目錄
定義
種類
如何選擇損失函數?
平方(均方)損失函數(Mean Squared Error, MSE)
均方根誤差
交叉熵
對數損失
筆記回饋
邏輯回歸中一些注意事項:
定義
損失函數又叫誤差函數、成本函數、代價函數,用來衡量算法的運行情況,用符號L表示。
假設我們的回歸函數是:y = wx+b,那么損失函數的作用就是用來獲取誤差,然后來更新w和b,從而使預測值y更貼近真實值。也就是訓練過程就是讓這個損失越來越小的過程(最小化損失函數)。
作用:1衡量模型性能 2優化參數(w和b)
種類
均方誤差(MSE)、均方根誤差(RMSE)、平均絕對誤差(MAE)、交叉熵誤差、對數損失或邏輯回歸損失、Hinge損失、Huber損失、余弦相似損失等。
問題一:為什么這么多損失函數?我該怎么選擇?
因為損失函數是用于優化權重的函數,好的損失函數決定了訓練的速度和質量,因此人們在損失函數下了很大功夫,做了很多研究,就發明了這么多損失函數,用于解決不同的需求和環境。怎么選擇損失函數,其實這些損失函數都能優化權重,你可以隨便選擇一種,當然你也可以跟據損失函數的優缺點,選擇對你任務最優的函數來嘗試。


公式亂碼了:以下是Huber損失的函數
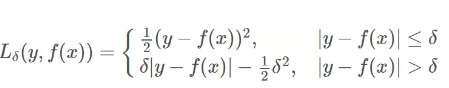

如何選擇損失函數?
選擇損失函數時,您可以根據以下幾個因素來決定:
-
任務類型:如果是回歸問題,常用的損失函數有均方誤差(MSE)、均方根誤差(RMSE)、平均絕對誤差(MAE);如果是分類問題,交叉熵(Cross-Entropy)或對數損失(Log Loss)是常見的選擇。
-
數據特征:如果數據中包含異常值,使用均方誤差可能會讓模型過度關注這些異常值。此時可以考慮使用Huber損失或平均絕對誤差(MAE)。
-
模型類型:一些特定的模型(如支持向量機)通常使用特定的損失函數,比如Hinge損失。
-
計算要求:一些損失函數(如交叉熵)可能需要計算概率值,適用于概率模型;而像均方誤差則適用于普通的回歸模型
如果需要更多學習資料可以打開【咸魚】https://m.tb.cn/h.6h707H6?tk=rRbqVZ2WNdh HU926?
點擊鏈接直接打開,三0元以下帶你完成人臉識別、關鍵點識別、手勢識別等多個項目,涵蓋SVM、knn、yolov8、語義分割!!!零基礎適合小白
