前言
- 1. ResNet — 殘差神經網絡
- 背景
- 核心問題與解決方案
- 原理
- 模型架構
- ResNet 系列變體
- 技術創新與影響
- 2. ViT — Vision Transformer
- 背景
- 核心思想
- 發展歷程
- Transformer的起源:
- ViT的出現:
- ViT的進一步發展:
- 模型架構
- 技術創新與影響
- 3. Swin Transformer
- 背景
- 核心思想
- 模型架構
- 技術創新與影響
- CLIP — Contrastive Language-Image Pre-training
- 背景
- CLIP 核心思想
- 模型架構
- 訓練方法
- 零樣本推理(Zero-Shot Prediction)
- 關鍵實驗結果
- 技術創新與影響
- 5. ViLT — Vision-and-Language Transformer
- 背景
- ViLT 的核心特點
- 模型架構
- 技術創新與影響

人工智能領域的模型架構經歷了從單模態(專注于單一數據類型)到多模態(融合多種數據類型)的跨越式發展。這一過程中,殘差學習、注意力機制、對比學習等技術的突破推動了模型的性能提升和應用場景擴展。本文將深入解析五個里程碑模型——ResNet、ViT、Swin Transformer、CLIP、ViLT,探討其核心架構與技術創新,并梳理從單模態到多模態的技術演進路徑。
1. ResNet — 殘差神經網絡
背景
2015年,何愷明團隊提出的深度殘差網絡(ResNet)解決了深度卷積神經網絡訓練中的梯度消失/爆炸問題,使得構建和訓練超深網絡成為可能。ResNet在ImageNet競賽中取得當時最先進的性能,并獲得了2015年CVPR最佳論文獎。
核心問題與解決方案
傳統CNN模型在層數增加時會遇到退化問題(degradation problem):隨著網絡深度增加,準確率開始飽和,然后迅速下降。ResNet通過引入殘差學習框架解決了這一問題。
原理
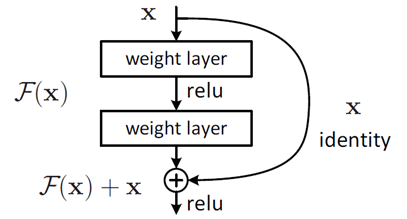
殘差學習(Residual Learning):隨著網絡深度的增加,傳統的深層網絡面臨著梯度消失或梯度爆炸的問題,使得網絡難以訓練。ResNet通過引入“殘差塊”(Residual Block),讓網絡可以輕松地學習恒等映射(Identity Mapping)。這意味著,在深層次網絡中,如果某一層沒有對特征提取有幫助,則該層可以學為零,從而不會對最終結果造成負面影響。
