管道架構概述
RAG 管道由多個處理階段組成,這些階段將文本內容轉換為適合智能檢索的結構化知識表示:
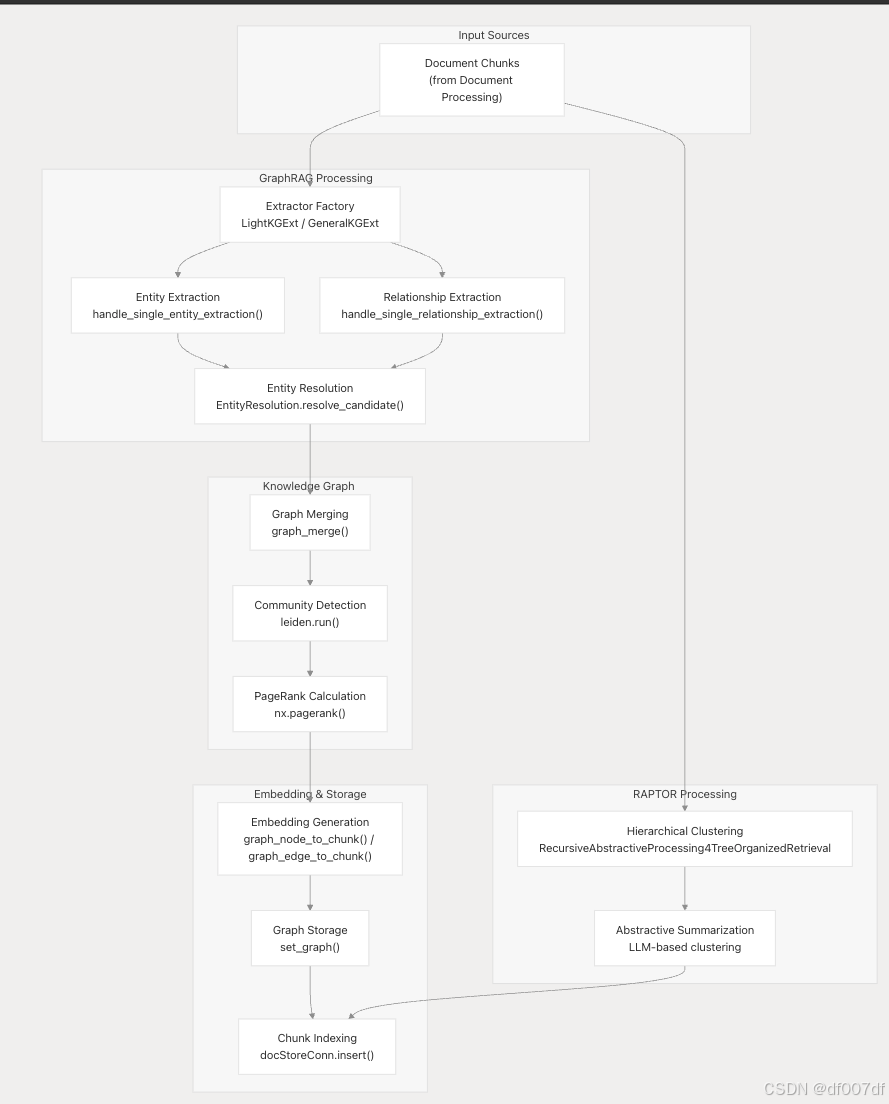
文檔到知識圖譜工作流程
主要處理工作流程通過 run_graphrag 功能將單個文檔塊轉換為統一的知識圖譜:
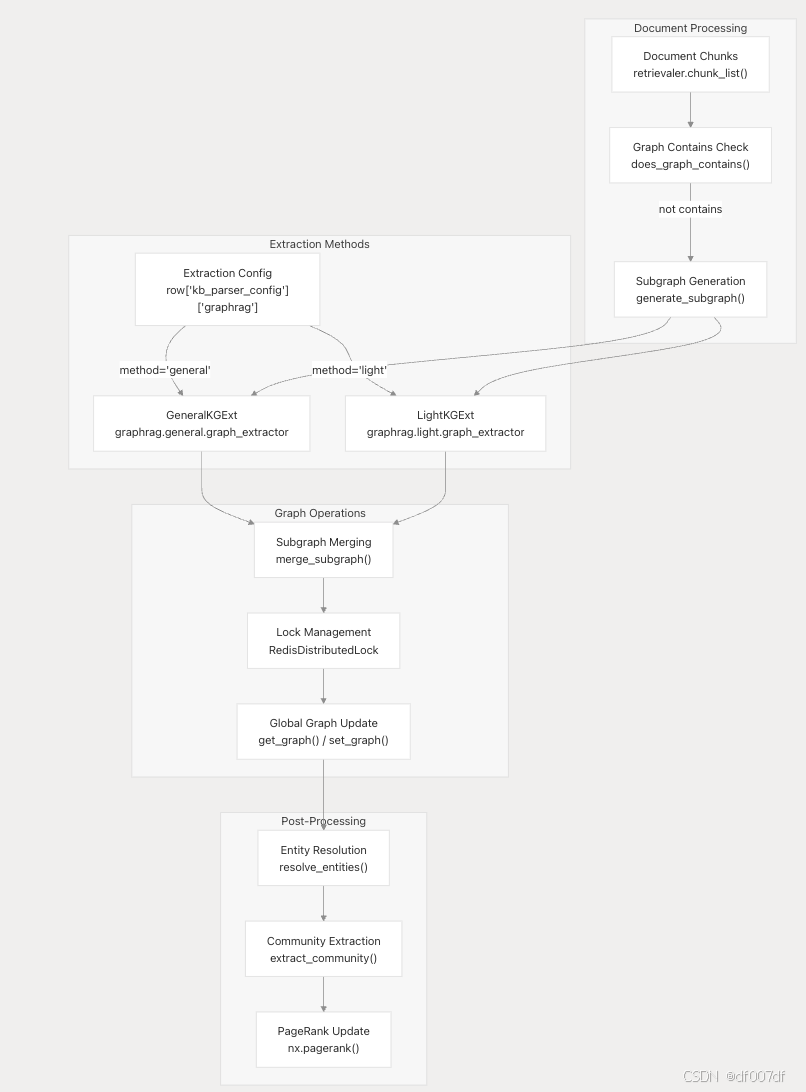
GraphRAG 處理方法
RAGFlow 支持兩種不同的 GraphRAG 提取方法,每種方法都針對不同的用例進行了優化:
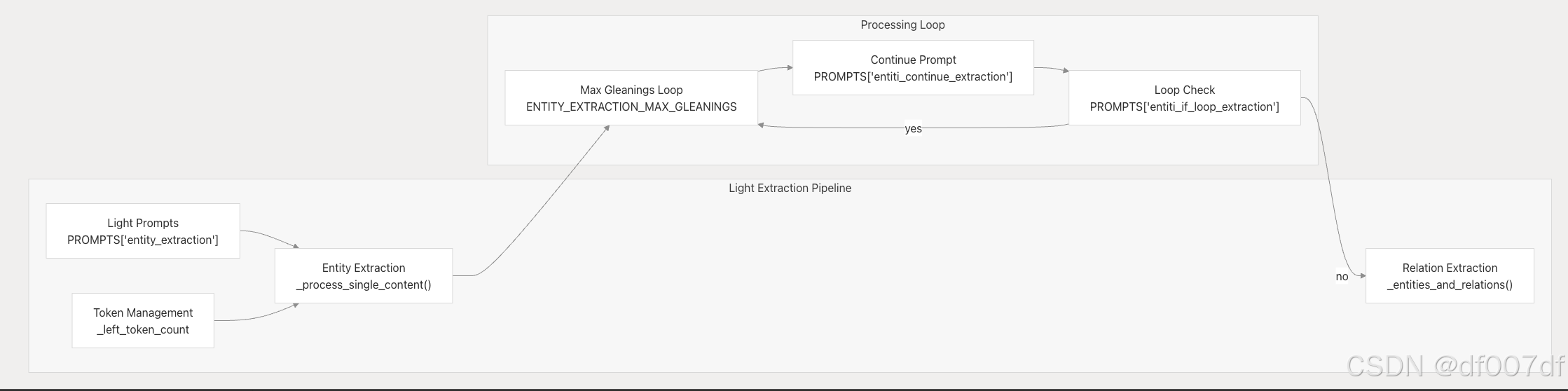
Light GraphRAG 方法
Light 方法使用簡化的基于提示的方法來加快處理速度:
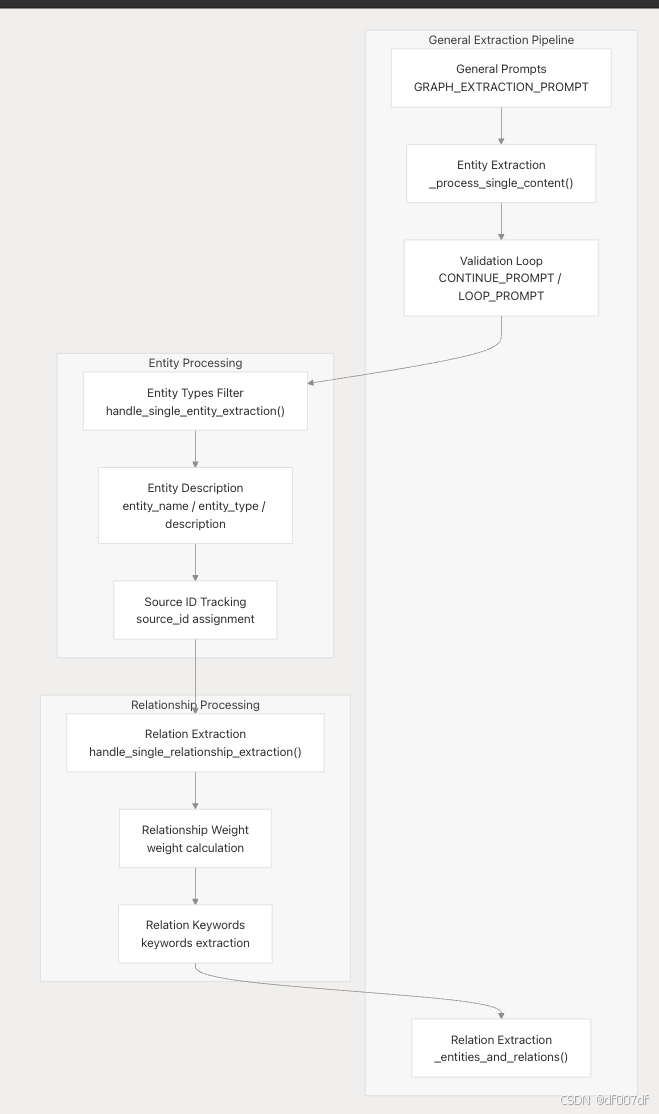
通用 GraphRAG 方法
常規方法通過多個驗證步驟提供更全面的提取:
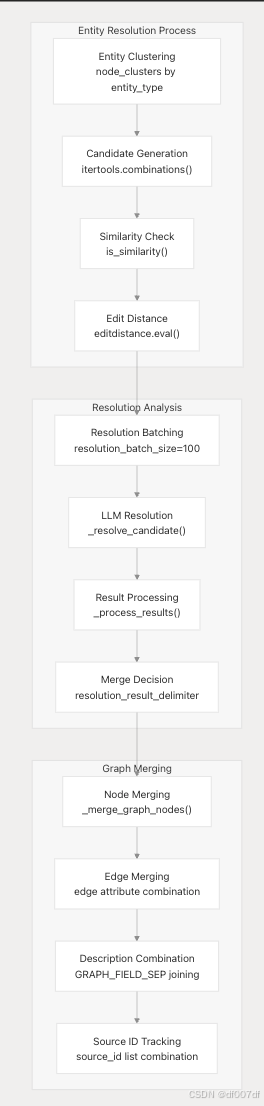
實體解析和圖形合并
實體解析過程使用基于 LLM 的相似性分析來識別和合并重復實體:
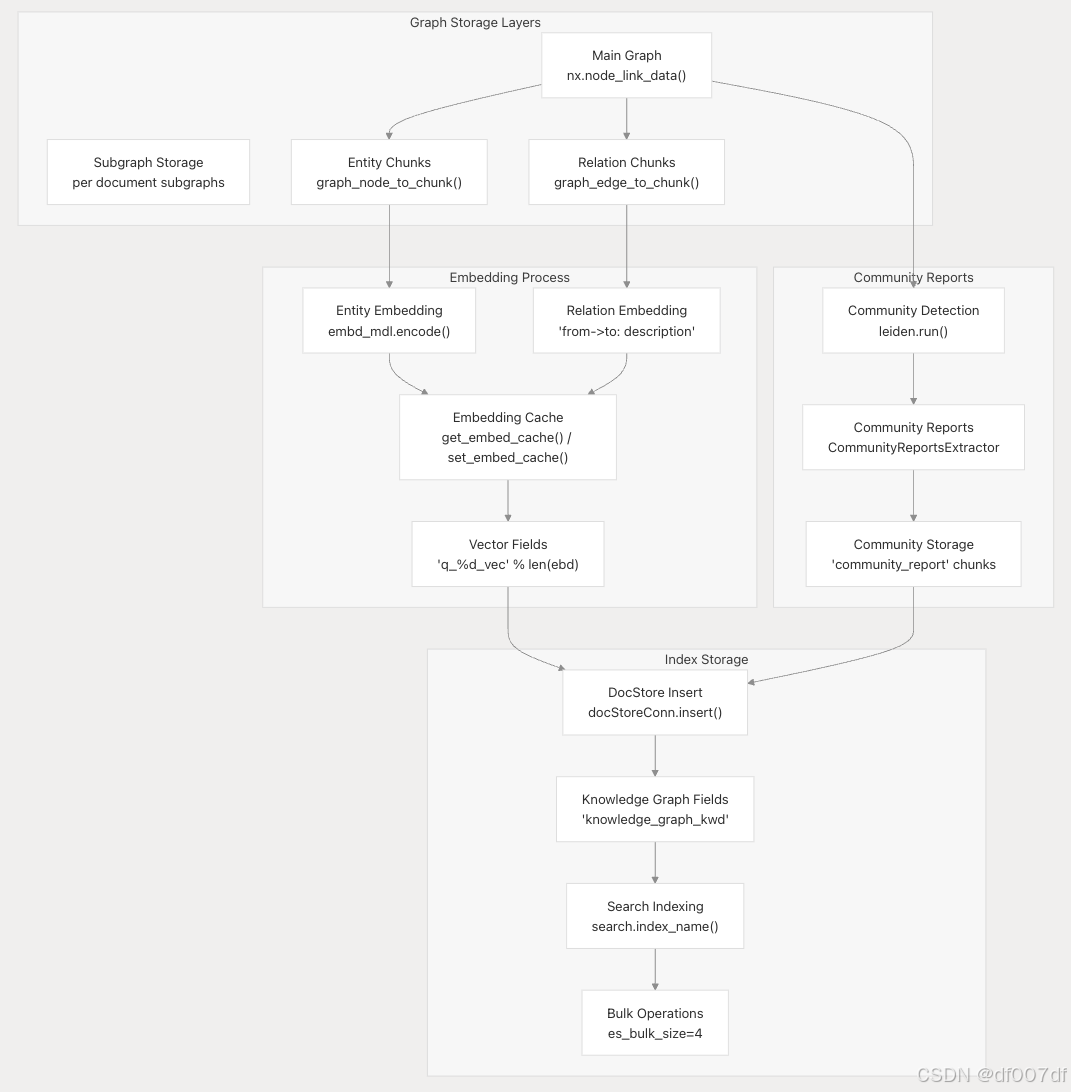
知識圖譜存儲和索引
處理后的知識圖譜以多層格式存儲,支持圖和向量運算:
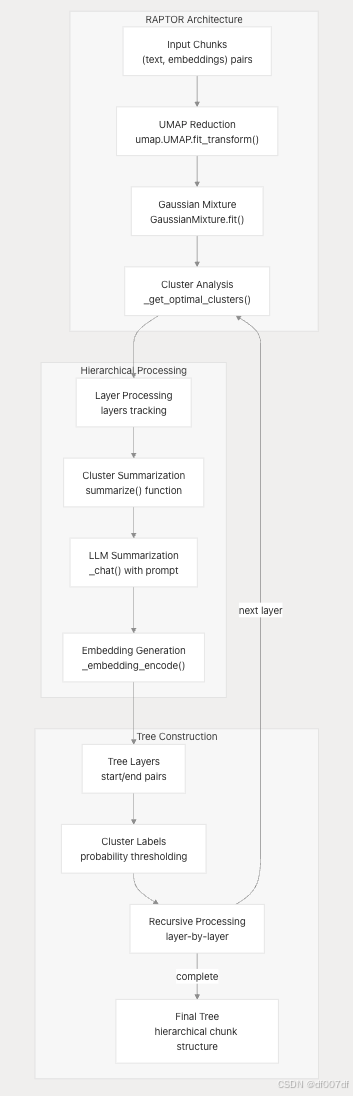
RAPTOR 分層處理
RAPTOR(用于樹組織檢索的遞歸抽象處理)提供分層聚類和總結:
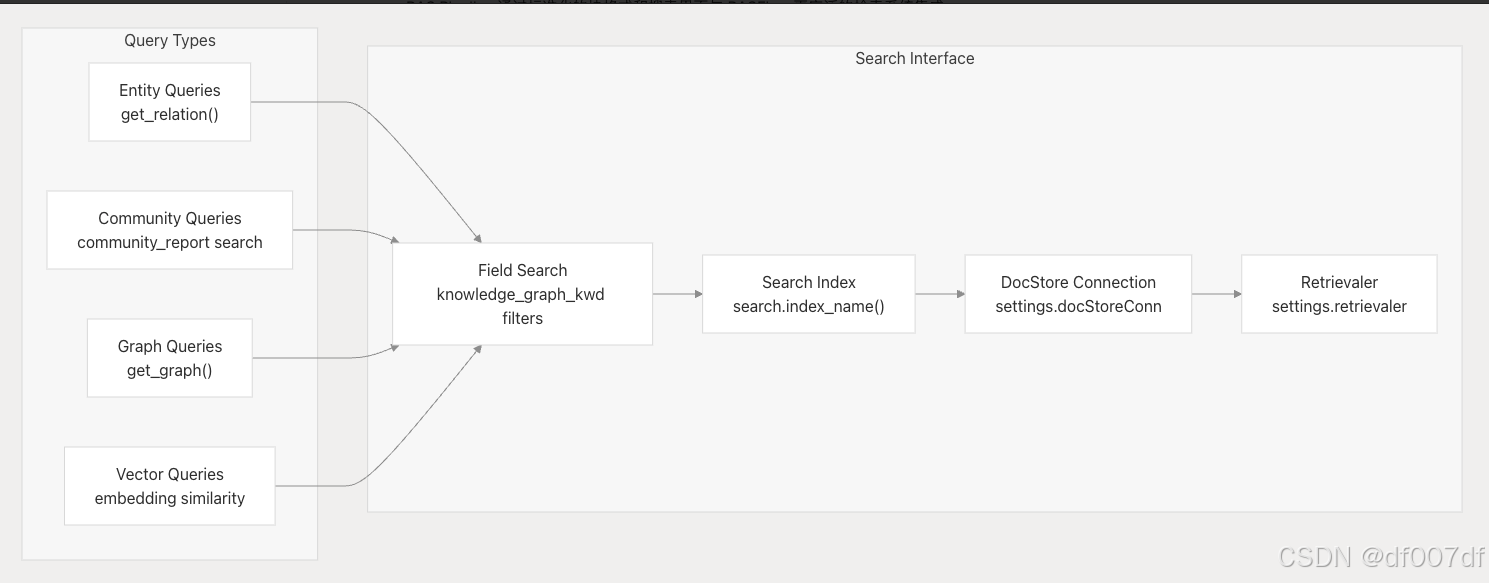
與檢索系統集成
RAG Pipeline 通過標準化的塊格式和搜索界面與 RAGFlow 更廣泛的檢索系統集成:
| 元件 | 積分點 | 數據格式 |
|---|---|---|
| 知識圖譜實體 | knowledge_graph_kwd: “entity” | entity_kwd、entity_type_kwd、content_with_weight |
| 知識圖譜關系 | knowledge_graph_kwd: “relation” | from_entity_kwd、to_entity_kwd、weight_int |
| 社區報告 | knowledge_graph_kwd: “community_report” | entities_kwd、weight_flt、docnm_kwd |
| 圖結構 | knowledge_graph_kwd: “graph” | NetworkX 序列化為 JSON |
| 猛禽摘要 | 標準塊格式 | 分層嵌入向量 |
管道支持通過多種查詢模式進行檢索:



:Visual Studio(IDE) VS Visual Studio Code)
)
免安裝中文版)





)





)

)