目錄:導讀
- 前言
- 一、Python編程入門到精通
- 二、接口自動化項目實戰
- 三、Web自動化項目實戰
- 四、App自動化項目實戰
- 五、一線大廠簡歷
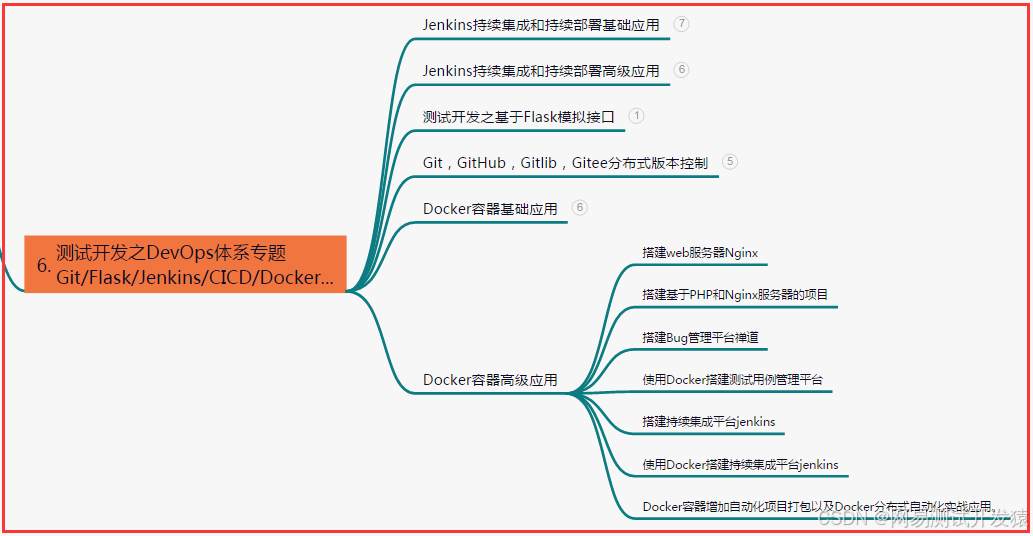
- 六、測試開發DevOps體系
- 七、常用自動化測試工具
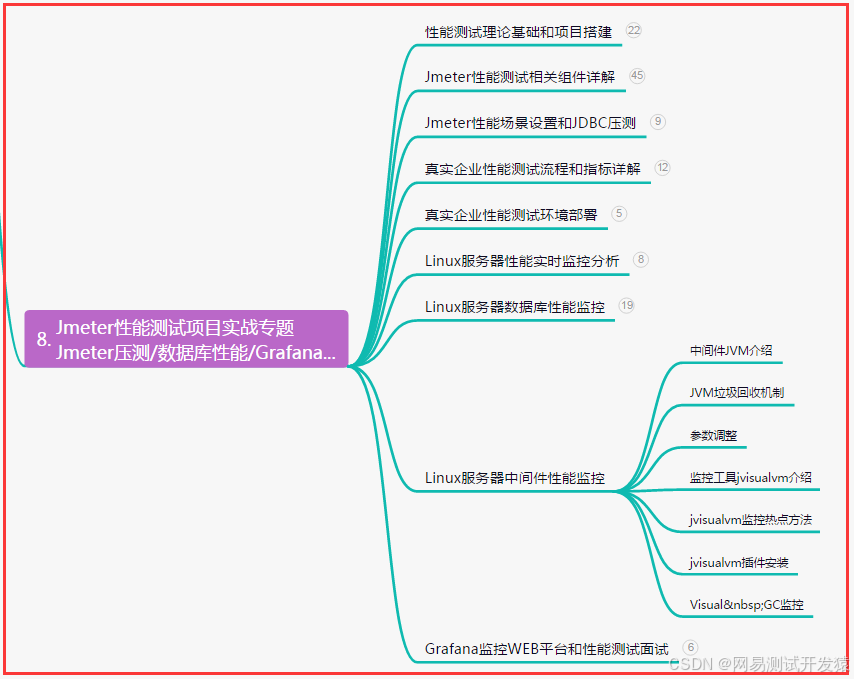
- 八、JMeter性能測試
- 九、總結(尾部小驚喜)
前言
1、準備工作
準備工作在性能測試中,是最為耗時以及麻煩的,不僅需要各個團隊協同配合,還需要不斷驗證,以確保相關的準備事項不會對性能測試結果造成較大影響。
以我司的性能測試流程來說,準備階段的各事項以及對應責任人,如下圖:
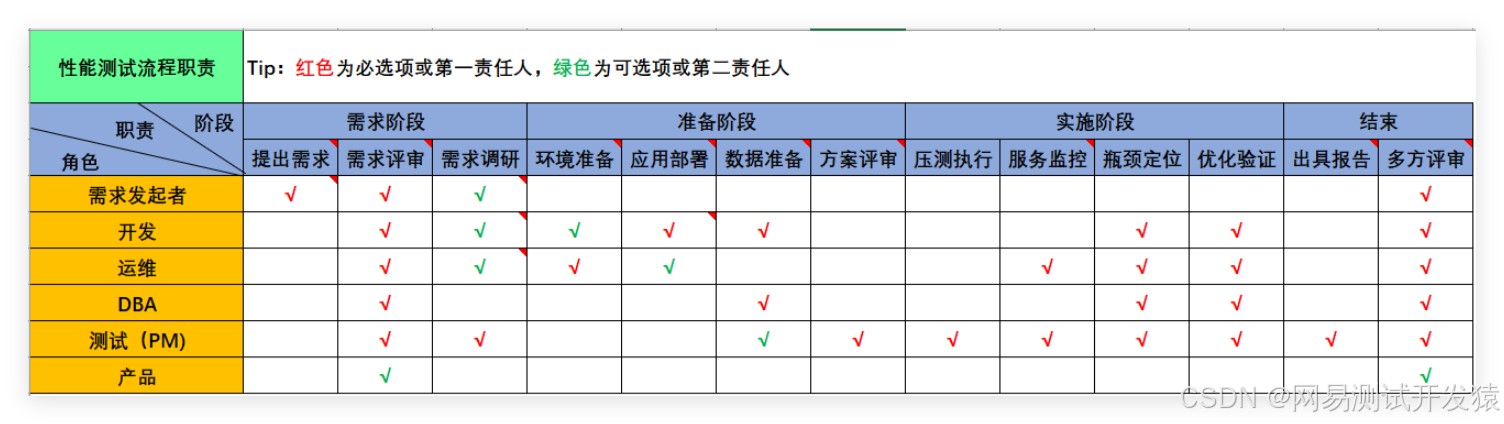
在準備階段,性能測試童鞋,要盡可能承擔起PM這一角色的職責,跨部門溝通,協調資源以及推動準備工作的快速落地,這樣才能在有限時間內完成準備事項,為壓測預留足夠的時間。
2、壓測監控
完成了前面的幾項工作,就可以進入壓測階段了,這一階段,可以分為兩部分,壓測+監控。
1)壓測
壓測工作主要有如下幾種情景,按照預先制定的測試策略執行即可(不排除臨時特殊情況,這里需靈活調整)。
①單機單接口測試:該策略主要是為了驗證單接口的性能基準,避免整個調用鏈路過程中某個服務/接口成為瓶頸;