模型架構
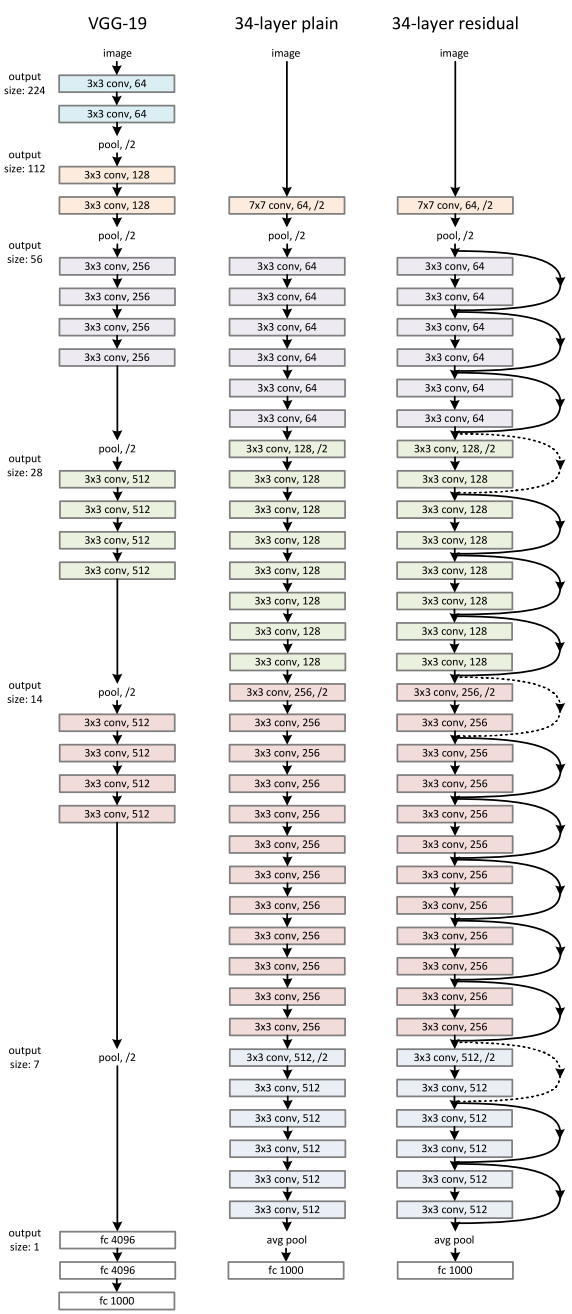
ResNet的架構 : ResNet34 使用的受 VGG-19 啟發的 34 層普通網絡架構,隨后添加了快捷連接。隨后通過這些快捷連接將該架構轉變為殘差網絡,如下圖所示:
ResNet的核心是殘差塊(Residual Block),其結構如下:
- 殘差連接(Skip Connection):將輸入信號直接添加到層的輸出
- 殘差學習:網絡不直接學習原始映射H(x),而是學習殘差
F ( x ) = H ( x ) ? x F(x) = H(x) - x F(x)=H(x)?x
一個基本的殘差塊可以表示為:
y = F ( x , W i ) + x y = F(x, {Wi}) + x y=F(x,Wi)+x
其中F(x, {Wi})表示殘差映射,可以是多層堆疊的卷積操作。
ResNet的完整架構包括:
- 初始卷積層(7×7卷積,步長2)
- 最大池化層(3×3,步長2)
- 4組殘差塊堆疊(每組有不同數量的殘差塊)
- 全局平均池化
- 全連接層+Softmax
ResNet有多種變體,包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,數字表示網絡深度。
ResNet 系列變體
| 模型 | 層數 | 參數量 | 結構說明 |
|---|---|---|---|
| ResNet-18 | 18 | 11M | 基礎殘差塊 |
| ResNet-34 | 34 | 21M | 基礎殘差塊 |
| ResNet-50 | 50 | 25M | Bottleneck 殘差塊 |
| ResNet-101 | 101 | 44M | Bottleneck 殘差塊 |
| ResNet-152 | 152 | 60M | Bottleneck 殘差塊 |
技術創新與影響
- 解決深度網絡訓練問題:殘差連接使得信息可以直接從淺層傳遞到深層
- 梯度流動改善:短路連接有助于梯度在反向傳播中更好地流動
- 表示能力增強:更深的網絡具有更強的特征提取能力
- 訓練穩定性:殘差學習框架使訓練更加穩定
2. ViT — Vision Transformer
背景
