操作系統在進行線程切換時需要進行哪些動作?
-
保存當前線程的上下文
保存寄存器狀態、保存棧信息。
-
調度器選擇下一個線程
調度算法決策:根據策略(如輪轉、優先級、公平共享)從就緒隊列選擇目標線程。
處理優先級:實時系統中可能涉及優先級繼承或調整。
-
恢復目標線程的上下文
加載寄存器狀態:從目標線程的TCB中恢復PC、SP、通用寄存器等。
恢復內核堆棧:若目標線程在內核態被掛起,需切換內核堆棧指針。
-
更新線程控制塊(TCB)、調度隊列
切換堆棧指針:用戶態堆棧指針切換至目標線程的堆棧。
設置新線程狀態:將目標線程狀態設為
運行中(Running)。模式切換(若需要):從內核態返回到用戶態,恢復目標線程執行。
什么是用戶態和內核態?
用戶態是普通應用程序的運行級別,具有較低的權限。
-
在用戶態下,程序只能訪問有限的系統資源。
-
用戶態程序只能執行普通指令,不能執行特權指令。
-
用戶態程序通常只能訪問自己的虛擬地址空間。
內核態是操作系統中具有最高權限的運行級別,操作系統的核心代碼和關鍵任務在內核態下運行。
-
在內核態下,程序可以訪問系統的全部資源。
-
內核態代碼可以直接訪問和修改系統的核心數據結構,例如PCB等等。
-
操作系統的核心功能都在內核態下運行。
用戶態什么時候會切換到內核態?
-
用戶態程序通過系統調用請求操作系統服務。此時,操作系統會切換到內核態,執行相應的內核代碼。
-
當中斷/異常發生時,操作系統會從用戶態切換到內核態。
進程之間的通信方式有哪些?
匿名管道
-
匿名管道是特殊文件只存在于內存,沒有存在于文件系統中。
-
通信的數據是無格式的流并且大小受限。
-
通信的方式是單向的,數據只能在一個方向上流動,如果要雙向通信,需要創建兩個管道。
-
匿名管道是只能用于存在父子進程間通信。
命名管道
-
突破了匿名管道只能在親緣關系進程間的通信限制,因為使用命名管道的前提,需要在文件系統創建一個類型為 p 的設備文件,那么毫無關系的進程就可以通過這個設備文件進行通信。
-
另外,不管是匿名管道還是命名管道,進程寫入的數據都是緩存在內核中,另一個進程讀取數據時候自然也是從內核中獲取,同時通信數據都遵循先進先出原則,不支持 lseek 之類的文件定位操作。
消息隊列
-
克服了管道通信的數據是無格式的字節流的問題,消息隊列實際上是保存在內核的「消息鏈表」,消息隊列的消息體是可以用戶自定義的數據類型,發送數據時,會被分成一個一個獨立的消息體,當然接收數據時,也要與發送方發送的消息體的數據類型保持一致,這樣才能保證讀取的數據是正確的。消息隊列通信的速度不是最及時的,畢竟每次數據的寫入和讀取都需要經過用戶態與內核態之間的拷貝過程。
共享內存
-
可以解決消息隊列通信中用戶態與內核態之間數據拷貝過程帶來的開銷,它直接分配一個共享空間,每個進程都可以直接訪問,就像訪問進程自己的空間一樣快捷方便,不需要陷入內核態或者系統調用,大大提高了通信的速度,享有最快的進程間通信方式之名。但是便捷高效的共享內存通信,帶來新的問題,多進程競爭同個共享資源會造成數據的錯亂。
信號量
-
可以保護共享資源,以確保任何時刻只能有一個進程訪問共享資源,這種方式就是互斥訪問。
-
信號量不僅可以實現訪問的互斥性,還可以實現進程間的同步,信號量其實是一個計數器,表示的是資源個數,其值可以通過兩個原子操作來控制,分別是 P 操作和 V 操作。
Socket 通信
-
如果要與不同主機的進程間通信,那么就需要 Socket 通信了。Socket 實際上不僅用于不同的主機進程間通信,還可以用于本地主機進程間通信,可根據創建 Socket 的類型不同,分為三種常見的通信方式,一個是基于 TCP 協議的通信方式,一個是基于 UDP 協議的通信方式,一個是本地進程間通信方式。
進程有哪五種狀態?
