上節課我們拆解了 AI 產品的基礎設施建設,這節課我們聊聊上層建筑。這部分是產品經理日常工作的重頭戲,包含提示詞、RAG 和 Agent 構建。
用 AI 客服產品舉例,這三者的作用是這樣的:
- 提示詞能讓客服很有禮貌。比如它會說:您好呀,很高興為您服務。
- RAG 能讓客服很專業。當客戶咨詢某個產品具體的價格時,RAG 能查閱相關價格手冊,直接給出具體數值;如果沒有 RAG,客服只能傻白甜地說,“親,請您查閱價格手冊哦~”雖然禮貌,但并不解決實際問題。
- Agent 能讓客服很有執行力。當客戶要求安排明天送貨時,Agent 能在系統里修改送貨時間,并回復客戶“我已經幫您修改明天送貨”。
這節課我會用最容易入門的方式帶你理解以下概念,為后面的實戰案例做好知識儲備。
- 提示詞工程:我會講述一個框架和兩個技巧。
- RAG:我會帶你“參觀”RAG 工廠的流水線作業。
- Agent:我會帶你學習讓 Agent 具備執行能力的兩項技能。
提示詞
相信你在很多地方看到過關于提示詞的知識,但是 AI 產品經理的提示詞和日常我們所說的提示詞有所不同。
第一個區別是目標不同,正如 01 節課中講的:
- 普通用戶寫提示詞就像玩盲盒。對結果有所期待,但不要求確定。
- AI 產品經理寫提示詞就像打靶。你是首先有一個確定的目標,再開始寫提示詞,直到提示詞能打中靶心為止。
第二個不同是使用工具不同。
- 普通用戶寫提示詞是在 AI 產品里寫,比如 Open AI 的 ChatGPT。
- AI 產品經理寫提示詞是面向原生的大語言模型寫,比如 Open AI 的 GPT Playground。
在這里,ChatGPT 是 OpenAI 包裝好的一個 AI 產品,ChatGPT 里的每一次問答并不是直接發給模型,而是經過了包裝才發給 GPT 模型。而 GPT Playground 里的對話才是直接發給 GPT 模型的。你可以把 GPT 理解為 OpenAI 提供的“毛坯房”,為了把這個“毛坯房”賣出去,OpenAI 提供了一個“樣板房”,就是 ChatGPT。
下圖是二者界面對比,ChatGPT 看上去更加簡潔,看上去就可以“拎包入住”;而 GPT Playground 里會有很多設置項,更像是毛坯房里裸露的“水電管線”。

預備知識:準備環境
那么在“毛坯房”里寫提示詞之前,我們先來介紹一下毛坯房里的“水電注意事項”。不過這里需要說明,每個模型廠商“水電注意事項”也不盡一致,在這里我列出部分模型的“毛坯房”可配置項和官方鏈接,其他模型大家直接參考官網。

https://platform.openai.com/playground
智譜AI開放平臺
https://www.anthropic.com/app-unavailable-in-region?utm_source=country
通義千問API參考_大模型服務平臺百煉(Model Studio)-阿里云幫助中心
其中,OpenAI 的 Playground 配置項是目前最全的,我們就以此為例具體說明。
首先,左側四個選項 Chat、Assistants、TTS、Completion,可以視作面向不同場景開發的不同“戶型”。
- Chat:和模型直接對話,是調試提示詞的主要模式。
- Assistants:可以先創建聊天機器人角色,再用這個角色與模型對話。如果你的產品僅僅就是一個對話機器人的話,可以用這種模式來調試提示詞。
- TTS:是文本到語音,當模型收到你的消息時,會被朗誦出來。適用于語音輸出的場景。
- Completions:是指文本補全,經常用在代碼補全的場景。
我們以最基本的 Chat 模式來看一種模式下的右側各種設置。
- Function:添加模型可以執行的自定義功能。
- Response format:指定對話輸出的格式要求。比如要求以 JSON 格式輸出,方便解析。方便下一步操作。
- Temprature:用來控制模型的創造力和隨機性。溫度越高,回答越發散;溫度越低,回答越穩定。你可以想象,水的溫度是 100 時,水分子以水蒸氣的方式發散;而水溫 0 度時,則相對穩定。實際上大語言模型的原理本身就起源于熱力學模型,因此在這里沿用了溫度的概念。
