緩存一致性
1.兩次更新
- 先更新數據庫,再更新緩存;
- 先更新緩存,再更新數據庫;
出現不一致問題場景:
先更新數據庫,再更新緩存;

先更新緩存,再更新數據庫;

兩次更新的適用場景:
????????如果我們的業務對緩存命中率(一定要用到緩存)有很高的要求,我們可以采用「更新數據庫 + 更新緩存」的方案,因為更新緩存并不會出現緩存未命中的情況。
?解決緩存不一致的辦法
- 在更新緩存前先加個分布式鎖,保證同一時間只運行一個請求更新緩存,就會不會產生并發問題了,當然引入了鎖后,對于寫入的性能就會帶來影響。
- 在更新完緩存時,給緩存加上較短的過期時間,這樣即時出現緩存不一致的情況,緩存的數據也會很快過期,對業務還是能接受的。
2.更新+刪除策略
2.1 先刪除緩存再更新數據庫
出現問題的場景
請求A更新 請求B讀取
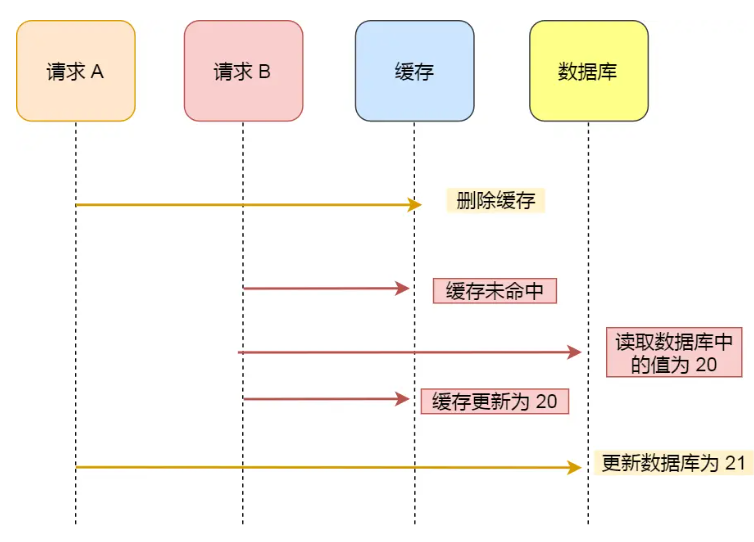
解決辦法
延遲雙刪:
????????請求A先刪除緩存然后再更新數據庫,再給A加個睡眠時間,主要是為了確保其他請求完成讀操作寫入的緩存,然后請求 A 睡眠完,再刪除緩存。
????????所以,請求 A 的睡眠時間就需要大于請求 B 「從數據庫讀取數據 + 寫入緩存」的時間。
但是具體睡眠多久其實是個玄學,很難評估出來,所以這個方案也只是盡可能保證一致性而已,極端情況下,依然也會出現緩存不一致的現象。
因此,還是比較建議用「先更新數據庫,再刪除緩存」的方案。
2.2 先更新數據庫再刪除緩存
請求A讀取?請求B更新
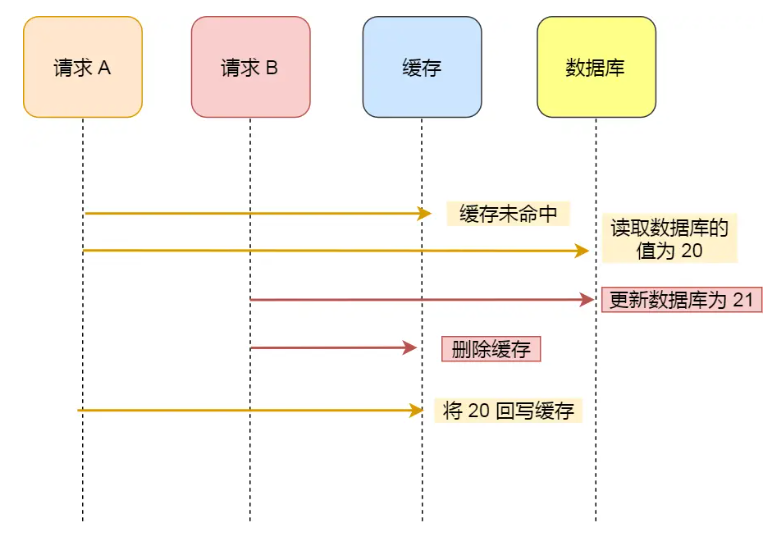
上圖是可能出現不一致的場景,但是在實際中,這個問題出現的概率并不高。因為緩存的寫入通常要遠遠快于數據庫的寫入。
出現問題的場景:
?????「先更新數據庫, 再刪除緩存」其實是兩個操作,在刪除緩存(第二個操作)的時候可能會失敗,導致緩存中的數據是舊值,而數據庫是最新值。
確保刪除成功的辦法
消息隊列重試機制
????????我們可以引入消息隊列,將第二個操作(刪除緩存)要操作的數據加入到消息隊列,由消費者來操作數據。
- 如果應用刪除緩存失敗,可以從消息隊列中重新讀取數據,然后再次刪除緩存,這個就是重試機制。當然,如果重試超過的一定次數,還是沒有成功,我們就需要向業務層發送報錯信息了。
- 如果刪除緩存成功,就要把數據從消息隊列中移除,避免重復操作,否則就繼續重試。
缺點是,對代碼入侵性比較強,因為需要改造原本業務的代碼。
訂閱 MySQL binlog,再操作緩存
????????如果是MySQL、Redis緩存同步場景,為了保證成功率,可以用一個消費服務訂閱MySQL binlog 日志,拿到具體要操作的數據,然后再向Redis執行緩存刪除操作。
更具體的說法:
????????可以通過訂閱 binlog 日志,拿到具體要操作的數據,然后再執行緩存刪除,阿里巴巴開源的 Canal 中間件就是基于這個實現的。
????????Canal 模擬 MySQL 主從復制的交互協議,把自己偽裝成一個 MySQL 的從節點,向 MySQL 主節點發送 dump 請求,MySQL 收到請求后,就會開始推送 Binlog 給 Canal,Canal 解析 Binlog 字節流之后,將binlog日志采集發送到MQ隊列里面,然后編寫一個簡單的緩存刪除消息者訂閱binlog日志,根據更新log刪除緩存,并且通過ACK機制確認處理這條更新log,保證數據緩存一致性。
![[Windows] 字體渲染 mactype v2025.4.11](http://pic.xiahunao.cn/[Windows] 字體渲染 mactype v2025.4.11)



串口通訊(串口通訊教程)(串口接收發送教程))

)

![第二期:[特殊字符] 深入理解MyBatis[特殊字符]MyBatis基礎CRUD操作詳解[特殊字符]](http://pic.xiahunao.cn/第二期:[特殊字符] 深入理解MyBatis[特殊字符]MyBatis基礎CRUD操作詳解[特殊字符])








)

