通過之前的學習我們已經了解了操作系統當中的基本的概念包括進程、基礎IO、磁盤文件存儲等,但是到目前為止我們還未了解到線程相關的概念,這就使得當前我們對操作系統的認知還不是完整的,現在我們是還是無法理解一個進程當中是如何同時的執行多個任務的。接下來在本篇當中我們就將來了解到線程的相關概念,包括線程在我們的理解上應該是什么樣的,還有線程在操作系統當中具體是如何實現的,以及具體的在我們使用的Linux當中是如何使用的,還會將線程對比我們之前學習的進程,最后再來了解一些線程控制相關的接口,相信通過本篇的學習能讓你對線程有基本的認知,接下來就開始本篇的學習吧!!!

1.線程概念
1.1 什么是線程
實際上從教材當中解釋的線程和之前我們學習過的進程的概念如下所示:
進程:操作系統分配資源(內存、文件描述符等)的基本單位。
線程:進程中的“執行單元”,它負責具體運行代碼。
但是目前的問題是我們還沒有了解過什么是執行流,那么這時我們就試著不從教程中這些晦澀的文字區理解欸,而是轉為從實際Linux當中區理解試試看。
通過之前進程的學習知道進程=內核數據結構+代碼和數據,每個進程都會有其對應的虛擬地址空間和進行映射的頁表,本質上進程的task_struct就是通過虛擬地址空間來“看到”實際上的物理內存,這時就可以將地址空間看作是一個“窗口”。
那么通過以上的理論就可以說明之前我們創建的進程都是讓一個task_struct享有所有的mm_struct,那么會不會出現一種情況就是進程當中同時擁有多個task_struct,這時不就可以讓多個task_struct共享進程當中的虛擬地址空間了嗎。
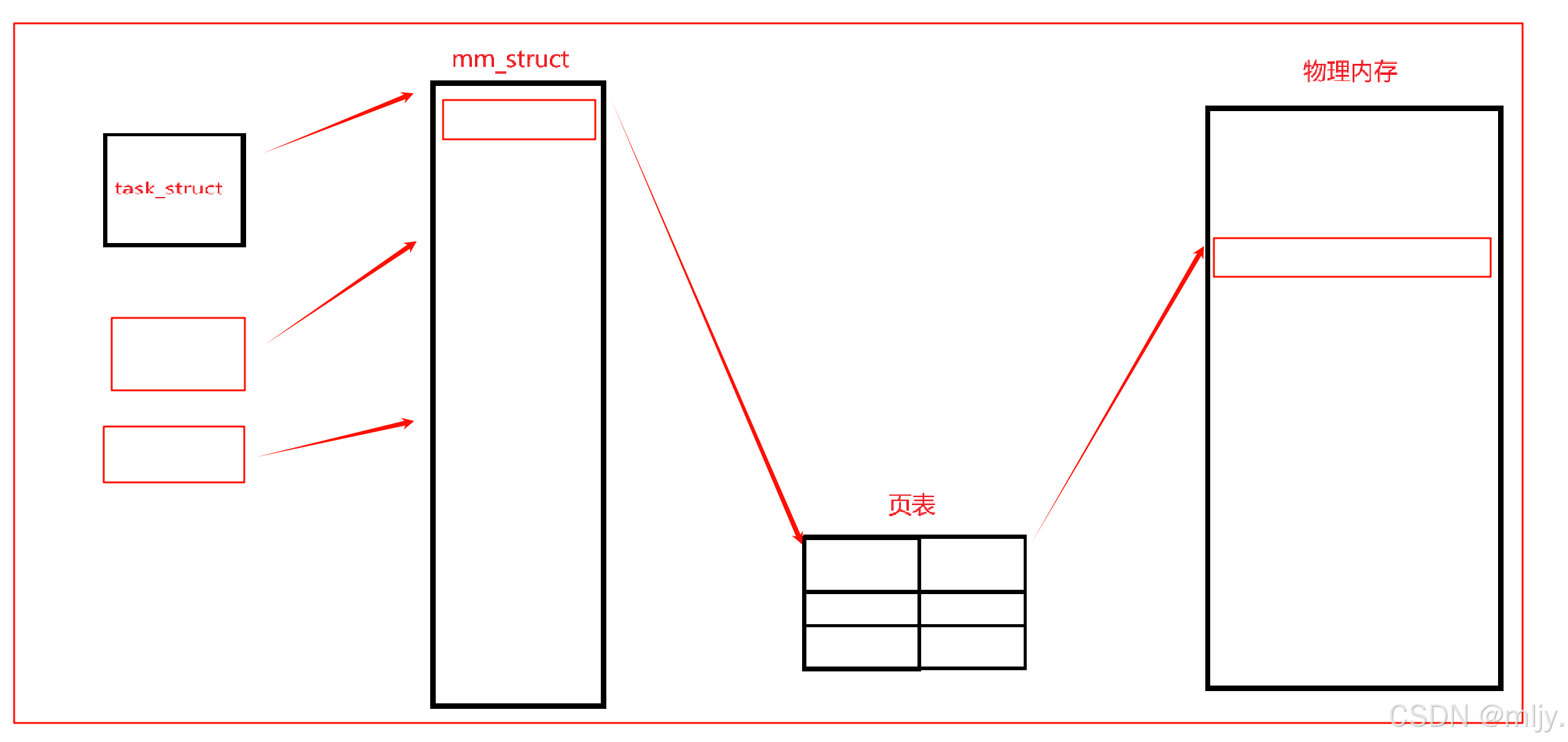