2020年10月,谷歌研究團隊發布了論文"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",首次將自然語言處理領域的Transformer架構直接應用于計算機視覺任務,但是因為其模型“簡單”且效果好,可擴展性強(scalable,模型越大效果越好),成為了transformer在CV領域應用的里程碑著作,也引爆了后續相關研究。
核心思想
ViT的核心思想是將圖像視為"單詞序列",摒棄了CNN中的歸納偏置(如平移不變性、局部連接等),完全依賴自注意力機制處理視覺信息。
發展歷程
Transformer的起源:
- 2017年,Google提出了Transformer模型,這是一種基于Seq2Seq結構的語言模型,它首次引入了Self-Attention機制,取代了基于RNN的模型結構。
- Transformer的架構包括Encoder和Decoder兩部分,通過Self-Attention機制實現了對全局信息的建模,從而能夠解決RNN中的長距離依賴問題。
ViT的出現:
- ViT采用了Transformer模型中的自注意力機制來建模圖像的特征,這與CNN通過卷積層和池化層來提取圖像的局部特征的方式有所不同。
- ViT模型主體的Block結構基于Transformer的Encoder結構,包含Multi-head Attention結構。
ViT的進一步發展:
- 隨著研究的深入,ViT的架構和訓練策略得到了進一步的優化和改進,使其在多個計算機視覺任務中都取得了與CNN相當甚至更好的性能。
- 目前,ViT已經成為計算機視覺領域的一個重要研究方向,并有望在未來進一步替代CNN成為主流方法。
模型架構
ViT將輸入圖片分為多個patch(16x16),再將每個patch投影為固定長度的向量送入Transformer,后續encoder的操作和原始Transformer中完全相同。但是因為對圖片分類,因此在輸入序列中加入一個特殊的token,該token對應的輸出即為最后的類別預測
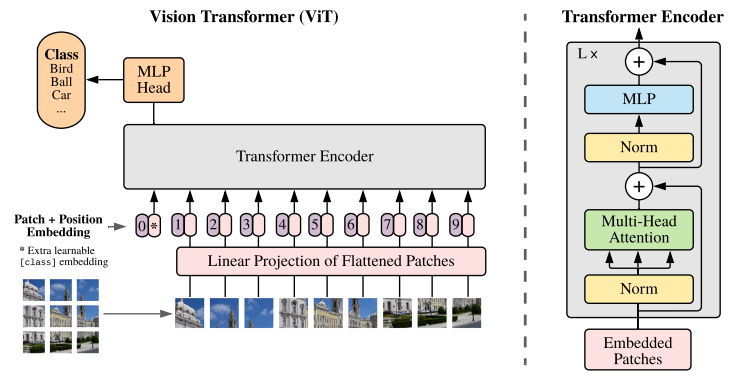
ViT的處理流程如下:
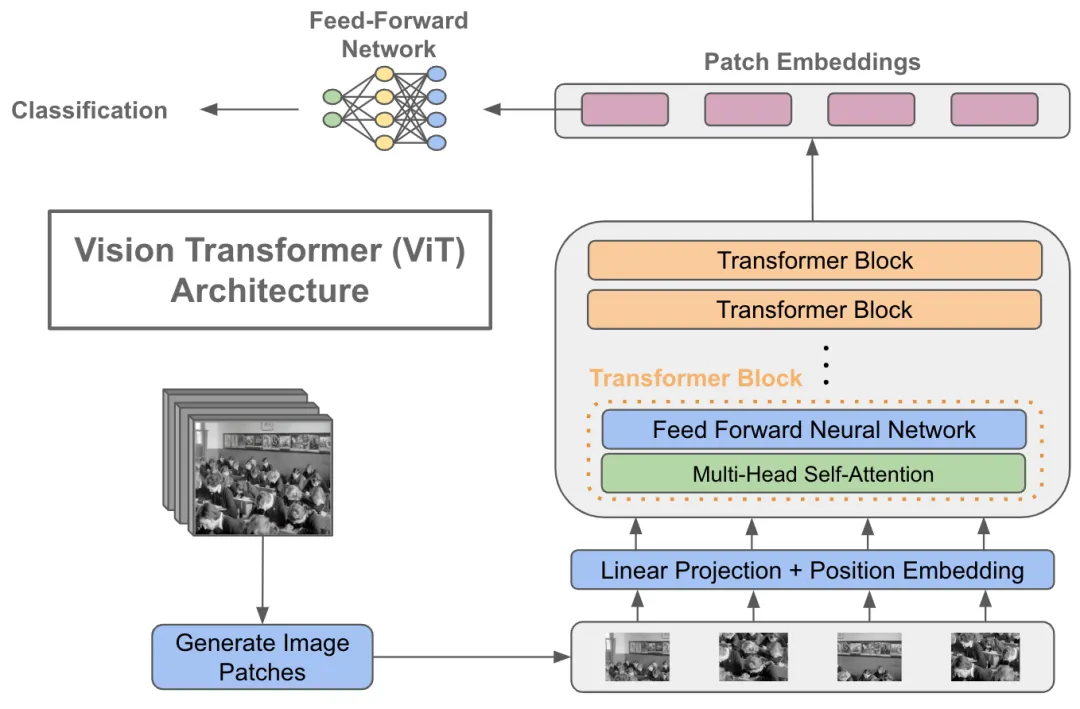
-
圖像分塊與線性投影
- 將輸入圖像劃分為固定尺寸的方形區域(如16×16像素),生成二維網格序列。每個圖像塊經全連接層進行線性投影,轉化為768維特征向量。此時視覺數據完成形態轉換,形成類序列結構。
-
類別標記注入
- 在序列首部插入可學習的分類標識向量,該特殊標記貫穿整個網絡運算,最終作為圖像表征的聚合載體。此操作使序列長度由N增至N+1,同時保持特征維度一致性。
-
位置編碼融合
