AWS OpenSearch 介紹
OpenSearch 是一種全面開源搜索和分析引擎,使用案例包括日志分析、實時應用程序監控、點擊流分析等。Amazon OpenSearch Service 是一項托管服務,讓用戶能夠在 AWS 云中輕松部署、運行并擴展 OpenSearch 集群。
觀測云
觀測云是一款專為 IT 工程師打造的全鏈路可觀測產品,它集成了基礎設施監控、應用程序性能監控和日志管理,為整個技術棧提供實時可觀察性。這款產品能夠幫助工程師全面了解端到端的用戶體驗追蹤,了解應用內函數的每一次調用,以及全面監控云時代的基礎設施。此外,觀測云還具備快速發現系統安全風險的能力,為數字化時代提供安全保障。
采集器配置
- 登陸觀測云控制臺
- 點擊【集成】菜單,選擇【云賬號管理】
- 點擊【添加云賬號】,選擇【AWS】,填寫界面所需的信息,如之前已配置過云賬號信息,則忽略此步驟
- 點擊【測試】,測試成功后點擊【保存】,如果測試失敗,請檢查相關配置信息是否正確,并重新測試
- 點擊【云賬號管理】列表上可以看到已添加的云賬號,點擊相應的云賬號,進入詳情頁
- 點擊云賬號詳情頁的【集成】按鈕,在未安裝列表下,找到AWS OpenSearch,點擊【安裝】按鈕,彈出安裝界面安裝即可。
關鍵指標
| 指標名稱 | 描述 | 單位 |
|---|---|---|
| ClusterStatus_green | 值為 1 指示將所有索引分片分配給集群中的節點,表示集群處于健康狀態 | Int |
| ClusterStatus_yellow | 值為 1 指示將所有索引的主要分片分配給集群中的節點,但是至少有一個索引的分片副本不是如此 | Int |
| ClusterStatus_red | 值為 1 指示至少一個索引的主分片和副本分片未分配給集群中的節點 | Int |
| