源碼
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Config(object):"""配置參數類,用于存儲模型和訓練的超參數"""def __init__(self, dataset, embedding):self.model_name = 'TextRNN' # 模型名稱self.train_path = dataset + '/data/train.txt' # 訓練集路徑self.dev_path = dataset + '/data/dev.txt' # 驗證集路徑self.test_path = dataset + '/data/test.txt' # 測試集路徑self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()] # 類別列表self.vocab_path = dataset + '/data/vocab.pkl' # 詞表路徑self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型保存路徑self.log_path = dataset + '/log/' + self.model_name # 日志保存路徑# 加載預訓練詞向量(若提供)self.embedding_pretrained = torch.tensor(np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32')) \if embedding != 'random' else Noneself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 訓練設備# 模型超參數self.dropout = 0.5 # 隨機失活率self.require_improvement = 1000 # 若超過該batch數效果未提升,則提前終止訓練self.num_classes = len(self.class_list) # 類別數self.n_vocab = 0 # 詞表大小(運行時賦值)self.num_epochs = 10 # 訓練輪次self.batch_size = 128 # 批次大小self.pad_size = 32 # 句子填充/截斷長度self.learning_rate = 1e-3 # 學習率# 詞向量維度(使用預訓練時與預訓練維度對齊,否則設為300)self.embed = self.embedding_pretrained.size(1) \if self.embedding_pretrained is not None else 300self.hidden_size = 128 # LSTM隱藏層維度self.num_layers = 2 # LSTM層數'''基于LSTM的文本分類模型'''
class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()# 詞嵌入層:加載預訓練詞向量或隨機初始化if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# 雙向LSTM層self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,bidirectional=True, batch_first=True, dropout=config.dropout)# 全連接分類層self.fc = nn.Linear(config.hidden_size * 2, config.num_classes) # 雙向LSTM輸出維度翻倍def forward(self, x):x, _ = x # 輸入x為(padded_seq, seq_len),此處取padded_seqout = self.embedding(x) # [batch_size, seq_len, embed_dim]out, _ = self.lstm(out) # LSTM輸出維度 [batch_size, seq_len, hidden_size*2]# 取最后一個時間步的輸出作為句子表示out = self.fc(out[:, -1, :]) # [batch_size, num_classes]return out
