化回答,并在醫療、教育等垂直領域表現出色(如驗血報告分析)?。
測試顯示其推理能力和復雜問題處理優于部分國內競品?。
2、?豆包?
采用輕量化模型設計,響應速度更快,適合碎片化場景(如快速生成營銷文案)?。
在用戶模糊提問(如“尤釋然是誰”)時,能通過多源數據拼接生成詳細回答,但存在引用過時或不可靠數據的風險?。
3、?通義千問?
阿里系產品,強調商業場景適配性,擅長數據分析與行業報告生成,被用于企業培訓課程中的“文案匯報、PPT制作”等場景?。
在內容結構化輸出(如分點論述、案例嵌入)上表現突出?。
4、?DeepSeek?
學術領域優勢明顯,提供嚴謹的文獻檢索和摘要生成功能,但面對實時性較強的社會熱點問題時,回答保守且準確性較低?。
5、?ChatGPT(國外)?
通用性更強,語言生成流暢度和創意性領先(如故事創作、代碼編寫)?。
缺乏對中文互聯網生態的深度理解,在涉及國內政策、本土企業案例等場景時易出現偏差?。
二、用戶體驗與場景適配性對比
三、國內外媒體報道與評測結論
1、?深度評測報告?
文小言在醫療、教育等場景的準確率超80%,但需警惕其“記憶功能”可能引發的隱私爭議?。
豆包在“尤釋然”等冷門人物問答測試中表現優于DeepSeek,但存在編造數據的隱患?。
ChatGPT生成內容更自然,但在中文領域錯誤率是國產AI的2-3倍(如政策解讀)?。
2、?行業應用趨勢?
國內平臺更注重“工具屬性”(如文小言的排版優化建議、通義千問的圖表生成)?;
國外產品側重“創意輔助”,適合內容創作者和開發者?。
四、國際視角與對比觀察
1、?技術架構差異?
?DeepSeek創新設計?:采用混合專家模型(MoE)、多頭潛注意力(MLA)架構,推理成本比GPT-4降低30%-50%,開源生態吸引中小開發者,而文心一言、通義千問仍以API封閉服務為主?。
?ChatGPT語言優勢?:在創意寫作、多語言支持上保持領先,但缺乏中文互聯網生態理解,例如在解讀“網絡流行語”或本土政策時易出現偏差?。
2、?商業化路徑對比?
?國產AI的B端深耕?:DeepSeek與券商合作開發量化交易模型,通義千問嵌入企業培訓系統生成PPT模板,均聚焦企業高頻剛需;ChatGPT則通過開發者生態構建通用工具鏈,缺乏行業定制化能力?。
?成本競爭力?:DeepSeek API調用成本僅為GPT-4的1/10,且支持私有化部署;百度文小言依賴公有云服務,數據合規性門檻較高?。
五、風險提示與未來趨勢
1、?數據可靠性爭議?
豆包、DeepSeek等平臺存在引用自媒體內容未標注來源的問題,ChatGPT因訓練數據非實時,無法覆蓋最新政策變化(如2025年稅收新規)?。
2、?行業預測?
?輕型化趨勢?:DeepSeek推出10B參數小模型適配邊緣設備,文心一言計劃壓縮模型體積以降低算力依賴,與ChatGPT的“大而全”路線形成差異?。
?多模態競賽?:百度文小言已實現圖片/語音搜索,DeepSeek加速圖像數據分析工具開發,而ChatGPT多模態功能尚未全面開放?
總結:差異化競爭格局
?國產AI優勢?:本土數據適配性、垂直場景深耕(如醫療、電商)、多模態交互?;
?ChatGPT優勢?:語言生成能力、全球知識庫覆蓋、開發者生態?;
風險提示?:AI生成內容需人工核驗,避免被過時數據或虛假案例誤導?。

![Python 趣味學習 -數據類型脫口秀速記公式 [特殊字符]](http://pic.xiahunao.cn/Python 趣味學習 -數據類型脫口秀速記公式 [特殊字符])















暴力娛樂篇31)

、數據湖與數據運河)