其實以上的設想就是Linux當中實現線程的基本邏輯,本質上在Linux當中是沒有真正的線程的,本質上是使用進程來模擬實現進程,我們將這種用于模擬線程的進程稱為“輕量級進程”,在一個進程當中是會可能出現多個task_struct的,本質上一個task_struct就可以代表一個線程,只不過在之前的學習當中使用到的進程都是只有一個tesk_struct的,這時就表示該進程當中是只有一個線程的。
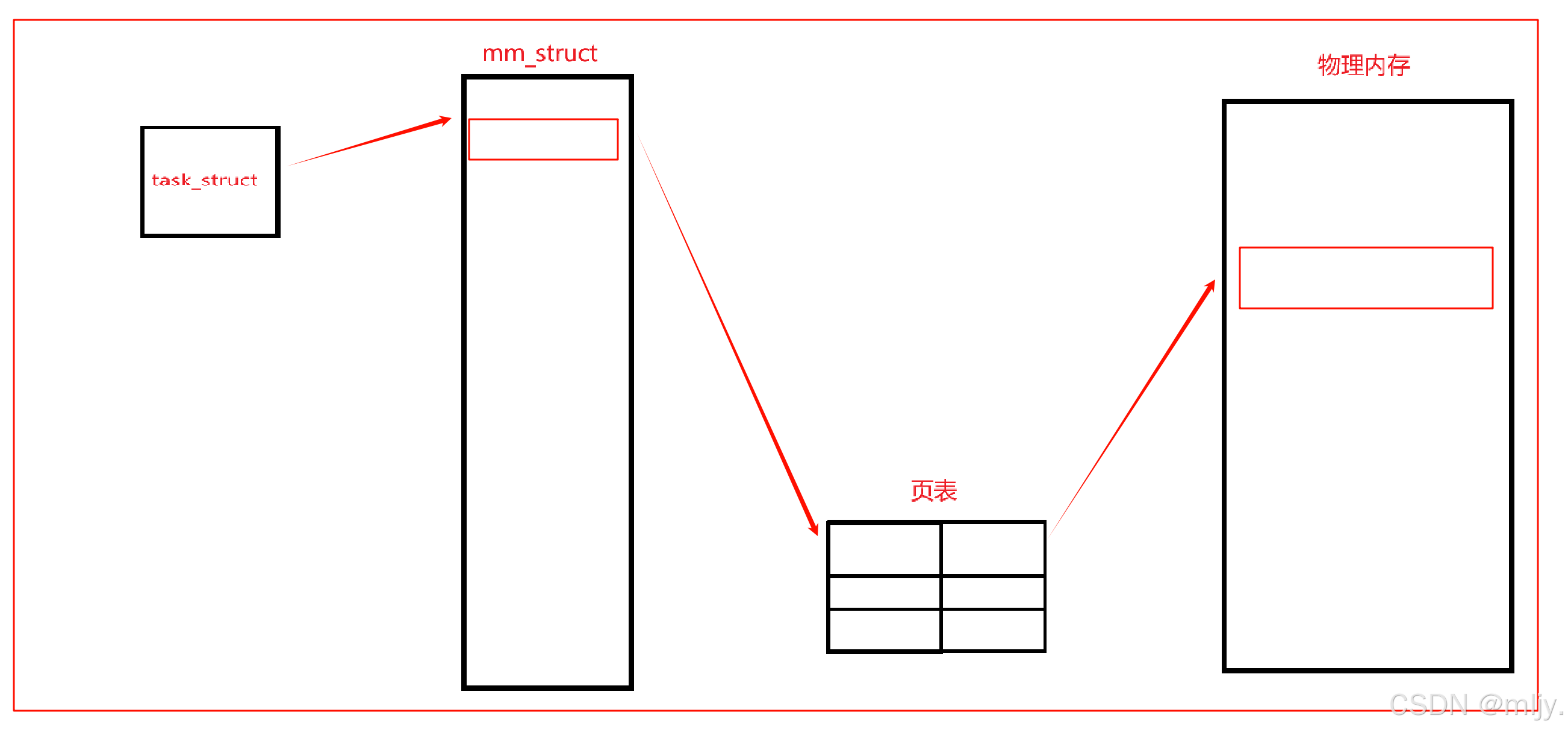
通過以上的說明,那么你其實就可以將執行流簡單的先理解為線程,一個進程當中可以存在多個線程就是可以同時存在多個執行流,相比進程線程創建、銷毀的成本更小,從內核當中就可以理解為線程在銷毀的時候只需要銷毀對應的PCB即可,但是進程則需要將虛擬地址空間和頁表也進行銷毀。
但實際上線程是不完全等同與執行流的,實際上 線程=執行流+必要的運行環境。
注:輕量級進程這種概念實際上只是在Linux當中才有的,其他的操作系統當中正常是沒有的,因為例如Windows這些操作系統實現線程的方式是在內核當中實現真正的線程。
這時候你可能就會思考,為什么在Linux當中要使用這種方法來實現線程呢?為什么不在內核當中實現真正的線程的數據結構對象呢?
這個問題其實很好理解,Linux其實也可以像Windows一樣在內核當中實現真正的線程,在Windows當中有專門的數據結構對象TCB,而在Linux當中使用PCB來模擬實現線程是因為使用PCB就意味著線程的內核代碼是可以復用PCB的代碼的,那么這時就可以讓線程基于原來的代碼實現。
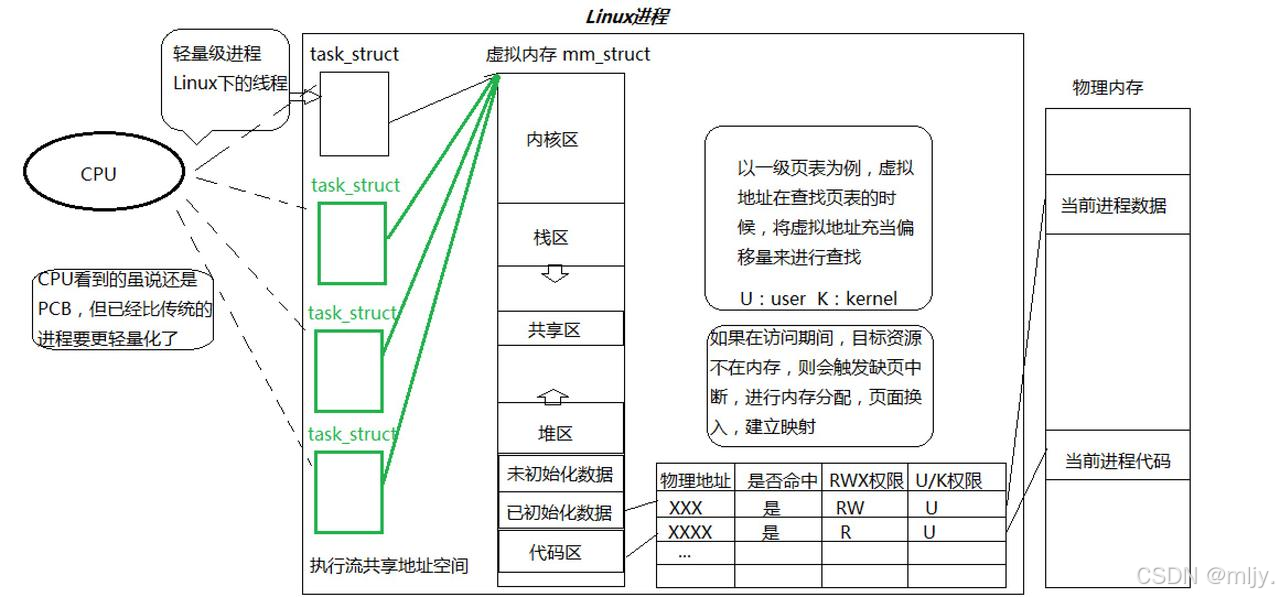
通過以上的理解我們就可以得出以下的結論:
1.在Linux當中實際上線程是由輕量級進程來模擬的。
2. 在進程當中線程對于資源的劃分本質上就是對地址空間范圍的劃分。而虛擬地址空間就是資源的代表。
3.在進程當中的虛擬地址空間對于線程來說是如何進行劃分的呢?實際上劃分的操是不需要用戶來執行的,我們知道不同的函數時有不同的入口地址,那么這時候不同的線程實際上就會指向不同虛擬地址空間。
通過以上的理解我們就可以發現實際上在操作系統學科當中和實際上的操作系統是有一定的區別的,在操作系統當中只是提供了基本的思想,而在具體的操作系統當中是按照操作系統給定的基本思想實現的,但不同的實現的思想可能不同。
實際上感性上的理解進程和線程可以將進程理解為一個家庭,而線程是家庭當中的一個成員,那么進行社會資源分配的時候的基本實體就是家庭,而家庭當中的成員又可以具體的劃分是在干什么。
因此在操作系統當中進程是進行資源分配的基本單位,而線程是系統當中進行調度的最小單位。
1.2 分頁式存儲
在之前的學習當中我們了解過在進程當中是通過頁表將虛擬地址空間二號物理內存完成兩個之間的映射關系的,有了頁表就可以將實際數據存儲的從物理內存當中的無序變成了虛擬地址空間上的有序。這樣在進程的視角當中就可以認為數據的存儲是連續的。
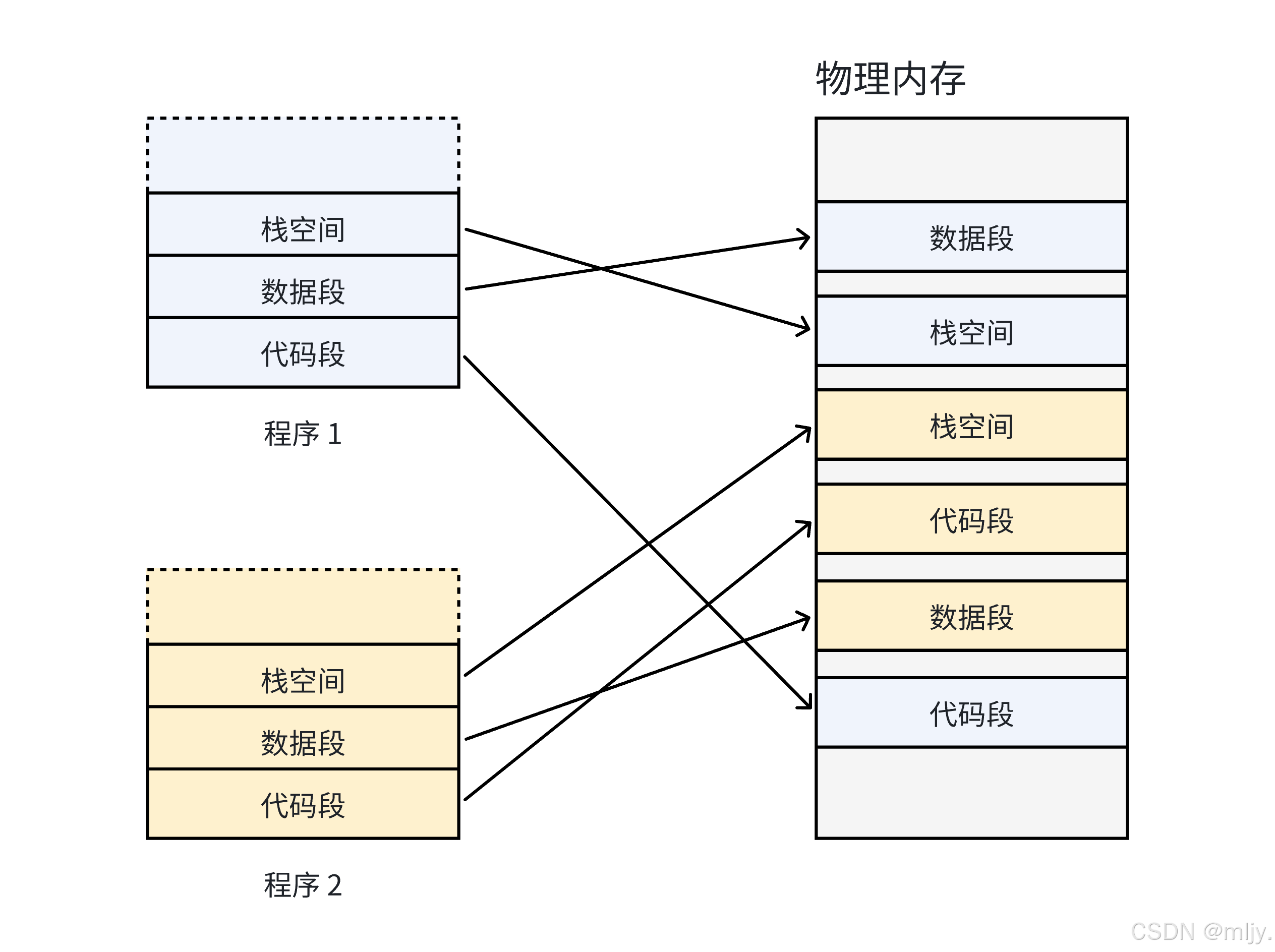
但是目前的問題是實際上虛擬地址和物理地址是如何進行映射的呢?
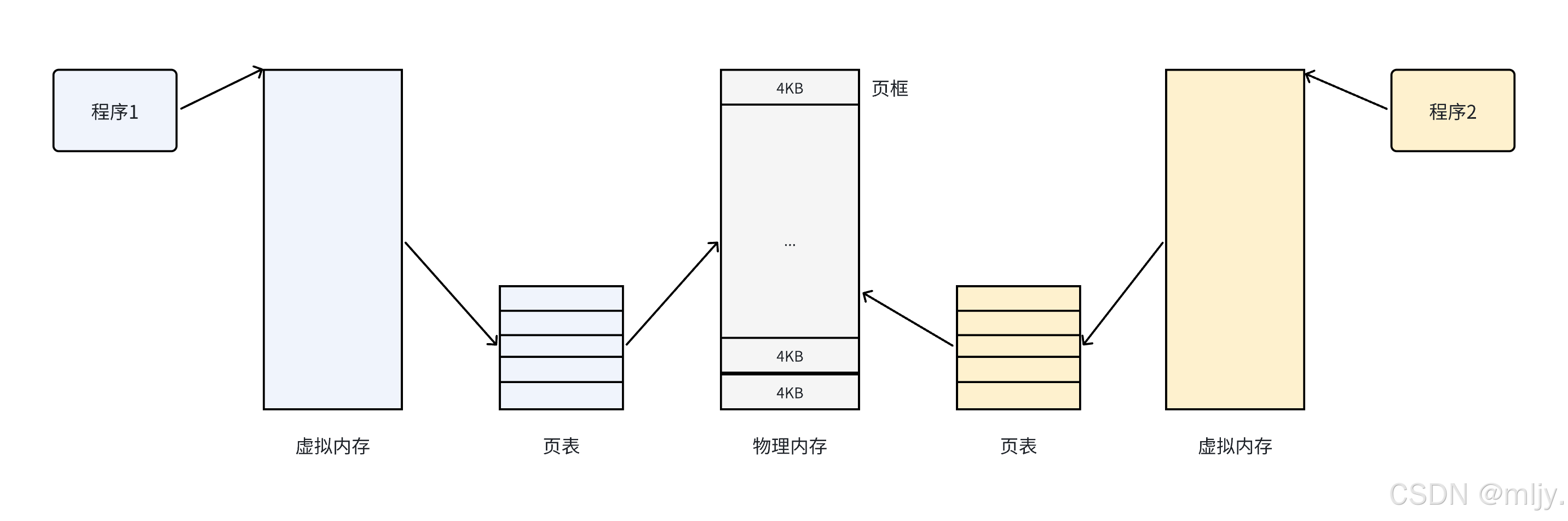
如果是按照之前的了解其實是虛擬地址空間當中的每天一個虛擬地址都和實際內存當中的一個物理地址進行映射,那么這時就會出現在下x86的系統當中,頁表當中每個物理地址和虛擬地址進行映射的一條頁表就會在內存當中占用8字節,假設虛擬地址空間的大小是4GB,這時將所有虛擬地址和物理地址進行映射頁表的最終大小就為32GB,那么這種情況下在操作系統載入之后就要占用內存當中的32GB,這時不就非常的不合理嗎?
