線性回歸(linear regression)是一種基于數學模型的算法,首先假設數據集與標簽之間存在線性關系,然后簡歷線性模型求解參數。在實際生活中,線性回歸算法因為其簡單容易計算,在統計學經濟學等領域都有廣泛的應用,所以也作為工業界常用的模型。下面按照目錄的順序介紹:
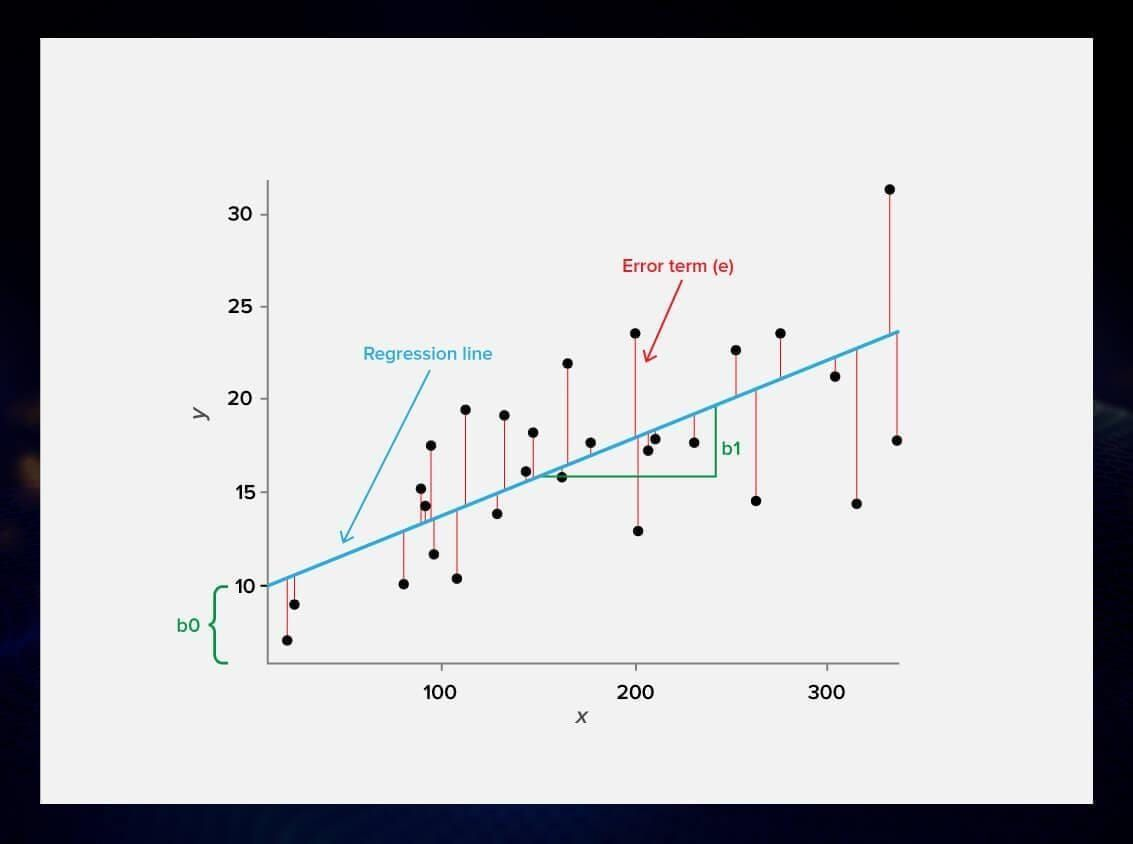
1線性回歸的三要素
1線性映射
2損失函數?
3優化目標---將損失函數(MSE,mean squared error)最小化
2兩種常用的求解方法
話不多說,這里我們使用實例代碼介紹正規方程和梯度下降。
1正規方程(Normal Equation)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
theta = np.linalg.inv(X.T @ X) @ X.T @ y_train
-
X 是特征矩陣(包含所有樣本的特征數據)。
-
X? 是矩陣 X 的轉置。
-
X?X是特征矩陣的內積。
這個公式表示的是通過正規方程直接計算最優回歸系數 θ 的方法。
2梯度下降(gradient descent)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
-
α 是學習率,決定每次更新的步長。
-
?J(θ)??是損失函數 J(θ) 對 θ的梯度,表示損失函數在當前參數點的變化率。
這個公式表示的是 梯度下降算法 中的參數更新步驟,通過反向傳播梯度,逐步調整模型的參數,以最小化損失函數。
Q&A環節:
1.MSE 對比下 RMSE 區別和用法?
