【目標檢測】【深度學習】【Pytorch版本】YOLOV2模型算法詳解
文章目錄
- 【目標檢測】【深度學習】【Pytorch版本】YOLOV2模型算法詳解
- 前言
- YOLOV2的模型結構
- YOLOV2模型的基本執行流程
- YOLOV2模型的網絡參數
- YOLOV2模型的訓練方式
- YOLOV2的核心思想
- 前向傳播階段
- 反向傳播階段
- 總結
前言
YOLOV2是由華盛頓大學的Joseph Redmon等人在《YOLO9000:Better, Faster, Stronger【CVPR-2017】》【論文地址】中提出的YOLO系列單階段目標檢測模型的升級改進版,核心思想是在YOLOV1基礎上,通過一系列改進措施提升檢測性能,即引入批量歸一化(Batch Normalization)、使用高分辨率分類器/檢查器、設計新的網絡結構Darknet-19、采用多尺度訓練(Multi-Scale Training)使得YOLOV2在保持高速的同時,大幅提升了檢測精度;提出了全卷積的Anchor Boxes機制,借鑒了Faster R-CNN中的區域建議思想,但將其整合到單階段框架中,避免了復雜的候選區域生成步驟;引入了維度聚類(Dimension Clustering)方法,通過對訓練數據中邊界框尺寸進行聚類分析,選擇最優的Anchor Box形狀,從而進一步提高檢測效果。
傳統目標檢測方法以及早期的深度學習模型(如R-CNN系列)雖然在精度上表現出色,但通常存在計算復雜度高、推理速度慢的問題。而YOLOv1雖然以速度見長,但其精度相對較低,尤其是在小目標檢測方面效果不足。yolov2較好的解決了yolov1中定位不準確和檢測召回率較低的問題,但在小目標檢測方面提升有限。
YOLOV2的模型結構
YOLOV2模型的基本執行流程
下圖是博主根據原論文繪制了YOLOV2模型流程示意圖:

基本流程: 將輸入圖像調整為固定大小(416x416),使用改進版的Darknet-19作為骨干網絡來提取圖像的特征(包含了檢測框位置、大小、置信度以及分類概率)并劃分網格,每個單元網格負責預測一定數量的邊界框及其對應的類別概率。
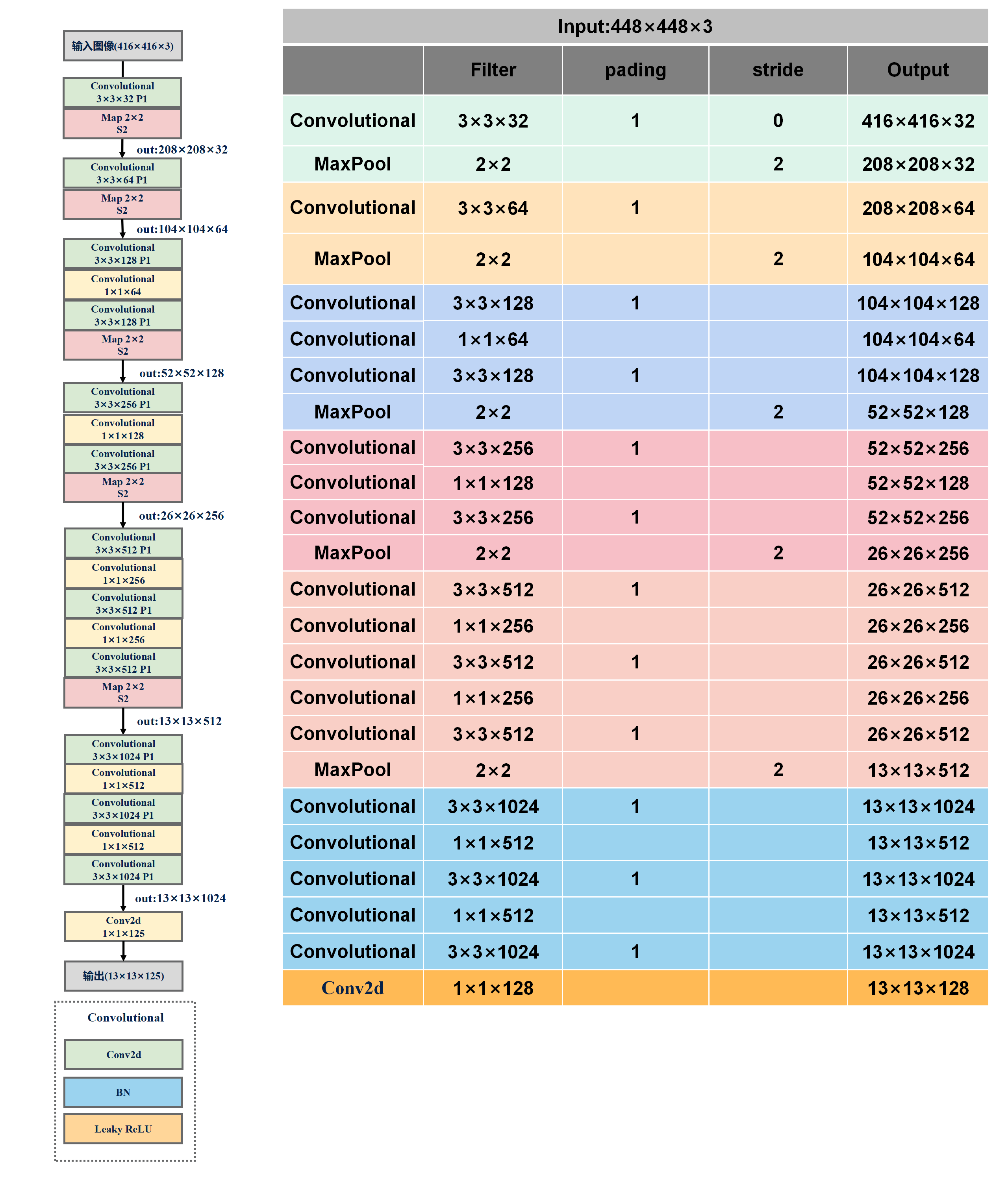
YOLOV2模型的網絡參數
YOLOV2網絡參數: YOLOV2采用的Darknet-19結構由于沒有全連接層,模型的輸入可以是任意圖片大小,不管是448×448還是224×224,因此可以進行多尺度訓練。
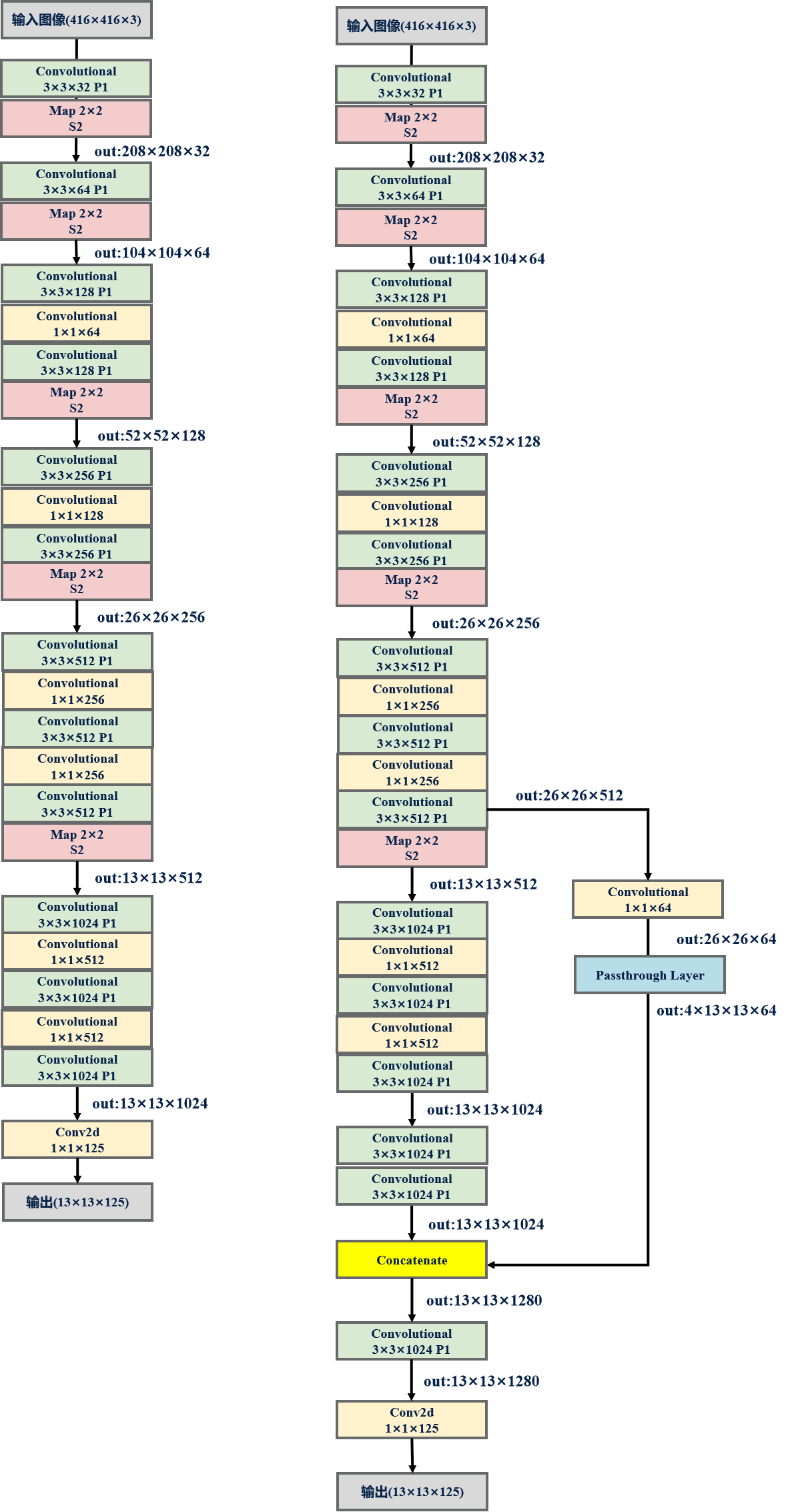
19是指有19個Convolutional層,注意這里的YOLOV2模型是非完成版的,還缺少缺少了passthough結構,在YOLOV2的核心思想部分會介紹完整版模型。
YOLOV2模型的訓練方式
YOLOV2訓練分為兩個階段:
- 在ImageNet分類數據集上預訓練分類模型。網絡模型的輸入先是224x224,訓練160輪次;
- 將網絡的輸入調整為448x448,繼續在ImageNet分類數據集上再次訓練10輪次;
- 將分類模型調整為檢測模型。多尺度訓練,動態調整(每訓練10個批次隨機調整)網絡模型的輸入尺寸{320×320,352×352,… ,608×608},去除最后一層1×1×1000的卷積層(目的是完成1000分類)和全局平均池化層,并新加入3個3x3x1024卷積層以及1個1×1×125卷積,最后模型的輸出為{10×10×125,11×11×125,… ,19×19×125}的向量大小。
輸入尺寸取值是32的倍數,最小是320,最大是608,詳細原因在后續中會解釋。
YOLOV2的核心思想

