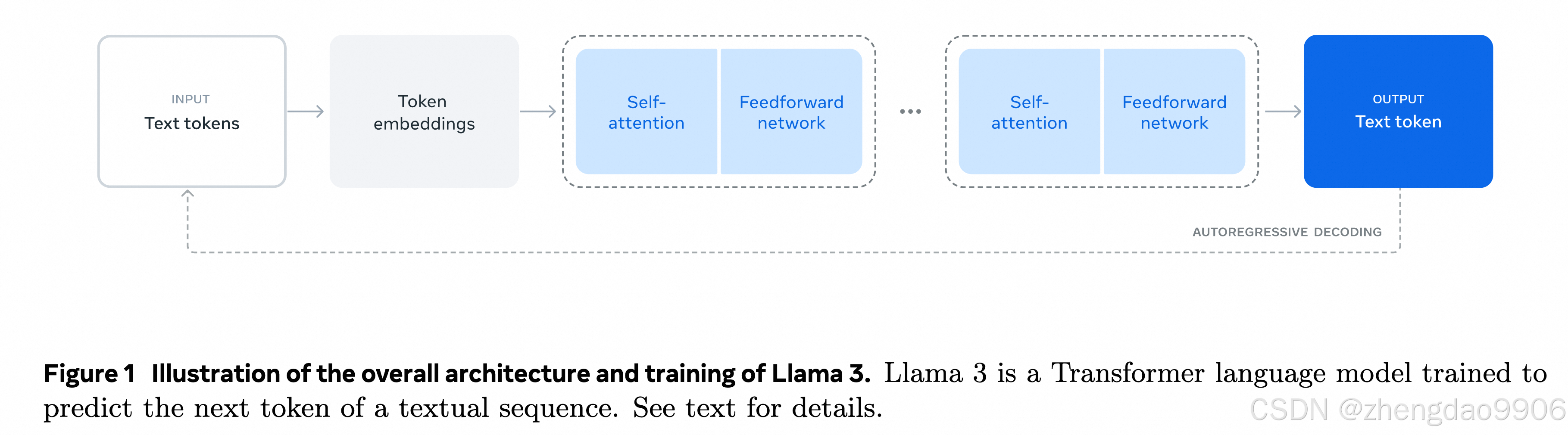
Llama 3中的頂級模型是一個擁有4050億參數的密集Transformer模型,并且它的上下文窗口長度可以達到128,000個tokens。這意味著它能夠處理非常長的文本,記住和理解更多的信息。Llama 3.1的論文長達92頁,詳細描述了模型的開發階段、優化策略、模型架構、性能比較、新功能等。

