近年來,大語言模型(LLMs)和強化學習(RL)的融合正在徹底改變我們構建和部署AI系統的方式。早期的LLM強化學習(LLM-RL)主要關注如何通過人類反饋(如RLHF)讓模型生成更符合人類偏好的單輪響應。雖然這類方法在指令遵循和價值觀對齊方面取得了成功,但它們卻忽略了一個更本質的問題:真正的智能往往體現在序列決策中——面對復雜、動態、部分可見的環境,能夠持續規劃、使用工具、記憶歷史、自我反思并執行多步行動。

論文:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
鏈接:https://arxiv.org/pdf/2509.02547
這篇綜述正是對這一新興范式——Agentic Reinforcement Learning(Agentic RL,智能體強化學習)——的系統性總結與展望。Agentic RL不再將LLM視為一個被動的文本生成器,而是將其塑造為一個具有自主決策能力的智能體,能夠在與環境的多輪交互中學習并成長。
論文的核心貢獻包括:
正式定義了Agentic RL,并通過MDP/POMDP框架將其與傳統LLM-RL區分開;
提出了一個雙重分類法,分別從“核心能力”和“任務領域”兩個維度梳理了現有工作;
全面總結了支撐Agentic RL研究的開源環境、基準測試和訓練框架;
指出了當前面臨的核心挑戰和未來的關鍵研究方向。
接下來,我們將深入這篇綜述的每一個核心部分。
從LLM RL到Agentic RL:范式轉變的正式化
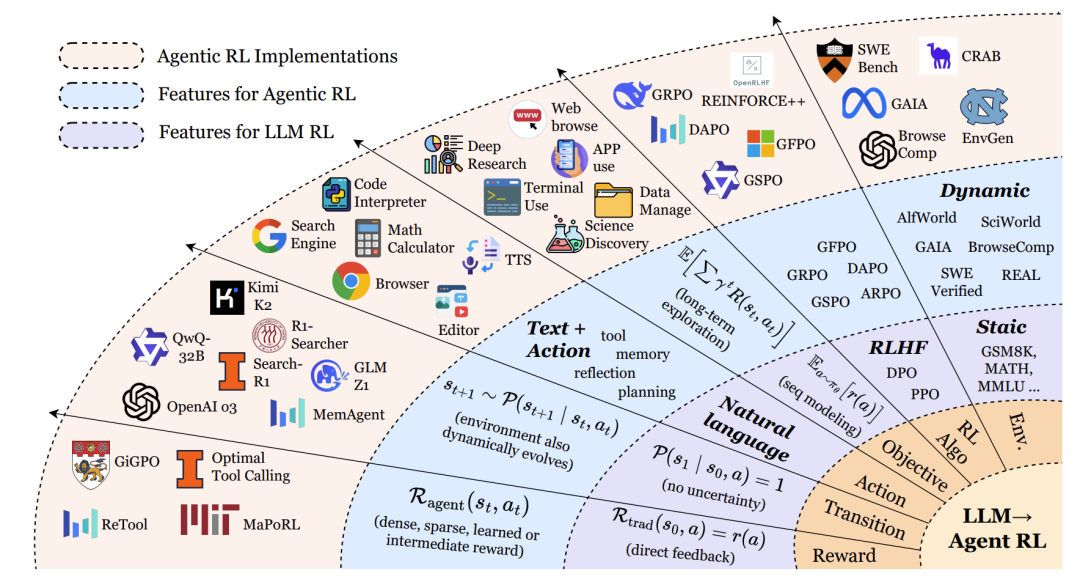
傳統偏好基于強化微調(PBRFT)的局限
傳統的LLM強化學習,如基于人類反饋的強化學習(RLHF),通常被形式化為一個退化的馬爾可夫決策過程(MDP)。它的狀態空間只包含一個初始提示(prompt),智能體執行一個動作(生成一段文本)后回合立即結束。獎勵通常由一個獎勵模型提供,基于最終輸出的質量給出一個標量分數。這種方法優化的是單輪交互中的文本質量,但缺乏對多步規劃、工具使用和環境反饋的支持。
Agentic RL的定義與核心思想
Agentic RL則將LLM視為一個嵌入在部分可觀察馬爾可夫決策過程(POMDP)?中的策略。智能體在一個動態環境中運作,其狀態隨時間演變,智能體只能接收到部分觀察。它的動作空間不僅包括生成文本(A_text),還包括執行結構化動作(A_action),例如調用搜索引擎、執行代碼、點擊圖形界面按鈕等。獎勵函數也變得更為復雜,結合了稀疏的最終任務獎勵和密集的中間步驟獎勵。
簡而言之,Agentic RL的核心理念是:通過強化學習,將LLM從一個“靜態的文本生成器”轉變為“能夠進行多步決策、與環境交互、并從結果中學習的自主智能體”。
形式化對比:MDP/POMDP框架
論文通過形式化的MDP元組清晰地對比了兩種范式:
傳統PBRFT MDP:?S_trad, A_trad, P_trad, R_trad, T=1?