②單機多接口測試:相較于微服務架構的服務解耦,有時候某些服務間互相調用依賴的強關系可能會造成資源競爭等情況,需要通過這種方式來排查驗證;
③單機混合場景測試:這種測試方式的主要作用是得到一個單機混合場景下的最優性能表現,為服務擴容和線上容量規劃提供參考數據;
④多節點測試:現在大多數的互聯網企業都采用的集群/分布式/微服務架構,在多節點部署時候,考慮到SLB的邊際遞減效應,需要進行多節點測試;
通過該種方式,來驗證負載均衡遞減比率,為生產擴容提供精確的參考依據;
⑤高可用測試:高可用主要驗證2點:服務異常/宕機是否可以恢復以及恢復到正常水*所耗費的時間(越短越好)。
⑥穩定性測試:前面提到了核心業務流程必須保證穩定性,穩定性測試一般根據系統特點和業務類型,分為兩類:5d*12h、7d*24h。
一般來說,穩定性測試的執行時間,12h即可(當然,24h或者更長也可以,根據具體情況靈活調整)。
2)監控
性能測試過程中,監控是很重要的一環,它可以幫助我們驗證測試的結果是否滿足預期指標,以及協助我們發現系統存在的問題。常見的監控指標如下:
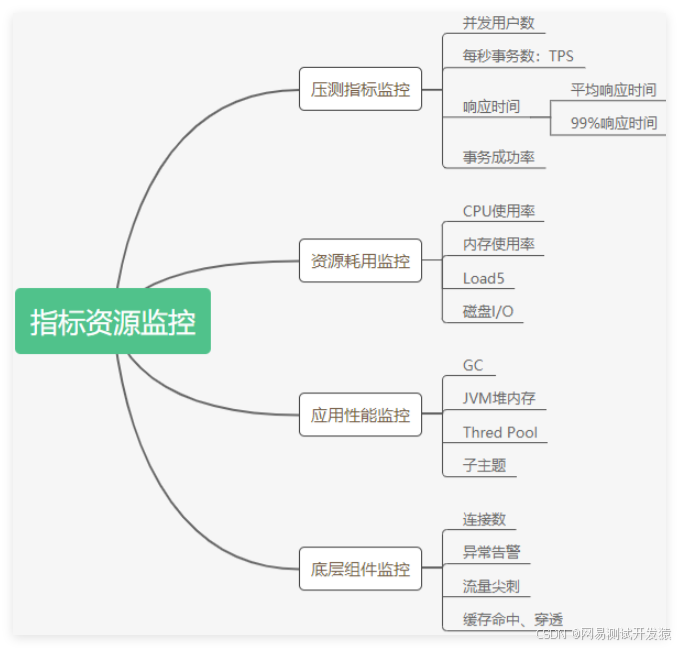
那么如何監控這些指標呢?
如果采用的云服務器(比如阿里云),現在國內的云廠商都提供了監控大盤以及各種監控服務(比如阿里云的APM、ARMS、AHAS)。