- 通過可訓練的位置嵌入表為每個序列元素注入空間信息。采用向量相加方式而非拼接,在保留原始特征維度的前提下,使模型感知元素的相對位置關系。
-
Transformer編碼架構
-
由多層相同結構模塊堆疊組成,每個模塊包含:
-
層歸一化處理的多頭注意力機制:將特征拆分為多個子空間(如12個64維頭部),并行捕獲異構關聯模式,輸出重聚合后維持768維
-
多層感知機擴展層:先進行4倍維度擴展(768→3072)增強表征能力,再投影回原維度保證結構統一性
-
-
特征演化與輸出
- 所有編碼模塊保持輸入輸出同維度(197×768),實現深度堆疊。最終提取首位的類別標記向量作為全局圖像描述符,或采用全序列均值池化策略,接入分類器完成視覺任務。這種架構通過序列化處理實現了視覺與語言模型的范式統一。
ViT的公式表示:
z 0 = [ x c l a s s ; x 1 E ; x 2 E ; . . . ; x N E ] + E p o s z_0 = [x_class; x_1^E; x_2^E; ...; x_N^E] + E_pos z0?=[xc?lass;x1E?;x2E?;...;xNE?]+Ep?os
z l = M S A ( L N ( z l ? 1 ) ) + z l ? 1 z_l = MSA(LN(z_{l-1})) + z_{l-1} zl?=MSA(LN(zl?1?))+zl?1?
z l = M L P ( L N ( z l ) ) + z l z_l = MLP(LN(z_l)) + z_l zl?=MLP(LN(zl?))+zl?
y = L N ( z L 0 ) y = LN(z_L^0) y=LN(zL0?)
技術創新與影響
- 打破CNN壟斷:ViT證明了純Transformer架構在視覺任務上的可行性
- 縮小模態差距:為視覺和語言任務提供了統一的架構基礎
- 全局感受野:自注意力機制天然具有全局視野,不同于CNN的局部感受野
- 數據效率權衡:需要大量數據預訓練才能超越CNN模型
ViT的出現標志著計算機視覺領域的范式轉變,開啟了"Transformer時代",大大推動了視覺-語言多模態模型的發展。
3. Swin Transformer
背景
微軟研究院于2021年3月發表Swin Transformer,試圖解決ViT在計算效率和細粒度特征提取方面的局限性,尤其是針對密集預測任務(如目標檢測、分割)。
核心思想
