在日常工作中,多模態模型的 “幻覺” 問題已成為影響效率的關鍵痛點 —— 當我們需要模型基于文檔生成建議性內容(如行業報告分析、論文數據解讀等)時,模型常因無法準確理解文檔信息,輸出包含 “虛構內容” 的結果,尤其是文檔中存在復雜表格、數據公式時,問題更為突出。
這種 “幻覺” 的根源,在于多模態模型對文檔的識別與理解存在局限性:面對含復雜表格(如合并單元格、跨頁表、框線殘缺表)、手寫批注、印章覆蓋,或融合文本、圖表、公式等多元素的文檔時,模型難以精準提取圖像中的關鍵信息,無法完成基礎的 “信息讀懂” 環節,最終只能通過 “腦補” 生成內容,導致輸出與文檔實際信息脫節。
而 “幻覺” 帶來的連鎖反應,直接打破了工作效率提升的預期:用戶需額外增加校對環節,逐一核對模型輸出與文檔原文的一致性,不僅消耗大量時間成本,還可能因人工校對疏漏,導致錯誤信息流入后續工作(如數據核對、合規審核),引發更高的風險。
TextIn 文檔解析工具 —— 從 “源頭”解決模型 “幻覺”
要修正多模態模型對表格 “虛構描述” 的問題,核心在于解決模型 “讀不懂文檔” 的源頭矛盾 —— 通過專業的文檔解析工具,提前將文檔中的復雜信息轉化為模型可理解的結構化數據,為模型提供精準、完整的輸入。
TextIn 文檔解析工具正是針對這一需求設計,其核心功能是將文檔按邏輯與元素分離識別,精準提取文本、表格、圖表、公式等各類信息,讓多模態模型能 “清晰讀懂” 文檔中的每一個細節,從根本上減少 “腦補式幻覺” 的產生。
