目錄
1. 什么是 Alluxio??
2. Alluxio 的誕生背景:為什么需要數據編排層??
痛點 1:計算與存儲強耦合,適配成本高?
痛點 2:跨集群 / 跨云數據移動效率低?
痛點 3:數據訪問延遲高,緩存機制碎片化?
3. Alluxio 的架構設計:分層解耦,彈性擴展?
3.1 核心組件詳解?
(1)主節點(Master):元數據管理中心?
(2)從節點(Worker):數據存儲與服務節點?
(3)客戶端(Client):計算框架的對接入口?
(4)底層存儲(Under Storage):數據持久化層?
3.2 架構分層圖
3.3 核心數據流程:以 “讀取 S3 數據” 為例?
4. Alluxio 解決的核心問題:直擊大數據架構痛點?
問題 1:打破數據孤島,實現統一數據訪問?
問題 2:降低數據訪問延遲,提升計算效率?
問題 3:減少跨存儲 / 跨云數據移動,節省帶寬成本?
問題 4:解耦計算與存儲,提升架構彈性?
5. Alluxio 的關鍵特性:為什么它能成為數據編排首選??
特性 1:內存優先的多級存儲(Tiered Storage)?
特性 2:兼容 HDFS API,零成本遷移?
特性 3:強一致性與高可用?
特性 4:云原生友好,支持彈性擴縮容?
特性 5:跨云 / 跨集群數據管理?
特性 6:細粒度的緩存與權限控制?
特性 7:豐富的監控與診斷工具?
6. Alluxio 與同類產品對比:它的差異化優勢在哪里??
7. Alluxio 的使用方法:從部署到集成 Spark 實操?
7.1 環境準備?
7.2 集群部署(3 節點:1 Master + 2 Worker)?
7.3 集成 Spark 讀取 Alluxio 數據?
7.4 常用命令行工具?
8.總結與最佳實踐?
參考資料:
?
Alluxio是當今大數據和人工智能領域最具創新性的數據編排平臺之一,它通過獨特的架構設計解決了計算與存儲分離帶來的性能瓶頸,成為云原生和存算分離架構的關鍵組件。作為位于計算框架與底層存儲之間的中間層,Alluxio提供統一的API接口和全局命名空間,將數據從存儲層移動到更接近計算應用的位置,顯著加速數據訪問 。在AI訓練場景中,Alluxio可將模型訓練速度提高20倍,模型服務速度提高10倍,同時將GPU利用率提升至90%以上,成為企業構建高效AI基礎設施的首選技術。
1. 什么是 Alluxio??
Alluxio 的官方定義是:面向云原生和大數據場景的開源分布式數據編排系統(Data Orchestration Platform),它在計算框架(如 Spark、Flink)和底層存儲系統(如 HDFS、S3、OSS、HBase)之間搭建了一層 “數據中間層”,核心作用是統一數據訪問入口、加速數據流轉、打破數據孤島。?
更通俗地說:如果把大數據架構比作 “物流網絡”,計算框架是 “快遞公司”(負責處理數據),底層存儲是 “倉庫”(負責存放數據),那么 Alluxio 就是 “物流調度中心 + 高速中轉站”—— 它統一管理所有 “倉庫” 的地址(統一命名空間),讓 “快遞公司” 不用逐個對接 “倉庫”;同時通過緩存高頻數據(如內存、SSD),讓 “快遞運輸”(數據讀取)速度提升 10 倍甚至 100 倍。?
關鍵標簽:?
- 開源協議:Apache License 2.0?
- 核心定位:數據編排層(Data Orchestration Layer)?
- 關鍵能力:統一數據訪問、多級緩存加速、跨存儲 / 跨云兼容?
2. Alluxio 的誕生背景:為什么需要數據編排層??
Alluxio 誕生于 2013 年,由加州大學伯克利分校 AMP 實驗室(Apache Spark、Apache Mesos 的發源地)發起,創始人是李浩源(Haoyuan Li)。它的出現,本質是為了解決大數據發展中 “計算 - 存儲分離” 帶來的三大核心痛點:?
痛點 1:計算與存儲強耦合,適配成本高?
早期大數據架構(如 Hadoop 1.x)是 “計算 + 存儲一體化”(MapReduce+HDFS),但隨著場景升級,計算框架逐漸多樣化(Spark、Flink、Presto),存儲系統也走向異構(HDFS、S3、OSS、Azure Blob)。此時,每個計算框架都需要單獨適配不同的存儲接口(如 Spark 對接 S3 要寫 s3a 協議,對接 HDFS 要寫 hdfs 協議),開發和維護成本急劇上升。?
痛點 2:跨集群 / 跨云數據移動效率低?
企業數據往往分散在多個存儲系統中(如本地 HDFS 存離線數據,S3 存云端熱數據),當計算框架需要跨存儲讀取數據時,只能通過 “全量拷貝”(如用distcp從 HDFS 拷貝到 S3),不僅耗時(TB 級數據可能需要數小時),還會占用大量網絡帶寬,導致 “數據不動,計算空等”。?
痛點 3:數據訪問延遲高,緩存機制碎片化?
大數據計算中,高頻訪問的數據(如機器學習訓練的樣本數據、實時分析的熱點表)如果每次都從遠端存儲(如 S3)讀取,會產生很高的網絡延遲(毫秒級甚至秒級)。而不同計算框架的緩存機制(如 Spark 的 RDD 緩存、Flink 的 State Backend)是孤立的,無法共享緩存數據,導致資源浪費和重復讀取。?
正是這些痛點,催生了 Alluxio—— 它通過 “統一抽象 + 全局緩存”,讓計算框架與存儲系統解耦,同時實現數據的 “一次加載,多次復用”。?
