目錄
一、從傳統查找的痛點到哈希表的優勢?
二、哈希表的核心結構:文件柜的構成?
2.1、 dictht 結構體:文件柜本體?
2.2、dictEntry 結構體:帶鏈條的文件夾?
2.2.1、 哈希沖突的解決:抽屜里的鏈條?
2.3、字典的高層封裝:文件柜管理系統?
2.4、dictType:文件處理工具包?
三、哈希計算:如何確定文件位置?
四、動態擴容與收縮:文件柜的大小調整?
4.1、何時需要調整大小??
4.2、調整大小的規則?
4.3、漸進式 rehash:邊營業邊搬家?
4.4、寫時復制優化:拍照時不整理房間?
五、字典與 SDS 的完美配合?
六、字典設計的核心智慧?
如果說 SDS 是 Redis 的 "智能筆記本",鏈表是 "活頁文件夾",那么字典就是把這些筆記和文件夾有序管理起來的 "智能文件柜系統"。當你在 Redis 中使用哈希類型存儲用戶信息(如HSET user:1 name "張三" age 30)時,背后正是字典結構在高效運作。?
一、從傳統查找的痛點到哈希表的優勢?
想象你在圖書館找書的三種方式:?
- 按書架順序查找:像數組遍歷一樣,逐個查看每個書架,效率極低?
- 按分類目錄查找:像鏈表遍歷一樣,雖然有分類但仍需逐個翻閱?
- 按編號定位查找:像哈希表一樣,通過書號直接計算出所在書架和位置,一步到位?
Redis 的字典采用哈希表作為底層實現,正是為了實現這種 "一步到位" 的高效查找能力。哈希表就像配備了智能索引系統的文件柜,能在 O (1) 時間復雜度內完成數據的查找、添加和刪除操作。?
二、哈希表的核心結構:文件柜的構成?
Redis 的哈希表結構由三個關鍵部分組成,就像文件柜的不同組件:?
2.1、 dictht 結構體:文件柜本體?
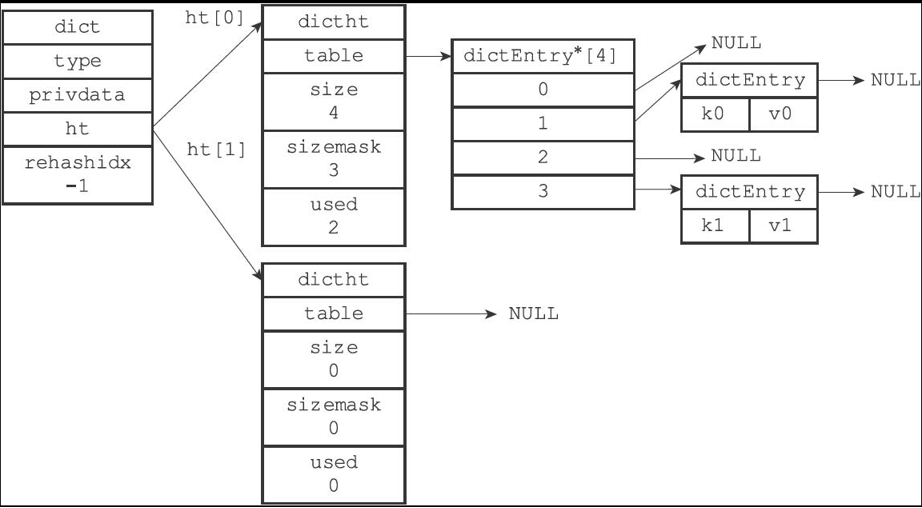
struct dictht {?dictEntry **table; // 抽屜數組(哈希表節點數組)?unsigned long size; // 抽屜總數(哈希表大小)?unsigned long sizemask; // 定位掩碼(總是等于size-1)?unsigned long used; // 已使用抽屜數(節點數量)?};?這個結構體就像一個文件柜:?