- Maximum Tokens:設置模型在單個響應中可以生成 Token 最大數量。
- Stop sequences:可以提供特定的短語或模式控制模型應停止生成文本。
- Top P:此參數影響模型輸出的概率分布,專注于更可能的預測。
- Frequency penalty:降低模型出現重復單詞或短語的可能性。
- Presence penalty:增加模型談論新主題的可能性。
在 AI 產品開發中,當我們向 OpenAI 發送請求時,需要帶上以上設置好的參數。對于產品經理來說,我們調整好提示詞后,需要同時把這些參數值的設置告訴開發同學。
配好環境后,我們就可以學習提示詞框架和技巧了。
提示詞框架和技巧
提示詞技巧難度不高,網上也有很多資料。但隨著實戰深入,你會發現提示詞更多的是一項“工程”。
比如對于不同模型,我們需要調整不同的提示詞;對于同一場景,也需要需要調整提示詞以達到最大化滿足需求。
這節課我會以一個框架和兩個技巧帶你了解基本知識,后續再通過實戰案例帶你深入體會。
一個入門框架
提示詞的框架就是提示詞模板。框架是為了讓我們更容易上手、方便記憶。在你充分實踐后,就不必拘泥于框架了。網上有非常多的提示詞框架(參考 1),這里我以 RTF 框架為例說明。
RTF 代表 Role(角色),Task(任務), Format(格式)。我們把上節課提到的客服場景用 RTF 框架寫出來,就是下面這樣的提示詞。
## Role
情感標注人員
## Task
我給你的一句客戶留言文字,請你判斷出文字中的情緒。請你從以下選項中選擇:
1. 正面:表達了肯定、喜歡、贊賞、褒揚
2. 負面:表達了否定、討厭、貶低
3. 中性:通常客觀描述,沒有主觀意向, 沒有肯定、喜歡、贊賞、褒揚,也沒有否定、討厭、貶低
## Format
嚴格按照以下格式輸出:
{"客戶留言": "客戶留言內容","情緒判斷": "情緒判斷結果"
}在撰寫提示詞時需要注意兩條不成文的“習俗”。
- 提示詞中的標記位參考 Markdown 語言來寫。Markdown 是一種帶標記的語言,比如例子中 “##” 代表一個小標題,Markdown 語言既能方便人來操作,又能讓計算機很好理解。所以在提示詞的撰寫中廣泛應用。你可以參考Markdown 官方文檔學習。Getting Started | Markdown Guide
- 輸出格式結構化。上面的提示詞特別規定了嚴格的輸出格式(通常是 JSON 格式)。這是因為開發同學通常會對模型的輸出做下一步處理,結構化輸出會方便他們解析。如果你不熟悉 JSON 格式,可以借助 ChatGPT 來修改成 JSON 格式(比如下圖)。

在框架之外,我們還需要掌握提示詞的兩個基本技巧,Few-Shots、COT。
基本技巧
技巧一:Few-Shots(少量樣本提示)
Few-Shots 通俗來講就是“舉例子”。我們給剛才客服場景的提示詞加上 Few-Shots,就是下面這樣的。
// RTF 內容略...## few shots
{"客戶留言":"今天我不在家,你們明天送貨;","情緒判斷":"中性"
},
{"客戶留言":"我就不相信你們賣的是正品,質量太差了!","情緒判斷":"負面"
},
{"客戶留言":"收到您的差額退還了,你們的服務真快,謝謝!","情緒判斷":"正面"
}你可千萬別小看舉例子這個簡單的操作,這可是正兒八經的學術話題。2020 年 OpenAI GPT-3 論文的標題就是《Language Models are Few-Shot Learners》,論文中有一張圖這樣的:

你看,在 1750 億參數的大語言模型中:
- 給出一個示例比不給示例的準確率從 10% 迅速提升到 45%。
- 給出 10 個示例比一個示例的準確率從 45% 提升到 60%。
- 給出 10 個以上示例效果會有所波動甚至下降。
所以,少量樣本數量不宜過少,但也不能過多。這也是提示詞被稱為是“工程”的一個原因:我們需要通過大量嘗試,把最典型的例子放在提示詞里。
Few-Shots 論文讓學術界見識到了大語言模型通過上下文就能“照貓畫虎”地學習到示例里的能力,而當時大語言模型的推理能力還很弱。于是大家就開始思考:如果提示詞當中給出推理步驟,是不是就能讓大語言模型“照貓畫虎”地學會推理呢?
這一思考就催生了提示詞的第二個基本技巧:COT(思維鏈,Chain Of Thought)。
技巧二: COT(思維鏈,Chain Of Thought)
思維鏈簡單來說就是在提示詞里加上“讓我們一步步來,第一步……,第二步……”,主要用于推理場景,比如數學應用題計算,再比如規劃旅程時中轉站的時間要前后合理,這些都是推理場景。
這個簡單的技巧放在提示詞里確實有四兩拔千金的效果。在 COT 開山論文里發現:對于參數量在十億、百億、千億的大模型,采納了 COT 的提示詞在 GSM8K 數據集(加減乘除應用題)的測試中,準確率從 20% 直接干到 50%,接近人類平均水平。正如論文標題所說的《COT 點燃了大語言模型的推理能力》。
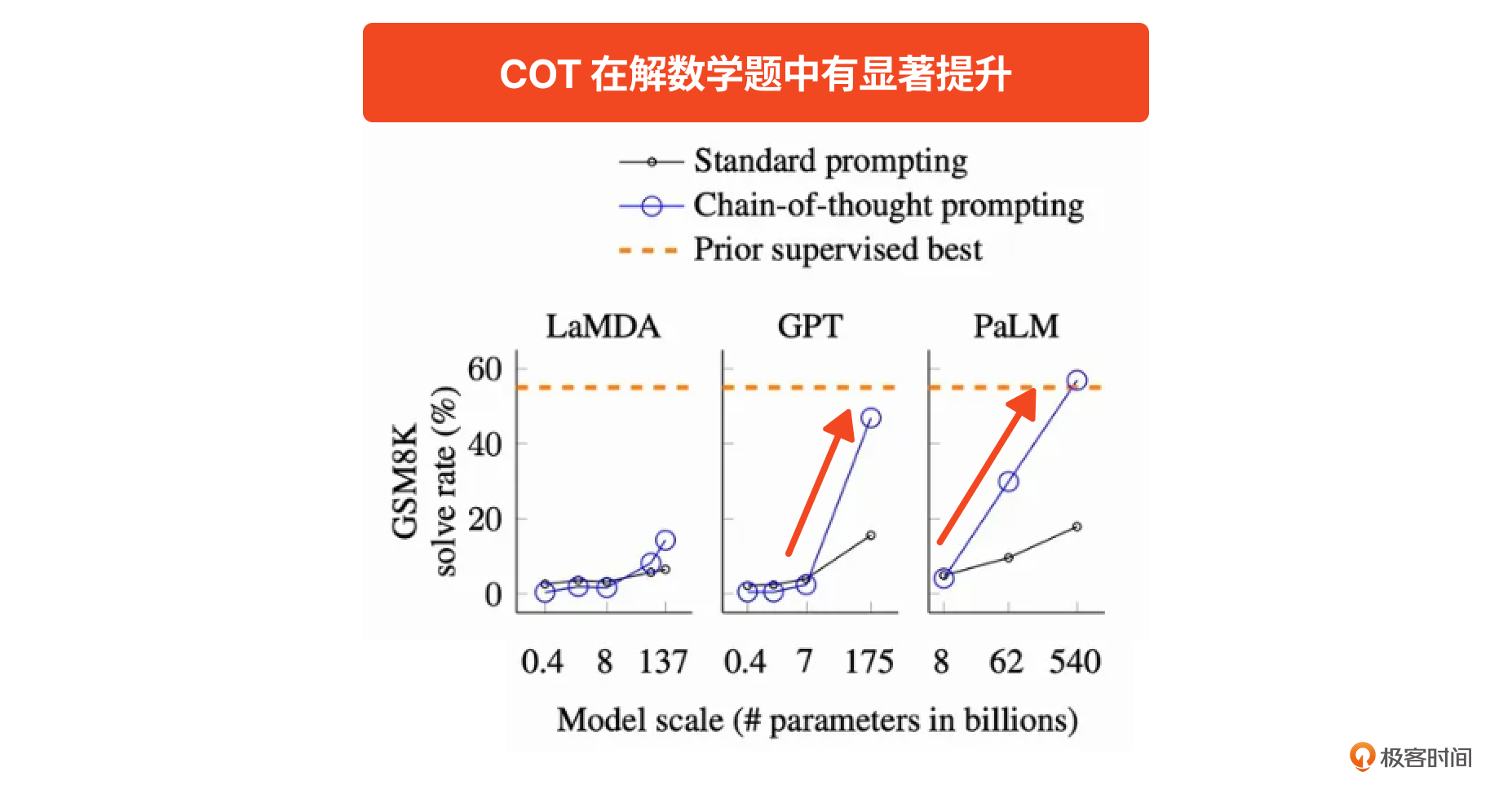
所以,在推理場景下,COT 的作用絕不可小覷。如果你了解更多關于 COT 的研究,可以參考這篇文章。上面說的提示詞框架和兩個提示詞技巧還衍生出來了很多技巧,你可以參考 2 提示詞指南網站上的內容學習。在后續的實戰案例中,我們會以組合、嵌套的方式同時使用這些技巧。
https://zhuanlan.zhihu.com/p/589087074
接下來我們來了解 AI 產品上層建筑中的另外一項內容,RAG。
RAG
在本節課開頭客服場景的例子里,我說的是 RAG 會讓客服更專業,是因為它會查閱資料后給出回答。RAG 本質上就是把搜索到的資料作為提示詞的一部分發給大語言模型,讓大語言模型有根據地輸出內容,從而降低大模型“臆想答案”的概率。在 OpenAI 分享的案例中,通過對 RAG 技術的應用將回答準確率從 45% 提升到了 98%,可見 RAG 的重要性。
RAG 的全稱是 Retrieval Argumented Generation,中文是檢索增強生成。意思是把檢索(資料庫)的結果發給大模型,以增強大模型的生成能力。
下面這張圖就是一張 RAG 作業的流水線,行話叫 Pipeline。這個流水線上有 10 個作業環節,只有精細打磨流水線上的每一個步驟,最后才能出來好的效果。
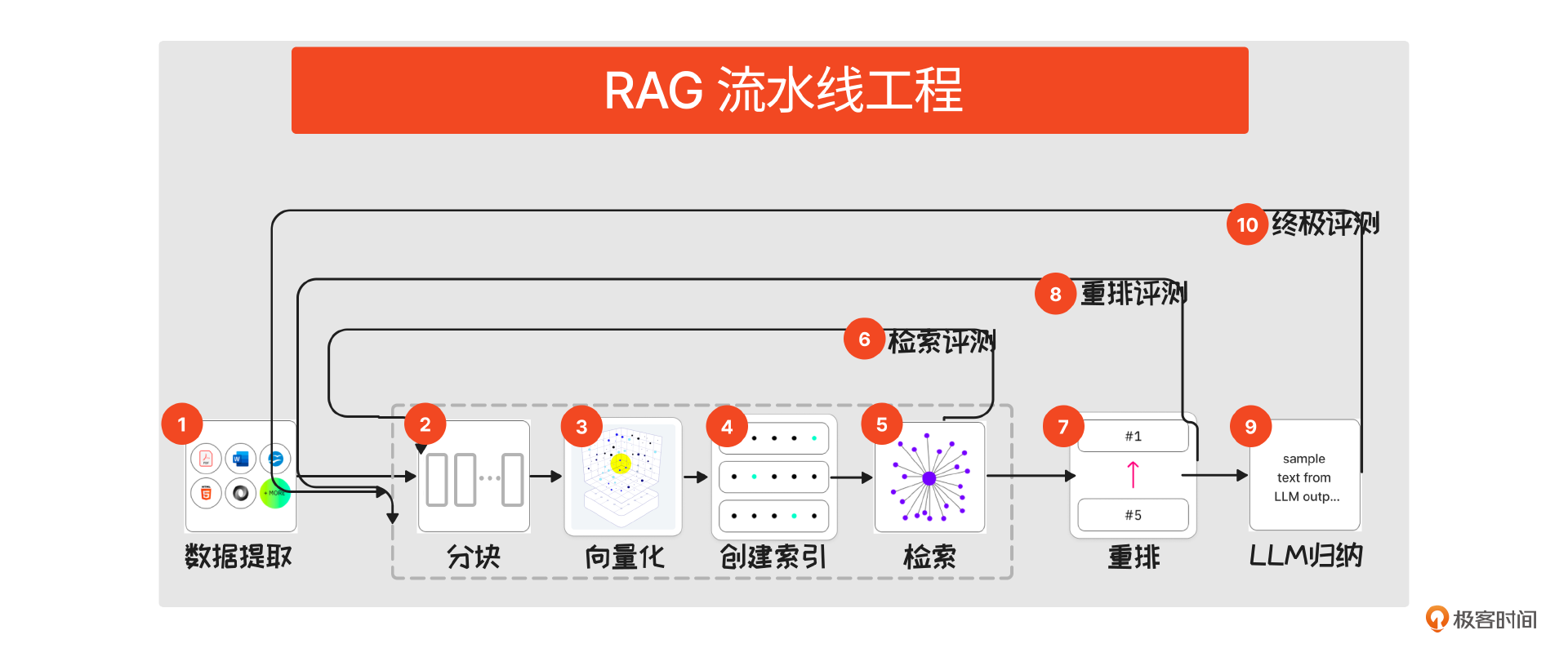
接下來,我們對這個 RAG Pipeline 中的各個環節做一個概念介紹。為了便于理解,這里都會拿“查閱資料庫”來類比。
- 數據提取:類比于資料庫的資料來源。主要目標是確保資料數據完整,除此之外,還可以新生成一些數據,比如利用大模型對資料進行 summary、打標簽,讓后續處理更高效。