上面介紹損失函數的公式以及優缺點,但是大家還是難以有個直觀感受,以下希望通過代碼的形式讓你有個直觀體驗:
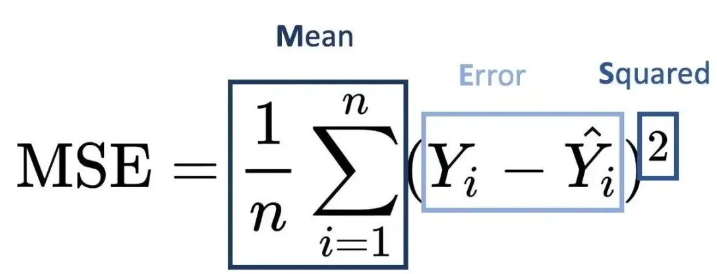
平方(均方)損失函數(Mean Squared Error, MSE)
預測值與真實值的差的平方的n分之一。這個函數不適用于分類問題,而適用于預測的輸出值是一個實數值的任務中,所以整體而言我們不會和他打太多交道(但是在強化學習的TD算法里,我們會遇到)
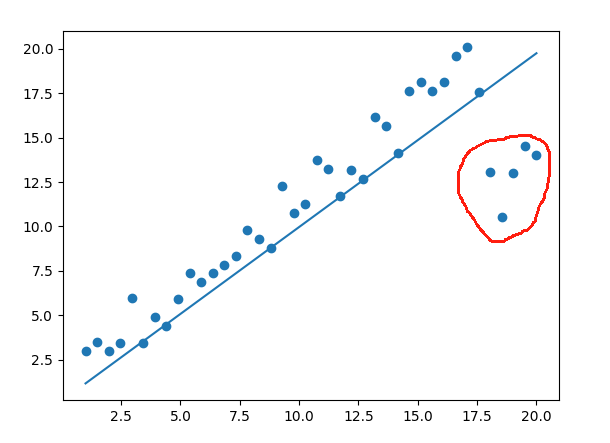
如圖所示,假設我們有一條直線,如果我們的數據存在誤差(比如一張貓的圖片被我們標注成了狗),那么均方損失函數會偏向于懲罰較大的點,賦予了較大權重,如圖藍線靠近了紅色圓圈區域。MSE對異常值非常敏感,因為較大的誤差會受到更大的懲罰(誤差的平方會放大差異)。它通常用于需要精確預測的場景,但可能不適用于異常值較多的數據集。
懲罰的意思就是,平方損失函數在誤差較大時,由于他是平方,也就是誤差的平方,那么訓練的時候那些誤差較大的數據會影響訓練的效果。訓練的模型會過度關注誤差。
這里補充個知識點,離群點也就是紅色圓圈圈起來的點。
代碼:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(1, 20, 40)
y = x + [np.random.choice(4) for _ in range(40)]
y[-5:] -= 8
X = np.vstack((np.ones_like(x),x)) # 引入常數項 1
m = X.shape[1]
# 參數初始化
W = np.zeros((1,2))# 迭代訓練
num_iter = 20
lr = 0.01
J = []
for i in range(num_iter):y_pred = W.dot(X)loss = 1/(2*m) * np.sum((y-y_pred)**2)J.append(loss)W = W + lr * 1/m * (y-y_pred).dot(X.T)# 作圖
y1 = W[0,0] + W[0,1]*1
y2 = W[0,0] + W[0,1]*20
