🔥 Github 主倉庫(優先更新)https://github.com/roinli/SSD-GPU-POOL | Gitee 鏡像倉庫
> 原倉庫因故暫停使用,本倉庫為鏡像項目。開源版本將持續迭代優化,歡迎提交 Issue 或加入社群交流。

GPU 池化平臺 | AI 全生命周期管理解決方案
(支持訓練加速/推理優化/資源調度)
一、AI 開發面臨的挑戰
1. GPU 資源管理困境
- 資源利用率低:昂貴算力資源缺乏有效調度,閑置率高達 40%+
- 多租戶管理難:缺乏細粒度權限控制和資源隔離機制
- 成本不可控:缺乏用量監控與成本分析體系
2. AI 開發效率瓶頸
- 環境配置復雜:CUDA 版本沖突、依賴包管理等消耗 30%+ 開發時間
- 協作效率低下:代碼/數據/模型缺乏版本管理和共享機制
- 訓練周期長:缺乏任務隊列管理和分布式訓練優化
- 資產復用困難:實驗過程不可追溯,模型迭代缺乏系統化管理
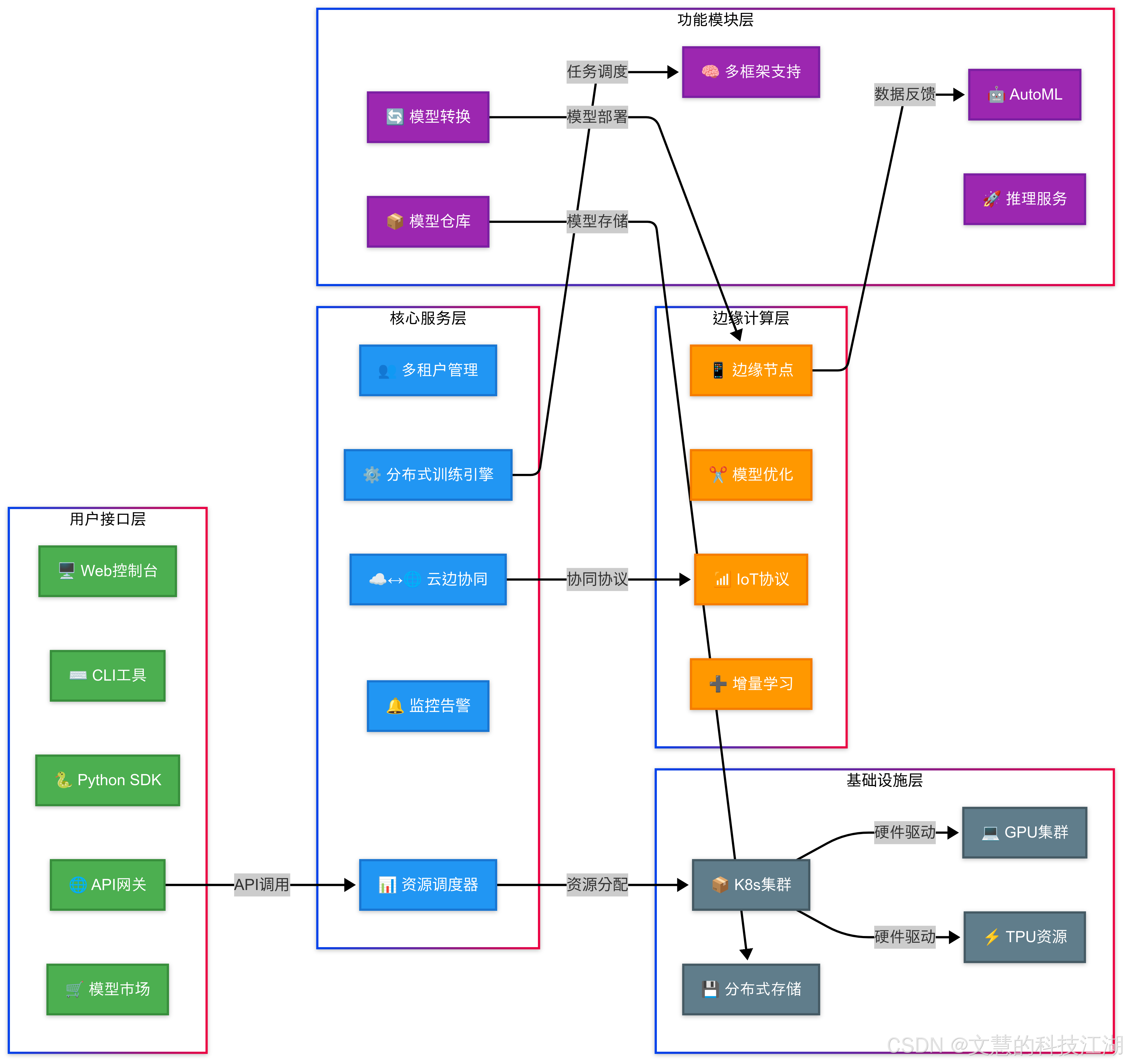
二、平臺核心價值
1. 全流程 AI 開發管理
- 覆蓋數據標注 → 模型開發 → 訓練優化 → 推理部署全生命周期
- 支持 TensorFlow/PyTorch/MXNet 等主流框架的異構計算調度
2. 智能資源調度引擎
- 動態 GPU 池化技術:支持 NVIDIA/AMD 多型號 GPU 混合調度
- 智能排隊系統:支持搶占式任務調度和資源回收機制
- 多租戶隔離:基于 cgroups 的硬件資源隔離,QoS 保障
3. 企業級功能特性
- 分布式訓練加速:優化 AllReduce 算法,線性加速比達 0.95+
- 可視化監控:實時展示 GPU 利用率/顯存占用/網絡吞吐等 50+ 指標
- 安全合規:符合 GDPR 的數據加密傳輸和存儲方案