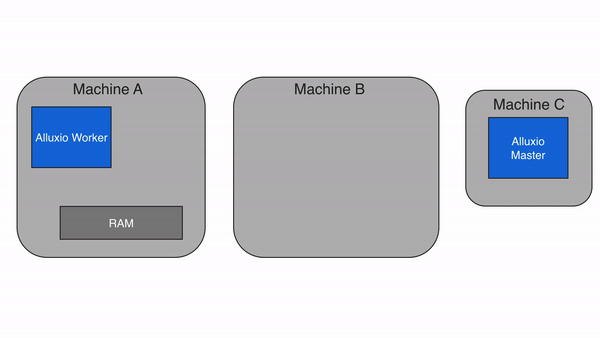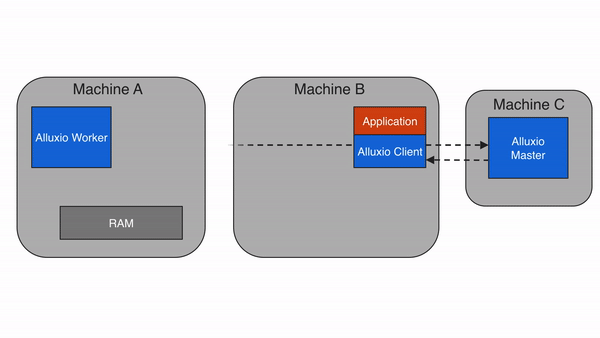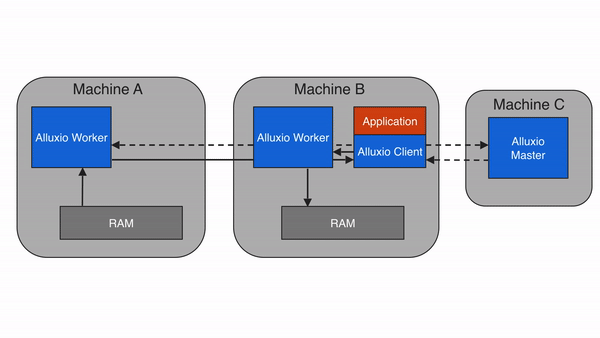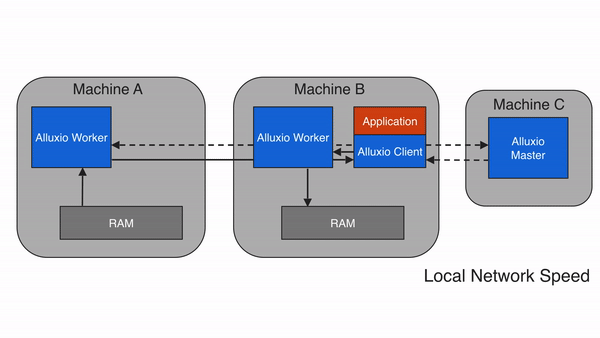
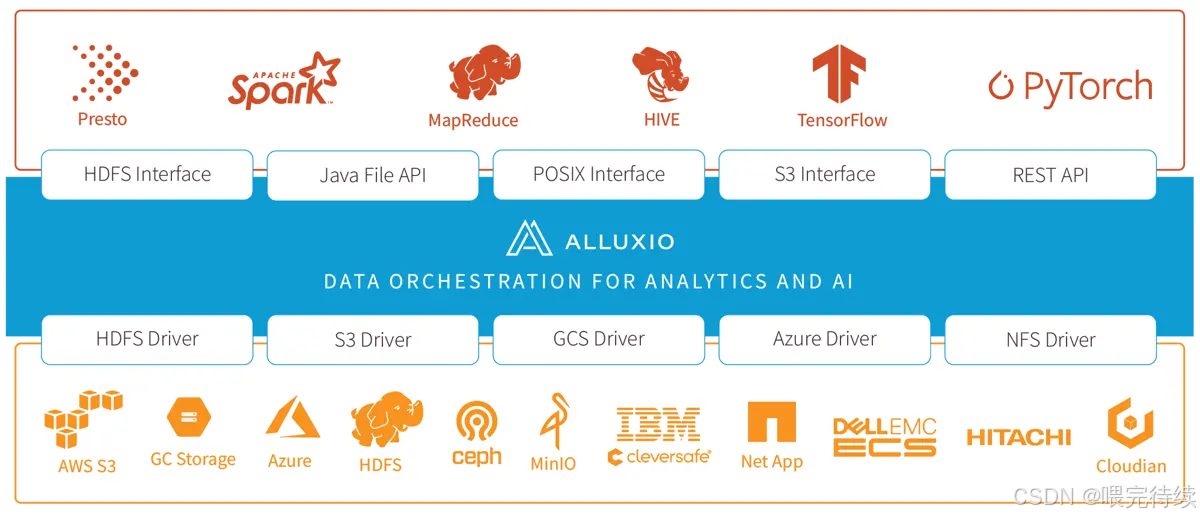
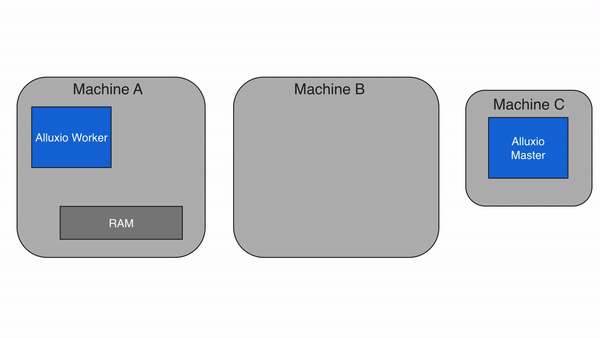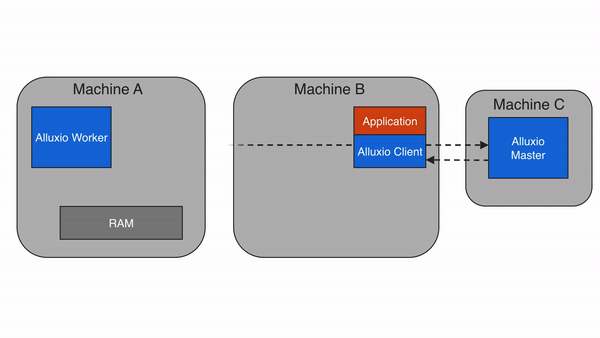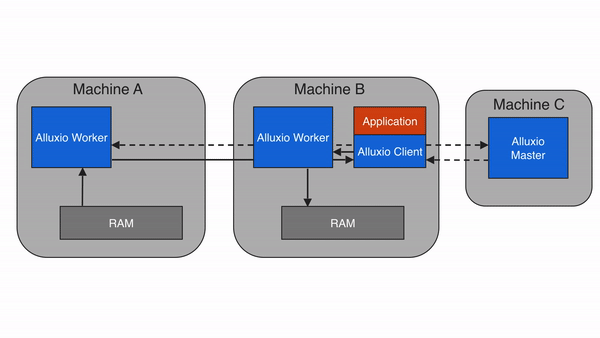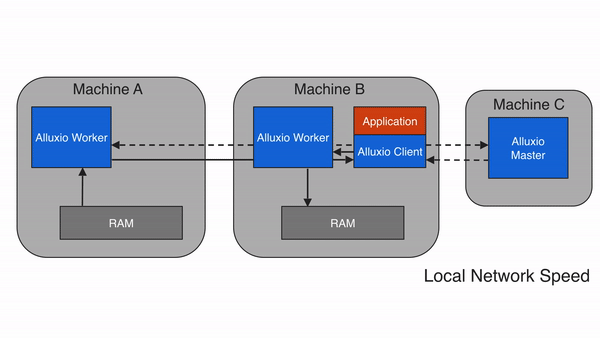
3. Alluxio 的架構設計:分層解耦,彈性擴展?
Alluxio 采用主從架構(Master-Worker),配合客戶端(Client)和底層存儲(Under Storage),形成四層結構(客戶端層、主節點層、從節點層、存儲層)。這種設計的核心是 “元數據與數據分離”——Master 只管理元數據(如文件路徑、權限、塊位置),Worker 負責存儲數據塊和提供讀寫服務,確保架構輕量、高效、可擴展。?