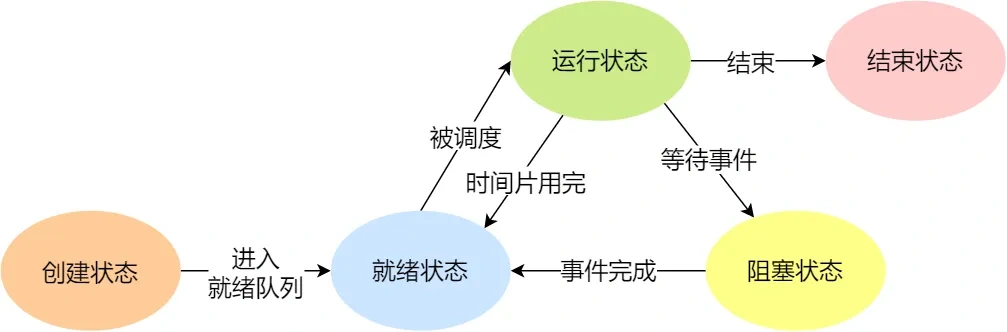
進程的調度算法?
先來先服務 FCFS
最簡單的一個調度算法,就是非搶占式的先來先服務(First Come First Severd, FCFS)算法了。

顧名思義,先來后到,每次從就緒隊列選擇最先進入隊列的進程,然后一直運行,直到進程退出或被阻塞,才會繼續從隊列中選擇第一個進程接著運行。
這似乎很公平,但是當一個長作業先運行了,那么后面的短作業等待的時間就會很長,不利于短作業。 FCFS 對長作業有利,適用于 CPU 繁忙型作業的系統,而不適用于 I/O 繁忙型作業的系統。
最短作業優先 SJF
最短作業優先(Shortest Job First, SJF)調度算法同樣也是顧名思義,它會優先選擇運行時間最短的進程來運行,這有助于提高系統的吞吐量。
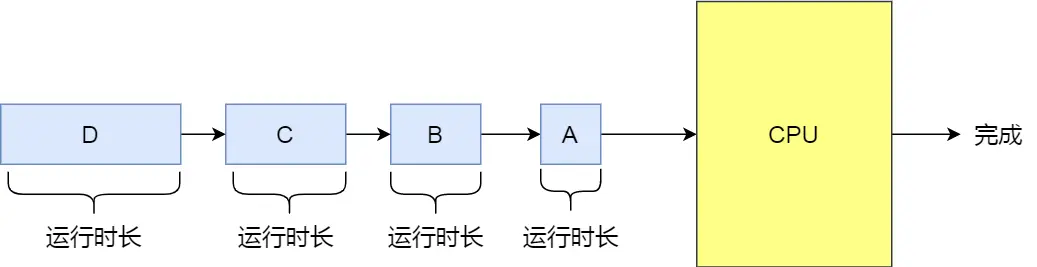
這顯然對長作業不利,很容易造成一種極端現象。
比如,一個長作業在就緒隊列等待運行,而這個就緒隊列有非常多的短作業,那么就會使得長作業不斷的往后推,周轉時間變長,致使長作業長期不會被運行。
高響應比優先 HRRN
前面的「先來先服務調度算法」和「最短作業優先調度算法」都沒有很好的權衡短作業和長作業。
那么,高響應比優先 (Highest Response Ratio Next, HRRN)調度算法主要是權衡了短作業和長作業。
每次進行進程調度時,先計算「響應比優先級」,然后把「響應比優先級」最高的進程投入運行,「響應比優先級」的計算公式:
從上面的公式,可以發現:
-
如果兩個進程的「等待時間」相同時,「要求的服務時間」越短,「響應比」就越高,這樣短作業的進程容易被選中運行;
-
如果兩個進程「要求的服務時間」相同時,「等待時間」越長,「響應比」就越高,這就兼顧到了長作業進程,因為進程的響應比可以隨時間等待的增加而提高,當其等待時間足夠長時,其響應比便可以升到很高,從而獲得運行的機會;
時間片輪轉 RR
最古老、最簡單、最公平且使用最廣的算法就是時間片輪轉(Round Robin, RR)調度算法。
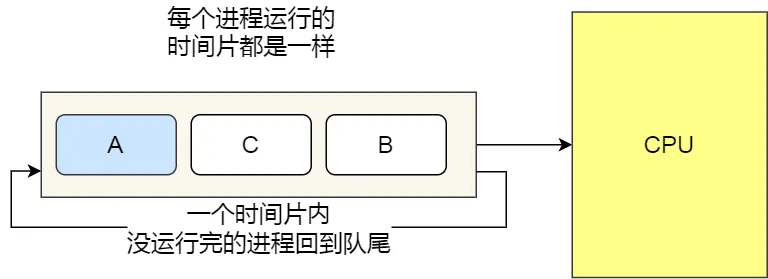
每個進程被分配一個時間段,稱為時間片(Quantum),即允許該進程在該時間段中運行。
-
如果時間片用完,進程還在運行,那么將會把此進程從 CPU 釋放出來,并把 CPU 分配另外一個進程;
-
如果該進程在時間片結束前阻塞或結束,則 CPU 立即進行切換;
另外,時間片的長度就是一個很關鍵的點:
-
如果時間片設得太短會導致過多的進程上下文切換,降低了 CPU 效率;
-
如果設得太長又可能引起對短作業進程的響應時間變長。將