前向傳播階段
添加Batch Normalization: BN層是在InceptionV2中提出的,具體的原理參考【博文】。
多特征輸入數據 X = { x 1 , x 2 , x 3 . . . . x n ? 1 , x n } X = \left\{ {{{\rm{x}}_1},{{\rm{x}}_2},{{\rm{x}}_3}....{{\rm{x}}_{{\rm{n - 1}}}},{{\rm{x}}_{\rm{n}}}} \right\} X={x1?,x2?,x3?....xn?1?,xn?},每個特征 x i x_i xi?都對應著不同的物理含義,每個物理含義的標準通常都不一致,因此不同特征 x i x_i xi?對應的數值大小范圍千差萬別。如下圖所示,特征 X X X都有與之對應的權重系數 W = { w 1 , w 2 , w 3 . . . . w n ? 1 , w n } W = \left\{ {{{\rm{w}}_1},{{\rm{w}}_2},{{\rm{w}}_3}....{{\rm{w}}_{{\rm{n - 1}}}},{{\rm{w}}_{\rm{n}}}} \right\} W={w1?,w2?,w3?....wn?1?,wn?},所有特征 x i x_i xi?單獨乘以各自的權重 w i w_i wi?后,再累加得到結果。就結果好壞的影響而言,可能小數值特征 x 1 x_1 x1?重要程度比較高,相反,大數值特征 x 4 x_4 x4?重要程度比較低,這就要求權重 w 1 w_1 w1?恰當的大,保證小數值特征 x 1 x_1 x1?的影響力被有效加強,而權重 w 4 w_4 w4?恰當的小,保證大數值特征 x 4 x_4 x4?的影響力被明顯削弱。
這里的 w 1 w_1 w1?恰當的大或者 w 4 w_4 w4?恰當的小,不是指 w 1 w_1 w1?就一定比 w 4 w_4 w4?大,只是對于 x 1 x_1 x1?和 x 4 x_4 x4?, w 1 w_1 w1?和 w 4 w_4 w4?需要對它們加強或削弱,平衡之后能夠有好的輸出結果就好。博主在這里舉例比較極端是方便大家理解。