- table是一排抽屜,每個抽屜可以放多個文件夾(通過鏈表連接)?
- size記錄總共有多少個抽屜?
- sizemask是定位工具,用來計算文件應該放入哪個抽屜?
- used記錄已經放了多少文件?
2.2、dictEntry 結構體:帶鏈條的文件夾?
struct dictEntry {?void *key; // 文件標簽(鍵)?union { // 文件內容(值)?void *val;?uint64_t u64;?int64_t s64;?} v;?struct dictEntry *next; // 下一個文件夾(解決沖突的鏈表)?};?每個節點就像一個帶鏈條的文件夾:?
- key是文件的標簽,在 Redis 中通常用 SDS 存儲(比如 "name"、"age")?
- v是文件內容,可以是字符串指針(void *val)、無符號整數(u64)或有符號整數(s64)?
- next是連接鏈條,當多個文件需要放入同一個抽屜時,用鏈條將它們串起來(哈希沖突解決)?
2.2.1、 哈希沖突的解決:抽屜里的鏈條?
當兩個不同的鍵計算出相同的抽屜編號時(哈希沖突),就像兩個文件要放進同一個抽屜,這時next指針就發揮作用了 —— 它把這些文件串成一個鏈表,這種方法稱為 "鏈地址法"。?
比如 "張三" 和 "張三豐" 計算出相同的抽屜編號,它們會通過next指針連接在一起,查找時只需遍歷這個小鏈表即可。?
2.3、字典的高層封裝:文件柜管理系統?
Redis 的字典結構在哈希表之上增加了管理層,就像文件柜的智能管理系統:?
struct dict {?dictType *type; // 操作工具集?void *privdata; // 工具參數?dictht ht[2]; // 兩個哈希表(主表和備用表)?int rehashidx; // 搬家進度(-1表示未進行)?};?這個管理系統的核心功能:?
- 維護兩個哈希表ht[0](日常使用)和ht[1](搬家時使用)?
- 通過rehashidx記錄數據遷移進度?
- 提供type中定義的工具函數處理不同類型的數據?
2.4、dictType:文件處理工具包?
struct dictType {?unsigned int (*hashFunction)(const void *key); // 計算抽屜編號的工具?void *(*keyDup)(void *privdata, const void *key); // 復制標簽的工具?void *(*valDup)(void *privdata, const void *obj); // 復制內容的工具?int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比較標簽的工具?void (*keyDestructor)(void *privdata, void *key); // 銷毀標簽的工具?};?這些函數就像文件柜的配套工具:?
- hashFunction:根據文件名計算抽屜編號(哈希函數)?
- keyDup:復制文件標簽(比如復制 SDS 字符串)?
- keyCompare:比較兩個文件標簽是否相同?
- 其他工具負責數據的復制和銷毀?
三、哈希計算:如何確定文件位置?
把文件放入文件柜需要兩步:計算哈希值(文件名編碼)和計算索引(抽屜編號):?
- 計算哈希值:用hashFunction對鍵(key)進行計算,比如對 SDS 字符串 "name" 計算得到一個大整數?
- 計算索引:用哈希值與sizemask(size-1)做與運算,得到抽屜編號:?
?索引 = 哈希值 & sizemask?
例如:當size=8(sizemask=7),哈希值 = 10(二進制 1010)時:?
1010 & 0111 = 0010(二進制)→ 索引=2?
這種計算方式要求size必須是 2 的冪次方,這樣sizemask的二進制表示全是 1,能保證索引均勻分布在0到size-1之間。?
四、動態擴容與收縮:文件柜的大小調整?
隨著文件增減,文件柜需要動態調整大小以保持效率,這個過程稱為 "rehash"(重新散列):?
4.1、何時需要調整大小??
- 擴展條件:當文件太多導致擁擠時?
- 無備份任務時,負載因子≥1(used/size ≥1)?
- 有備份任務時,負載因子≥5(避免頻繁復制內存)?
- 收縮條件:當文件太少導致空間浪費時?