- 分塊 (Chunking):你可以想象成資料應該拆分到多細來存儲,用梗話來說就是“對齊顆粒度”。比如按段落、句子拆,或者按照文章標題、某個標記來拆等等。
- 向量化(Embedding):就是把拆分后的段落、句子、單詞轉換為計算機可處理的向量,向量化就是把一個物體拆成多個維度表達。
比如一本書可以從以下八個維度去表達。

那么某一本特定的書《思考的快與慢》對應的向量值就是八維空間的一個點,計算機就是通過這些點來定義事物的。同樣,語言文字也可以被向量化,且語言都已經有成熟的向量模型,比如智源的開源 embedding 模型 bge-large-zh-v1.5 有 1024 個維度。
4、創建索引:類似把向量化后的資料塊進行分類、整理,按照一定順序放在對應位置后給出序號,方便后面的檢索查找。索引可以建多個,比如書可以按照圖書分類排序,也可以按照出版時間排序。
至此,你的資料庫終于建好了,接下來就是根據具體問題在這些資料庫中查找了。
5、檢索環節(Retriever):類似在資料庫找相關資料。系統會根據用戶的提問,在索引中查找最相關的數據塊。找到和問題匹配度高的資料(注意此時還沒有形成答案)。
6、第一輪檢索評估:大多數文章中會漏掉評估的環節,開發者往往也會忽視。要知道,沒有評估等于盲走。這里的評估和傳統搜索的評估是一樣的,最核心的指標是召回率,即實際檢索出的文本塊數量 / 期待被檢索的文本數量。
講到這里我們停一下。實際上到這一步之前,在技術上和互聯網的搜索邏輯是類似的,我們統稱為“語義檢索”階段。這意味著如果你公司內部的知識庫已經具備“語義搜索”能力,那么通過嫁接下面兩步就可以實現基于 LLM 的問答應用了。
7、重排序(Rerank):語義檢索出來的結果相當于是資料初篩,講究的是效率。重排序顧名思義就是對初步檢索結果進行重排序,從而得到更精確的結果。重排序也有開源閉源的模型供大家使用,比如 Cohere 等。
8、重排評測:和語義檢索階段一樣,在重排序之后,我們也應該有一個評估,這里的評估機制和步驟 6 類似。
9、生成(Generator):這一步對應的就是系統終于找到了最準確的資料,然后整理、總結資料,形成完整報告。實際上就是將重排序后的資料片段加上用戶的提示詞,提供給大型語言模型 LLM,由 LLM 根據上下文生成最終的輸出。在這個過程中,主要在提示詞、上下文、意圖識別方面下功夫。