如果是自建服務機房,可以借助運維搭建的監控體系,比如全鏈路追蹤(pinpoint、cat、zipkin、skywalking),專業的監控工具比如Nmon、Zabbix等。
測試指標的監控,可以搭建基于開源組件的Grafana+InfluxDB+Jmeter+Nmon2influxdb,或者ELK等監控體系。
3、分析調優
1)性能分析
性能分析是一個復雜的話題,不同的系統架構設計、應用場景、業務邏輯、編程語言及采用的框架,都有一定的差異。抽象來說,有如下三種分析思路:
①自上而下:即通過生成負載來觀察被測系統的性能表現,比如通過對TPS、RT等指標的監控,從請求發起端到OS端層層剖析,從而找到系統性能瓶頸。
②自下而上:通過監控各硬件及操作系統相關指標(CPU、Memory、磁盤I/O、網絡)來分析性能瓶頸。
③從局部到整體:即通過性能表象結合工作經驗做快速排除,確定可能存在瓶頸的局部所在,快速修改驗證,避免大而全的全面分析帶來的耗時,提高效率。
2)性能調優
性能調優主要關注三個方面:降低響應時間、提高系統吞吐量、提高服務的可用性。
性能優化的目的是:在保持和降低系統99%RT的前提下,不斷提高系統吞吐量以及流量高峰時期的服務可用性。
性能調優建議遵循如下幾點原則:
①Gustafson定律:系統優化某組件所獲得的系統性能的改善程度,取決于該部件被使用的頻率,或所占總執行時間的比例。
②Amdahl定律:S=1/(1-a+a/n)
