MySQL深度分頁優化思路
常見的3種優化思路如下:
1. 子查詢優化方式
示例改寫前:
SELECT * FROM words
WHERE name = 'oee'
ORDER BY id
LIMIT 99999990, 10;
這個寫法會導致 MySQL 掃描并丟棄前面 99999990 行,效率極低。
示例改寫后:
SELECT * FROM words
WHERE name = 'one'AND id >= (SELECT id FROM wordsWHERE name = 'one'ORDER BY idLIMIT 99999990, 1)
ORDER BY id
LIMIT 10;
優點:
- 子查詢只查索引字段
id,訪問數據量小; - 主查詢直接從命中的
id開始,避免大范圍跳過; - 支持使用覆蓋索引提升速度。
2. 記錄 ID 方式(基于位置的分頁)
每頁返回當前頁最大 ID,前端保存下來作為下一頁的起點。
示例:
上一頁最后一條記錄的 id = 100001,則下一頁查詢為:
SELECT * FROM words
WHERE id > 100001
ORDER BY id
LIMIT 10;
優點:
- 無需 OFFSET,不跳過數據,效率高;
- 避免回表和大量掃描,非常適合“滾動加載”或“下一頁”模式。
3. 使用 Elasticsearch 替代分頁
對于超大數據量,可以將數據同步到 Elasticsearch,利用其內建的分頁機制如:
search_after(推薦)scroll(適合大批量導出)
優點:
- ES 的倒排索引和分頁機制在大數據下表現更好;
- 查詢速度快,靈活支持多字段排序和全文搜索。
主從同步機制和實現策略
MySQL中的主從同步機制是一種數據復制技術,將主庫(Master)的數據同步到一個或多個從庫(Slave),主要通過二進制日志(bin log)實現數據的復制,然后推送給從數據庫,從庫重放對應日志完成復制。
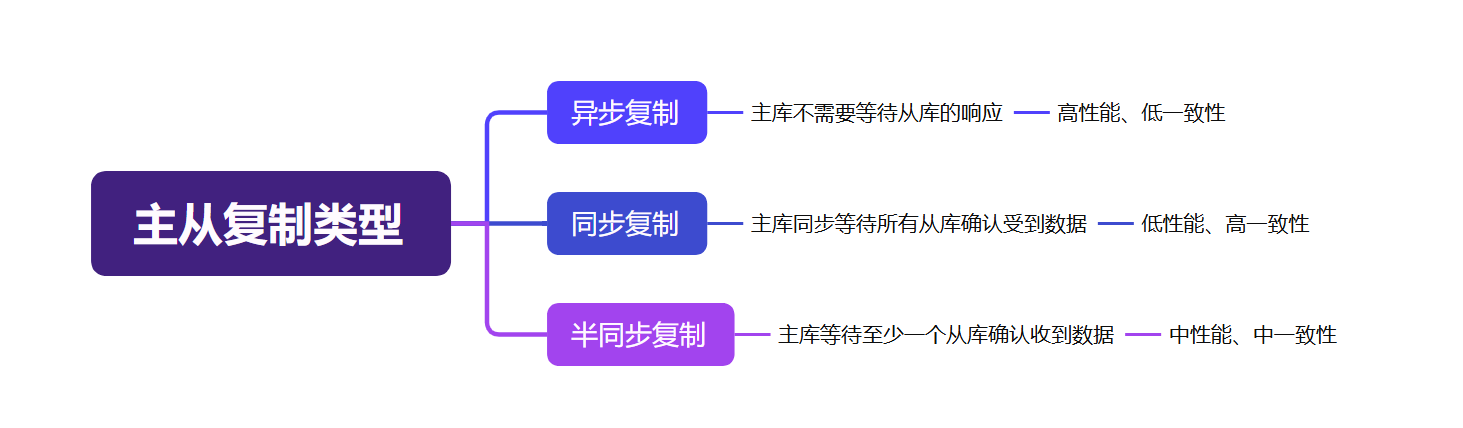
優化主從同步延遲
延遲是必然存在的,只能優化無法避免。
常見的4種解決方式:
1. 二次查詢
如果從庫查詢不到結果,可以降級回主庫查詢一次。
查詢從庫 → 沒查到 → 查詢主庫 → 返回結果
優點:
- 實現簡單,屬于兜底策略;
- 適用于部分對一致性有要求的接口,比如用戶剛注冊、寫入后馬上查詢的場景。
缺點:
- 如果用得太頻繁,反而將讀壓力轉移回主庫;
- 對主庫造成沖擊,違背了讀寫分離的初衷;
- 如果某些查詢確定從庫必定查不到,可能加劇問題。
2. 強制寫后讀走主庫
對于“寫入后立即讀取”的操作,強制綁定這些查詢走主庫,確保數據最新。
在代碼層約定:某些操作的讀取必須從主庫讀。
優點:
- 保證強一致性;
- 避免延遲導致的數據查不到問題。
缺點:
- 寫死邏輯,靈活性差;
- 開發維護成本高,不推薦大范圍使用;
- 無法利用從庫分擔查詢壓力。
3. 關鍵業務讀寫都走主庫
對于一些關鍵業務(如登錄、注冊、下單)直接從主庫讀寫,不依賴從庫。
舉例:
用戶注冊后馬上登錄,如果讀取從庫可能查不到注冊信息;此時登錄接口直接走主庫即可避免問題。
優點:
- 避免數據同步延遲引起的“查不到”;
- 適用于低頻關鍵路徑操作;
- 實現相對簡單,業務上可控。
缺點:
- 主庫讀壓力可能上升(但頻率不高問題不大);
- 邏輯需要與業務強綁定。
4. 使用緩存(如 Redis)中轉數據
主庫寫入后,將數據同步到緩存中(如 Redis)。讀取請求優先從緩存中查詢。
優點:
- 規避主從延遲問題,緩存讀取更快;
- 減輕主庫和從庫壓力;
- 適用于頻繁訪問的熱點數據。
缺點:
- 引入緩存一致性問題;
- 緩存更新/失效策略需要配合設計;
- 系統復雜度提升。
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 二次查詢 | 簡單兜底 | 主庫壓力增加 | 不一致時容錯 |
| 強制寫后讀主庫 | 保證一致性 | 寫死邏輯、維護復雜 | 寫后即查操作 |
| 關鍵讀寫走主庫 | 可控、可靠 | 主庫壓力略大 | 注冊/登錄類接口 |
| 使用緩存 | 高性能、抗延遲 | 引入一致性問題 | 熱點數據讀多寫少 |






)


)






)