權重 W W W的更新幅度是由 W W W的梯度和學習率相乘計算而來:
W n e w = W o l d ? γ ? L ? W {W_{{\rm{new}}}} = {W_{{\rm{old}}}} - \gamma \frac{{\partial L}}{{\partial W}} Wnew?=Wold??γ?W?L?
γ \gamma γ是學習率,決定了我們在梯度方向上邁出的步長大小; ? L ? W \frac{{\partial L}}{{\partial W}} ?W?L?是損失函數 L L L關于權重 W W W的偏導數,即梯度; γ ? L ? W \gamma \frac{{\partial L}}{{\partial W}} γ?W?L?就是本次權重 W W W的更新幅度。
W W W更新學習過程中如下圖所示:權重 w 1 w_1 w1?梯度 ? L ? w 1 \frac{{\partial L}}{{\partial w_1}} ?w1??L?比較劇烈,大的學習率 γ \gamma γ可以得出盡可能大的更新幅度 γ ? L ? w 1 \gamma \frac{{\partial L}}{{\partial w_1}} γ?w1??L?,盡快移動到最優位置,但由于 w 1 w_1 w1?需要恰當的大,因此仍然需要漫長的迭代學習;權重 w 4 w_4 w4?的梯度 ? L ? w 4 \frac{{\partial L}}{{\partial w_4}} ?w4??L?盡管快速變緩,但因為 w 4 w_4 w4?需要恰當的小,在大的學習率下更新幅度 γ ? L ? w 4 \gamma \frac{{\partial L}}{{\partial w_4}} γ?w4??L?仍舊比較大,很難準確移動到在最優位置,因此在最優位置反復震蕩,更新困難。
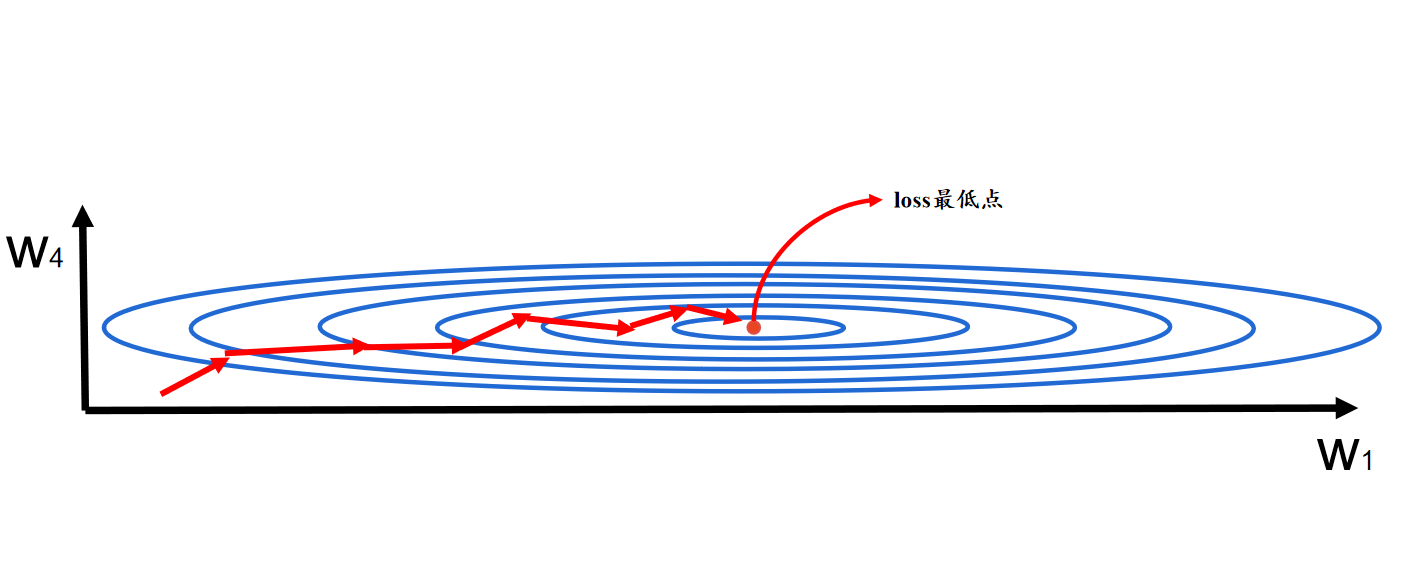
為了方便講解,下圖是只關于的 w 1 w_1 w1?和 w 4 w_4 w4?的簡易更新學習流程圖,loss最低點代表 w 1 w_1 w1?和 w 4 w_4 w4?的最佳取值點;圓環表示 w w w的取值區域,越接近loss最低點中心代表 w w w的值越有價值,loss越低。
w 1 w_1 w1?的更新是在X軸左右挪動; w 4 w_4 w4?的更新是在Y軸上下挪動。
總結,此前深度神經網絡訓練過程常常伴隨以下主要問題:
- 內部協變量偏移:網絡中每一層的輸入數據分布 X = { x 1 , x 2 , x 3 . . . . x n ? 1 , x n } X = \left\{ {{{\rm{x}}_1},{{\rm{x}}_2},{{\rm{x}}_3}....{{\rm{x}}_{{\rm{n - 1}}}},{{\rm{x}}_{\rm{n}}}} \right\} X={x1?,x2?,x3?....xn?1?,xn?}是一直在發生變化的,因為每一層的輸入分布會隨著前面層參數的更新而不斷變化。以某一層的某個輸入特征 x 1 x_1 x1?的分布變化為例,之前 x 1 x_1 x1?分布范圍是0到9,由于前面層參數更新, x 1 x_1 x1?的分布范圍變成了100到999,導致每一層需要不斷適應新的分布,訓練過程變得不穩定且緩慢。
- 減少對初始化的依賴:權重的初始化對訓練結果有很大影響。假設 w 1 w_1 w1?初始值和最優值差距很大,訓練過程就很緩慢。
- 學習率的設置:較大的學習率可能會導致訓練不穩定甚至發散。 w 1 w_1 w1?和 w 4 w_4 w4?在學習率上的選擇存在著矛盾, w 4 w_4 w4?的最優值的取值(如0.008)比較小,當 w 4 w_4 w4?的值接近最優值(如0.007)時,適合小學習率進行學習,但此時 w 1 w_1 w1?的值與最優值差距甚遠,此時仍是大學習率,導致 w 4 w_4 w4?更新幅度(如0.005)也很大, w 4 w_4 w4?(如0.012)變得糟糕。
BN層的出現,通過規范化每一層的輸入數據分布,解決了訓練過程中的一些關鍵問題,從而提升了模型的性能和訓練效率。如下圖所示,將 X = { x 1 , x 2 , x 3 . . . . x n ? 1 , x n } X = \left\{ {{{\rm{x}}_1},{{\rm{x}}_2},{{\rm{x}}_3}....{{\rm{x}}_{{\rm{n - 1}}}},{{\rm{x}}_{\rm{n}}}} \right\} X={x1?,x2?,x3?....xn?1?,xn?}中的所有特征都進行歸一化,統一不同特征 x i x_i xi?數值大小范圍標準。即使特征 x 1 x_1 x1?重要程度比較高,特征 x 4 x_4 x4?重要程度比較低,由于特征間的數值差異極具縮小,因此權重 w 1 w_1 w1?和權重 w 4 w_4 w4?的差異也不再巨大。
BN層對深度神經網絡的作用:
- 緩解內部協變量偏移:通過對每一層的輸入進行歸一化處理,將其均值和方差調整為固定值,使得每一層的輸入分布更加穩定。這樣可以減少內部協變量偏移的影響,優化器(如SGD或Adam)在參數空間中的搜索路徑變得更加平滑,減少了梯度消失或梯度爆炸的風險,加速模型收斂。
- 更高的學習率:通過規范化輸入分布,增強了模型對學習率的魯棒性。如 w 1 w_1 w1?遠未達到最優,而 w 4 w_4 w4?(如5.8)已接近最優(如6),使用更高的學習率, w 4 w_4 w4?更新幅度(如0.9)較大的影響(如0.67)也不是很劇烈,從而整體進一步加速訓練。
- 正則化作用:使用小批量的統計信息均值和方差來歸一化數據,這引入了一定的噪聲,類似于Dropout的效果(但與Dropout不能共用),一定程度上起到了正則化的作用,可以減少過擬合。
全卷積的Anchor boxes(預選框): YOLOV2最后是通過全連接網絡直接預測目標位置,YOLOV2在YOLOV1基礎上進行了優化改造:
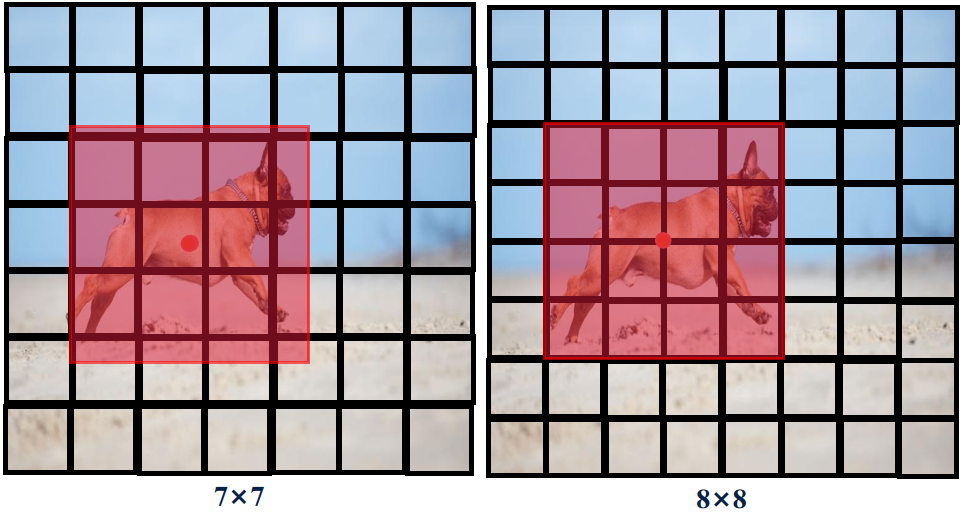
- 網絡模型的輸入大小由原來的448×448被替換成416×416。檢測任務中,目標物體通常出現在圖像中心,因此輸出特征圖的分辨率設定通常為奇數的(如7×7),否則,為偶數時(如8×8),物體的中心點很容易落在網格的角落,不容易確定歸屬那個小方格(四個小方格)。因此論文作者才更改模型的輸入尺寸。
- 移除最后一個池化層,去掉最后的全連接層部分,使得卷積層輸出更高分辨率特征圖;

- 利用預選框來預測目標的空間位置和類別。YOLOV1是直接預測出物體的檢測框大小和坐標,由于目標物體的大小不一,直接根據主干網絡提取的信息進行邊界檢測框大小和坐標的預測存在極大的困難。因此,YOLOV2則借鑒了Faster R-CNN和SSD的做法,基于現有的合理的預選框預測真實的邊界檢測框,相比YOLOV1直接預測檢測框難度大幅降低。