兩者非常接近,但是對RMSE平方后開方的操作使其與y有相同的量綱,從直觀角度易于比較。我們可以簡單認為RMSE作為模型的評價指標?,MSE則是作為損失函數用在訓練的時候。
2關于梯度下降,選取什么樣式的梯度下降?
不論是MBGD(小批量梯度下降) SGD (隨機梯度下降)其實都可以叫做SGD ,雖然理論上兩種算法不一樣,SGD不如MBGD穩健(B是關鍵點哈哈)一般情況不怎么做嚴格的分別。
3學習率對于訓練影響
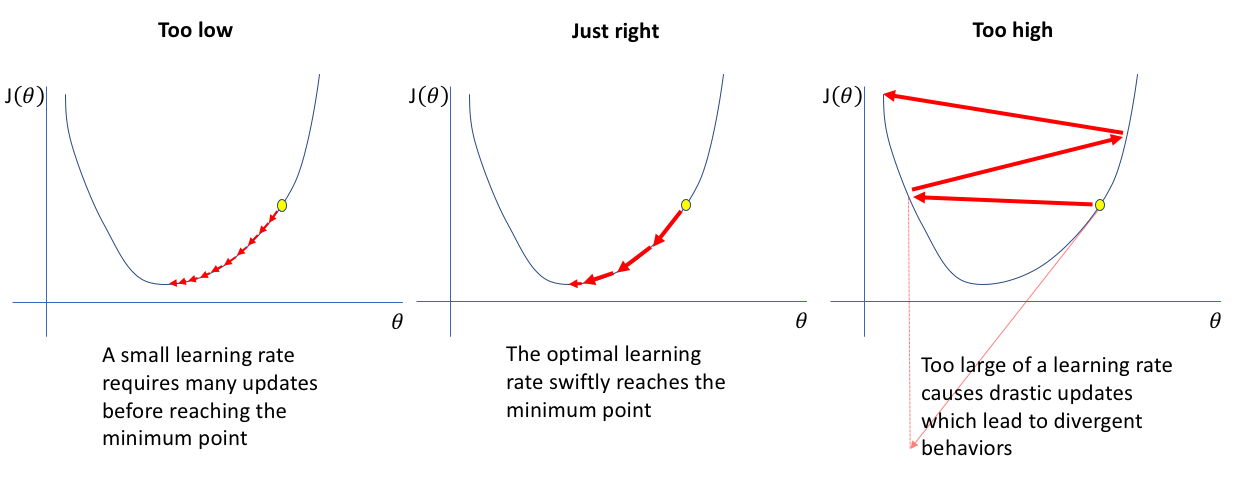
顯然,選擇合適的學習率非常重要哈,步子太小會趕不上時代,太大會傷到自己。
4啥時候使用正規方程以及梯度下降法?
正規方程優雅簡潔,適合理論;梯度下降靈活萬用,適合實戰。有點類似于正規方程是優雅的數學系,不需要學習率設置,更不需要去迭代,最最最nb的是得出的就是最優解。梯度下降法是工程師以及生活中更加通用的方法(那誰說局部最優不是最優解!!!達不到想要的那就從頭再試一下嘛哈哈哈)哈哈哈。
5回歸系數有幾個啊?
一般來說是特征數加上一個偏置項。
6線性回歸的標準化重要么如果不標準化對結果是否有很大改變呢?



![[electron]自動注冊IPC的解決方案](http://pic.xiahunao.cn/[electron]自動注冊IPC的解決方案)







)


![[250409] GitHub Copilot 全面升級,推出AI代理模式,可支援MCP | Devin 2.0 發布](http://pic.xiahunao.cn/[250409] GitHub Copilot 全面升級,推出AI代理模式,可支援MCP | Devin 2.0 發布)




)