通常時間片設為 20ms~50ms 通常是一個比較合理的折中值。
優先級調度 HPF
前面的「時間片輪轉算法」做了個假設,即讓所有的進程同等重要,也不偏袒誰,大家的運行時間都一樣。
但是,對于多用戶計算機系統就有不同的看法了,它們希望調度是有優先級的,即希望調度程序能從就緒隊列中選擇最高優先級的進程進行運行,這稱為最高優先級(Highest Priority First,HPF)調度算法。 進程的優先級可以分為,靜態優先級或動態優先級:
-
靜態優先級:創建進程時候,就已經確定了優先級了,然后整個運行時間優先級都不會變化;
-
動態優先級:根據進程的動態變化調整優先級,比如如果進程運行時間增加,則降低其優先級,如果進程等待時間(就緒隊列的等待時間)增加,則升高其優先級,也就是隨著時間的推移增加等待進程的優先級。
該算法也有兩種處理優先級高的方法,非搶占式和搶占式:
-
非搶占式:當就緒隊列中出現優先級高的進程,運行完當前進程,再選擇優先級高的進程。
-
搶占式:當就緒隊列中出現優先級高的進程,當前進程掛起,調度優先級高的進程運行。
但是依然有缺點,可能會導致低優先級的進程永遠不會運行。
多級反饋隊列調度算法
多級反饋隊列(Multilevel Feedback Queue)調度算法是「時間片輪轉算法」和「最高優先級算法」的綜合和發展。
顧名思義:
-
「多級」表示有多個隊列,每個隊列優先級從高到低,同時優先級越高時間片越短。
-
「反饋」表示如果有新的進程加入優先級高的隊列時,立刻停止當前正在運行的進程,轉而去運行優先級高的隊列;
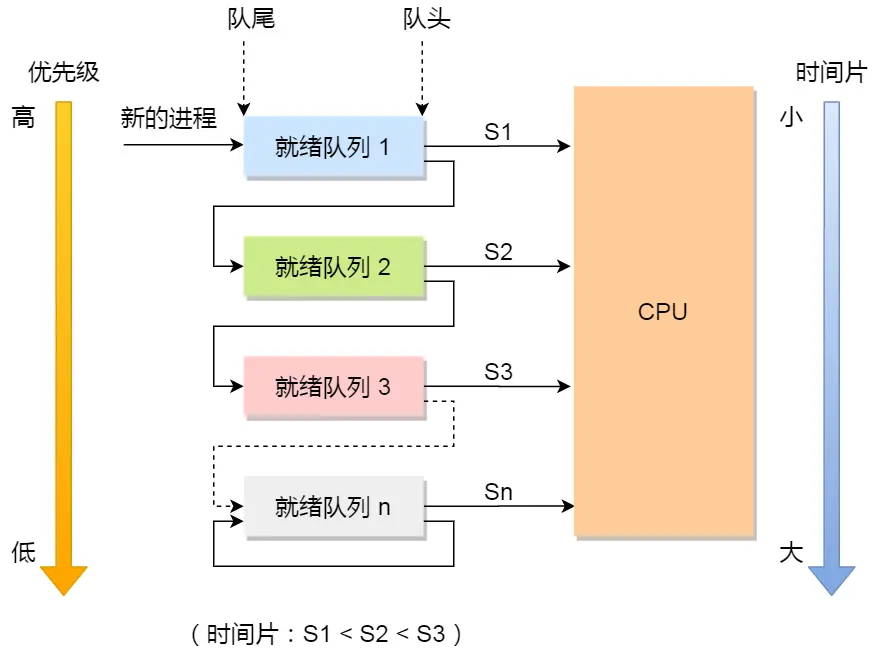
來看看,它是如何工作的:
-
設置了多個隊列,賦予每個隊列不同的優先級,每個隊列優先級從高到低,同時優先級越高時間片越短;
-
新的進程會被放入到第一級隊列的末尾,按先來先服務的原則排隊等待被調度,如果在第一級隊列規定的時間片沒運行完成,則將其轉入到第二級隊列的末尾,以此類推,直至完成;
-
當較高優先級的隊列為空,才調度較低優先級的隊列中的進程運行。如果進程運行時,有新進程進入較高優先級的隊列,則停止當前運行的進程并將其移入到原隊列末尾,接著讓較高優先級的進程運行;
可以發現,對于短作業可能可以在第一級隊列很快被處理完。
對于長作業,如果在第一級隊列處理不完,可以移入下次隊列等待被執行,雖然等待的時間變長了,但是運行時間也會更長了,所以該算法很好的兼顧了長短作業,同時有較好的響應時間。
| 調度算法 | 公平性 | 系統吞吐量 | 響應時間 | 復雜度 | 適用場景 |
| FCFS | 低 | 低 | 高 | 低 | 簡單系統 |
| SJF | 低 | 高 | 高 | 中 | 批處理系統(需解決饑餓) |