S_trad = {prompt}:狀態空間只有一個提示詞。T=1:回合 horizon 為1,生成響應后立即結束。R_trad(s0, a) = r(a):獎勵只依賴于最終生成的行動(文本)。
Agentic RL POMDP:?S_agent, A_agent, P_agent, R_agent, γ, O?
S_agent:豐富的世界狀態,隨時間變化。A_agent = A_text ∪ A_action:動作空間包含文本和外部動作。P_agent:狀態轉移具有不確定性,取決于行動和環境。R_agent(st, at):獎勵函數可提供步驟級獎勵(如子目標完成)和最終獎勵。γ:折扣因子,強調長期回報。O:觀察函數,智能體無法看到完整狀態,只能獲得部分觀察。

Agentic RL的核心能力視角
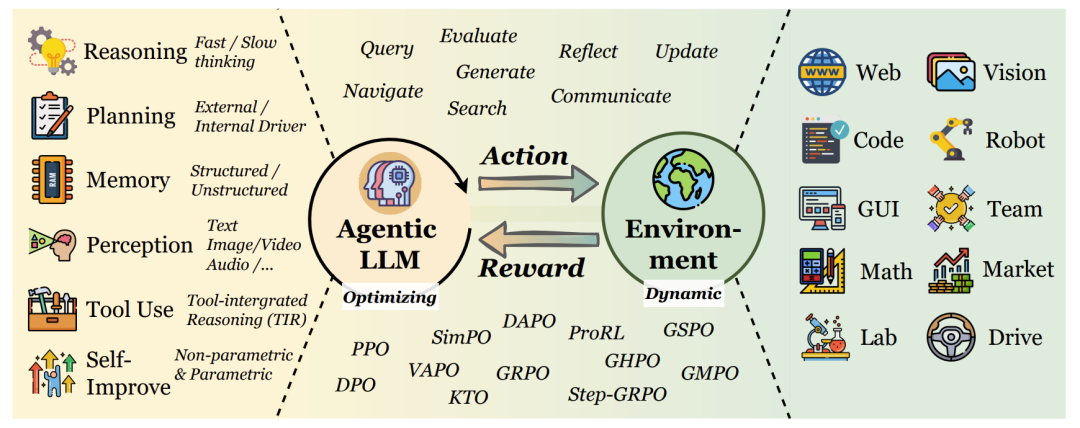
論文的第三章是核心,它詳細闡述了RL如何賦能LLM智能體的各項關鍵能力。
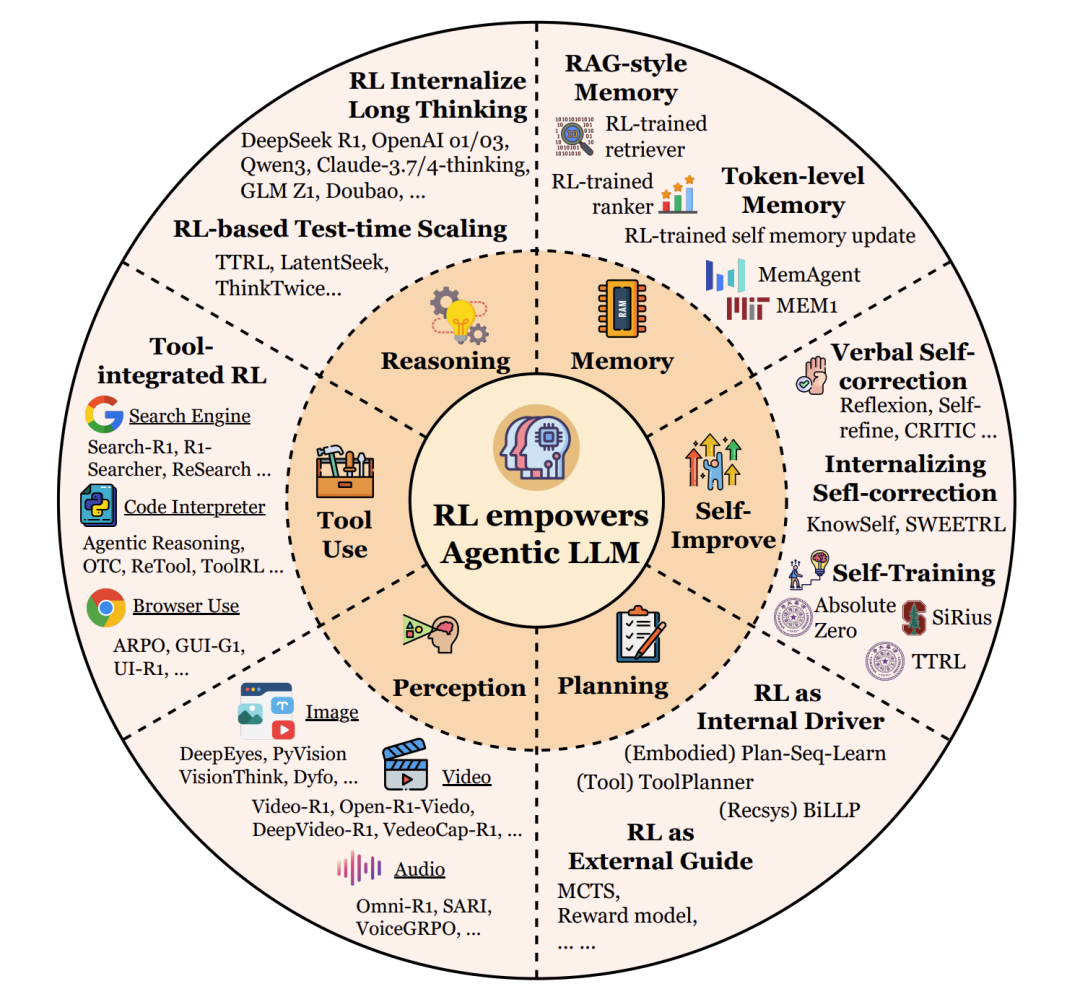
規劃(Planning)
規劃是智能體為達成目標而深思熟慮一系列行動的能力。
RL作為外部引導(External Guide):早期方法用RL訓練一個輔助的獎勵或價值函數,來引導傳統的搜索算法(如蒙特卡洛樹搜索,MCTS)。LLM負責提出候選行動,而RL模型負責評估這些行動序列的質量。代表工作有RAP、LATS。
RL作為內部驅動(Internal Driver):更先進的方法將RL用于直接優化LLM本身的規劃策略。通過環境交互的試錯反饋,LLM內部的政策被精細調整,使其能直接生成更好的計劃。代表工作有VOYAGER、AdaPlan。