pre-train(預訓練階段)
訓練的兩個階段,第一個階段是預訓練做詞語預測或者文章總結;第二個階段是后訓練用來做模型的微調,或者是人類偏好對齊。
pre-train(預訓練階段)
模型的預訓練分多階段,第一個階段是初始化的預訓練,第二階段是長上下文預訓練,第三階段是退火模擬。
初始化
● 模型在訓練的初始階段,學習率從一個較低的值逐漸增加(稱為線性預熱)
● 為了提高訓練的穩定性,在訓練初期使用較小的批次大小。在訓練過程中,為了提高效率,逐步增大批次大小。
● 增加非英語數據、數學數據、網絡數據減少了那些在訓練過程中被識別為低質量的數據子集(交叉熵自動計算&人工標注網站)。
長序列訓練
● 目標:最終的預訓練目標是讓模型能夠處理長達128K(128,000)個tokens的上下文序列。
● 逐步增加上下文長度:為了讓模型逐漸適應更長的上下文長度,預訓練過程中按階段逐步增加序列長度。每個階段會先讓模型在新的序列長度下進行預訓練,直到模型適應這個新的長度。
● 成功適應的評估:模型能夠完美解決在這個長度下的“needle in a haystack”(大海撈針)任務。這種任務是指在很長的文本中找到特定的信息或答案。
● 最后階段的長序列預訓練使用了大約8000億(800B)個訓練tokens。
模擬退火
● 預訓練過程的最后階段:在預訓練的最后階段,使用了 4000 萬個文本標記(tokens)來訓練模型。
● 學習率(模型在每次迭代中調整其參數的速度)被線性下降到 0。也就是說,訓練開始時學習率較高,然后逐漸降低,直到最后完全停止調整。
● 模型檢查點的平均:在學習率逐漸降低的過程中,使用了一種叫做“Polyak 平均”的方法(根據 Polyak 在 1991 年提出的方法)。這意味著,取了多個時間點的模型參數的平均值,來得到一個更穩定、性能更好的最終模型。(模型)
post-train(后訓練階段)
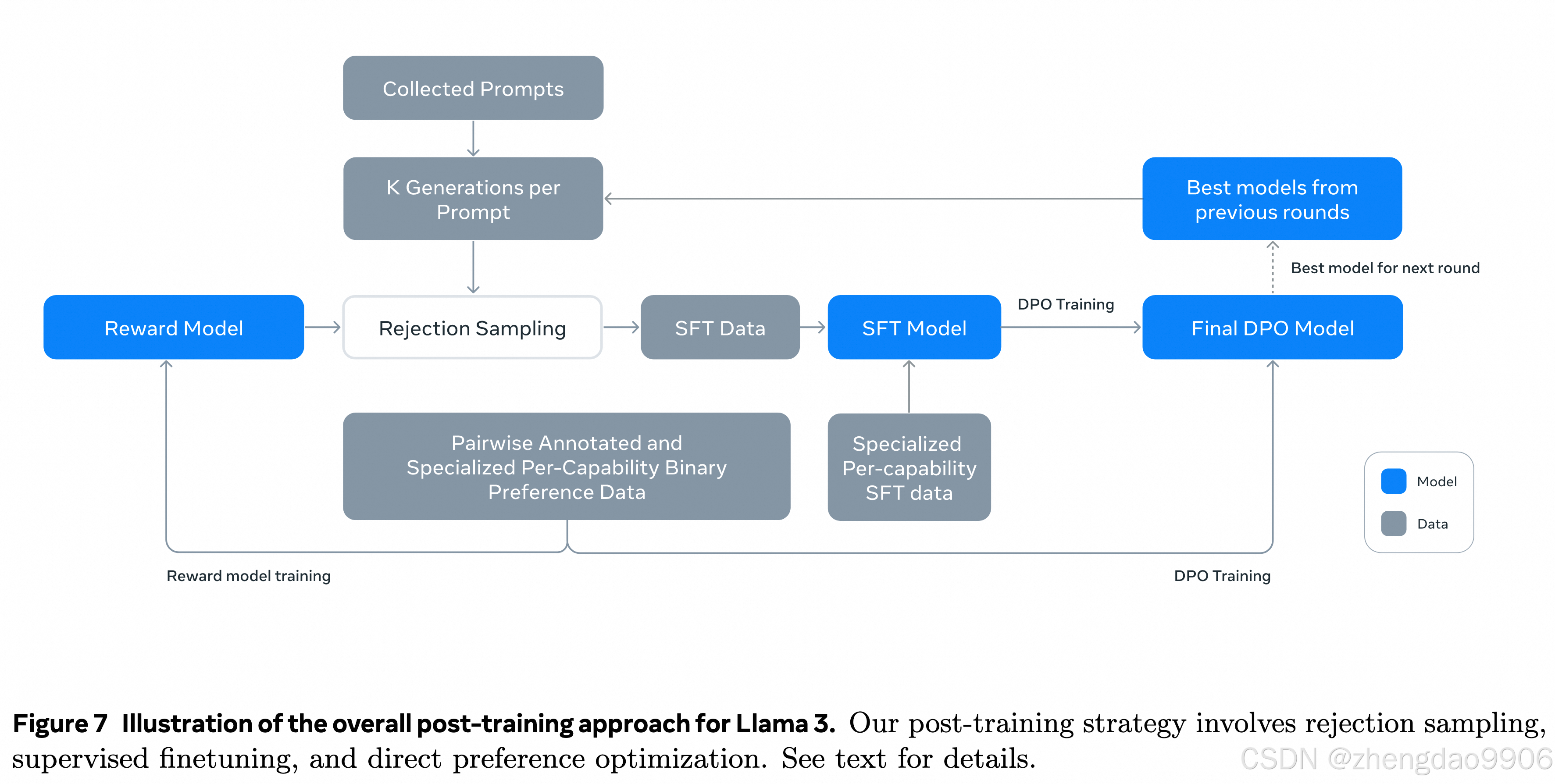
核心策略是獎勵模型和語言模型。
獎勵模型:這個模型的目的是幫助評估生成的文本是否符合人類的偏好。它基于預訓練好的模型,使用人類注釋的偏好數據進行訓練。
● 訓練獎勵模型:在預訓練好的模型基礎上,使用人類注釋的偏好數據來訓練獎勵模型。人類注釋的偏好數據是指人類標記哪些生成的文本更符合他們的期望或喜好。
● 有監督微調(SFT):接下來,對預訓練好的模型進行有監督微調(SFT),這是利用具體任務的標注數據來進一步訓練模型,使其在特定任務上表現更好。Tricks:使用獎勵模型進行拒絕采樣,提高用于微調的數據質量。