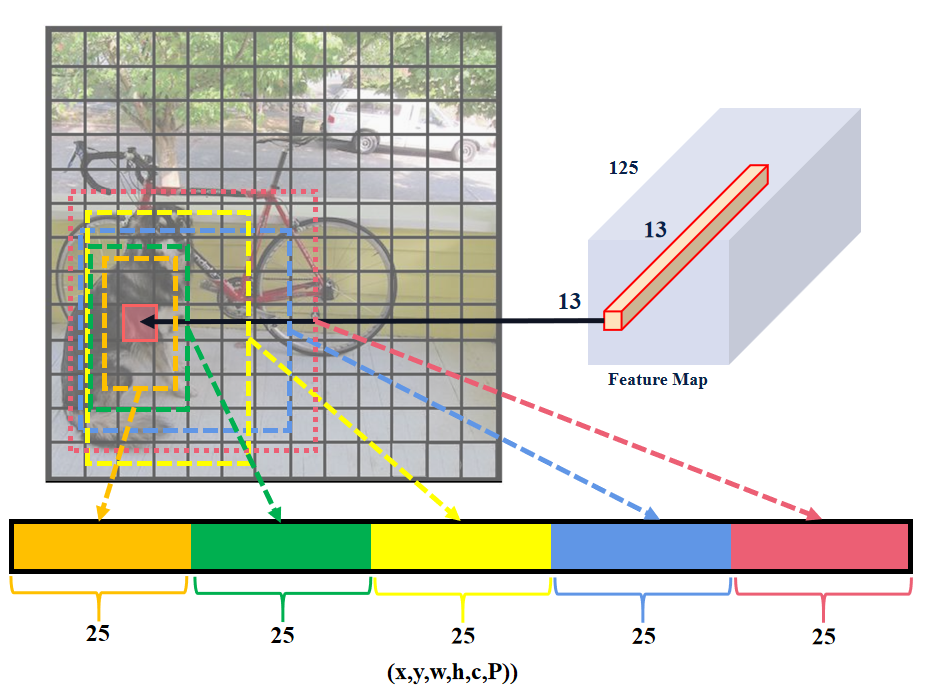
- 將分類和空間檢測解耦。YOLOV1每個網格單元的輸出深度是30: ( x , y , w , h , c ) × 2 + P {\rm{(x,y,w,h,c)}} \times {\rm{2}}+ P (x,y,w,h,c)×2+P,現在YOLOV2更改:為125: ( x , y , w , h , c , P ) × 9 {\rm{(x,y,w,h,c,P)}} \times {\rm{9}} (x,y,w,h,c,P)×9。YOLOV1中2個邊界檢測框綁定共用一個分類概率P,YOLOV2則是5個邊界檢測框都有獨立的分類概率P,意味著一個網格單元可以檢測多個類別。
后續的YOLOV3、YOLOV4以及YOLOV5都是基于anchor box進行預測的,三種尺寸(小128、中256、大512)和三種寬高比例(1:1、1:2、2:1)可以組合成3×3=9種不同的預選框。
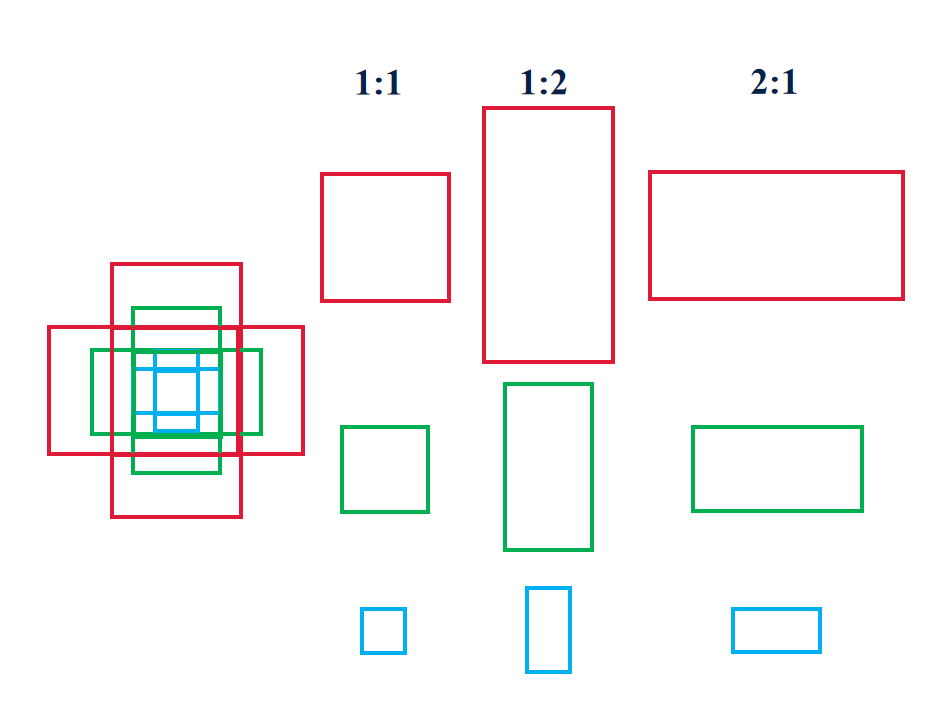
預選框–歐式距離聚類: YOLOV2引入Anchor boxes的過程中,相比人為指定Anchor boxes的尺寸比例,原作者提出了自動化的手段,在訓練數據集中使用k-means算法得到k個尺寸比例。
手選預選框尺寸,如果先驗尺寸分配合理,會加快學習的速度和效果;反之會影響學習的速度和效果。
K-means算法是一種廣泛應用于數據挖掘和機器學習領域的典型的基于距離(歐式距離、曼哈頓距離)聚類分析方法。采用距離作為相似性的評價指標,它的目標是將給定的數據集劃分為k個簇,其中每個簇的數據都盡可能相似,而不同簇的數據盡可能不同。“k”是用戶指定的參數,表示想要劃分出的簇的數量。【參考】
YOLOV2使用歐氏距離的K-mean算法獲得預選框的步驟如下:
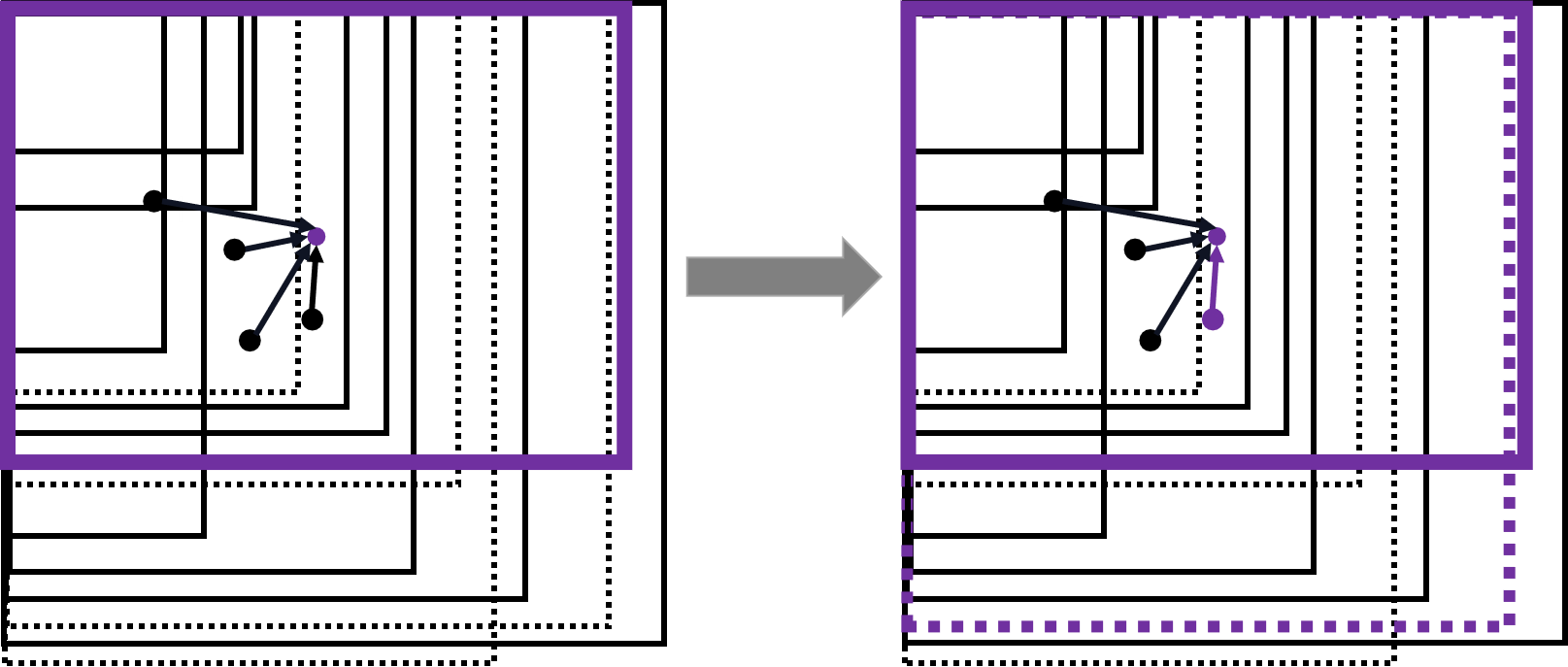
- 1.所有的真實框樣本都以左上角為基準點對齊,自定義簇類總數K(5個),并隨機選取K個樣本(彩色加粗框的中心點)作為簇中心;