3.1 核心組件詳解?
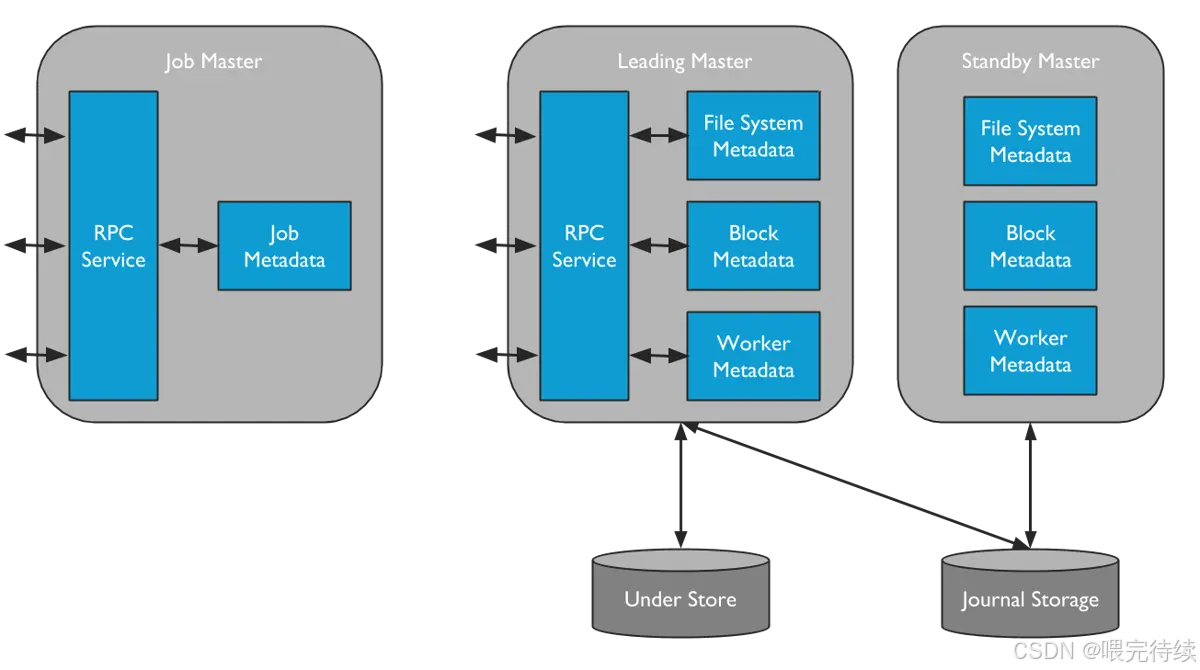
(1)主節點(Master):元數據管理中心?
Master 是 Alluxio 的 “大腦”,主要負責元數據管理和集群協調,不存儲實際數據塊。核心功能包括:?
- 元數據管理:維護文件系統的命名空間(如目錄、文件、塊的層級關系)、文件權限、塊與 Worker 的映射關系;?
- 塊管理:負責數據塊的分配(如將塊分配給哪個 Worker)、復制(保證數據可靠性)、回收(淘汰冷數據);?
- 集群管理:監控 Worker 的健康狀態(如心跳檢測)、處理 Worker 的加入 / 退出;?
- 高可用(HA):支持多 Master 部署(1 個 Active Master + 多個 Standby Master),通過 Journal 日志(記錄元數據變更)實現故障切換,避免單點故障。?
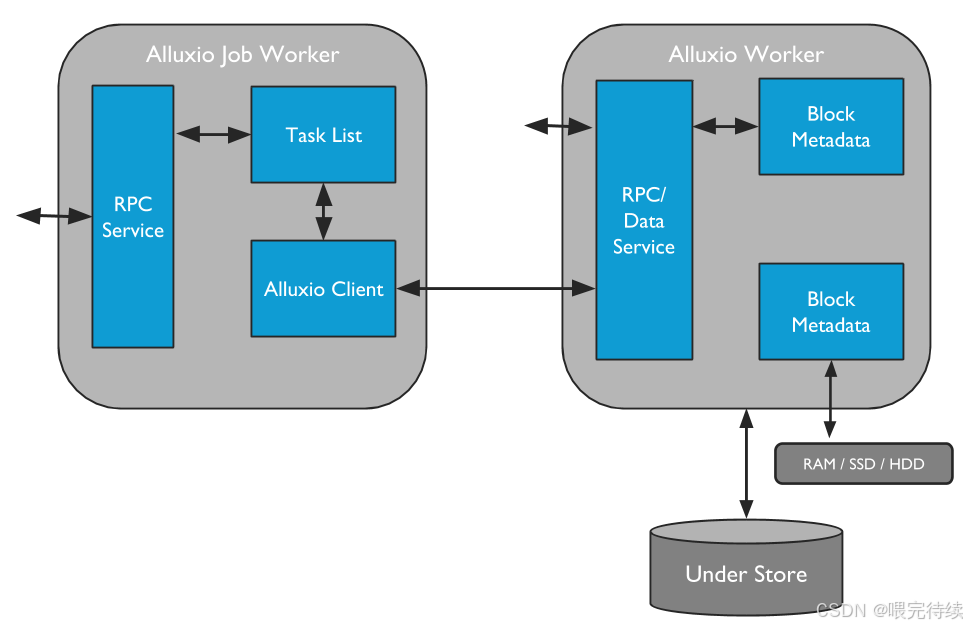
(2)從節點(Worker):數據存儲與服務節點?
Worker 是 Alluxio 的 “手腳”,部署在計算節點或存儲節點上,負責實際數據塊的存儲、讀取和寫入。核心功能包括:?
