INnoDB? ?三特性? ?事務? ?外鍵? ? 行級鎖(開啟事務時,查詢后加FOR UPDATE)
MySQL 使用 InnoDB,在 默認隔離級別 —— REPEATABLE READ(可重復讀) 下? 開啟事務,執行 UPDATE 時默認會加行鎖? 只要事務沒有提交? 這條數據會鎖住
Mysql概述
數據庫(DataBase),簡稱:DB.存儲數據的倉庫,數據是有組織的進行存儲
數據庫管理系統(DataBase Management System),簡稱:DBMS.操作和管理數據庫的大型軟件
SQL(Structured Query Language):操作關系型數據庫的編程語言,定義了一套操作關系型數據庫統一標準
Windows中Mysql的啟動命令
net start mysql80
net stop mysql80
Mysql客戶端連接
mysql [-h 127.0.0.1] [-P 3306] -u root -p
系統管理類的 SQL 命令 元數據查詢
查詢所有數據庫:SHOW DATABASES;
查詢當前使用的數據庫: SELECT DATABSES();
-
SHOW DATABASES;:查看所有數據庫 -
SHOW TABLES;:查看當前數據庫中的所有表 -
SHOW COLUMNS FROM 表名;:查看表結構 -
SHOW INDEX FROM 表名;:查看索引 -
SHOW GRANTS FOR 用戶;:查看權限
查詢當前數據庫所有表
SHOW TABLES;
查詢表結構
DESC 表名;
查詢指定表的建表語句
SHOW CREATE TABLE?表名
SQL分類
DDL(Data Definition Language):數據定義語言,用來定義數據庫對象(數據庫,表,字段)
常用關鍵字:
-
CREATE:創建數據庫、表、視圖等 -
DROP:刪除數據庫、表、視圖等 -
ALTER:修改表結構(增加/刪除列、修改列類型等) -
TRUNCATE:清空表數據(比 DELETE 快,不可回滾) -
RENAME:重命名數據庫對象
創建數據庫:
CREATE DATABASES [ IF NOT EXISTS] 數據庫名 [DEFAULT CHARSET 字符集] [ COLLATE 排序規則];
刪除數據庫
DORP DATABASE [IF EXISTS] 數據庫名;
使用數據庫
USE 數據庫名
例如
create database itcast;
創建表
CREATE TABLE [IF NOT EXISTS] 表名(
? ? ? ? 字段1 字段1類型 [COMMENT 字段1注釋],
????????字段2 字段2類型 [COMMENT 字段2注釋]
)[COMMENT 表注釋]
例如:
CREATE TABLE tb_user(id int comment '編號',name varchar(50) comment '姓名',age int comment '年齡',gender varchar(1) comment '性別') comment '用戶表';
查看表結構:DESC tb_user;
查看指定表的建表語句:SHOW CREATE TABLE tb_user;
Mysql的數據類型
1.數值類型
有符號:指出現負數的范圍? ? 無符號:指沒有負數的范圍
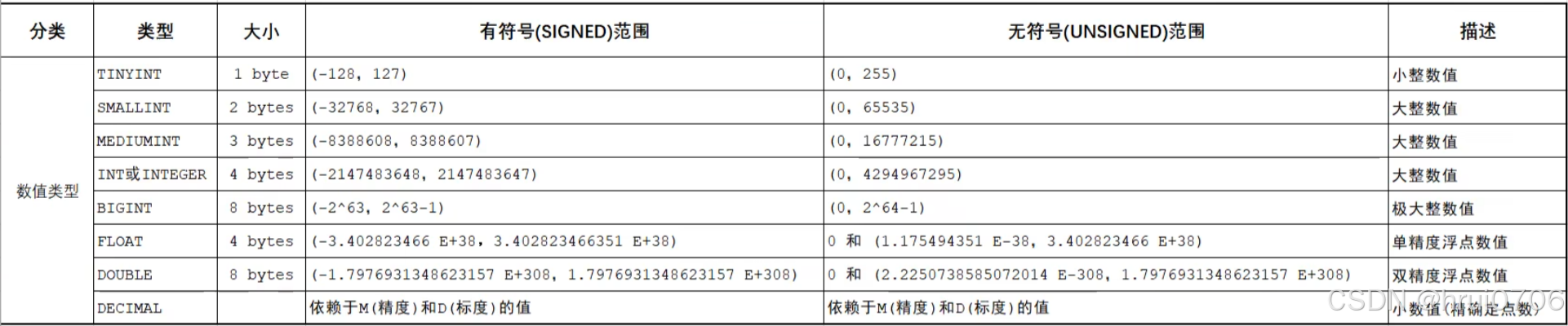
DECIMAL(10, 2) 第一個參數10代表精度? ?第二個參數代表標度
精度表示最多可存儲 10 位數字
標度表示其中 2 位是小數位
例如:12345678.11
默認情況下在Navicat中即使不顯示指定精度和標度
針對于Decimal類型需要顯示指定精度和標度? 不然無法存小數
Doubel即使0,0也可以存小數? 應該是Navicat的顯示誤區
例如你希望用double表示分數? 可以用double(4,1) 最多4位? 小數點后保留1位
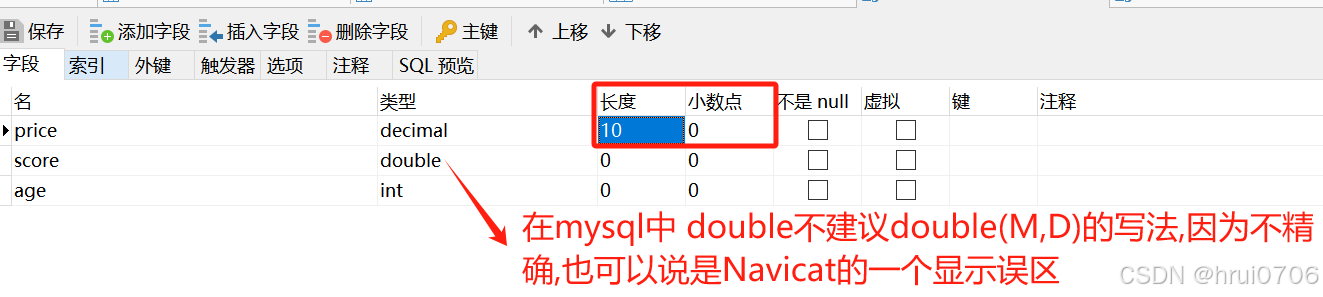
默認都是有符號的
指定無符號示例
CREATE TABLE users (
? ? id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
? ? age TINYINT UNSIGNED,
? ? score INT,
? ? balance DECIMAL(10,2) UNSIGNED
);
?
2.字符串類型
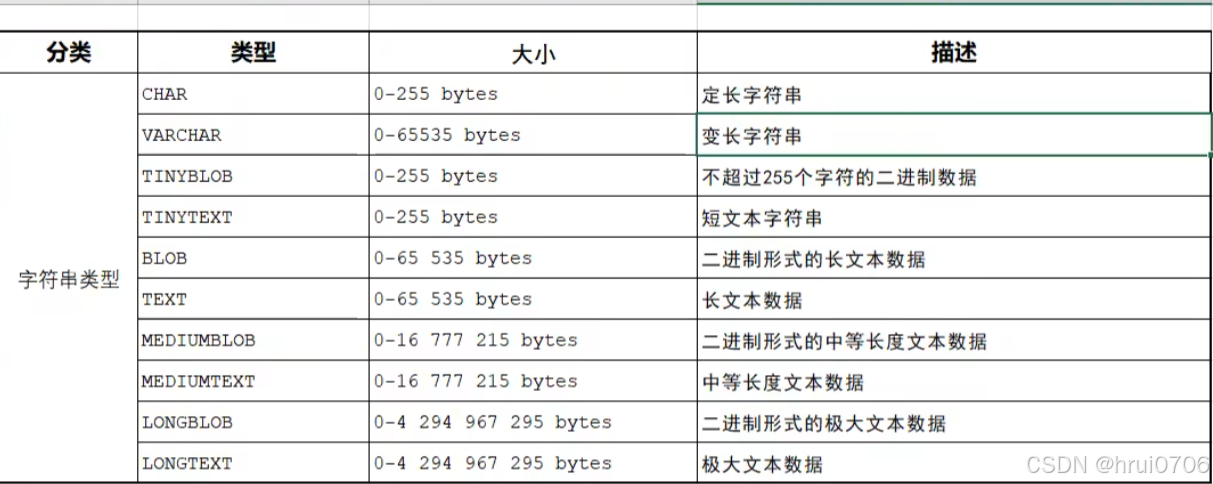
3.日期時間類型

練習

CREATE TABLE emp (
? ? id INT COMMENT '編號',
? ? workno VARCHAR(10) COMMENT '工號',
? ? name VARCHAR(10) COMMENT '姓名',
? ? gender CHAR(1) COMMENT '性別',
? ? age TINYINT UNSIGNED COMMENT '年齡',
? ? idcard CHAR(18) COMMENT '身份證號',
? ? entrydate DATE COMMENT '入職時間'
) COMMENT='員工表';
?
DDL-表操作-修改和刪除
添加字段
ALTER TABLE 表名 ADD 字段名 類型 [UNSIGNED] [NOT NULL] [DEFAULT 值] [COMMENT '說明'];
修改數據類型
ALTER TABLE 表名 MODIFY 字段名 新數據類型(長度) [UNSIGNED] [NOT NULL | NULL] [DEFAULT 值] [COMMENT '注釋'];
修改字段名和字段類型? 注意用CHANGE的話必須寫“舊字段名”和“新字段名”,哪怕名字不變!
ALTER TABLE 表名?
CHANGE 舊字段名 新字段名 新數據類型(長度) [UNSIGNED] [NOT NULL | NULL] [DEFAULT 值] [COMMENT '注釋'];
刪除字段
ALTER TBALE 表名 DROP 字段名;
修改表名
ALTER TABLE 表名 RENAME 新表名;
刪除表
刪除整張表(連結構都沒了)
DROP TABLE [IF EXISTS] 表名;
清空表數據,但保留表結構??重置表的自增計數器(如果有)不是逐行刪除(像?DELETE?那樣)
對于大表,TRUNCATE?比?DELETE FROM 表名?快得多 DELETE是DML操作
TRUNCATE TABLE 表名;
DDL-數據庫操作總結
SHOW DATABASES; ? ? ? ? ? ? ? ? ? ? ? ? ? ?-- 查看所有數據庫
CREATE DATABASE 數據庫名; ? ? ? ? ? ? ? ? ?-- 創建數據庫
USE 數據庫名; ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?-- 切換當前數據庫
SELECT DATABASE(); ? ? ? ? ? ? ? ? ? ? ? ? -- 查看當前所用數據庫
DROP DATABASE [IF EXISTS] 數據庫名; ? ? ? ?-- 刪除數據庫(推薦加 IF EXISTS)
DDL-表操作總結
SHOW TABLES; ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? -- 查看當前數據庫中所有表
CREATE TABLE 表名 (
? ? 字段名 數據類型 [約束] [COMMENT '注釋'],
? ? ...
); ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?-- 創建表
DESC 表名; ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?-- 查看表結構(字段+類型+約束)
SHOW CREATE TABLE 表名; ? ? ? ? ? ? ? ? ? ? -- 查看完整建表語句
-- 表結構變更(操作不能混用在一條 ALTER 中):
ALTER TABLE 表名 ADD 列名 類型(長度) ... ; ? ? ? ? -- 添加字段
ALTER TABLE 表名 MODIFY 列名 新類型(長度) ... ; ? ? -- 修改字段類型
ALTER TABLE 表名 CHANGE 舊名 新名 類型(長度) ... ; ?-- 改字段名+類型
ALTER TABLE 表名 DROP COLUMN 列名; ? ? ? ? ? ? ? ?-- 刪除字段
ALTER TABLE 表名 RENAME TO 新表名; ? ? ? ? ? ? ? ? -- 修改表名
DROP TABLE [IF EXISTS] 表名; ? ? ? ? ? ? ? ? ? ? ?-- 刪除表
?
DML(Data Manipulation Language):數據操作語言,用來對數據庫表中的數據進行增刪改
常用關鍵字:
-
INSERT:插入數據 -
UPDATE:更新數據 -
DELETE:刪除數據
添加數據INSERT
全量字段插入
INSERT INTO T_USER VALUES(1,"張三",18);
批量插入
INSERT INTO t_user VALUES(1,"張三",18),(2,"李四",19);
指定字段插入
INSERT INTO t_user(name,age)VALUES("王五",17),("趙六",19);
一些特殊用法
整張表數據復制
INSERT INTO 表B
SELECT * FROM 表A;
?
指定字段復制
INSERT INTO 表B(字段1, 字段2, ...)
SELECT 字段A1, 字段A2, ...
FROM 表A;
復制時加條件
INSERT INTO 表B
SELECT * FROM 表A
WHERE 條件;
跨數據庫復制
INSERT INTO 新庫.表B
SELECT * FROM 舊庫.表A;
?
備份原表數據
CREATE TABLE emp_bak LIKE emp;
INSERT INTO emp_bak SELECT * FROM emp;
注意:插入數據時,指定字段順序需要與值得順序對應
字符串和日期型數據應該包含在引號中
插入的數據大小應該在字段的規定范圍內
?
修改數據UPDATE
UPDATE 表名 SET 字段名1=值,字段名2=值2,...[WHERE 條件];
如果沒有條件則修改整張表數據
刪除數據DELETE
DELETE FROM 表名 [WHERE 條件];
DQL(Data Query Language):數據查詢語言,用來查詢數據庫中表的記錄
常用關鍵字:
-
SELECT:查詢數據 -
FROM:指定數據來源的表 -
WHERE:設置查詢條件 -
GROUP BY:分組 -
HAVING:過濾分組后的結果 -
ORDER BY:排序 -
JOIN:多表連接查詢
SELECT
? ? ? ? 字段列表
FROM?
? ? ? ? 表名列表
WHERE
? ? ? ? 條件列表
GROUP BY
? ? ? ? 分組字段列表
HAVING
? ? ? ? 分組后條件列表
ORDER BY?
? ? ? ? 排序字段列表
LIMIT
? ? ? ? 分頁參數
執行順序
from ---?join ---?on --- where --- group by --- having --- select --- distinct --- order by ---- limit
CREATE TABLE emp (
? ? id INT PRIMARY KEY AUTO_INCREMENT COMMENT '編號',
? ? workno VARCHAR(10) COMMENT '工號',
? ? name VARCHAR(10) COMMENT '姓名',
? ? gender CHAR(1) COMMENT '性別',
? ? age TINYINT UNSIGNED COMMENT '年齡',
? ? idcard CHAR(18) COMMENT '身份證號',
? ? workaddress VARCHAR(50) COMMENT '工作地址',
? ? entrydate DATE COMMENT '入職時間'
) COMMENT='員工表';
INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)
VALUES
(1, '1', '柳巖', '女', 20, '123456789012345678', '北京', '2000-01-01'),
(2, '2', '張無忌', '男', 18, '123456789012345670', '北京', '2005-09-01'),
(3, '3', '韋一笑', '男', 38, '123456789712345670', '上海', '2005-08-01'),
(4, '4', '趙敏', '女', 18, '123456757123845670', '北京', '2009-12-01'),
(5, '5', '小昭', '女', 16, '123456789012345678', '上海', '2007-07-01'),
(6, '6', '楊逍', '男', 28, '12345678931234567X', '北京', '2006-01-01'),
(7, '7', '范遙', '男', 40, '123456789212345670', '北京', '2005-05-01'),
(8, '8', '黛綺絲', '女', 38, '123456157123465670', '天津', '2015-05-01'),
(9, '9', '范涼涼', '女', 45, '123156789012345678', '北京', '2010-04-01'),
(10, '10', '陳友諒', '男', 53, '123456789012345670', '上海', '2011-01-01'),
(11, '11', '張士誠', '男', 55, '12356789712345670', '江蘇', '2015-05-01'),
(12, '12', '常遇春', '男', 32, '12346475712345670', '北京', '2004-02-01'),
(13, '13', '張三豐', '男', 88, '12365678712345678', '江蘇', '2020-11-01'),
(14, '14', '滅絕', '女', 65, '123456791297123456', '西安', '2019-05-01'),
(15, '15', '胡青牛', '男', 70, '12345674971234567X', '西安', '2018-04-01'),
(16, '16', '周芷若', '女', NULL, '123456789012345670', '北京', '2012-06-01');
基本查詢
SELECT 字段1,字段2,字段3,...FROM 表名;
SELECT * FROM 表名;
設置別名
SELECT 字段1 [AS 別名1],字段2 [AS 別名2],.... FROM 表名;
去除重復記錄
SELECT DISTINCT 字段列表 FROM 表名;
基本查詢練習
1.查詢指定字段 name,workno,age
SELECT name,workno,age FROM emp;
2.查詢所有字段
SELECT * FROM emp; #最好列出所有字段 不要用*
3.查詢所有員工的工作地址,起別名
SELECT workaddress AS address FROM emp;
4.查詢公司員工的上班地址(不要重復)
SELECT DISTINCT workaddress AS address FROM emp;
條件查詢(WHERE)
SELECT 字段列表 FROM 表名 WHERE 條件列表;
條件:



條件查詢練習
查詢年齡等于88的員工
SELECT * FROM emp where age=88;
查詢年齡小于20的員工信息
SELECT * FROM emp WHERE age<20;
查詢年齡小于等于20的員工
SELECT * FROM emp WHERE age<=20;
查詢沒有身份證號的員工信息
SELECT * FROM emp WHERE idcard IS NULL;?
查詢有身份證號的員工信息
SELECT * FROM emp WHERE idcard IS NOT NULL;?
查詢年齡不等于88的員工信息
SELECT * FROM emp WHERE age!=88;
SELECT * FROM emp WHERE age<>88;
查詢年齡在15歲(包含)到20歲(包含的)員工信息;
SELECT * FROM emp
WHERE age >= 15 AND age <= 20;
SELECT * FROM emp
WHERE age >= 15 &&age <= 20;
SELECT * FROM emp
WHERE age BETWEEN 15 AND 20;等價于age >= 15 AND age <= 20
注意:使用BETWEEN 參數1 AND 參數2? 時候 參數1<=參數2
查詢性別為女且年齡小于25歲員工信息
SELECT * FROM emp WHERE gender='女' AND age<25;
SELECT * FROM emp WHERE gender='女' && age<25;
查詢年齡等于18或20或40的員工信息
SELECT * FROM emp WHERE age = 18 OR age=20 OR age=40;
SELECT * FROM emp WHERE age IN(18,20,40);
查詢姓名為2個字的員工信息
SELECT * FROM emp WHERE name like '__'; #兩個下劃線? ?一個_代表一個字符
SELECT * FROM emp
WHERE CHAR_LENGTH(name) = 2;
查詢身份證最后一位是X的員工信息
SELECT * FROM emp
WHERE idcard LIKE '%X';
SELECT * FROM emp
WHERE idcard LIKE '_________________X'; #前面寫17個下劃線也行
聚合函數(COUNT MAX MIN AVG SUM)
將一列數據做為一個整體,進行縱向計算
常見聚合函數
COUNT? ?統計數量
MAX? ? ? ? 最大值
MIN? ? ? ? ? 最小值
AVG? ? ? ? ?平均值
SUM? ? ? ? 求和
語法:
SELECT 聚合函數(字段列表) FROM 表名;
SELECT COUNT(*) FROM emp;?
SELECT COUNT(1) FROM emp; #效率上和COUNT(*)幾乎等價
SELECT COUNT(age) FROM emp; #會自動排除age為null的行
注意:如果指定列名,為null的列不參與統計,會自動排除NULL的列
聚合函數練習
統計該企業員工數量
SELECT COUNT(*) FROM emp;
統計該企業員工平均年齡
SELECT AVG(age) FROM emp;
統計該企業員工最大年齡
SELECT MAX(age) FROM emp;
統計該企業員工的最小年齡
SELECT MIN(age) FROM emp;
統計西安地區員工年齡之和
SELECT * FROM emp WHERE workaddress='西安';
分組查詢(GROUP BY)
語法:
SELECT 字段列表 FROM 表名 [WHERE 條件] GROUP BY 分組字段名 [HAVING 分組后過濾條件];
WHERE與HAVING的區別
執行時機不同:WHERE執行在GROUP BY之前,不滿足WHERE條件的不參與GROUP BY,HAVING是GROUP BY之后對結果進行過濾
判斷條件不同:WHERE不能對聚合函數進行判斷,而HAVING可以
分組查詢練習
根據性別分組,統計男性員工和女性員工數量
SELECT gender, COUNT(*) AS total
FROM emp
GROUP BY gender;? #分組字段不寫入查詢? 查詢變得沒有意義
根據性別分組,統計男性員工和女性員工的平均年齡
SELECT gender, AVG(age) AS total
FROM emp
GROUP BY gender;
查詢年齡小于45的員工,并根據工作地址分組,獲取員工數量大于等于3的工作地址
SELECT workaddress,COUNT(*) total FROM emp where age<45 GROUP BY workaddress HAVING total>3;
SELECT workaddress,COUNT(*) total FROM emp where age<45 GROUP BY workaddress HAVING COUNT(*)>3; #select 之后起了別名? 除了ORDER BY之后 HAVING之后也是可以的
注意:
執行順序? WHERE --- GROUP BY ---?聚合函數 ---HAVING
分組之后,查詢的一般為聚合函數和分組字段,查詢其他字段無任何意義,一般來說如果用了分組查詢,分組的字段不寫入查詢也會變得無意義(因為不知道這是個什么) 除非就是寫死,只有自己知道這是個啥
1. FROM
2. JOIN
3. ON
4. WHERE
5. **GROUP BY** ? ← 把數據分組
6. **聚合函數計算**(如 COUNT、SUM)
7. HAVING
8. SELECT
9. ORDER BY
10. LIMIT
排序查詢(ORDER BY)
語法:
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1,字段2 排序方式2;
ASC 代表升序? 默認值
DESC 降序
如果多字段排序,當第一個字段值相同時,才會根據第二個字段進行排序
排序查詢練習
根據年齡對公司的員工進行升序排序
SELECT * FROM emp ORDER BY age; #默認ASC 可以不寫
根據入職時間,對員工進行降序排序
SELECT * FROM emp ORDER BY?entrydate DESC;
根據年齡對公司員工進行升序排序,年齡相同按入職時間進行降序排序
SELECT * FROM emp ORDER BY age,entrydate DESC;
分頁查詢(LIMIT)
語法:
SELECT 字段列表 FROM emp LIMIT 起始索引,查詢記錄數;
如果將pageNum當頁數? ?pageSize當每頁顯示條數
注意:該公式不能直接當SQL寫入? 需要計算好(pageNum-1)*pageSize,pageSize
SELECT 字段列表 FROM emp LIMIT (pageNum-1)*pageSize,pageSize;
注意:分頁查詢,不同數據庫有不同實現,Mysql中是LIMIT
DQL練習
查詢年齡為20,21,22,23歲的員工信息
SELECT * FROM emp WHERE age=20 OR age=21 OR age=22 OR age=23;
SELECT * FROM emp WHERE age BETWEEN 20 AND 23;
SELECT * FROM emp WHERE age IN(20,21,22,23);
查詢性別為男,并且年齡在20-40歲(都包含)以內的姓名為三個字的員工信息
SELECT * FROM emp WHERE gender='男' AND age BETWEEN 20 AND 40 AND name LIKE '___';
統計員工表中,年齡小于60歲的,男性員工共和女性員工的人數
SELECT gender,COUNT(*) FROM emp WHERE age<60 GROUP BY gender;
查詢所有年齡小于35歲員工的姓名,年齡,并對查詢結果按年齡升序排序,如果年齡相同按入職時間降序排序
SELECT name, age?
FROM emp?
WHERE age <= 35?
ORDER BY age, entrydate DESC;
查詢性別為男,且年齡在20-40歲(包含)以內的前5個員工信息,對查詢的結果按年齡升序排序,年齡相同按入職時間升序排序
SELECT * FROM emp WHERE gender='男' AND age BETWEEN 20 AND 40 ORDER BY age,entrydate LIMIT 5;
DCL(Data Control Language):數據控制語言,用來創建數據庫用戶,控制數據庫的訪問權限
常用關鍵字:
-
GRANT:授予權限 -
REVOKE:撤銷權限 -
DENY:拒絕權限(部分數據庫支持,如 SQL Server)
DCL管理用戶
1.查詢用戶
USE mysql;? ?
SELECT * FROM user;? ?#這個user是表名
2.創建用戶
CREATE USER '用戶名'@'主機名' IDENTIFIED BY '密碼';? ?#這里的USER是關鍵字
3修改用戶密碼
ALTER USER?'用戶名'@'主機名' IDENTIFIED WITH mysql_native_password BY '新密碼';
4.刪除用戶
DROP USER?'用戶名'@'主機名';
創建用戶root1 可以從任何地址來連接數據庫? ?密碼是abc123456
CREATE USER 'root2'@'%' IDENTIFIED BY 'abc123456';
修改用戶登錄密碼
ALTER USER 'root1'@'%' IDENTIFIED WITH mysql_native_password BY 'abc1234561';
刪除用戶root1
DROP USER?'root1'@'%';
TCL管理練習
?創建用戶'hrui',只能夠在當前主機localhost訪問,密碼'123456'
#該用戶創建之后沒有權限 只能看到information_schema一張表
CREATE USER 'hrui'@'localhost' IDENTIFIED BY '123456';
修改用戶登錄密碼
ALTER USER 'root1'@'%' IDENTIFIED WITH mysql_native_password BY 'abc1234561';
刪除用戶root1
DROP USER?'root1'@'%';
權限設置? 默認創建用戶后? 該用戶登錄之后? 沒有權限 只能看到information_schema和performance_schema兩張表

查詢用戶權限
SHOW GRANTS FOR '用戶名'@'主機名';
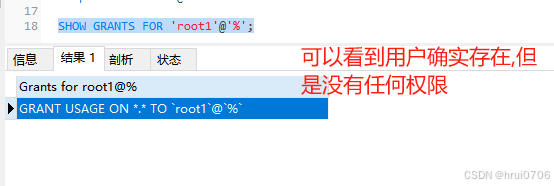
新創建的用戶只能看到
授予權限
GRANT 權限列表 ON 數據庫名.表名 TO '用戶名'@'主機名';? #如果? *.* 表示所有數據庫,所有表

GRANT ALL ON *.* TO 'root1'@'%'; #授予root1所有權限? ?注意:RDS上不能這么做 不能給與非root用戶所有的權限? 可以設置具體的庫和具體的表
GRANT ALL PRIVILEGES ON testdb.* TO 'root1'@'%';和GRANT ALL ON testdb.* TO 'root1'@'%';效果事一樣的
撤銷權限
REVOKE all on *.* FROM 'root1'@'%'; 撤銷所有權限
注意:多個權限用逗號分隔,授權時數據庫和表名可以使用 * 進行統配 *.* 就是所有庫所有表
阿里云RDS不允許創建非root用戶 的 *.* 全庫權限
重點
1.用戶管理
CREATE USER '用戶名'@'主機名' IDENTIFIED BY '密碼'; #可以在任何庫執行? 不需要指定庫
ALTER USER '用戶名'@'主機名' IDENTIFIED WITH mysql_native_password BY '新密碼';
DROP USER '用戶名'@'主機名';#可以在任何庫執行? 不需要指定庫 就是不用use xxx
2.權限控制
GRANT 權限列表 ON 數據庫名.表名 TO '用戶名'@'主機名';
REVOKE 權限列表 ON 數據庫名.表名 FROM '用戶名'@'主機名';
select * from user; #需要指定數據庫 use mysql;
TCL(Transaction Control Language):事務控制語句,用于控制事務
常用關鍵字:
-
BEGIN/START TRANSACTION:開始事務 -
COMMIT:提交事務 -
ROLLBACK:回滾事務 -
SAVEPOINT:設置保存點 -
SET TRANSACTION:設置事務屬性
函數
指一段可以直接被另一段程序調用的程序或代碼
字符串函數
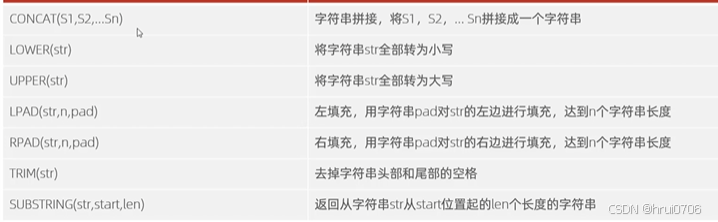
CONCAT 參數可以是1個或者多個? 依次拼接參數 模糊查詢時候經常用到
注意SUBSTRING? ?start是從1開始的? ? TRIM 無法去掉str中間的空格
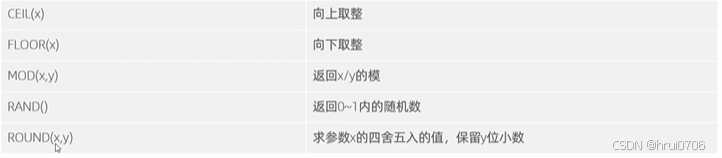
數值函數
常用的數值函數
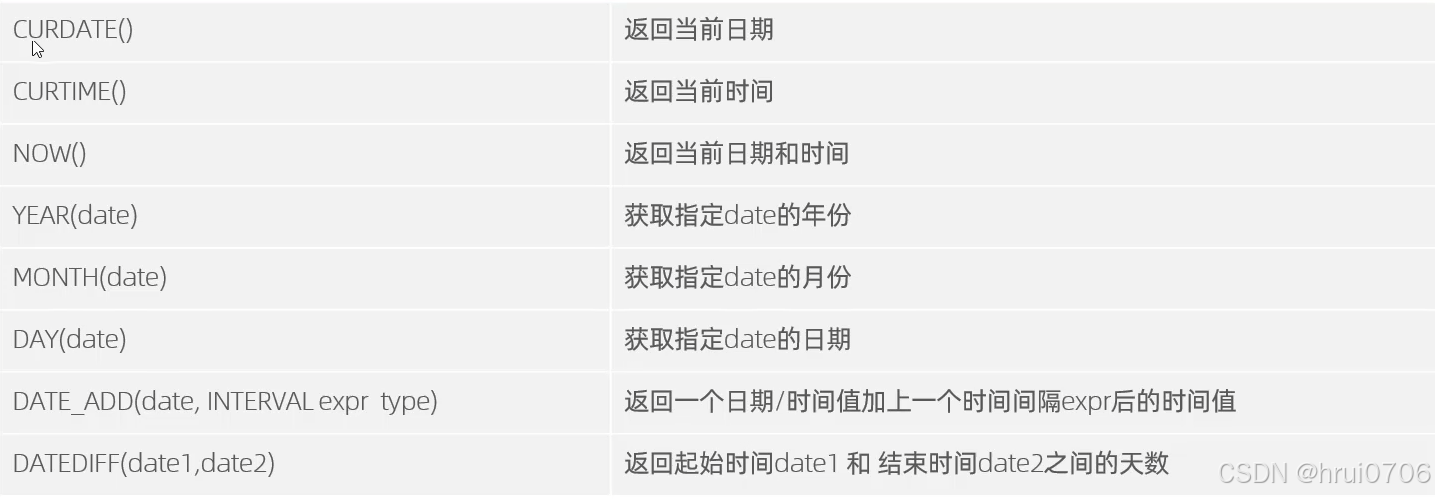
日期函數
流程函數

常用示例

END是為了結束語法? 必寫? 然后取個別名? ELSE 可以不寫? 不寫的話都沒有匹配到就返回NULL

約束
約束:作用于表中字段上的規則,用于限制存儲在表中的數據
目的:保證數據庫中的數據的正確,有效性完整性

各種約束示例
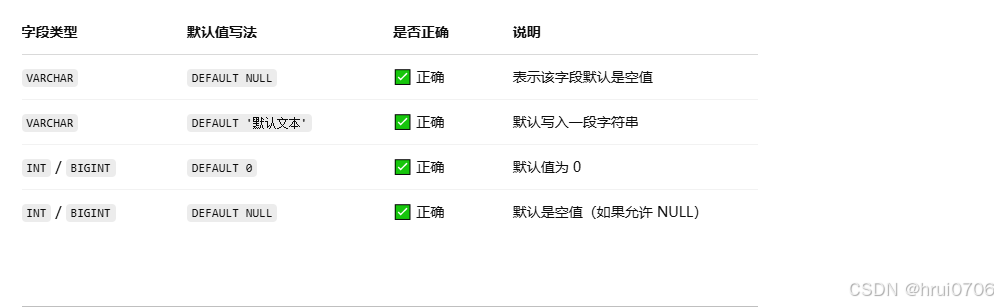
DEFAULT NULL,? ?DEFAULT 0, DEFAULT 'XXX'

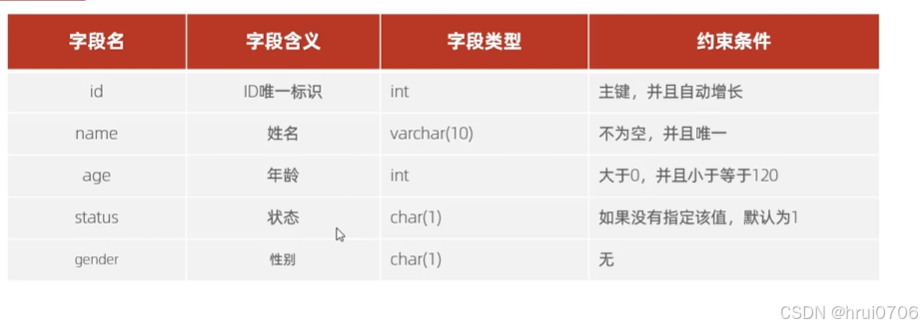
CREATE TABLE users (
? ? id INT PRIMARY KEY AUTO_INCREMENT COMMENT 'ID唯一標識',
? ? name VARCHAR(10) NOT NULL UNIQUE COMMENT '姓名',
? ? age INT CHECK (age > 0 AND age <= 120) COMMENT '年齡',
? ? status CHAR(1) DEFAULT '1' COMMENT '狀態',
? ? gender CHAR(1) COMMENT '性別'
) COMMENT='用戶表';
?
約束是作用于表中字段上的,可以在創建表/修改表的時候添加約束
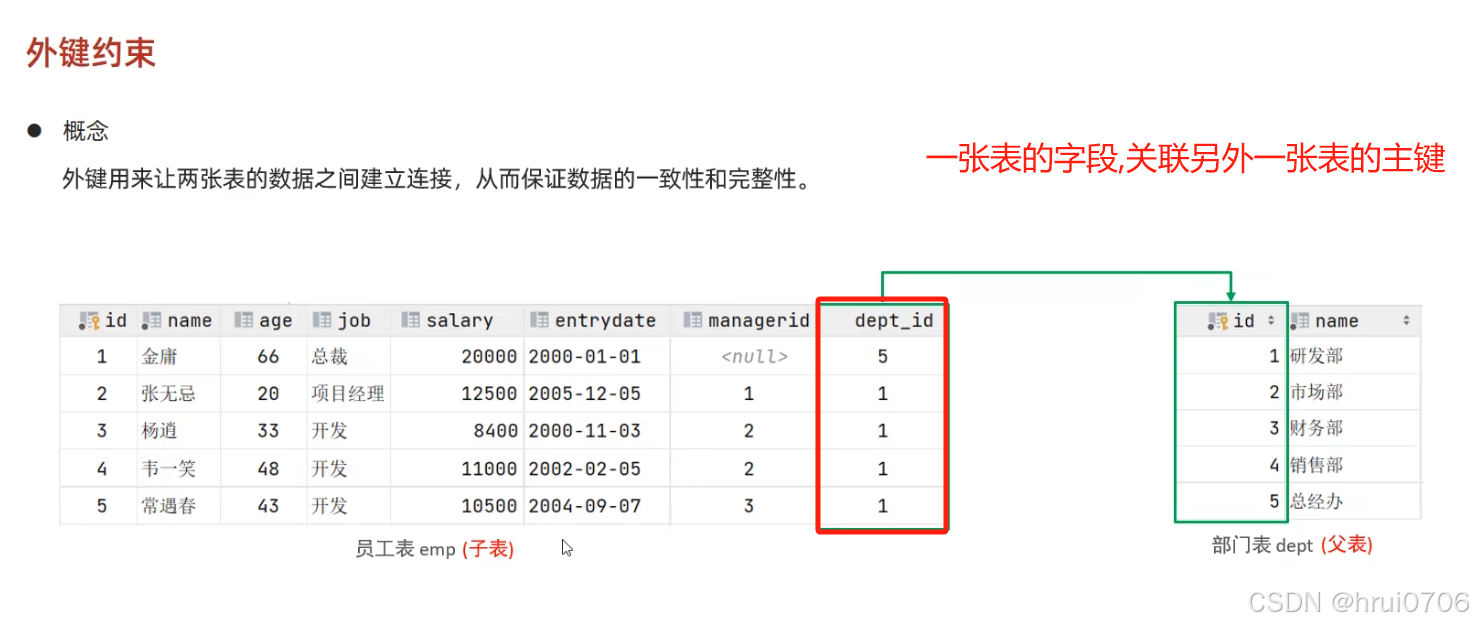
外鍵約束
當一張表中的字段引用了另一張表的主鍵時,這個字段稱為“外鍵”(foreign key),這個關系稱為外鍵約束。
這樣 如果要刪除dept表中數據前,先要刪除emp表中關聯數據
示例
后面加ON



多表查詢
關于sql92和sql99寫法
sql92寫法? 兩張表用","分割,關聯關系放在where后面
SELECT emp.name, dept.name
FROM emp, dept
WHERE emp.dept_id = dept.id;
?
sql99語法
SELECT emp.name, dept.name
FROM emp
INNER JOIN dept ON emp.dept_id = dept.id;
?
多表關系
在關系型數據庫中,常見的表與表之間關系有這 三種:一般現在都不建議外鍵
1.一對一
CREATE TABLE user (
? ? id INT PRIMARY KEY AUTO_INCREMENT,
? ? username VARCHAR(50)
);CREATE TABLE user_detail (
? ? id INT PRIMARY KEY AUTO_INCREMENT, ? -- 自己的主鍵
? ? user_id INT UNIQUE, ? ? ? ? ? ? ? ? ?-- 外鍵 + 唯一約束實現一對一
? ? address VARCHAR(100),
? ? phone VARCHAR(20),
? ? FOREIGN KEY (user_id) REFERENCES user(id)
);
查詢示例SELECT u.username, d.phone
FROM user u
LEFT JOIN user_detail d ON u.id = d.user_id
WHERE u.id = 1;
?
A 表的一條記錄只能對應 B 表的一條記錄,反之亦然
2.一對多
A 表一條記錄可以對應 B 表的多條記錄
CREATE TABLE dept (
? ? id INT PRIMARY KEY,
? ? name VARCHAR(50)
);CREATE TABLE emp (
? ? id INT PRIMARY KEY,
? ? name VARCHAR(50),
? ? dept_id INT,
? ? FOREIGN KEY (dept_id) REFERENCES dept(id)
);
查詢示例,查某個部門下的員工SELECT d.name AS 部門名, e.name AS 員工名
FROM dept d
LEFT JOIN emp e ON d.id = e.dept_id
WHERE d.id = 1;
查某個員工在哪個部門SELECT e.name AS 員工名, d.name AS 部門名
FROM emp e
JOIN dept d ON e.dept_id = d.id
WHERE e.id = 1;
3.多對多
A 表中的記錄可以對應 B 表的多條記錄,B 表中的記錄也能對應 A 表的多條記錄? 需要一張中間表保存A表ID和B表ID
CREATE TABLE student (
? ? id INT PRIMARY KEY,
? ? name VARCHAR(50)
);CREATE TABLE course (
? ? id INT PRIMARY KEY,
? ? name VARCHAR(50)
);CREATE TABLE student_course ( -- 中間表
? ? student_id INT,
? ? course_id INT,
? ? PRIMARY KEY (student_id, course_id), #可以用這個做主鍵 因為student_id和course_id? ? ? ? 一定唯一,也可以單獨創建主鍵? 自行維護? 外鍵現在一般都不建議
? ? FOREIGN KEY (student_id) REFERENCES student(id),
? ? FOREIGN KEY (course_id) REFERENCES course(id)
);查詢示例:查某個員工選了哪些課程
SELECT s.name AS 學生, c.name AS 課程
FROM student s
JOIN student_course sc ON s.id = sc.student_id
JOIN course c ON sc.course_id = c.id
WHERE s.id = 1;
多表查詢創建幾張關聯表
#創建部門表并插入數據
CREATE TABLE dept (
? ? id INT AUTO_INCREMENT COMMENT 'ID' PRIMARY KEY,
? ? name VARCHAR(50) NOT NULL COMMENT '部門名稱'
) COMMENT '部門表';INSERT INTO dept (id, name) VALUES
(1, '研發部'),
(2, '市場部'),
(3, '財務部'),
(4, '銷售部'),
(5, '總經辦'),
(6, '人事部');#創建員工表并插入數據
CREATE TABLE emp (
? ? id INT AUTO_INCREMENT COMMENT 'ID' PRIMARY KEY,
? ? name VARCHAR(50) NOT NULL COMMENT '姓名',
? ? age INT COMMENT '年齡',
? ? job VARCHAR(20) COMMENT '職位',
? ? salary INT COMMENT '薪資',
? ? entrydate DATE COMMENT '入職時間',
? ? managerid INT COMMENT '直屬領導ID',
? ? dept_id INT COMMENT '部門ID'
) COMMENT '員工表';INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id) VALUES
(1, '金庸', 66, '總裁', 20000, '2000-01-01', NULL, 5),
(2, '張無忌', 20, '項目經理', 12500, '2005-12-05', 1, 1),
(3, '楊逍', 33, '開發', 8400, '2000-11-03', 2, 1),
(4, '韋一笑', 48, '開發', 11000, '2002-02-05', 2, 1),
(5, '常遇春', 43, '開發', 10500, '2004-09-07', 3, 1),
(6, '小昭', 19, '程序員鼓勵師', 6600, '2004-10-12', 2, 1),
(7, '滅絕', 60, '財務總監', 8500, '2002-09-12', 1, 3),
(8, '周芷若', 19, '會計', 48000, '2006-06-02', 7, 3),
(9, '丁敏君', 23, '出納', 5250, '2009-05-13', 7, 3),
(10, '趙敏', 20, '市場部總監', 12500, '2004-10-12', 1, 2),
(11, '鹿杖客', 56, '職員', 3750, '2006-10-03', 10, 2),
(12, '鶴筆翁', 19, '職員', 3750, '2007-05-09', 10, 2),
(13, '方東白', 19, '職員', 5500, '2009-02-12', 10, 2),
(14, '張三豐', 88, '銷售總監', 14000, '2004-10-12', 1, 4),
(15, '俞蓮舟', 38, '銷售', 4600, '2004-10-12', 14, 4),
(16, '宋遠橋', 40, '銷售', 4600, '2004-10-12', 14, 4),
(17, '陳友諒', 42, NULL, 2000, '2011-10-12', 1, NULL);
?#在員工表中創建外鍵
ALTER TABLE emp
ADD CONSTRAINT fk_emp_dept_id
FOREIGN KEY (dept_id) REFERENCES dept(id);
笛卡爾積演示
SELECT * FROM emp,dept;
沒有 WHERE 條件或 JOIN 連接條件,數據庫就會把 emp 表中的每一行,與 dept 表中的每一行都組合一遍。
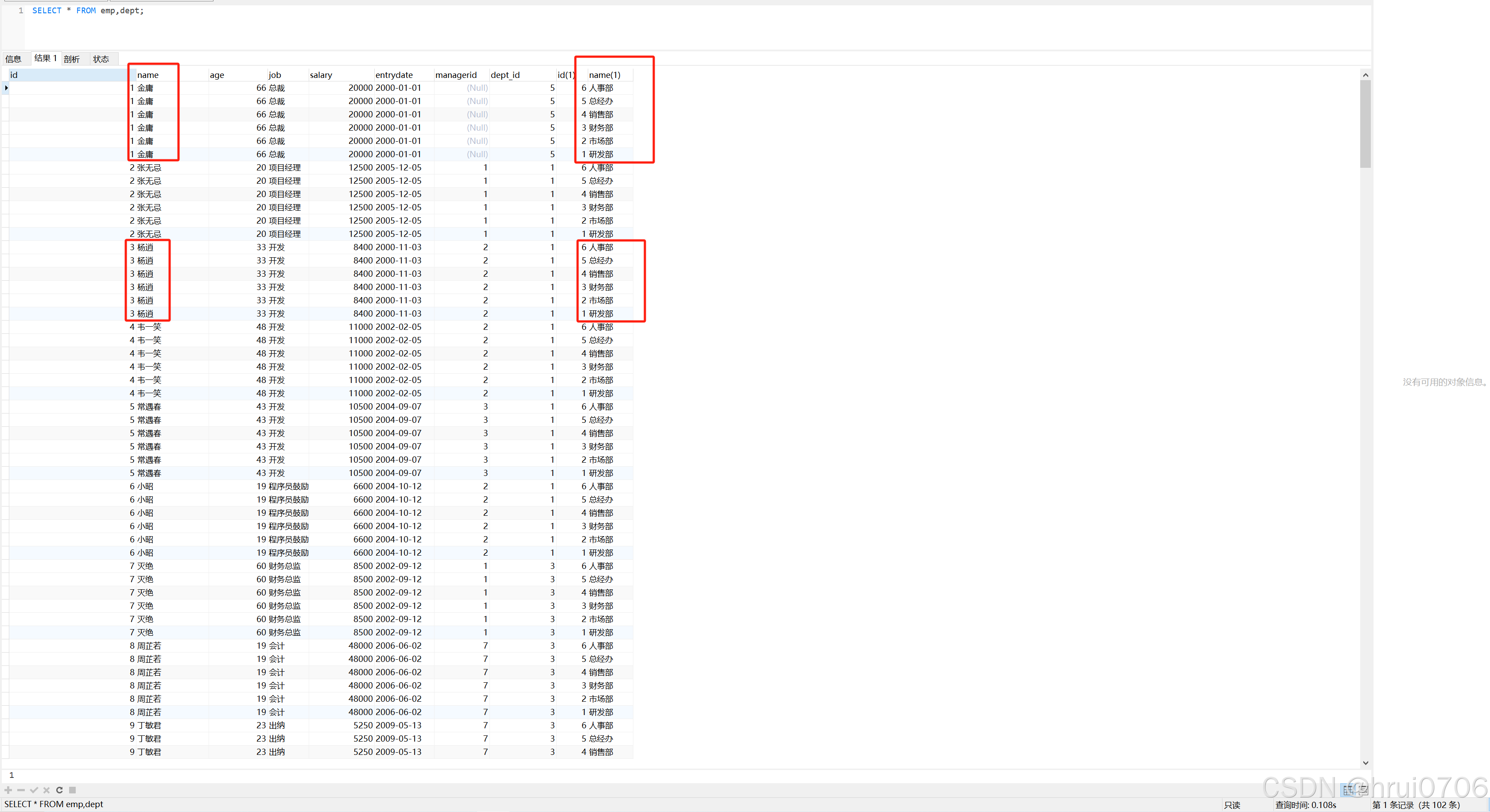
-
emp有 17 條數據 -
dept有 6 條數據 -
17 × 6 = 102 行
需要寫連接條件
多表查詢分類?
多表查詢分類:
1.連接查詢
? ? ? ? 1.1)內連接:相當于查詢A,B交集部門數據
? ? ? ? 1.2)外連接:
? ? ? ? ? ? ? ? 2.1)左外連接:查詢左表所有數據,以及兩張表交集部門數據
? ? ? ? ? ? ? ? 2.2)右外連接:查詢右表所有數據,以及兩張表交集部門數據
? ? ? ? 1.3)自連接:當前表與自身的連接查詢,自連接必須使用表別名
2.子查詢:把單表分為兩張表,需要有連接條件
內連接
返回的是兩張表交集部門的數據
sql92寫法(隱式寫法)
SELECT 字段列表 FROM 表1,表2 WHERE 表1.字段=表2.字段;
sql99寫法(顯式寫法)
SELECT 字段列表
FROM 表1 [INNER] JOIN 表2 ON 表1.字段 = 表2.字段;
內連接練習
查詢每一個員工的姓名,及關聯的部門的名稱(隱式內連接實現)
SELECT a.name,b.name deptName FROM emp a,dept b WHERE a.dept_id=b.id;
查詢每一個員工的姓名,及關聯的部門名稱(顯式內連接實現)
SELECT a.name,b.name deptName FROM emp a JOIN dept b ON a.dept_id=b.id;
外連接
左外連接
語法
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2? ON 連接條件;
以左表為主,查左表所有數據,及交集數據 交集沒有的以null填充
右外連接
語法
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN? 表2 ON 連接條件;?
以右表為主,查右表所有數據,及交集數據 交集沒有的以null填充
自連接
自連接查詢可以是內連接查詢也可以是外連接查詢
SELECT 字段列表 FROM 表1 別名A JOIN 表2 別名B ON 連接條件;
連接條件
員工的manage_id=老板表.id
聯合查詢UNION,UNION ALL
UNION查詢,就是把多次查詢的結果合并起來,形成一個新的查詢結果集
語法
SELECT 字段1, 字段2, ...
FROM 表1
WHERE 條件
UNION [ALL]
SELECT 字段1, 字段2, ...
FROM 表2
WHERE 條件;
注意:需要保證查詢出來的字段名 或者別名是相同的并且列數是相同的

子查詢
定義:SQL語句中嵌套SELECT語句,稱為嵌套查詢,又稱為子查詢
SELECT * FROM 表1 WHERE column1=(SELECT column1 FROM 表2)
子查詢的寫法很多
子查詢外部的語句可以是INSERT/UPDATE/DELETE/SELECT的任何一個
① SELECT *?
? ?FROM A?
? ?WHERE EXISTS (
? ? ? ?SELECT id?
? ? ? ?FROM B?
? ? ? ?WHERE B.aid = A.id
? ?)#為什么用DISTINCT? ?如果A和B是1對多情況 A表數據匹配B表多條會出現重復
② SELECT DISTINCT A.*
? ?FROM A
? ?JOIN B ON A.id = B.aid③ SELECT *?
? ?FROM A?
? ?WHERE A.id IN (
? ? ? ?SELECT B.aid?
? ? ? ?FROM B
? ?)
三種寫法結果是等價的

子查詢根據結果不同,可以分為
1.標量子查詢(子查詢結果為單個值)
2.列子查詢(子查詢結果為一列)
3.行子查詢(子查詢結果為一行)
4.表子查詢(子查詢結果為多行多列)
根據子查詢位置,分為:WHERE之后,FROM 之后,SELECT之后.
標量子查詢
子查詢結果為單個值
常用的操作符: =? ? <>? ?>? ?>=? ? <? ? <=
查詢銷售部的所有的員工信息
SELECT * FROM emp WHERE dept_id=(SELECT id FROM dept WHERE name='銷售部')
查詢在方東白入職之后入職的員工信息
SELECT * FROM emp WHERE entrydate>(SELECT entrydate FROM emp WHERE name='方東白')
列子查詢
子查詢結果為一列
常用操作符:IN? ? ? NOT IN? ? ANY? ? SOME? ?ALL

查詢銷售部和市場部的所有員工信息
SELECT * FROM emp WHERE dept_id IN(SELECT id FROM dept WHERE name IN('銷售部','市場部'))
查詢比財務部所有員工工資都高的員工 (這里將財務部周芷若的工資改為8000)插入數據時候數據有問題
SELECT * FROM emp WHERE salary >(SELECT MAX(salary) FROM emp WHERE dept_id=(SELECT id FROM dept WHERE name='財務部'))
SELECT * FROM emp WHERE salary >all(SELECT salary?FROM emp WHERE dept_id=(SELECT id FROM dept WHERE name='財務部'))
查詢比研發部其中任意一人工資高的員工信息
SELECT * FROM emp WHERE salary>any(SELECT salary FROM emp WHERE dept_id=(SELECT id FROM dept WHERE name='研發部'))
行子查詢
子查詢結果為一行(可以是多列)
常用操作符: =? ? ?<>? ? IN? ? NOT IN
查詢與張無忌的薪資及直屬領導相同的員工信息
薪資相同
SELECT salary FROM emp WHERE salary=(SELECT salary FROM emp WHERE name='張無忌')
直屬領導相同
SELECT manageid?FROM emp ?WHERE name='張無忌'?
SELECT *?
FROM emp?
WHERE salary = (
? ? SELECT salary FROM emp WHERE name = '張無忌'
)
AND managerid = (
? ? SELECT managerid FROM emp WHERE name = '張無忌'
);
可以這么寫
SELECT *?
FROM emp?
WHERE (salary, managerid) = (
? ? SELECT salary, managerid?
? ? FROM emp?
? ? WHERE name = '張無忌'
);
表子查詢
子查詢結果為多行多列
常用操作符:IN
查詢與鹿杖客 宋遠橋的職位和薪資相同的員工信息
鹿杖客 宋遠橋的職位和薪資
SELECT job,salary FROM emp WHERE name IN('鹿杖客','宋遠橋')
SELECT * FROM emp WHERE (job,salary) IN(SELECT job,salary FROM emp WHERE name IN('鹿杖客','宋遠橋'))
查詢入職日期是2006-01-01之后的員工信息,及其部門信息
SELECT
? ? A.*,
? ? B.name
FROM emp A
LEFT JOIN dept B ON A.dept_id = B.id
WHERE A.entrydate > '2006-01-01';
也可以這樣
SELECT e.*, d.*?
FROM (
? ? SELECT * FROM emp WHERE entrydate > '2006-01-01'
) e
LEFT JOIN dept d ON e.dept_id = d.id;
?
多表查詢案例
新增下面這張表? 工資等級表(媽了個巴子資本主義啊) 孫中山先生是偉大的'理想家'......
CREATE TABLE salgrade (
? ? grade INT COMMENT '等級',
? ? losal INT COMMENT '最低工資',
? ? hisal INT COMMENT '最高工資'
) COMMENT='薪資等級表';INSERT INTO salgrade VALUES?
(1, 0, ? ? 3000),
(2, 3001, ?5000),
(3, 5001, ?8000),
(4, 8001, 10000),
(5,10001, 15000),
(6,15001, 20000),
(7,20001, 25000),
(8,25001, 30000);
查詢員工的姓名,年齡,職位,部門信息
SELECT a.name,a.age,a.job,b.name deptName FROM emp a LEFT JOIN dept b ON a.dept_id=b.id
查詢年齡小于30歲的員工姓名,年齡,職位,部門信息
SELECT a.name,a.age,a.job,b.name deptName FROM emp a LEFT JOIN dept b ON a.dept_id=b.id WHERE a.age<30
查詢擁有員工的部門ID,部門名稱? ?(查詢交集部分去重)
SELECT id,name FROM dept WHERE id IN(SELECT dept_id FROM emp WHERE dept_id is not null)
SELECT DISTINCT d.id,d.name FROM emp e,dept d WHERE e.dept_id=d.id
查詢所有年齡大于40歲的員工,及其歸屬的部門名稱,如果員工沒有分配部門,也需要展示出來
SELECT a.name,b.name deptName FROM emp a LEFT JOIN dept b ON a.dept_id=b.id WHERE a.age>40
查詢所有員工的工資等級
SELECT
?? ?a.NAME,
?? ?b.grade?
FROM
?? ?emp a LEFT JOIN salgrade b?
ON?
? a.salary BETWEEN b.losal AND b.hisal
或者
SELECT a.name, b.grade?
FROM emp a?
LEFT JOIN salgrade b?
? ? ON a.salary >= b.losal AND a.salary <= b.hisal;
查詢研發部所有員工的信息及工資等級
SELECT
?? ?a.NAME,
?? ?c.grade,
?? ?b.NAME deptName??
FROM
?? ?emp a
?? ?JOIN dept b ON a.dept_id = b.id JOIN salgrade c ON a.salary BETWEEN c.losal?
?? ?AND c.hisal?
WHERE
?? ?b.NAME = '研發部'
查詢研發部員工的平均工資
SELECT
? ? a.name AS deptName,
? ? AVG(b.salary) AS avgSalary
FROM dept a
LEFT JOIN emp b ON a.id = b.dept_id
WHERE a.name = '研發部'
GROUP BY a.name;
查詢工資比滅絕高的員工信息
SELECT * FROM emp WHERE salary>(SELECT salary FROM emp WHERE name='滅絕')
查詢比平均薪資高的員工信息
SELECT * FROM emp WHERE salary>(SELECT AVG(salary) FROM emp)
查詢低于本部門平均工資的員工信息
SELECT a.*
FROM emp a
JOIN (
? ? SELECT dept_id, AVG(salary) AS avg_salary
? ? FROM emp
? ? GROUP BY dept_id
) AS b ON a.dept_id = b.dept_id
WHERE a.salary < b.avg_salary;
?
查詢所有的部門信息,并統計部門的員工人數
SELECT deptName, COUNT(*)?
FROM (SELECT a.*, b.name deptName?
? ? ? FROM emp a?
? ? ? JOIN dept b ON a.dept_id = b.id) t
GROUP BY deptName
事務
事務是一組操作的集合,它是一個不可分割的工作單位,事務會把所有的操作作為一個整體一起向系統提交或撤銷操作請求,這些操作要么同時成功,要么同時失敗
默認情況下,使用Mysql默認自動提交事務的
創建事務演示表
CREATE TABLE account (
? ? id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID',
? ? name VARCHAR(10) COMMENT '姓名',
? ? money INT COMMENT '余額'
) COMMENT='賬戶表';
INSERT INTO account (id, name, money)?
VALUES?
? ? (NULL, '張三', 2000),
? ? (NULL, '李四', 2000);
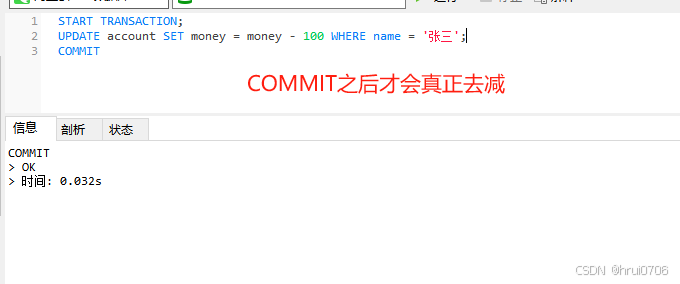
事務操作
以下兩種都是臨時會話級別設置事務手動提交
方式1:
開啟事務: START TRANSACTION? 或者? BEGIN
提交事務: COMMIT??
回滾事務: ROLLBACK
方式2
可以通過上面方式? 也可以設置
SELECT @@autocommit;? ?#如果是1 自動提交? ?0手動提交
SET @@autocommit = 0;
方式2不需要START TRANSACTION? 或者? BEGIN? ?可以直接用COMMIT? ?ROLLBACK
一般只需要了解會話級別事務即可
方式1
方式2

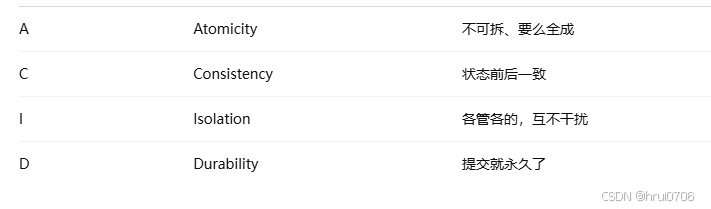
事務四大特性
1. 原子性(Atomicity)
事務是不可分割的最小操作單元,要么全部成功,要么全部失敗。
💡 比如轉賬:扣錢成功但收錢失敗,就要全部回滾。
2. 一致性(Consistency)
事務執行后,必須使數據庫從一個一致狀態變為另一個一致狀態。
💡 比如轉賬后,張三減少的錢和李四增加的錢總數不變,前后一致。
3. 隔離性(Isolation)
多個事務并發執行時,要互不干擾,互不影響,數據庫提供隔離機制保障這一點。
💡 比如你在查庫存時,別人的下單操作不會影響你看到的結果。
4. 持久性(Durability)
事務一旦提交,對數據庫的修改就是永久性的,即使系統崩潰也不會丟失。
💡 比如提交轉賬后,即使斷電重啟,數據也已經改了。
?
并發事務問題
兩個或多個事務在“同時”對同一份數據(同一條)進行操作或讀取,從而引發數據不一致、錯亂等問題。
例如張三的銀行卡
在一個事務中
SELECT money FROM account WHERE name = '張三'; ?-- 得到 1000
UPDATE account SET money = 1000 - 100 WHERE name = '張三'; ?-- 更新為 900
?在另外一個事務中
SELECT money FROM account WHERE name = '張三'; ?-- 也看到 1000!
UPDATE account SET money = 1000 - 200 WHERE name = '張三'; ?-- 更新為 800
結果誰最后提交就覆蓋了另一個,導致少減了一筆!?
臟讀
一個事務 讀取了另一個事務尚未提交的數據
Read Uncommitted(讀未提交)發生
舉例
當A事務開啟,執行 但是還沒有提交
UPDATE account SET money = 0 WHERE name = '張三';
此時事務 B 執行
SELECT money FROM account WHERE name = '張三'; ?-- 查到 0(但其實沒提交)
然后事務 A 回滾了,張三余額還是原來的,但事務 B 卻讀到了“臟數據”
不可重復讀
同一個事務中,前后兩次讀取同一條數據,結果不一樣(因為別的事務修改了數據并提交了)
Read Committed(讀已提交)會發生
舉例
當事務A開啟
SELECT money FROM account WHERE name = '張三'; ?-- 第一次查到 1000
此時事務B對該數據進行了操作
UPDATE account SET money = 500 WHERE name = '張三';
COMMIT;
當A事務再次查詢時候
SELECT money FROM account WHERE name = '張三'; ?-- 查到 500(發生了不可重復讀)
?
幻讀
幻讀是指:同一個事務內,使用相同查詢條件進行多次查詢時,結果集的“行數”或“記錄”發生了變化,原因是其他事務在期間插入或刪除了“符合條件的新記錄”。
Repeatable Read(可重復讀)
舉例
事務A開啟
SELECT * FROM account WHERE money > 1000; ?-- 查到 2 條記錄
?
事務B插入
INSERT INTO account(name, money) VALUES ('王五', 2000);
COMMIT;
當事務A再次執行相同查詢
SELECT * FROM account WHERE money > 1000; ?-- 現在查到 3 條記錄(多了一條“幻影”)
?

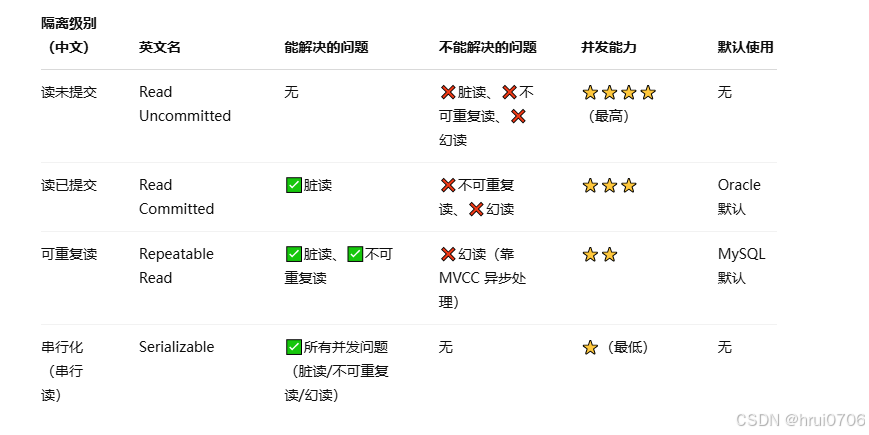
事務隔離級別

默認自己安裝的Mysql是可重復讀? ? ?阿里云RDS是讀已提交
查看事務隔離級別
SELECT @@transaction_isolation;
-- 或舊版本:
SELECT @@tx_isolation;
會話級別設置
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
全局設置
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
可選級別
READ UNCOMMITTED? ? ?讀未提交
READ COMMITTED? ? 讀已提交
REPEATABLE READ? ?可重復讀
SERIALIZABLE? ?序列化讀


Mysql進階篇

存儲引擎
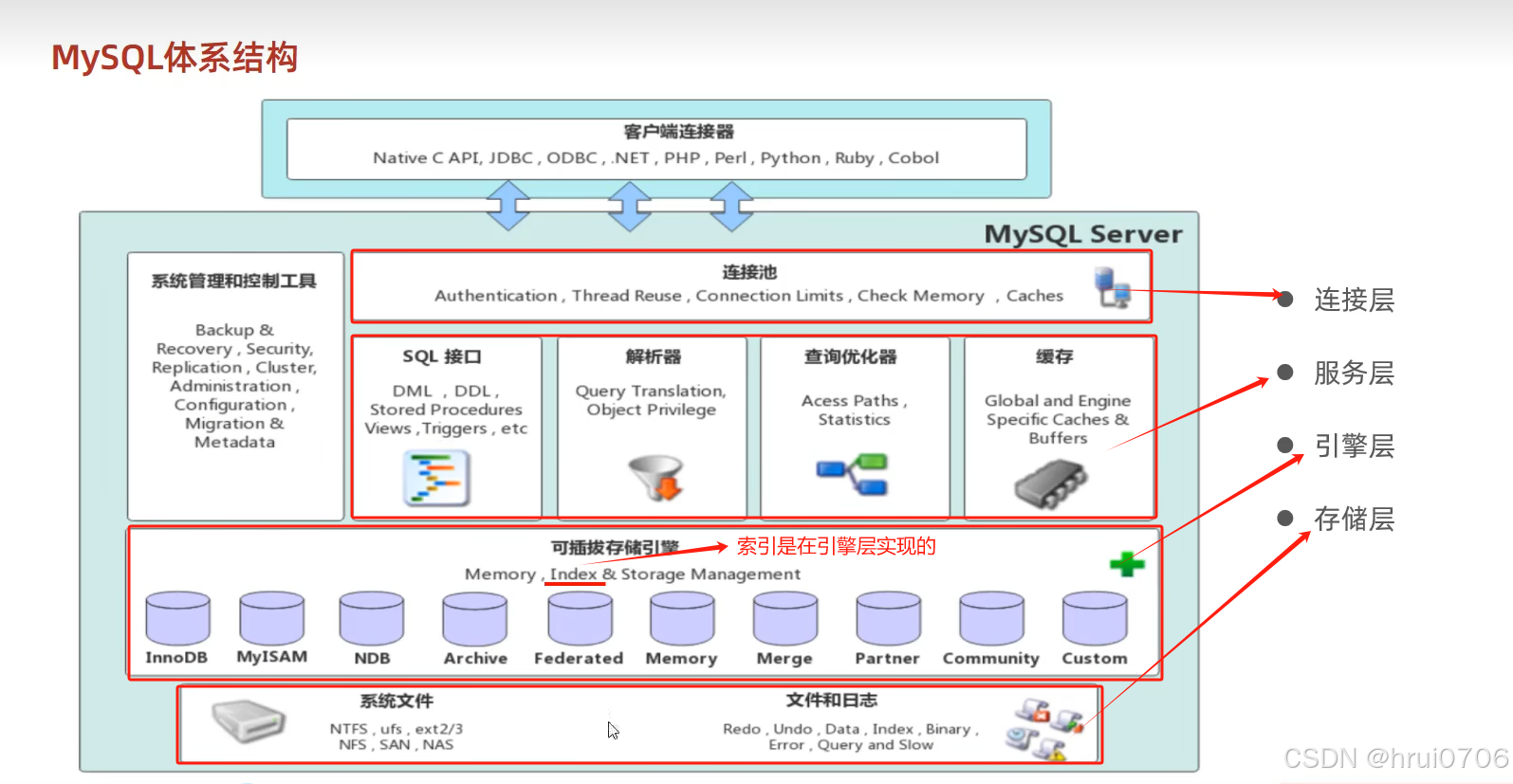
在Java(編程語言)中,"引擎"(Engine)就是某一類核心功能的實現模塊/組件,它封裝了復雜的底層邏輯,開發者只需要調用接口就能使用。
MySQL 的存儲引擎是數據庫內部用于管理表數據的核心模塊,負責實現數據的存儲、索引的建立與維護、數據的讀取、更新、刪除等底層功能。存儲引擎是基于表的,而不是基于庫的,所以存儲引擎也被稱表類型
就像 Java 引擎對外暴露接口供你使用一樣,MySQL 把數據管理的復雜邏輯封裝在“引擎”里,不同引擎有不同的能力,比如是否支持事務、是否支持全文索引等。
-
決定數據怎么存(數據結構、磁盤布局)
-
決定索引怎么建(B+ 樹、哈希等)
-
決定數據怎么讀寫(是否緩存、是否支持并發控制)
-
決定是否支持事務、外鍵、崩潰恢復等高級功能
在創建表時如果沒有顯式指定存儲引擎(ENGINE),MySQL 會使用系統設置的“默認引擎”,Mysql的默認引擎是InnoDB,并不是基于庫的
default_storage_engine 是 MySQL 中用于指定“默認存儲引擎”的系統變量。
當你創建一張表時沒有顯式寫 ENGINE=xxx,就會自動使用這個變量指定的存儲引擎。
查看默認引擎
SHOW VARIABLES LIKE 'default_storage_engine';
創建表時候指定存儲引擎
CREATE TABLE 表名 (
? ? 字段1 字段1類型 COMMENT '字段1注釋',
? ? 字段2 字段2類型 COMMENT '字段2注釋',
? ? ...
? ? 字段n 字段n類型 COMMENT '字段n注釋'
) ENGINE = INNODB COMMENT = '表注釋';
?
MySQL 內置已“注冊”的所有存儲引擎類型
SHOW ENGINES;?
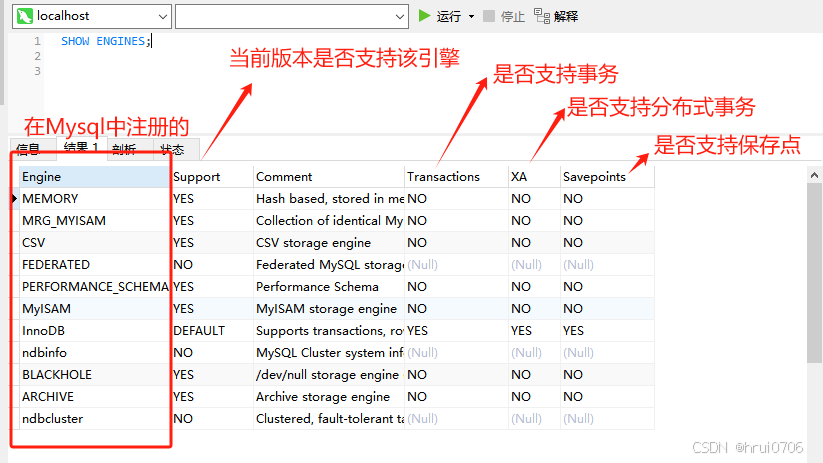
InnoDB,MyISAM,MEMORY三種引擎介紹
InnoDB介紹
Mysql5.5之后,InnoDB是默認的Mysql存儲引擎

InnoDB特點
DML操作遵循ACID模型,支持事務;
行級鎖,提高并發訪問性能
支持外鍵FOREIGN KEY約束,保證數據的完整性和正確性
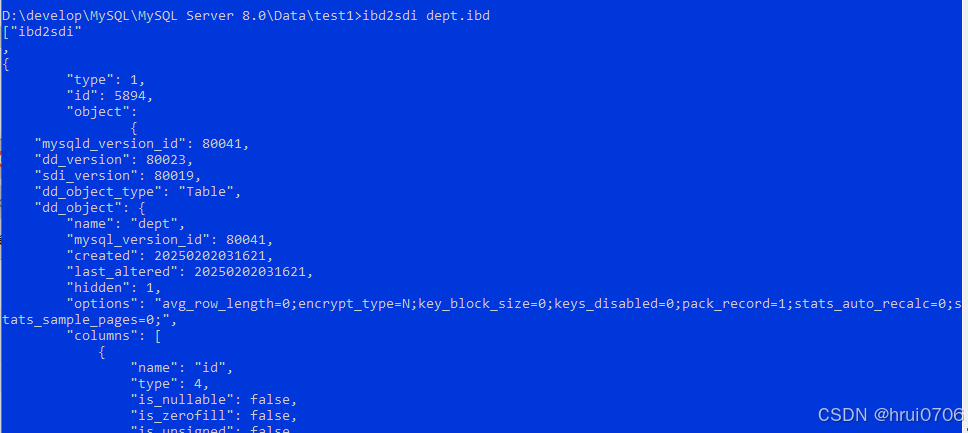
每張使用 InnoDB 存儲引擎的表,在磁盤上會有一個
.ibd文件,這個文件就是該表的**“獨立表空間”**,用來存儲表的:
結構(配合
.sdi?文件)數據
索引
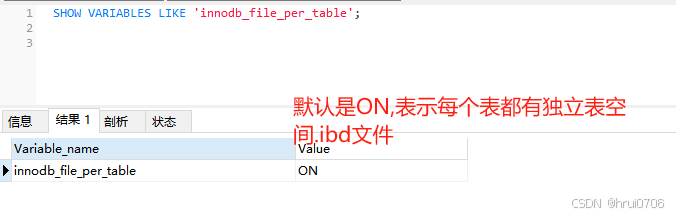
這個行為是由參數 innodb_file_per_table 控制的。
參數:innodb_file_per_table
SHOW VARIABLES LIKE 'innodb_file_per_table';

該文件是二進制的 普通記事本打開看不到啥
可以通過cmd命令
ibd2sdi emp.ibd? ? ? ? ? ? ? ? ? ? ?ibd2sdi是命令? ?emp.ibd是表空間? 好比表
我這里出現這個原因可能是文件損壞了? 因為安裝過不同版本的
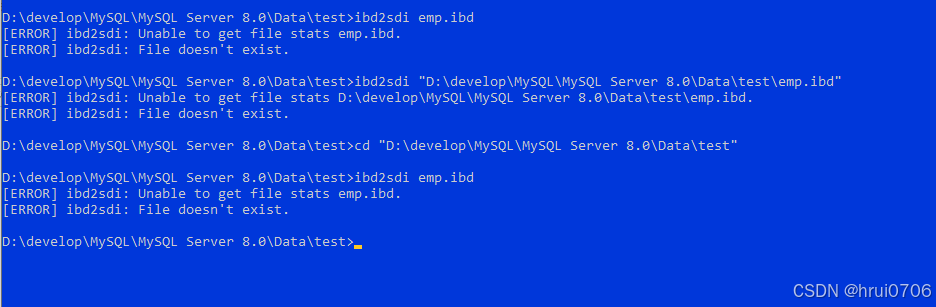

