進程概念
- 1.認識馮諾依曼結構
- 2. 操作系統(Operator system)
- 2.1 概念
- 2.2 設計OS的目的
- 2.3 理解操作系統
- 2.4 如何理解管理
- 2.5 理解系統調用和庫函數
- 3. 進程
- 3.1 基本概念和基本操作
- 3.1.1 描述進程 - PCB
- 3.1.2 task_struct
- 3.1.3 查看進程
- 3.2 進程狀態
- 3.2.1 運行&&阻塞&&掛起
- 3.2.2 課本上的說法
- 3.2.3 理解內核鏈表
- 3.2.4 Linux中的進程狀態
- 3.2.5 孤兒進程
- 3.3 進程優先級
- 3.3.1 基本概念
- 3.3.2 查看系統進程
- 3.3.3 補充部分概念
- 3.4進程切換與調度
- 3.4.1死循環進程如何運行
- 3.4.2 CPU和寄存器
- 3.4.3 進程如何切換
- 3.4.4 Linux2.6內核進程O(1)調度隊列
- 4. 環境變量
- 4.1 基本概念
- 4.2 命令行參數
- 4.2 認識一個環境變量
- 4.3 認識更多的環境變量
- 4.4 獲取環境變量的方法
- 4.5 理解環境變量
- 5. 程序地址空間
- 5.1 程序地址空間回顧
- 5.2 虛擬地址
- 5.3 虛擬地址空間
- 5.5 為什么要有虛擬地址空間呢?
1.認識馮諾依曼結構
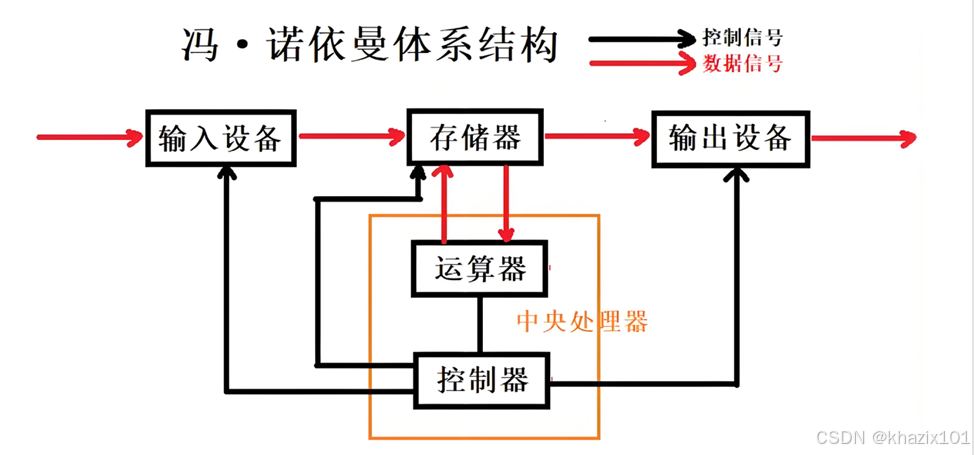
這就是現代計算機的體系結構,優化了以運算器為中心的馮諾依曼體系,以存儲器為中心。
下面給出一些概念:
輸入設備:鍵盤、鼠標、話筒、磁盤、網卡等。
輸出設備:顯示器、打印機、磁盤、網卡。
中央處理器(CPU):包含了運算器和控制器,其實現代的CPU還集成了內存中的MAR、MDR,Cache、一些通用寄存器等。
運算器:完成算術運算和邏輯運算。
控制器:計算機的指揮中心,指揮計算機完成取指令、分析指令、執行指令。
存儲器:指的是內存或者是主存,所有設備都只能直接和內存打交道。
主機:運算器、控制器、內存。
外設:輸入設備、輸出設備、外存。
I/O:站在內存的角度,輸入設備向內存輸入數據就是I(Input),內存向輸入設備輸出數據就是O(Output)。
摩爾定律:當價格不變時,集成電路上可容納的晶體管數目大約每 18 到 24 個月翻一倍,計算機的性能也將隨之提升
下面拋出一些問題并給出答案:
- 我們知道程序運行之前需要加載到內存,為什么需要先加載到內存后運行呢,那程序運行之前在哪呢?
1.從上面的現代計算器體系結構中可以看出,CPU獲取數據只能通過內存,在數據層面之和內存打交道,所謂程序運行就是CPU運行代碼、訪問數據的過程。程序運行前就是磁盤上的二進制文件,這里的加載就是I(Input).
2. 數據從輸入設備-> 內存 -> cpu -> 內存 -> 輸出設備,這其實是一個數據拷貝的過程,所以體系結構的效率由設備的"拷貝”效率決定。
- 為什么體系結構一定要存儲器的存在呢?輸入設備 --> CPU – > 輸出設備這樣不可以嘛,這里涉及到存儲分級。
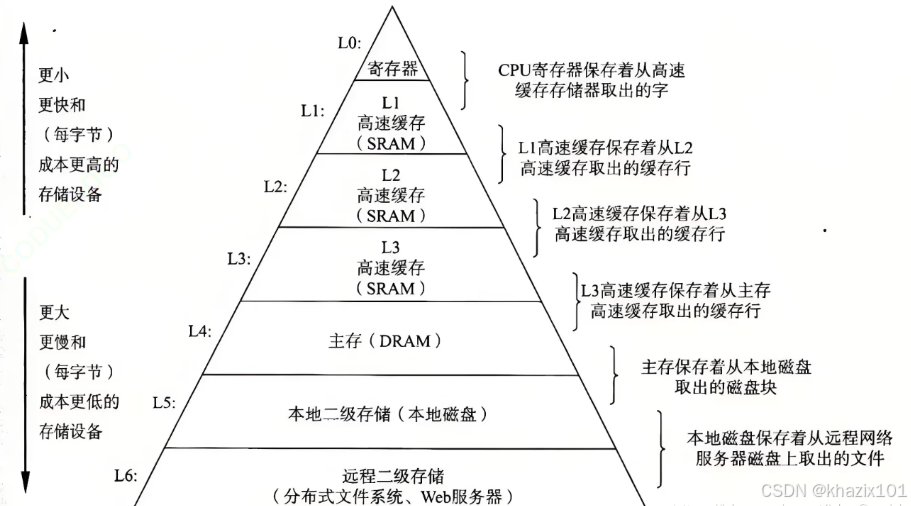
計算機內有各級存儲原件,距離CPU越近,存儲容量越小、速度越快、成本更高,距離CPU越遠,存儲容量越大、速度越快、成本更低。
若沒有存儲器緩沖,輸入輸出設備直接與CPU相接,系統的效率就由較慢的外部設備決定了(木桶原理),CPU的大部分時間都是空閑的。
存儲器(緩存機制、局部性原理和層次化存儲策略)的設置是主要意義在于在成本、容量和速度之間取得最佳平衡,當代計算機是性價比的產物。
- 從硬件的角度來理解數據流動

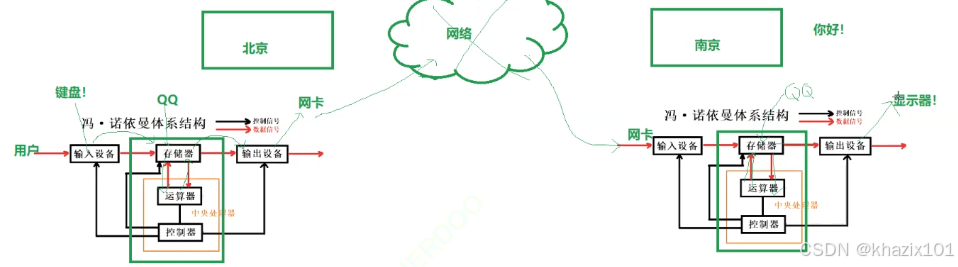
一個北京的網友通過電腦給南京的網友發信息的圖示,請按照現代計算機的體系結構分析數據流動。
北京網友鍵盤輸入(輸入設備)的信息被在內存中運行的聊天軟件拿到,然后送給運算器加密封包等操作后返回給內存、然后通過網卡(輸出設備)、網絡傳輸到南京網友的網卡(輸入設備),后加載到內存,進入運算器解密等,回到內存,最后刷新到設備屏幕上(輸出設備)。
2. 操作系統(Operator system)
2.1 概念
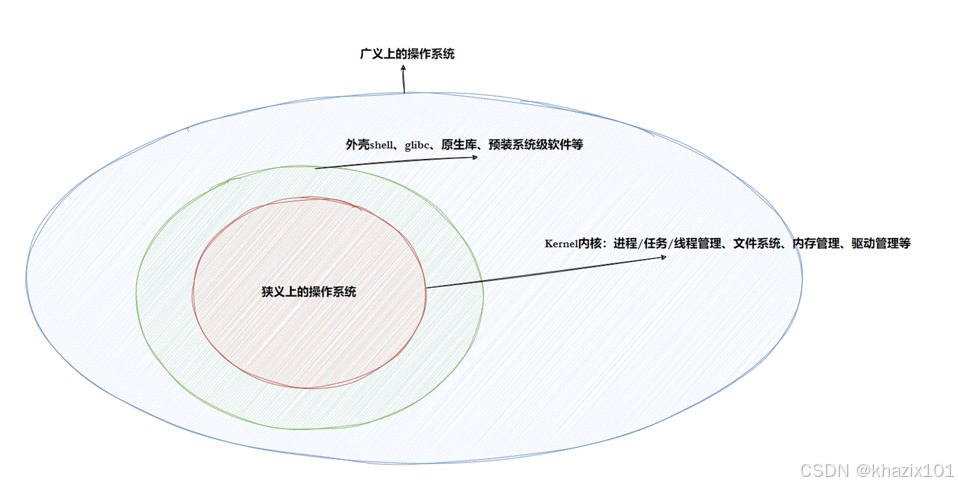
操作系統是?個基本的程序集合,是一款管理軟硬件的軟件,操作系統包括內核和其他程序。
- 內核(進程管理,內存管理,文件管理,驅動管理),這是狹義上的操作系統,是最核心的部分。
- 其他程序(例如函數庫,shell程序等等)
安卓系統的內核程序就是基于Linux的。
2.2 設計OS的目的
- 對下,與硬件交互,管理所有的軟硬件資源
- 對上,為用戶程序(應用程序)提供?個良好的執行環境
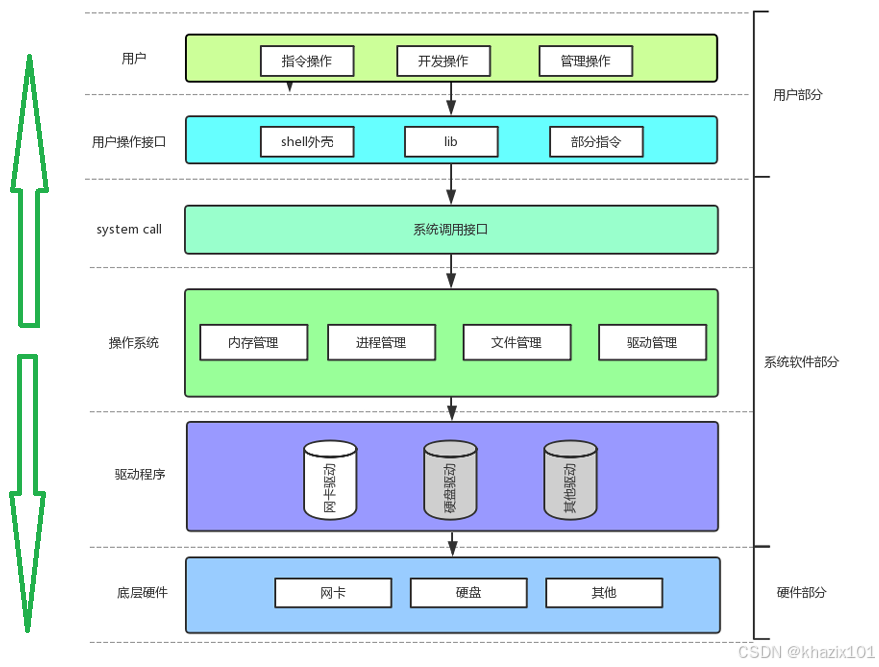
- 軟硬件體系結構為層狀結構,設計的思想為高內聚低耦合。
- 訪問操作系統,必須通過系統調用(系統提供的函數),例如C語言的printf函數,本質就是封裝了系統調用,通過操作系統對驅動程序進行訪問,最后把數據交給硬件。
- 我們的程序,只要判斷出其訪問了硬件,那么就必須貫穿整個軟硬件體系。
2.3 理解操作系統
在整個計算機軟硬件架構中,操作系統的定位是:?款純正的“搞管理”的軟件。
2.4 如何理解管理
管理的例子:校長、輔導員、學生。
校長:管理者(決策) 類比操作系統
輔導員:(執行) 類比驅動程序
學生:被管理者 類比底層硬件
- 實際上管理者和被管理者不需要直接接觸,管理的必要條件不是直接接觸,而是管理者可以拿到被管理者的相關數據,例如:校長可以根據一個學生的績點靠前而發放獎學金,也可以把一個開除一個多門掛科的學生,學生拿到獎學金或者從學校被開除滾回家甚至可以不和校長接觸。重要的是如何拿到數據呢?在校長和學生之間有一個輔導員,管理員收集你的信息到教務系統,這樣校長就可以通過教務系統拿到數據并對數據做管理了。同理:系統和硬件不需要接觸,系統需要的信息從驅動那里獲取,系統據對硬件做管理也是通過驅動進行的,系統對硬件的管理本質上是對有關硬件的數據進行管理。
- 假設校長開始是通過execl表格對一個學校的學生進行管理的,例如給績點最高的學生發放校長獎學金,校長就需要在execl表格中對遍歷所有的學生信息,這樣效率是低下的。然后校長學會了C語言,把學生描述為了一個結構體 struct_student,結構體中定義了姓名、性別、身高、電話等基本信息。一個學生對應一個結構體變量。后來校長學習了數據結構又在每個struct_student結構體中添加了一個struct_student* 類型的指針,把全體學生組織成了一個鏈表并實現了了排序等方法,這樣校長很方便的找到績點最高的學生了。校長把對學生的管理轉變成了對鏈表的增刪查改。
- 上面這個過程就是一種建模的過程,可以精簡為先描述再組織,這6個字適用于對任何管理場景的建模。例如:操作系統是如何管理所有的硬件的,操作系統可以在內部把所有硬件描述為一個結構體或者類,成員包括了硬件的各種信息,這樣每個硬件對應了一個結構體變量或者類對象,操作系統對硬件的管理就變成了對各種數據結構的管理。同理操作系統對進程如何管理呢?先描述為task_struct,然后組織成合適的數據結構,這樣就把對進程的管理轉變為對數據結構的管理。C提供的結構體/C++提供的類就是解決先描述的問題,C++提供的STL(各種數據結構和算法)解決的是組織的問題。各個高級語言中的類特性和數據結構與算法的存在是歷史的必然,因為其解決了在計算機中對現實世界建模和各種高效操作的需求。。
操作系統需要對各類場景被描述為的數據進行管理,所以操作系統一定會充滿大量的數據結構和該數據結構匹配的算法。
2.5 理解系統調用和庫函數
操作系統不相信任何用戶,不允許用戶訪問其的任何細節,但是操作系統還需要給用戶提供服務,所以向上給出了封裝好的系統調用。一般的系統如:windows、Linux、macos都是C語言來寫的,所以系統提供的系統調用都是C風格的函數。函數的參數是用戶給操作系統的,返回值是操作系統給用戶的,所以系統調用的本質就是用戶和操作系統之間的數據交互。
小白不了解系統,進而就不理解系統調用的參數和返回值,使用系統調用的成本很高,并且系統調用的功能比較基礎,所以開發者對系統調用進行了各種的封裝進而形成了各種的庫,并提供了各種shell外殼程序(例如:圖形化界面)和指令,這樣就降低了用戶使用系統的成本。
下面舉個例子說明一下:
銀行不相信用戶,不允許用戶進入銀行內部,但是還要給用戶提供存錢和取錢等服務,所以銀行提供了窗口和工作人員,我們可以給工作人員說我要取100塊,工作人員按照流程后就會取出100塊給你。銀行的業務處理的流程一般比較繁瑣,所以銀行一般會配備一個大堂經理,幫助一些年長者完成業務。
如何判斷一個庫函數是否封裝了系統調用?庫函數如果最終訪問了硬件,那么就一定封裝了系統調用。
3. 進程
操作系統的進程的管理也是表現為先描述,再組織。
3.1 基本概念和基本操作
課本概念:程序的一個執行實例或者正在執行的程序等。
內核概念:擔當分配系統資源(CPU時間,內存)的實體。
3.1.1 描述進程 - PCB
當一個計算機開機時,操作系統會被加載到內存中,在我們使用的時候,很多的程序在一段時間內也在內存中運行,這些程序需要被操作系統管理和調度,所以系統需要對這些程序進行描述和組織,使用C語言的結構體對進程的所有屬性進行描述,例如:代碼地址、數據地址、程序狀態、優先級等,然后選取合適的數據結構對程序的對應的結構體進行組織,這樣系統可以通過對該結構體的管理實現了對進程的管理。圖示如下:
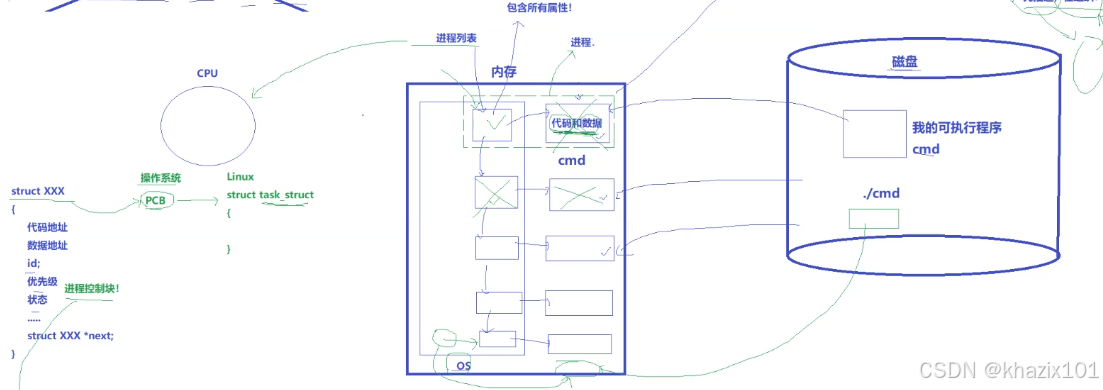
上面提到的結構體就是進程控制塊(Process Control Block),其包含了對應程序的所有屬性,Linux下的PCB叫做task_struct,這里給出進程的通俗的概念:進程 = 內核數據結構+自己的代碼和數據 ,在Linux下可以叫做PCB(task_struct)+自己的代碼和數據,這樣對進程的管理就變成了對進程鏈表(數據結構)的增刪查改。
舉個例子:
找工作的時候,需要提交個人簡歷,這個個人簡歷就是對自己的描述,找工作本質不是自己在找工作,而是簡歷在找工作,自己的個人簡歷被組織在一打簡歷里面,這里就是一個簡歷隊列,面試官篩選的不是人,而是簡歷。這里的簡歷就是PCB,人就是程序的數據,面試官就是CPU。
3.1.2 task_struct

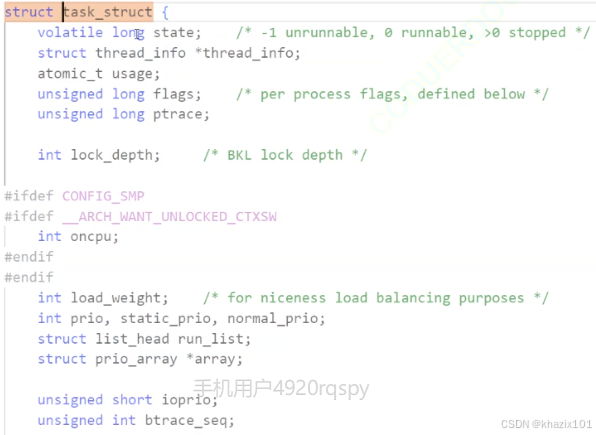
進程的屬性有好幾百條,我們后面會學習一些重要的屬性。
3.1.3 查看進程
首先要理解,我們歷史上所有的指令、工具、自己寫的程序運行起來,全部都是進程,用戶是以進程的方式訪問操作系統的。

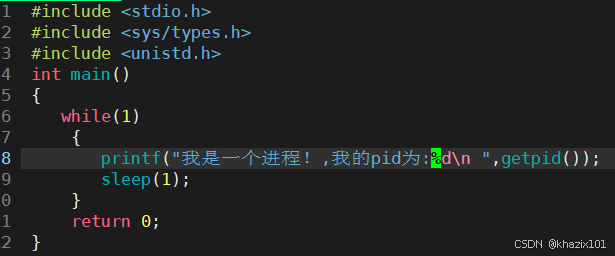
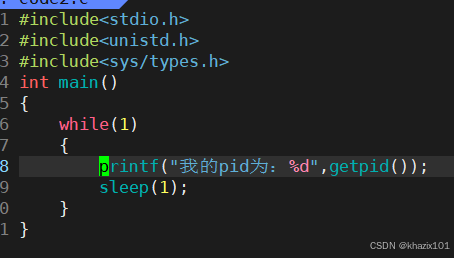
此時我們寫的程序正在死循環運行,這就是一個進程,那么如何查看這個進程呢?
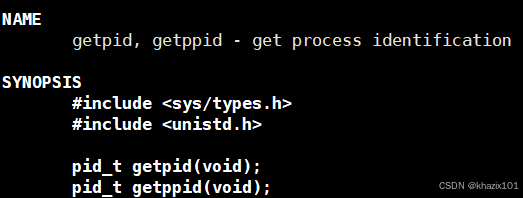
getpid 獲取當前進程的標識符,返回值pid_t是一個整數類型,下面修改一下程序,查看一下進程的pid。
如何查找系統中的進程呢?ps axj或者top,關于ps的指令的具體選項后面會詳細的介紹。
ps axj | grep 程序名可以過濾找到指定的進程。

ps axj | head -1 && ps axj | grep myprocess ,或者改&&為;都可以把進程的表頭屬性打印出來。
這樣grep會把自己也查出來,grep -v grep可以過濾掉自己。
ps axj | head -1 && ps axj | grep myprocess | grep -v grep