- 塊存儲:通過 “多級存儲(Tiered Storage)” 存儲數據塊,支持內存(DRAM)、SSD、HDD、NVMe 等介質,優先將高頻數據存放在高速介質(如內存)中;?
- 數據服務:響應客戶端的讀寫請求(如讀取塊、寫入塊),并與底層存儲交互(如下載數據到本地緩存、將數據持久化到底層存儲);?
- 緩存管理:基于 LRU(最近最少使用)等策略淘汰冷數據,釋放存儲空間;?
- 心跳匯報:定期向 Master 匯報自身狀態(如可用存儲空間、當前存儲的塊列表)。?
(3)客戶端(Client):計算框架的對接入口?
Client 是計算框架(Spark、Flink 等)與 Alluxio 交互的 “橋梁”,提供文件系統 API(兼容 HDFS API)和 SDK(Java、Python、Go 等)。核心功能包括:?
- 元數據操作:向 Master 發起目錄創建、文件刪除、元數據查詢等請求;?
- 數據讀寫:向 Worker 發起數據塊的讀寫請求,本地緩存元數據(減少與 Master 的交互);?
- 協議適配:自動適配底層存儲的協議(如 S3、HDFS、OSS),計算框架無需感知底層存儲差異。?
(4)底層存儲(Under Storage):數據持久化層?
Alluxio 本身不負責數據的長期持久化(Worker 的緩存是臨時的),底層存儲是數據的 “最終歸宿”,支持幾乎所有主流存儲系統:?
- 分布式文件系統:HDFS、MapR FS;?
- 對象存儲:AWS S3、阿里云 OSS、騰訊云 COS、Azure Blob;?
- 數據庫:HBase、Cassandra;?
- 本地文件系統:Linux Local FS。?
Alluxio 通過 “掛載(Mount)” 機制將底層存儲接入統一命名空間(如將 S3 的bucket1掛載到 Alluxio 的/s3data目錄),實現對多存儲系統的統一管理。?
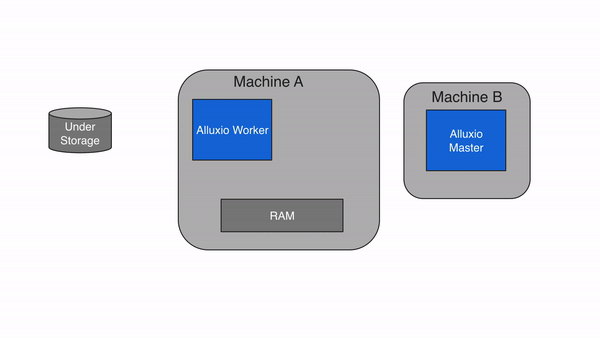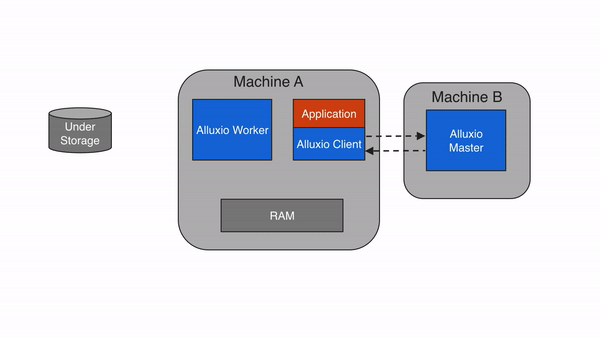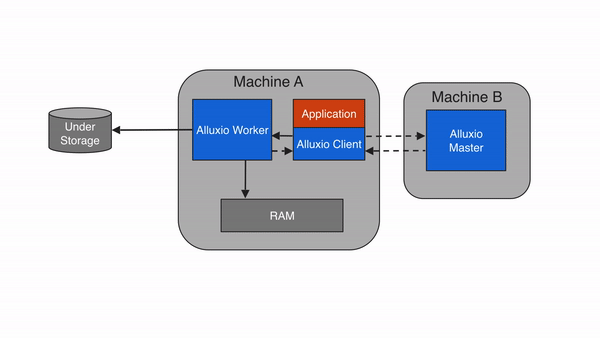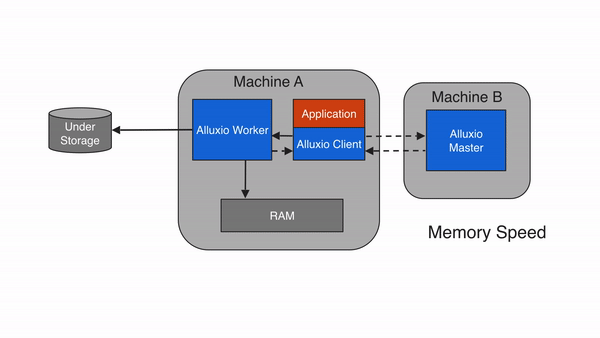
3.2 架構分層圖
?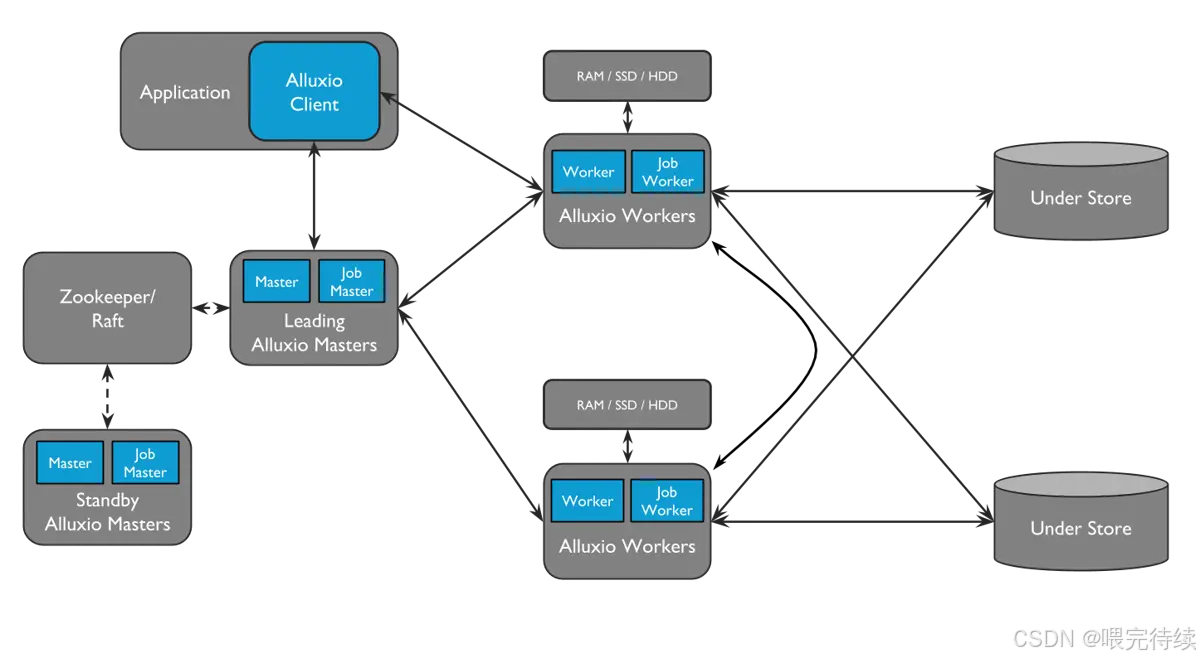
3.3 核心數據流程:以 “讀取 S3 數據” 為例?