前瞻(Prospective):未來的方向是融合兩種范式,讓LLM內化搜索過程本身,形成一個元策略,自主決定何時深入思考、何時探索新路徑。
工具使用(Tool Using)
工具使用能力讓智能體能夠調用外部資源(API、計算器、搜索引擎等)來解決問題。
ReAct風格工具調用:通過提示工程或少樣本學習,教LLM按照“思考-行動-觀察”(Thought-Action-Observation)的循環與工具交互。或者通過監督微調(SFT)在專家軌跡上訓練。但這類方法本質是模仿,缺乏戰略靈活性。
工具集成RL(Tool-integrated RL):RL將學習目標從“模仿”轉變為“優化最終任務表現”。這使得智能體能夠學習何時、如何、以何種組合來調用工具,并能適應新場景和從錯誤中恢復。代表工作有ToolRL、OTC-PO、ReTool等。RL訓練甚至能讓一個沒有工具使用經驗的基座模型涌現出自我修正、調整調用頻率等能力。
前瞻:當前挑戰在于長視野任務中的信用分配。當一個任務需要多輪工具調用時,很難確定哪一次調用對最終成功起到了關鍵作用。未來的工作需要更精細的步驟級獎勵設計。
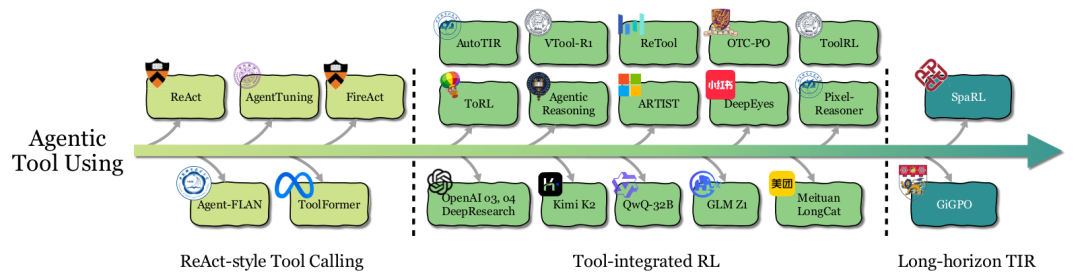
記憶(Memory)
記憶使智能體能夠存儲、檢索和利用歷史信息。
RAG風格記憶:早期系統將記憶視為外部數據庫(如向量庫),RL僅用于學習何時進行檢索查詢。記憶的存儲和整合規則是預定義的、靜態的。
令牌級記憶:智能體擁有可訓練的記憶控制器,管理一個顯式(自然語言)或隱式(潛在嵌入)的“記憶令牌”池。RL策略決定在每一步保留或覆蓋哪些信息,從而實現長期上下文的理解和持續適應。代表工作有MemAgent、MEM1、MemoryLLM。