- 2.分別計算所有樣本框到K個簇中心的歐式距離,即樣本框中心點 ( x i , y i ) (x_i,y_i) (xi?,yi?)到蔟中心點 ( x k j , y k j ) \left( {{{\rm{x}}_{{\rm{kj}}}}{\rm{,}}{{\rm{y}}_{{\rm{kj}}}}} \right) (xkj?,ykj?)的距離,下面展示部分樣本框(虛線框)的中心到某個蔟中心點的距離 d d d,樣本框中心離哪個蔟中心距離更近,就屬于個簇中心;
- 3.更新聚類中心,對于每個聚類,計算的所有樣本框的中心點的均值作為新的簇中心;
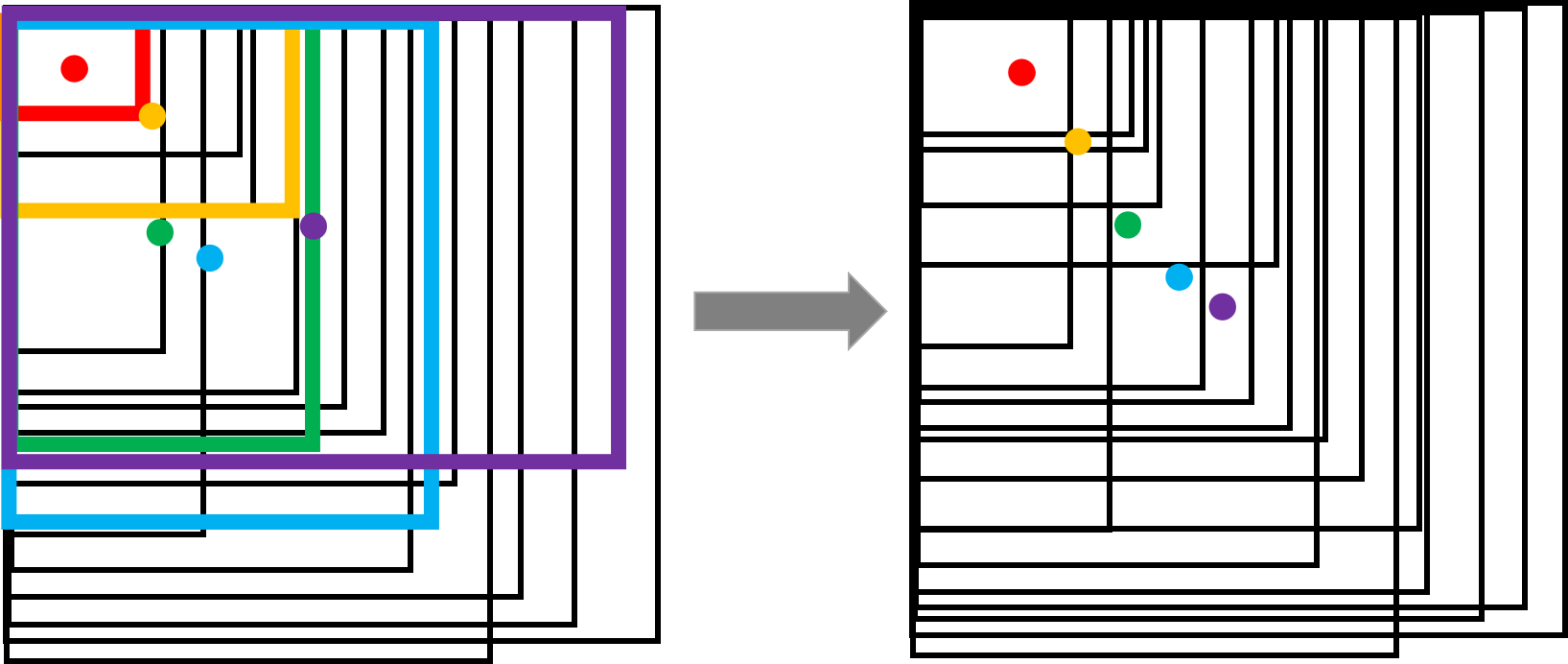
- 4.重復2和3,直到新的中心和原來的中心基本不變化,或者循環次數達到事先規定的次數時,算法結束。獲得合適的k個預選框,即根據各個簇中心到左上角對齊點的距離可以計算出預選框的寬高。

存在的問題: 在使用標準歐氏距離進行距離度量時,大真實框和小真實框之間的中心點距離差異導致誤差分布不均。核心在于尺度敏感性:對于尺寸較小的框而言,即使中心點的偏移相對很小,這個偏移相對于框的大小來說也是一個顯著的變化,如30×30和10×10的小框,中心點的距離是 ( 15 ? 5 ) 2 + ( 15 ? 5 ) 2 ≈ 14.1 \sqrt {{{(15 - 5)}^2} + {{(15 - 5)}^2}} \approx 14.1 (15?5)2+(15?5)2?≈14.1;相反,對于尺寸較大的框,同樣(相似)的中心點偏移只代表了較為微小的變化,如130×130和110×110的大框,中心點的距離是 ( 65 ? 55 ) 2 + ( 65 ? 55 ) 2 ≈ 14.1 \sqrt {{{(65 - 55)}^2} + {{(65 - 55)}^2}} \approx 14.1 (65?55)2+(65?55)2?≈14.1。因此,標準歐氏距離并沒有考慮框的尺寸差異,大真實框的聚類會比小真實框產生更多的誤差。這可能會導致大框被劃分到更多的簇,而中小框則被只劃分到極少的簇。假設k等于5的情況下,大的box被分成4個簇,而中小的box被分到一個簇中。
預選框–IoU聚類(改進): 為了消除歐式距離對聚類的影響,尋找合理的預選框,利用IoU來進行聚類的評判指標:
d ( b o x , c e n t r o i d ) = 1 ? I O U ( b o x , c e n t r o i d ) d(box,centroid){\rm{ }} = {\rm{ }}1 - IOU(box,centroid) d(box,centroid)=1?IOU(box,centroid)
改進后,YOLOV2使用IoU距離的K-mean算法獲得預選框的步驟如下:
-
1.所有的真實框樣本都以中心點為基準點對齊,自定義簇類總數K(5個),并隨機選取K個樣本(彩色加粗框的)作為簇中心框;

-
2.分別計算所有樣本框與K個簇中心的 I o U IoU IoU,根據樣本框與蔟中心框的 I o U IoU IoU計算距離 d d d,下面展示部分樣本框(虛線框)的中心到某個蔟中心點的距離 d d d,樣本框中心離哪個蔟中心距離更近,就屬于個簇中心框;
同樣使用 I o U IoU IoU距離進行距離度量,30×30和10×10的小框的距離是 1 ? ( 10 × 10 ) ( 30 × 30 ) ≈ 0 . 89 {\rm{1 - }}\frac{{\left( {10 \times {\rm{10}}} \right)}}{{\left( {30 \times 30} \right)}} \approx {\rm{0}}{\rm{.89}} 1?(30×30)(10×10)?≈0.89;130×130和110×110的大框的距離是 1 ? ( 110 × 110 ) ( 130 × 130 ) ≈ 0 . 28 {\rm{1 - }}\frac{{\left( {110 \times {\rm{110}}} \right)}}{{\left( {130 \times 130} \right)}} \approx {\rm{0}}{\rm{.28}} 1?(130×130)(110×110)?≈0.28。可以發現,使用 I o U IoU IoU距離進行距離度量更合理。