- 客戶端(如 Spark)向 Alluxio Master 發起請求:“讀取/s3data/user.csv文件”;?
- Master 查詢元數據,發現該文件對應的塊分散在 Worker 1 和 Worker 2 的緩存中(若未緩存,則返回底層存儲 S3 的地址);?
- Master 將塊的位置信息返回給客戶端;?
- 客戶端直接向 Worker 1 和 Worker 2 讀取數據塊(無需經過 Master,減少轉發開銷);?
- 若 Worker 中無緩存塊,Worker 會先從 S3 下載數據塊到本地緩存,再返回給客戶端(下次讀取直接用緩存)。?
4. Alluxio 解決的核心問題:直擊大數據架構痛點?
基于上述架構,Alluxio 精準解決了大數據場景中的四大核心問題:?
問題 1:打破數據孤島,實現統一數據訪問?
通過 “統一命名空間”,Alluxio 將多個底層存儲系統(如 HDFS、S3、OSS)掛載到同一個目錄樹下,計算框架只需通過 Alluxio 的路徑(如alluxio://master:19998/s3data/user.csv)即可訪問任意存儲的數據,無需關注數據實際存放在哪里。?
價值:開發人員無需為不同存儲編寫不同的訪問代碼,運維人員無需管理多套存儲的訪問權限,降低了跨存儲數據管理的復雜度。?
問題 2:降低數據訪問延遲,提升計算效率?
通過 “多級緩存”(內存→SSD→HDD),Alluxio 將高頻訪問的數據緩存到靠近計算節點的高速介質中,避免每次都從遠端存儲(如 S3)讀取。根據官方測試,緩存命中時,數據讀取延遲可從 “秒級” 降至 “毫秒級”,Spark 作業執行速度提升 3-10 倍。?
價值:實時計算(如 Flink 流處理)、機器學習訓練(如 TensorFlow)等對延遲敏感的場景,可大幅提升吞吐和響應速度。?
問題 3:減少跨存儲 / 跨云數據移動,節省帶寬成本?
當計算需要跨存儲讀取數據時(如 Spark 讀取 S3 數據后寫入 HDFS),Alluxio 會先將數據緩存到本地 Worker,后續計算直接復用緩存,無需重復從 S3 下載。此外,Alluxio 支持 “數據預加載”(提前將冷數據緩存到 Worker),避免計算時等待數據下載。?
價值:減少跨云 / 跨集群的網絡傳輸量(最高可減少 90%),降低帶寬成本,同時避免 “計算空等數據” 的情況。?
問題 4:解耦計算與存儲,提升架構彈性?
Alluxio 作為中間層,隔離了計算框架和底層存儲的依賴關系:計算框架只需適配 Alluxio API,無需適配不同存儲的協議;底層存儲可以獨立升級或替換(如從 HDFS 遷移到 S3),無需修改計算代碼。?
價值:大數據架構的靈活性大幅提升,支持 “計算彈性擴縮容” 和 “存儲獨立演進”,更適配云原生場景。?
5. Alluxio 的關鍵特性:為什么它能成為數據編排首選??
Alluxio 的核心競爭力源于其七大關鍵特性,這些特性讓它在數據編排領域脫穎而出:?
特性 1:內存優先的多級存儲(Tiered Storage)?
- 能力:支持內存、SSD、HDD、NVMe 等多種存儲介質,可配置不同介質的優先級(如內存優先),自動將高頻數據遷移到高速介質,冷數據下沉到低速介質;?
- 場景:實時分析、機器學習訓練等需要低延遲數據訪問的場景;?
- 優勢:平衡性能與成本,既利用內存的高速特性,又通過 HDD 存儲大量冷數據。?
特性 2:兼容 HDFS API,零成本遷移?
- 能力:Alluxio 的文件系統 API 完全兼容 HDFS API(如FileSystem接口),現有基于 HDFS 開發的應用(如 Spark、Hive)無需修改代碼,只需將hdfs://協議替換為alluxio://即可接入;?
- 場景:從 Hadoop 架構向 “計算 - 存儲分離” 架構遷移的場景;?
- 優勢:遷移成本極低,無需重構現有應用。?
特性 3:強一致性與高可用?
- 能力:
????????????強一致性:元數據變更通過 Journal 日志同步,確保所有客戶端看到一致的文件系統狀態;????????????高可用:支持多 Master 部署(Active/Standby),Journal Node 集群存儲元數據日志,故? ? ? ? ? ? ?障切換時間 < 30 秒;?
- 場景:金融、電商等對數據一致性和系統可用性要求高的場景;?
- 優勢:避免數據不一致導致的業務錯誤,保障系統穩定運行。?
特性 4:云原生友好,支持彈性擴縮容?
- 能力:?
? ? ? ? ? ?支持 Kubernetes 部署(通過 Alluxio Operator),可動態創建 / 刪除 Worker Pod;?
? ? ? ? ? ?支持自動擴縮容(根據存儲使用率、CPU 負載觸發擴縮容);?
- 場景:云原生大數據平臺(如 EKS、ACK 上的 Spark/Flink 集群);?
- 優勢:適配云環境的彈性特性,按需分配資源,降低運維成本。?
特性 5:跨云 / 跨集群數據管理?
- 能力:支持掛載不同云廠商的存儲(如 AWS S3、阿里云 OSS、Azure Blob),實現跨云數據統一訪問;同時支持跨 Alluxio 集群的數據復制(如將北京集群的緩存數據同步到上海集群);?
- 場景:多云部署、異地災備的企業;?
- 優勢:打破云廠商鎖定,簡化跨云數據管理。?
特性 6:細粒度的緩存與權限控制?
- 能力:?