plt.scatter(x, y)
plt.plot([1,20],[y1,y2])
plt.show()這里只是畫出了直線和數據集的表示,并不是拿了損失值優化直線的效果。怎么理解這句話呢,可能需要涉及到epoch概念,就好比我現在畫出的直線就是一個模型,然后圖中的點就是標簽(測試集),可見我們的模型和這些點的距離很大,這個距離就是損失。我們拿著這個損失去優化下一個epoch,也就是下一次迭代中我們的直線就可以更好的擬合這些點。
我想說的是,你要分清損失函數起作用是在那個環節,上圖顯示的只是損失(真實-預測)的大小,并不是均方損失的大小。就是損失可能一般指兩者間的距離,并不是損失函數。我們的MSE需要拿著損失再做一些計算,你不能看著上面的圖就說是MSE損失函數,上面的圖只是真實值與預測值的差距,也就是損失,并不是損失函數!
下面我們拿均方誤差來進行優化w,看迭代20次后,分割的效果。原代碼在下面。
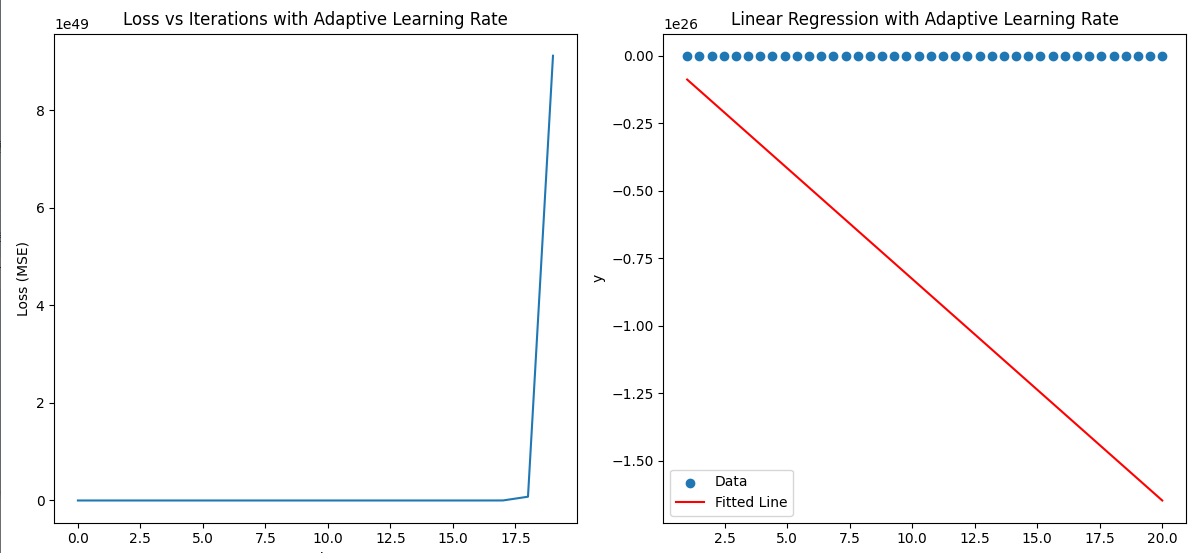
可見我們20層后直線和數據的預測出現了較大的分割,為什么?這里我們通過debug模式發現計算后的損失很大,究其原因是一開始y - y_pred差距太大,而y_pred = X.dot(W)也就是第一層的時候w為0導致y_pred 等于0。這里就涉及初始化權重概念,請跳轉鏈接。
這里我們需要先初始化權重,但是初始化后好像并沒有解決問題。我們通過debug模式發現gradient很大,導致w變得很大,導致欠擬合了。欠擬合和過擬合是什么,請跳轉鏈接
原先w:-50,b:-643
跳整后w:-27,b:-384
第一層接近很多了,但還是導致了梯度爆炸,什么是梯度爆炸,請跳轉鏈接。
# 初始化參數
W = np.array([2.0, 3.0]) # 手動設定初始權重為 [2, 3]看我們的預測好多了一點點。為什么一開始文章說需要根據數據集來選擇不同的損失函數,這就一個方面,但是我們這里不在損失函數上的選擇做文章,我們先通過初始化權重看能不能將直線更好的擬合數據。這里我們通過調整w初始值讓gradient趨近于0,也就是第一層的損失接近于0。
W = np.array([1.5, 2.0]) # 調整1