因此實際上在操作系統當中是肯定無法使用一個單獨的頁表來進行虛擬地址和物理內存的映射。因此實際上的頁表是通過多級完成映射的。
大致的結構如下所示:
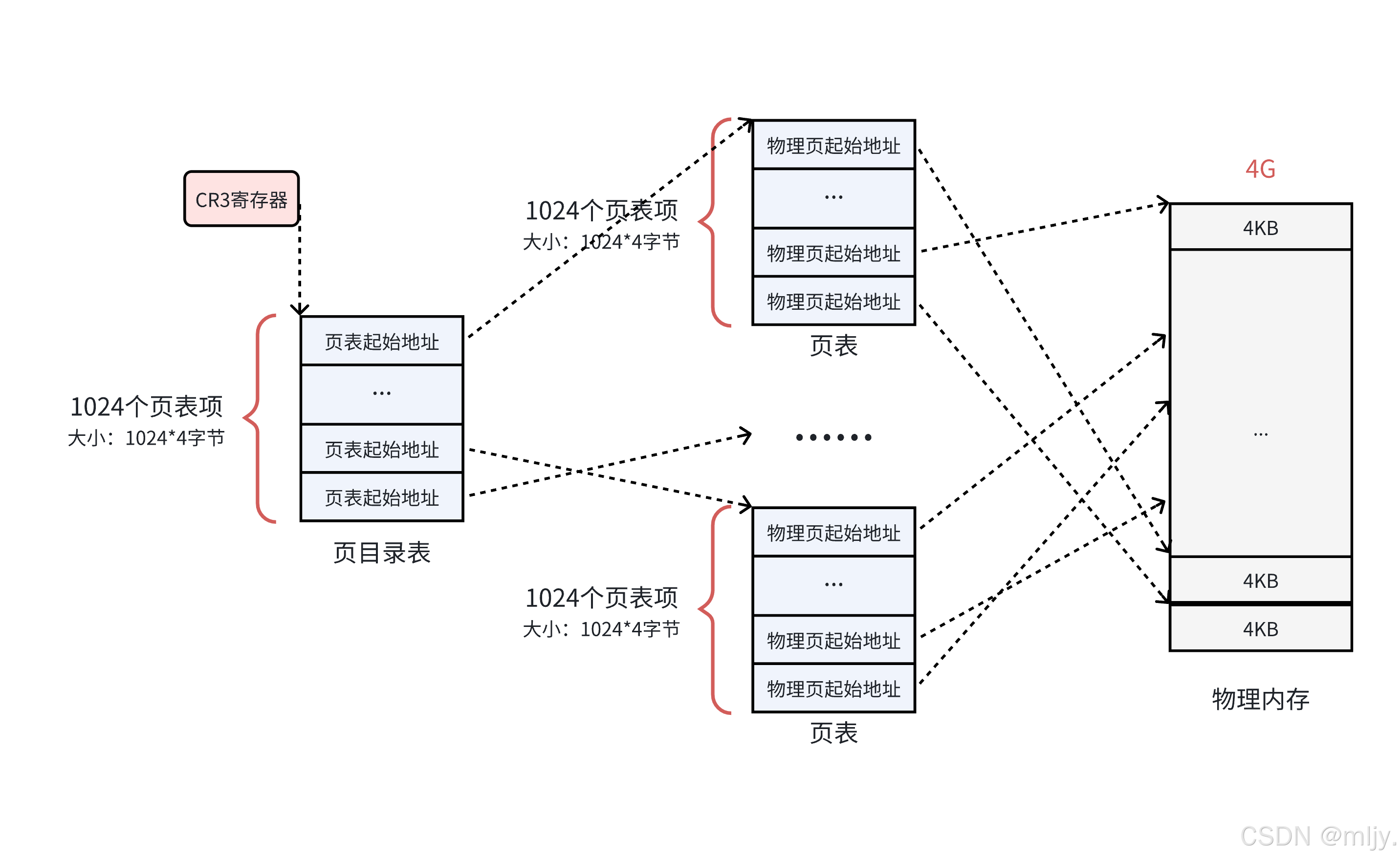
首先會有一個頁表當中存儲虛擬地址當中的前部分的地址內容,例如虛擬地址的長度為32,那么頁表當中存儲的就是虛擬地址前10位,那么這時就會有2^10=1024個表項,接下來再將虛擬地址當中的后10位的地址再作為頁表的當中的地址,那么在這種設計的情況下就可以使得每個頁表目錄當中的地址都能指向一個大小為1024的空間。
在之前文件的存儲學習當中我們就了解到了,在磁盤當中內存的加載都是按照4kb的大小為基本的單位的,實際上在內存當中進行內存的加載也是按照4kb的單位進行的,這就說明即使實際程序申請內存的大小為4097B,那么在內存當中實際申請的大小也是8kb。那么這就說明在內存當中進行數據管理也是按照4kb進行管理的,在此就將每個4kb的物理空間成為頁框。那么在操作系統當中就需要將這些頁框進行管理,,這樣操作系統就知道哪些頁框是使用的,哪些頁框是空閑的,內核當中實現了以下所示的結構體來表示每個物理頁。
/* include/linux/mm_types.h */
struct page
{/* 原?標志,有些情況下會異步更新 */unsigned long flags;union{struct{/* 換出?列表,例如由zone->lru_lock保護的active_list */struct list_head lru;/* 如果最低為為0,則指向inode* address_space,或為NULL* 如果?映射為匿名內存,最低為置位* ?且該指針指向anon_vma對象*/struct address_space *mapping;/* 在映射內的偏移量 */pgoff_t index;/** 由映射私有,不透明數據* 如果設置了PagePrivate,通常?于buffer_heads* 如果設置了PageSwapCache,則?于swp_entry_t* 如果設置了PG_buddy,則?于表?伙伴系統中的階*/unsigned long private;};struct{ /* slab, slob and slub */union{struct list_head slab_list; /* uses lru */struct{ /* Partial pages */struct page *next;
#ifdef CONFIG_64BITint pages; /* Nr of pages left */int pobjects; /* Approximate count */
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist; /* first free object */union{void *s_mem; /* slab: first object */unsigned long counters; /* SLUB */struct{ /* SLUB */unsigned inuse : 16; /* ?于SLUB分配器:對象的數? */unsigned objects : 15;unsigned frozen : 1;};}};...};union{/* 內存管理?系統中映射的?表項計數,?于表??是否已經映射,還?于限制逆向映射搜索*/atomic_t _mapcount;unsigned int page_type;unsigned int active; /* SLAB */int units; /* SLOB */};...
#if defined(WANT_PAGE_VIRTUAL)/* 內核虛擬地址(如果沒有映射則為NULL,即?端內存) */void *virtual;
#endif /* WANT_PAGE_VIRTUAL */...