● 直接偏好優化(DPO):最后,使用直接偏好優化(DPO)進一步調整模型。DPO方法通過獎勵模型的反饋,直接優化模型生成的文本,使其更符合人類的偏好。
聊天對話協議
● 定義聊天對話協議:為了讓模型理解人類的指令并執行對話任務,需要定義一個聊天對話協議。
● 工具使用:與前一代模型相比,Llama 3 擁有新功能,例如工具使用,這可能需要在一個對話輪次內生成多個消息并發送到不同的地方(例如,用戶、ipython)。
獎勵模型
● 獎勵模型的訓練:在預訓練好的模型基礎上訓練一個獎勵模型,這個模型用于評估和提升模型的各項能力。
● 使用偏好數據:使用所有的偏好數據來訓練獎勵模型,但會過濾掉那些回應相似的樣本。
● 偏好數據的處理:除了標準的偏好對(即chosen, rejected),還為一些提示創建了第三種“edited”,這些回應是在選中回應的基礎上、人工進一步改進的。因此,每個偏好排序樣本會有兩到三種回應,且有明確的排序(edited > 即chosen > rejected)。
監督訓練
● 使用獎勵模型進行拒絕采樣:使用之前訓練的獎勵模型對人工標注的數據進行拒絕采樣。這意味著會根據獎勵模型的評分來篩選出高質量的回應。
● 監督微調階段:這一階段稱為監督微調(SFT),盡管很多訓練目標是模型生成的。這意味著用高質量的訓練數據對模型進行進一步調整,使其性能更好。
直接偏好優化
● DPO:一種優化算法,用于調整模型以更好地符合人類偏好。相比其他算法(如PPO),DPO在大規模模型上的計算需求更少,性能更好,尤其是在遵循指令的基準測試上表現出色。
● 訓練數據:使用最新收集的偏好數據,這些數據來自于之前優化輪次中表現最好的模型。這樣,訓練數據更符合正在優化的策略模型的分布。
實驗結果
改進了一些具體的能力,以提升模型的整體表現。
● 代碼能力:提升模型理解和生成代碼的能力。
● 多語言能力(:讓模型能夠處理多種語言,而不僅限于一種語言。
● 數學和推理能力:提高模型進行數學計算和邏輯推理的準確性和能力。
● 長上下文處理能力:增強模型處理長文本的能力,使其在面對長篇文章時表現更好。
● 工具使用能力:提升模型使用各種工具和接口的能力。
● 事實性:確保模型提供的信息準確且基于事實。
● 可引導性:增強模型按照用戶指令進行操作和回答的能力。
參考文獻
arxiv-pdf:https://arxiv.org/pdf/2407.21783v3
llama官方主頁:https://llama.meta.com/
:JVM概述和JVM功能)
 服務無法啟動)



)

:實時系統介紹與實例分析)


)

)