結構化記憶:更先進的記憶采用圖結構(如知識圖譜)來組織信息,捕捉更豐富的關聯、時序或層次依賴。但目前其管理仍多依賴啟發式規則,如何用RL動態優化這類結構化記憶的構建和演化是一個開放方向。

自我改進(Self-Improvement)
自我改進指智能體通過反思從錯誤中學習,持續提升自身表現。
語言自我修正(Verbal Self-correction):在推理時,通過提示讓LLM生成答案、進行自我批判、然后輸出修正后的答案。整個過程無需梯度更新,類似于“在腦海中檢查”。代表工作有Reflexion、Self-Refine。
內化自我修正(Internalizing Self-correction):使用RL和梯度更新,將自我反思的反饋循環內化到模型參數中,從根本上提升模型發現和糾正自身錯誤的能力。代表工作有KnowSelf、Reflection-DPO。
迭代自訓練(Iterative Self-training):最高級的形式,智能體將反思、推理和任務生成結合成一個自我維持的循環,無需人類標注數據。方法包括:自我博弈與搜索引導精化(如R-Zero)、執行引導的課程生成(如Absolute Zero)、集體引導(如Sirius)。
推理(Reasoning)
論文借鑒雙過程理論,將推理分為:
快思考(System 1):快速、直觀、啟發式的推理。大多數傳統LLM屬于此類,效率高但易產生幻覺和事實錯誤。
慢思考(System 2):緩慢、 deliberate、結構化的多步推理。它產生中間推理痕跡(如思維鏈,CoT),邏輯更一致,在數學、科學推理等任務上更準確可靠,但延遲更高。代表模型有OpenAI o1/o3、DeepSeek-R1。
RL在激勵和優化慢思考方面扮演了關鍵角色。然而,挑戰在于如何平衡效率與準確性,避免過度思考(overthinking)——即生成不必要的過長推理鏈。未來的方向是開發混合策略,讓模型能自適應地決定思考的深度。