W = np.array([4.0, 2.0]) # 后面再調整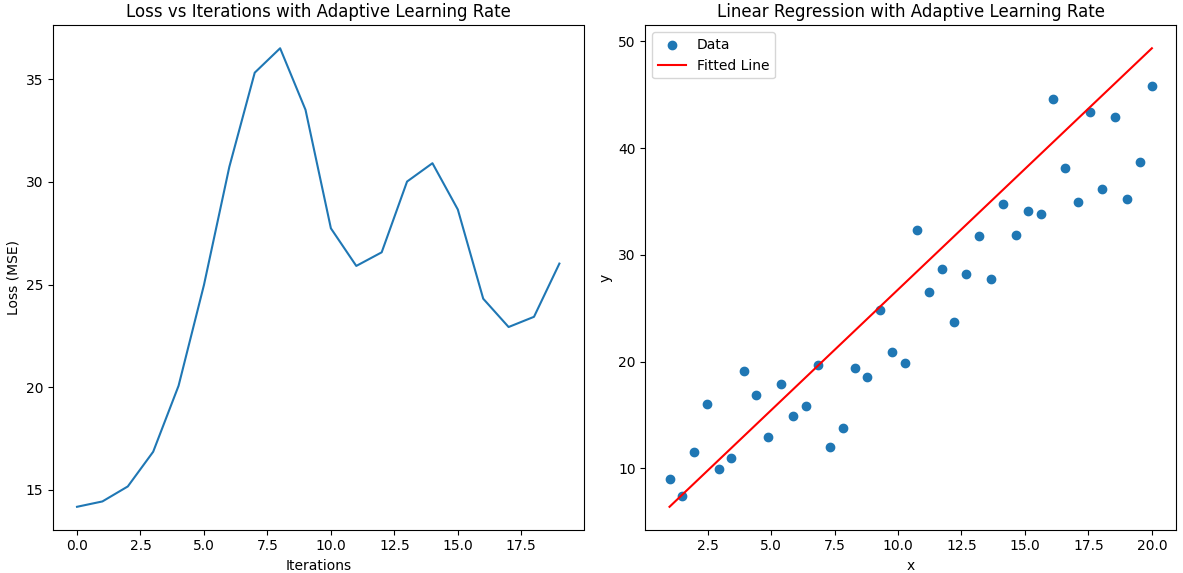
由此可見擬合得很好了,但是這有什么意義呢?通過手動調參來使曲線擬合?首先分析問題出在這個梯度很大導致w變化很大,那么我們需要先解決梯度爆炸問題。
現在我們把權重重新設置為W = np.array([0.0, 0.0]),讓模型產生梯度爆炸。梯度爆炸主要可以通過降低學習率、梯度裁剪、初始化權重、使用優化器、正則化、改變模型架構。
當我們將學習率調整到initial_lr = 0.001時發現,即使初始化權重為0可以擬合數據。
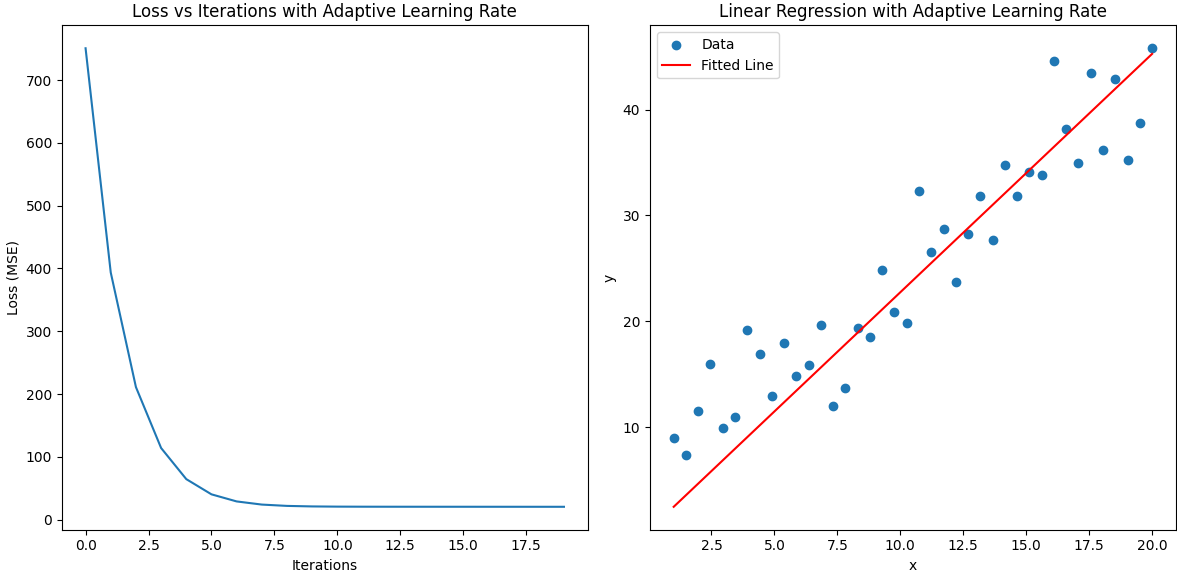
那么難道不是初始化權重的問題嗎?怎么現在學習率更改了也能擬合曲線。我們尋找本質問題其實是由于損失值過大導致的。如果我們一開始的權重就比較好擬合曲線,那么損失值就不會太大,那么后期即使學習率很大,小損失*大學習率-》優化權重,權重變化不會很大,也就是會一值保持較低的損失。但是我們通過MSE評估模型時,發現損失并不是一直下降的。
正常情況下損失應該越來越小,單調遞減的,而不是震蕩的。導致震蕩的原因就是學習率太大了。因此我們還需要調整學習率。那么我們直接調整學習率為什么也能解決問題,還是根據大損失*小學習率-》優化權重,這樣我們的權重也不會出現很大變化,因此小的學習率也可以解決梯度爆炸的問題。
現在我們再來評估初始化權重最本質的作用。
當我們設置正常的學習率0.001
我們對比W = np.array([0.0, 0.0])和W = np.array([4.0, 2.0]) 導致MSE的變化。
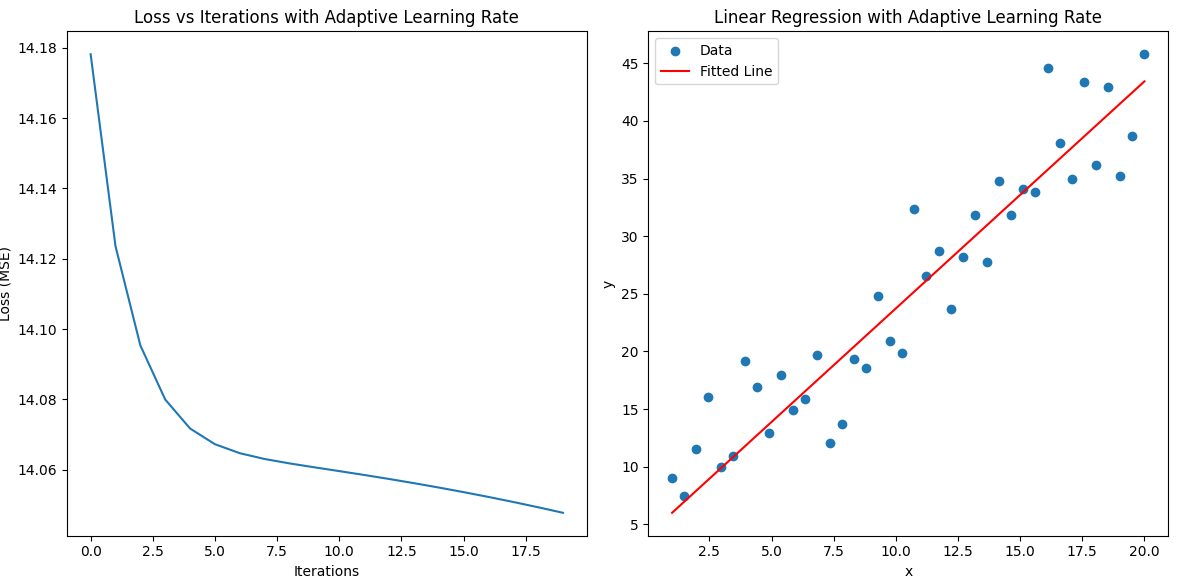
發現MSE在一開始就變得很小,不會從700多往下降。也就是好的初始化權重能讓模型擬合的更快,但是我們多訓練很多層也可以擬合模型,只是有了初始化權重會擬合的更快。
這時候我們再來看這個w0w1,分別是4和2,這和我們制造數據集的公式的兩個權重很接近?
y = 2 * x + 5 + np.random.normal(0, 4, size=x.shape) # y = 2x + 5 + 噪聲
這個公式的兩個權重分別是2和5,我們計算的是2和4,為什么沒有完全擬合,這是因為你有噪聲。如果我們把噪聲去掉呢?
