粗排
在推薦系統鏈路中,排序階段至關重要,通常分為召回、粗排和精排三個環節。粗排作為精排前的預處理階段,需要在效果和性能之間取得平衡。

雙塔模型
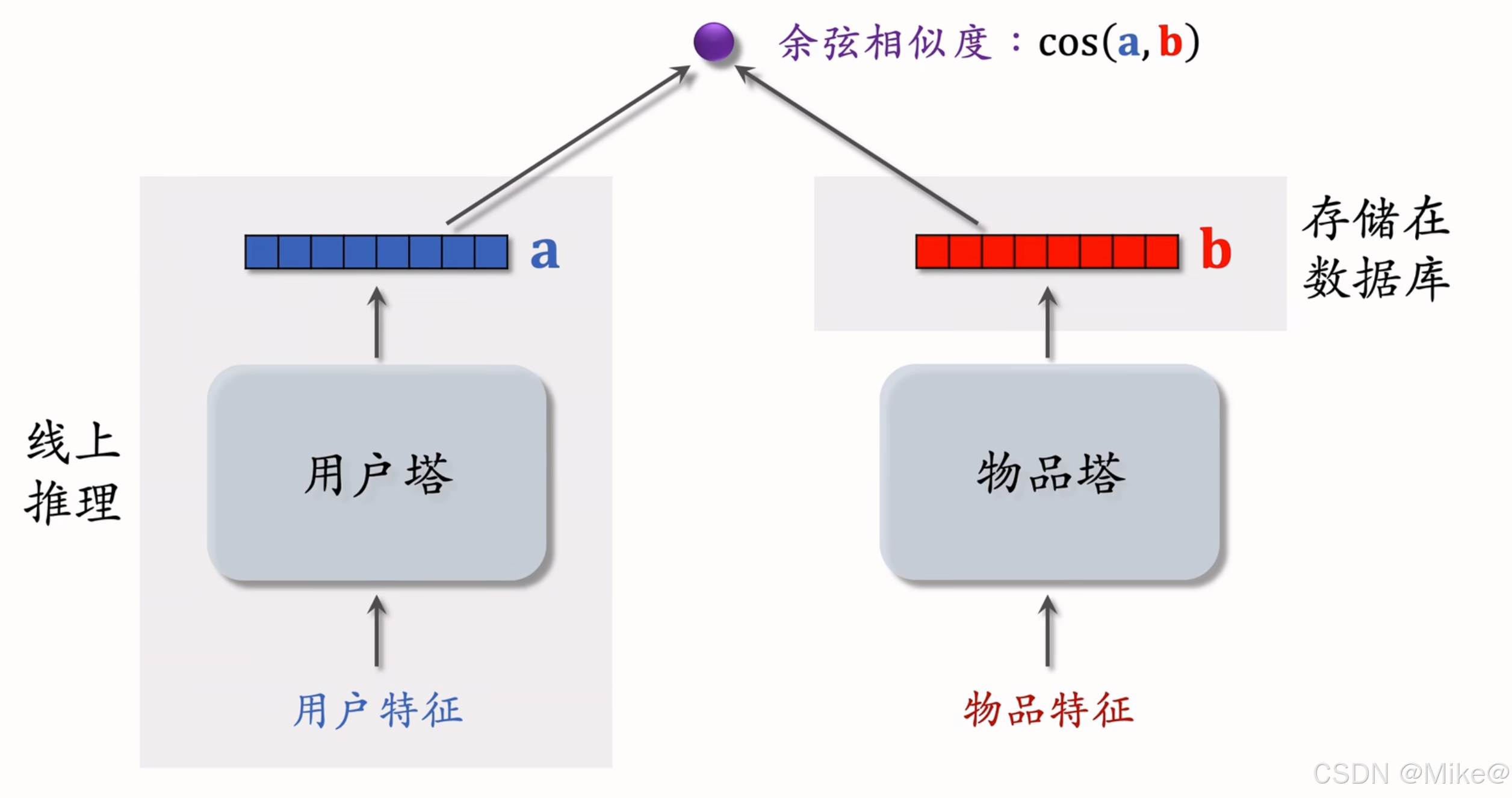
- 后期融合:把用戶、物品特征分別輸入不同的神經網絡,不對用戶、物品特征做融合
- 線上計算量小:
- 用戶塔只需要做一次線上推理,計算用戶表征a
- 物品表征b事先儲存在向量數據庫中,物品塔在線上不做推理。
- 預估準確性不如精排模型。
三塔模型
阿里巴巴2020年論文《COLD: Towards the Next Generation of Pre-Ranking System》(Zhe Wang et al., DIP.KDD 2020)的核心思想
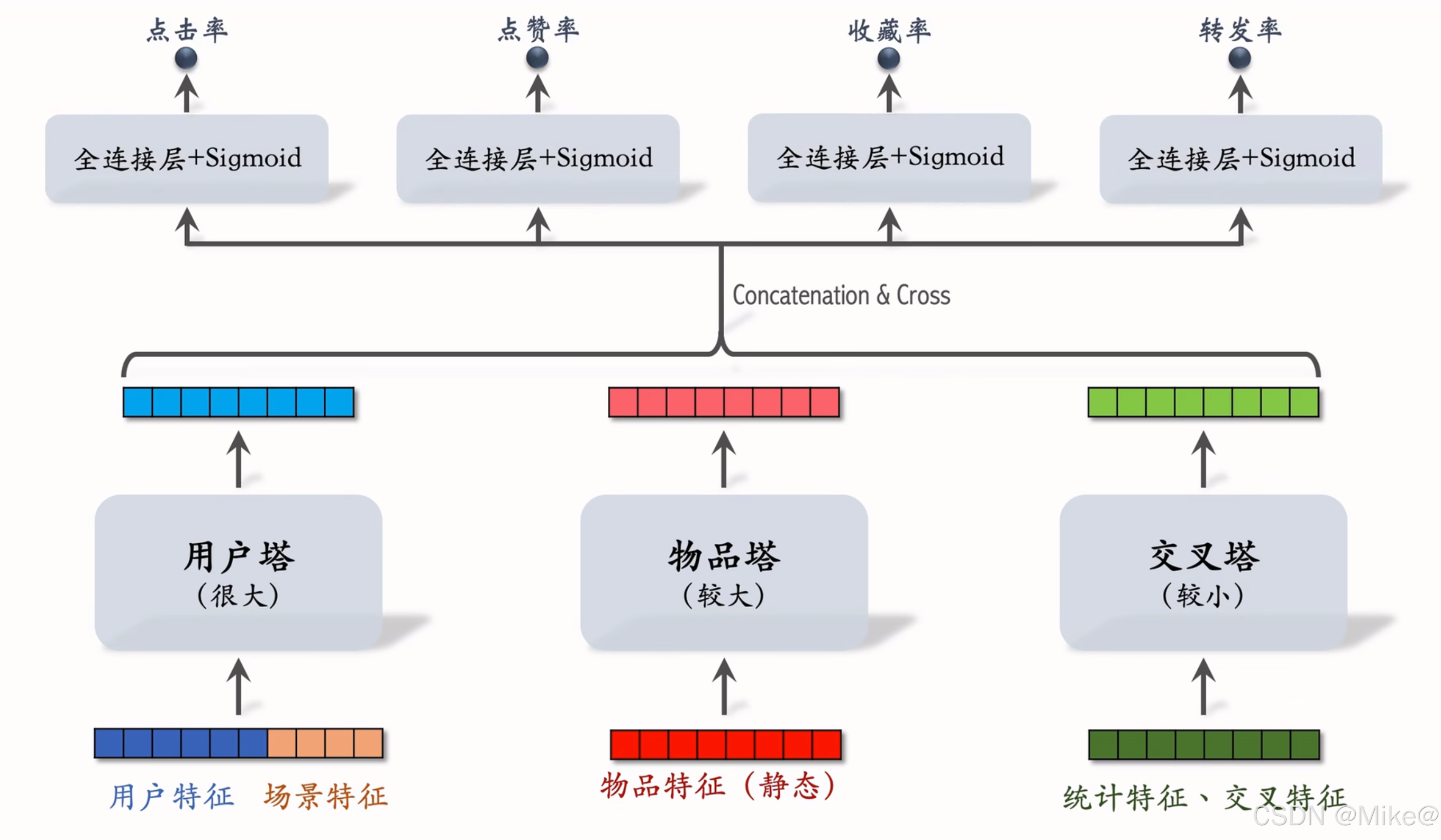
-
用戶塔(很大)
- 用戶特征和場景特征
- 每次只有一個用戶,用戶塔只作一次推理,即使用戶塔很大,總計算量也不大
-
物品塔(較大)
- 物品特征(靜態)
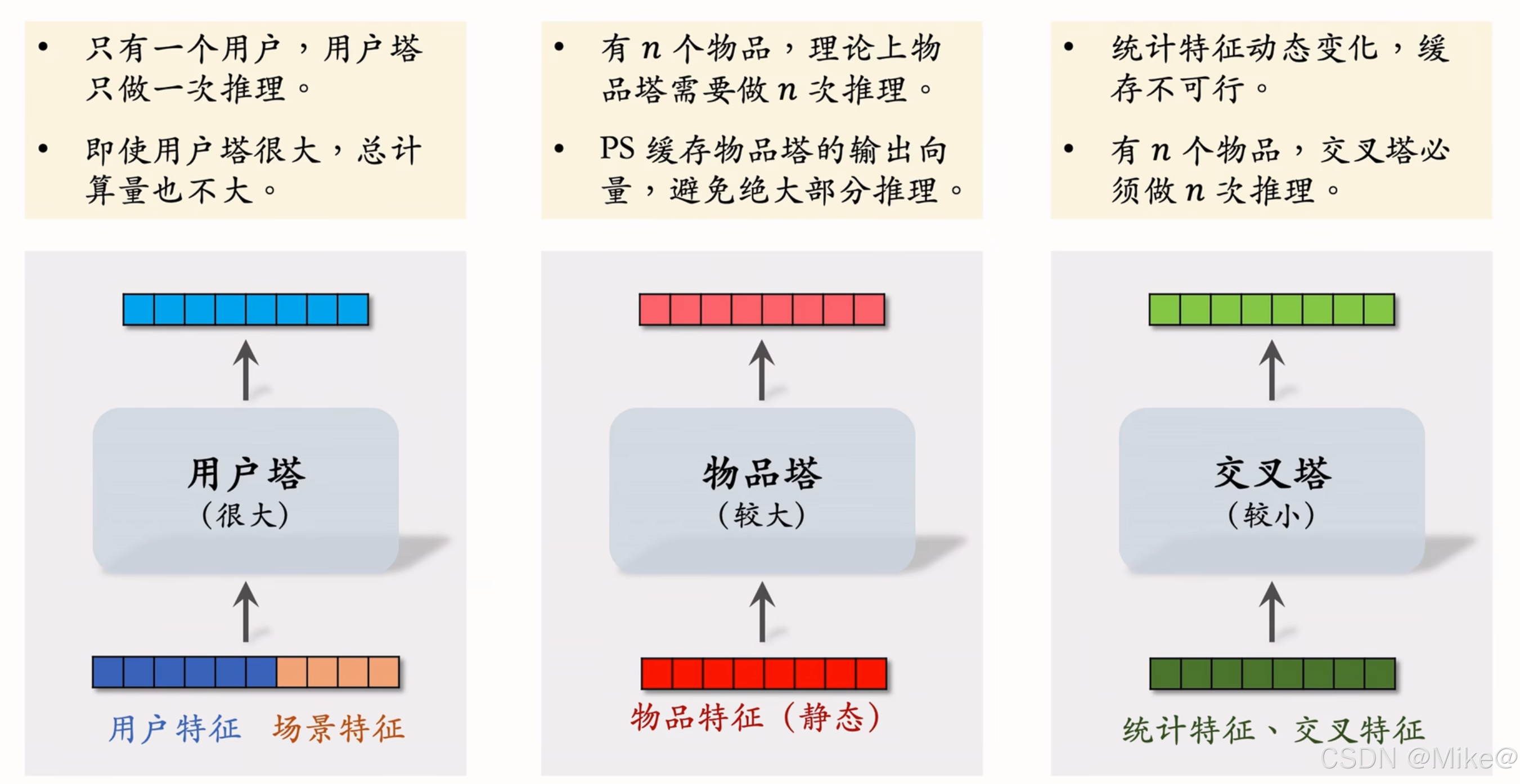