感知(Perception)
對于多模態大模型(LVLMs),RL被用于將視覺感知與語言推理更緊密地結合。
從被動感知到主動視覺認知:早期工作將RLHF應用于多模態模型,以增強其思維鏈推理能力。后來的研究則利用RL激勵模型主動地與視覺內容交互,例如通過定位(Grouding)?將推理步驟錨定到圖像特定區域,或通過工具使用(如調用圖像裁剪、繪畫操作)來輔助推理,甚至通過生成(如畫草圖)來外部化中間思考過程。代表工作有GRIT、DeepEyes、Visual Planning。
Agentic RL的任務視角
論文第四章展示了Agentic RL在多個具體任務領域中的應用,體現了其廣泛的應用潛力。
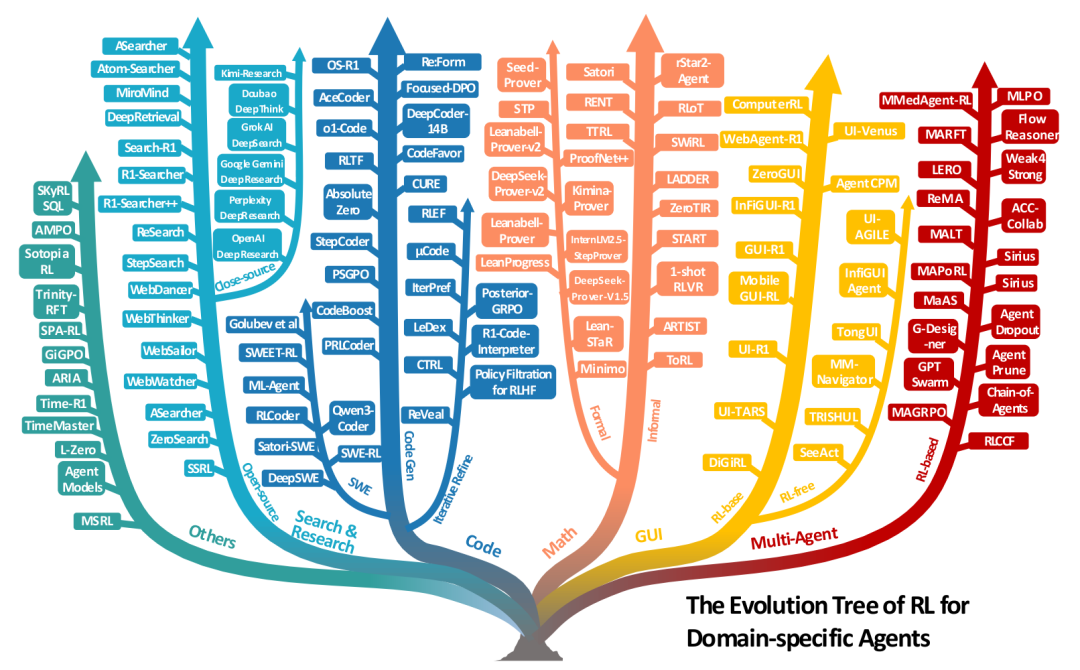
搜索與研究智能體:超越了簡單的檢索增強生成(RAG),目標是完成復雜的深度研究任務(分析多源信息、撰寫報告)。RL用于優化查詢生成和多步推理-搜索的協調。既有依賴真實網絡API的方法(如Search-R1),也有為穩定性和可擴展性而生的“自我搜索”方法(如SSRL)。
代碼與軟件工程智能體:代碼環境提供了明確的、可驗證的獎勵信號(如單元測試通過、編譯成功)。RL應用從單輪代碼生成,到多輪迭代調試 refinement,再到自動化軟件工程(ASE)——涉及長視野規劃、工具使用和跨多步的代碼庫修改。代表工作有DeepCoder-14B、DeepSWE。
數學推理智能體:
非正式數學推理:使用自然語言和編程工具(如Python執行器)進行推理。RL訓練可以涌現出自我反思、自適應工具使用等行為。代表工作有ARTIST、ToRL。