換了一個庫的表.ibd就好了

MyISAM介紹
MyISAM是Mysql早期的默認存儲引擎
特點
不支持事務,不支持外鍵
支持表鎖,不支持行鎖
訪問速度快(具體說和InnoDB比,看具體場景分析)
文件結構 .myd? ?.myi? ?.sdi
MEMORY介紹
Memory引擎的表數據存儲在內存中,受到硬件問題,或者斷電的影響,只能做為臨時或者緩存使用
特點
內存中存放
hash索引(默認)
文件? xxx.sdi存儲表結構信息無具體數據
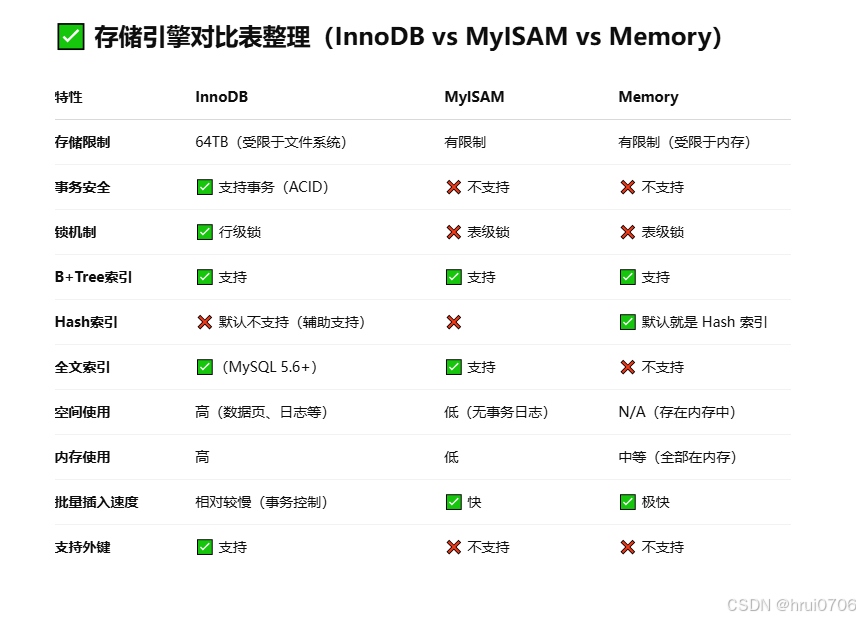

主要用的是InnoDB? ? MyISAM被MongoDB取代? ? MEMORY被Redis取代

Linux中Mysql安裝?
https://www.mysql.com/


mkdir /usr/local/develop
cd /usr/local/develop
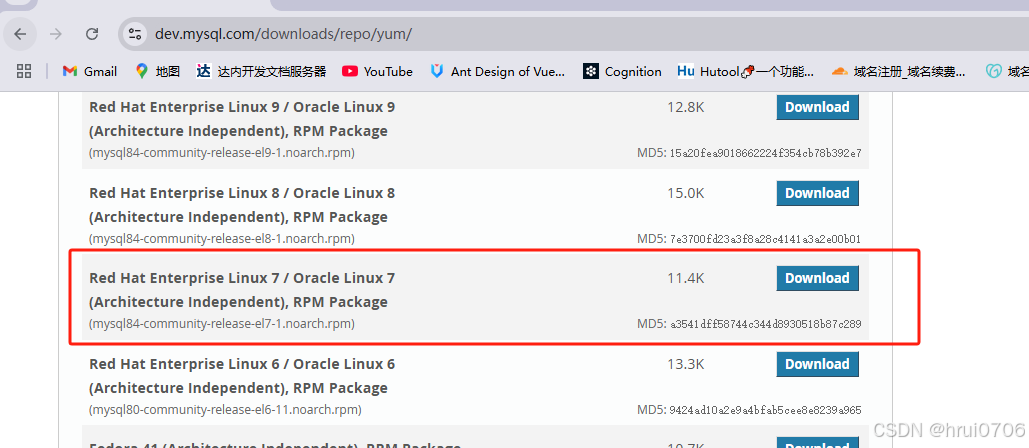
上傳到服務器
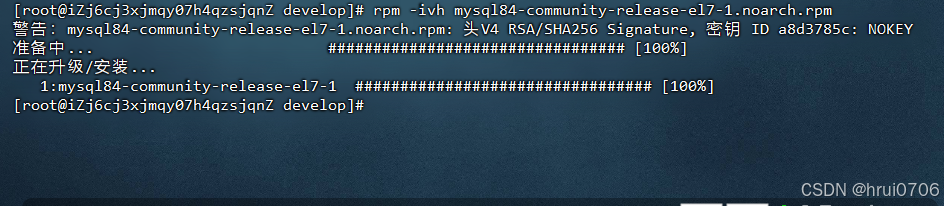
rpm -ivh mysql84-community-release-el7-1.noarch.rpm
yum install -y mysql-community-server
systemctl start mysqld
systemctl status mysqld
查看初始密碼
grep 'temporary password' /var/log/mysqld.log
mysql -u root -p
修改密碼
ALTER USER 'root'@'localhost' IDENTIFIED BY 'NewPassword123!';

use mysql;
select host,user from user;
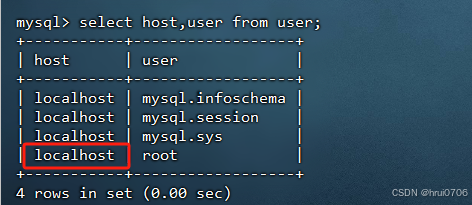
其實是建議再創建一個root? ?Mysql支持同一個用戶名有多個不同的登錄規則
在Mysql中? 用戶是通過 user@host的組合來做唯一標識的而不是單純看用戶名
我是直接Update了? 如果需要重新創建? 執行下面三跳命令
CREATE USER 'root'@'%' IDENTIFIED BY 'StrongPassword123!';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;這個好比刷新 好像不需要執行
UPDATE mysql.user SET host='%' WHERE user='root' AND host='localhost';
exit
vim /etc/my.cnf
bind-address = 0.0.0.0?
systemctl restart mysqld
安全組打開3306
其他安裝方式
你也可以下載整個RPM包
https://dev.mysql.com/downloads/mysql/
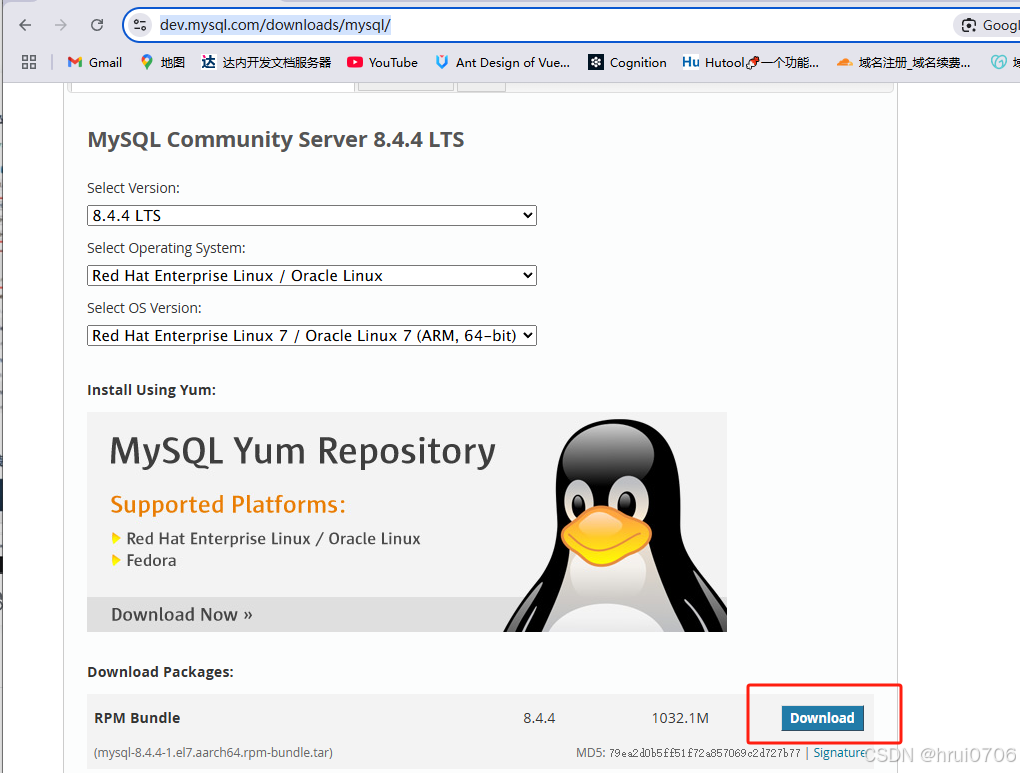
mkdir /usr/local/develop
cd /usr/local/develop
將下載的
mysql-8.4.4-1.el7.aarch64.rpm-bundle.tar? 上傳到服務器
tar -xzf?mysql-8.4.4-1.el7.aarch64.rpm-bundle.tar
這種方式沒有試驗? 使用的是上面的? ?解壓之后? 安裝是有順序的? 大致如下
安裝順序

systemctl start mysqld
systemctl restart mysqld
systemctl stop mysqld
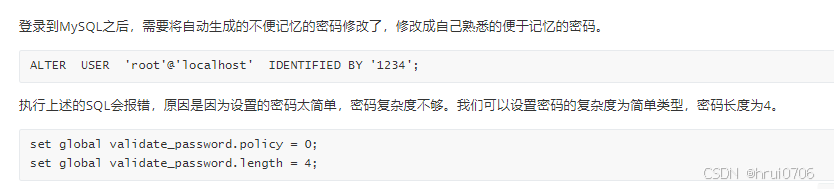
啟動之后? 查詢密碼
grep 'temporary password' /var/log/mysqld.log
mysql -u root -p
ALTER ?USER ?'root'@'localhost' ?IDENTIFIED BY '1234';
如果需要的話
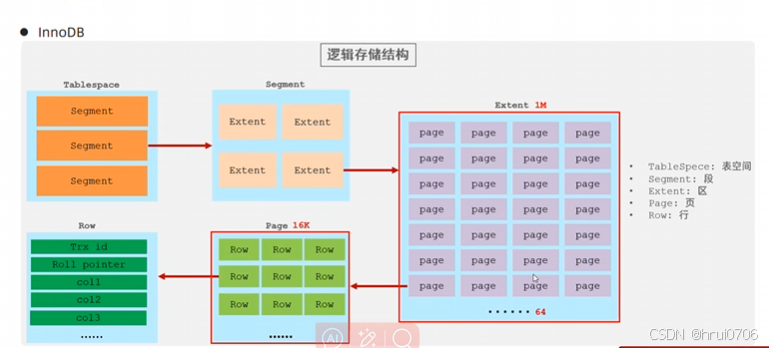
索引
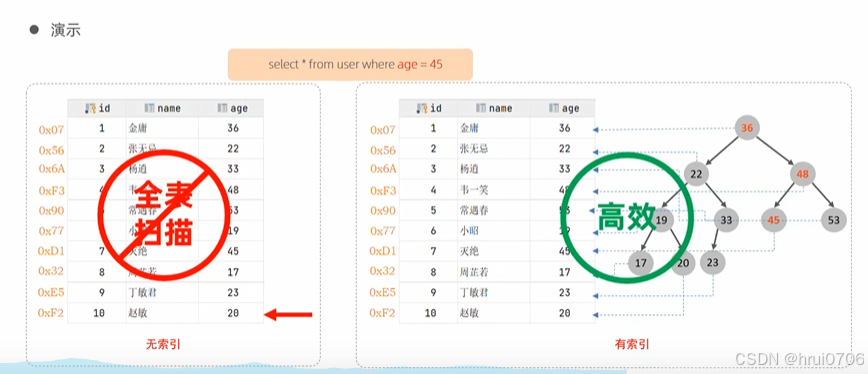
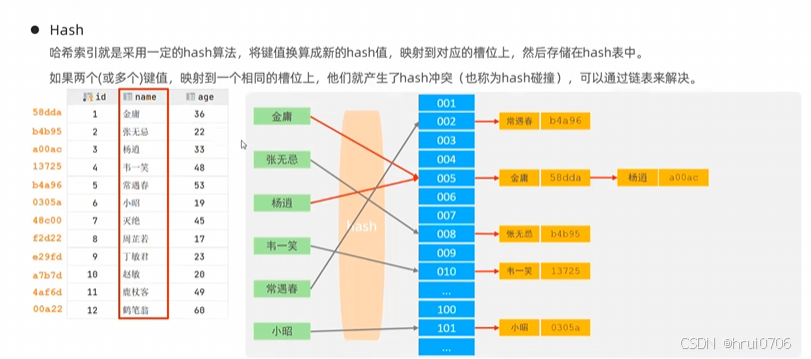
索引是 MySQL 中用于提高數據查詢效率的數據結構,它類似于書的目錄或字典的檢索頁,通過有序的數據結構,快速定位到目標數據。
什么是索引:索引是用于提高數據查詢效率有序的數據結構
沒有索引的查詢是全表查詢:每條數據都需要查一遍
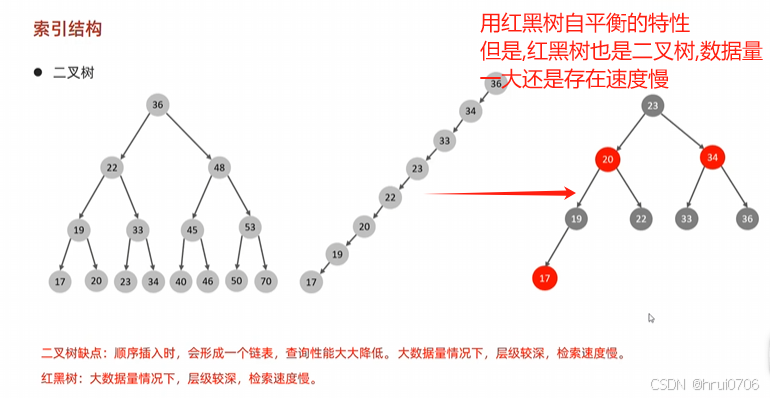
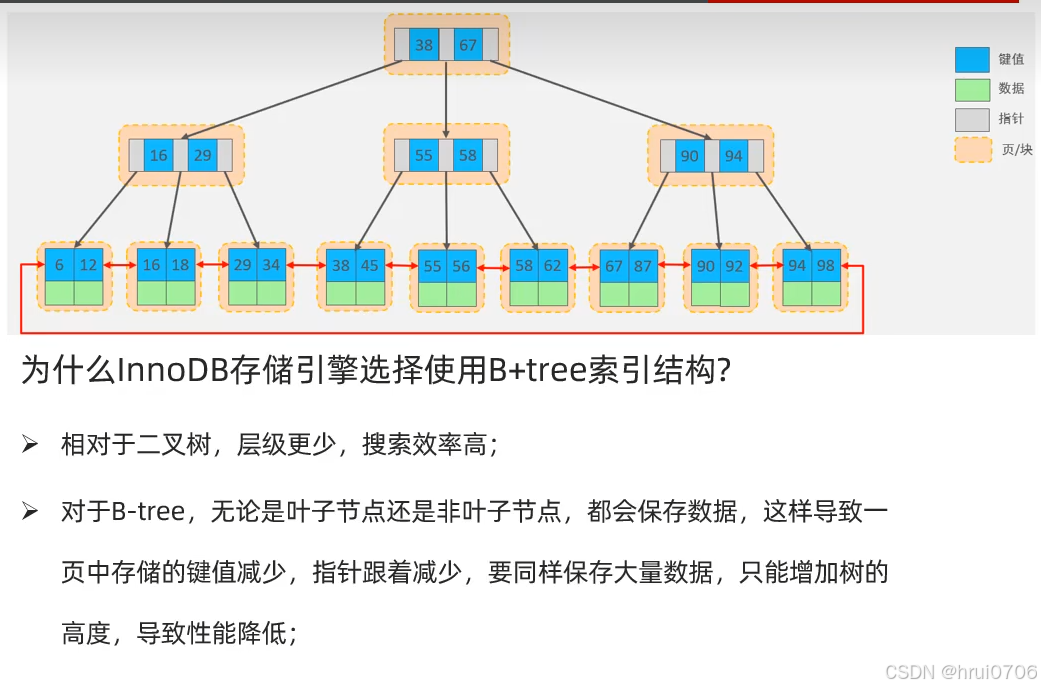
MySQL 的索引數據結構不是二叉樹,而是多路搜索樹——最常見的是 B+ 樹。
以二叉樹為例子介紹索引? 注意 二叉樹不是索引數據結構? 就是說為什么快了

索引的好處是提高了查詢,因索引需要維護,降低了增刪改的效率
索引的好處是:提高查詢效率
索引的代價是:增刪改操作時要維護索引結構,導致效率下降
索引數據結構
Mysql的索引實在存儲引擎層實現的,不同的存儲引擎有不同的結構,主要包含以下幾種


我們平常所說的索引,如果沒有特別指明,都是指B+樹結構的索引
注意二叉樹不是索引的數據結構? 下圖講的是為什么二叉樹不作為索引數據結構的原因
紅黑樹面對大數據時候還是無法避免層級較深,導致檢索速度慢
B-TREE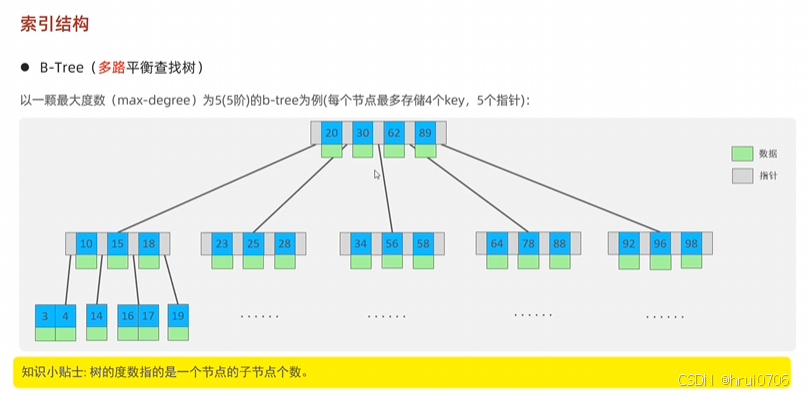
B+TREE?


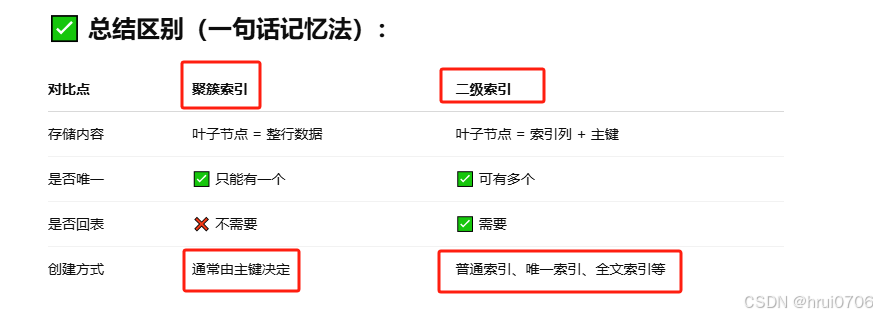
索引的分類?

總結一句話: 主鍵索引一張表只能有一個? 其他索引都可以有多個
MySQL 索引分為:主鍵索引(唯一 + 非空)、唯一索引(值不能重復)、普通索引(僅加速查詢)、全文索引(文本匹配)。使用時根據數據特征和查詢需求選擇合適的類型。


 ?
?
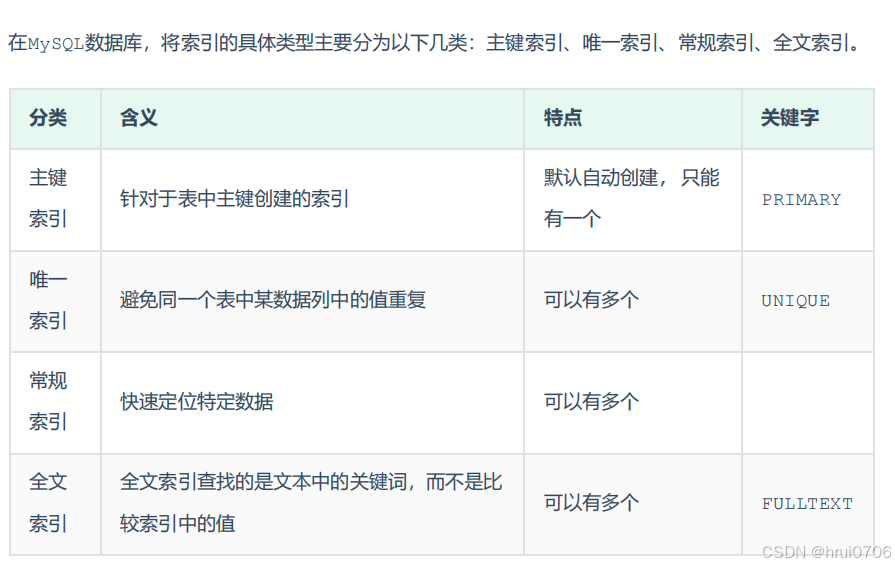
創建索引
索引語法
CREATE [UNIQUE FULLTEXT] INDEX index_name ON table_name(列1,列2);
1.主鍵索引(PRIMARY KEY)
每個表只能有一個主鍵索引
主鍵值不能重復,不能為NULL(非空且唯一),實際是一個特殊的唯一索引
2.唯一索引(UNIQUE)
保證某一列或多列的值唯一
可以有多個唯一索引,允許NULL值(但只能有一個NULL)
CREATE UNIQUE INDEX inx_email ON users(email);
或者建表時
CREATE TABLE users (?
? ? id INT PRIMARY KEY,
? ? email VARCHAR(100) UNIQUE,
? ? username VARCHAR(100) UNIQUE
);
CREATE TABLE tasks (
? ? user_id INT,
? ? project_id INT,
? ? task_name VARCHAR(100),
? ? UNIQUE KEY uniq_user_project (user_id, project_id)
);?
3.普通索引
即B-TREE索引
普通索引,沒有唯一性限制,用于提高查詢速度
CREATE INDEX inx_name ON users(name);??
普通索引(非唯一索引)是可以為 NULL 的!
4.復合索引
包含多個列的索引
只有查詢條件命中從最左邊開始的一段,才能用到索引
CREATE INDEX inx_name_age ON users(name,age);
5.全文索引(FULLTEXT)
用于全文搜索,主要針對CHAR VARCHAR TEXT
CREATE FULLTEXT INDEX idx_content ON articles(content)
MyISAM 和 InnoDB 引擎都支持 FULLTEXT(MySQL 5.6 及以上 InnoDB 開始支持)。
6.空間索引
用于地理空間數據(如點,多邊形),依賴GIS
必須在使用MyISAM引擎時有效
CREATE SPATIAL INDEX idx_location ON places(location);
MySQL 復合索引的使用原則 —— 特別是 最左前綴原則
例如創建了 復合索引或者多列聯合唯一索引
例如 A列? B列? C列? ?D列
A? B? C是有索引的
只要查詢條件中有A? 都會使用到索引? ?即使查詢條件中有D
查看索引
SHOW INDEX FROM table_name
刪除索引
DROP INDEX index_name ON table_name;
注意:

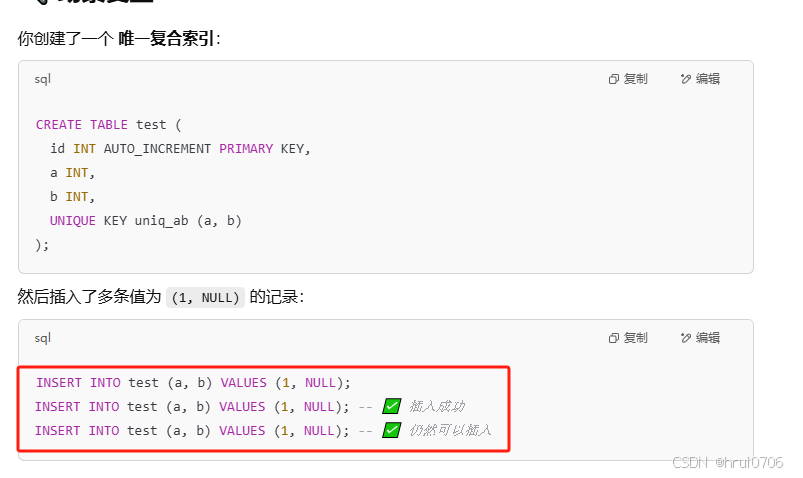
練習
CREATE TABLE tb_user (
?? ?id INT PRIMARY KEY auto_increment COMMENT '主鍵',
?? ?NAME VARCHAR ( 50 ) NOT NULL COMMENT '用戶名',
?? ?phone VARCHAR ( 11 ) NOT NULL COMMENT '手機號',
?? ?email VARCHAR ( 100 ) COMMENT '郵箱',
?? ?profession VARCHAR ( 11 ) COMMENT '專業',
?? ?age TINYINT UNSIGNED COMMENT '年齡',
?? ?gender CHAR ( 1 ) COMMENT '性別 , 1: 男, 2: 女',
?? ?STATUS CHAR ( 1 ) COMMENT '狀態',
createtime datetime COMMENT '創建時間'?
) COMMENT '系統用戶表';INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('呂布', '17799990000', 'lvbu666@163.com', '軟件工程', 23, '1',
'6', '2001-02-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('曹操', '17799990001', 'caocao666@qq.com', '通訊工程', 33,
'1', '0', '2001-03-05 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('趙云', '17799990002', '17799990@139.com', '英語', 34, '1',
'2', '2002-03-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('孫悟空', '17799990003', '17799990@sina.com', '工程造價', 54,
'1', '0', '2001-07-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('花木蘭', '17799990004', '19980729@sina.com', '軟件工程', 23,
'2', '1', '2001-04-22 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('大喬', '17799990005', 'daqiao666@sina.com', '舞蹈', 22, '2',
'0', '2001-02-07 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('露娜', '17799990006', 'luna_love@sina.com', '應用數學', 24,
'2', '0', '2001-02-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('程咬金', '17799990007', 'chengyaojin@163.com', '化工', 38,
'1', '5', '2001-05-23 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('項羽', '17799990008', 'xiaoyu666@qq.com', '金屬材料', 43,
'1', '0', '2001-09-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('白起', '17799990009', 'baiqi666@sina.com', '機械工程及其自動
化', 27, '1', '2', '2001-08-16 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('韓信', '17799990010', 'hanxin520@163.com', '無機非金屬材料工
程', 27, '1', '0', '2001-06-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('荊軻', '17799990011', 'jingke123@163.com', '會計', 29, '1',
'0', '2001-05-11 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('蘭陵王', '17799990012', 'lanlinwang666@126.com', '工程造價',
44, '1', '1', '2001-04-09 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('狂鐵', '17799990013', 'kuangtie@sina.com', '應用數學', 43,
'1', '2', '2001-04-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('貂蟬', '17799990014', '84958948374@qq.com', '軟件工程', 40,
'2', '3', '2001-02-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('妲己', '17799990015', '2783238293@qq.com', '軟件工程', 31,
'2', '0', '2001-01-30 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('羋月', '17799990016', 'xiaomin2001@sina.com', '工業經濟', 35,
'2', '0', '2000-05-03 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('嬴政', '17799990017', '8839434342@qq.com', '化工', 38, '1',
'1', '2001-08-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('狄仁杰', '17799990018', 'jujiamlm8166@163.com', '國際貿易',
30, '1', '0', '2007-03-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('安琪拉', '17799990019', 'jdodm1h@126.com', '城市規劃', 51,
'2', '0', '2001-08-15 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('典韋', '17799990020', 'ycaunanjian@163.com', '城市規劃', 52,
'1', '2', '2000-04-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('廉頗', '17799990021', 'lianpo321@126.com', '土木工程', 19,
'1', '3', '2002-07-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('后羿', '17799990022', 'altycj2000@139.com', '城市園林', 20,
'1', '0', '2002-03-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,
createtime) VALUES ('姜子牙', '17799990023', '37483844@qq.com', '工程造價', 29,
'1', '4', '2003-05-26 00:00:00');
1.name字段為姓名字段,該字段的值可能會重復,為該字段創建索引
CREATE INDEX inx_user_name ON tb_user(name);
2.phone手機號字段的值,是非空,且唯一的,為該字段創建唯一索引
CREATE UNIQUE INDEX inx_user_phone ON tb_user(phone);
3.為profession,age,status創建聯合索引
CREATE INDEX inx_user_pro_age_sta ON tb_user(profession,age,status);
4.為email建立合適的索引來提升查詢效率
CREATE INDEX inx_user_email ON tb_user(email);
SQL性能分析(SQL優化)
SQL執行頻率
SHOW [SESSION|GLOBAL] STATUS查看服務狀態信息
SHOW SESSION STATUS
SHOW GLOBAL STATUS
SHOW GLOBAL STATUS LIKE 'Com_______';
SHOW GLOBAL STATUS LIKE 'Com_select'
慢查詢日志
慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句的日志
Mysql的慢查詢日志默認沒有開啟,需要在Mysql的配置文件(/etc/my.cnf)中配置

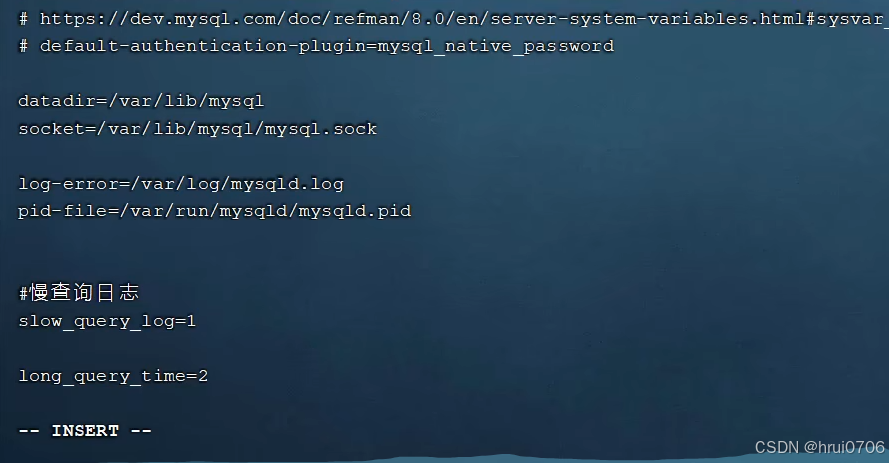
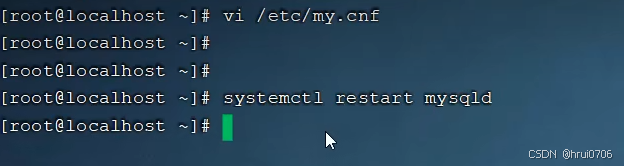
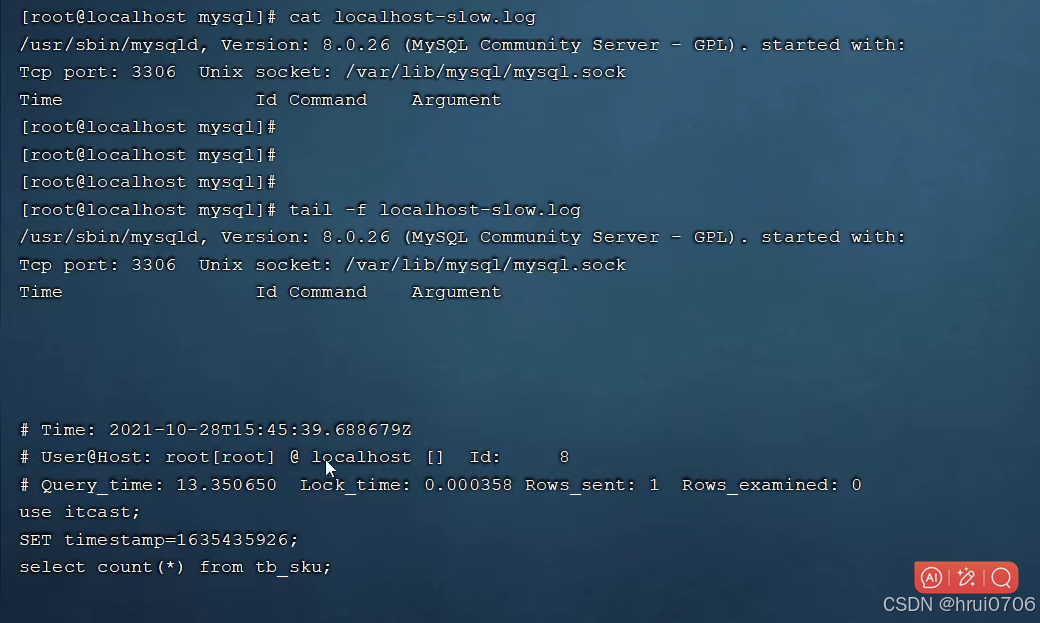
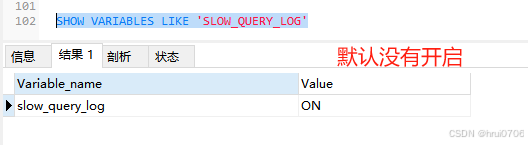
SHOW VARIABLES LIKE 'SLOW_QUERY_LOG'
這里用的是阿里云RDS? 默認是開啟的
沒有開啟是OFF
開啟Profile詳情
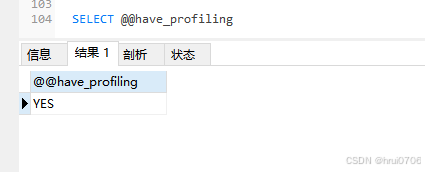
show profiles能夠在做SQL優化時幫助我們了解時間都耗費到哪里了.通過have_profiling參數,可以查看當前Mysql是否支持profile操作
SELECT @@have_profiling
以下是阿里云RDS配置? 默認是關閉的
SELECT @@profiling
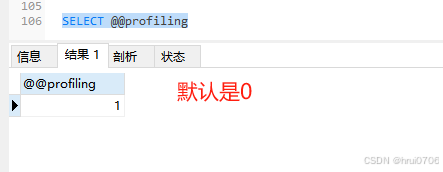
可以通過SET? 開啟profiling
SET profiling=1
開啟profile詳情之后
通過指令可以查看執行耗時情況
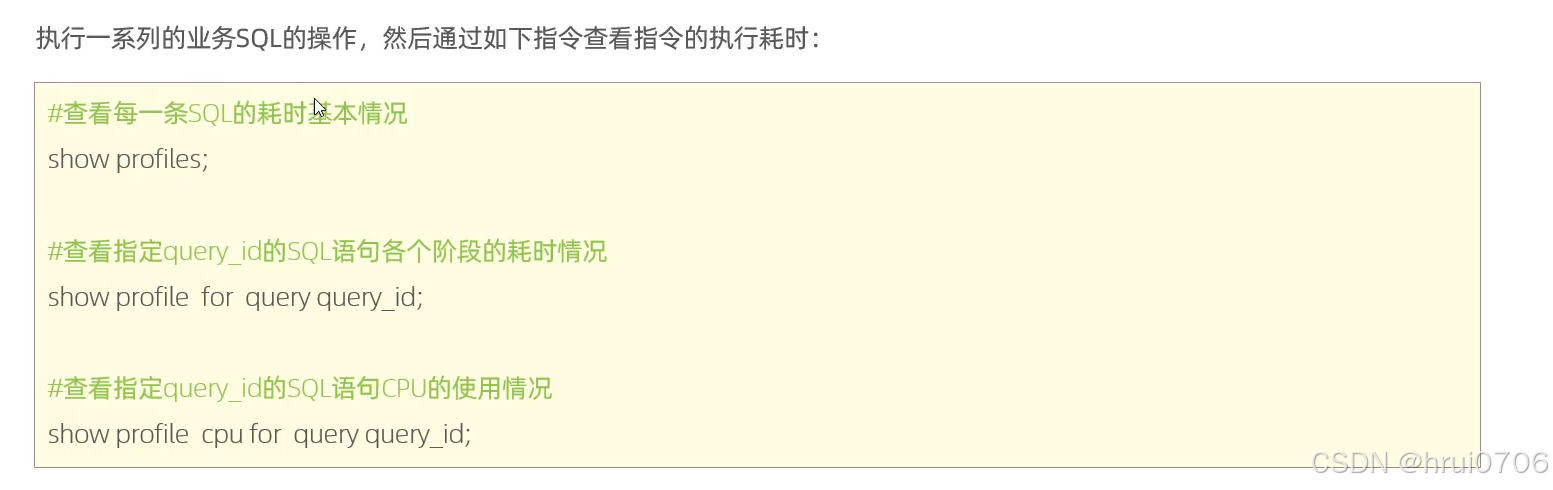
開啟profile之后,當你執行SQL操作? 通過
SHOW profiles查看執行情況
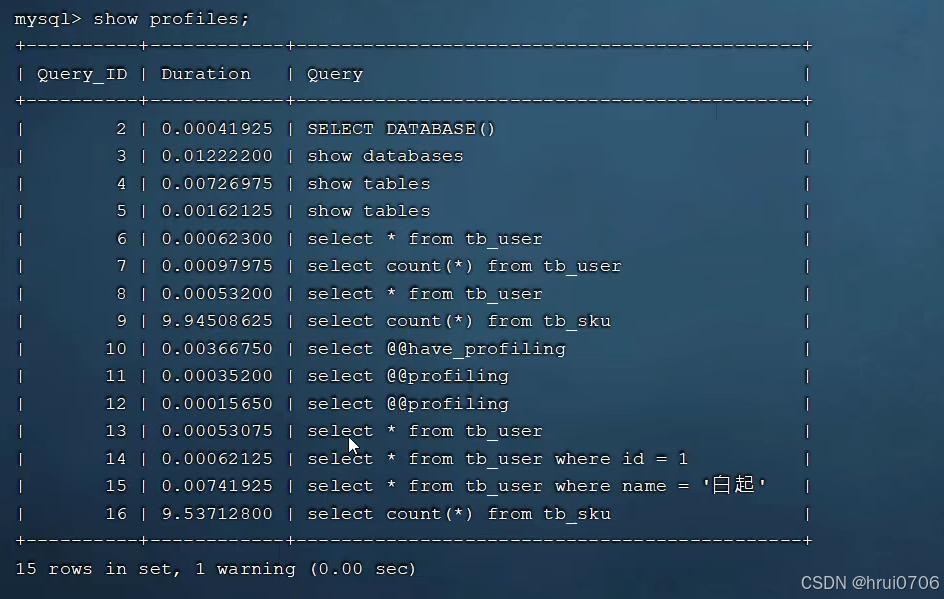
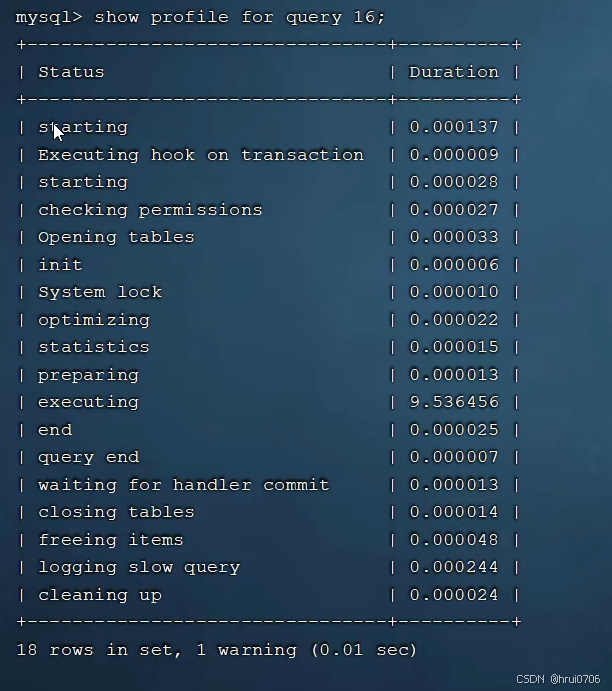
SHOW profile for query 16;? 查看指定sql各階段耗時情況
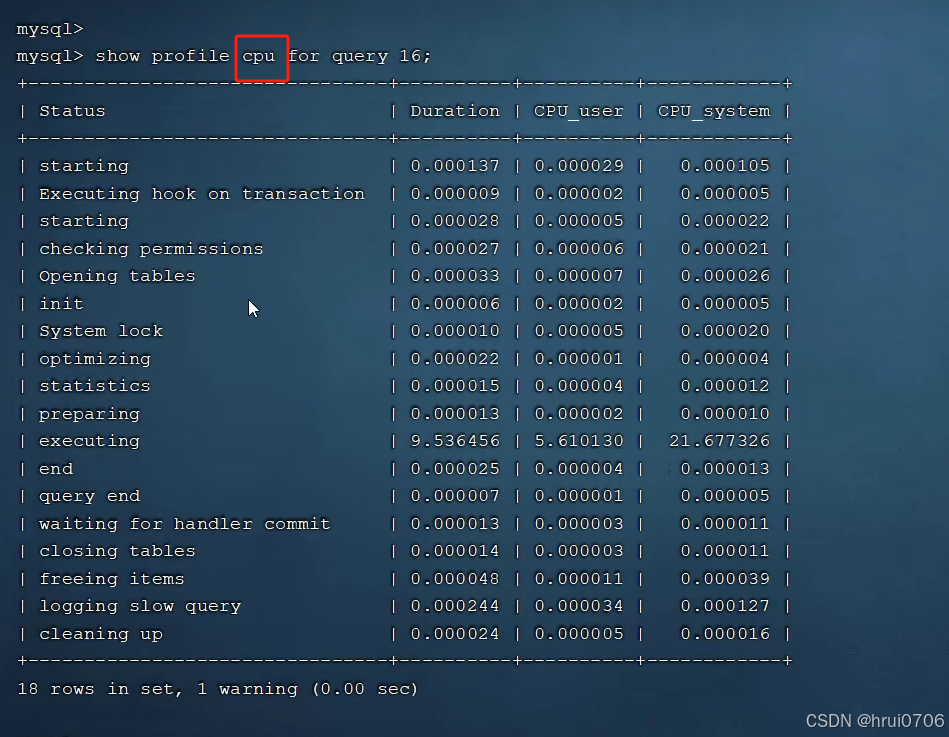
Explain執行計劃
開啟profile可以看到SQL的執行時間,但是單純看到執行時間還是不能精確定位分析SQL的優化
explain執行計劃可以看到包括SELECT語句執行過程,例如如果連接和連接順序,是否用到索引
通過EXPLAIN或者DESC命令獲取Mysql如何執行SELECT語句信息
直接在SELECT語句之前加上關鍵字expain/desc
EXPLAN SELECT 字段列表 FROM 表名 WHERE 條件;

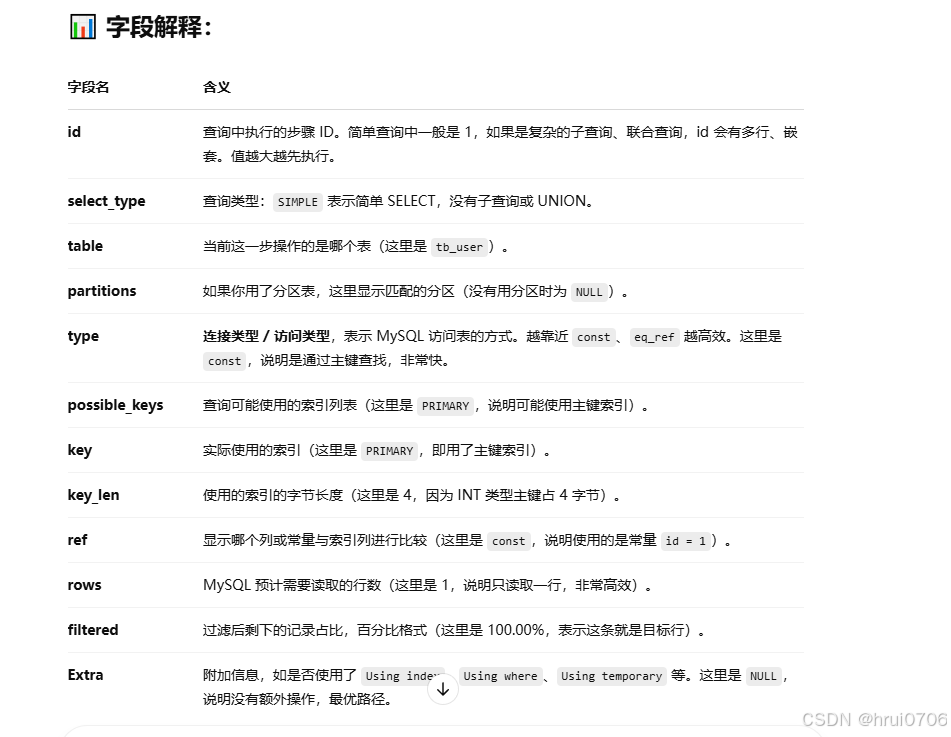
索引使用與失效
SELECT * FROM tb_sku WHERE sn = '10000003145004';
如果一張表的數據量很大 那么可以對sn創建索引
SELECT * FROM tb_sku WHERE sn = '10000003145004' AND other_field = 'xxx';
只要
sn是查詢條件的一部分,MySQL 仍然會使用sn的索引來過濾第一步的結果集。
然后,它會在命中的 sn 結果基礎上,繼續判斷其他字段(如 other_field)的條件是否滿足。
最左前綴法則
如果索引了多列(聯合索引),要遵守最左前綴法則,最左前綴法則指的是查詢從索引的最左列開始,并且不跳過索引中的列.如果跳躍某一列,索引將部分失效(后面的字段索引失效)
例如A列? B列? C列? D列? ?ABC是復合索引? D沒有索引
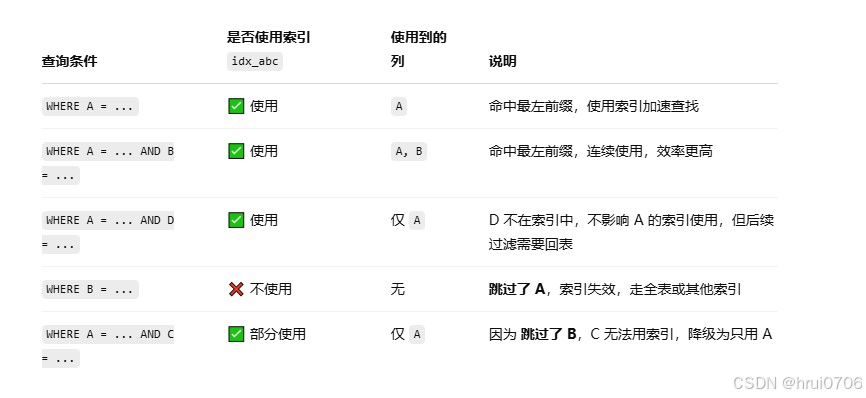
注意只要WHERE條件中存在? ?和位置在前或者在后沒關系
范圍查詢
聯合索引中,出現范圍查詢,范圍查詢,右側的列索引將失效