? ? ? ? ? ?緩存策略:支持按文件、目錄配置緩存規則(如/hotdata目錄的文件全部緩存到內存),支? ? ? ? ? ? ?持 TTL(過期時間)淘汰;?
? ? ? ? ? ?權限控制:兼容 POSIX 權限模型,支持集成 LDAP、Kerberos 進行身份認證;?
- 場景:多租戶共享的大數據平臺;?
- 優勢:精細化管理緩存資源和數據訪問權限,保障數據安全。?
特性 7:豐富的監控與診斷工具?
- 能力:?
? ? ? ? ? ?內置 Web UI(默認端口 19999),展示集群狀態、元數據信息、緩存命中率;?
? ? ? ? ? 支持集成 Prometheus+Grafana 監控關鍵指標(如緩存命中率、讀寫延遲、Worker 使用? ? ? ? ? ? ? ? 率);?
? ? ? ? ? 提供日志分析工具(Alluxio Log Analyzer),快速定位問題;?
- 場景:大規模集群的運維監控;?
- 優勢:實時掌握集群運行狀態,快速排查故障,降低運維難度。?
6. Alluxio 與同類產品對比:它的差異化優勢在哪里??
在分布式緩存和數據中間層領域,Alluxio 常被與 Apache Ignite、Redis(分布式緩存場景)、HDFS(作為中間層時)對比。下面從核心定位、適用場景、關鍵能力三個維度進行對比,幫助大家選擇:?
| 特性? | Alluxio? | Apache Ignite? | Redis(分布式緩存)? | HDFS(作為中間層)? |
| 核心定位? | 數據編排平臺(連接計算與多存儲)? | 內存計算平臺(計算 + 存儲一體化)? | 分布式緩存 / 鍵值數據庫? | 分布式文件系統(存儲層)? |
| 支持存儲介質? | 內存、SSD、HDD、NVMe(多級)? | 內存、SSD、HDD(多級)? | 內存(主要)、SSD(持久化)? | HDD、SSD(主要)? |
| 統一數據訪問? | 支持多存儲(S3/OSS/HDFS 等)掛載? | 支持部分存儲集成(HDFS/S3)? | 不支持(需手動對接存儲)? | 僅支持自身,不支持其他存儲? |
| 計算框架集成? | 無縫集成 Spark/Flink/Presto 等? | 支持集成 Spark/Flink,但需適配? | 需通過 API 集成,適配成本高? | 原生集成 Hadoop 生態,但擴展性差? |
| 高可用? | 支持多 Master+Journal Node? | 支持分區副本,無專門 Master HA? | 支持主從復制、哨兵模式? | 支持 NameNode HA? |
| 適用場景? | 跨存儲數據加速、統一數據訪問? | 內存計算、實時分析? | 高頻小數據緩存(如會話、熱點 key)? | 大規模數據持久化存儲? |
| 差異化優勢? | 解耦計算與多存儲,跨云能力強? | 計算與存儲結合,適合內存密集計算? | 低延遲、高吞吐,適合小數據緩存? | 成熟穩定,適合大規模持久化? |
結論:?
- 若需統一管理多存儲系統、跨云數據加速,Alluxio 是最佳選擇;?
- 若需內存密集型計算(如實時 OLAP),Apache Ignite 更合適;?
- 若需高頻小數據緩存(如業務系統的熱點數據),Redis 更高效;?
- 若僅需單一存儲的持久化,HDFS 仍是經典方案。?
7. Alluxio 的使用方法:從部署到集成 Spark 實操?
下面以 “Alluxio 2.9.0 版本” 為例,帶大家完成從環境準備、集群部署到集成 Spark 的實操步驟(基于 Linux 環境)。?
7.1 環境準備?
前置依賴?
- JDK 1.8+(推薦 JDK 11);?
- 集群節點間 SSH 免密登錄;?
- 底層存儲(本文以 HDFS 為例,需提前部署 HDFS 集群);?
- (可選)Kubernetes 環境(若需容器化部署)。?
下載 Alluxio 安裝包?
從官網下載二進制包:?
# 下載2.9.0版本(Hadoop 3.3兼容版)
wget https://downloads.alluxio.io/downloads/files/2.9.0/alluxio-2.9.0-bin-hadoop-3.3.tar.gz
# 解壓
tar -zxvf alluxio-2.9.0-bin-hadoop-3.3.tar.gz
cd alluxio-2.9.07.2 集群部署(3 節點:1 Master + 2 Worker)?
步驟 1:配置環境變量?
編輯conf/alluxio-env.sh,設置 JDK 路徑和 HDFS 配置:?
# 復制模板
cp conf/alluxio-env.sh.template conf/alluxio-env.sh
# 編輯配置
vi conf/alluxio-env.sh添加以下內容:?
export JAVA_HOME=/usr/local/jdk11 # 你的JDK路徑
export ALLUXIO_MASTER_HOSTNAME=master # Master節點主機名
export ALLUXIO_UNDERFS_ADDRESS=hdfs://hdfs-master:9000/alluxio # 底層HDFS路徑(需提前創建)
export ALLUXIO_WORKER_MEMORY_SIZE=4GB # Worker內存緩存大小
export ALLUXIO_WORKER_TIERED_STORAGE_LEVELS=1 # 1級存儲(僅內存,如需SSD可配置多級)步驟 2:配置 Worker 節點列表?
編輯conf/workers,添加 Worker 節點主機名:?
worker1
worker2步驟 3:分發安裝包到所有節點?
# 假設Master節點已免密登錄Worker節點
./bin/alluxio-copy-ssh-id.sh worker1
./bin/alluxio-copy-ssh-id.sh worker2
# 分發安裝包
for node in worker1 worker2; doscp -r alluxio-2.9.0 $node:/opt/
done步驟 4:格式化與啟動集群?