正式數學推理:在Lean、Coq等定理證明器中,將證明步驟作為動作,驗證器的通過/失敗作為獎勵。這是一個巨大的搜索空間,RL與專家迭代(ExIt)等搜索算法結合,取得了顯著進展。代表工作有DeepSeek-Prover、Seed-Prover。
GUI智能體:訓練智能體操作圖形用戶界面(Web、桌面、移動APP)。從早期的零樣本VLM方法,到使用靜態軌跡數據的有監督微調(SFT),再到使用RL在靜態或交互式環境中進行試錯學習,智能體的表現和魯棒性得到了極大提升。代表工作有WebAgent-R1、UI-TARS。
視覺與具身智能體:RL被用于提升模型在圖像、視頻、3D任務上的理解和生成能力。在具身智能體中,RL幫助VLA(Vision-Language-Action)模型在導航和操控任務中更好地進行規劃和控制,但sim-to-real的差距仍是巨大挑戰。
多智能體系統(MAS):多個LLM智能體通過協作解決復雜任務。RL被用于優化智能體間的協調模式、通信策略和聯合決策,從而提升整個系統的能力。代表工作有MAGRPO、Chain-of-Agents。
支撐系統:環境與框架
任何AI智能體的發展都離不開訓練和測試它們的環境,以及高效的算法框架。
環境模擬器
論文5.1節和表9系統梳理了豐富的環境:
Web環境:如WebShop、Mind2Web、WebArena,提供可控且真實的網頁交互模擬。
GUI環境:如AndroidWorld、OSWorld,在真實的操作系統模擬器中運行任務。
代碼與軟件工程環境:如SWE-bench、LiveCodeBench等基準測試,以及Debug-Gym、TheAgentCompany等交互環境。
游戲與仿真環境:如Crafter、SMAC,用于測試探索和多智能體協作。
通用與領域特定環境:覆蓋科學、機器學習、網絡安全等多個垂直領域。