Swin Transformer的核心思想在于利用窗口內的自注意力機制,同時通過層級結構實現跨窗口的信息交互,從而實現了高效的視覺特征提取和表達。具體來說:
- 窗口化自注意力(Window-based Self-Attention, W-MSA):將圖像劃分為不重疊的窗口,僅在每個窗口內進行自注意力計算。
- 移位窗口(Shifted Windows, SW-MSA):通過在相鄰層之間移動窗口位置,實現窗口間的交互,彌補W-MSA缺乏跨窗口連接的不足。
- 層次化結構:借鑒CNN的多尺度設計,Swin Transformer通過逐步合并patch降低分辨率,擴大感受野,形成類似金字塔的特征提取過程
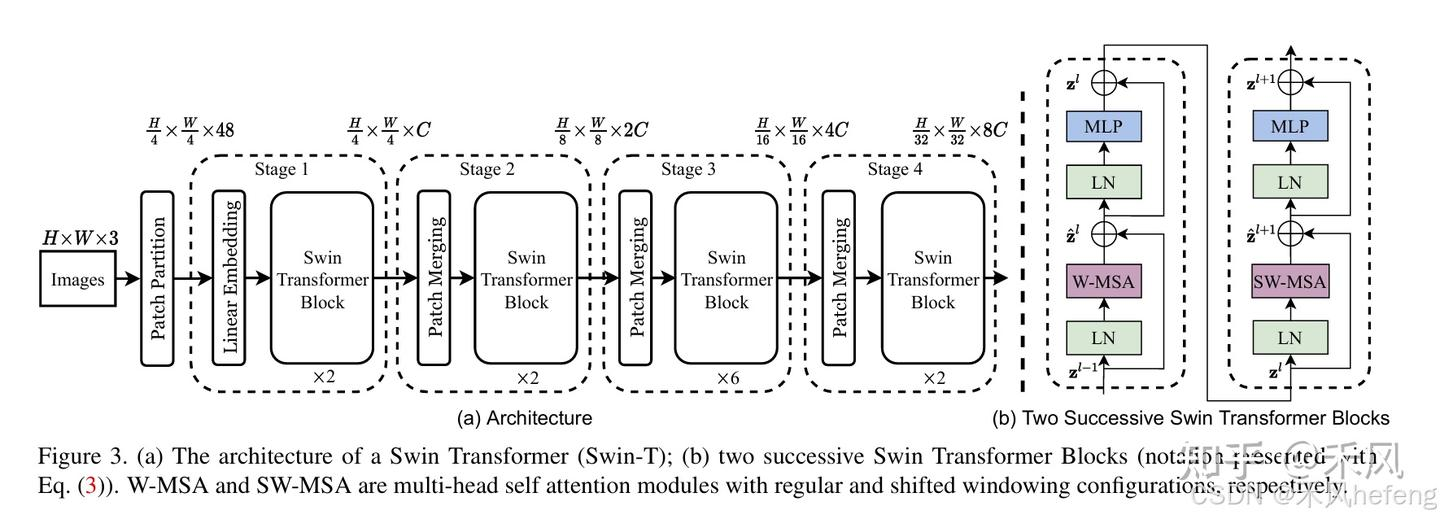
模型架構
Swin Transformer的關鍵設計包括:
- 層級結構:類似CNN的層級特征圖,分辨率逐層下降
- 窗口自注意力:將自注意力計算限制在局部窗口內(如7×7大小)
- 窗口移位操作:在連續層之間交替使用常規窗口和移位窗口,使得不同窗口之間可以交換信息
- 相對位置編碼:在窗口內使用相對位置偏置而非絕對位置編碼
Swin Transformer包含4個階段:
Swin Transformer的整體架構包括Patch Embedding、多個Swin Transformer Block以及分類頭。下面逐步介紹其主要組成部分:
- Patch Partition:這是模型對輸入圖像進行預處理的一種重要操作。該操作的主要目的是將原始的連續像素圖像分割成一系列固定大小的圖像塊(patches),以便進一步轉化為Transformer可以處理的序列數據 2。
- Swin Transformer Block:是模型的核心單元,每個block包含以下步驟:
- Layer Normalization
- W-MSA或SW-MSA
- 殘差連接
- 再次Layer Normalization
- 前饋網絡(FFN)
- 殘差連接
- Patch Merging:為了實現層次化特征提取,Swin Transformer在每個stage結束后通過Patch Merging合并相鄰patch。這一步驟類似于卷積神經網絡中的池化操作,但采用的是線性變換而不是簡單的最大值或平均值操作 5。
- 輸出模塊:包括一個LayerNorm層、一個AdaptiveAvgPool1d層和一個全連接層,用于最終的分類或其他任務 4
技術創新與影響
- 線性計算復雜度:窗口注意力使得計算復雜度與圖像大小成線性關系,而非ViT的二次關系