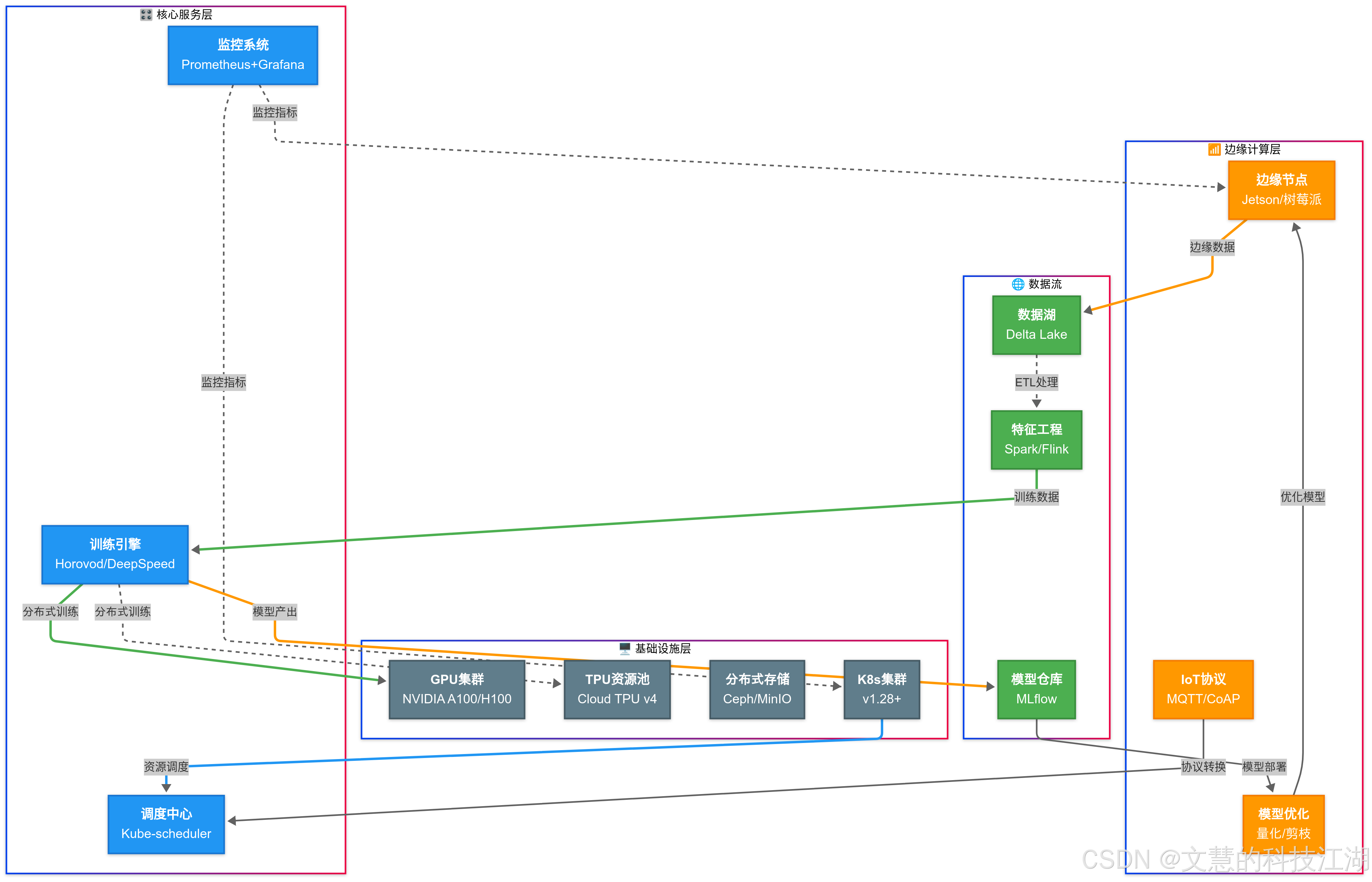
三、功能架構
核心模塊說明:
-
開發環境
- 支持 JupyterLab/VSCode Remote/SSH 多種接入方式
- 預置 20+ 深度學習基礎鏡像,秒級環境啟動
- 資源配額管理(CPU/GPU/Memory/Disk)
-
訓練中心
- 分布式訓練自動拓撲發現
- 斷點續訓和模型自動保存
- TensorBoard 可視化集成
-
資產中心
- 版本化模型倉庫(支持 ONNX/PMML 格式)
- 數據集版本控制(兼容 S3/HDFS 存儲)
- 實驗過程全記錄(超參/指標/日志)
-
調度系統
- 智能批處理作業調度
- 基于公平份額的資源分配算法
- 硬件故障自動遷移
四、技術優勢對比
| 功能項 | 開源版本 | 商業版 | 競品A |
|---|---|---|---|