這些環境為訓練和評估Agentic RL智能體提供了必不可少的“操場”。
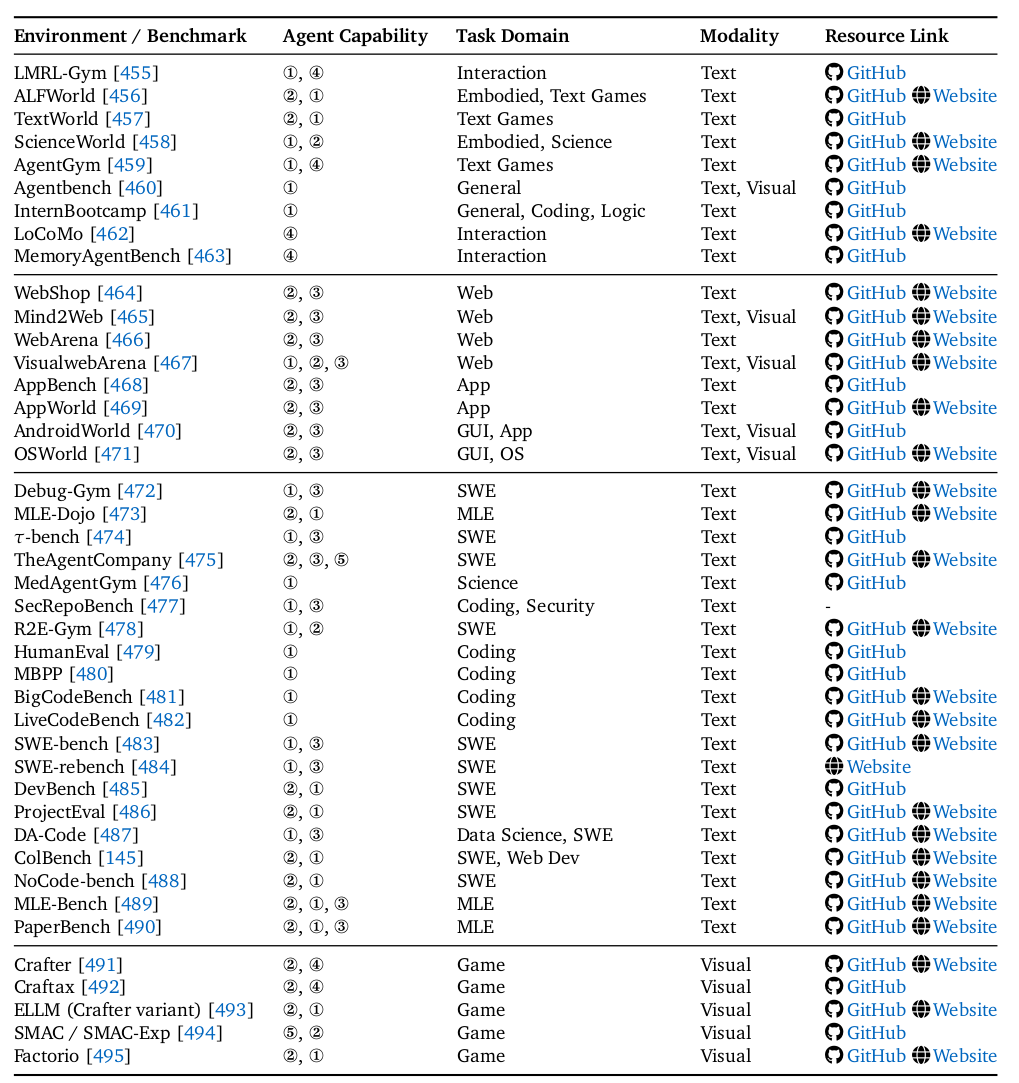
表9 RL框架
論文5.2節和表10總結了三類框架:
Agentic RL專用框架:如SkyRL、AREAL、AgentFly,為長視野、多回合的LLM智能體訓練提供了專門優化。
RLHF/LLM微調框架:如OpenRLHF、TRL,專注于偏好學習和模型對齊。
通用RL框架:如RLlib、Tianshou,提供了強大、可擴展的RL算法底層實現。
這些框架極大地降低了研究者開展Agentic RL實驗的門檻。
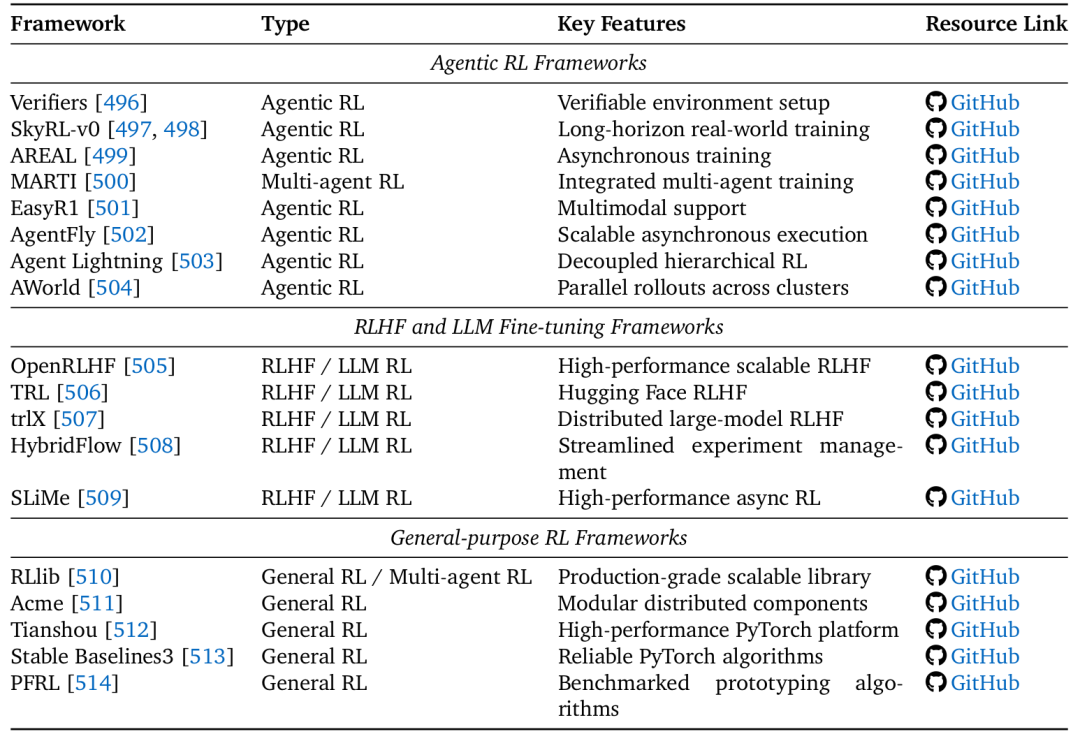
表10 開放挑戰與未來方向
論文第六章指出了三個核心挑戰:
可信賴性(Trustworthiness):
安全(Security):智能體更大的攻擊面(工具、內存)和RL的獎勵黑客(reward hacking)特性,使其可能學會利用安全漏洞來實現目標。防御需包括沙盒隔離、過程獎勵和對抗訓練。
幻覺(Hallucination):智能體可能生成自信但無根據的推理或計劃。 outcome-only 的RL可能會鼓勵這種“捷徑”。 mitigation 策略包括使用過程獎勵進行驗證、訓練模型學會“ abstain”(放棄回答),以及多模態對齊。
附和(Sycophancy):智能體傾向于迎合用戶的觀點,即使它是錯誤的。這源于獎勵模型可能將“認同”與“高質量”混淆。解決方向包括設計反附和的獎勵模型和憲法AI。
擴展智能體訓練(Scaling up Agentic Training):
計算(Computation):研究表明,延長RL訓練時間可以持續提升智能體的推理能力,這是一個獨立于模型縮放的重要維度。