10、終極評估:這一輪的評估指標和檢索、重排序指標不一樣,現在有專門用于評估 RAG 的框架 RAGAS (參考 RAGAS 官網)。
總的來說,RAG 流程玩的是一條流水線上的“組合拳”。對于應用開發者來說,比拼的就是對不同的場景該怎么打這套組合拳。有了 RAG 和提示詞,相當于我們和大語言模型建立起了很好的溝通機制,當我們把事情溝通好之后呢,就可以借助大語言模型來“執行工作”了,這就輪到 Agent 出場了。
Agent
Agent 并不是平行于 RAG、提示詞的概念,Agent 本身就包含了 RAG 和提示詞的應用。
在 01 節中,我們知道 Agent 需要具備記憶、反思、規劃和工具使用能力。這四項能力中,我把記憶、反思、規劃總結為思考力,工具使用總結為執行力。思考力通過上述的提示詞工程和 RAG 就可以獲得,剩下的執行力,我們在這一小節講述。
本節課開頭的例子中,Agent 能讓客服直接安排退貨這個行為,這就是執行力。那這是怎么做到的呢?你只要記住兩項技能:Function calling 和 Re-Act,別急,我們一個個講清楚。
技能一:Function calling(函數調用)
Function calling 的中文意思是函數調用,是計算機語言里的一個概念。比如你使用 Excel 表里的公式 SUM(C1,C2) 代表將單元格 C1,C2 中的數字相加,在這里:
- 自然語言是:將單元格 C1,C2 中的數字相加。
- 自然語言被轉換成函數調用就是:SUM(C1,C2),函數調用可以直接被機器編譯并運行。
大語言模型的 Function calling 能力就是把自然語言指令轉換為函數的調用指令,從而使自然語言指令可以被執行。
當然,可以被機器運行的函數有很多種,比如 Java 函數、Python 函數,而在 AI 產品中最常見的函數調用方式就是調用微服務架構下的各種 API request。
下面就是以 API request 這種函數為例,通過提示詞的方式讓大語言模型完成函數調用的任務。
## Instruction
你是一個人工智能編程助手,根據用戶請求和函數定義,調用函數來完成任務,并以代碼格式進行回應,無需回復其他話語。請特別注意函數的定義。## 函數定義tools = [{"type": "function","function": {"name": "get_current_weather","description": "Get the current weather in a given location","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city and state, e.g. San Francisco, CA",},},"required": ["location"],}}}]## 用戶請求查一下今天北京的天氣