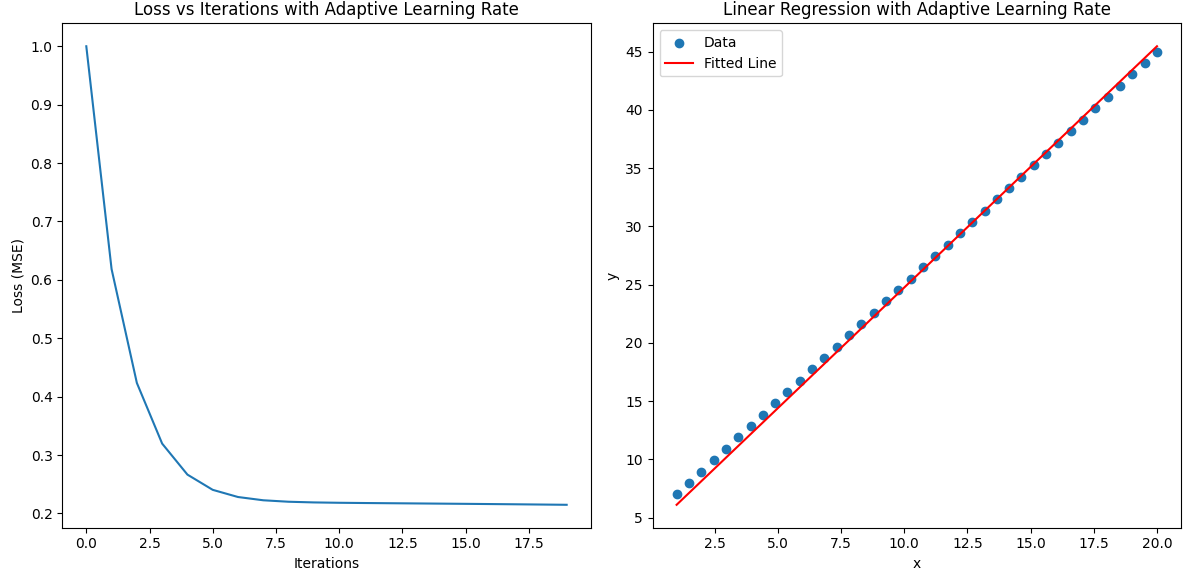
看!多完美的直線哈哈。然后我們也關注到他的損失降低到了0.2左右了,但是我們的w0和w1為什么還是4和2呢?
看起來還沒有擬合,我們加多訓練層數。當訓練層數達到60時,w0變成了4.14了,更靠近5了。70層時達到了4.22。到72層發現損失變大了,75層變得更大,這種現象是什么?這是因為長期損失下降,我們不斷增加學習率,導致后期的學習率過大,小梯度在大的學習率下也會時權重變化過大。這里我們加入loss在小于0.16的時候就不增加學習率。
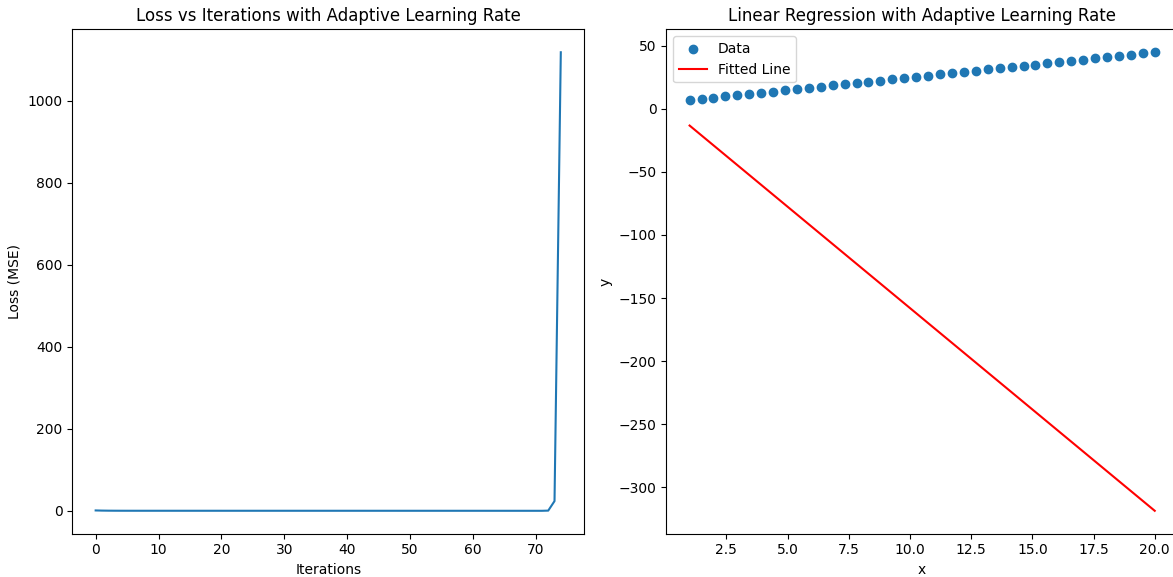
if i > 0 and loss < loss_history[i - 1] and loss > 0.16:
但是我們看損失函數在后期還有較大的波動,我們把loss大于0.17就不會出現了。
# 動態調整學習率if i > 0 and loss < loss_history[i - 1] and loss > 0.17:# 如果損失下降,則增加學習率(但不超過最大學習率)initial_lr = min(initial_lr * lr_adjustment_factor, lr_max)else:# 如果損失沒有下降,減少學習率(但不低于最小學習率)if loss < 0.17 and initial_lr < 0.003:initial_lr = 0.003initial_lr = max(initial_lr / lr_adjustment_factor, lr_min)這時候我們再增加層數到190時,損失能繼續下降,然后繼續修改層數到2000次時,發現此時的w0達到4.9315,已經相當靠近5了。這差不多也就擬合我們的數據了。
但是我們的數據不可能一直這么完美,我們加入點噪聲+ np.random.normal(0, 2, size=x.shape)
我們用提前中斷的方式,獲得一個好的訓練效果。那么我們得到一個判斷就是訓練層數越多,模型越不穩定。很可能在擬合一定效果后得不到提升,這就要提到殘差網絡了,這里不涉及。
總結如下:
1損失函數是每一次迭代后,更新權重,因此你每次看到的回歸直線和數據集間的差距并不是平均損失,而是預測值和真實值之間的差距。我們的損失函數是拿著個差距來計算,更新下次權重的過程。
2梯度爆炸跟學習率和學習步長有關,當然還有初始化權重、正則化、模型、梯度裁剪等方式相關。我們這里嘗試了學習率、權重初始化、梯度裁剪等方式。
3梯度爆炸主要看loss曲線。
4訓練層數太深了模型可能并不能得到提升
#源代碼?
#源代碼
import numpy as np
import matplotlib.pyplot as plt# 數據生成
np.random.seed(42)
x = np.linspace(1, 20, 40)
y = 2 * x + 5 + np.random.normal(0, 4, size=x.shape) # y = 2x + 5 + 噪聲# 添加常數項
X = np.vstack((np.ones_like(x), x)).T # 引入常數項