-
- 更新聚類中心:對于每個聚類,計算所有分配給它的標注框的平均寬度和高度,并將這些平均值作為新的聚類中心的尺寸。
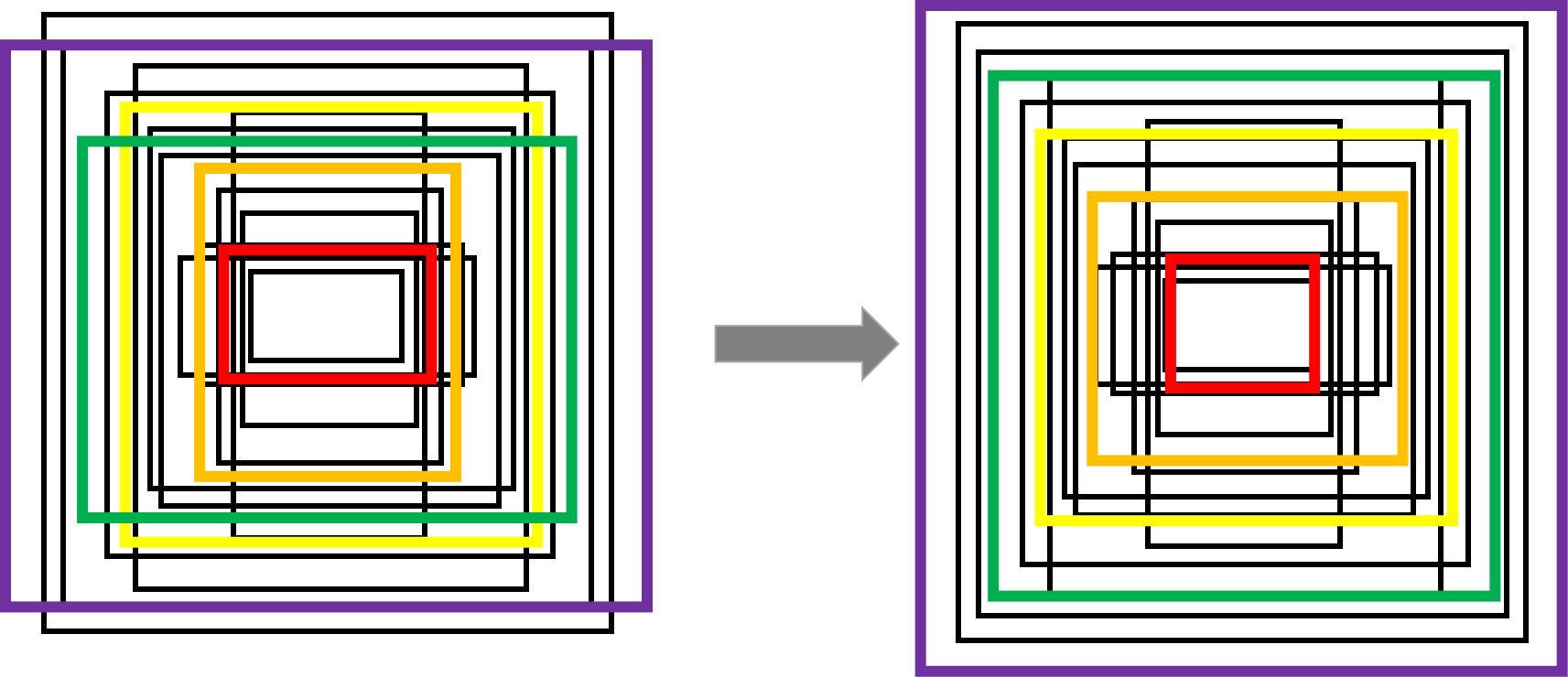
- 更新聚類中心:對于每個聚類,計算所有分配給它的標注框的平均寬度和高度,并將這些平均值作為新的聚類中心的尺寸。
-
4.重復2和3,直到新的中心框和原來的中心框基本不變化,或者循環次數達到事先規定的次數時,算法結束。獲得合適的k個預選框。
需要注意的是,預選框聚類算法的目標是選擇一組適合于數據集的先驗框尺寸,以便在目標檢測任務中能夠更好地適應不同大小的目標。聚類算法根據數據集中目標的分布來自動確定先驗框的尺寸,以提高檢測的準確性和效果。
論文作者在VOC2007數據集(黑色)和COCO數據集(藍色)中,嘗試了1~15個聚類數,最后發現5個(拐點)是最合理的,因為5之后曲線上升變緩了:

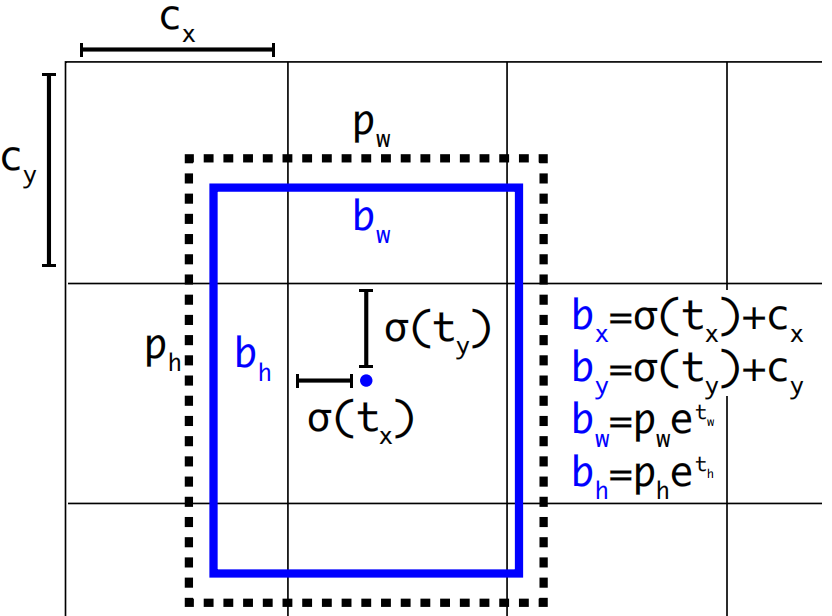
位置預測: YOLOV2借鑒了RPN網絡利用預選框來預測邊界框相對預選框之間的誤差補償(offsets),預測邊界框位置(中心點)在所屬網格單元左上角位置進行相對偏移值,預測邊界框尺寸基于所對應的預選框寬高進行相對縮放:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{array}{l} {b_x} = \sigma ({t_x}) + {c_x}\\ {b_y} = \sigma ({t_y}) + {c_y}\\ {b_w} = {p_w}{e^{{t_w}}}\\ {b_h} = {p_h}{e^{{t_h}}} \end{array} bx?=σ(tx?)+cx?by?=σ(ty?)+cy?bw?=pw?etw?bh?=ph?eth??
使用sigmoid函數處理偏移值,將邊界框中心點約束在所屬網格單元中,網格單元的尺度為1,而偏移值在(0,1)范圍內,防止過度偏移。
( c x , c y ) ({c_x},{c_y}) (cx?,cy?)是網格單元的左上角坐標, p w p_w pw?和 p h p_h ph?是預選框的寬度與高度, e t w e^{{t_w}} etw?和 e t h e^{{t_h}} eth?則沒有過多約束是因為物體的大小是不受限制的。
RPN網絡方法: 預測邊界框的實際中心位置 ( x , y ) ({\rm{x,y}}) (x,y)是需要根據預測的縮放值 ( d x , d y ) ({\rm{d}}_x{\rm{,d}}_y) (dx?,dy?),以及預選框的尺寸 ( w a , h a ) ({w_a}{\rm{,}}{h_a}) (wa?,ha?)計算而來:
x = x a + ( d x × w a ) y = y a + ( d y × h a ) \begin{array}{l} x = {x_a} + ({d_x} \times {w_a})\\ y = {y_a} + ({d_y} \times {h_a}) \end{array} x=xa?+(dx?×wa?)y=ya?+(dy?×ha?)?
x a x_a xa?和 y a y_a ya?是預選框的中心點, x x x和 y y y是預測框的中心點。但是這種方式計算的偏移值 d x × w a {d_x} \times {w_a} dx?×wa?是無約束的,預測邊界框很容易在任何方向上大范圍偏移,每個位置預測的邊界框可以落在圖片任何位置,這導致模型的不穩定性,需要很長時間訓練出正確的offsets。