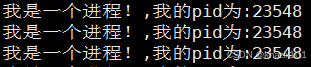
我們可以看到同一個程序運行后會獲得不同的pid,pid的分配是線性遞增的。
如何殺死一個進程呢?ctrl c或者kill -9 pid
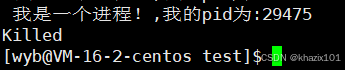
查看進程還可以通過文件的方式查看,ls /proc,/proc是內存級的文件系統,Linux下一切皆文件,進程甚至可以轉換為若干個文件。

數字目錄對應的都是各種進程的pid,目錄中的內存就是這個進程的動態屬性,當前我們程序的pid為32272,那么一定在 /proc下可以查找到名為32272的目錄。


同理,當我們殺死這個進程的時候,/proc 下就找不到這個進程了

那么進程目錄中有什么東西呢?這次對應的進程號為4185

今天我們要學習的是目錄下的cwd和exe。
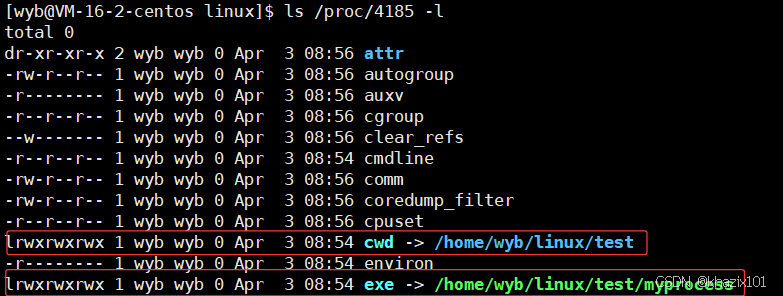
exe記錄下的就是進程對應的可執行文件的絕對路徑。
當我們把這個可執行文件刪除后,進程還在運行,說明在磁盤中的程序已經被充分的拷貝的內存了。
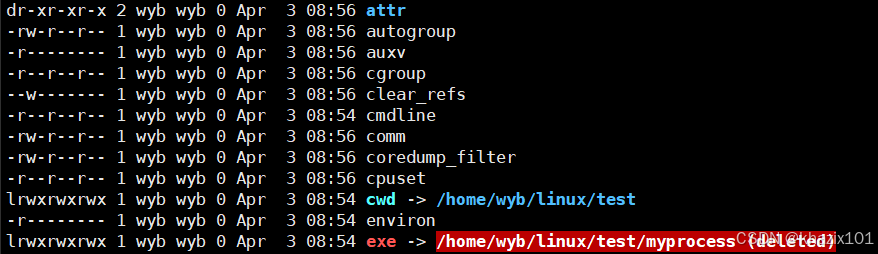
當我們再次查詢的時候,就發現發現進程的可執行文件被刪除了。
那cwd是什么呢?current work dir ,即為當前程序所在的工作路徑。這也是C語言中fopen("d.txt","w")不用指定絕對路徑的原因。
那我們如果修改了這個進程當前路徑呢?
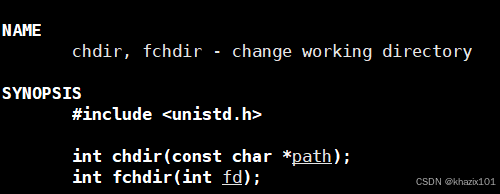
這次的進程號為:10499

查看一下進程對應的文件,cwd果然被修改了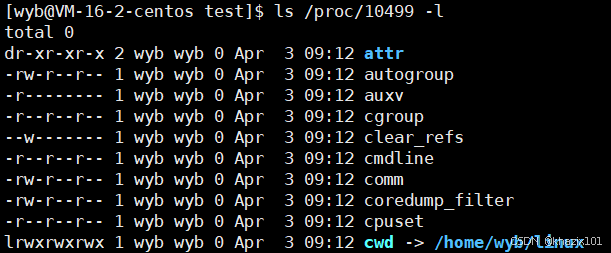
那么fopen創建的文件是在被修改后的工作目錄下么?

前面我們提到了getpid可以獲取自己的進程號,那getppid呢,其實這個系統調用可以獲取當前進程的父進程的進程號。Linux系統中的的所有進程都是被其父進程創建的。下面修改一下代碼,查找自己的父進程。
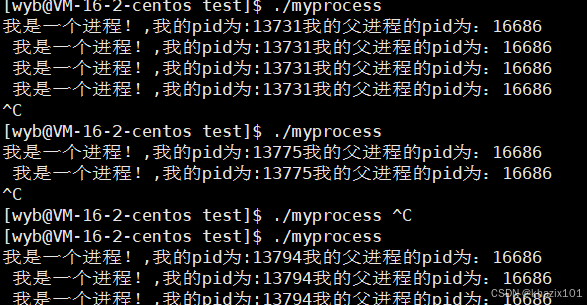
當我們多次啟動程序后,發現每次程序對應的進程的父進程的進程號時不變的。

這里的bash是什么,bash其實是命令行解釋器,其本身就是一個進程,操作系統會給每個登錄用戶分配一個bash。
我們之前運行的命令ls pwd cd...的父進程都是bash。

這就是bash打印的字符串,等待用戶輸入命令。
下面用代碼創建子進程。
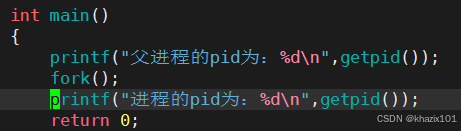

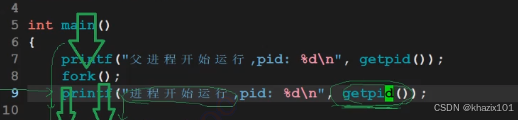
可以看出確實創建了一個子進程,下面描述一下原理。
父進程有自己的PCB以及代碼和數據,創建子進程的時候,子進程也要有自己的PCB以及代碼和數據,子進程的PCB由父進程PCB拷貝而來,并對部分屬性做出修改,例如pid、ppid等,但是大部分的屬性也是一樣的,子進程擁有和父進程一樣的地址指針,可以指向父進程的數據和代碼,所以子進程被調度的時候就會執行父進程創建出子進程之后的代碼。
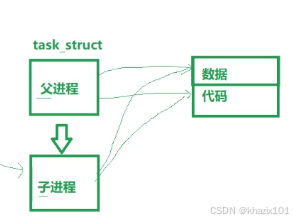
子進程沒有自己獨立的代碼和數據,因為目前,程序沒有被新加載。
下面看一下fork的返回值說明