其中,a為并行計算部分所占比例,n為并行處理結點個數。這樣,當1-a=0時,(沒有串行,只有并行)最大加速比s=n;
當a=0時(只有串行,沒有并行),最小加速比s=1;當n→∞時,極限加速比s→ 1/(1-a),這也就是加速比的上限。
③最小可用原則:一般情況下,系統的代碼量會隨著功能的增加而變多,健壯性有時候也需要通過編寫異常處理代碼來實現,異常考慮越全面,異常處理的代碼量就越大。
隨著代碼量的增大,引入BUG的概率也越大,系統也就越不健壯。從另一個方面來說,異常流程處理代碼也要考慮健壯性的問題,這就形成了無限循環。
因此在系統設計和代碼編寫過程中,要求:一個功能模塊如非必要,就不要;一段代碼如非必寫,則不寫。
4、容量規劃
性能測試的最終目的是保證線上服務的可用性,及時響應并滿足業務需求。而容量規劃,是對線上服務在峰值流量沖擊下穩定運行的最佳保障。
1)單機混合容量
這里的容量指的是在單臺服務器下,混合場景壓測的最優性能表現(而不是最高)。比如一臺4C8G的服務器,對核心業務場景進行按業務配比混合壓測,示例如下圖:
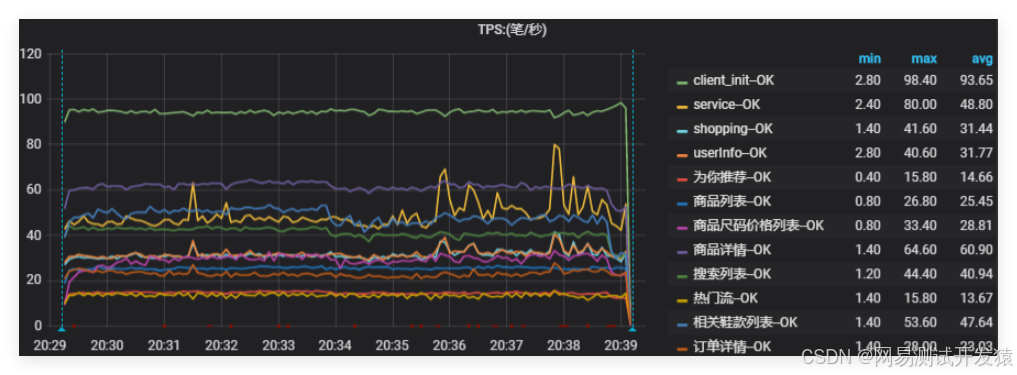
得到單機最優容量數值,然后可以通過增加被測系統的服務節點,來驗證容量是否隨著服務節點的增加而線性增長。
2)多節點SLB容量
以上面的示例圖來說,單機最優TPS≈450,然后通過增加服務節點數量,再次壓測,通過擴容后的壓測數值除以服務節點數量,然后和單機混合容量對比,就可以得到多節點SLB的遞減比率。