# 在Master節點執行格式化(僅首次啟動需執行)
./bin/alluxio format
# 啟動集群
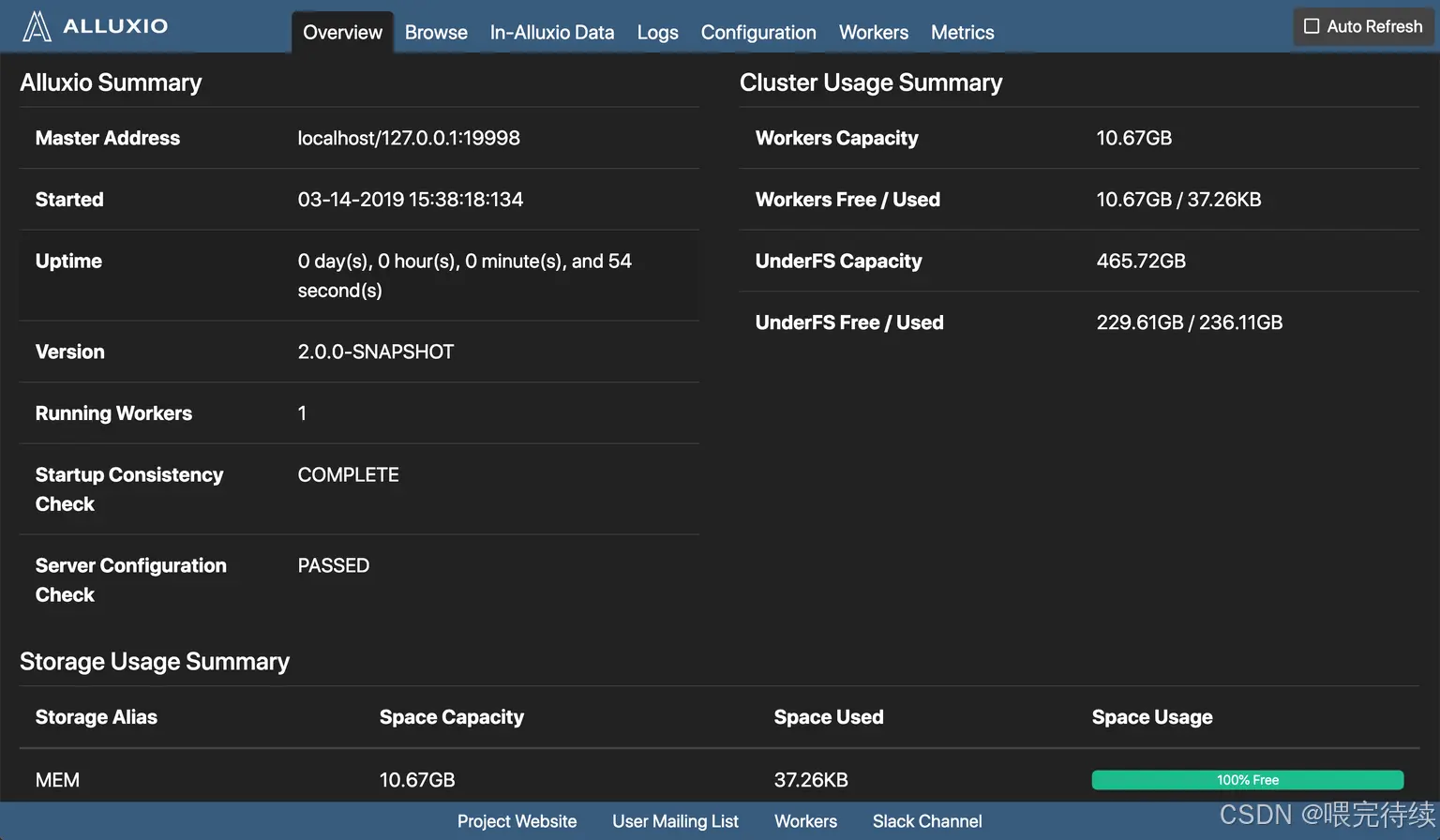
./bin/alluxio-start.sh all步驟 5:驗證集群狀態?
- 訪問 Master Web UI:http://master:19999,查看集群狀態(Worker 數量、緩存使用率等);?
- 執行命令行測試:?
# 創建目錄
./bin/alluxio fs mkdir /test
# 上傳本地文件到Alluxio(自動持久化到HDFS)
./bin/alluxio fs copyFromLocal ./LICENSE /test/
# 查看文件信息(確認塊已緩存)
./bin/alluxio fs ls /test/LICENSE
7.3 集成 Spark 讀取 Alluxio 數據?
步驟 1:配置 Spark 依賴?
將 Alluxio 客戶端 JAR 包復制到 Spark 的jars目錄(或通過--jars指定):?
cp $ALLUXIO_HOME/client/alluxio-client-hadoop-3.3-2.9.0.jar $SPARK_HOME/jars/步驟 2:編寫 Spark 作業(Scala 示例)?
import org.apache.spark.sql.SparkSessionobject AlluxioSparkDemo {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("AlluxioSparkDemo").master("yarn") // 或local[*].getOrCreate()// 讀取Alluxio中的文件(協議為alluxio://)val df = spark.read.text("alluxio://master:19998/test/LICENSE")// 統計文件行數val count = df.count()println(s"Alluxio file /test/LICENSE has $count lines")spark.stop()}
}步驟 3:提交 Spark 作業?
spark-submit \--class AlluxioSparkDemo \--master yarn \--deploy-mode cluster \demo.jar步驟 4:驗證緩存效果?
- 首次運行:Spark 從 HDFS 下載數據到 Alluxio Worker 緩存,耗時較長;?
- 第二次運行:Spark 直接讀取 Alluxio 緩存,耗時顯著減少(可在 Alluxio Web UI 查看 “緩存命中率” 提升)。?
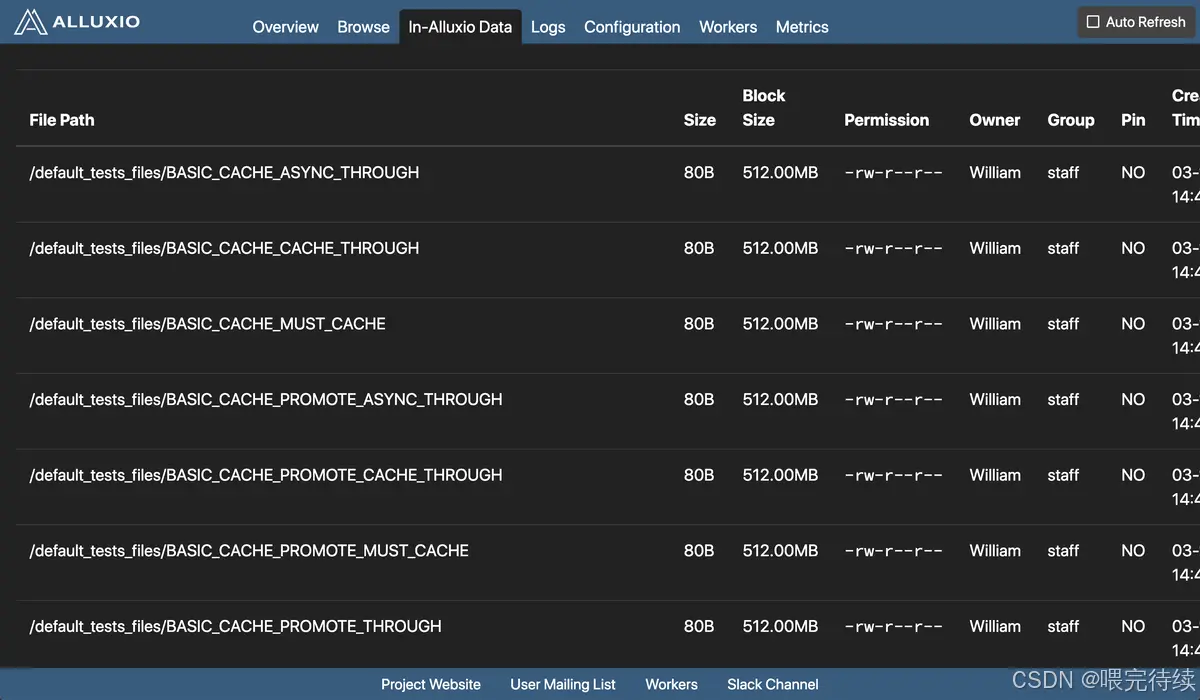
7.4 常用命令行工具?