}有了以上的struct page結構體之后就可以在內核當中創建struct page的數組,這樣就內核就可以通過對該數組的管理來完成對實際物理內存的管理。那么這級相比直接對物理內存進行管理的代價小的多了。
所以總的來說Linux 內核里的 struct page 是連接“物理內存頁幀”與“內核/用戶內存管理機制”之間的橋梁。
所以實際上在頁表當中每個元素當中存儲的也是物理內存當中每個頁框的地址,那么在要X86當中從虛擬地址定位到物理地址時候最后就只需要將后12位當作該頁框當作的偏移量,這樣要訪問對于的就只需要得到對于都要訪問地址的的頁框地址再加上+頁內偏移即可。
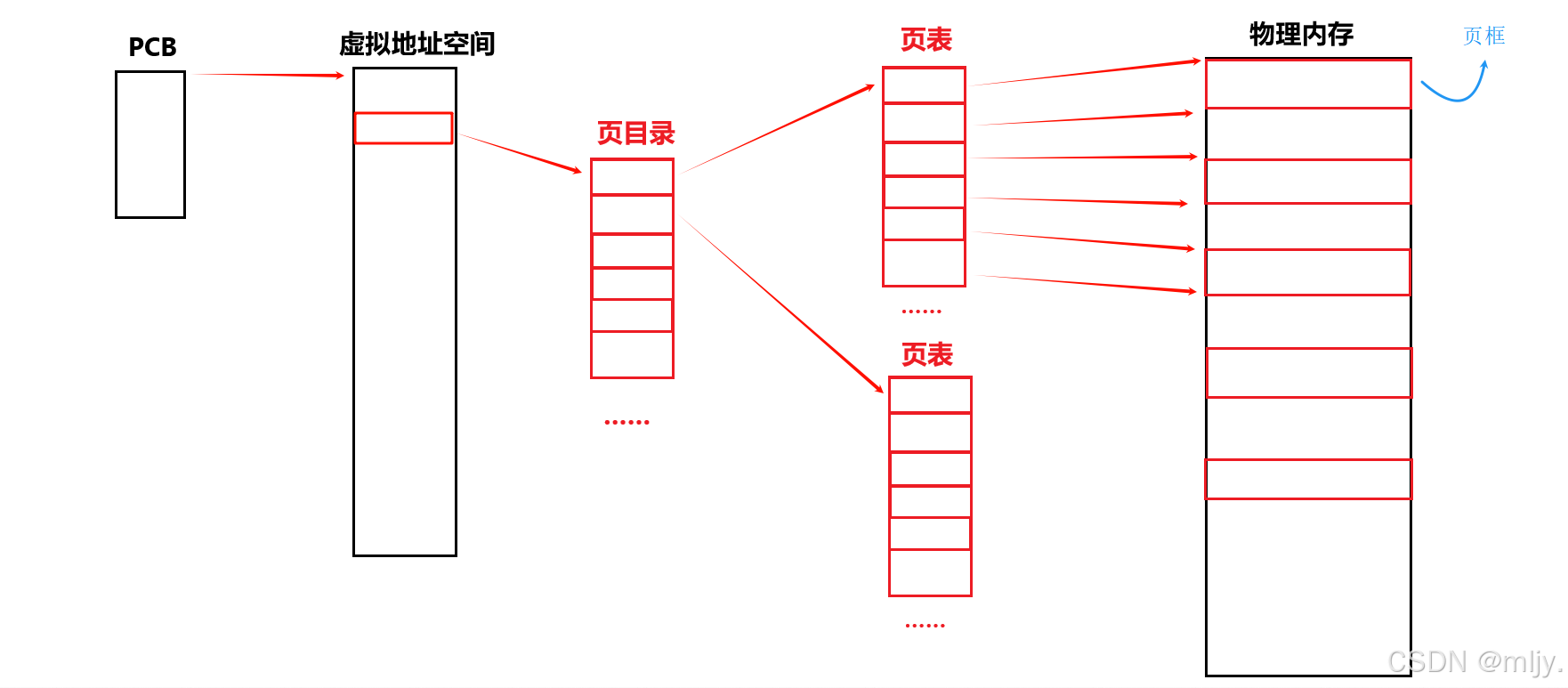
因此總結來說就可以將虛擬地址映射到物理地址上需要進行以下的兩步操作:
1.先找到對于的虛擬地址對應的頁框
2.在x86的條件下,之后再將虛擬地址當作的后12位置作為頁內偏移量,訪問具體的字節
實際上在之前了解的寫實拷貝和缺頁中斷等都需要從新建立虛擬地址空間和物理內存之間的映射關系。
1.3 線程周邊
以上我們了解到了實際上在操作系統當中頁表是通過多級的方式來建立虛擬地址和物理內存之間的映射關系的,這樣實現的方式是能減少頁表在內存當中的占用空間,但是事物都是有兩面性的,多級頁表映射的方式雖然確實能減少頁表在內存當中的占用但是也就存在相比直接進行映射的時候查找的效率較低的問題,所以在操作系統當中就TBL來減緩多級頁表在查詢是效率就低的問題,實現的邏輯如下所示:
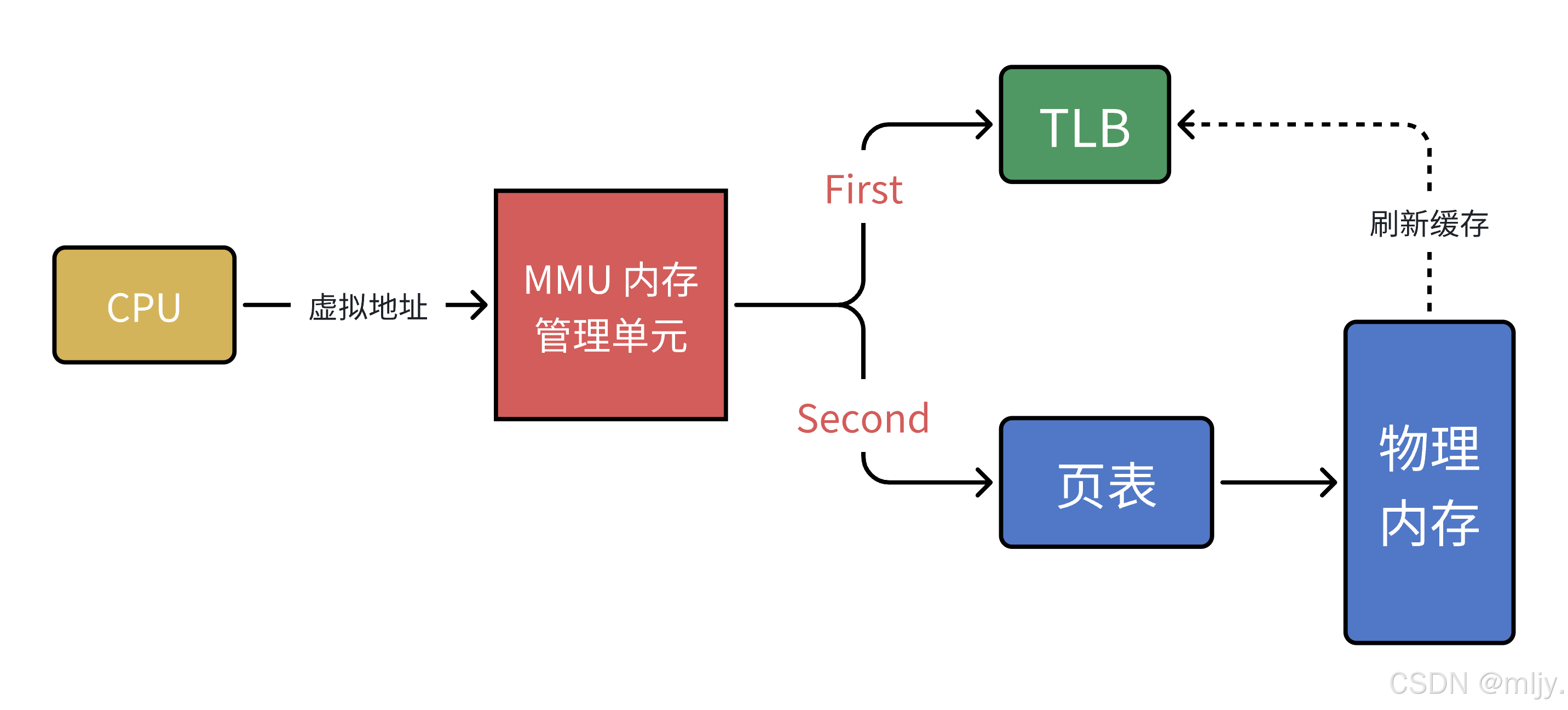
當中CUP得到對應的虛擬地址之后首先就會將該地址發給MMU,這時MMU就不會像之前一樣直接的在多級頁表當中進行查詢而是先從TLB當中查詢有沒有直接可以得到該虛擬地址映射的物理地址,這樣就能提高虛擬地址到物理地址之間轉換的效率。實際上TLB的本質就是一小塊的緩存,會將訪問頻率較高的虛擬地址和物理地址之間的映射保存下來。
一句話進行總結TLB的作用就是:緩存最近常用的虛擬頁到物理頁的映射,讓 CPU 在訪問內存時大多數情況下不必再通過多級頁表查找,從而大幅提升效率。
如果我們在TLB和頁表當中都無法找到對應的映射關系話,這時CPU就會給自己發送缺頁異常從而觸發缺頁中斷,那么這時CPU得到對應的中斷號接下來在操作系統當中的中斷向量表中得到中斷處理方法,而這個中斷處理方法的工作就是建立對應的虛擬地址和物理地址之間的頁表映射關系。
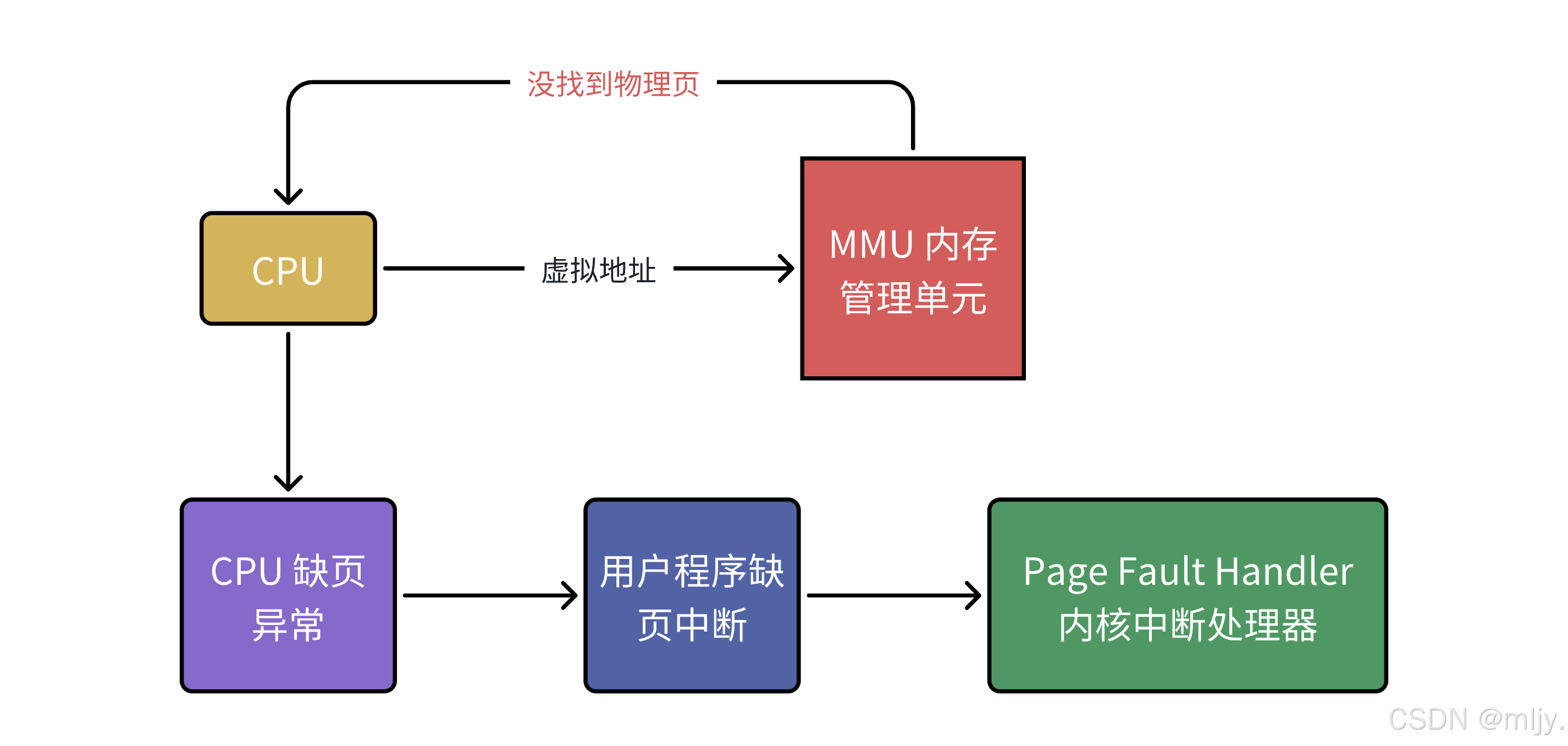
1.4?線程優點以及缺點
線程的優點如下所示:
1.創建和切換開銷小,創建線程比創建進程輕量
線程切換不需要更換虛擬內存空間 → 避免了 TLB 刷新 和大量緩存失效。資源消耗少
同一進程內的線程共享代碼段、數據段、文件等資源。相比進程更節省系統資源。
2.并行能力強
在多處理器系統上,線程可以并行運行,提高計算效率。
3.提升 I/O 性能
I/O 等待時,其他線程還能繼續執行,避免 CPU 空閑。
多線程可以并發等待多個 I/O,提高吞吐量。
線程的缺點如下所示:
1.性能損失
多線程需要額外的調度和同步開銷。
當線程數多于處理器數時,計算密集型線程之間會爭搶 CPU,效率可能反而下降。
2.健壯性降低
線程共享內存空間,彼此缺乏隔離。
小的時間差或錯誤的共享變量使用,容易導致難以發現的 bug(如競態條件、死鎖)。
3.缺乏訪問控制
進程是操作系統的最小保護單位,而線程不是。
一個線程的錯誤操作可能影響整個進程,導致全部線程出問題。
4.編程難度高
需要處理同步、互斥、死鎖等復雜問題。
調試和維護難度遠高于單線程程序。
通過以上我們就能發現線程的優點很大,但缺點也并不是“小問題”。它要求開發者必須非常謹慎地設計和實現,否則很容易出現嚴重問題。
1.5 線程 VS 進程
通過以上的學習再結合之前進程的學習我們就知道了進程是資源分配的基本單位,線程是調度的基本單位。那么除此之外線程相比進程還有哪些的區別呢?