直通層Passthrough: 將淺層特征圖與深層特征圖進行融合。輸入圖像經過多層網絡提取特征,最后輸出的特征圖中較小的對象特征已經不再明顯,甚至被忽略掉了。為了更好的檢測出較小的對象,最后輸出的特征圖需要保留一些淺層特征圖的細節信息。
Passthrough具體操作:提取Darknet-19最后一個池化層的26×26×512的輸入特征圖,經過passthrough處理變成4個13×13×256的特征圖,再與Darknet-19輸出的13×13×1024的特征圖連接變成13×13×3072的特征圖,最后在這個特征圖上做預測。
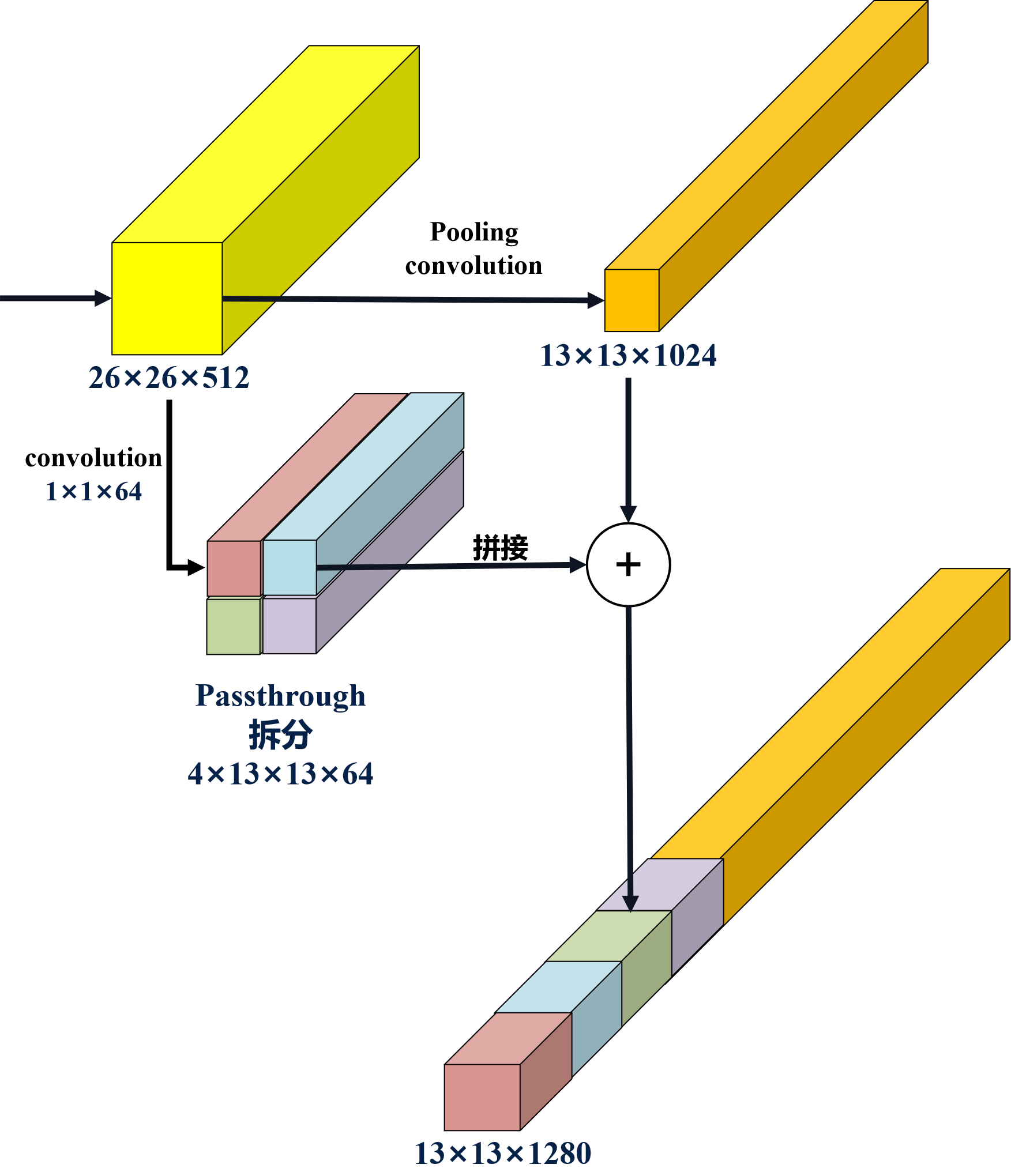
特征圖拆分成四塊的方式:抽取原特征圖每個2×2的局部區域組成新的特征圖,原特征圖大小降低4倍,通道數增加4倍。

完整版Darknet-19-檢測模型:新增了3個3x3x1024卷積層,同時增加了1個passthrough層,最后使用1x1卷積層輸出預測結果。
多尺度訓練: YOLOV2模型只使用卷積層和池化層,因此可以實時調整大小,因此應用多尺度訓練(輸入圖像尺寸動態變化),讓模型能夠魯棒地運行在不同尺寸的圖像上。訓練過程中,每10個批次,網絡就會隨機選擇一個新的圖像尺寸。

由于YOLOV2模型縮減了32倍,因此圖像尺寸范圍都是32的倍數 ( 320 , 352 , … , 608 ) (320, 352, …, 608) (320,352,…,608),最小的選項是320×320,最大的是608×608。圖像尺寸越大,計算量越大,速度越慢,mAP越大。