數據集
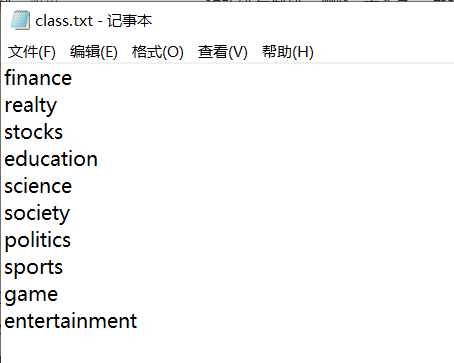
上圖是我們這次做的文本分類。一共十個話題領域,我們的目標是輸入一句話,模型能夠實現對話題領域的區分。

上圖是我們使用的數據集。前面的漢字部分是模型學習的文本,后面接一個tab鍵是對該文本的分類。
配置類
配置的重點是模型的超參數,這里分析一下模型涉及的超參數。
Dropout隨機失活率
self.dropout = 0.5在LSTM層之間隨機屏蔽部分神經元輸出,強迫模型學習冗余特征表示。公式:hdrop=h⊙mhdrop?=h⊙m,其中mm是伯努利分布的0-1掩碼。
早停閾值
elf.require_improvement = 1000早停閾值的思想是:連續N個batch在驗證集無精度提升則終止訓練。首次訓練數據的時候可能摸不清楚情況,設置了較大的epoch值,浪費掉大量訓練時間。假設batch_size=128,數據集1萬樣本 , 每個epoch大約有78個batch。1000個batch的耐心期大約是13個epoch。
序列填充長度
self.pad_size = 32序列填充長度的作用是,將變長文本序列處理為固定長度,滿足神經網絡批量處理的要求 。如果文本長度小于32,則填充特定的字符。如果文本長度大于32,則進行截斷,保留32個字符。
序列填充長度通常使用95分位方式獲得,獲取代碼如下
import numpy as np
lengths = [len(text.split()) for text in train_texts]
pad_size = int(np.percentile(lengths, 95)) # 覆蓋95%樣本
詞向量維度
self.embed = 300詞向量的維度決定了語義空間的自由度 。假設我們使用字分割,每個文字對應一個300維的向量,將向量輸入到模型中完成訓練。
可以得出,向量維數越多,可以包含的信息數量就越多。但是并不是維度越高越好,下面的表是高維和低維的對比。
| 因子 | 低維(d=50) | 高維(d=1024) |
|---|---|---|
| 語義區分度 | 相似詞易混淆 | 可學習細粒度差異 |
| 計算復雜度 | O(Vd) 內存占用低 | GPU顯存需求高 |
| 訓練數據需求 | 1M+ tokens即可 | 需100M+ tokens |
| 下游任務適配性 | 適合簡單分類任務 | 適合語義匹配任務 |
由于我們的數據量較小,所以使用較低的詞向量維度。另外,如果使用預訓練模型,詞向量維度的值需要和預訓練模型的值相同。
LSTM隱藏層維度
self.hidden_size = 128隱藏層維度先賣個關子,下一章LSTM模型解析的時候講。
模型搭建
Input Text → Embedding Layer → Bidirectional LSTM → Last Timestep Output → FC Layer → Class Probabilities
文本是無法直接被計算機識別的,所以文本需要映射為稠密向量才能輸入給模型。因此在輸入模型前要加一步向量映射。