- 層級表示:生成多尺度特征,適合各種視覺任務
- 跨窗口連接:移位窗口機制允許信息在不同窗口間流動
- 通用視覺骨干網:成為視覺領域的通用主干網絡,用于分類、檢測和分割等多種任務
Swin Transformer成功地將Transformer的優勢與CNN的層級結構相結合,為后續多模態模型提供了更高效的視覺特征提取器。
CLIP — Contrastive Language-Image Pre-training
背景
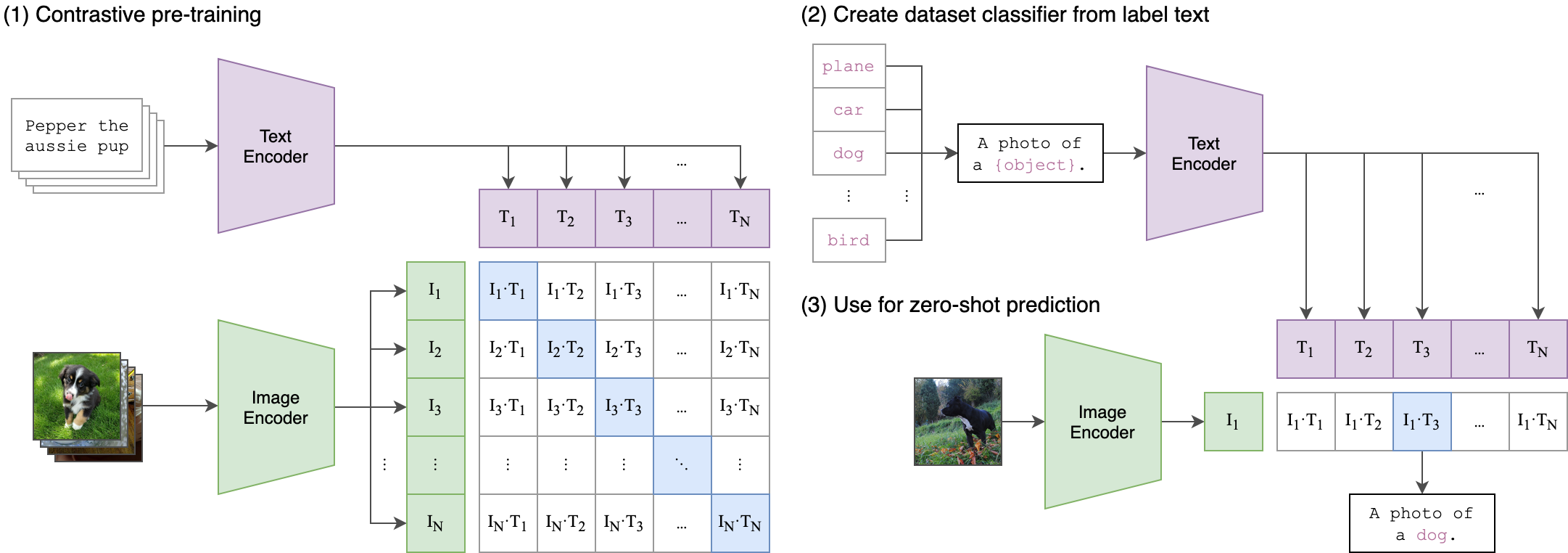
CLIP(Contrastive Language-Image Pretraining)是 OpenAI 在 2021 年提出的 多模態預訓練模型,通過對比學習將圖像和文本映射到同一語義空間,實現 零樣本(Zero-Shot)分類、跨模態檢索等任務。它徹底改變了傳統視覺模型的訓練方式,成為多模態領域的里程碑工作。
CLIP 核心思想
(1) 核心目標
-
學習圖像和文本的聯合表示,使匹配的圖文對在特征空間中靠近,不匹配的遠離。
-
無需人工標注的類別標簽,直接利用自然語言描述(如“一只貓在沙發上”)作為監督信號。
(2) 關鍵創新
-
對比學習(Contrastive Learning):通過大規模圖文對訓練,拉近正樣本對(匹配圖文),推開負樣本對(不匹配圖文)。
-
自然語言作為監督信號:擺脫固定類別標簽的限制,支持開放詞匯(Open-Vocabulary)任務。
-
零樣本遷移能力:預訓練后可直接用于下游任務(如分類、檢索),無需微調。
模型架構
CLIP 包含兩個獨立的編碼器:
-
圖像編碼器(Image Encoder):
-
可選架構:ViT(Vision Transformer) 或 ResNet(如 ResNet-50)。
-
輸入:圖像 → 輸出:圖像特征向量(如 512 維)。
-
-
文本編碼器(Text Encoder):
-
基于 Transformer(類似 GPT-2)。
-
輸入:文本描述 → 輸出:文本特征向量(與圖像特征同維度)。
-
訓練方法
1. 對比損失(Contrastive Loss)
- 對一個 batch 中的 N 個圖文對:
- 計算圖像特征 Ii 和文本特征 Tj的余弦相似度矩陣
S i , j = I i ? T j S i , j = I i ? ? T j ? Si,j=Ii?TjS i,j =I i? ?T j? Si,j=Ii?TjSi,j=Ii??Tj?