Alluxio 提供bin/alluxio fs命令行工具,常用命令如下:?
| 命令? | 功能描述? |
| alluxio fs ls /path? | 查看目錄下文件? |
| alluxio fs mkdir /path? | 創建目錄? |
| alluxio fs copyFromLocal localPath alluxioPath? | 本地文件上傳到 Alluxio? |
| alluxio fs copyToLocal alluxioPath localPath? | Alluxio 文件下載到本地? |
| alluxio fs cache /path? | 手動緩存文件到 Worker? |
| alluxio fs free /path? | 手動釋放文件緩存? |
| alluxio fsadmin report? | 查看集群狀態報告? |
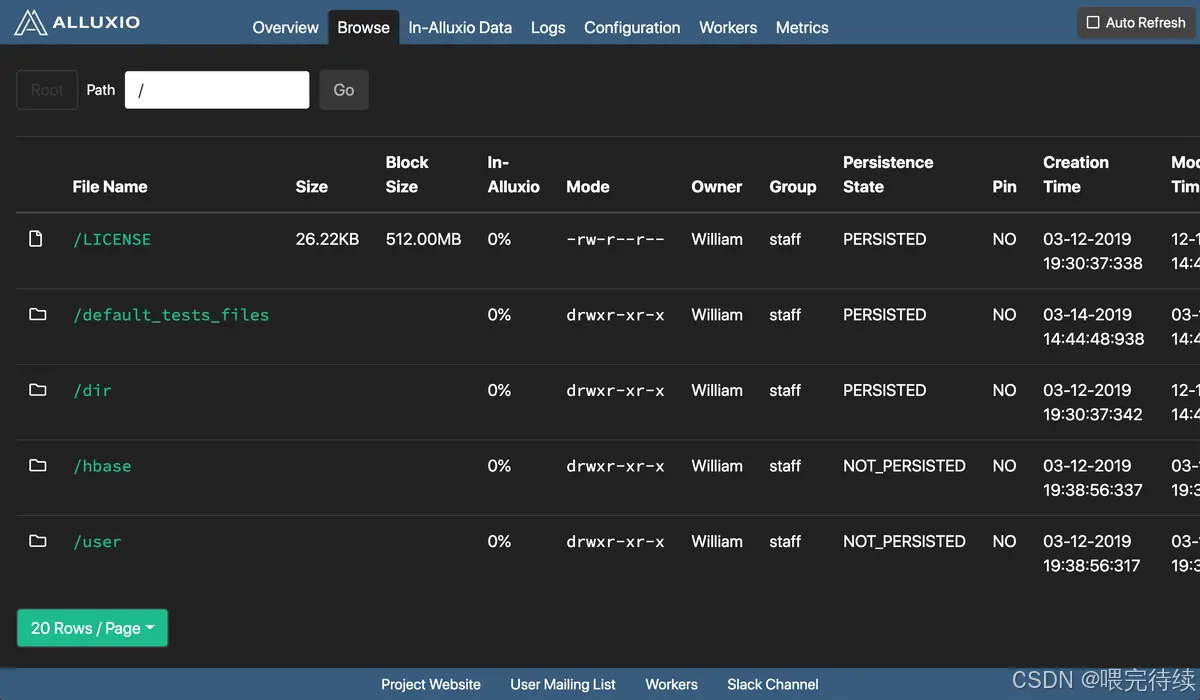
8.總結與最佳實踐?
Alluxio 作為數據編排層的核心技術,通過 “統一訪問 + 多級緩存”,解決了大數據架構中 “計算 - 存儲分離” 帶來的效率低、管理難、成本高的問題。在實際使用中,建議遵循以下最佳實踐:?
- 緩存策略選擇:高頻訪問的小文件(如 <1GB)優先緩存到內存,低頻大文件(如> 10GB)緩存到 SSD;?
- 內存配置:Worker 內存緩存大小建議為計算節點內存的 50%-70%(避免與計算框架爭奪內存);?
- 高可用部署:生產環境必須啟用 Master HA 和 Journal Node 集群,避免單點故障;?
- 監控重點:核心監控指標包括 “緩存命中率”(目標 > 90%)、“Worker 內存使用率”(避免超過 90%)、“元數據操作延遲”(避免 > 100ms);?
- 云原生部署:在 Kubernetes 環境中,使用 Alluxio Operator 管理集群,配合 PVC 動態分配存儲資源。?
如果大家在使用 Alluxio 過程中遇到問題,或有更復雜的場景(如跨云數據同步、機器學習緩存優化),歡迎在評論區交流 —— 后續我會針對具體場景推出更深入的實操教程。
參考資料:
- Alluxio
?本博客專注于分享開源技術、微服務架構、職場晉升以及個人生活隨筆,這里有:
📌 技術決策深度文(從選型到落地的全鏈路分析)
💭 開發者成長思考(職業規劃/團隊管理/認知升級)
🎯 行業趨勢觀察(AI對開發的影響/云原生下一站)
關注我,每周日與你聊“技術內外的那些事”,讓你的代碼之外,更有“技術眼光”。
日更專刊:
🥇 《Thinking in Java》 🌀 java、spring、微服務的序列晉升之路!
🏆 《Technology and Architecture》 🌀 大數據相關技術原理與架構,幫你構建完整知識體系!關于博主:
🌟博主GitHub
🌞博主知識星球
?
?




)





)