m = len(x)# 初始化參數
W = np.zeros(2) # 初始權重# 設置超參數
num_iter = 20 # 迭代次數
initial_lr = 0.01 # 初始學習率
lr_adjustment_factor = 1.05 # 學習率調整因子
lr_min = 0.001 # 最小學習率
lr_max = 0.2 # 最大學習率# 存儲損失
loss_history = []# 訓練模型
for i in range(num_iter):# 預測y_pred = X.dot(W)# 計算MSE損失loss = np.mean((y - y_pred) ** 2)loss_history.append(loss)# 計算梯度gradient = -2 * X.T.dot(y - y_pred) / m# 更新參數W -= initial_lr * gradient# 動態調整學習率if i > 0 and loss < loss_history[i - 1]:# 如果損失下降,則增加學習率(但不超過最大學習率)initial_lr = min(initial_lr * lr_adjustment_factor, lr_max)else:# 如果損失沒有下降,減少學習率(但不低于最小學習率)initial_lr = max(initial_lr / lr_adjustment_factor, lr_min)# 每10步打印一次學習率if i % 10 == 0:print(f"Iteration {i+1}/{num_iter}, Loss: {loss:.4f}, Learning Rate: {initial_lr:.5f}")# 創建兩個子圖,進行并排顯示
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
# 輸出最終權重
print(f"Final parameters: W0 = {W[0]}, W1 = {W[1]}")
# 繪制損失曲線
ax[0].plot(loss_history)
ax[0].set_xlabel('Iterations')
ax[0].set_ylabel('Loss (MSE)')
ax[0].set_title('Loss vs Iterations with Adaptive Learning Rate')# 繪制回歸效果
y_pred_final = X.dot(W)
ax[1].scatter(x, y, label='Data')
ax[1].plot(x, y_pred_final, color='r', label='Fitted Line')
ax[1].set_xlabel('x')
ax[1].set_ylabel('y')
ax[1].set_title('Linear Regression with Adaptive Learning Rate')
ax[1].legend()plt.tight_layout() # 自動調整子圖間的間距
plt.show()#修改后?