損失函數(對稱交叉熵損失):
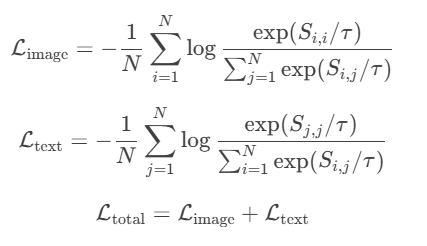
其中τ 是溫度系數(可學習參數)。
(2) 訓練數據
-
數據集:4 億個互聯網公開圖文對(WebImageText)。
-
數據增強:隨機裁剪、顏色抖動等。
零樣本推理(Zero-Shot Prediction)
(1) 分類任務流程
-
構建文本模板:
- 將類別名稱(如“dog”)填入提示模板(Prompt Template),例如:
“a photo of a {dog}”
- 生成所有類別的文本描述,并編碼為文本特征 T1,T2,…,T K 。
- 將類別名稱(如“dog”)填入提示模板(Prompt Template),例如:
- 編碼待分類圖像:得到圖像特征 I
- 計算相似度:
-
圖像特征與所有文本特征計算余弦相似度。
-
選擇相似度最高的文本對應的類別作為預測結果。
-
(2) 優勢
-
無需微調:直接利用預訓練模型。
-
支持開放詞匯:新增類別只需修改文本描述,無需重新訓練。
關鍵實驗結果
(1) 零樣本分類性能
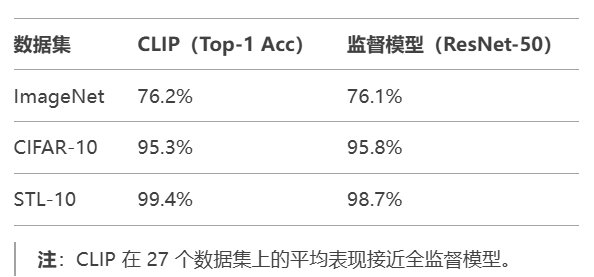
技術創新與影響
- 零樣本遷移學習:無需針對特定任務微調即可應用于新類別
- 大規模預訓練:在4億圖像-文本對上訓練
- 多模態理解:構建圖像和文本的聯合表示空間
- 靈活性:可用于圖像分類、圖像檢索、文本檢索等多種任務
- 減少標注依賴:利用互聯網上自然存在的圖像-文本對訓練
CLIP開創了視覺-語言預訓練的新范式,證明了通過自然語言監督可以學習到強大且通用的視覺表示,奠定了多模態AI系統的基礎。
5. ViLT — Vision-and-Language Transformer
背景
ViLT(Vision-and-Language Transformer)是 2021 年提出的一種 純 Transformer 架構的視覺-語言多模態模型,其核心思想是 用統一的 Transformer 同時處理圖像和文本,無需卷積網絡(CNN)或區域特征提取(如 Faster R-CNN),極大簡化了多模態模型的復雜度。
ViLT 的核心特點
(1) 極簡架構設計
- 完全基于 Transformer:
-
傳統多模態模型(如 LXMERT、UNITER)依賴 CNN 提取圖像特征 或 Faster R-CNN 提取區域特征,計算成本高。
-
ViLT 直接對原始圖像像素進行 Patch Embedding(類似 ViT),文本則通過 Token Embedding 輸入,兩者共享同一 Transformer 編碼器。
-
(2) 模態交互方式
-
單流架構(Single-Stream):
-
圖像和文本的嵌入向量拼接后輸入同一 Transformer,通過自注意力機制直接交互。
-
對比雙流架構(如 CLIP),計算更高效,模態融合更徹底。
-
(3) 輕量高效
-
參數量僅為傳統模型的 1/10:
-
ViLT-Base 參數量約 110M,而類似功能的 UNITER 需 1B+ 參數。
-
訓練速度提升 2-10 倍,適合低資源場景。
-
模型架構