| RR | 高 | 中 | 低 | 中 | 交互式系統 |
| 優先級調度 | 中 | 中 | 中 | 中 | 實時系統 |
| 多級反饋隊列 | 高 | 高 | 低 | 高 | 復雜系統 |
| HRRN | 高 | 高 | 低 | 中 | 平衡短作業和長作業的系統 |
| 公平共享調度 | 高 | 中 | 中 | 高 | 多用戶系統 |
| 實時調度算法 | 高 | 高 | 低 | 高 | 實時系統 |
線程和進程有什么區別?
| 進程 | 線程 | |
| 定義 | 操作系統分配資源的基本單位 | 進程內的一個執行單元 |
| 資源分配 | 獨立地址空間、文件描述符表等 | 共享所屬進程的資源 |
| 創建和銷毀開銷 | 大 | 小 |
| 通信方式 | 需要IPC機制 | 直接通過共享內存 |
| 調度 | 操作系統調度的基本單位 | CPU調度的基本單位 |
| 內存使用 | 獨立內存空間 | 共享內存空間 |
| 應用場景 | 需要獨立運行、資源隔離 | 需要并發執行、提高效率 |
為什么要有虛擬內存?
虛擬內存是一種計算機存儲管理技術,它可以在硬盤上模擬出一個比物理內存更大的地址空間,使得操作系統和應用程序可以使用比實際可用內存更大的內存。以下是虛擬內存的主要作用和原因:
-
擴展可用內存
背景:計算機的物理內存(RAM)是有限的,而現代應用程序和操作系統可能需要比實際物理內存更多的內存空間來運行。
作用:虛擬內存通過將一部分硬盤空間(通常是磁盤分區或文件)作為擴展內存使用,從而擴展了可用的內存空間。當物理內存不足時,操作系統會將暫時不用的數據從物理內存移動到虛擬內存(磁盤空間)中,這個過程稱為“交換”(Swapping)或“分頁”(Paging)。
優勢:允許運行比實際物理內存更大的程序,提高了系統的靈活性和可用性。
-
隔離進程地址空間
背景:在多任務操作系統中,多個進程同時運行,每個進程都有自己的代碼、數據和堆棧。
作用:虛擬內存為每個進程提供了一個獨立的虛擬地址空間。每個進程都認為自己獨占了整個內存空間,而實際上這些地址空間是由操作系統通過虛擬內存管理單元(MMU)映射到物理內存中的。
優勢:
??保護:防止一個進程訪問或破壞另一個進程的內存空間,提高了系統的穩定性和安全性。
??簡化編程:程序員可以編寫代碼時假設整個地址空間都是可用的,而不需要擔心內存沖突。
-
提高內存利用率
背景:物理內存的分配和回收是一個復雜的過程,容易導致內存碎片化,降低內存的利用率。
作用:虛擬內存通過分頁或分段機制,將內存劃分為固定大小的頁面(通常是4KB)或段。操作系統可以動態地分配和回收這些頁面,從而更高效地利用物理內存。
優勢:減少了內存碎片化,提高了內存的利用率,使得更多的程序可以同時運行。
I/O是什么?