子進程創建成功,子進程的pid返回給父進程,0返回給子進程。
子進程創建失敗 ,-1返回給父進程
先看下面的代碼。


fork之后父子代碼是共享的,所以程序結果如上。
這里給出問題
- 為什么fork給父子不同的返回值?
Linux系統中,父進程個數:子進程個數 = 1:n,父進程要根據不同的pid來區分不同的子進程,所以會把子進程的pid返回給父進程。
子進程可以通過getppid即可獲取父進程的進程號,所以僅表示成功創建即可,返回0。
- 為什么一個函數會返回兩次呢?
fork函數如果執行到return 0 ,那么它的核心功能已經執行完畢了。也就是子進程已經創建完成了,所以父子進程都會執行
return id;,自然會返回兩次了。
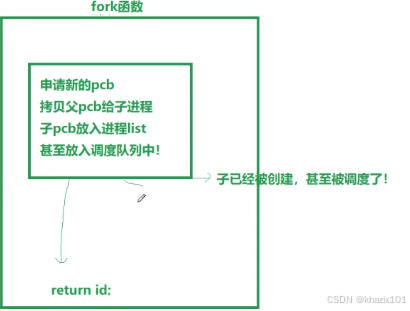
3. 為什么一個變量即大于0,又等于0,導致if else同時成立?
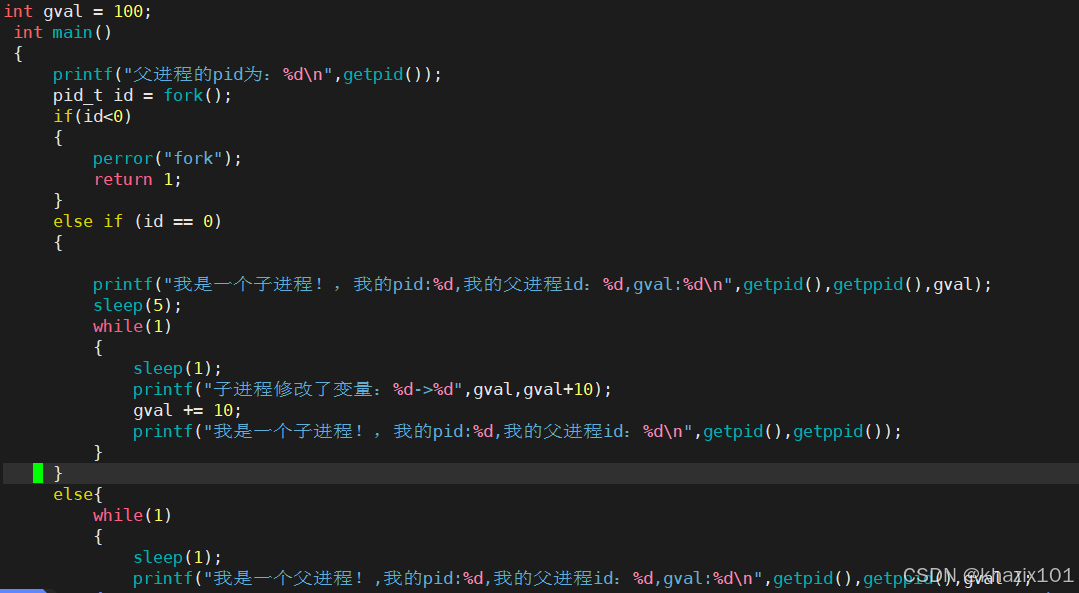
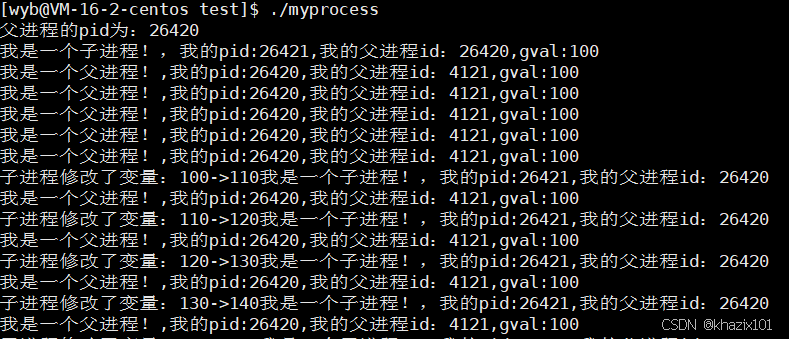
進程具有獨立性,一個進程掛了不會影響另外一個進程,同時父子進程共享父進程的代碼和數據,代碼是只讀的,也不會有影響。
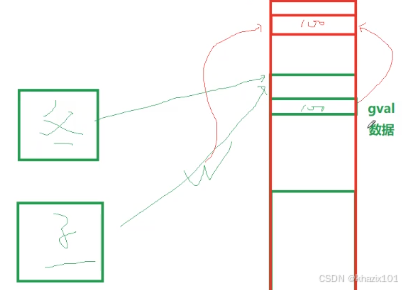
父子進程在數據層面默認是共享的,但是一旦父子進程任何一方要修改數據,OS會在底層把數據拷貝一份,讓目標進程修改這個拷貝(寫時拷貝)。
下面寫代碼對寫時拷貝做驗證。
寫時拷貝示意圖如下。
3.2 進程狀態
3.2.1 運行&&阻塞&&掛起
- 運行狀態
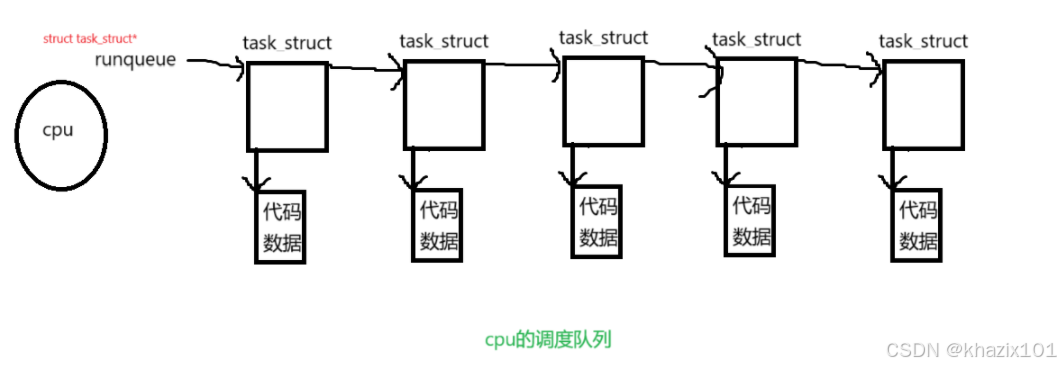
1.上面是一個CPU的調度隊列,簡單的調度算法是FIFO。
2.只要進程在調度隊列中,進程的狀態就是運行態。
-
阻塞狀態
當C程序執行到scanf函數的時候,等待用戶輸入數據的時候,C程序對應的進程就是一種阻塞狀態,阻塞狀態就是進程等待某種設備或者資源的狀態。
下面通過硬件視角來解讀阻塞狀態。
操作系統要對硬件做管理,就要先描述在組織,可以組織為一個結構體struct device,所以操作系統對硬件的管理,就變成了對這些結構體的管理。當運行態一個進程需要等待某種硬件資源,例如鍵盤的時候,cpu就會把該進程pcb鏈入到鍵盤對應的struct device的等待隊列中,當前pcb中屬性值也需要被修改,例如狀態。
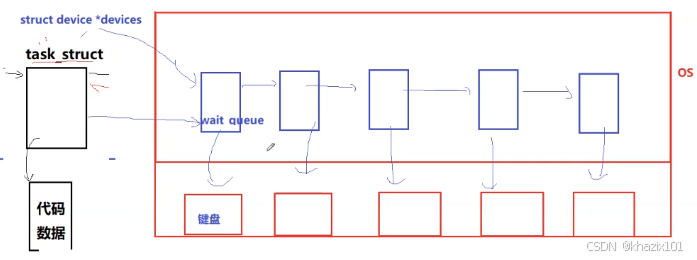
同理,當我們在鍵盤上輸入后,OS會修改鍵盤對應結構的狀態為活躍并檢查等待隊列,若隊列不為空,就會修改隊頭PCB狀態并把該PCB重新鏈入到運行隊列中。
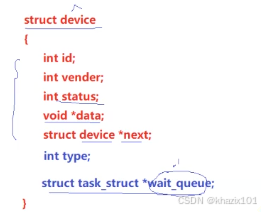
struct device的屬性結構體大致如下
-
掛起狀態
當計算機資源嚴重不足的時候,OS就會把不會被立即訪問的數據換出到磁盤(swap分區中):例如某些設備等待隊列上阻塞狀態的進程的代碼和數據,這個就是阻塞掛起,當設備輸入的時候,OS就會把代碼數據換入到內存中并重新構建隊首PCB的指針映射,然后把隊首進程鏈入到運行隊列中。更加嚴重的,OS甚至會把運行隊列的末端進程對應的代碼和數據換出到磁盤中,這種進程的狀態就是就緒掛起。
3.2.2 課本上的說法
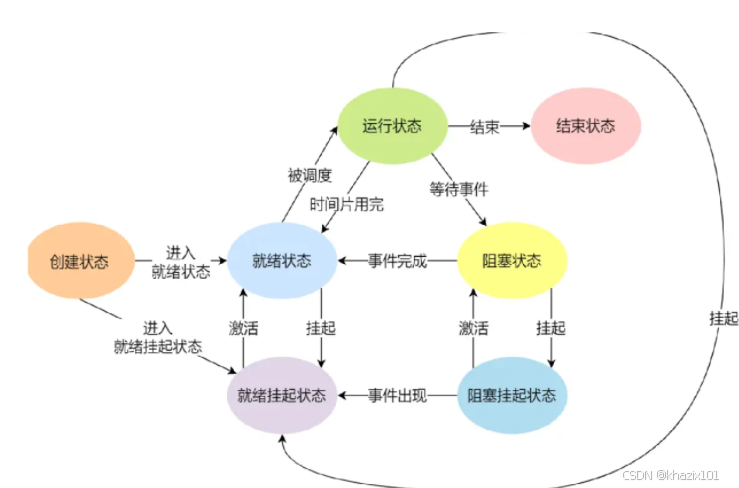
上面的是課本上給出的各種進程狀態。進程狀態轉換的本質就是PCB在不同隊列里流動。
3.2.3 理解內核鏈表
Linux中的一個PCB結點可能會在多個數據結構中,在雙鏈表中的同時也可能在一個隊列中。
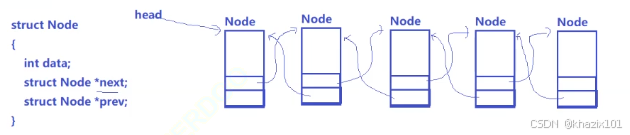
上面是我們在數據結構部分學習的雙鏈表的表示方法,那Linux系統中是如何做到各種數據結構交錯呢?task_struct中有多個類型為struct list_head 的屬性。

那么task_struct之間的關系圖如下:
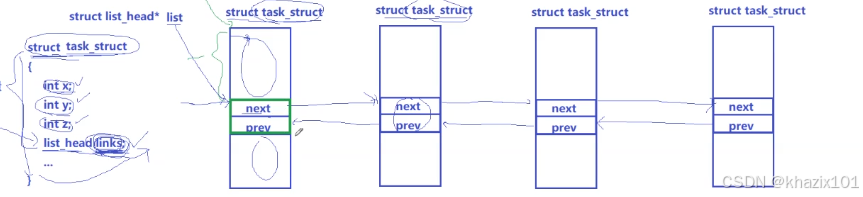
遍歷無法拿到對應task_struct的起始地址,那就無法訪問各種屬性。
如何解決這個問題呢?C語言中的offset宏給出了答案。
&((struct task_struct *)0->links)
這樣就拿到了一個task_struct中 links相對于其起始地址的偏移量。
(struct task_struct*)(next/list - &((struct task_struct *)0->links))
這樣就可以訪問每個task_struct的屬性了。
剛剛說了一個task_struct中有多個list_head屬性,這樣一個結點就可以屬于多種數據結構了。這也就意味著Linux中的數據結構是一種交錯的網狀結構。
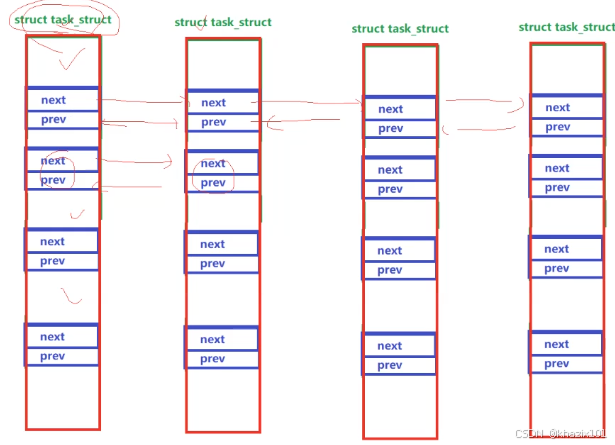
3.2.4 Linux中的進程狀態
先給出進程狀態的查看命令ps
a:顯示一個終端的所用的進程,包括其他用戶的進程
x:顯示沒有控制終端的進程,例如后臺運行的守護進程。
j:顯示進程歸屬的進程組ID、會話ID、父進程ID,以及作用控制相關信息。
u:以用戶為中心的格式顯示進程信息,提供
進程狀態就是一個task_struct內的一個宏定義的整數。

上面就是Linux內核中的進程狀態,下面我們一一介紹。
- R(運行態)
寫出一下的程序并編譯運行
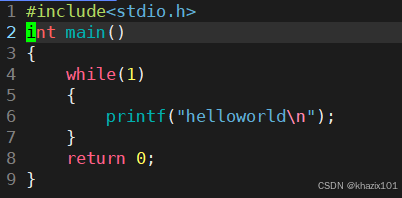
查看一下進程狀態
while :; do ps axj | head -1 && ps axj | grep process | grep -v grep; sleep 1; done

process進程不是在循環么,為什么會有S(阻塞狀態)呢?,因為代碼中有printf,在進程等待IO的時候,進程就變成阻塞態了。
當去除代碼中的printf的時候,process進程的狀態就總是R了
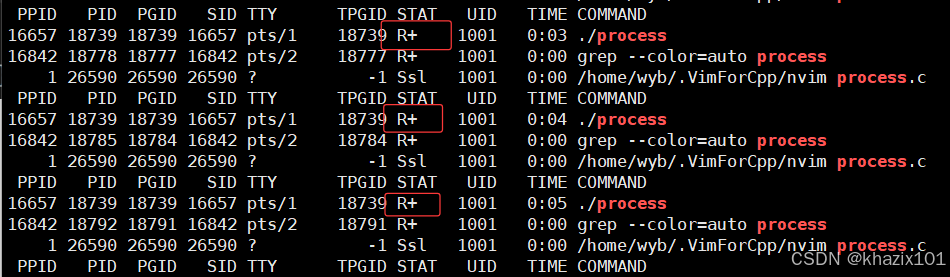
這里的R+的+的意思是程序是在前臺啟動的,./process &就可以保證程序在后臺運行了,對應的狀態也就是R而非R+。