反向傳播階段
損失函數: YOLOV2的損失函數公式為:
L o s s t = ∑ i = 0 W ∑ j = 0 H ∑ k = 0 A ( 1 M a x I O U < T h r e s h λ n o o b j ( ? b i j k o ) 2 + 1 t < 12800 λ p r i o r ∑ r ∈ ( x , y , w , h ) ( p r i o r k r ? b i j k r ) 2 + 1 k t r u t h ( λ c o o r d ∑ r ∈ ( x , y , w , h ) ( t r u t h r ? b i j k r ) 2 + λ o b j ( I O U t r u t h r ? b i j k o ) 2 + λ c l a s s ∑ c = 1 C ( t r u t h c ? b i j k c ) 2 ) ) Los{s_{\rm{t}}} = \sum\limits_{{\rm{i = 0}}}^W {\sum\limits_{{\rm{j = 0}}}^H {\sum\limits_{{\rm{k = 0}}}^A {\left( {{1_{MaxIOU < Thresh}}{\lambda _{noobj}}{{\left( { - b_{ijk}^o} \right)}^2} + {1_{t < 12800}}{\lambda _{prior}}{{\sum\limits_{r \in (x,y,w,h)} {\left( {prior_k^r - b_{ijk}^r} \right)} }^2} + 1_k^{truth}\left( {{\lambda _{coord}}{{\sum\limits_{r \in (x,y,w,h)} {\left( {trut{h^r} - b_{ijk}^r} \right)} }^2} + {\lambda _{obj}}{{\left( {IOU_{truth}^r - b_{ijk}^o} \right)}^2} + {\lambda _{class}}{{\sum\limits_{c = 1}^C {(trut{h^c} - b_{ijk}^c)} }^2}} \right)} \right)} } } Losst?=i=0∑W?j=0∑H?k=0∑A? ?1MaxIOU<Thresh?λnoobj?(?bijko?)2+1t<12800?λprior?r∈(x,y,w,h)∑?(priorkr??bijkr?)2+1ktruth? ?λcoord?r∈(x,y,w,h)∑?(truthr?bijkr?)2+λobj?(IOUtruthr??bijko?)2+λclass?c=1∑C?(truthc?bijkc?)2 ? ?
- ∑ i = 0 W ∑ j = 0 H \sum\limits_{{\rm{i = 0}}}^W {\sum\limits_{{\rm{j = 0}}}^H {} } i=0∑W?j=0∑H?表示遍歷所有網格單元并進行累加;
- ∑ k = 0 A {\sum\limits_{{\rm{k = 0}}}^A {} } k=0∑A?表示遍歷所有預測邊界框并進行累加;
背景置信度損失: 如果預測框中的是背景(標簽為0),則預測框的置信度盡可能等于0:
1 M a x I O U < T h r e s h λ n o o b j ( ? b i j k o ) 2 {{1_{MaxIOU < Thresh}}{\lambda _{noobj}}{{\left( { - b_{ijk}^o} \right)}^2}} 1MaxIOU<Thresh?λnoobj?(?bijko?)2
- 1 M a x I O U < T h r e s h {{1_{MaxIOU < Thresh}}} 1MaxIOU<Thresh?作為是否是背景的判定條件:計算當前預測框和所有真實框的IOU,假設IOU最大的值MaxIOU小于指定閾值,該預測框就標記為背景;
- λ n o o b j {{\lambda _{noobj}}} λnoobj?表示縮放系數,值為1;
- b b b表示預測框,上標表示預測框具體信息,根據下標表示預測框具體序號;
- b i j k o b_{ijk}^o bijko?預測框,上標 o o o表示置信度,即是物體的概率。
預選框和預測框的損失: 預選框是從訓練集中聚類得來,在訓練前期快速學習到預選框的形狀。保證模型輸出的預測框比較合理。
1 t < 12800 λ p r i o r ∑ r ∈ ( x , y , w , h ) ( p r i o r k r ? b i j k r ) 2 {{1_{t < 12800}}{\lambda _{prior}}{{\sum\limits_{r \in (x,y,w,h)} {\left( {prior_k^r - b_{ijk}^r} \right)} }^2}} 1t<12800?λprior?r∈(x,y,w,h)∑?(priorkr??bijkr?)2
- 1 t < 12800 {{1_{t < 12800}}} 1t<12800?表示只在前12800批次內計算,目的是在訓練前期使預測框快速學習到 預選框的形狀;
- λ p r i o r {{\lambda _{prior}}} λprior?表示縮放系數,值為0.01;
- p r i o r k r prior_k^r priorkr?預選框,上標 r ∈ ( x , y , w , h ) r \in (x,y,w,h) r∈(x,y,w,h)表示坐標和寬高;
- b i j k r b_{ijk}^r bijkr?預測框,上標 r ∈ ( x , y , w , h ) r \in (x,y,w,h) r∈(x,y,w,h)表示坐標和寬高。
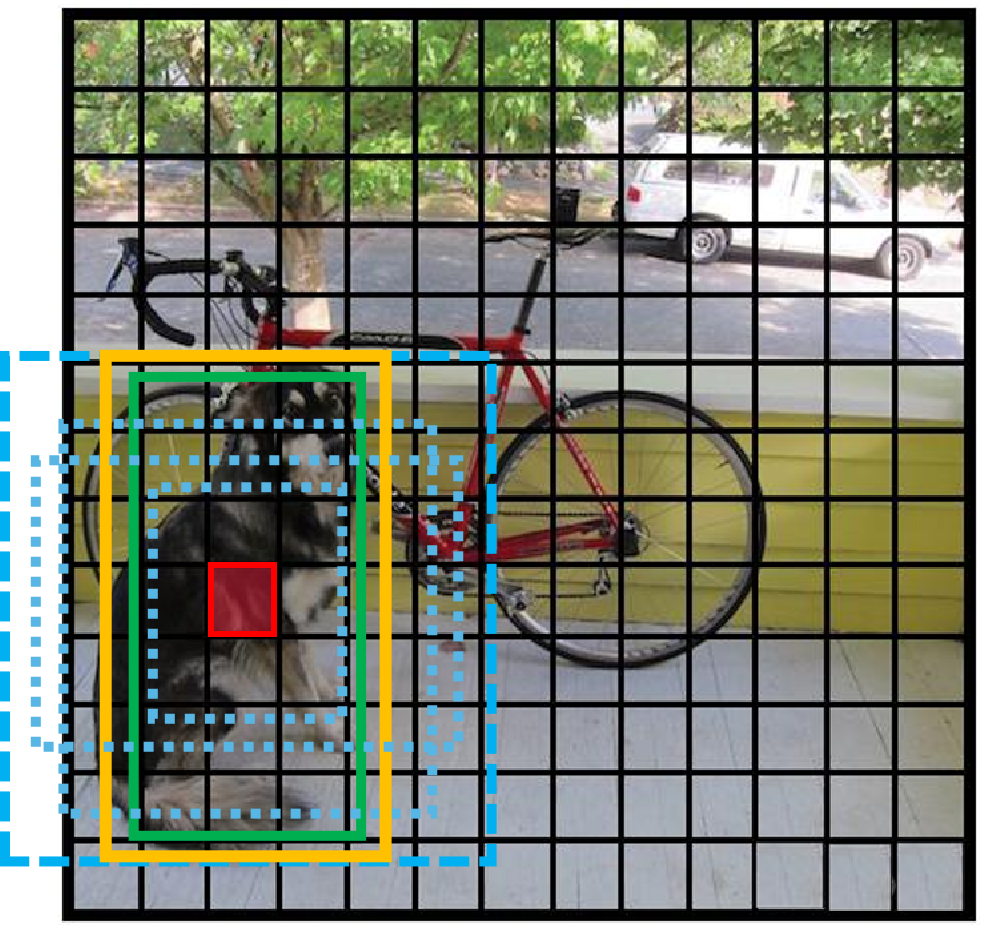
預選框和真實框的損失: 預測框中有物體的損失,包括坐標損失,置信度損失以及分類損失。
1 k t r u t h ( λ c o o r d ∑ r ∈ ( x , y , w , h ) ( t r u t h r ? b i j k r ) 2 + λ o b j ( I O U t r u t h r ? b i j k o ) 2 + λ c l a s s ∑ c = 1 C ( t r u t h c ? b i j k c ) 2 ) {1_k^{truth}\left( {{\lambda _{coord}}{{\sum\limits_{r \in (x,y,w,h)} {\left( {trut{h^r} - b_{ijk}^r} \right)} }^2} + {\lambda _{obj}}{{\left( {IOU_{truth}^r - b_{ijk}^o} \right)}^2} + {\lambda _{class}}{{\sum\limits_{c = 1}^C {(trut{h^c} - b_{ijk}^c)} }^2}} \right)} 1ktruth? ?λcoord?r∈(x,y,w,h)∑?(truthr?bijkr?)2+λobj?(IOUtruthr??bijko?)2+λclass?c=1∑C?(truthc?bijkc?)2 ?
- 1 k t r u t h {1_k^{truth}} 1ktruth? 表示匹配到真實框的預測框,一個真實框只匹配一個預測框;
計算真實框(橙色實線)位于那個網格單元,將對應網格單元中所有預測框(藍色虛線)與真實框中心對齊(只考慮形狀不考慮坐標位置),在IoU大于閾值的預測框中選擇IoU最大的預測框(綠色實線),其他IoU大于閾值的預測框舍棄,小于閾值的預測框計算置信度損失。
- λ c o o r d {{\lambda _{coord}}} λcoord?表示定位損失的縮放系數,值為1;
- t r u t h r {trut{h^r}} truthr真實框,上標 r ∈ ( x , y , w , h ) r \in (x,y,w,h) r∈(x,y,w,h)表示坐標和寬高;
- b i j k r b_{ijk}^r bijkr?預測框,上標 r ∈ ( x , y , w , h ) r \in (x,y,w,h) r∈(x,y,w,h)表示坐標和寬高;
- λ o b j {{\lambda _{obj}}} λobj?表示置信度損失的縮放系數,值為5;
- I O U t r u t h r {IOU_{truth}^r} IOUtruthr?表示匹配到真實框與預測框的IoU;
- b i j k o b_{ijk}^o bijko?預測框,上標 o o o表示置信度;
- λ c l a s s {{\lambda _{class}}} λclass?表示分類損失的縮放系數,值為1;
- t r u t h c {trut{h^c}} truthc真實框,上標 c c c表示類別;
- b i j k c b_{ijk}^c bijkc?預測框,上標 c c c表示類別。
總結
盡可能簡單、詳細的介紹了YOLOV2模型的結構,深入講解了YOLOV2核心思想。

——個人理解篇5(梯度下降中遇到的問題))






 | 零基礎入門STM32第九十五步)