I/O(Input/Output,輸入/輸出)是指計算機系統中與外部設備進行數據交換的過程。
I/O系統主要由以下幾個部分組成:輸入設備、輸出設備、存儲設備。
I/O操作可以根據數據傳輸的方向和方式分為:
-
輸入:從外部設備向計算機系統傳輸數據。
-
輸出:從計算機系統向外部設備傳輸數據。
IO 處理機制與 IO 模型的關系與區別
1. 核心概念區分
I/O 處理機制(如 Polling、Interrupt、DMA) 屬于底層硬件與操作系統協作的技術,解決的是數據如何從設備傳輸到內存的問題,關注的是物理層面的效率(CPU 利用率、數據傳輸速度等)。
例如:DMA 控制器如何繞過 CPU 直接搬運磁盤數據到內存。
I/O 模型(如阻塞、非阻塞、多路復用、異步) 屬于應用程序與操作系統交互的編程范式,解決的是如何組織和管理 I/O 操作的問題,關注的是代碼邏輯的簡潔性和性能優化。
例如:使用
select函數同時監控多個 socket 的讀寫狀態。
I/O處理機制三種
I/O操作可以通過不同的模式進行,主要取決于數據傳輸的控制方式和性能要求:
-
程序控制I/O(Polling):
-
本質:CPU主動輪詢設備狀態(“忙等待”模式)。
-
原理:CPU通過輪詢(Polling)的方式不斷檢查I/O設備的狀態,以確定設備是否準備好進行數據傳輸。
-
優點:實現簡單,不需要額外的硬件支持。
-
缺點:CPU效率低,因為CPU需要不斷檢查設備狀態,可能導致CPU資源浪費。
-
-
中斷驅動I/O(Interrupt-Driven I/O):
-
本質:設備主動通知CPU(事件驅動模式)。
-
原理:I/O設備在準備好數據后,通過中斷信號通知CPU。CPU在接收到中斷信號后,執行中斷處理程序來完成數據傳輸。
-
優點:CPU不需要頻繁檢查設備狀態,可以更高效地執行其他任務。
-
缺點:中斷處理需要一定的開銷,頻繁的中斷可能會降低系統性能。
-
-
直接內存訪問(DMA,Direct Memory Access):
-
本質:繞過CPU,設備直接與內存交互。
-
原理:DMA允許I/O設備直接與內存進行數據傳輸,而不需要CPU的直接參與。DMA控制器負責管理數據傳輸過程。
-
優點:大大減少了CPU的負擔,提高了數據傳輸效率。
-
缺點:需要額外的硬件支持(DMA控制器),并且DMA操作需要與CPU協調,以避免內存訪問沖突。
-
I/O模型有哪些?(編程層面)
-
阻塞式I/O(Blocking I/O)
-
原理
-
線程發起
read()調用后阻塞等待數據就緒,直到數據到達后才返回。
-
-
特點:
-
效率較低,因為線程在等待I/O操作完成時無法執行其他任務。
-
-
非阻塞式I/O(Non-Blocking I/O)
-
原理:
-
線程發起
read()后立即返回,需輪詢檢查狀態(返回EAGAIN時重試)。
-
-
特點:
-
避免了線程阻塞,但輪詢操作會占用大量CPU資源,效率較低。
-
-
I/O多路復用(I/O Multiplexing)
-
原理:
-
“I/O多路復用”允許一個進程同時監視多個輸入/輸出源,當任何一個源準備就緒時,該進程都能夠及時地處理它。
-
當任何一個I/O事件準備好時,系統調用返回,應用程序可以處理相應的I/O操作。
-
-
特點:
-
提高了線程的利用率,減少了線程上下文切換的開銷。
-
同步和異步的區別?