后臺運行的程序不會影響前臺的命令行輸入,即使后臺程序在向前臺打印信息。
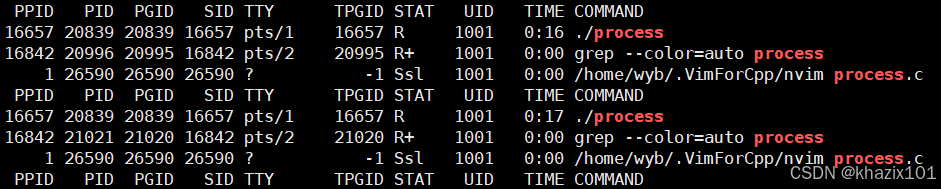
kill -9 進程號可以殺掉對應的后臺進程。

- S(sleep) 睡眠狀態
Linux下的S狀態對應的是系統理論中的阻塞狀態。
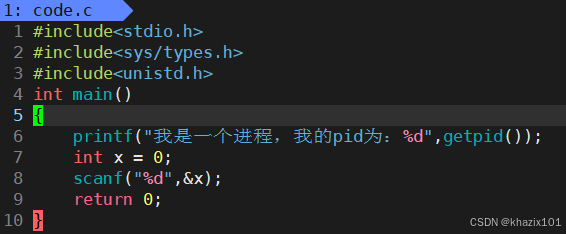
編譯運行一下。


進程運行到scanf函數時,需要等待IO,進程阻塞。
- T(stopped)/t(tracing stop)
gcc code.c -o process -g 編譯(gdb調試)
gdb process 啟動gdb調試process
l 打印源程序
b 8 在第8行打斷點
r 運行程序

process進程被debug,程序暫停了,對應的狀態為**t(追蹤狀態),**進程被調試的時候就是這個狀態。
修改一下代碼,然后編譯運行。
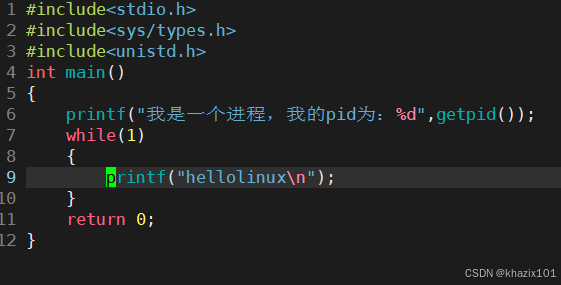
ctrl+z
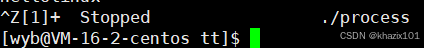
此時進程的狀態為T(暫停狀態)。

T和S狀態不同,S狀態表現為進程在等待資源,T狀態表現為進程的某種條件不具備或者進程做了非法操作,T狀態為Linux特有的一種狀態。
- D disk sleep(磁盤休眠)
S狀態稱為可中斷休眠/潛休眠狀態,這個狀態的進程可以被殺掉。
D狀態稱為不可中斷休眠/深度休眠狀態。
下面講解一下D狀態的場景:
當內存資源嚴重不足的時候,OS可能會直接殺掉部分進程,當進程在阻塞態(S)等待數據寫入磁盤的時候被殺掉并且磁盤空間不足寫入失敗的時候,這部分數據就會被丟棄且用戶端不會察覺(因為相關進程已經被殺死)。這是不合理的,所以在OS內,進程在對磁盤等關鍵數據存儲設備進行高IO訪問的時候,進程的狀態為D而不是S,同時OS不可殺掉D狀態。D狀態也是阻塞的一種。
可以使用dd命令模擬高IO場景來看到dd進程的出現D狀態。
dd if=/dev/zero of=~/test.txt bs=4096 count=10000000

- X(dead)/Z (zombie)
創建子進程的目的就是為了讓子進程完成一項功能,所以在子進程退出之前需要讓父進程讀取有關數據,這個時候的子進程的狀態就是Z狀態(僵尸狀態),改狀態下僅保留了進程的PCB,其他數據已經被釋放。
下面嘗試模擬Z狀態
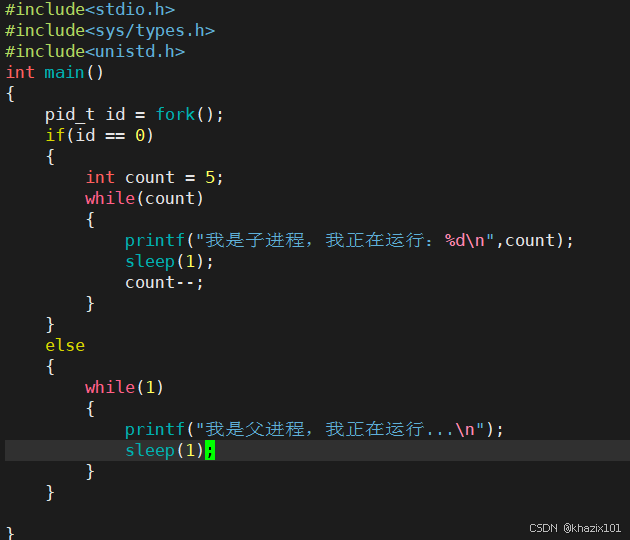
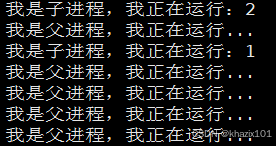

程序運行5秒后,子進程就處于Z(僵尸狀態) 了,如果父進程一直不獲取處于Z狀態子進程的信息,那么Z進程PCB將會一直維護,內存將會一直被占用,產生內存泄露的問題。
X狀態就是Z狀態的下一個狀態,即對應的PCB被父進程獲取并釋放,該進程在內存上就不存在了,對應的狀態為結束狀態。
至于掛起狀態,是OS應對內存資源不足的一種策略,在Linux中并沒有體現給用戶。
3.2.5 孤兒進程
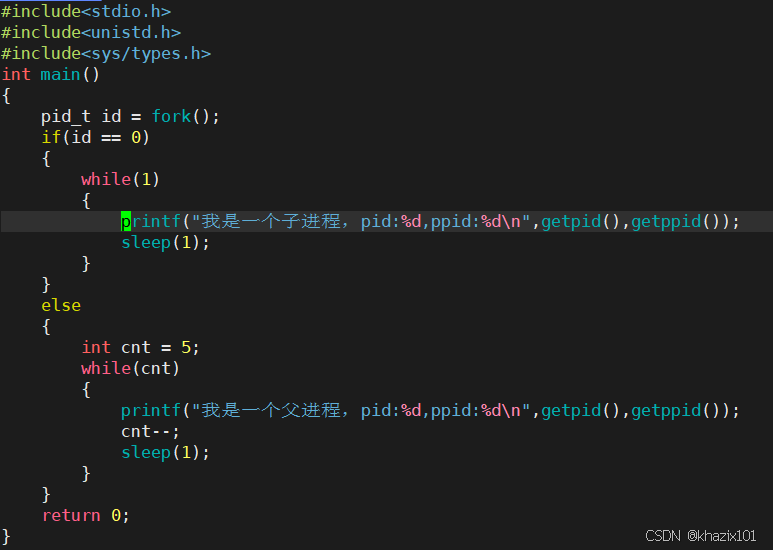
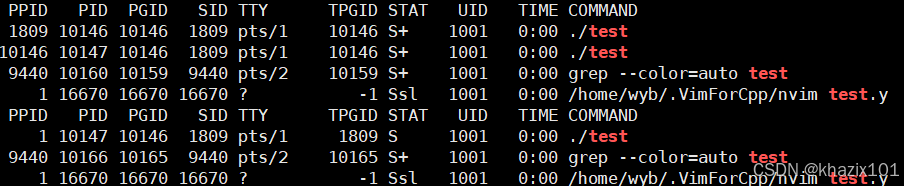
父子進程中,如果父進程先退出,子進程要被1號進程領養,這個被領養的進程就是孤兒進程。

這里可以簡單認為1號進程就是OS。

部分系統的一號進程叫做**‘init’**
為什么1號進程要領養孤兒進程呢?
因為如果不領養,子進程可能會變成僵尸進程造成內存泄露的問題。
這里的父進程會被其父進程bash回收,不會有任何問題。
孤兒進程一旦被領養就會變成后臺進程,后臺進程可以向前臺打印消息,但是ctrl c無法殺掉后臺進程,可以使用kill -9 進程號來殺死后臺進程。
3.3 進程優先級
3.3.1 基本概念
進程得到CPU資源的先后順序就是進程優先級。為什么需要優先級呢?本質在于CPU資源稀缺,導致需要優先級來確定哪個進程先被調度。
3.3.2 查看系統進程
進程優先級在Linux系統中體現為為task_struct中的一種整形性質的變量,這個變量的值越低優先級越高,反之優先級越低。一個進程的優先級可能會變化,但是變化的幅度會不太大。
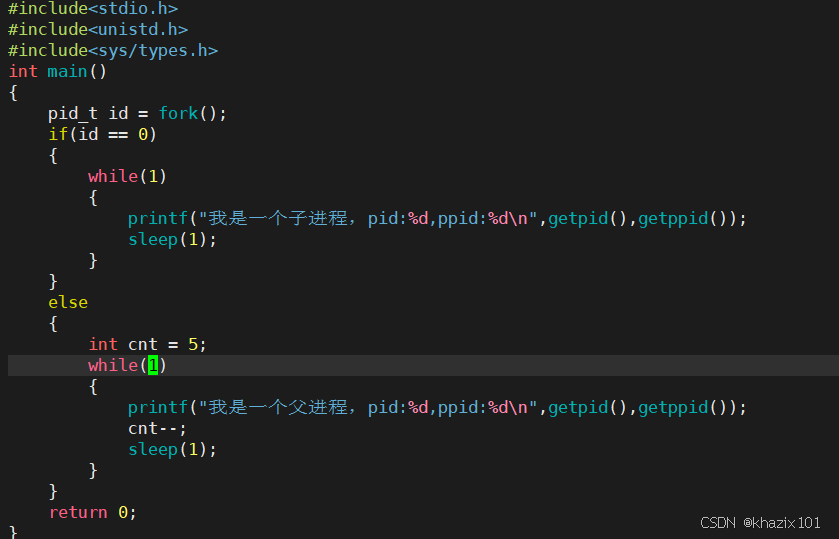

UID:每個用戶都對應一個id,這就是UID
上面的UID記錄的是誰啟動的相關進程。
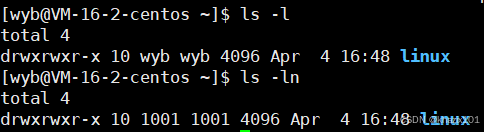
系統怎么知道我訪問文件的時候,是擁有者或者所屬組還是other呢?
我們用指令訪問文件的時候,本質就是進程在訪問文件,進程記錄下啟動進程的UID和文件屬性中各種角色的UID來對比,判斷用戶屬于什么角色。
PRI:進程優先級,默認值為80。
NI: 進程優先級的修正數據,稱為nice值。
進程的真實優先級 = PRI(修正值)= PRI(默認)+ NI ;
修改進程優先級方法1:
- top
- r
- 輸入進程號
- 輸入nice值

把優先級的NI值設置為10,優先級降低。
修改進行優先級的其他方法:
nice rinice 命令
get/setpriority 系統調用
…
優先級的極值為多少呢?