#修改后
import numpy as np
import matplotlib.pyplot as plt# 數據生成
np.random.seed(42)
x = np.linspace(1, 20, 40)
y = 2 * x + 5 # y = 2x + 5 + 噪聲+ np.random.normal(0, 4, size=x.shape)# 添加常數項
X = np.vstack((np.ones_like(x), x)).T # 引入常數項
m = len(x)# 初始化參數
W = np.array([4.0, 2.0]) # 手動設定初始權重為 [2, 3]
# regularization_strength = 0.01#加入正則化# 設置超參數
num_iter = 2000 # 迭代次數
initial_lr = 0.001 # 初始學習率
lr_adjustment_factor = 1.05 # 學習率調整因子
lr_min = 0.001 # 最小學習率
lr_max = 0.005 # 最大學習率# 存儲損失
loss_history = []# 訓練模型
for i in range(num_iter):# 預測y_pred = X.dot(W)# 計算MSE損失# loss = np.mean((y - y_pred) ** 2) + regularization_strength * np.sum(W**2)loss = np.mean((y - y_pred) ** 2)#MSE# loss = 1/m * np.sum(np.abs(y-y_pred))#MAE# loss = np.sqrt(1/m * np.sum((y - y_pred)**2))#均方根# epsilon = 1e-10 # 避免log(0)的錯誤 交叉熵 有誤 放棄# loss = -np.mean(y * np.log(y_pred + epsilon))loss_history.append(loss)# 計算梯度gradient = -2 * X.T.dot(y - y_pred) / m# 更新參數W -= initial_lr * gradient# 動態調整學習率if i > 0 and loss < loss_history[i - 1] and loss > 0.17:# 如果損失下降,則增加學習率(但不超過最大學習率)initial_lr = min(initial_lr * lr_adjustment_factor, lr_max)else:# 如果損失沒有下降,減少學習率(但不低于最小學習率)if loss < 0.17 and initial_lr < 0.003:initial_lr = 0.003initial_lr = max(initial_lr / lr_adjustment_factor, lr_min)# 每10步打印一次學習率if i % 10 == 0:print(f"Iteration {i+1}/{num_iter}, Loss: {loss:.4f}, Learning Rate: {initial_lr:.5f}")# 創建兩個子圖,進行并排顯示
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
# 輸出最終權重
print(f"Final parameters: W0 = {W[0]}, W1 = {W[1]}")
# 繪制損失曲線
ax[0].plot(loss_history)
ax[0].set_xlabel('Iterations')
ax[0].set_ylabel('Loss (MSE)')
ax[0].set_title('Loss vs Iterations with Adaptive Learning Rate')# 繪制回歸效果
y_pred_final = X.dot(W)
ax[1].scatter(x, y, label='Data')
ax[1].plot(x, y_pred_final, color='r', label='Fitted Line')
ax[1].set_xlabel('x')
ax[1].set_ylabel('y')
ax[1].set_title('Linear Regression with Adaptive Learning Rate')
ax[1].legend()plt.tight_layout() # 自動調整子圖間的間距
plt.show()
平均絕對誤差(Mean Absolute Error,MAE):絕對誤差(MAE)計算的是預測值與真實值之間差的絕對值的平均值。
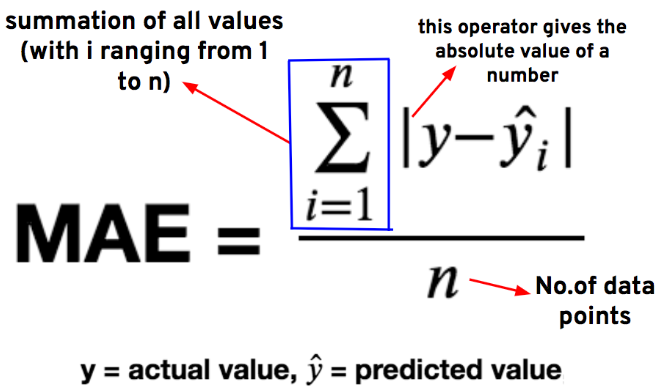
相比于均方誤差,平均絕對誤差對于離群點懲罰力度沒有MSE那么強烈,因為MSE沒有進行平方,而MAE是對誤差進行了平方。你可以將MSE直接替換成MAE,然后看一下最后的訓練效果,我的2000層最后達到了4.9972,比MSE更接近。我們從損失值來判斷兩個函數的效果,發現MAE在訓練中途上升了。而MSE的loss很快就小于0.17了,也就是很快學習率趨于0.003梯度截斷了。這是為什么呢?