舉例:擴容后的壓測數值為R,服務節點數量為N,單機混合容量為D,那么多節點SLB的遞減比率計算公式為:SLB%=(R/N)/D。
以前面的例子來說,單機混合容量為450,服務節點擴展到2臺,得到測試結果為750,那么SLB%=(750/2)/450≈83.33%。
以此類推,如果預期線上性能指標要求TPS≥5000,那么通過計算,我們可以得到線上服務節點最少需要擴容到14臺,才能滿足需要。
PS:服務節點數量越多,那么遞減效應越明顯,建議通過測試多個服務節點的遞減比率,來得到一個區間數。
3)告警閾值
這里的告警閾值,指的是運維同事對各個服務狀態及相關資源指標進行監控時,設定的提醒和告警閾值。
前面所說的單機混合容量的最優值,建議結合運維設定的閾值來綜合評估(比如運維告警設定的閾值是CPU使用率達到80%,那么就以單機CPU80%耗用下的容量數值作為計算基準)。
4)Buffer機
文章的開頭已經說過,系統不僅要具有高可用和穩定性,還要具有容災機制。比如某個或某部分服務不可用,服務器宕機,需要預留的機器來隨時補上來。
本文所說的Buffer機,即作為預留容災的機器。按照我個人的實踐經驗來說,以線上擴容機器數量的30%來作為預留Buffer機,已經能滿足絕大部分情況(適合中小型團隊)。
當然,有些特殊場景(比如2019年春節聯歡晚會,百度承包的口令紅包場景),就需要綜合考慮更多的影響因素。