經測試nice值的修改范圍為[-20,19],進程的優先級為[60,99]共四十個數值。
Linux系統的優先級范圍設置較小并且不允許頻繁修改進程優先級的原因是:這樣會導致優先級低的進程長時間無法獲得CPU資源,這樣就會造成進程饑餓。
3.3.3 補充部分概念
1.競爭性:系統進程數?眾多,?CPU資源只有少量,甚?1個,所以進程之間是具有競爭屬性的。為了?效完成任務,更合理競爭相關資源,便具有了優先級
2.獨?性:多進程運?,需要獨享各種資源,多進程運?期間互不?擾
3**.并?**:多個進程在多個CPU下分別,同時進?運?,這稱之為并?
4.并發:多個進程在?個CPU下采?進程切換的?式,在?段時間之內,讓多個進程都得以推進,稱之為并發
3.4進程切換與調度
3.4.1死循環進程如何運行
一個進程占領CPU會直接把代碼跑完么?
不會,每個進程只會在一個在CPU運行一個時間片,然后進程切換,這其實就是并發。所以死循環進程不會打死系統,因為不會一直占領CPU。
3.4.2 CPU和寄存器
當一個進程被調度的時候,CPU會根據進程PCB中的內存指針來找到進程的代碼和數據,然后代碼和數據會分批拷貝至CPU內的寄存器中供CPU運算。圖示如下。
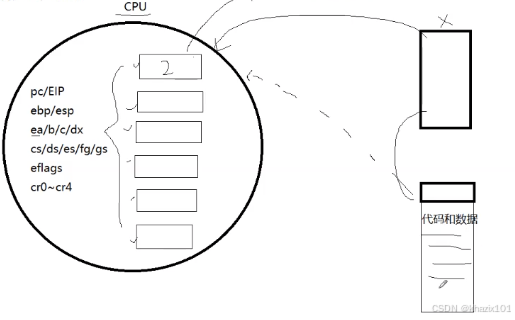
- 寄存器就是CPU內的保存臨時數據的器件。
- 寄存器 不等于 寄存器中的數據
3.4.3 進程如何切換
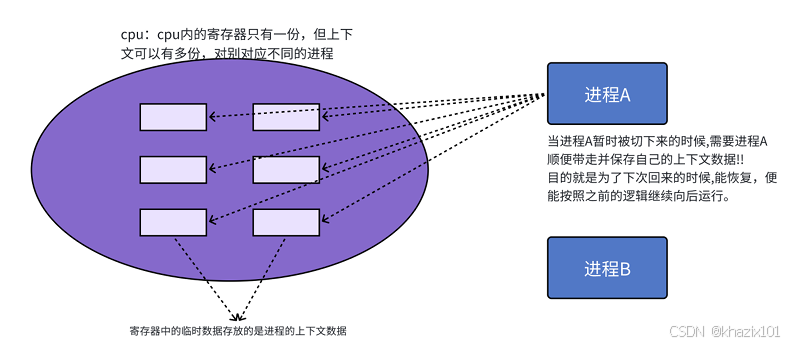
上下文數據:某時刻存儲在CPU寄存器中有關進程的各種數據。
進程切換最核心的就是保存和恢復進程的硬件上下文數據,即CPU中寄存器的內容。
- 進程切換時,進程的上下文數據被保存在哪里了呢?
可以理解保存到進程的PCB中的TSS中,當代Linux已經把TSS從PCB中移除了。
我們找出第一代的Linux代碼看一下。

- 如何區分全新的進程和已經被調度過的進程呢?
當代Linux內核中給出了一個 isrunning的屬性做為,調度過為1,沒有調度過為0。
一個CPU一秒鐘會調度很多次,可以把一個實體CPU分為幾個邏輯CPU,邏輯CPU效率總和為實體CPU的效率。
3.4.4 Linux2.6內核進程O(1)調度隊列
一個CPU一個運行隊列,Linux2.6的運行隊列名稱為runqueue。
1.成員變量有queue[140],類型為struct task_struct *,是一個PCB指針數組
2.140指的是Linux有140個優先級,[0,99] 是實時優先級,對應的是實時操作系統(搶占式的進程切換)。
3.剩下的40個屬于分時優先級,也是3.3講到的優先級,可以通過x-60+(140-40)映射到對應的下標處并鏈接入隊,queue本質就是hash表。
4.宏觀上可以根據優先級遍歷,局部(即優先級相同的PCB指針隊列)使用FIFO遍歷。
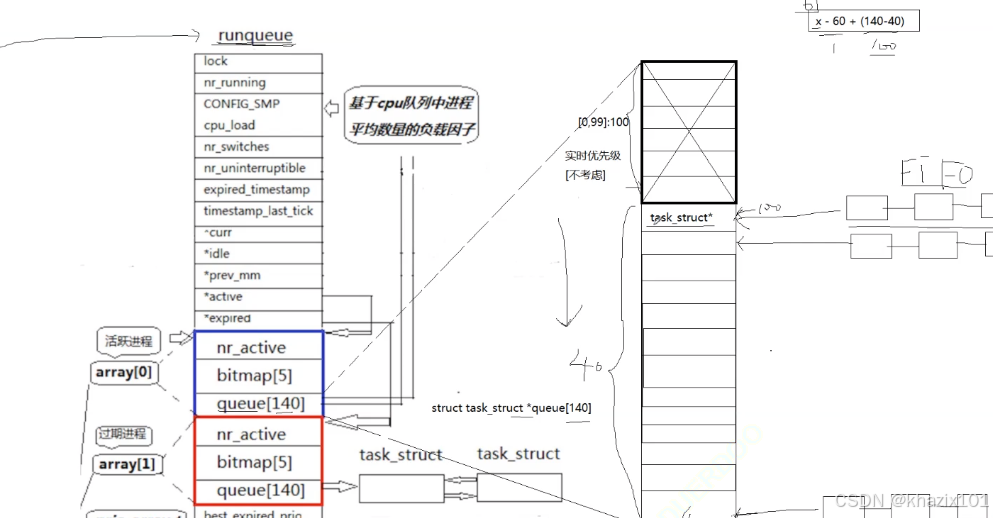
unsigned int bitmap[5],這是一個位圖,可以表示160位bit,和1-140位bit位quque[140]對應。n位為1對應quque[n-1]為空,n為0對應queue[n-1]隊列非空,位圖的設置簡化了對quque[]的遍歷。
nr_active 標識了整個調度隊列中有多少個進程,調度器挑選進程時候,先查nr_active ,nr_active大于0,再查nitmap[5],確認下標,直接索引queue,找到目標隊列,移除隊頭pcb,執行調度和切換算法。
4. 環境變量
4.1 基本概念
環境變量(environment variables)?般是指在操作系統用來指定操作系統運?環境的?些參數。環境變量通常具有某些特殊?途,還有在系統當中通常具有全局特性。
如:我們在編寫C/C++代碼的時候,在鏈接的時候,從來不知道我們的所鏈接的動態靜態庫在哪?,但是照樣可以鏈接成功,?成可執?程序,原因就是有相關環境變量幫助編譯器進?查找。
4.2 命令行參數
main有參數嘛,之前在學習C語言的時候,我們寫的C語言程序都是不帶參數的。起始main函數是有參數的,main函數也需要被其他函數調用。
int main(int argc, char* argv[])
argv 字符指針數組
argv 數組中的元素個數
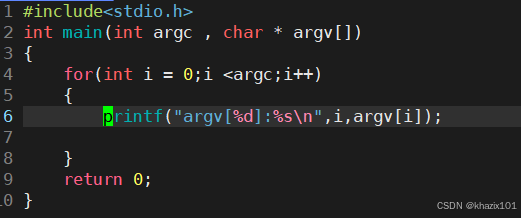
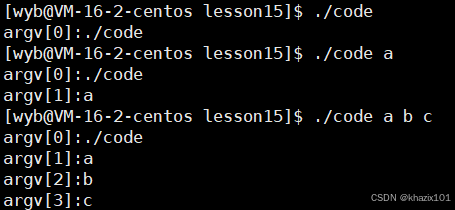
命令行命令被以空格分隔成命令行參數,并分布取地址存儲到字符指針數組中。
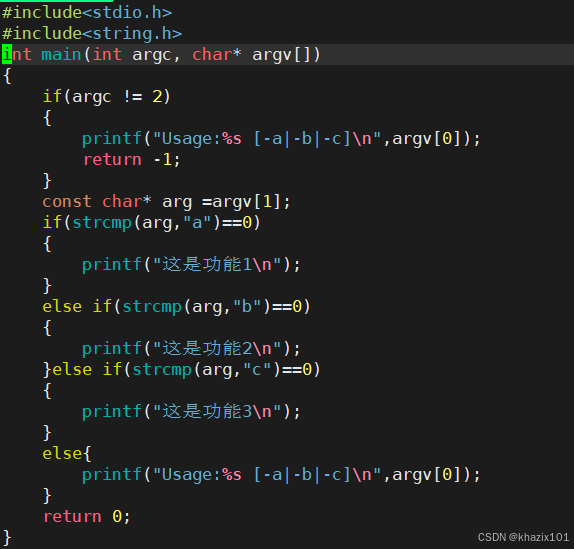
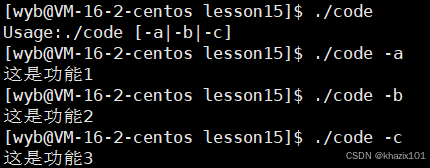
通過上面程序模擬了指令+選項對應不同功能,所以命令行參數的用途是可以讓一個程序通過不同的選項來實現不同的子功能。這也是指令可以帶選項的原因,指令的本質也是一個可運行二進制程序。
4.2 認識一個環境變量
指令和我們寫的程序都是二進制程序,為什么運行系統指令不需要路徑呢?因為系統中存在環境變量來幫助找到目標二進制文件 。
這個環境變量為PATH,PATH中記錄的是搜索指令的默認搜索路徑。
env可以查看Linux系統中的所有的環境變量。
查看一個環境變量可以使用echo $環境變量名。
環境變量 = 名稱+內容。

冒號為路徑的分隔符,程序沒有路徑的時候,系統就會到PATH中依次匹配。
若把當前程序的路徑拷貝到PATH中,那么不用指定路徑就可以運行程序了。

如何理解環境變量呢?(存儲的角度)
環境變量存儲在bash中,叫做環境變量表,當我們輸入命令’ls -a’的時候,bash就會在環境變量表中匹配,匹配失敗就會打印出報錯信息,匹配成功就會結合同樣存儲在bash中的命令行參數表創建子進程。
環境變量最開始是從哪里來的?
環境變量最開始是在系統的配置文件中,當bash進程創建的時候就會在配置文件中讀取所有環境變量的值并在自己的內部創建出環境變量表。
配置文件存放在家目錄下,.bashrc,bash_profile.bash_profile會加載.bashrc,.bashrc會加載etc/bash.
可以在.bashrc文件中添加自己需要的PATH路徑,這樣該PATH路徑就常駐系統了。
4.3 認識更多的環境變量