操作步驟
- 文檔上傳與初始識別:將含復雜表格、多元素的目標文檔(如行業報告、論文、合規文件等)上傳至 TextIn 平臺,工具會自動啟動多模態元素掃描,快速定位文檔中的表格、文本、手寫體、印章、圖表、公式等核心元素,完成初步元素分類。
- 針對性元素解析與數據抽取:針對不同元素啟動專項解析能力 —— 對復雜表格,工具會精準切割單元格邊界、還原表格結構,將數據抽取為 Markdown、JSON 等結構化格式;對手寫體或印章覆蓋的文字,自動分離背景干擾,清晰識別覆蓋內容;對多元素組合文檔,額外分析元素間的上下文關聯(如圖表標題與圖表、表格數據與正文論點的對應關系)。
- 結構化數據輸出與模型對接:解析完成后,工具輸出語義清晰、格式規范的結構化數據,用戶可直接將該數據作為輸入,傳遞給多模態模型。此時模型基于精準的結構化信息生成內容,無需再 “腦補” 表格數據,從源頭避免 “虛構描述” 的出現。
優勢亮點
- 復雜表格精準解析,杜絕數據 “失真”:針對行業報告、論文中常見的特殊表格(合并單元格、跨頁表、框線殘缺表),工具通過先進深度學習模型,實現表格結構的完整還原與數據的高保真抽取,輸出的結構化數據(如 Markdown、JSON)可直接用于模型輸入,避免傳統人工錄入效率低、簡單 OCR 識別錯誤率高的問題,為模型提供 “無偏差” 的表格數據基礎。