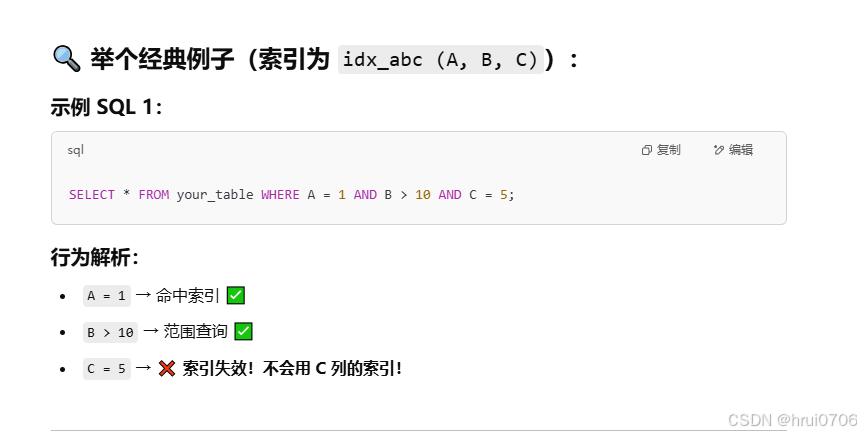
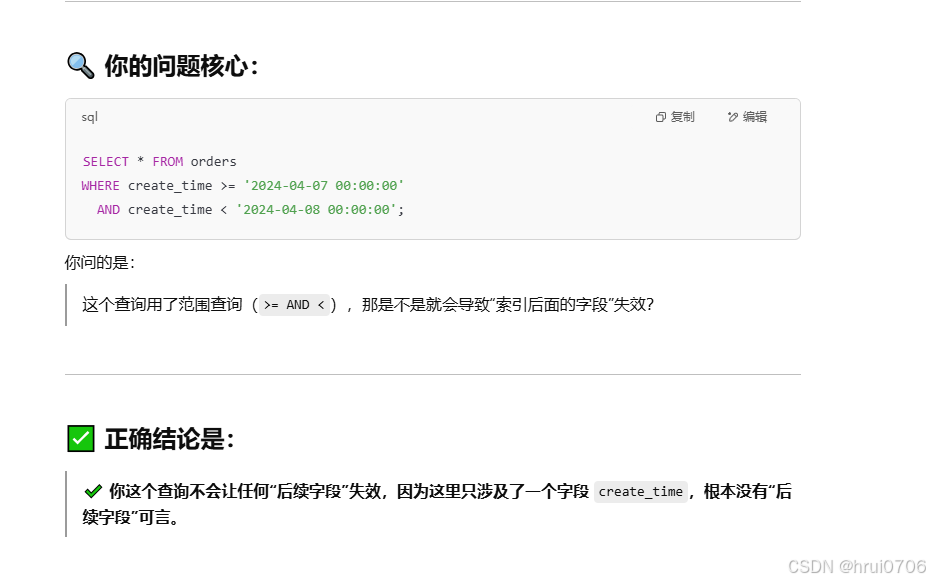
索引列運算
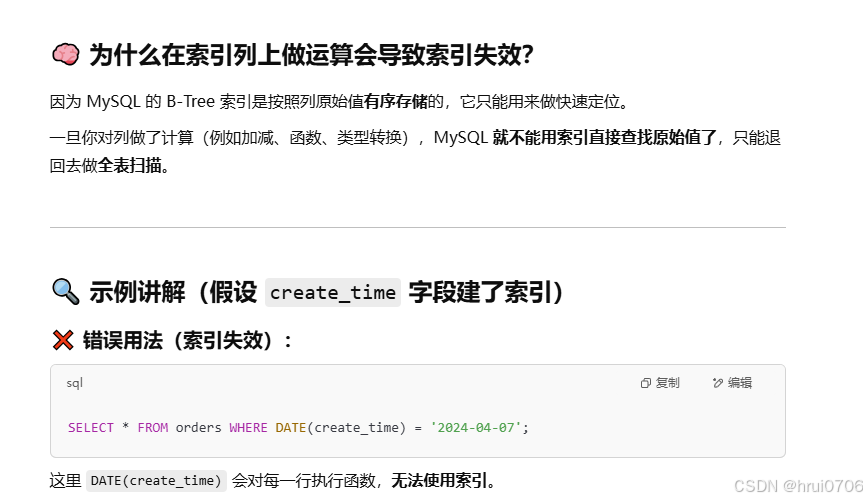
不要在索引列上進行運算操作,否則索引將失效
字符串不加引號?
字符串類型字段使用時,不加引號,索引將失效
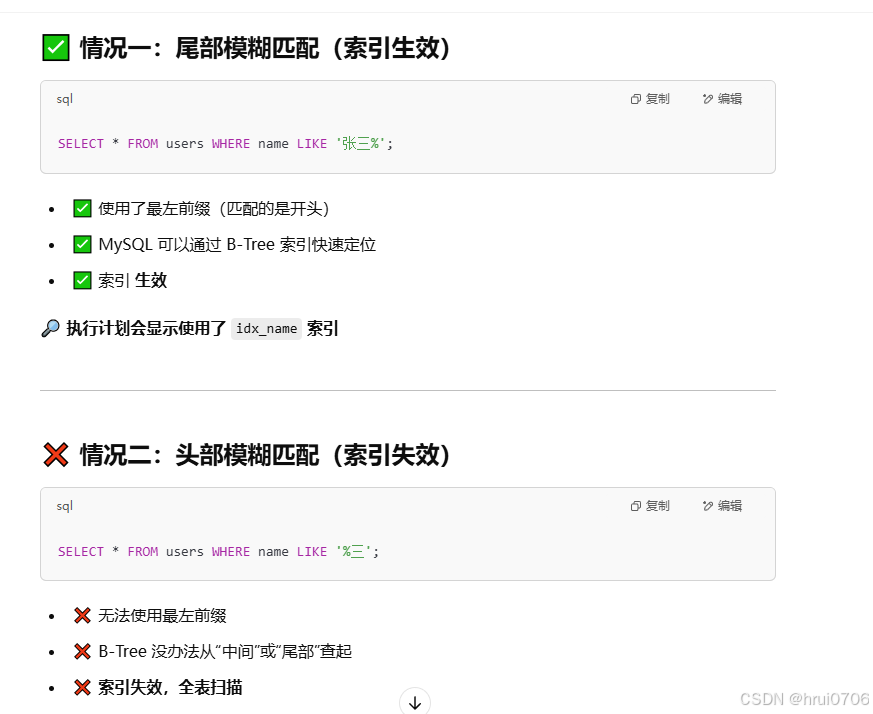
模糊查詢
如果僅僅是尾部模糊匹配,索引不會失效.如果是頭部模糊匹配,索引失效

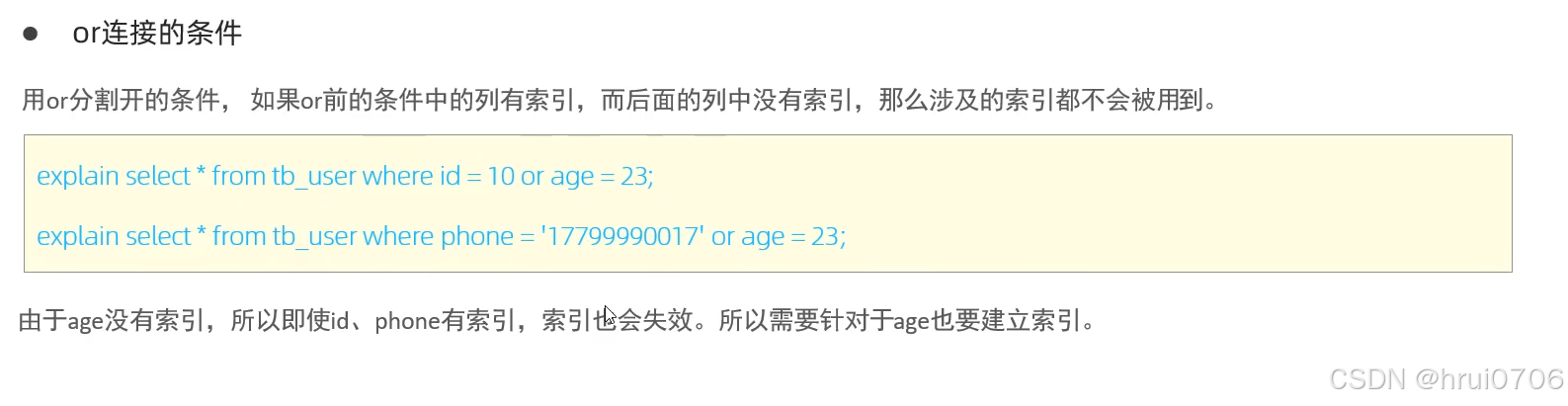
OR連接條件?
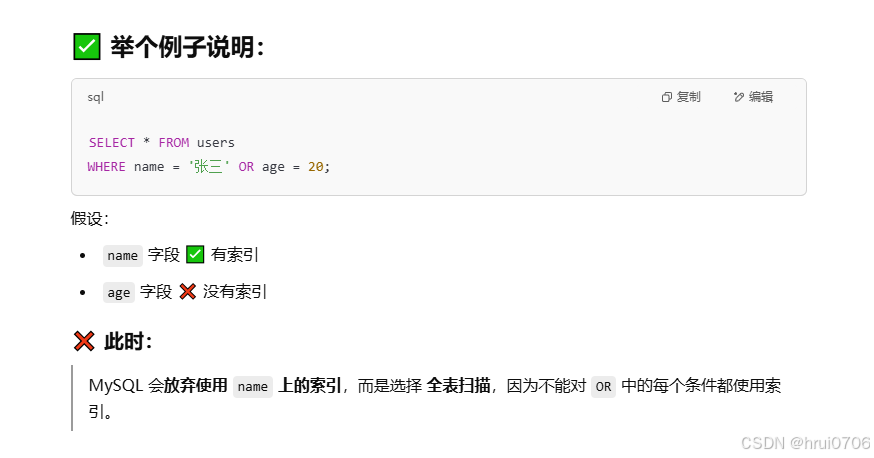
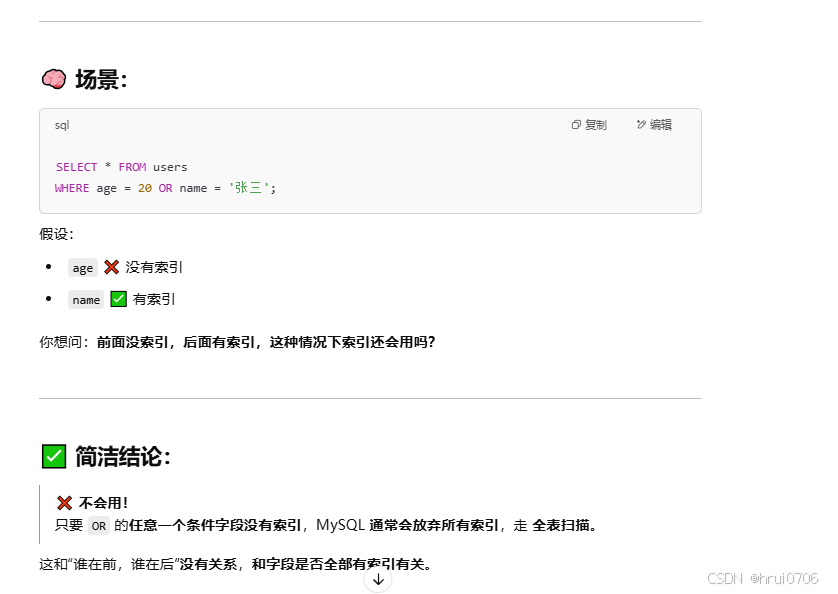
用OR分割開的條件,如果OR前的條件中的列有索引,而后面的列中沒有索引,那么涉及的索引都不會被用到
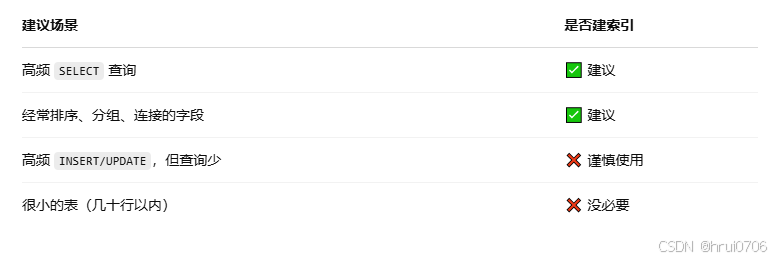
索引使用原則
數據分布影響:如果Mysql評估使用索引比全表掃描慢,則不適用索引

當大部分需要查的時候也可能會走全表掃描
當查詢的數據量占表中“大部分”時,MySQL 很可能放棄使用索引,選擇🔁全表掃描,因為它認為這樣反而更快!? ? 注意是可能
由查詢優化器決定
主要由 MySQL 查詢優化器(Query Optimizer) 根據多個因素動態評估查詢成本,決定是否使用索引。
索引的選擇(SQL提示)
當你創建了聯合索引, 例如 A? B? C 三個字段? ? ?而又對A也創建了一個索引
當你用A字段進行查詢時候
Mysql查詢優化器會動態選擇用哪一個索引
我們也可以指定使用哪個索引,稱為SQL提示
簡單來說,就是SQL語句中加入一些認為的提示來達到優化操作的目的
SQL提示
1.USE INDEX 告訴Mysql用哪個索引
例如:
SELECT * FROM tb_user USE INDEX(inx_use_pro) WHERE profession='軟件工程';
2.IGNORE INDEX? 告訴Mysql不要用哪個索引
SELECT * FROM tb_user IGNORE INDEX(inx_use_pro) WHERE profession='軟件工程';
3.FORCE INDEX 告訴Mysql必須用這個索引
SELECT * FROM tb_user FORCE INDEX(inx_use_pro) WHERE profession='軟件工程';
覆蓋索引
盡量使用覆蓋索引(查詢使用了索引,并且需要返回的列,在該索引中已經全部能夠找到),減少SELECT *
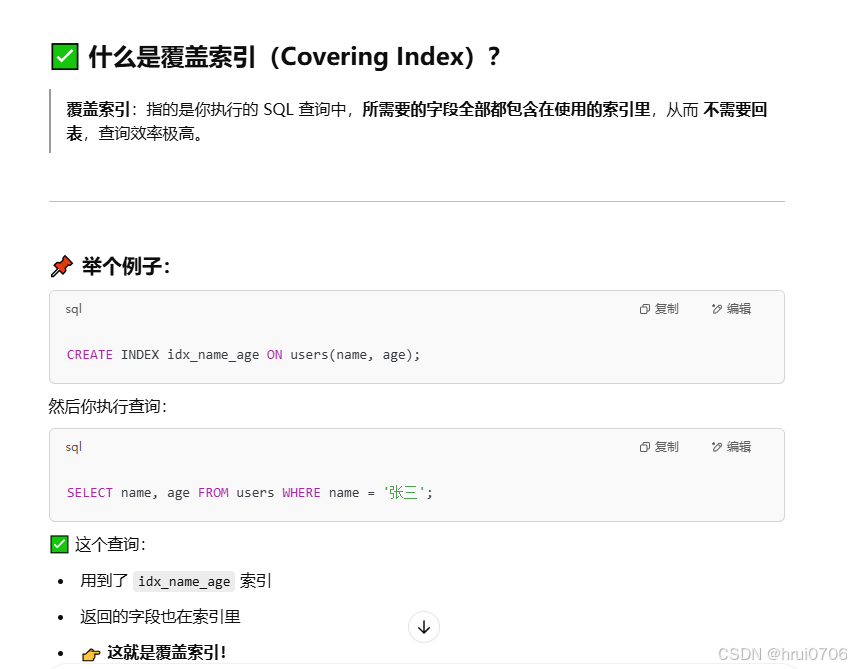

查詢條件是索引并且返回的字段也是索引就是覆蓋索引,使用SELECT * 容易出現回表查詢 除非所有字段都創建了索引
前綴索引
當字段類型為字符串(VARCHAR,TEXT等)時,有時候需要索引很長的字符串.會使索引變得很大,影響查詢效率.可以將字符串的一部分前綴,建立索引,可以節約索引空間.提高索引效率
前綴索引:指的是 只對字符串字段的前 N 個字符建立索引,而不是整列。
創建前綴索引
CREATE INDEX inx_table_xxx ON table_name(CLOLUMN(n))
例如
CREATE INDEX idx_email_prefix ON users(email(10));
單例索引和聯合索引的選擇
單例索引:即一個索引只包含單個列
聯合索引:即一個索引包含多個列
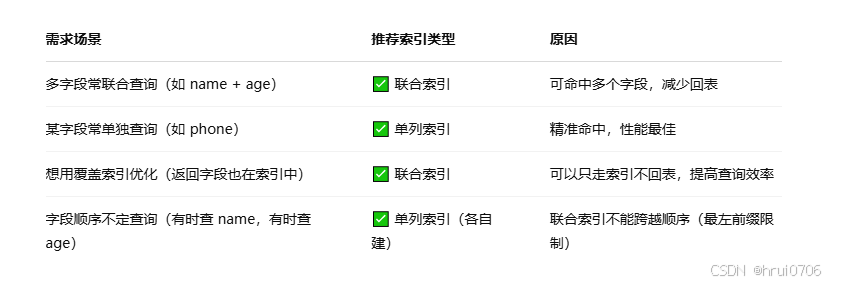
索引設計原則

SQL優化
創建索引可以當作查詢數據的優化,以下介紹其他操作的優化
插入數據優化
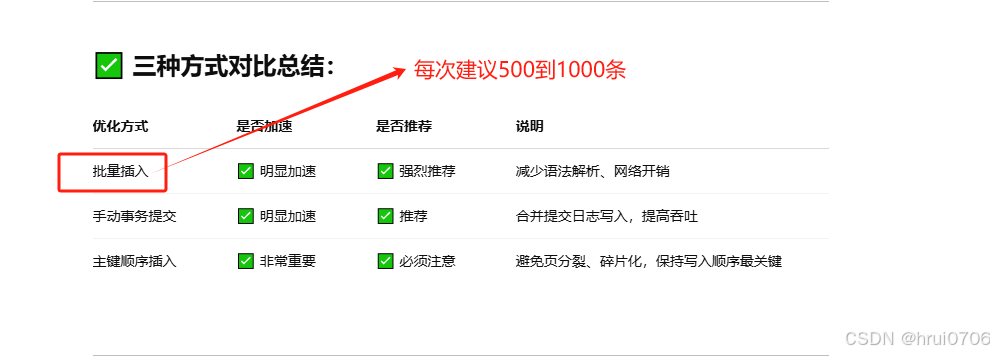
?在已經有sql腳本的情況下? 可以使用load命令

主鍵優化
主鍵順序插入的性能高于主鍵亂序插入----------->即為主鍵優化
order by優化


group by優化

limit優化
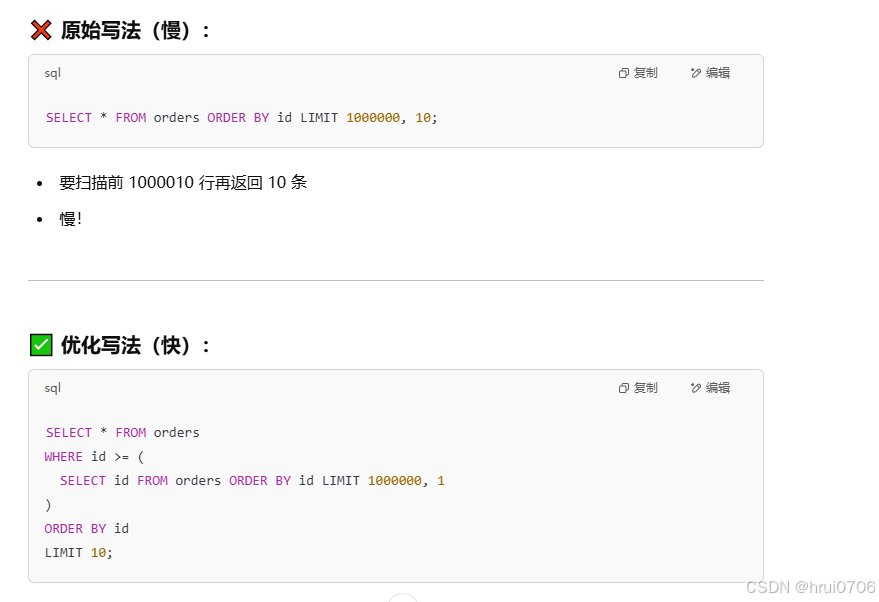
LIMIT查詢時候問題出在哪里
SELECT * FROM tb_user LIMIT 0,10;
SELECT * FROM tb_user LIMIT 1000000000,10;? 越往后查詢越慢
一個非常常見且代價昂貴的問題是使用 LIMIT 2000000, 10,這會導致 MySQL 必須掃描并排序 前 2000010 條記錄,然后丟棄前 2000000 條,僅返回后 10 條。因此,隨著 offset 越大,查詢性能會指數級下降,排序和掃描成本非常高。
通過覆蓋索引加子查詢來提高效率
count優化
當數據量大的時候? 使用InnoDB? COUNT(*)查詢是比較耗時的
暫時沒有好的優化,如果非要優化,自己計數
例如使用Redis等內存級別數據庫? 每插入一條數據就+1? ? 刪除一條數據-1? ? 比較繁瑣
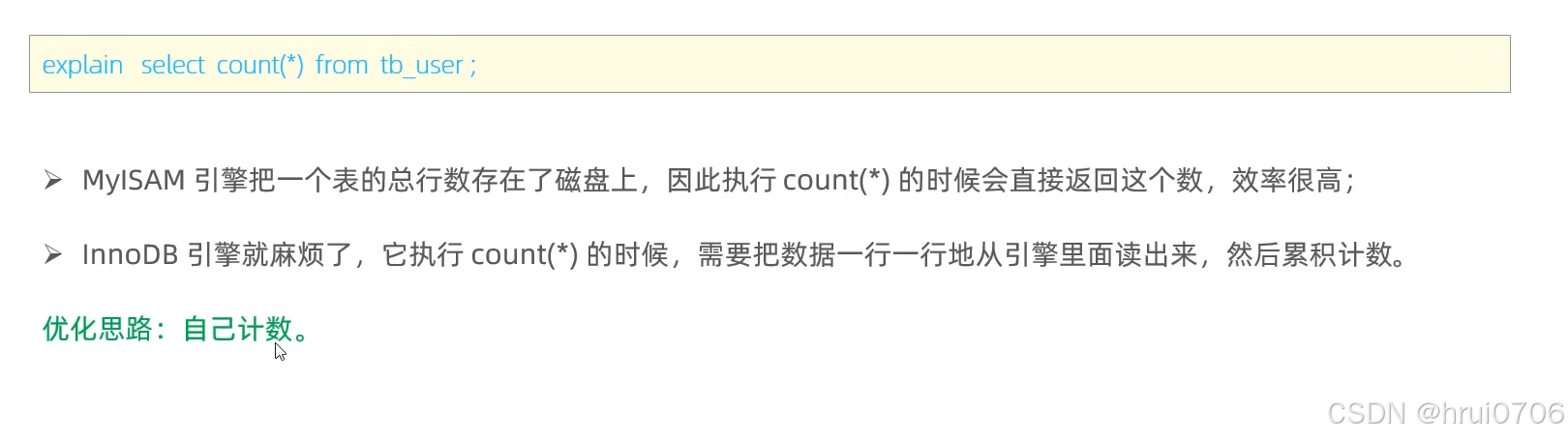
COUNT(*)效率最高 可以說約等于 COUNT(1)>COUNT(主鍵ID)>COUNT(其他字段)

update優化
INnoDB? ?三特性? ?事務? ?外鍵? ? 行級鎖
就是說更新時候通過索引更新效率高
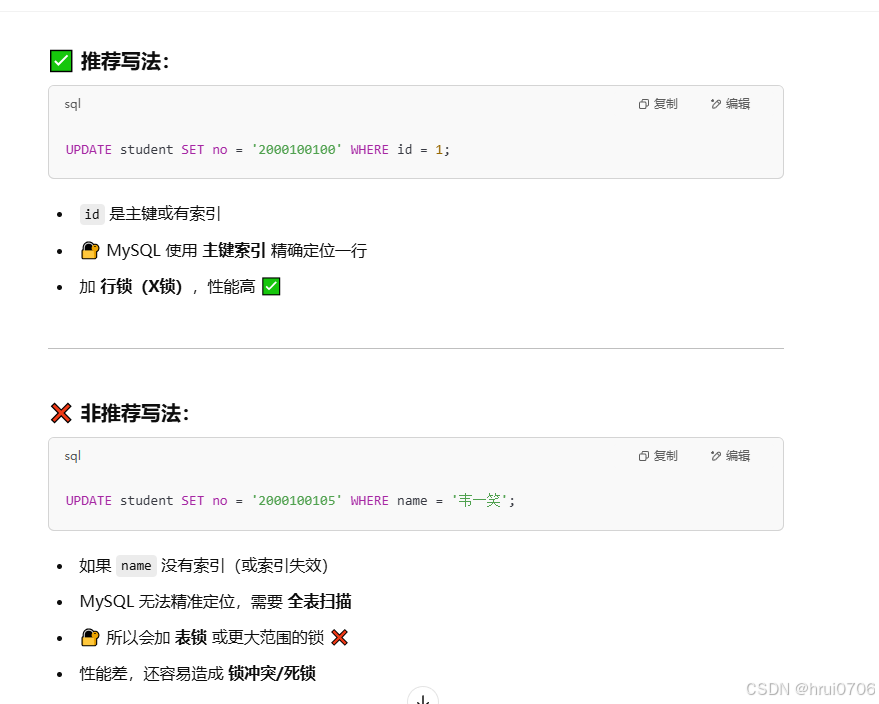
?不是“一定”加表鎖,而是“可能”會加表鎖。
默認情況下,InnoDB 仍然嘗試加「行鎖」,即便沒有命中索引,它會全表掃描并對每一行加行鎖。
但在某些情況下,為了提升性能或避免死鎖沖突,可能自動退化成表鎖(鎖升級)。?
視圖/存儲過程/觸發器
視圖
視圖(View)是一種虛擬存在的表.視圖中的數據并不在數據庫中實際存在,行和列數據來自定義視圖的查詢中使用的表,并且是在使用視圖時動態生成的。
視圖(View)本質上就是一個被命名的查詢語句
創建視圖
CREATE [OR REPLACE] VIEW 視圖名稱 [(列名列表)]
AS SELECT語句
[WITH [CASCADED | LOCAL] CHECK OPTION]

舉例? ?SELECT后面查詢的表稱為基表
CREATE VIEW active_users AS
SELECT id, username FROM users WHERE status = 'active';
?