-
同步:
-
原理:在同步模式下,調用方在發起一個操作后,必須等待該操作完成,才能繼續執行后續代碼。
-
缺點:效率較低,特別是在涉及I/O操作(如網絡請求、文件讀寫)時,調用方會浪費大量時間等待操作完成,導致資源利用率低。
-
適用場景:
-
對實時性要求不高,任務執行時間較短的場景。
-
任務之間依賴性強,必須按順序執行的場景。
-
簡單的腳本或工具,對性能要求不高的場景。
-
-
-
異步:
-
原理:在異步模式下,任務可以并發執行。調用方在發起一個操作后,不需要等待該操作完成,可以繼續執行其他任務。當操作完成時,系統會通知調用方。
-
缺點:實現復雜,代碼邏輯可能較難理解和維護,需要處理回調、事件通知等機制。
-
適用場景:
-
高并發場景,如Web服務器、聊天服務器等。
-
涉及大量I/O操作的場景,如網絡請求、文件讀寫等。
-
需要提高系統吞吐量和資源利用率的場景。
-
-
阻塞和非阻塞的區別?
阻塞(Blocking)和非阻塞(Non-Blocking)是描述I/O操作(輸入/輸出操作)行為的兩種模式。
-
阻塞:
-
在阻塞模式下,當調用方發起一個I/O操作(如讀取文件、從網絡接收數據)時,調用方會被掛起,直到I/O操作完成。調用方無法執行其他任務,必須等待I/O操作完成才能繼續執行。
-
-
非阻塞:
-
在非阻塞模式下,當調用方發起一個I/O操作時,調用方不會被掛起。如果I/O操作尚未完成,調用方會立即返回一個錯誤碼(如
EAGAIN或EWOULDBLOCK),表示操作尚未準備好。調用方可以繼續執行其他任務,稍后再嘗試I/O操作。
-
什么是物理地址,什么是邏輯地址?
-
邏輯地址(Logical Address)
-
由程序生成的地址,也稱為虛擬地址(Virtual Address)。在編寫代碼時,程序員使用的指針或變量地址均屬于邏輯地址。這些地址并非真實的物理內存位置,而是由操作系統和硬件共同管理的抽象層。
-
邏輯地址是程序在運行時使用的地址。它是程序中的變量、函數等在虛擬地址空間中的地址。邏輯地址通過內存管理單元(MMU)映射到物理地址。
-
-
物理地址(Physical Address)
-
實際存在于計算機硬件內存(RAM)或內存映射設備中的地址。CPU通過內存總線直接訪問這些地址,以訪問數據。
-
-
邏輯地址與物理地址之間的映射
-
MMU負責將邏輯地址轉換為物理地址。
-
頁表記錄了邏輯頁面與物理頁面幀之間的映射關系。
-
段表記錄了邏輯段與物理內存區域之間的映射關系。
-
-
轉換過程
在支持虛擬內存的系統中,邏輯地址需通過以下步驟轉換為物理地址:
-
分段機制(可選):
-
邏輯地址由段選擇符(Segment Selector)和段內偏移(Offset)組成。
-
段選擇符通過段描述符表(如GDT/LDT)找到段基址(Base Address)。
-
線性地址(Linear Address)= 段基址 + 偏移量。
-
注:現代操作系統(如Linux)通常使用平坦內存模型,段基址為0,邏輯地址直接等于線性地址。
-
-
分頁機制:
-
線性地址被拆分為頁號(Page Number)和頁內偏移(Page Offset)。
-
頁表(Page Table)將頁號映射為物理頁框號(Frame Number)。
-
物理地址 = 物理頁框號 × 頁大小(如4KB) + 頁內偏移。
-
示例: 假設邏輯地址為
0x0804A000,分頁后:
頁號:
0x0804A,頁內偏移:0x000頁表映射頁號
0x0804A到物理頁框0x12345物理地址:
0x12345 × 4096 + 0x000 = 0x12345000




——THORChain退款邏輯漏洞)








:使用屬性表(Property Sheet)實現自動化Qt編譯流程)



)

:少量實驗即可找到新材料,黑盒優化?量子退火)