這也是cd ~能切換到家目錄的原因。

SHELL記錄的是用戶登錄的時候使用的是哪一個版本的shell。

USER記錄當前用戶是誰。
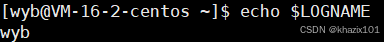
LOGNAME記錄登錄用戶是誰。
一般USER == LOGNAME ,且su 切換用戶的時候不會修改這兩個環境變量,su - 的表示重新登錄才會。

記錄歷史指令的上限數目,對應命令history(查看歷史命令)

記錄終端類型
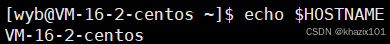
記錄主機名

記錄當前的工作路徑
…
4.4 獲取環境變量的方法
1.env
2. echo $XXX
3. export xxx=xxx 導入一個環境變量

4.unset xxx 取消一個環境變量

5.通過代碼的方式獲取環境變量
<1> main函數參數獲取環境變量
main函數的參數可以有三個

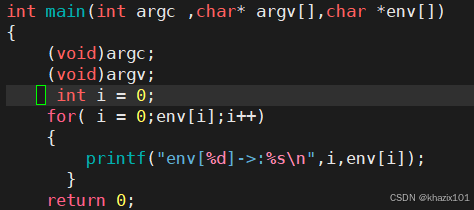
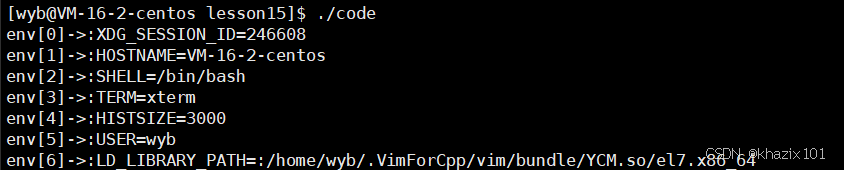
argv和env是由父進程傳遞給我們的,環境變量可以被子進程繼承,所以環境變量在系統中有全局特性。
<2> getenv系統調用
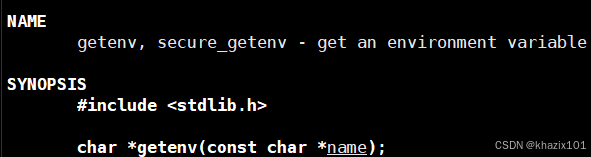
獲取指定變量的內容
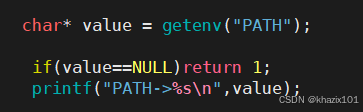

如果我想寫一個只能自己用的程序,該如何設計呢?
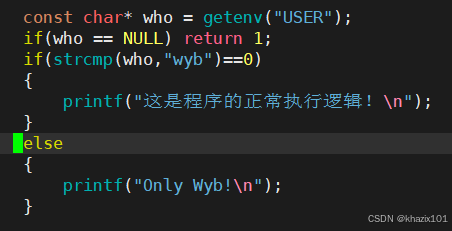

su - 切換登錄用戶后。

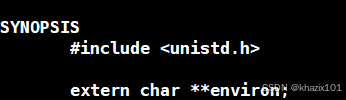
<3>environ:環境變量的全局數組
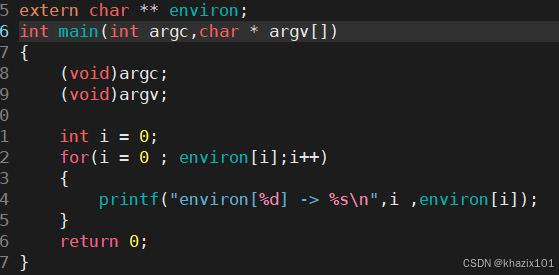
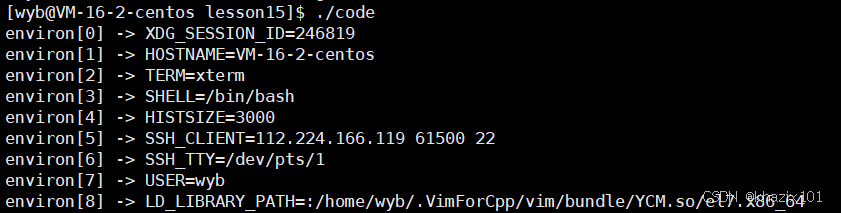
4.5 理解環境變量
環境變量具有全局特性,這個上面已經證明,bash的子進程可以獲取bash進程的環境變量。
補充兩個概念