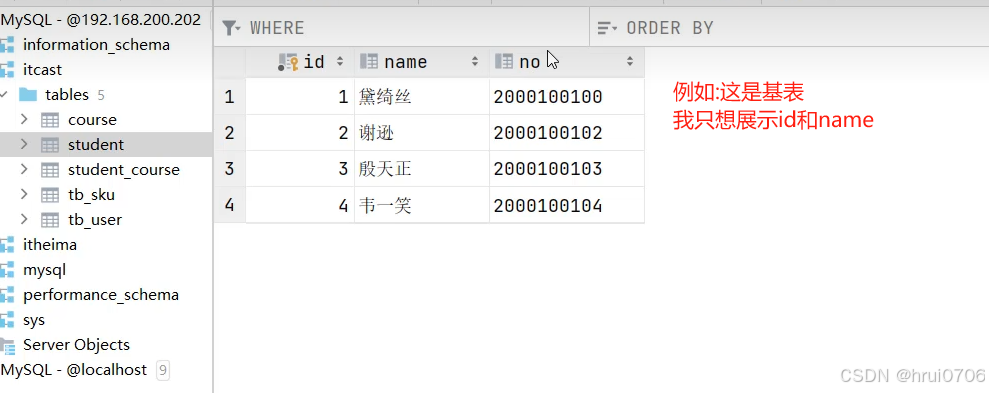
創建視圖?
CREATE VIEW stu_v_1 AS SELECT id,name FROM student WHERE id<=10;
查詢視圖
查看創建視圖語句:SHOW CREATE VIEW 視圖名稱;
查看視圖數據:SELECT * FROM 視圖名稱 ....;
修改視圖
注意修改視圖加上:OR REPLACE
CREATE OR REPLACE VIEW stu_v_1 AS?
SELECT id, name, age?
FROM student?
WHERE id <= 20;
?
或者
ALTER VIEW?stu_v_1 AS SELECT .......;
刪除視圖
DROP VIEW [IF EXISTS] 視圖名稱1 [,視圖名2];
視圖的創建增刪改查
創建視圖
CREATE OR REPLACE VIEW stu_v_1 AS SELECT id,name FROM student WHERE id<20;
查詢視圖中的數據
SELECT * FROM stu_v_1;
往視圖中插入數據
INSERT INTO stu_v_1 VALUES(6,'Tom');? ?注意插入的數據實際是插入到基表中的
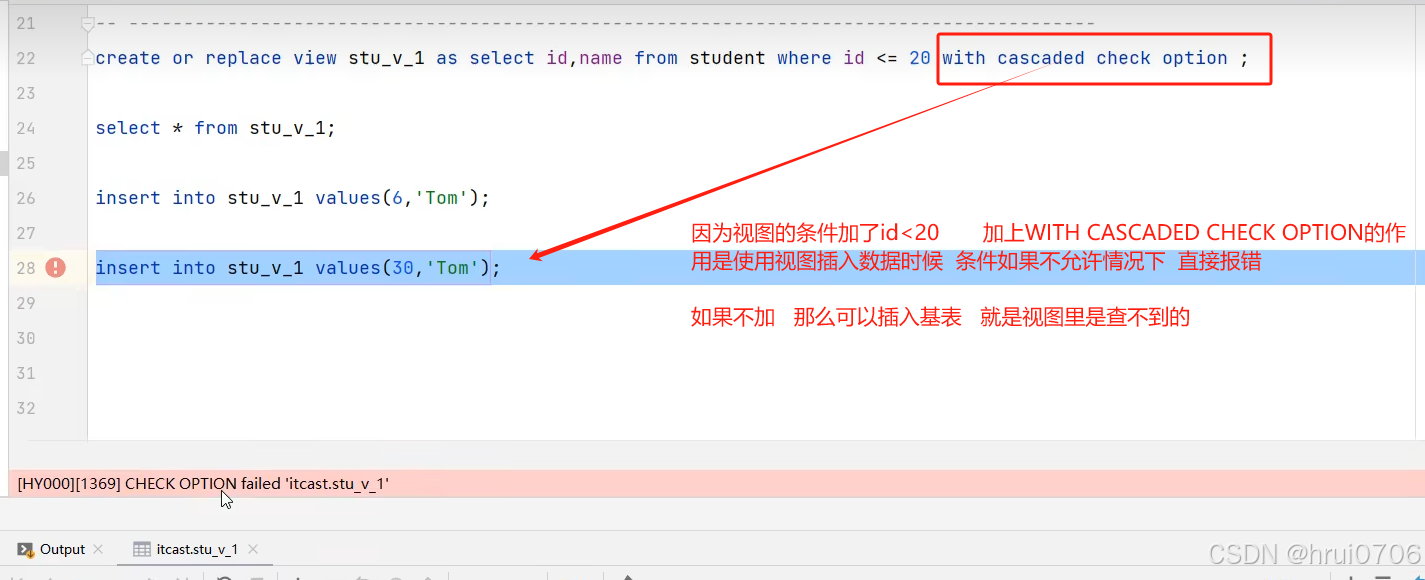
視圖的檢查選項
當創建視圖時候使用WITH CHECK OPTION子句創建時,Mysql會通過視圖檢查正在更改的每個,
新增,更新,刪除是否符合視圖定義.Mysql允許基于另一個視圖創建視圖.會檢查視圖規則
Mysql提供兩個規則選項
1.CASCADED(默認)
例如
CREATE VIEW v1 AS SELECT id,name FROM student WHERE id<20;
如果后面不加
WITH [CASEADED|LOCAL]?CHECK OPTION?
這樣在增刪改時候視圖是不會檢查條件的 條件就是id<20
CREATE VIEW v2 AS SELECT id,name FROM v1 WHERE id<20?WITH CASEADED CHECK OPTION;
如果這樣的話
在增刪改時候視圖會檢查條件,不光檢查V2條件 還會檢查V1的條件,相當于在創建視圖V1時候后面也加了WITH CASEADED CHECK OPTION;
2.LOCAL
WITH LOCAL CHECK OPTION的作用是如果視圖本身有條件需要滿足條件,不會強制父視圖滿足(如果有WITH [CASEADED|LOCAL ] CHECK OPTION需要滿足,沒有拉到)

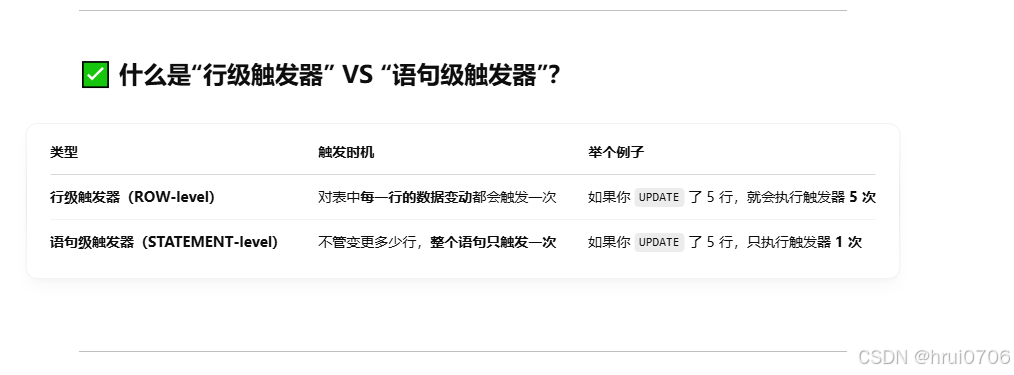
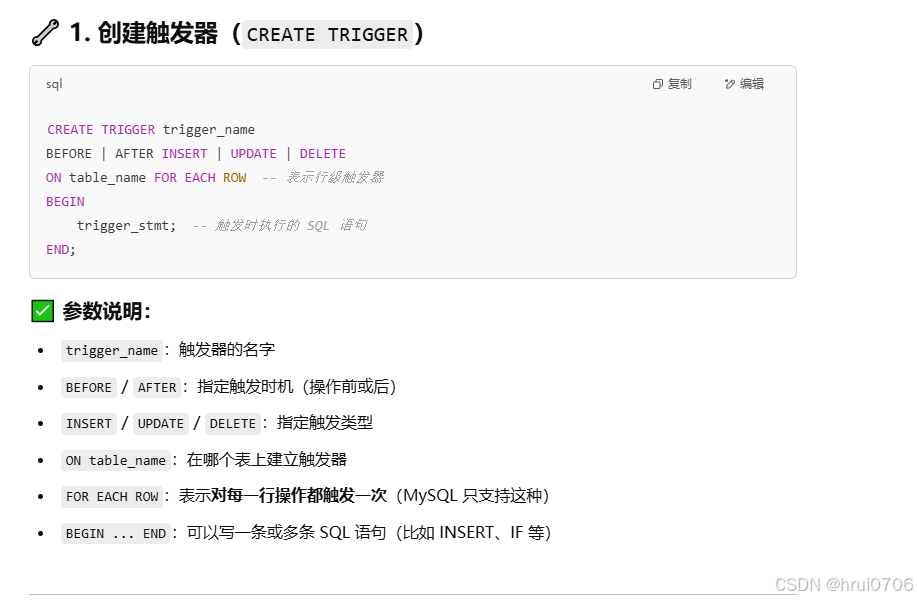
觸發器
觸發器是與表有關的數據庫對象,在INSERT/UPDATE/DELETE之前或之后,觸發并執行觸發器中定義的SQL語句集合.自動執行一段你提前定義好的 SQL 代碼(這些代碼叫“觸發器體”)。
所謂OLD和NEW 是觸發器給了我們一個定義:用來引用新的數據和老的數據
在Mysql中現在只支持行級觸發器,還不支持語句級觸發器


觸發器的創建查看刪除
不支持修改觸發器,可以先刪除再重新創建

觸發器練習
通過觸發器記錄tb_user表的數據變更日志,將變更日志插入到日志表user_logs中,包含增加修改,刪除
tb_user表上面有記錄
注意:user_logs和tb_user可以在同一個Mysql實例中
跨庫需要 數據庫.表? ? 不同實例間就需要應用代碼層去處理
CREATE TABLE user_logs (
? id INT(11) AUTO_INCREMENT PRIMARY KEY,
? operation VARCHAR(20) NOT NULL COMMENT '操作類型,例如 insert/update/delete',
? operate_time DATETIME NOT NULL COMMENT '操作時間',
? operate_id INT(11) NOT NULL COMMENT '操作的ID',
? operate_params VARCHAR(500) COMMENT '操作參數'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT觸發器
應該對字段進行NULL判斷,不然只要插入時候有一個是NULL,導致operate_params整個為NULL
CREATE TRIGGER tb_user_insert_trigger
AFTER INSERT ON tb_user
FOR EACH ROW
BEGIN
? INSERT INTO user_logs (id, operation, operate_time, operate_id, operate_params)
? VALUES (
? ? NULL,
? ? 'insert',
? ? NOW(),
? ? NEW.id,
? ? CONCAT(
? ? ? '插入的數據內容為: id=', NEW.id,
? ? ? ', name=', NEW.name,
? ? ? ', phone=', NEW.phone,
? ? ? ', email=', NEW.email,
? ? ? ', profession=', NEW.profession
? ? )
? );
END;
?修改之后? ?看是否有需要? 如果你在代碼層面已經控制的話就不需要了
CREATE TRIGGER tb_user_insert_trigger
AFTER INSERT ON tb_user
FOR EACH ROW
BEGIN
? INSERT INTO user_logs (id, operation, operate_time, operate_id, operate_params)
? VALUES (
? ? NULL,
? ? 'insert',
? ? NOW(),
? ? NEW.id,
? ? CONCAT(
? ? ? '插入的數據內容為: id=', IFNULL(NEW.id, ''),
? ? ? ', name=', IFNULL(NEW.name, ''),
? ? ? ', phone=', IFNULL(NEW.phone, ''),
? ? ? ', email=', IFNULL(NEW.email, ''),
? ? ? ', profession=', IFNULL(NEW.profession, '')
? ? )
? );
END;
?
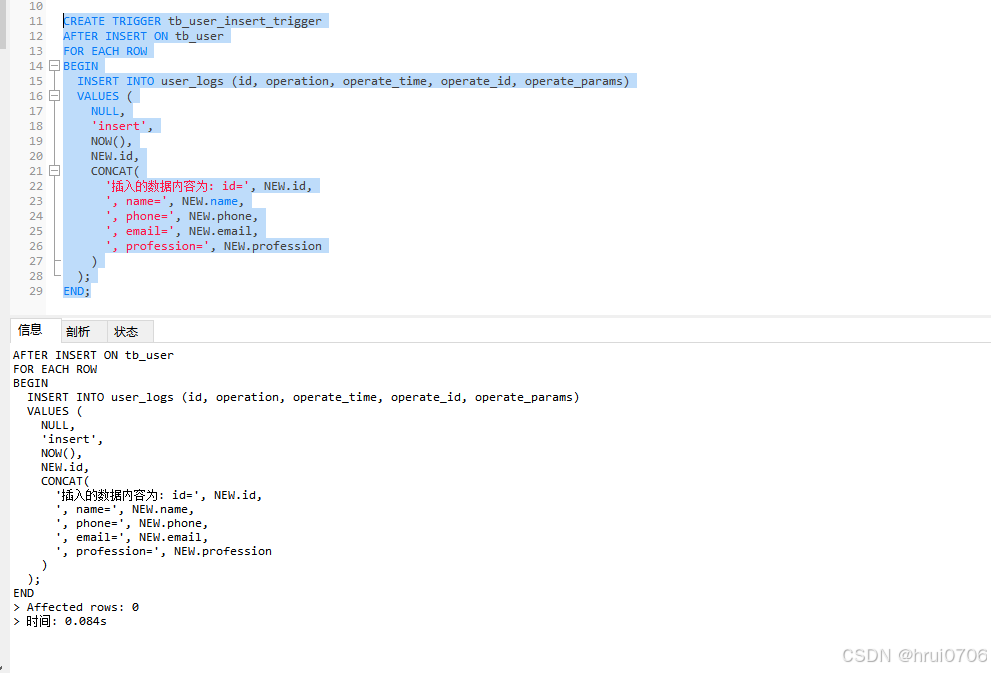
查看觸發器指令
SHOW TRIGGERS;
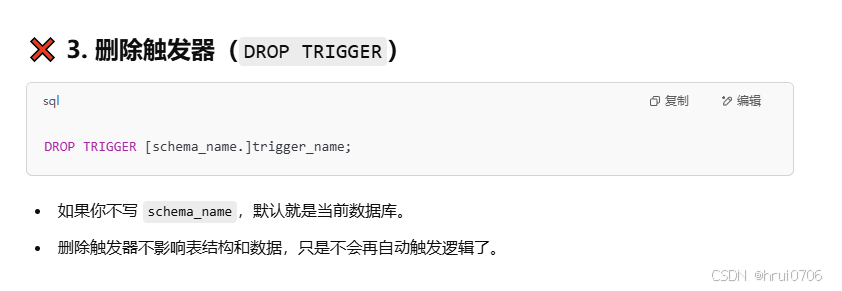
刪除觸發器
DROP TRIGGER?tb_user_insert_trigger;
?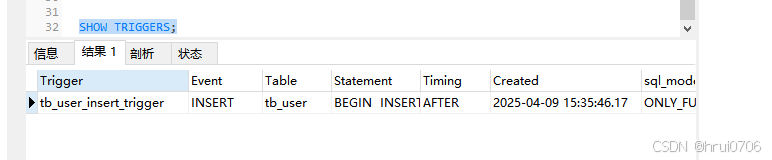
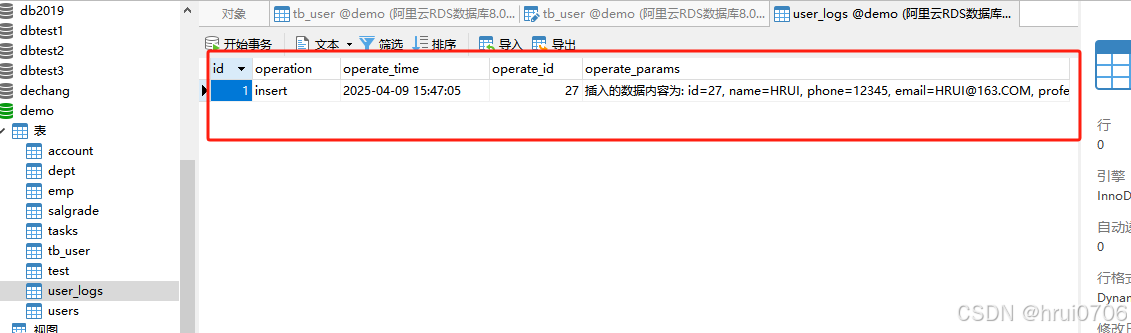
當往tb_user插入數據之后
INSERT INTO tb_user
VALUES (NULL, 'HRUI', '12345', 'HRUI@163.COM', '不務正業', 13, '男', 1, NOW());
UPDATE觸發器?
也需要對NULL的判斷? 這里就不寫了? ?參考INSERT
CREATE TRIGGER tb_user_update_trigger
AFTER UPDATE ON tb_user
FOR EACH ROW
BEGIN
? INSERT INTO user_logs (id, operation, operate_time, operate_id, operate_params)
? VALUES (
? ? NULL,
? ? 'insert',
? ? NOW(),
? ? NEW.id,
? ? CONCAT(
? ? ? '更新之前的數據: id=', OLD.id,
? ? ? ', name=', OLD.name,
? ? ? ', phone=', OLD.phone,
? ? ? ', email=', OLD.email,
? ? ? ', profession=', OLD.profession,??????';更新之前的數據: id=', NEW.id,
? ? ? ', name=', NEW.name,
? ? ? ', phone=', NEW.phone,
? ? ? ', email=', NEW.email,
? ? ? ', profession=', NEW.profession
? ? )
? );
END;
DELETE觸發器
CREATE TRIGGER tb_user_delete_trigger
AFTER DELETE ON tb_user
FOR EACH ROW
BEGIN
? INSERT INTO user_logs (id, operation, operate_time, operate_id, operate_params)
? VALUES (
? ? NULL,
? ? 'insert',
? ? NOW(),
? ? OLD.id,? ? ? 注意是OLD.id
? ? CONCAT(
? ? ? '刪除之前的數據: id=', OLD.id,
? ? ? ', name=', OLD.name,
? ? ? ', phone=', OLD.phone,
? ? ? ', email=', OLD.email,
? ? ? ', profession=', OLD.profession
? ? )
? );
END;
鎖
鎖是計算機協調多個進程或線程并發訪問某一資源的機制.
在數據庫中,這里的“資源”主要是指 數據本身,也可能包括元數據等。
數據庫除了傳統的資源競爭(比如 CPU、內存、I/O),還會面臨一個更核心的問題:
多個用戶同時訪問或修改相同數據,如何保證數據的一致性與正確性?
在數據庫中,鎖是保障數據一致性的重要機制,也是并發性能調優中必須面對的復雜問題。?

全局鎖
全局鎖是對整個數據庫實例加鎖,加鎖后整個實例進入只讀狀態。
-
所有 DML(如
INSERT、UPDATE、DELETE)和 DDL(如ALTER、DROP)語句都會被阻塞 -
已經提交的事務可以讀,但寫入、結構變更都會被鎖住
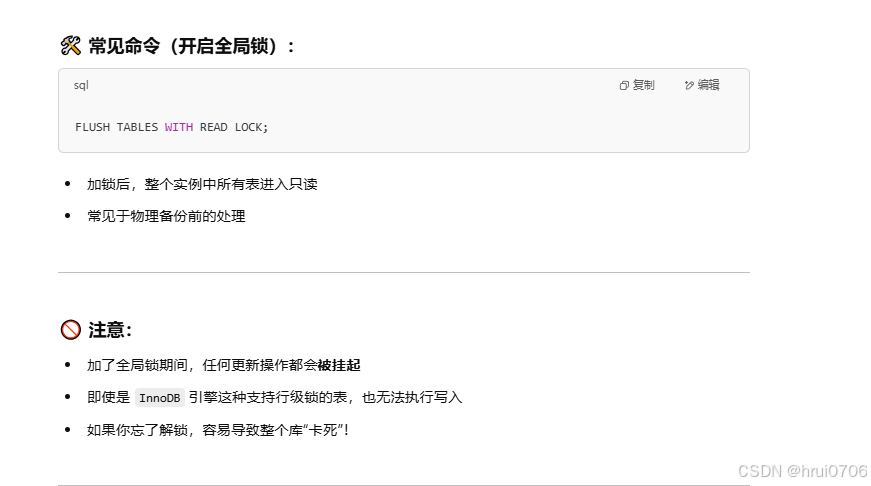
?FLUSH TABLES WITH READ LOCK?鎖會在連接斷開時自動釋放? ?是會話級別
DML和DDL操作會掛起,只能進行DQL
事務可以開啟但不能提交
掛起可以理解為卡住狀態,當應用程序對數據庫進行增刪改操作時候,應用長時間得不到回應會報錯
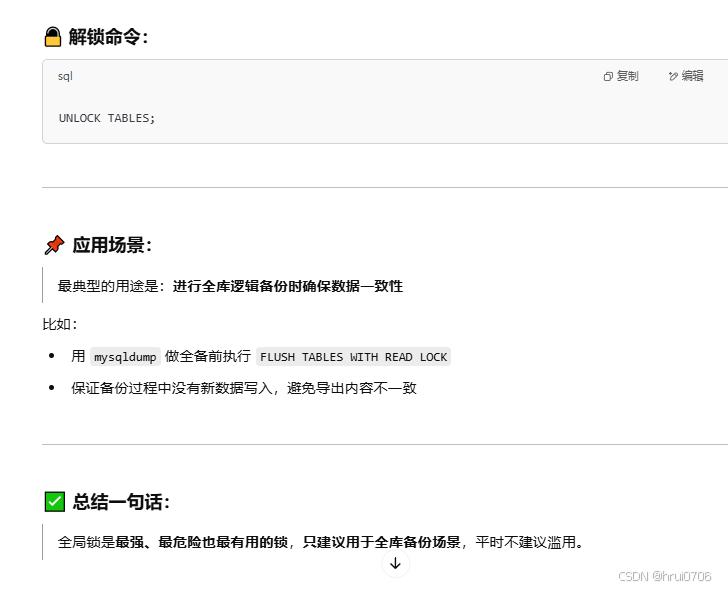
通過全局鎖進行數據庫備份
在mysql客戶端 FLUSH TABLES WITH READ LOCK? ? ?對數據庫庫實例加全局鎖
在Windows命令窗口? ?mysqldump [-h120.0.0.1 -P6666]?-uroot -p123456 數據庫名 > D:/db01.sql
在mysql客戶端??UNLOCK TABLES;? 解鎖? ? 加鎖和解鎖可以在同一窗口會話中進行

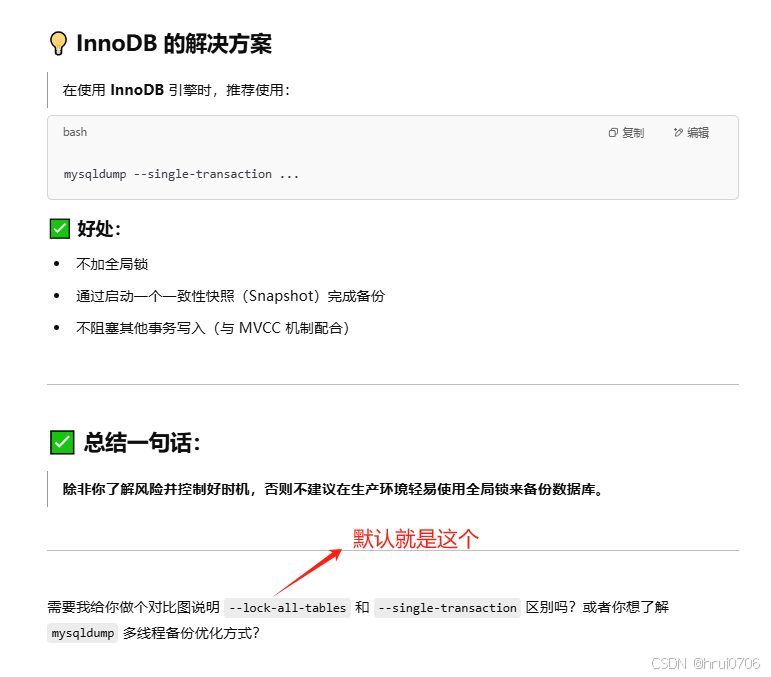
不加鎖進行備份?