- 負載因子≤0.1(used/size ≤0.1)?
負載因子就像 "擁擠度":比如 8 個抽屜放了 10 個文件,擁擠度 = 10/8=1.25。?
4.2、調整大小的規則?
- 擴展:ht[1]的大小是第一個大于等于ht[0].used*2的 2 的冪次方?
- 例:used=10 → 10*2=20 → 下一個 2 的冪次方是 32?
- 收縮:ht[1]的大小是第一個大于等于ht[0].used的 2 的冪次方?
- 例:used=10 → 下一個 2 的冪次方是 16?
4.3、漸進式 rehash:邊營業邊搬家?
如果文件柜需要從 8 個抽屜擴到 32 個抽屜,不可能一次性搬完所有文件 —— 這會導致圖書館暫時停業。Redis 采用 "漸進式 rehash" 策略,就像邊營業邊搬家:?
- 準備階段:為ht[1]分配新空間,rehashidx=0(開始搬家)?
- 漸進遷移:每次有讀寫操作時,順帶遷移ht[0]中rehashidx索引處的所有文件到ht[1],然后rehashidx加 1?
- 雙表并行:遷移期間,查找操作會同時檢查ht[0]和ht[1];新增操作直接放入ht[1],保證ht[0]只減不增?
- 完成遷移:當ht[0]所有文件都遷移到ht[1]后,ht[1]成為新的ht[0],rehashidx=-1(搬家完成)?
這種策略把巨大的遷移工作分散到每次操作中,避免了服務中斷。?
4.4、寫時復制優化:拍照時不整理房間?
當 Redis 執行 BGSAVE(備份)或 BGREWRITEAOF(日志重寫)時,會創建子進程。為了減少內存復制開銷,Redis 采用 "寫時復制" 技術:?
- 子進程創建時共享父進程內存,只有當數據修改時才復制相關內存頁?
- 因此在備份期間,Redis 提高擴展閾值(負載因子≥5 才擴展),減少內存寫入操作?
- 這就像拍照時不整理房間,等照片拍完再整理,避免重復勞動?
五、字典與 SDS 的完美配合?
SDS 在字典中扮演重要角色:?
- 鍵(key)的存儲:字典的鍵幾乎都是用 SDS 存儲的,比如HSET user:1 name "張三"中的 "name"?
?key → SDS結構:len=4, free=4, buf=['n','a','m','e','\0']?
- 字符串值的存儲:當值是字符串時,也用 SDS 存儲,比如 "張三"?
v.val → SDS結構:len=6, free=6, buf=['張','三','\0']?
- 數值的優化存儲:當值是整數時,直接用u64或s64存儲,避免 SDS 的內存開銷?
這種組合讓字典既能高效存儲字符串,又能優化數值類型的存儲。?
六、字典設計的核心智慧?
| 特性? | 生活比喻? | 技術價值? |
| 哈希表結構? | 智能文件柜? | O (1) 時間復雜度的基本操作? |
| 鏈地址法? | 抽屜里的鏈條? | 優雅解決哈希沖突? |
| 雙哈希表? | 新舊文件柜? | 支持動態擴容 / 收縮? |
| 漸進式 rehash? | 邊營業邊搬家? | 避免操作阻塞? |
| 類型特定函數? | 專用工具包? | 支持多類型數據處理? |
| 寫時復制適配? | 拍照時不整理? | 優化備份時的性能? |
Redis 字典通過這些設計,完美平衡了性能、靈活性和內存效率。它不僅是哈希類型的底層實現,還被用于 Redis 數據庫的核心(鍵空間)、集群節點通信等關鍵場景,是 Redis 高效運作的基石之一。?
理解了字典結構,你就掌握了 Redis 數據管理的核心機制 —— 從簡單的鍵值對到復雜的哈希對象,都依賴這個精妙的 "智能文件柜系統" 來實現高效管理。

)






)





:H264中的SEI)