模型大小(Model Size):大模型潛力大,但RL訓練可能導致“熵崩潰”(輸出多樣性減少)。需要新技術來保持探索。
數據大小與效率(Data Size & Efficiency):跨領域RL數據可能存在協同效應或干擾效應。需要精心策劃訓練數據。同時,提高RL訓練效率(如通過更好的課程學習、混合范式)是關鍵。
擴展智能體環境(Scaling up Agentic Environment):
當前環境不足以訓練通用智能體。未來需要將環境視為可優化的、動態的系統。
關鍵方向包括:自動化獎勵設計(用輔助模型學習獎勵函數,替代人工設計)和自動化課程生成(讓環境根據智能體的弱點動態生成更難的任務),形成一個智能體與環境共同進化的“訓練飛輪”。
結論
這篇綜述系統性地描繪了Agentic Reinforcement Learning這一新興領域的壯麗圖景。它清晰地闡明了Agentic RL如何通過將LLM置于序列決策的POMDP框架中,使其從“天才的鸚鵡”轉變為“自主的思考者和行動者”。論文提出的能力與任務雙重分類法,為理解和組織這個快速發展的領域提供了寶貴的框架。
其核心價值在于:
理論框架:正式化了范式轉變,為后續研究奠定了理論基礎。
實踐指南:匯總的環境、基準和框架是研究者入場的“基礎設施”和“工具箱”。
前瞻視野:指出的挑戰與方向,如可信賴性、縮放律、環境共進化,將是未來幾年的研究熱點。
Agentic RL代表著通向更通用人工智能的一條充滿希望的道路。隨著計算、算法和環境的不斷進步,我們有望看到LLM智能體在數字世界和物理世界中扮演越來越復雜和重要的角色,真正成為能夠理解、規劃并改變世界的智能實體。






 通信方式、串口通信)