表級鎖
表級鎖,每次操作鎖住整張表.鎖定粒度大,發生沖突概率高,并發度最低.
MyISAM,INNODB,BDB等存儲引擎中可以使用表級鎖

-- 給表加讀鎖(其他連接不能寫)
LOCK TABLES table_name READ;-- 給表加寫鎖(其他連接不能讀也不能寫)
LOCK TABLES table_name WRITE;
?
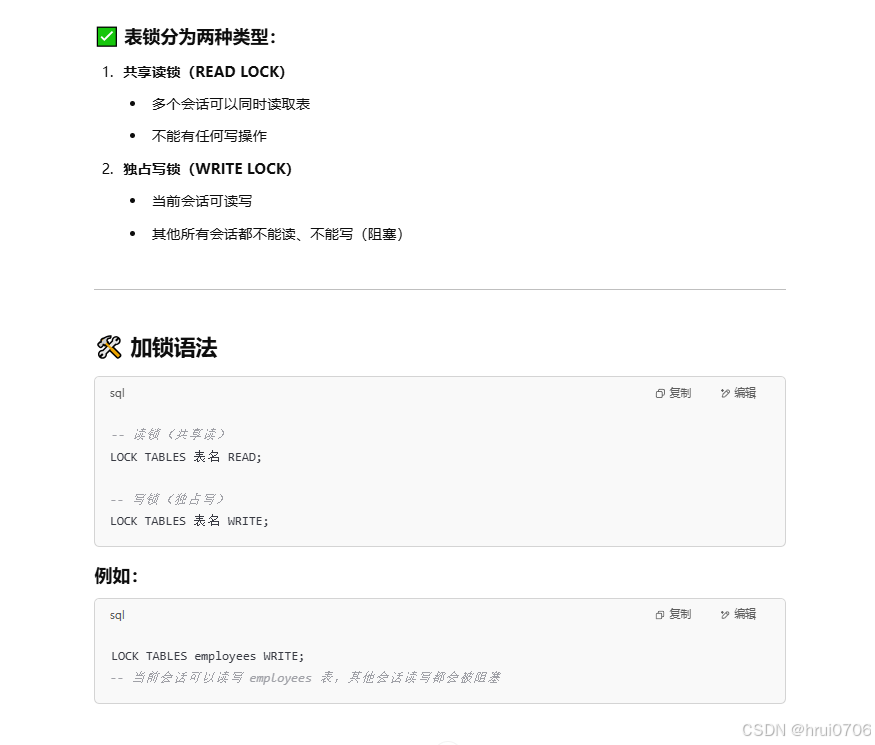
解鎖? 注意不用加表名? 并且斷開會話連接會自動解鎖
UNLOCK TABLES;
?
行級鎖
行級鎖,每次操作鎖住對應的行數據.鎖定粒度最小,發生鎖沖突的概率最低,并發度最高.應用在INnoDB引擎中
默認InnoDB核心講解
Mysql管理
Mysql運維篇
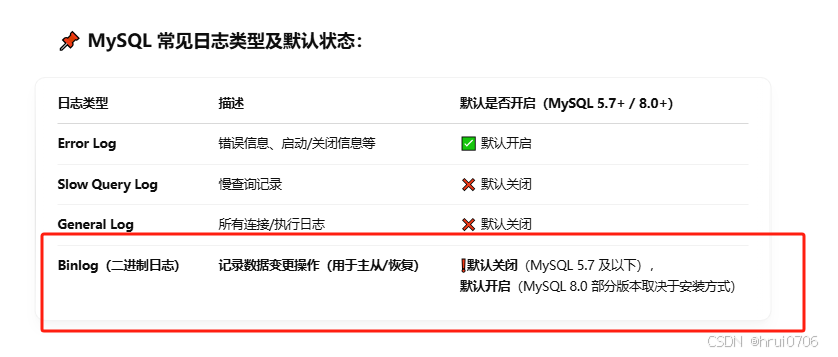
日志
主從復制
概述?
主從復制是指將主數據庫的DDL和DML操作通過二進制日志傳到從數據庫服務器中,然后在從庫上對這些日志重新執行(也叫重做),從而使得從庫和主庫的數據保持同步
Mysql支持一臺主庫同時向多臺從庫進行復制,從庫同時也可以做為其他從庫的主庫,實現鏈狀復制
主庫(Master)
從庫(Slave)
Mysql主從復制的優點
1.主庫出現問題,可以快速切換到從庫提供服務(這個可以想想代碼層面如何實現)
2.實現讀寫分離,降低主庫的訪問壓力
3.可以在從庫中執行備份,以避免備份期間影響主庫服務
原理
Mysql主從復制原理是基于二進制日志
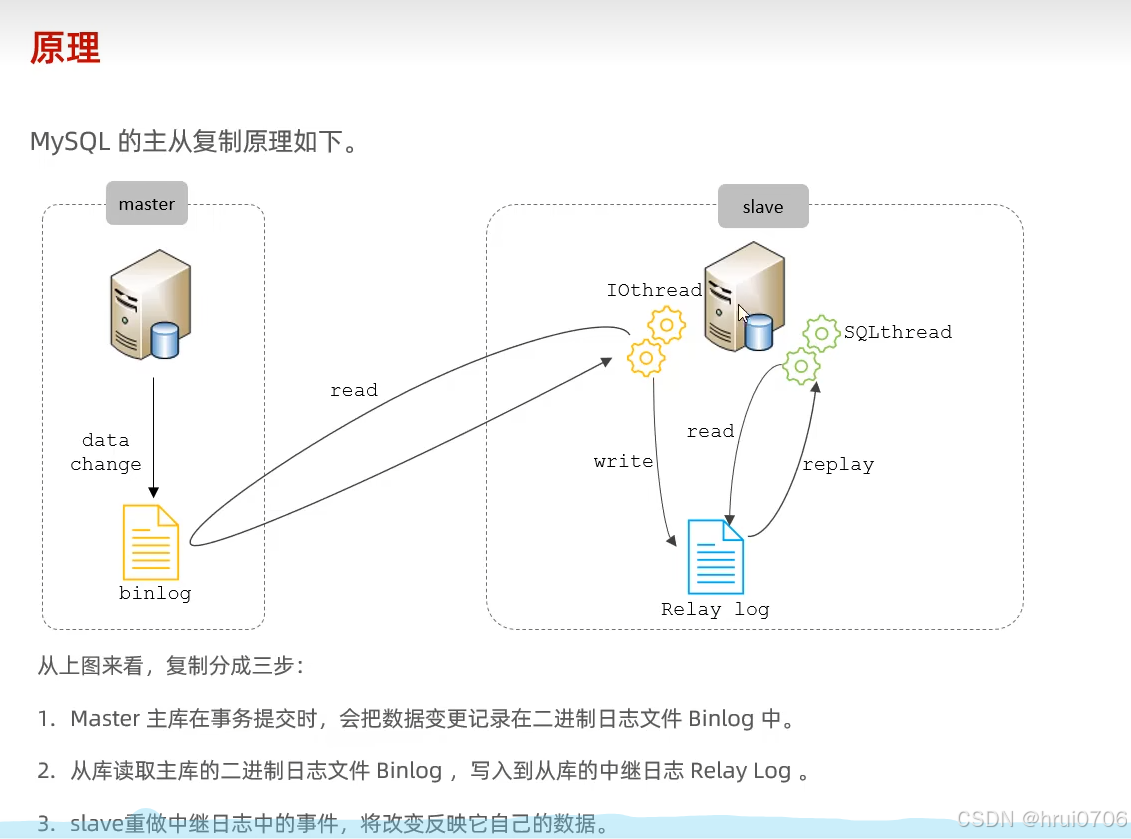

SHOW VARIABLES LIKE 'log_bin'; -- 正常情況下返回 Value = ONSHOW VARIABLES LIKE 'binlog_format'; -- 通常返回 ROWSHOW BINARY LOGS; -- 顯示現有的binlog文件列表
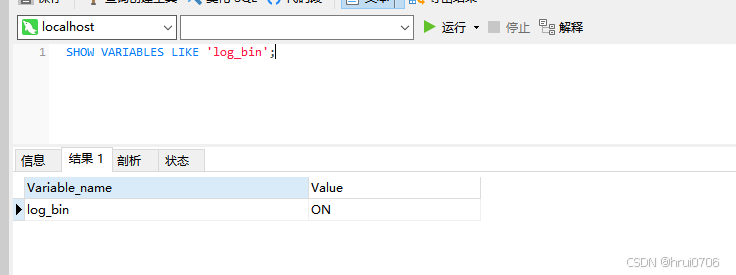
Mysql8中? ?binlog默認開啟? 如果需要顯示關閉(找死)

搭建
1.兩個Mysql實例
2.配置主從
主庫配置

配置完成之后重啟Mysql
systemctl restart mysqld;
主庫創建用于復制的用戶
CREATE USER '用戶名'@'%' IDENTIFIED WITH mysql_native_password BY '密碼';
-
@'%'表示允許任意主機(即從庫)使用該用戶連接主庫 -
使用
mysql_native_password插件認證(兼容性最好)
授權該用戶具備主從復制的權限
GRANT REPLICATION SLAVE ON *.* TO '用戶名'@'%';
-
REPLICATION SLAVE權限是必須的 -
它允許該用戶從主庫 讀取 binlog 并進行同步
當然如果你使用root用戶 那么上面這些可以不進行配置? use mysql; select * from user看下root用戶是否允許本機或者所有IP來進行連接? ?Mysql 以 用戶名/主機? 來定義用戶? ?例如可以多個root 但是host不一樣
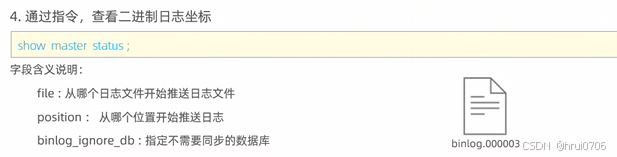
看下二進制坐標
SHOW master status;
主庫配置就完畢了
從庫配置
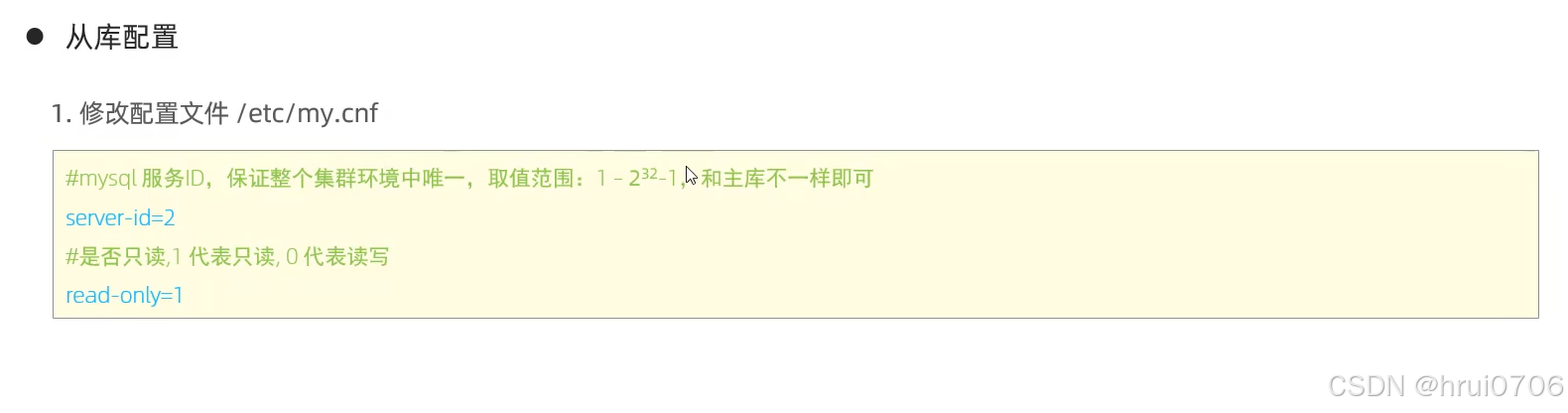

注意: read-only=1 針對的普通用戶? 對root用戶就不針對了
如果連超級用戶也要針對? ? 注意 中劃線和下劃線無所謂
# 保證 server-id 唯一
server-id=2# 普通只讀保護
read_only=1# 限制超級用戶寫入(更安全)
super_read_only=1
?
重啟從庫
systemctl restart mysqld;
主庫和從庫進行關聯? 在從數據庫執行命令
如果用的是root
CHANGE MASTER TO
? MASTER_HOST='主庫IP',
? MASTER_USER='root',
? MASTER_PASSWORD='你的密碼',
? MASTER_LOG_FILE='xxx',
? MASTER_LOG_POS=xxx;
查看版本
SELECT VERSION();
?
MySQL 8.0.23 及以后(新語法):
CHANGE REPLICATION SOURCE TO
? SOURCE_HOST='xxx.xxx.xxx.xxx',
? SOURCE_USER='用戶名',
? SOURCE_PASSWORD='密碼',
? SOURCE_LOG_FILE='binlog文件名',
? SOURCE_LOG_POS=位置;
MySQL 8.0.22 及以前(舊語法):
CHANGE MASTER TO
? MASTER_HOST='xxx.xxx.xxx.xxx',
? MASTER_USER='用戶名',
? MASTER_PASSWORD='密碼',
? MASTER_LOG_FILE='binlog文件名',
? MASTER_LOG_POS=位置;
SOURCE_LOG_FILE='binlog文件名', ? SOURCE_LOG_POS=位置; 可以在主庫中
SHOW MASTER STATUS;? 來查看
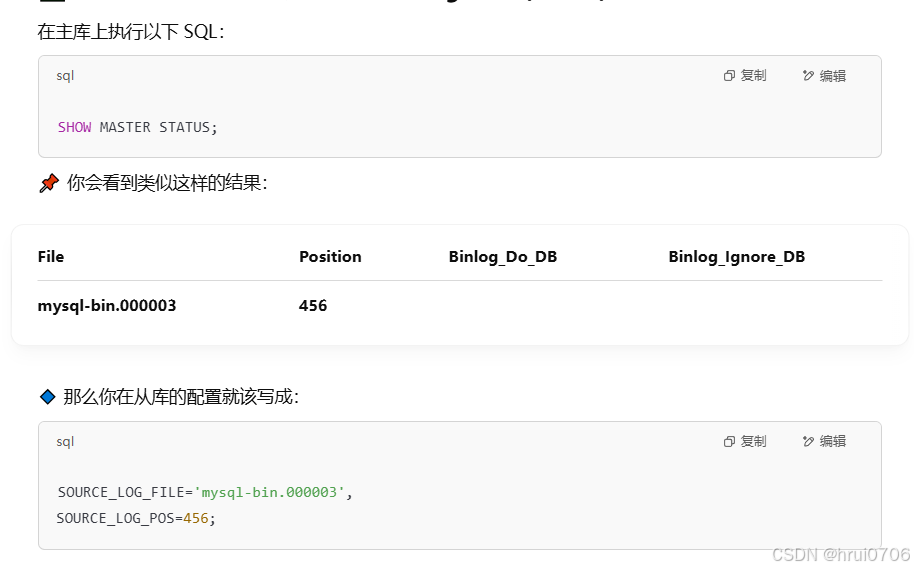
登錄主庫? ?SHOW SLAVE STATUS\G;可以查看從庫狀態? ? ?\G只是一種格式,沒什么特別含義
在主庫進行建表? ? 增刪改? ?都會在從庫同步
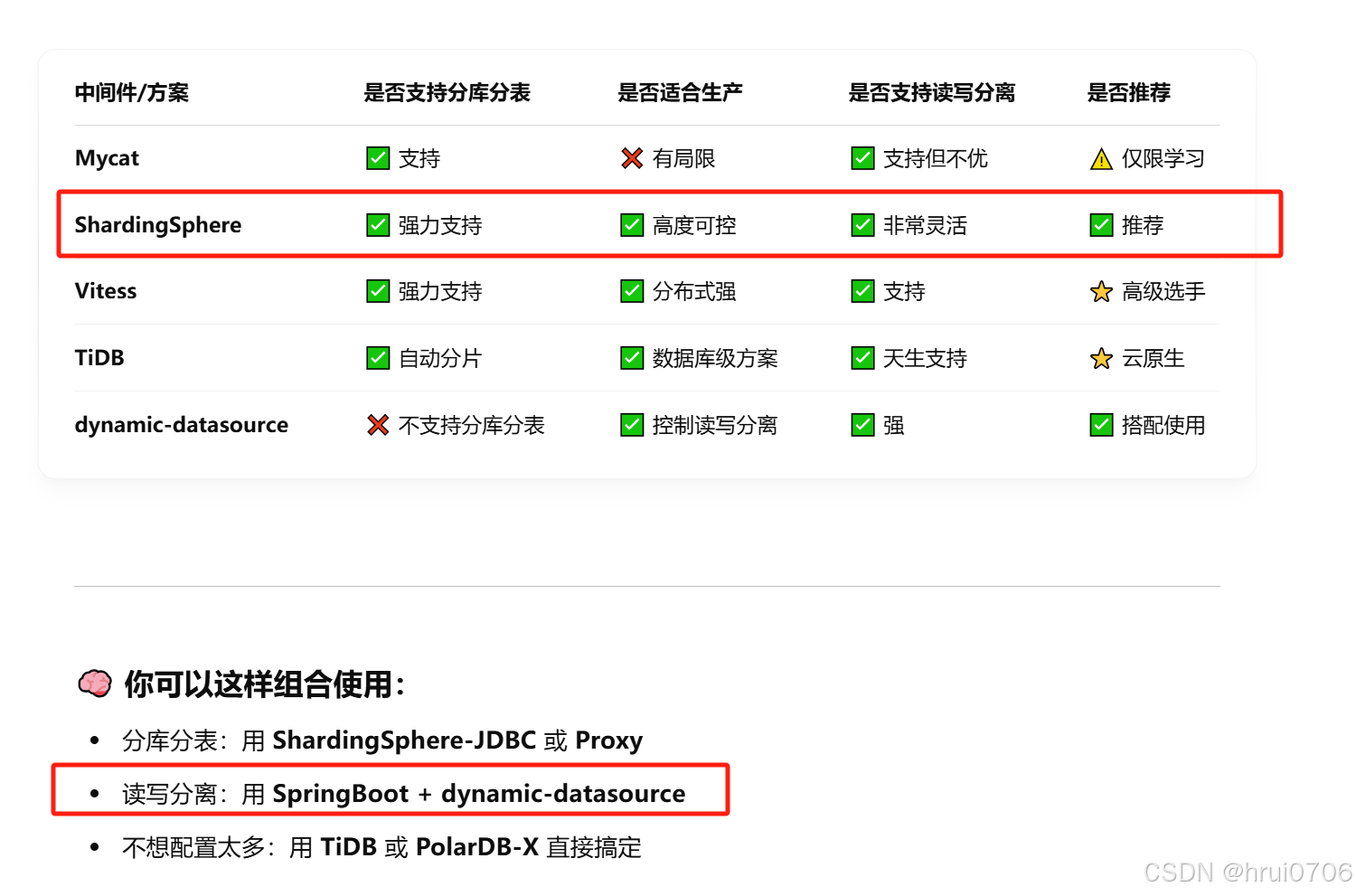
分庫分表
讀寫分離
介紹
讀寫分離是基于主從復制的? ? 都可以了解下
就是把對數據的讀和寫操作分開.減輕單臺數據庫的壓力
通過MyCat即可輕易實現,MyCat不僅支持Mysql,也支持Oracle和SQL Server
注意:Spring Boot + dynamic-datasource 的讀寫分離是代碼層面控制讀寫分離?屬于應用層的讀寫分離
MyCat是通過中間件層實現的,Spring Boot 的應用只連接一個邏輯數據源(Mycat),它背后再去路由主從數據庫。屬于中間件層的讀寫分離??端口 8066?
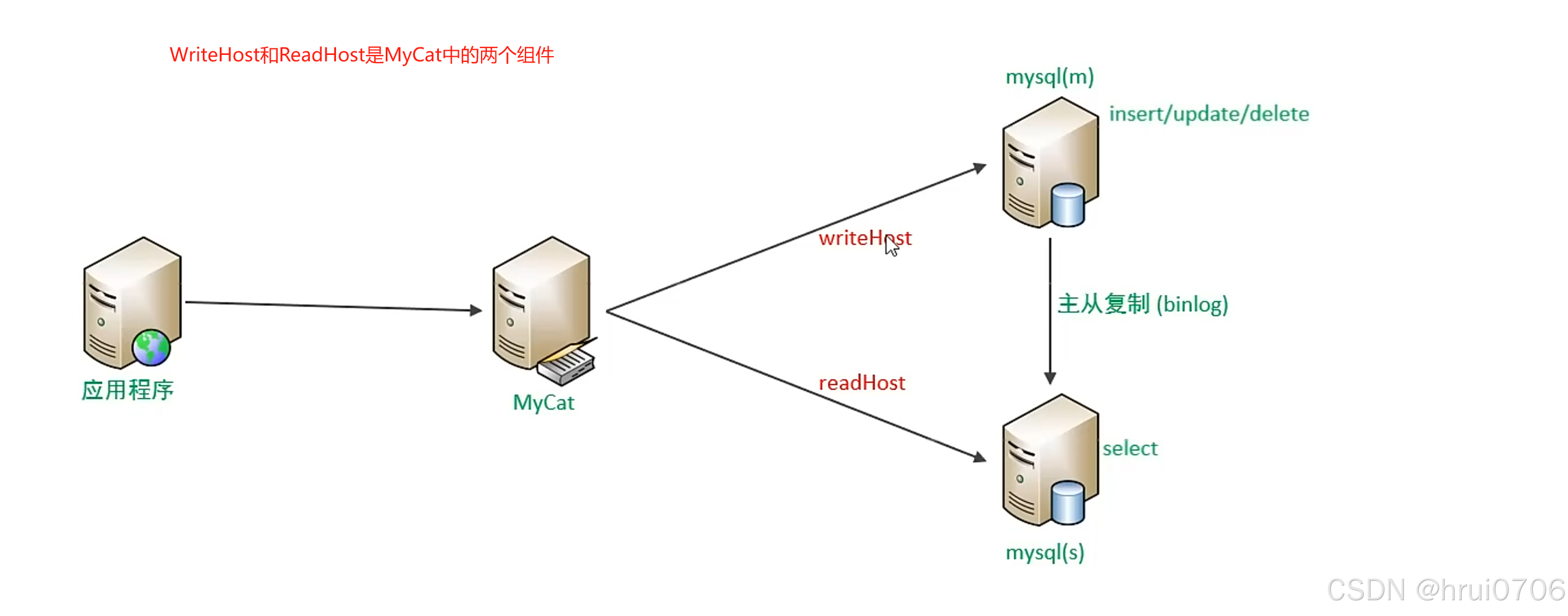
一主一從
一主一從的搭建上面已經有相關介紹
登錄主庫
SHOW SLAVE status\G;? 查看從庫狀態

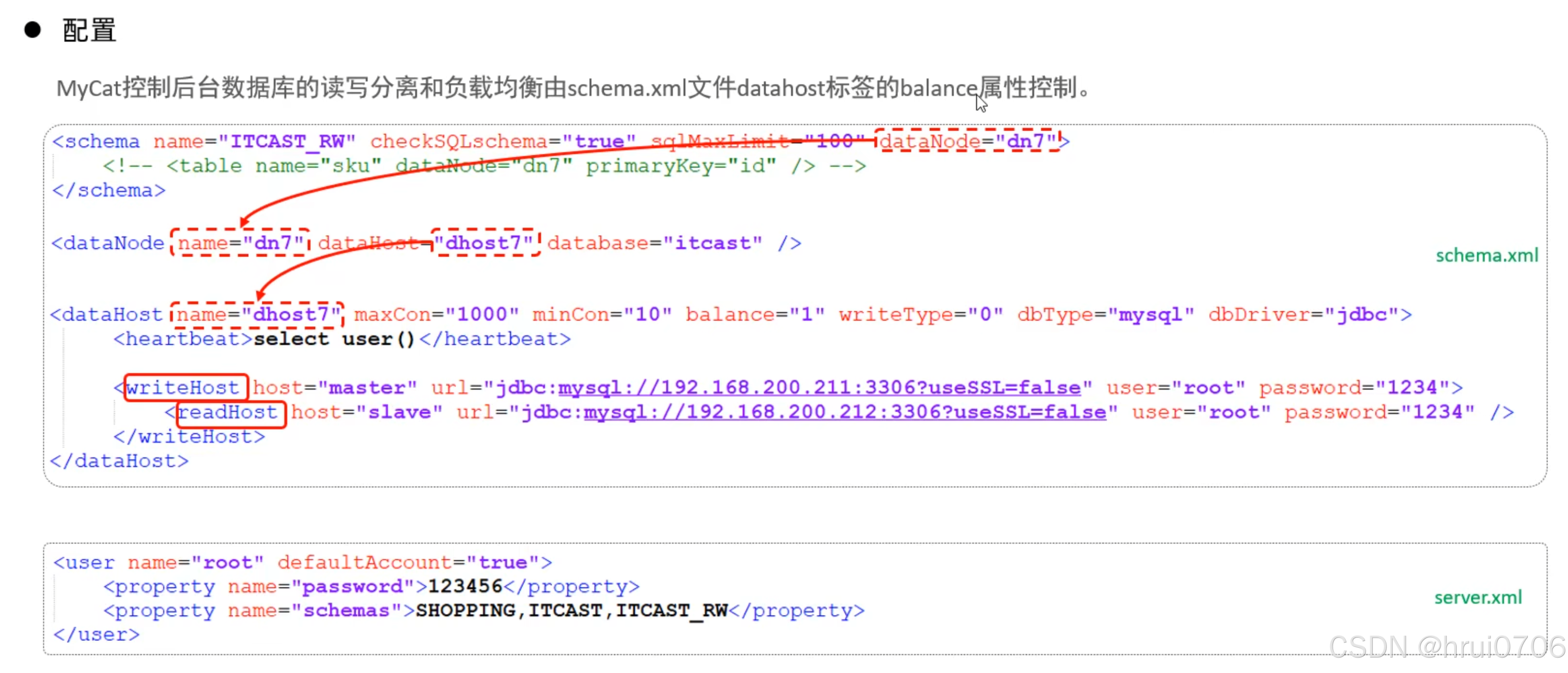
一主一從讀寫分離
![[IOI 1994] 數字三角形 Number Triangles](http://pic.xiahunao.cn/[IOI 1994] 數字三角形 Number Triangles)










![[electron]自動注冊IPC的解決方案](http://pic.xiahunao.cn/[electron]自動注冊IPC的解決方案)







)