- 有n個物品,理論上物品塔需要做n次推理,PS緩存物品塔的輸出向量,避免絕大部分推理,
- 由于用到緩存,物品塔只需要在遇到新物品的時候才需要計算,粗排給幾千個物品打分,粗排只需要給幾十個進行推理,物品塔規模可以比較大
-
交叉塔(較小)
- 統計特征,交叉特征(用戶特征與物品特征做交叉)
- 統計特征動態變化,比如用戶的點擊率,物品的被點擊量,緩存不可行。
- 有n個物品,交叉塔必須做n次推理,線上推理避免不掉,所以交叉塔必須足夠小,計算夠快,通常只有幾層,寬度也比較小。,
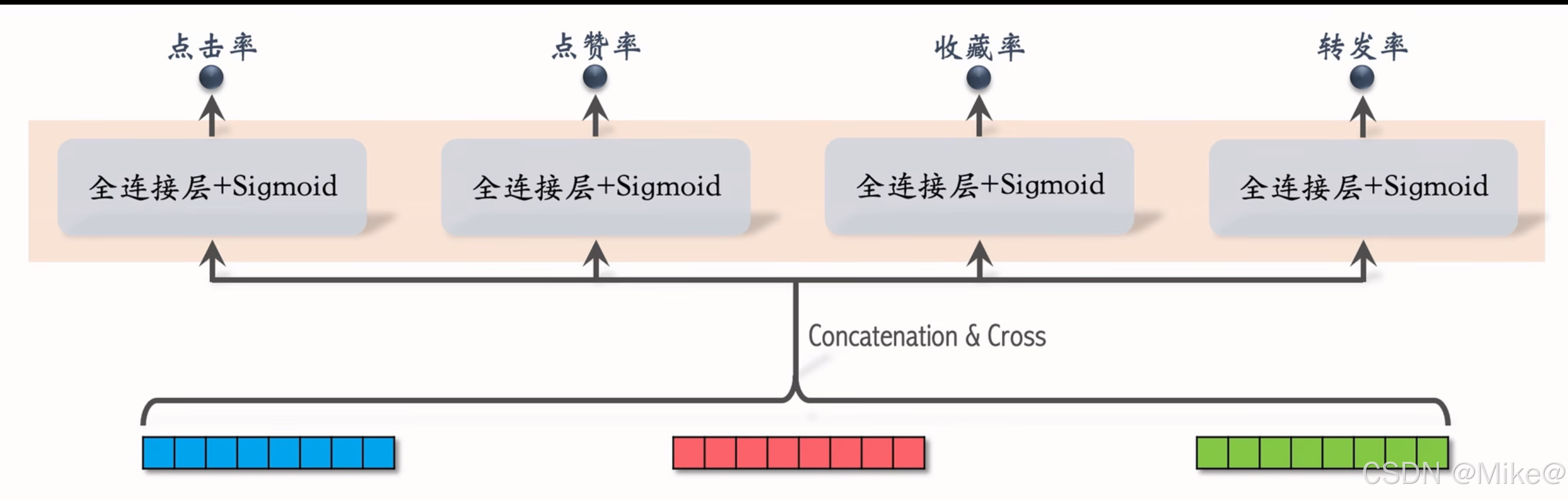
- 粗排上層介紹
- 有n個物品,模型上層需要做n次推理。
- 粗排推理的大部分計算都在模型上層
三塔模型的推理
- 從多個數據源提取特征:
- 1個用戶的畫像、統計特征
- n個物品的畫像、統計特征
- 用戶塔:只做1次推理
- 物品塔:實現緩存,未命中時需要做推理。實際上緩存命中率非常高
- 交叉塔:必須做n次推理(統計特征都是動態特征)
- 上層網絡必須做n次推理,給n個物品打分。
精排模型的特征體系
用戶畫像
- 用戶ID:
- 人口統計屬性:年齡、性別等基本信息
- 用戶賬號信息:新老、活躍度等等(模型需要對新用戶、低活用戶做優化)
- 感興趣的類目、關鍵詞、品牌(可以用是用戶填寫,也可以是算法自動提取,用戶興趣的信息對于排序是非常有幫助的)
物品畫像
現在業界的推薦系統都會使用用戶畫像和物品畫像
- 物品ID(在召回、排序做Embedding)
- 發布時間(或年齡),發布時間越久,價值越低
- GeoHash(經緯編碼)、所在城市
- 標題、類目、關鍵詞、品牌,通常做法是做Embedding
- 字數、圖片數、視頻清晰度、標簽數
- 內容信息量、圖片美學(算法打分),事先使用人工標注的數據集訓練cv和nlp模型,利用這些模型把內容信息量、圖片美學這些分數寫入物品畫像中
用戶統計特征
- 用戶30天(7天、1天、1小時)的曝光數、點擊數、點贊數、收藏數等,各種時間粒度反應用戶的興趣,長期、中長期和短期。
- 按照筆記圖文/視頻分桶(比如最近7天,該用戶對圖片的點擊率、對視頻筆記的點擊率)
- 按照筆記類目分桶。(比如30天。用戶對美妝筆記的點擊率、對美食筆記的點擊率、對數碼科技筆記的點擊率)。可以反應用戶對哪些類目更感興趣,如果一個用戶對美食筆記的點擊量和點擊率等指標都偏高。說明這個用戶對美食類目感興趣