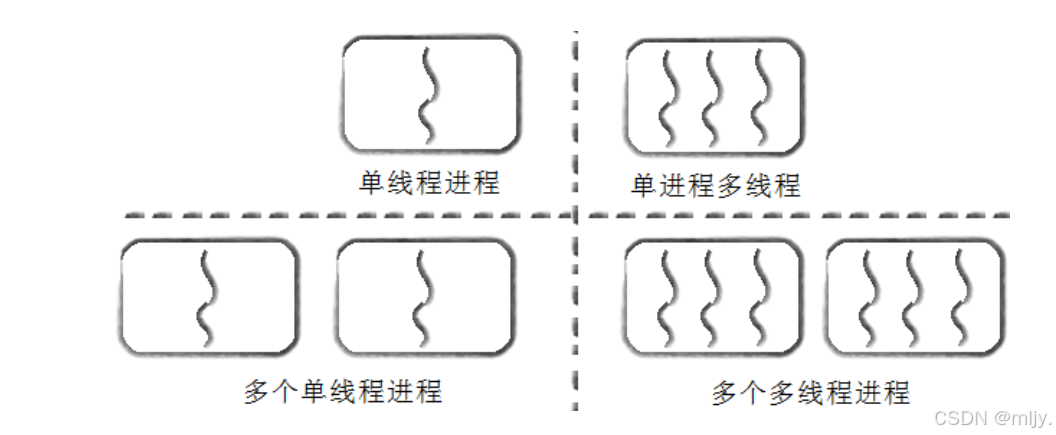
實際上同一個進程當中的所有線程是共用同一份的虛擬地址空間的,那么這時候就可以使得在同一個進程當中的線程在進行切換的時候依然能將原來的頁表和TLB和頁表繼續的保存下來,而在進程當中因為不同的進程都有自己獨立的一份虛擬地址空間,那么這時候就會造成進程切換的時候會將對應的TLB和頁表進行更新。
但線程除了有公共的部分還有獨立的部分,就例如線程有自己獨立的寄存器,用于保存線程的上下文數據;該背后就說明線程是被獨立調度的。除此之外線程還有獨立的棧,那么這就說明線程是一個動態的概念。
本質上通過以下的圖示就可以解答線程和進程之間的關系:
2.?初識Linux線程控制
2.1 POSIX線程庫
在此接下來我們要進行了解的線程庫是POSIX線程庫,本質上POSIX 線程庫(Portable Operating System Interface for uniX threads,簡稱 Pthreads)是遵循 POSIX 標準的一套 多線程編程接口。主要在類 Unix 系統(Linux、macOS、BSD 等)上使用,用 C 語言接口實現。
實際上除了以上的POSIX線程庫之外還存在其他的線程庫就例如語言當中提供的線程庫,例如在C++11當中提供對應的線程庫。這些庫底層一般還是調用操作系統的線程 API(Pthreads 或 Win32 threads),但對開發者更友好。
注:在此C++11當中線程庫的使用會等到在C++當中進行學習,不過建議將Linux當中的線程學習之后再去學習C++的線程API,那么這時理解起來會很簡單。
2.1 了解線程控制接口
以上我們已經了解到上面是POSIX庫,那么接下來就來了解該庫當中提供的線程創建相關的接口。
1.線程創建
功能:創建?個新的線程
原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);參數:
thread:返回線程ID
attr:設置線程的屬性,attr為NULL表?使?默認屬性
start_routine:是個函數地址,線程啟動后要執?的函數
arg:傳給線程啟動函數的參數返回值:成功返回0;失敗返回錯誤碼通過以上的描述就可以看出該函數是需要通過用戶傳入對應的線程ID以及線程對應對的屬性,還有線程運行起來之后需要執行的方法。該函數在創建線程成功的時候就會返回0,否則就會返回對應的錯誤碼。
接下來來看一下的代碼來看看使用以上的接口進行線程創建是什么樣的:
#include<iostream>
#include<pthread.h>
#include<unistd.h>void* routine(void* args)
{while(1){const char* s=static_cast<const char*>(args);std::cout<<"我是線程:"<<s<<" 正在運行"<<std::endl;sleep(1);}}int main()
{pthread_t t1;pthread_create(&t1,nullptr,routine,(void*)"pthread-1");while(1);return 0;
}以上代碼當中使用的對應的pthread_create來創建線程,在創建當中給該線程傳一個字符串的參數,那么在線程運行起來的時候就會執行routine方法,在該方法當中就可以通過函數的參數得到對應的字符串,只不過在獲得的過程當中需要將對應的指針進行強制類型轉換。
此時再實現以下的makefile文件之后接下來編譯以上的代碼:
Main:thread.ccg++ -o $@ $^ -lpthread
.PHONY:clean
clean:rm -f Main注:在此在使用g++的時候需要帶上-lpthread選項,那么程序在執行的時候才能找到對應的pthread庫。
以上程序運行的結果如下所示:

以上我們是讓main函數當中的主要進程只是運行而不輸出內容,如果該線程也向顯示器當中進行打印會出現什么樣的結果呢?