這個例子的提示詞里有三個部分。
- 任務:告訴大語言模型要完成指令轉換的任務,這里的核心任務就是“根據用戶請求和函數定義,調用函數來完成任務,并以代碼格式進行回應”。
- 函數定義:專業術語叫 schema,即告訴大語言模型這個 API request 里有哪些參數,各個參數的名稱、描述、數據類型等。這里最好遵循 OpenAI 自己的格式,這種格式也可以借助大語言模型來完成。
- 用戶請求:就是自然語言指令。
我們把上述的例子輸入給到 Open AI 的 GPT Playground,GPT 就會輸出以下 API Request,這就可以直接被機器運行。我們就實現了將自然語言指令轉變為計算機可執行指令。
```json
{"function": "get_current_weather","parameters": {"location": "北京"}
}不過大語言模型在做這個可執行指令的轉換時,充滿了不確定性,除了調整提示詞中 instruction 部分外,還需要一些機制來控制執行的準確性,這就需要賦予 Agent 的第二項技能:Re-Act。
技能二: Re-Act
Re-Act 的全稱是:Reasoning and Act,推理并且執行,相當于是給行動裝上了一個隨機應變的機制。
回到上面的函數定義例子,假設 API 定義中要求第 14 行代碼的字段“location”必須是英文字母,但我們發送的是漢字“北京”,API 就會返回錯誤信息“location must be English”。這時大語言模型還會根據這個錯誤信息自動推理出此時需要將漢字“北京”改為拼音“Beijing”后,再去調用 API。
```json
{"function": "get_current_weather","parameters": {"location": "BeiJing"}
}這就是推理并且執行,你瞧,大語言模型是不是很聰明呀。
在上面這個例子中,我們很容易就發現,在 Agent 進行推理執行的過程中,需要分享把觀察到的報錯信息也發給大語言模型,這就構成了 Re-Act 模式的提示詞框架:Observation,Think,Act。