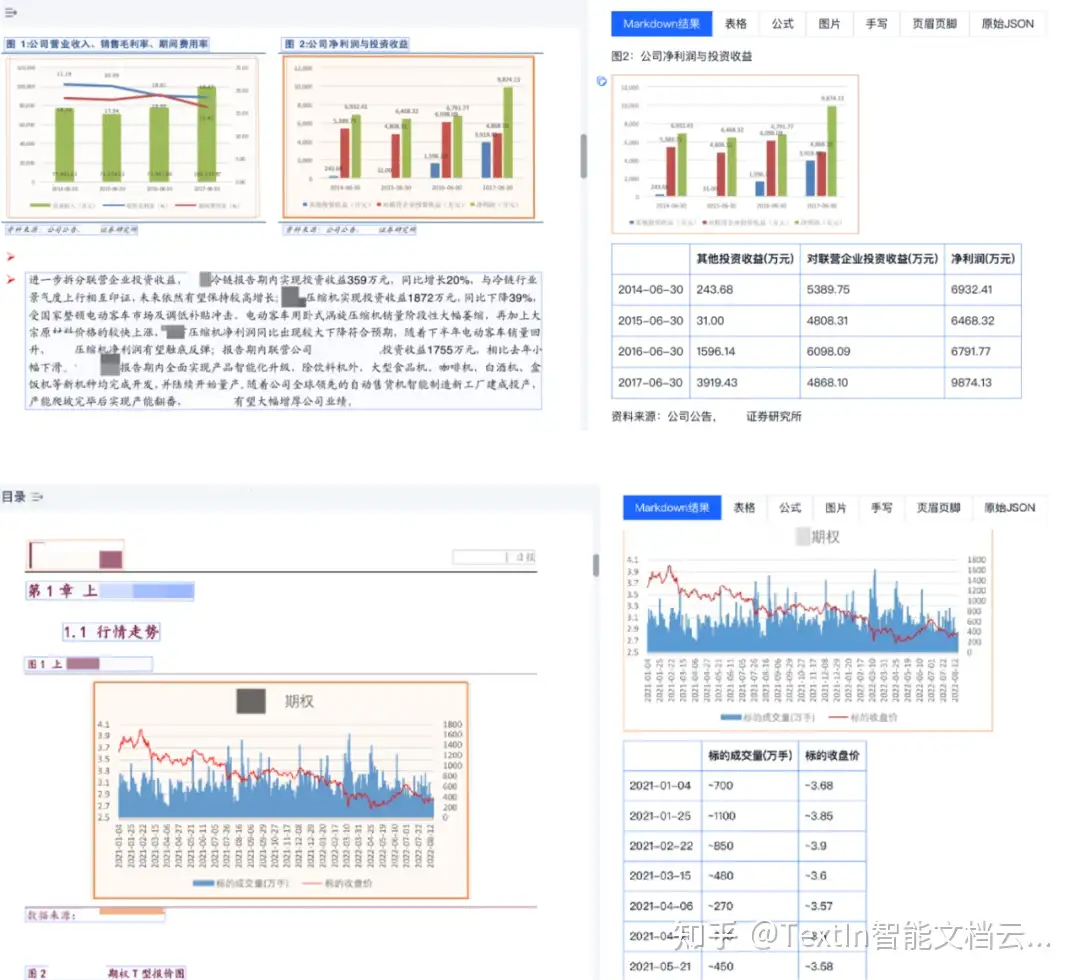
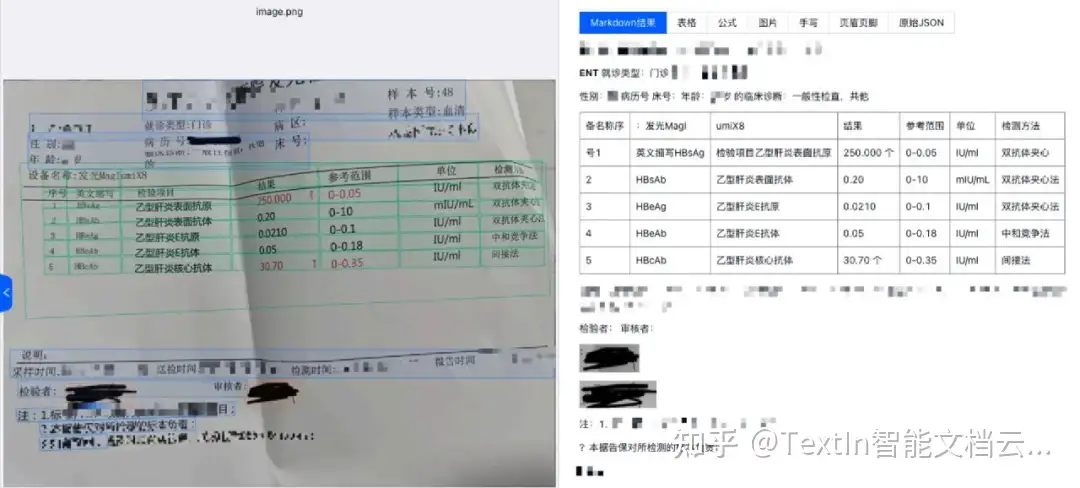
- 抗干擾識別,保障關鍵信息完整:面對日常文檔中常見的手寫簽名、批注、印章覆蓋等干擾,工具通過強大的圖像處理與文字識別能力,可有效分離背景印章、清晰辨識覆蓋文字,即使是潦草連筆的手寫體也能保持高識別準確率。這確保了簽字頁、手寫備注等關鍵信息不遺漏、不誤讀,滿足監管對文件 “清晰、準確” 的要求,也避免模型因關鍵信息缺失產生 “幻覺”。
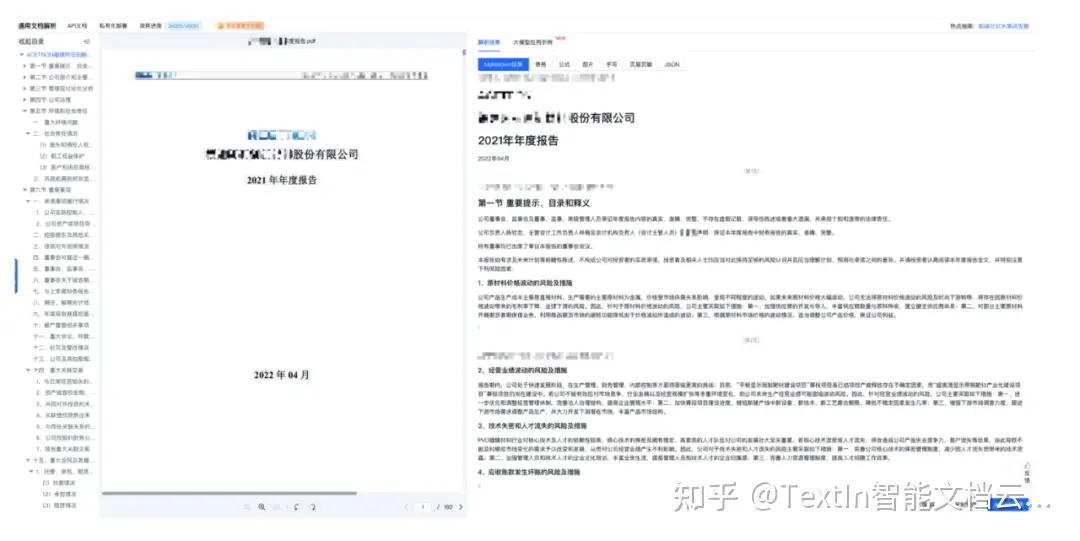
- 多元素語義關聯,實現深度結構化:不同于僅能識別單個元素的工具,TextIn 可理解文檔中文本、表格、圖表、公式等元素間的上下文關系(如識別圖表標題與對應圖表、理解表格數據支撐的正文論點)。這種深度結構化解析能力,為模型后續的智能審核(如數據一致性校驗、關鍵條款比對)提供語義清晰的輸入,讓模型能 “理解” 而非 “猜測” 元素間的邏輯,進一步減少 “虛構內容”的生成。
立即體驗 Textin文檔解析![]() https://cc.co/16YSWm
https://cc.co/16YSWm














)


)

