一、模型參數量
參數量的單位
參數量指的是模型中所有權重和偏置的數量總和。在大模型中,參數量的單位通常以“百萬”(M)或“億”(B,也常說十億)來表示。
百萬(M):表示一百萬個參數。例如,如果一個模型有110M個參數,那么它實際上有110,000,000(即1.1億)個參數。
億(B):表示十億個參數。例如,GPT-3模型有175B個參數,即175,000,000,000(即1750億)個參數。
二、內存數據量的單位
在大數據和機器學習的語境下,數據量通常指的是用于訓練或測試模型的數據的大小。數據量的單位可以是字節(Byte)、千字節(KB)、兆字節(MB)、吉字節(GB)等。
字節(Byte):是數據存儲的基本單位。一個字節由8個比特(bit)組成。
千字節(KB):等于1024個字節。
兆字節(MB):等于1024個千字節,也常用于表示文件或數據的大小。
吉字節(GB):等于1024個兆字節,是較大的數據存儲單位。
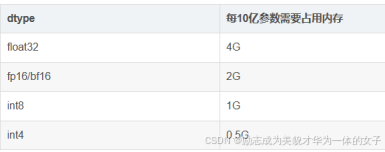
在大模型中,由于模型參數通常是以浮點數(如float32)存儲的,因此可以通過模型參數量來計算模型所需的存儲空間大小。例如,如果一個模型有1.1億個參數,并且每個參數用float32表示(即每個參數占4個字節),那么該模型所需的存儲空間大約為44MB(1.1億×4字節/1024/1024)。
bit(比特):bit是二進制數字中的位,是信息量的最小單位。在二進制數系統中,每個0或1就是一個bit。bit是計算機內部數據存儲和傳輸的基本單位。在數據傳輸過程中,通常以bit為單位來表示數據的傳輸速率或帶寬。
字節(Byte)定義:字節是計算機信息技術用于計量存儲容量的一種單位,也表示一些計算機編程語言中的數據類型和語言字符。字節通常由8個bit組成。字節是計算機中數據處理的基本單位。在存儲數據時,通常以字節為單位來表示數據的大小或容量。
bit和字節的關系:1字節(Byte)等于8比特(bit)。在計算機科學中,經常需要將數據的大小從字節轉換為比特,或者從比特轉換為字節。例如,在數據傳輸過程中,如果知道數據的傳輸速率是以比特每秒(bps)為單位的,那么可以通過除以8來將其轉換為字節每秒(Bps)的單位。