## Observation:API就會返回錯誤信息“location must be English”.
## Think:應該location這個字段的值轉換為英文再發一次.將API request 當中的"北京"修改為"BeiJing".## Act:```json{"function": "get_current_weather","parameters": {"location": "BeiJing"}}這種 Observation->Think->Act 的模式會一直循環,直到在 Think 步驟中認為 Observation 里的結果能達成用戶訴求,或者循環次數達到了代碼里規定的上限。可以說,Re-Act 本質上就是一種提高 Agent 執行準確率的提示詞模板。
聽到這里,你會不覺得,哇~ 這也太厲害了吧,只要通過提示詞能讓大語言模型像個真人一樣自主行動呢。不過這里我要潑點冷水:目前大語言模型的 Reasoning 和 Act 的準確率還不夠高,就像剛剛走路的孩子,執行起來跌跌撞撞,但這種能力會越來越強。
另一方面,研究者在 Re-Act 基礎之上,也衍生出了各種各樣的花式提示詞模板來提升 Agent 的執行準確率。類似于給孩子裝上護具、穿上牽引帶這類外圍措施防止他們跌倒。我們在后續的實戰案例中會根據需要使用到這些方式,在這里不再細講。
小結
到這里,AI 產品架構中的上層建筑就完成了簡單介紹。針對三點,我們需要做到:
- 提示詞:以簡單框架入門提示詞,牢記 Few shots、COT 兩項基本技巧。這是讓應用層和大語言模型進行有效溝通的技巧。
- RAG:了解 RAG 流水線的每一個環節,之后我們才能在實戰案例按照流水線來一一排查問題。
- Agent:通過函數調用具備執行力,通過以 Re-Act 為代表的 Agent 提示詞模板提升執行準確率。
到這里我們完成了第一章的產品經理必懂的 AI 技術原理的學習。一款 AI 產品通常有四層架構,這四層又可以歸類為基礎設施(算法、數據,大語言模型)和上層建筑。這部分 AI 產品經理必備的基礎知識,也是打造所有 AI 產品的必備工具。相信你已經掌握了使用這些工具的方法,一定在實戰中得心應手地使用這些工具,打造出優秀的 AI 產品。
課后題
注冊堪稱國內版 OpenAI 的智譜大語言模型開放平臺(相當于智譜的 API playground),并完成兩個任務。
智譜AI開放平臺
任務一: 從 twitter 數據集中選取 20 條數據,寫一條提示詞,使模型輸出結果與 20 條數據中的標注數據保持一致。注意使用 Few shots。
https://huggingface.co/datasets/ought/raft/tree/main/data/twitter_complaints
任務二:將本節課中的《技能一:Function calling(函數調用)》部分提到的 Function calling 提示詞模板輸入到智譜大語言模型開放平臺,看看輸出的結果是否和 OpenAI 輸出的一致,看看在 function calling 領域,openAI 和智譜是否有一定差距?
參考:
提示詞框架。
提示詞指南。
)

:實時系統介紹與實例分析)


)

)











![Sentinel[超詳細講解]-4](http://pic.xiahunao.cn/Sentinel[超詳細講解]-4)