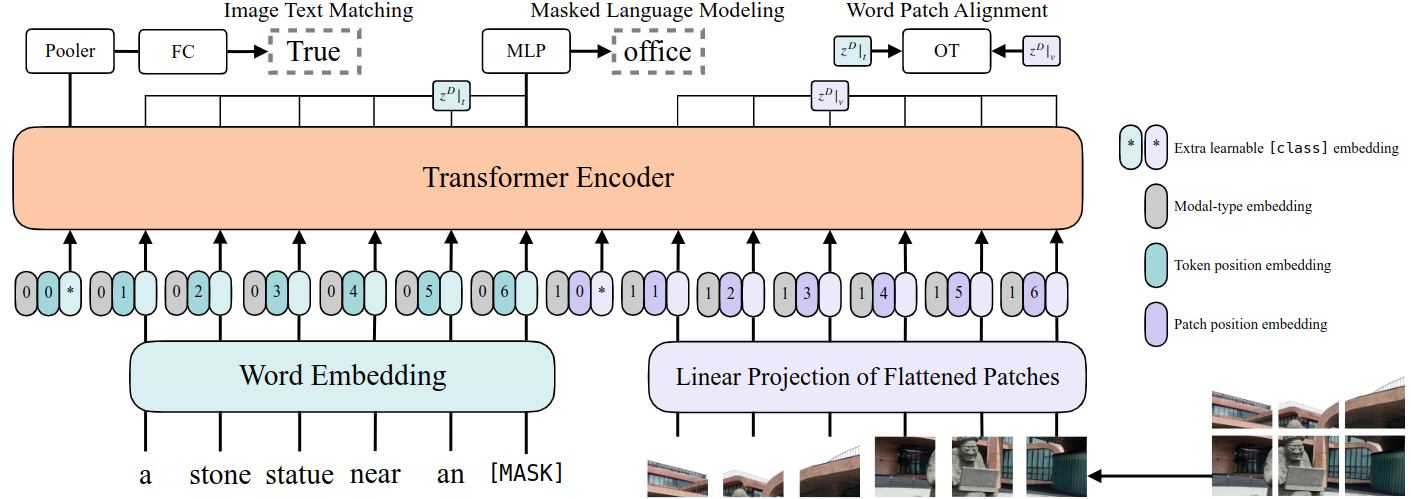
- 文本經過pre-trained BERT tokenizer得到word embedding(前面有CLS token,圖中*表示)
- 圖片經過ViT patch projection層得到patch embedding(也是用*表示CLS token);
- 文本特征+文本位置編碼+模態嵌入得到最終的text embedding,圖像這邊也是類似的操作得到image embedding;二者concat拼接之后,一起輸入transformer layer,然后做MSA交互(多頭自注意力)
(1) 輸入表示
-
圖像輸入:
-
將圖像分割為 N×N 的 Patches(如 32×32)。
-
線性投影為 Patch Embeddings,并添加位置編碼(Position Embedding)。
-
-
文本輸入:
-
使用 WordPiece 分詞,生成 Token Embeddings。
-
添加位置編碼和模態類型編碼(Modality-Type Embedding)。
-
(2) 共享 Transformer 編碼器
-
圖像和文本的 Embeddings 拼接后輸入 Transformer:
I n p u t = [ I m a g e E m b ; T e x t E m b ] + P o s i t i o n E m b + M o d a l i t y E m b Input=[Image_Emb;Text_Emb]+Position_Emb+Modality_Emb Input=[ImageE?mb;TextE?mb]+PositionE?mb+ModalityE?mb -
通過多層 Transformer Blocks 進行跨模態交互:
-
自注意力機制:圖像 Patch 和文本 Token 互相計算注意力權重。
-
模態無關性:不預設圖像/文本的優先級,完全依賴數據驅動學習。
-
(3) 預訓練任務
-
圖像-文本匹配(ITM):
- 二分類任務,判斷圖像和文本是否匹配。
-
掩碼語言建模(MLM):
- 隨機掩蓋文本 Token,預測被掩蓋的詞(類似 BERT)。
-
掩碼圖像建模(MIM):
- 隨機掩蓋圖像 Patches,預測被掩蓋的像素(類似 MAE)。
技術創新與影響
- 簡化流程:移除了預提取的視覺特征,大大簡化了處理流程
- 計算效率:比之前的視覺-語言模型快10-100倍
- 端到端訓練:整個模型可以從頭到尾聯合優化
- 性能與效率平衡:雖然性能可能略低于最先進模型,但效率大幅提升
資源友好:降低了計算和存儲需求,使多模態模型更易于部署
ViLT代表了多模態模型架構簡化的重要趨勢,表明有效的模態融合不一定需要復雜的特征提取步驟,為后續更高效的多模態系統鋪平了道路。

——Iterable接口)




)

![【Ai】MCP實戰:手寫 client 和 server [Python版本]](http://pic.xiahunao.cn/【Ai】MCP實戰:手寫 client 和 server [Python版本])
的使用介紹)




 的工作原理和優勢)