將代碼main函數修改為以下的形式:
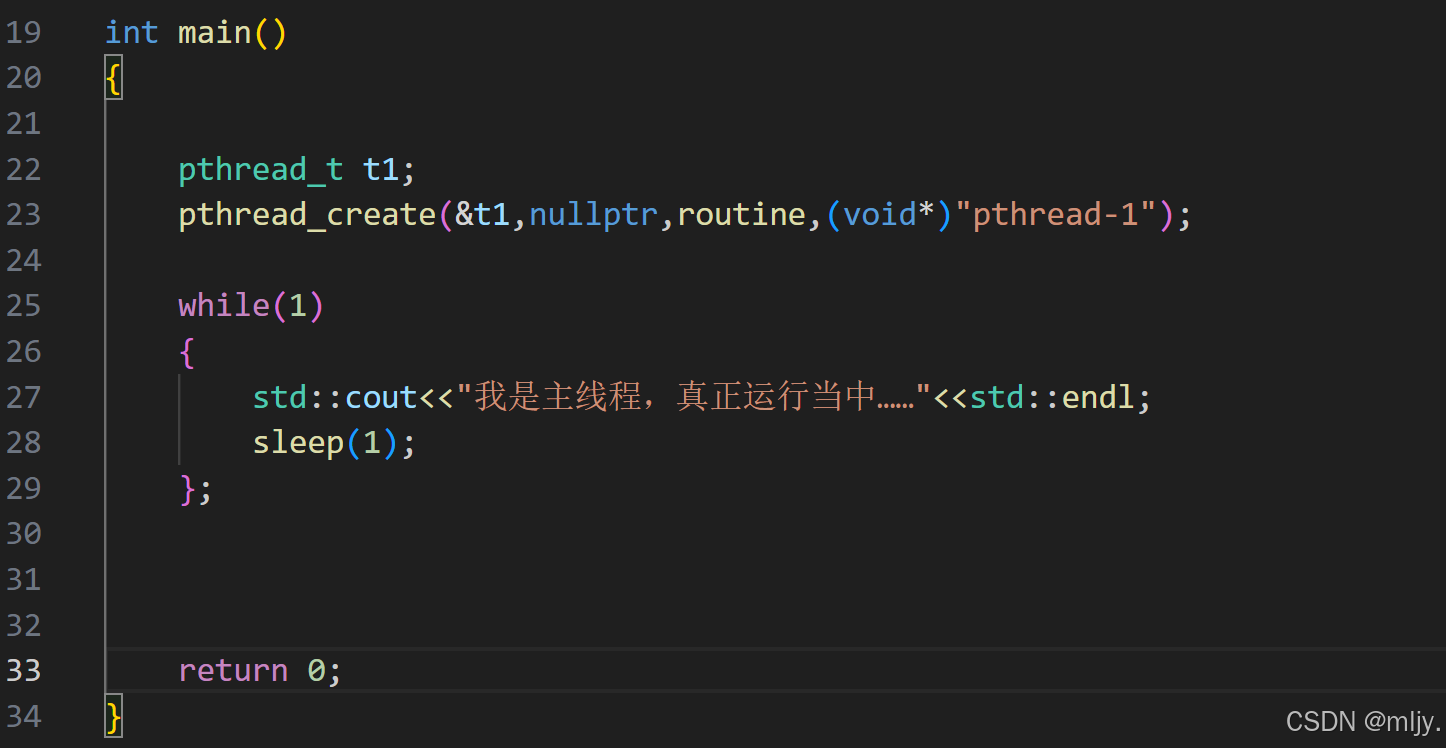
這時輸出結果就會變為以下的形式:
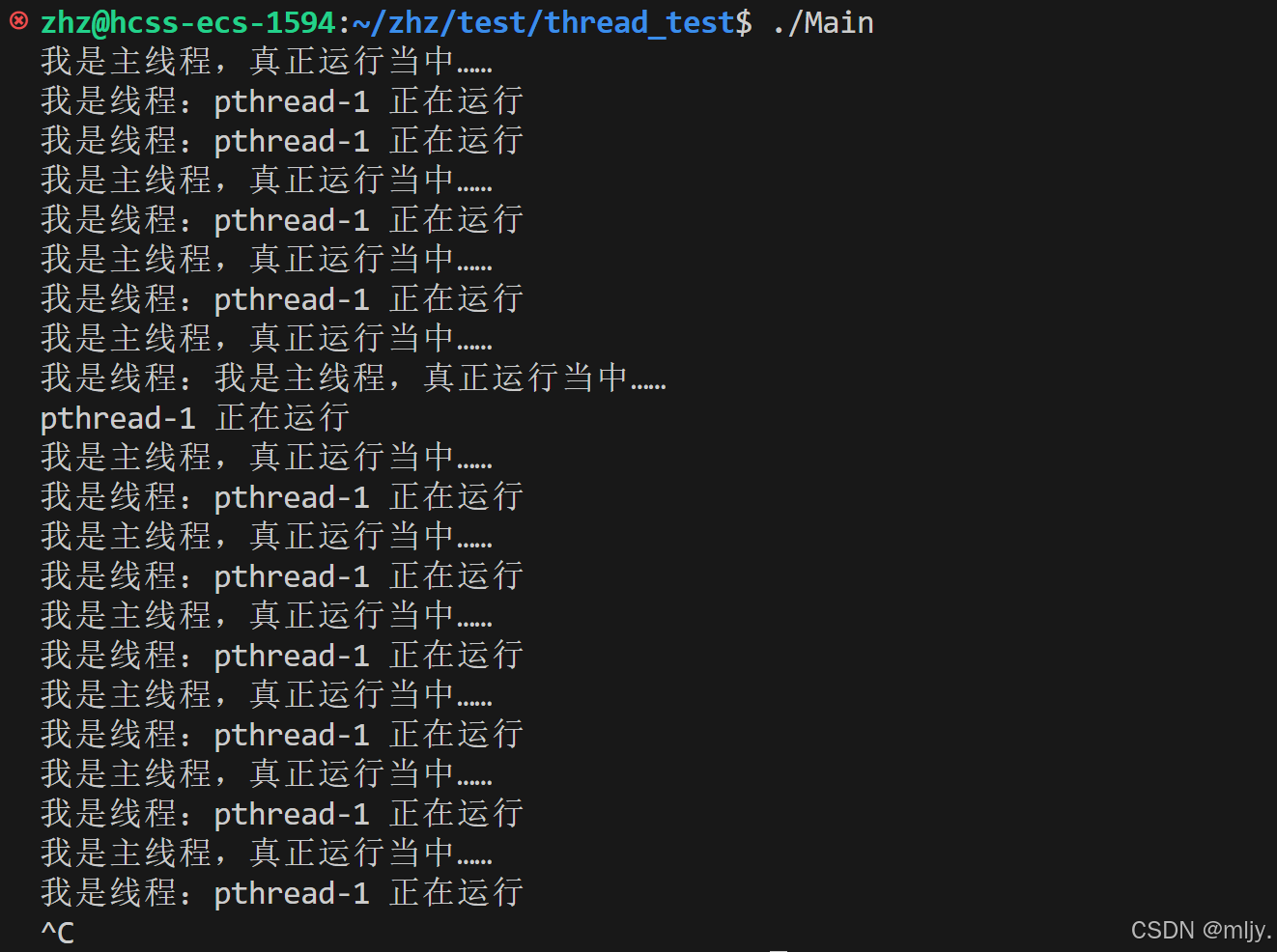
這時就會發現兩個線程輸出的內容混雜在了一起,這實際上是我們未進行線程同步的原因,要解決這個我問題就需要了解線程同步之后的概念。
在之前進程的學習當中我知道使用ps指令能查看當中操作系統當中的進程,那么使用什么樣的指令能查看操作系統當中的線程呢?