兩個函數MSE比MAE更快降低loss,讓學習率趨于穩定。但是我們還是遇到了一個老問題就是中途為什么損失值又上升了。我們是否可以做一些嘗試來避免?其實究其原因還是在較低的損失了,還采用了較高的學習率導致的,即使我們采用了梯度截斷。我們把這個截斷提前或許可以解決這個問題,但是我們是否可以設置一個學習率最大值降低,這樣就可以通過層數來彌補,也不會出現過大的學習率了。
這里我填報了lr_max = 0.005 # 最大學習率
我們看到MAE總是能比MSE更靠近真實值,我是這么認為的,因為MSE是平方,他對loss很敏感。而我們加入了小于0.17就開始減少學習率,也就是說MSE更容易超過0.17,他的步伐邁的比MAE大,因此在小的差距下處理的沒有MAE細膩。
代碼:
# loss = np.mean((y - y_pred) ** 2)#MSEloss = 1/m * np.sum(np.abs(y-y_pred))#MAE均方根誤差
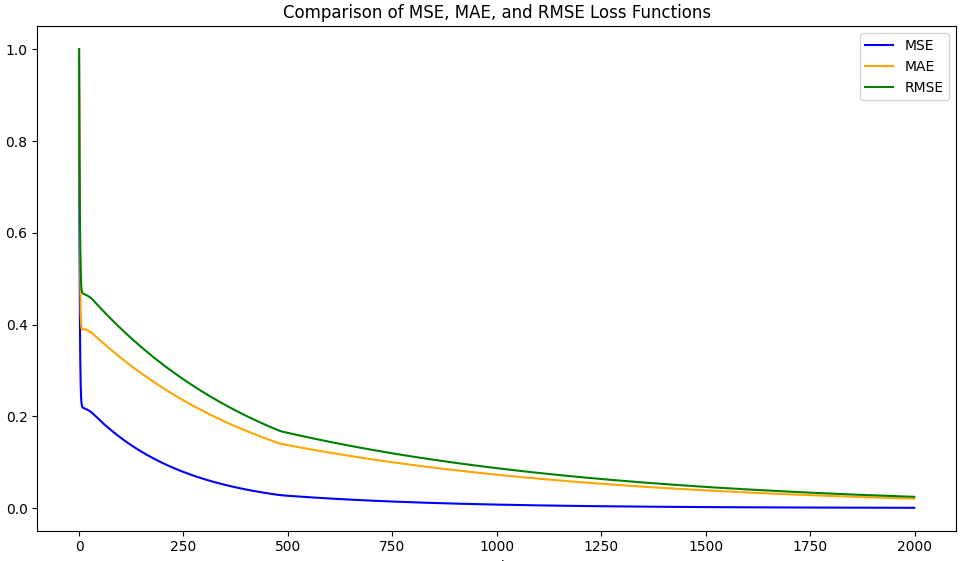
相比于MSE,由于最后進行開根,所以他的量綱和數據本身是一致的,可以更好理解,而MSE則是誤差的平方,RMSE是誤差的平方又開根號,維度是沒有變化的,也就是量綱沒有變化。在效果對于誤差的懲罰力度沒有MSE強。但是處理效果比MSE細膩。
loss = np.sqrt(1/m * np.sum((y - y_pred)**2))#均方根這里我們對三個損失進行了比較,發現RMSE損失降低的最慢,得到的權重更接近于5
交叉熵
交叉熵適合用于處理概率問題,就是他比較適合那種歸一化的問題,并且他會有兩種y和(1-y)兩種情況,適合二分類。
# epsilon = 1e-10 # 避免log(0)的錯誤 交叉熵 有誤 放棄# loss = -np.mean(y * np.log(y_pred + epsilon))#由于我們的是回歸問題這是每個樣本進行的損失計算,因為y只有0和1兩種可能,因此當y=1計算的是-ylog(y^),而右邊部分因為(1-y)=0,所以只計算左邊部分。
其次為什么是負號,這是因為我們的預測值y^是一個概率,只有0到1,log函數在0到1是負數,我們再加一個負號就是正數了,也就是說損失只有正號。
有人要問了,我們優化不是一個類似凸優化的計算嗎,那梯度應該是有正有負的。其實我們的損失計算的只是一個差距,真正的方向(±)是要靠求導后去確定。
對數損失
對數損失其實和交叉熵損失一樣。也就是我們上面那種更像是對數損失。
筆記回饋
-
什么梯度爆炸?(基礎知識)
-
損失是什么?損失函數和損失的關系是什么?(基礎知識)
-
請列舉你知道的損失函數,并且公式是什么?他的缺點和優點是什么?適合什么任務?(面試會考)
-
要如何避免梯度爆炸?(面試會考)
邏輯回歸中一些注意事項:

y = wx+b邏輯回歸公式
這個是做線性回歸用的,對于二分類,評分某個類別的概率需要用到激活函數西格瑪
邏輯回歸
邏輯回歸的代價函數
梯度下降法

為什么損失函數會有兩部分,我的猜想是二分類需要分別評估他是兩種類別的損失,然后加起來。
對數損失和叫交叉熵損失

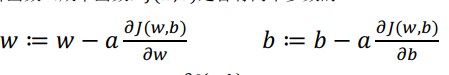
?如果需要更多學習資料可以打開【咸魚】https://m.tb.cn/h.6h707H6?tk=rRbqVZ2WNdh HU926?
點擊鏈接直接打開,三0元以下帶你完成人臉識別、關鍵點識別、手勢識別等多個項目,涵蓋SVM、knn、yolov8、語義分割!!!零基礎適合小白




)



)





——Iterable接口)




)

![【Ai】MCP實戰:手寫 client 和 server [Python版本]](http://pic.xiahunao.cn/【Ai】MCP實戰:手寫 client 和 server [Python版本])