三、模型參數精度
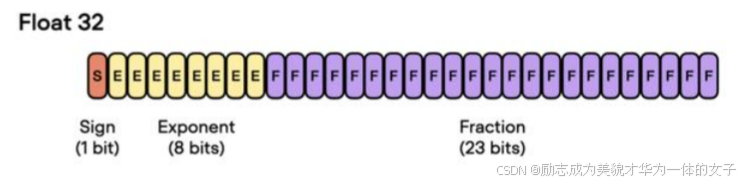
單精度浮點數 (32位) - float32:
含義:單精度浮點數用于表示實數,具有較高的精度,適用于大多數深度學習應用。
字節數:4字節(32位)
半精度浮點數 (16位) - float16:
含義:半精度浮點數用于表示實數,但相對于單精度浮點數,它的位數較少,因此精度稍低。然而,它可以在某些情況下顯著減少內存占用并加速計算。
字節數:2字節(16位)
雙精度浮點數 (64位) - float64:
含義:雙精度浮點數提供更高的精度,適用于需要更高數值精度的應用,但會占用更多的內存。
字節數:8字節(64位)
整數 (通常為32位或64位) - int32, int64:
含義:整數用于表示離散的數值,可以是有符號或無符號的。在某些情況下,例如分類問題中的標簽,可以使用整數數據類型來表示類別。
字節數:通常為4字節(32位)或8字節(64位)
int4 (4位整數):
含義:int4使用4位二進制來表示整數。在量化過程中,浮點數參數將被映射到一個有限的范圍內的整數,然后使用4位來存儲這些整數。
字節數:由于一個字節是8位,具體占用位數而非字節數,通常使用位操作存儲。
int8 (8位整數):
含義:int8使用8位二進制來表示整數。在量化過程中,浮點數參數將被映射到一個有限的范圍內的整數,然后使用8位來存儲這些整數。
字節數:1字節(8位)
量化:在量化過程中,模型參數的值被量化為最接近的可表示整數,這可能會導致一些信息損失。因此,在使用量化技術時,需要平衡壓縮效果和模型性能之間的權衡,并根據具體任務的需求來選擇合適的量化精度。
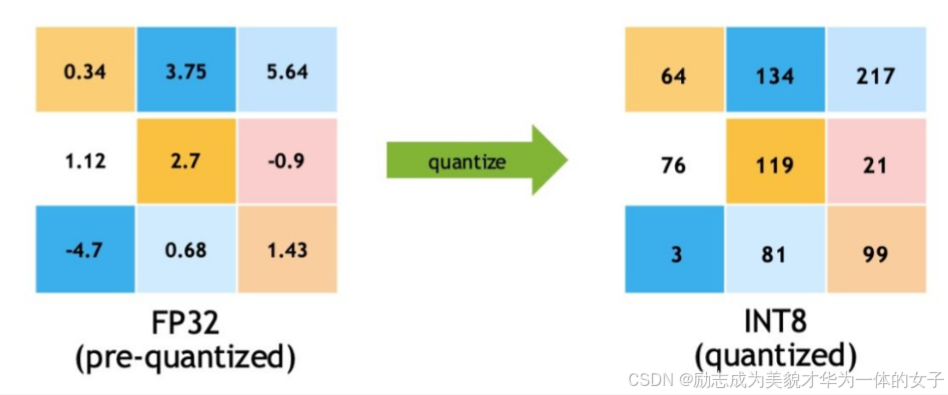
1B int8的存儲需要1GB的顯存?
?
四、訓練顯存
模型參數
梯度
存儲梯度所需的內存等于參數本身所需的內存。由于每個參數都有相應的梯度,因此它們的內存要求相同。
梯度內存 = 參數內存
優化器
優化器狀態是某些優化算法(如 Adam、RMSprop)維護的附加變量,用于提高訓練效率。這些狀態有助于根據過去的梯度更新模型參數。
不同的優化器維護不同類型的狀態。例如:
SGD(隨機梯度下降):沒有附加狀態;僅使用梯度來更新參數。
Adam:為每個參數維護兩個狀態:一階矩(梯度平均值)和二階矩(梯度平方平均值)。這有助于動態調整每個參數的學習率。對于具有 100 萬個參數的模型,Adam 需要為每個參數維護 2 個附加值(一階矩和二階矩),從而產生 200 萬個附加狀態。
優化器狀態的內存 = 參數數量 x 精度大小 x 優化器乘數
激活
激活指的是什么
前向傳遞過程中計算得到的,并在后向傳遞過程中需要用到的所有張量。激活值大小與批次大小和序列長度有關。
輸入數據和標簽:
訓練模型需要將輸入數據和相應的標簽加載到顯存中。這些數據的大小取決于每個批次的樣本數量以及每個樣本的維度。
中間計算:
在前向傳播和反向傳播過程中,可能需要存儲一些中間計算結果,例如激活函數的輸出、損失值等。
臨時緩沖區:
在計算過程中,可能需要一些臨時緩沖區來存儲臨時數據,例如中間梯度計算結果等。減少中間變量也可以節省顯存,這就體現出函數式編程語言的優勢了。
沒有固定的公式來計算激活的 GPU 內存。
以llama int 8 7B為例:
-
數據類型:Int8
-
模型參數: 7B * 1 bytes = 7GB
-
梯度:同上7GB
-
優化器參數: AdamW 2倍模型參數 7GB * 2 = 14GB
-
LLaMA的架構(hidden_size= 4096, intermediate_size(前饋網絡神經元的個數)=11008, num_hidden_lavers= 32, context.length = 2048),所以每個樣本大小:(4096 + 11008) * 2048 * 32 * 1byte = 990MB
-
A100 (80GB RAM)大概可以在int8精度下BatchSize設置為50
-
綜上總現存大小:7GB + 7GB + 14GB + 990M * 50/1024?~= 77GB
五、推理顯存?
-
模型加載:?計算模型中所有參數的大小,包括權重和偏差。
-
確定輸入數據尺寸:?根據模型結構和輸入數據大小,計算推理過程中每個中間計算結果的大小。
-
選擇批次大小:?考慮批處理大小和數據類型對顯存的影響。
大概是1.2倍的模型參數權重。
六、顯卡以及zero優化顯存
大模型在訓練或者微調時需要的顯卡個數其實與選擇的分布式訓練方法和微調方法有關。
比如大概120GB的內存如果單卡訓練需要兩張A100的顯卡。
如果我們采用多卡訓練同時運用zero的思想。那么顯存變化情況可以參考下圖:
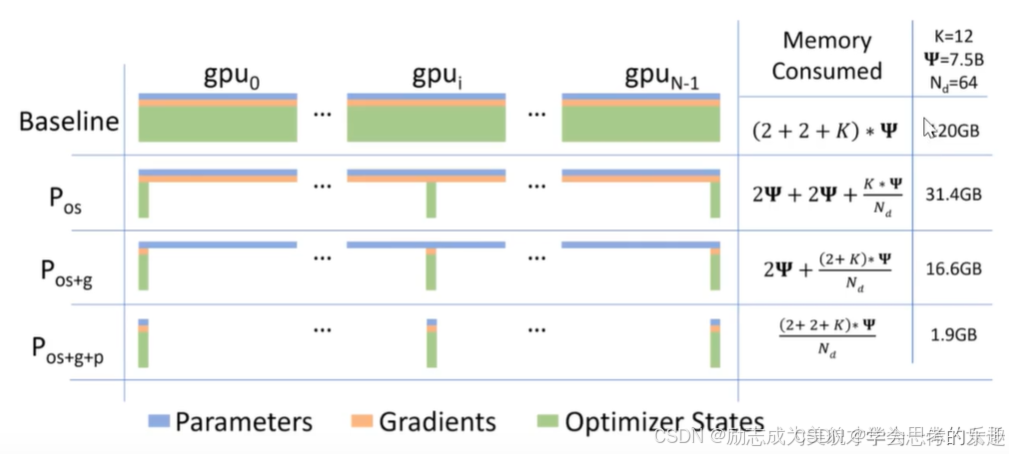
如果采用數據并行。模型并行:如果模型被均勻分割,那么可能需要與模型層數成比例的顯卡數量。
參考說明
開源大模型訓練及推理所需顯卡成本必讀:也看大模型參數與顯卡大小的大致映射策略_大模型 6b 13b是指什么-CSDN博客
大模型訓練時的激活值顯存占用 - 知乎




)







)



——個人理解篇5(梯度下降中遇到的問題))