實際上還是使用ps指令,只不過當前帶的選項是-L,例如以的程序在運行的時候使用?ps -aL?指令就能看到以下的結果。
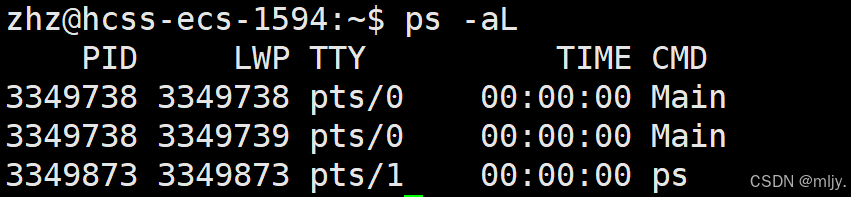
那么這時就可以看到兩個線程對應的PID是一樣的,但是這里又存在問題了,那就是以上當中的LWP又是什么呢?
實際上LWP就是light weight process 就是對應的輕量級進程,實際上我們也可以將其稱為線程id。
實際上和之前我們學習進程的調度類似,在線程當中也是會給不同的線程分配對應的時間片,那么這時候CPU就可以根據對應的時間片來進行線程的調度。
以上我們就了解到了pthread庫當中提供的線程創建接口pthread_create接口,那么這時候我們就要思考了為什么在此要實現一個pthread的庫,讓用戶直接調用對應的系統調用來進行線程的操作不就可以了嗎?
實際上在Linux操作系統當中確實提供了對應的線程調用接口,但是問題是在Linux當中線程操作的系統調用是和其他操作系統當中不同的,那么如果是使用系統調用來進行操作的話,那么我每在一個不同的操作系統當中就需要學習不同的系統調用,那么這對用戶來說壓力是很大的。因此為了解決該問題pthread在不同的操作系統當中就就將不同的系統調用進行封裝,實現給用戶統一的接口,那么這時就能讓用戶的進行線程的操作在不同的系統當中都是一樣的。
在Linux普通的使用用戶就不再需要LWP等輕量級進程的概念,也就不再需要了解到Linux當中是沒有真正的線程的。
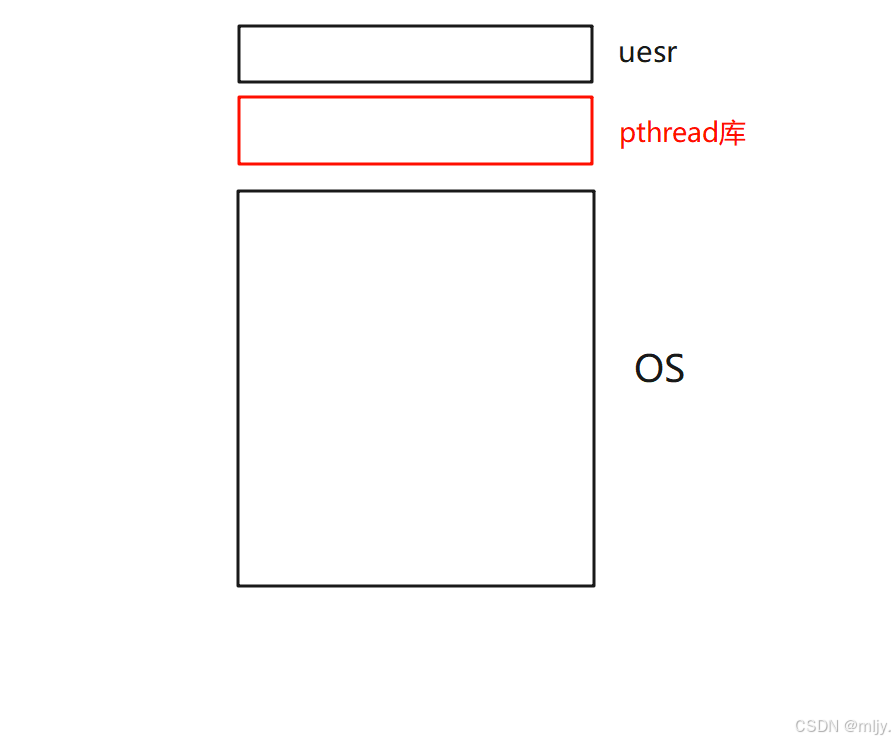
實際上pthread庫的實現是在用戶層當中的,所以將其稱為用戶級線程。
實際上在Linux當中是實現了對應的系統調用來實現來實現線程的創建的,系統調用的形式如下所示:
#include <sys/types.h>
#include <unistd.h>pid_t vfork(void);
vfork和之前我們學習的 fork的區別就是超級出來的子進程是和父進程公用同一個地址空間的,那么這時不就相當于創建了一個線程。
但是以上vfork本質還是封裝了以下的clone函數
#include <sched.h>int clone(int (*fn)(void *), void *stack, int flags, void *arg, .../* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
實際上除了以上的pthread庫之外在C++11當中也提供了對應的線程庫來實現線程創建的功能。
例如以下的示例:
#include <iostream>
#include <thread>
#include<unistd.h>void hello()
{while (1){std::cout << "我是子線程,正在運行" << std::endl;sleep(1);}
}int main()
{std::thread t(hello);while (1){std::cout << "我是主線程,正在運行" << std::endl;sleep(1);}return 0;
}那么接下來就需要思考為什么在語言當中也要實現對應的線程庫呢,其實這就要講到語言都是為了提高跨平臺的,提高語言的可移植性,那么如果一個用戶在Linux當中先進行開發之后接下來需要在Window當中進行開發,那么如果C++當中沒有提供對應的接口之后那么這時就無法進行跨平臺
。那么是如何實現的呢?實際上一般來說解決的方法就是將所有要兼容的平臺的代碼都編寫一份之后再進行條件編譯。
本質上實際上C++11當中提供的線程庫在Linux當中是封裝了pthread庫。
2. 線程等待
實際上和之前我們學習進程類似,在線程當中在進行線程的創建之后也是會申請出對應的空間的,只不過相比進程線程申請的資源比較少,但是如果不進行線程的等待還是會出現內存泄漏的問題的,在pthread庫當中提供了以下的接口。
#include <pthread.h>int pthread_join(pthread_t thread, void **retval);參數:
thread:要等待的線程 ID(pthread_create 返回的)。
retval:用于存放目標線程的返回值指針(如果線程用 pthread_exit 返回值,這里能拿到;如果不需要返回值,可以傳 NULL)。返回值:
成功返回 0
失敗返回錯誤碼(如 ESRCH:線程不存在,EINVAL:線程不可被 join 等)。
那么在了解了以上線程等待的接口之后接下來就可以使用以上的接口對上面實現的代碼進行線程的等待。
實現的代碼如下所示:
#include<iostream>
#include<pthread.h>
#include<unistd.h>void* routine(void* args)
{while(1){const char* s=static_cast<const char*>(args);std::cout<<"我是線程:"<<s<<" 正在運行"<<std::endl;sleep(1);}
}int main()
{pthread_t t1;pthread_create(&t1,nullptr,routine,(void*)"pthread-1");while(1){std::cout<<"我是主線程,真正運行當中……"<<std::endl;sleep(1);};pthread_join(t1,nullptr);return 0;
}以上就是本篇的全部內容了,接下來在線程概念《下》當中將繼續學習線程的概念,未完待續……

















)