class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()# 詞嵌入層:加載預訓練詞向量或隨機初始化if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# 雙向LSTM層self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,bidirectional=True, batch_first=True, dropout=config.dropout)# 全連接分類層self.fc = nn.Linear(config.hidden_size * 2, config.num_classes) # 雙向LSTM輸出維度翻倍def forward(self, x):x, _ = x # 輸入x為(padded_seq, seq_len),此處取padded_seqout = self.embedding(x) # [batch_size, seq_len, embed_dim]out, _ = self.lstm(out) # LSTM輸出維度 [batch_size, seq_len, hidden_size*2]# 取最后一個時間步的輸出作為句子表示out = self.fc(out[:, -1, :]) # [batch_size, num_classes]return out
詞嵌入層
首先構建詞嵌入層,將本地的預訓練embedding加載到pytorch里面。
雙向LSTM層
我們使用雙向LSTM模型,即將文本從左到右訓練一次,也從右到左(倒著來)訓練一次。
| 參數名 | 作用說明 | 典型值 |
|---|---|---|
| input_size | 輸入特征維度(等于嵌入維度) | 300 |
| hidden_size | 隱藏層維度 | 128/256 |
| num_layers | LSTM堆疊層數 | 2-4 |
| bidirectional | 啟用雙向LSTM | True |
| batch_first | 輸入輸出使用(batch, seq, *)格式 | True |
| dropout | 層間dropout概率(僅當num_layers>1時生效) | 0.5 |
全連接分類層
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
?全連接的輸入通道數是隱藏層維度的兩倍,原因是我們的模型是雙向的,雙向的結果都需要輸出給全連接層。
前向傳播
def forward(self, x):x, _ = x # 解包(padded_seq, seq_len)out = self.embedding(x) # [batch, seq_len, embed_dim]out, _ = self.lstm(out) # [batch, seq_len, 2*hidden_size]out = self.fc(out[:, -1, :]) # 取最后時刻的輸出return out
首先提取輸入x的填充張量。可以看到張量里有4760這種值,這個值是我們在文字長度不夠時的填充內容。
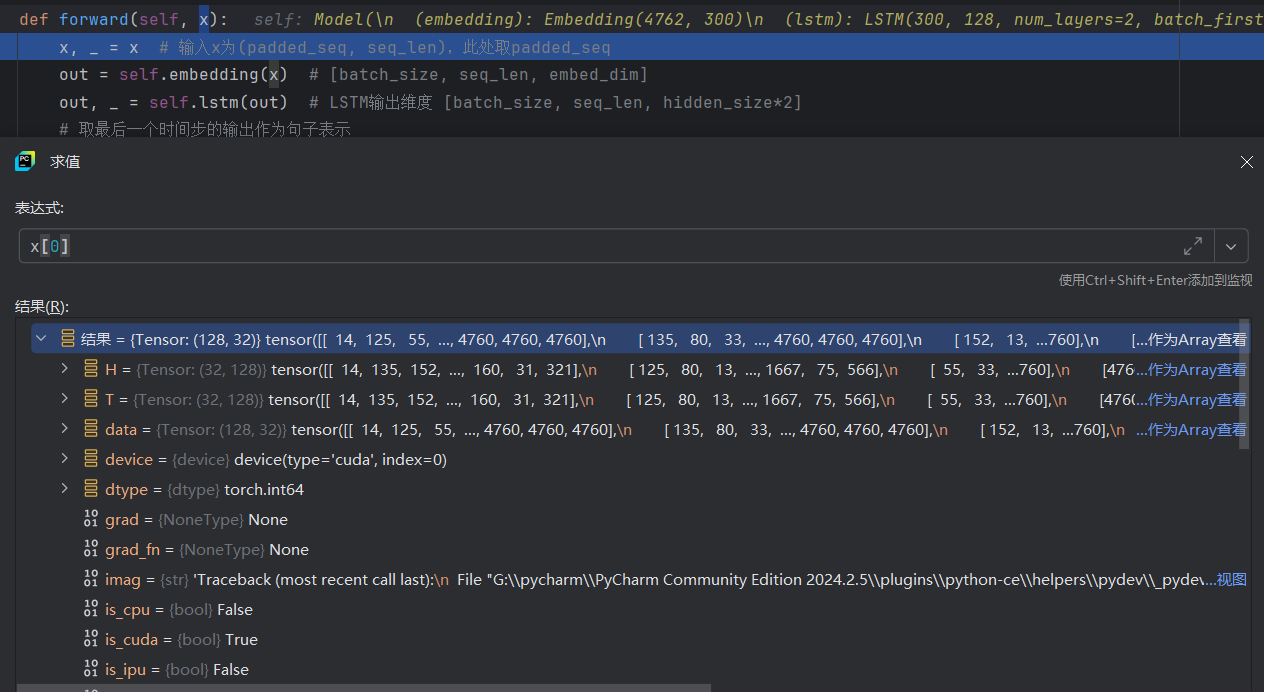 ?經過embedding映射后可以看到,張量out里的數據變成128*32*300的維度,300的維度就是詞向量維度,可以看到data里的數據都由原來的整數映射成了向量。
?經過embedding映射后可以看到,張量out里的數據變成128*32*300的維度,300的維度就是詞向量維度,可以看到data里的數據都由原來的整數映射成了向量。
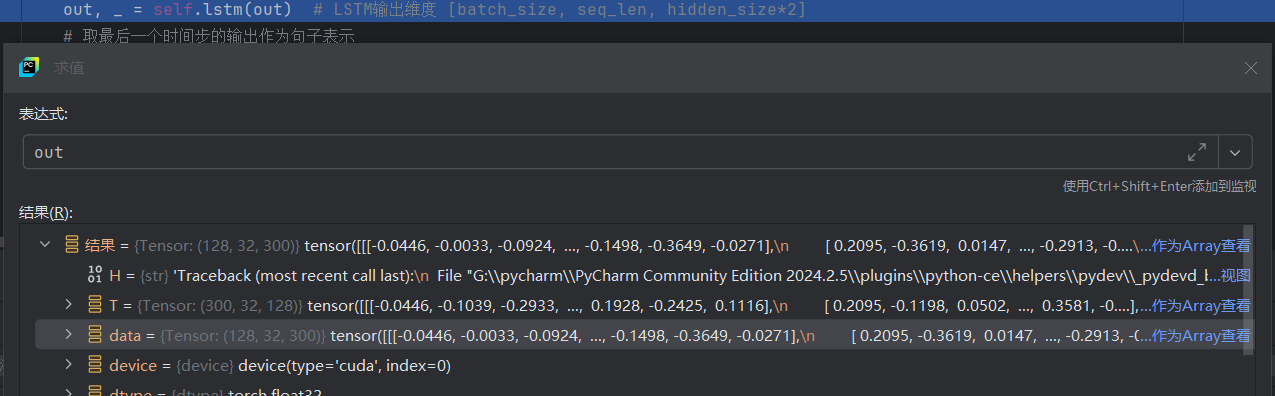
經過lstm運算后,out張量數據變成了128*32*128的維度
 ?最終經過全連接層,out張量變成了128*10維度的張量。128是batch_size,10個維度即代表該條數據在10個分類中的概率。
?最終經過全連接層,out張量變成了128*10維度的張量。128是batch_size,10個維度即代表該條數據在10個分類中的概率。









)





——THORChain退款邏輯漏洞)