除了容量規劃,我們還可以通過服務降級、網關限流甚至熔斷等機制,來保證系統在峰值流量的沖擊下保持服務可用。
完整版!企業級性能測試實戰,速通Jmeter性能測試到分布式集群壓測教程
| 下面是我整理的2025年最全的軟件測試工程師學習知識架構體系圖 |
一、Python編程入門到精通
二、接口自動化項目實戰
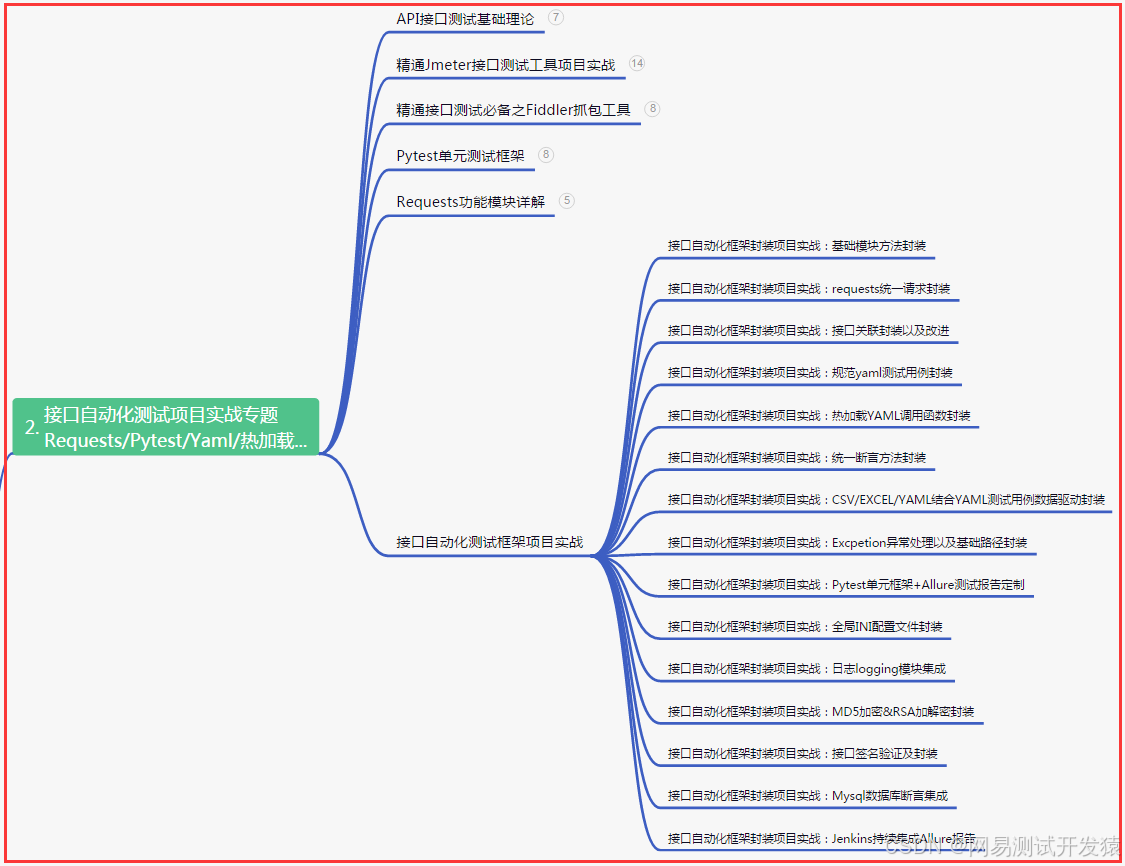
三、Web自動化項目實戰
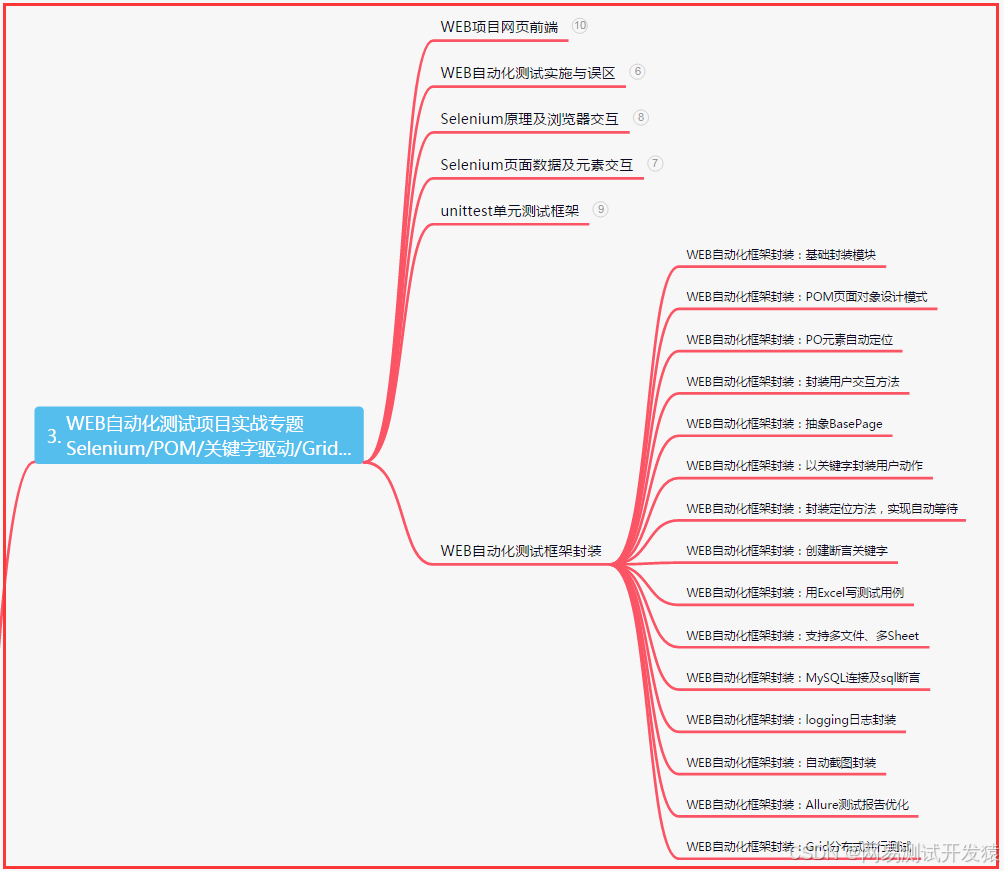
四、App自動化項目實戰
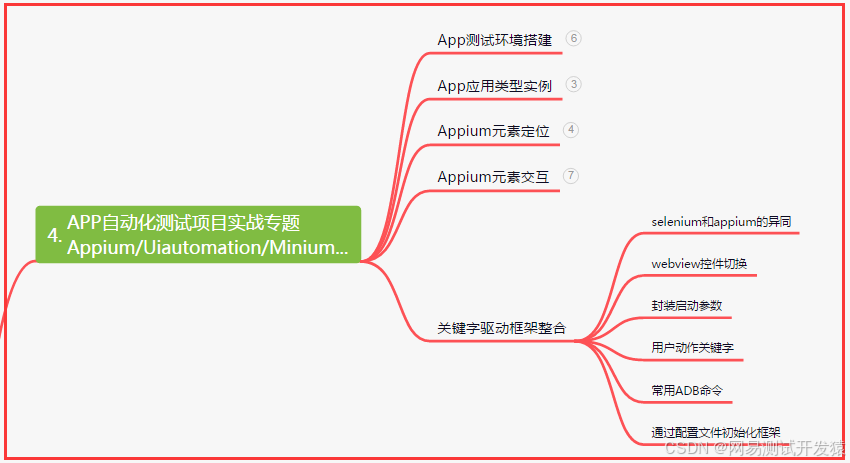
五、一線大廠簡歷
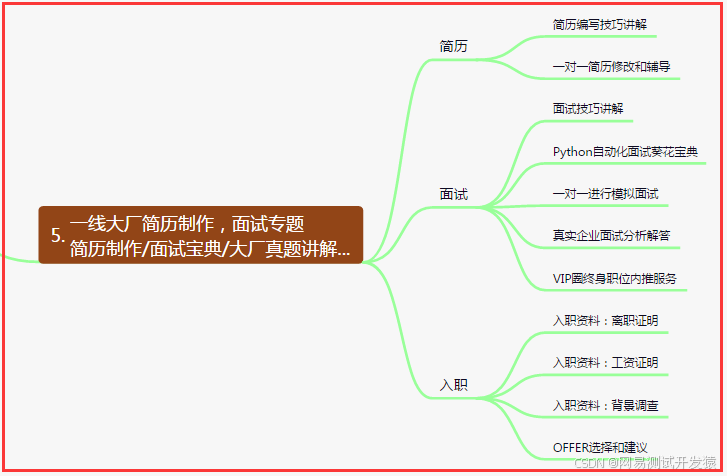
六、測試開發DevOps體系
七、常用自動化測試工具

八、JMeter性能測試
九、總結(尾部小驚喜)
人生最動人的風景,往往藏在最險峻的山巔。當你覺得力竭時,請記住:每一次堅持都在重塑更強大的自己。別問路有多遠,只管邁步向前;別怕山有多高,向上攀登就是答案!
你體內沉睡著改變世界的力量!每個清晨都是改寫命運的新機會,每次挫折都是精心包裝的禮物。當全世界都在說"不可能"時,正是你證明"可能"的最好時機!
 v1.0.2 綠色版)
)
:91-100語法+考え方13)


)

)





——非傳統影像輕量級解決方案)




)
)