上面這個是本地變量,本地變量不是環境變量。本地變量不會被子進程繼承,只會被bash內部使用。

unset可以取消本地變量。
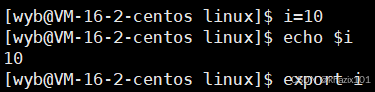
也可以把本地變量導入到環境變量中。
為什么export命令作為子進程可以把數據傳給父進程bash呢,進程之間不是相互獨立的么?
export 是內建命令,不需要創建子進程,而是讓bash之間親自執行,一般為bash調用系統調用完成的。
5. 程序地址空間
5.1 程序地址空間回顧
下面是程序地址空間的示意圖
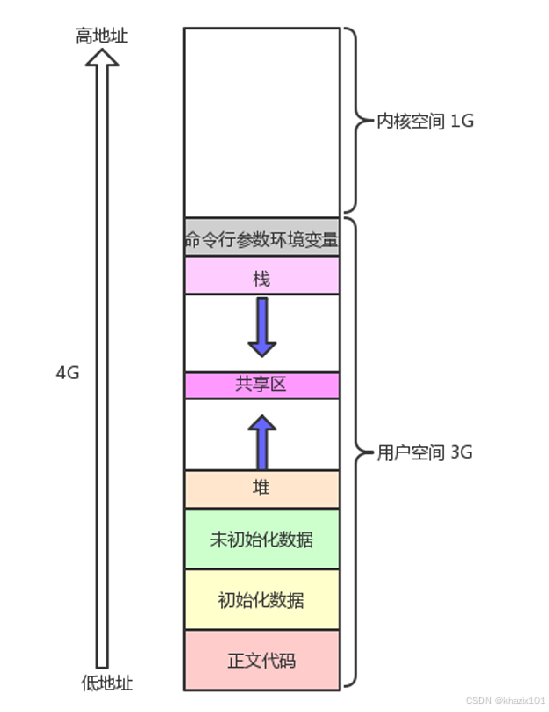
寫個代碼驗證一下:
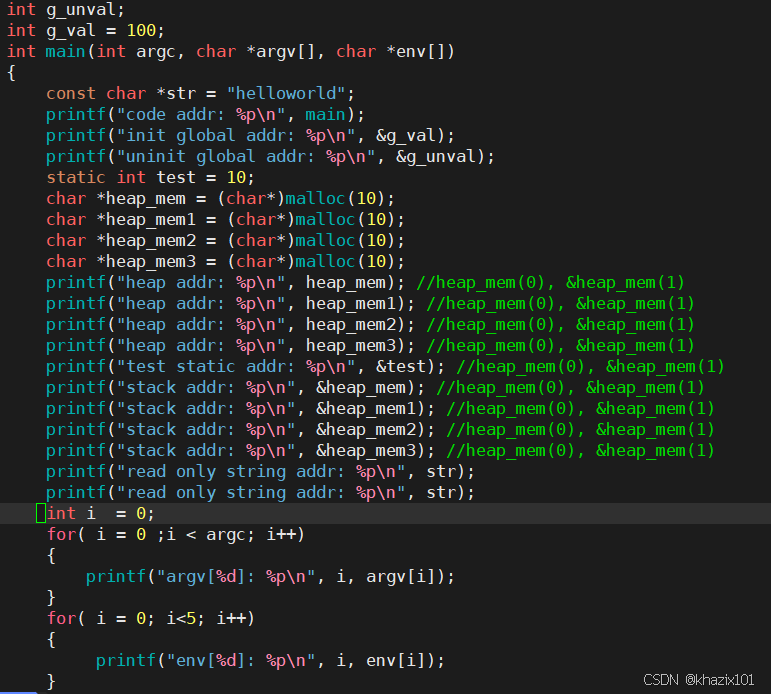
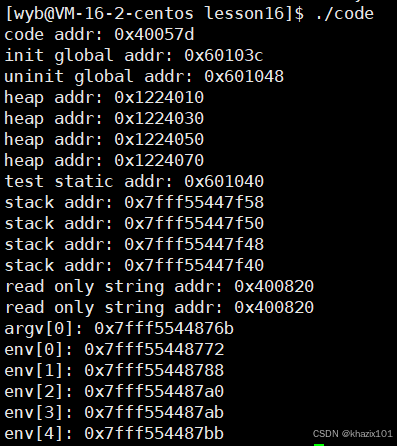
上面的程序地址空間是內存么?不是內存,程序地址空間現在可以稱為進程地址空間或者虛擬地址空間了。這是一個系統層面的概念而不是語言層面的概念。
5.2 虛擬地址
如何證明程序地址空間不是實際內存呢?下面寫段代碼證明:
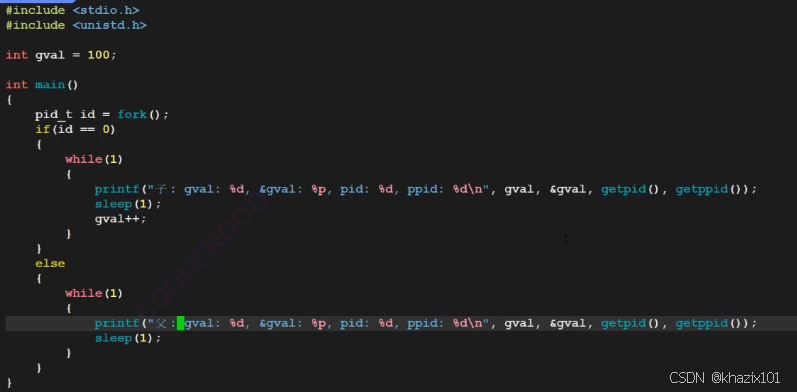
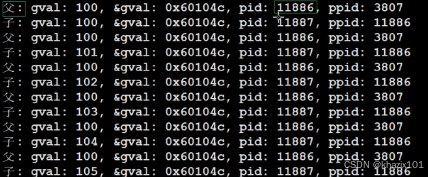
同一個變量(唯一地址)竟然可以輸出兩個不同的值,這里的地址不是內存中真實的地址,是虛擬地址。C/C++程序指針用到的地址都是虛擬地址。
一個進程擁有一個虛擬地址空間,在32位機器下,有2^32位地址共4G的空間,1-3G為用戶空間,第4G為內核空間。一個變量對應一個虛擬的地址同時在內存中對應一個真實的地址,一個進程也擁有一套頁表,頁表用來建立不同變量的虛擬地址和實際地址的映射關系.
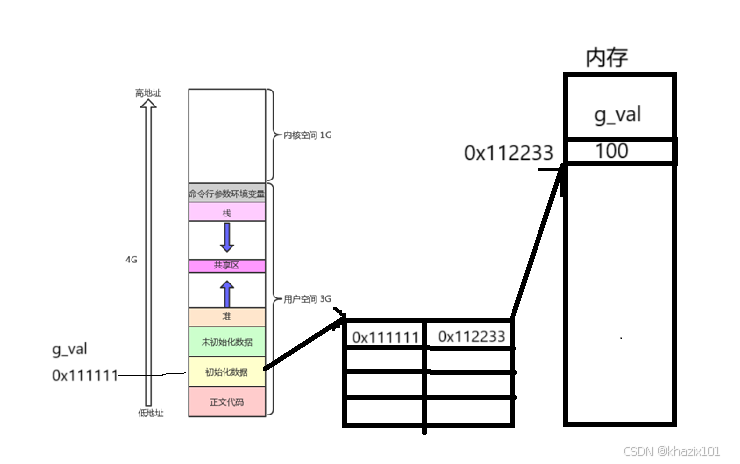
子進程的PCB、地址空間、頁表都是淺拷貝自父進程,父子進程的代碼和數據都是共享的,這也是為什么父子進程中打印變量的虛擬地址是相同的。
當子進程要修改變量的時候,系統就會在內存中重新找一塊內存空間存儲修改變量,并重新建立子進程頁面關于該變量的映射關系,這叫做寫時拷貝。這就是父子進程打印同一變量的時候打印出了不同的值。
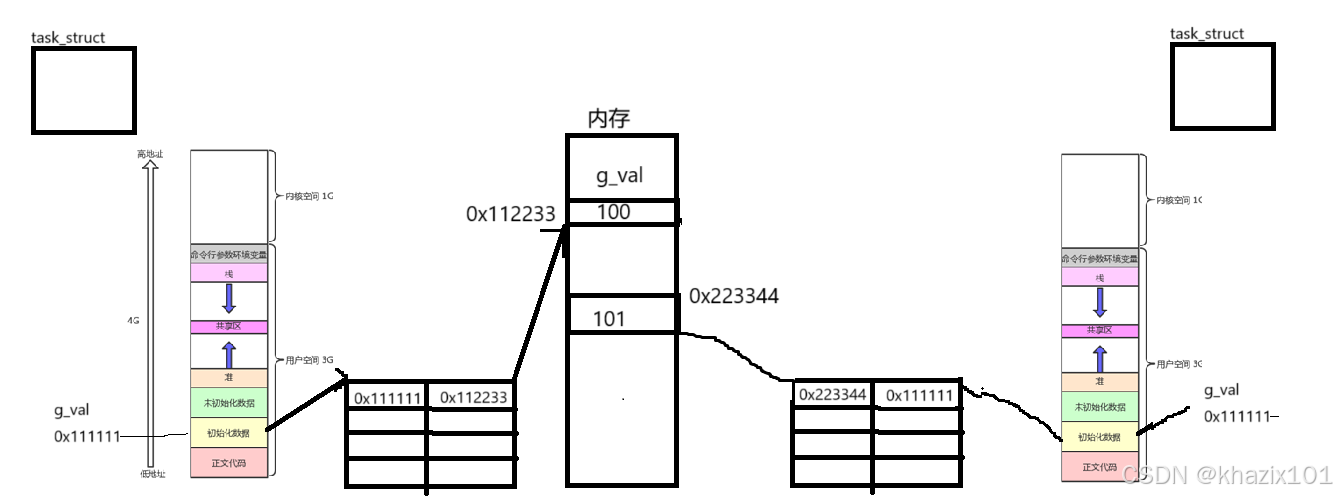
我們是否可以查看父子進程關于g_val變量的物理地址呢?不行,OS把物理地址隱藏只暴露虛擬地址給我們使用。
5.3 虛擬地址空間
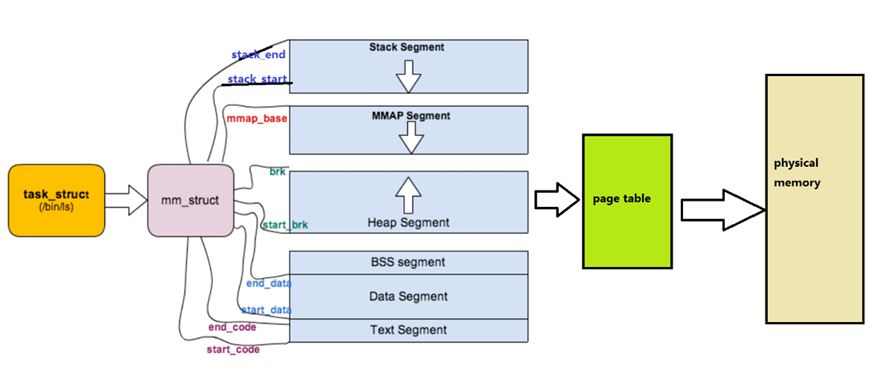
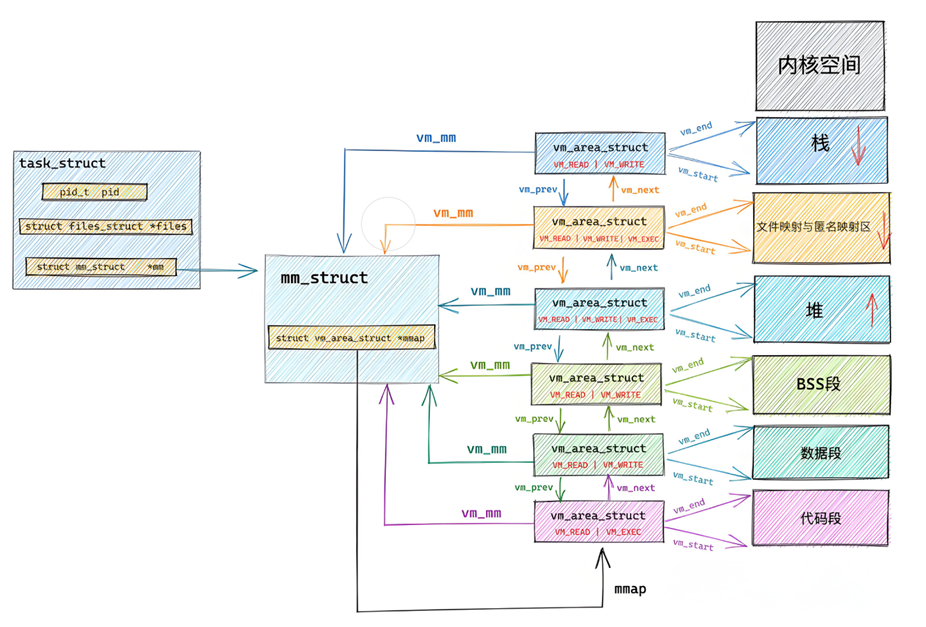
上面我們提到了虛擬地址空間,這里我們談一下其的具體細節。虛擬地址空間是OS給進程畫的餅,這讓每一個進程認為自己在獨占物理內存,每個進程都有一個虛擬地址空間,這個虛擬地址空間在Linux為mm_struct的結構體變量,每個進程的task_struct中都有一個指向該進程的mm_struct的指針,OS也會把所有的虛擬地址空間通過數據結構管理起來。
struct task_struct
{//....struct mm_struct *mm;//.....
}
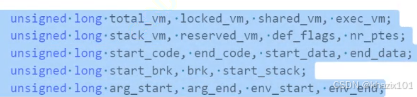
那么mm_struct是如何描述一個虛擬地址空間的呢?我們知道虛擬地址空間有很多區域劃分,例如棧、堆等,那么mm_struct是如何實現區域劃分的呢?需要定義變量來記錄開始地址和結束地址即可。
struct mm_struct //區域劃分形式大致如下
{//...long code_start;long code_end;long init_start;long init_end;//...修改變量的數據就可以實現區域調整。
來看一下Linux內核中的mm_struct
結構圖示如下:
下面我們在深入一點
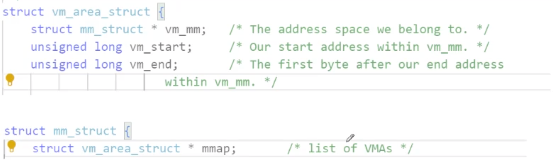
在mm_struct 中還存在一個vm_area_struct的指針,vm_are_struct 用來描述進程地址空間的一個連續的區域,vm_area_struct 結構也會被維護成一個鏈表。
物理地址轉變成虛擬地址的過程
- 在虛擬地址空間中調整區域劃分(mm_struct 會在程序被加載的時候初始化)。
- 加載程序,申請物理空間
- 進行頁表映射
虛擬地址供上層用戶使用,物理地址被屏蔽。
5.5 為什么要有虛擬地址空間呢?
這個問題可以轉換為:如果程序直接操作物理內存會造成什么問題?
- 安全風險:每個進程都可以訪問任意的內存空間,這也就意味著任意一個進程都能夠讀寫系統相關的內存區域,如果是一個木馬病毒,那么它就能隨意的修改內存空間,讓設備癱瘓。
2.地址不確定:如果直接使用物理地址的話,我們無法確定內存現在使用到哪里了,也就是說拷貝的實際內存地址每?次運行都是不確定的。
3.效率低下:如果直接使用物理內存的話,一個進程就是作為一個整體的(內存塊)來操作的,如果出現內存不夠用的情況,需要把整個進程從內存拷貝到磁盤,這樣拷貝時間長,效率太低。
虛擬地址空間和分頁機制就可以解決上面的問題
- 因為頁表映射的存在,程序在物理內存中理論上就可以任意位置加載。但是在進程視角中所有的內存分布都可以是有序的。
2.地址空間和頁表是OS創建并維護的,這意味著地址轉換的過程中,OS會對地址和操作進行合法判定,進而保護物理內存。 (野指針和字符常量寫入)- 因為虛擬地址空間的存在和頁表的映射的存在,我們的物理內存中可以對數據進行任意位置的加載,物理內存的分配和進程的管理可以做到沒有關系,進程管理模塊和內存管理模塊就完成了解耦合。
下面基于上面的學習說明一些問題
- 創建進程的時候,先有內核數據結構,然后再加載代碼和數據。
- 我們可以先創建內核數據結構和加載少量的代碼和數據,進程通過頁表找不到虛擬地址對應的物理地址的時候,這個時候進程阻塞,OS自動的會從磁盤中加載數據并建立映射,上面的過程叫做缺頁中斷。
- 阻塞掛起就是清空頁表,并把進程對應的代碼和數據換出到磁盤的swap分區中。




【注意:安裝失敗,謹慎參考!】)




 與 <iframe> 的優缺點及使用場景和方式)



VTK C++開發示例 --- 繪制多面錐體)
和閉源(僅限內部),以及公共(全員可訪問)和內部(特定團隊/項目組)四個維度)




)