| 多機多卡訓練支持 | ?? | ??+優化調度 | ? |
| 可視化監控面板 | 基礎版 | 企業級 | ?? |
| 分布式存儲加速 | ? | ??(Lustre 集成) | ? |
| 容器化部署 | Docker | K8s 云原生 | ?? |
| 模型服務化 (Serving) | ? | ??(Triton 集成) | ?? |
五、典型應用場景

場景 1:計算機視覺研發
- 支持 ImageNet 級數據集分布式預處理
- 自動混合精度訓練(AMP)
- 模型量化壓縮工具鏈
場景 2:NLP 模型訓練
- 支持百億參數大模型訓練
- 梯度累積與顯存優化技術
- HuggingFace 生態深度集成
場景 3:邊緣計算部署
- 模型自動轉換為 TensorRT 格式
- 服務網格化部署管理
- 在線模型熱更新
六、客戶案例
案例 1:某自動駕駛公司
- 挑戰:千卡集群利用率不足 50%,訓練任務排隊嚴重
- 方案:部署調度系統 + 分布式存儲加速
- 效果:資源利用率提升至 82%,訓練周期縮短 40%
案例 2:某醫療 AI 實驗室
- 需求:滿足 HIPAA 合規的協作平臺
- 方案:多租戶隔離 + 數據加密傳輸
- 成果:建立 20+ 研究員的協同開發環境
七、生態合作
硬件兼容:NVIDIA Tesla系列/AMD Instinct/華為昇騰
云平臺:AWS/Azure/阿里云/騰訊云
存儲方案:Ceph/GlusterFS/MinIO
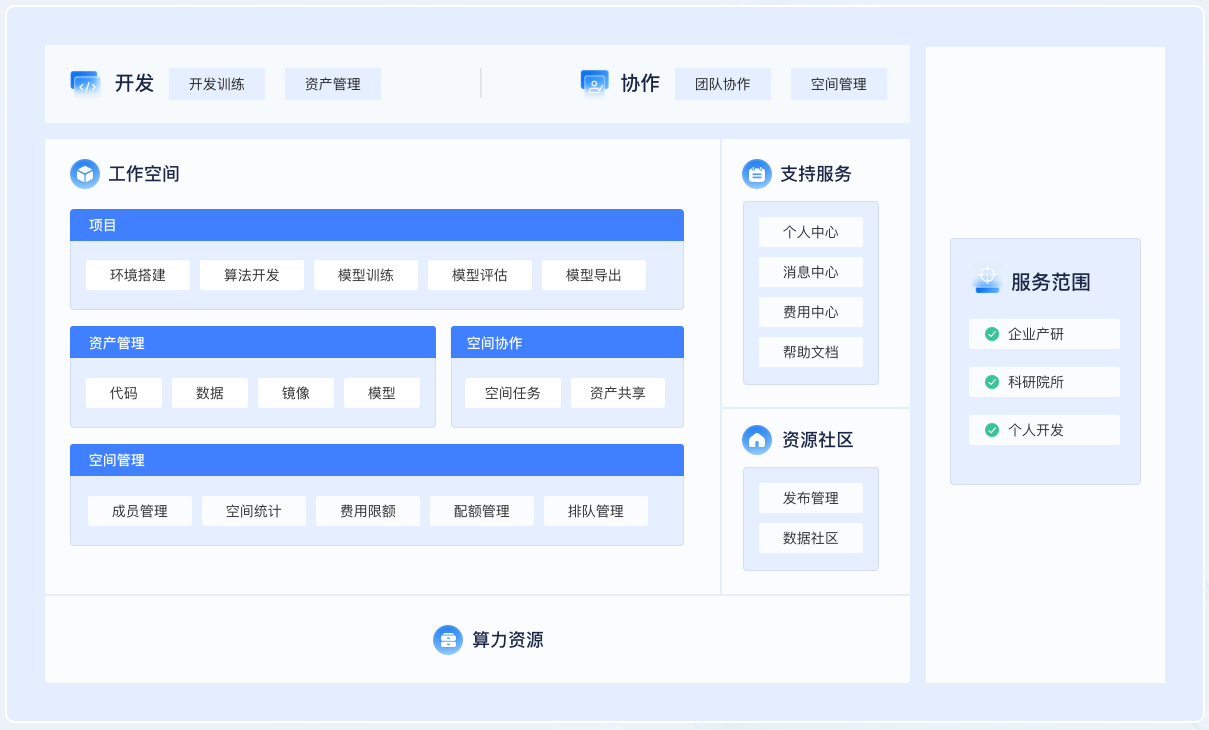
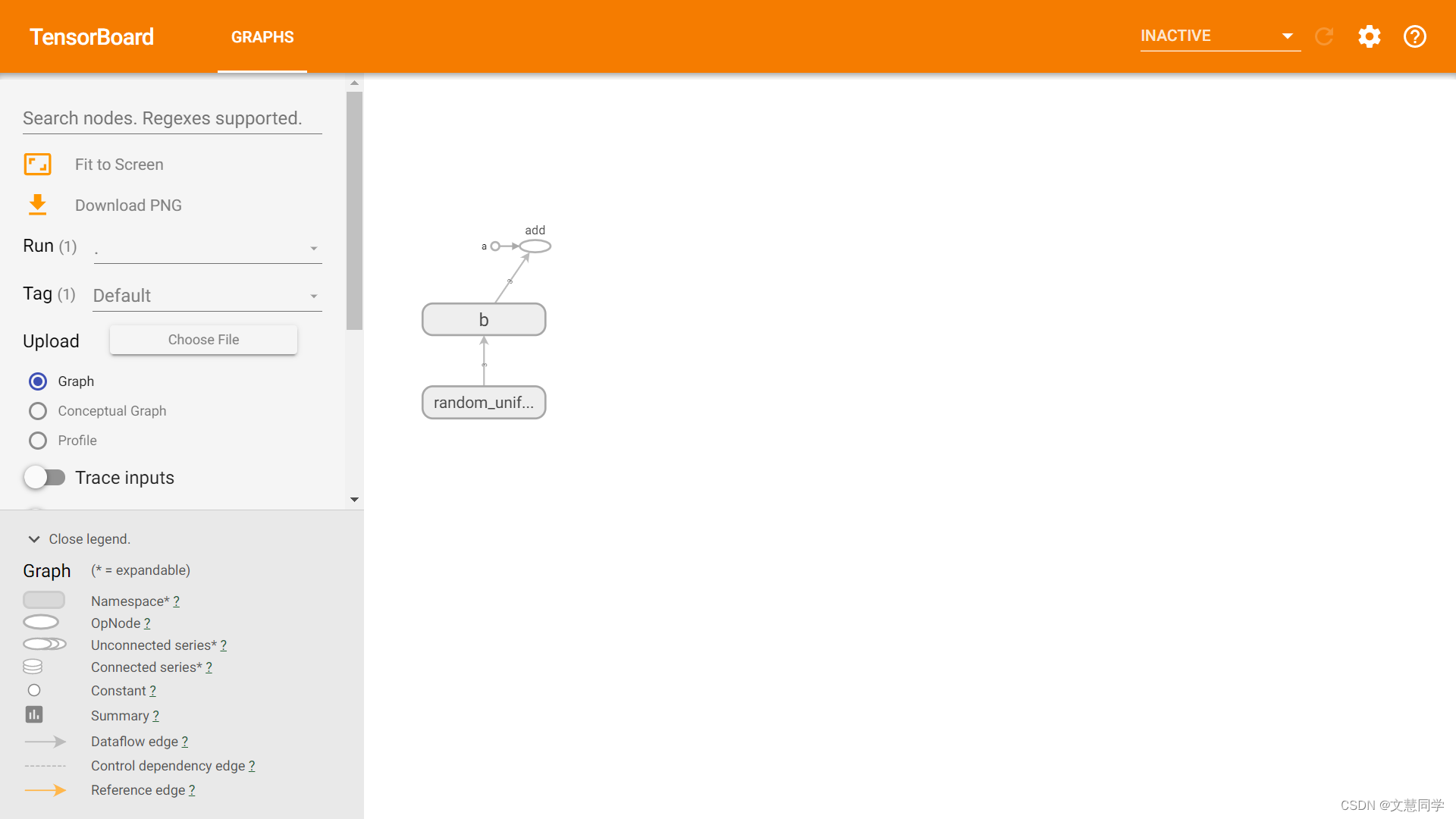
八、產品截圖
| 開發環境 | 訓練監控 |
|---|
| 資源調度 | 模型管理 |
|---|---|
 |  |







指南)