筆記統計特征
- 筆記 30天(7天、1天、1小時)的曝光數、點贊數、收藏數等指標,反應筆記的受歡迎程度,使用不同的粒度也是有道理的,某些筆記30天的點擊率都很高,但是最近一天指標變得很差,說明這些筆記已經過時了,不應該給過多流量
- 按用戶性別分桶、按照用戶年齡、地域分桶
- 作者的統計特征
- 發布的筆記數量
- 粉絲數
- 消費指標(曝光數、點擊數、點贊數、收藏數)(反應作者受歡迎程度和平均筆記質量)
場景特征
- 用戶定位GeoHash(經緯度編碼)、城市(對召回和排序都有用,用戶可能對自己周圍發生的事情比較感興趣)
- 當前時刻(分段做Embedding),一個人在一天不同時刻的興趣可能有所區別,在上班路上和晚上睡覺
- 是否周某,是否節假日
- 設備信息:手機品牌、手機型號、操作系統
特征處理
-
離散特征做Embedding
-
用戶ID、筆記ID、作者ID。(幾千萬、幾億級別)
-
類目、關鍵詞、城市、手機品牌 (筆記的類目也就幾百個,關鍵詞就幾百萬個,給他們做embedding比較容易,消耗內存也不多)
-
-
連續特征:分桶變成離散特征
- 年齡(10個年齡段、one-hot)或者Embedding,筆記長度、視頻長度
-
連續特征:其他變換
- 曝光數、點擊數、點贊數等數值做 log?(1+x)\log (1+x)log(1+x)
- 轉化為點擊率、點贊率等指標,并做平滑處理
特征覆蓋率
- 很多特征無法覆蓋100%樣本,存在缺失
- 很多用戶注冊的時候不填寫年齡,因此用戶年齡特征的覆蓋率遠小于100%
- 例:很多用戶設置隱私權限,APP 不能獲得用戶地理定位,因此場景特征有缺失。
- 做特征工程需要提高特征覆蓋率,讓排序模型更準,需要考慮當特征缺失的時候要用什么作為默認值
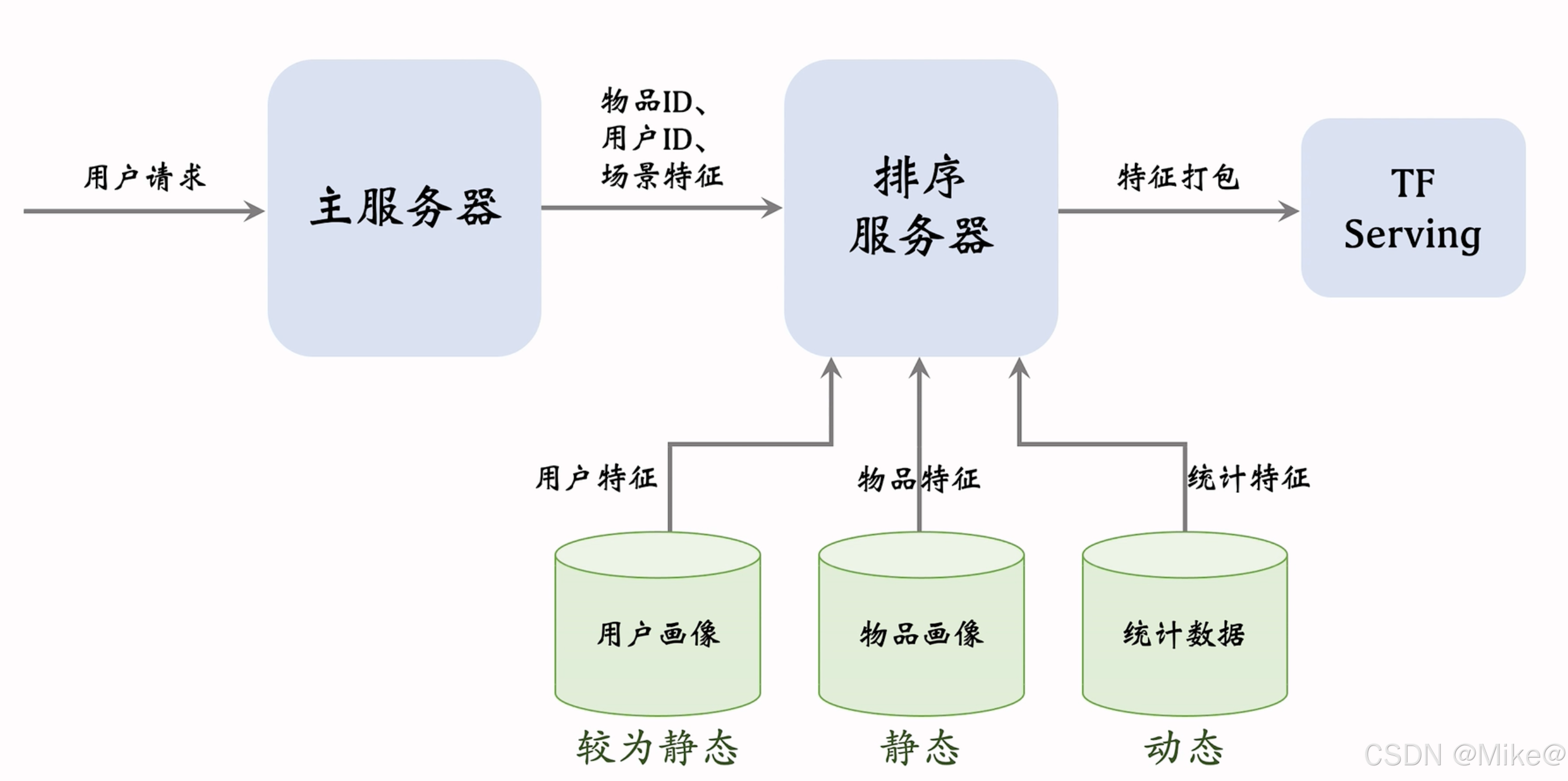
數據服務
排序服務器會從是三個數據源取回所需要的數據
- 用戶畫像(User Profile)
- 物品畫像(Item profile)
- 統計數據
用戶發送請求給主服務器,主服務器發生召回請求給召回服務器,召回服務器把幾千個召回結果發回主服務器,主服務器把物品ID、用戶ID、場景特征(用戶地點、當前時刻、是否節假日、手機型號,操作系統)發往排序服務器。排序服務器從三個源中獲取 用戶畫像、物品畫像、統計數據。排序服務器把特征打包傳遞給TF serving tensorflow會給筆記打分,把分數返回給排序服務器,排序服務會用排序融合分數,業務規則給筆記做排序。把排名最高的幾十篇筆記返回給主服務器
- 用戶畫像壓力比較小,每次只提取一個用戶
- 物品畫像壓力比較大,粗排要給幾千筆記做排序,讀取幾千筆記的特征
- 存用戶統計的壓力小,存物品統計的壓力很大
- 在工程實現里,用戶畫像可以存的很長很大,但是盡量不要在物品畫像存很大向量,否則物品畫像會承受很大的壓力
- 用戶畫像較為靜態,只需要天刷新就好,物品畫像則是靜態,算法給物品內容打分基本不變,這兩類讀取需要快,有時候可以把物品畫像和用戶畫像緩存在排序服務器本地
- 但是不能把統計數據緩存,統計數據是動態變化的,實效性很強 ,用戶刷了5篇筆記,用戶點擊,點贊等統計量都發生了變化,要盡快刷新數據庫
Reference
王樹森 推薦系統

)




)


工程文件結構)


 - 解題思路 + Golang實現)
:數據預處理)
》)




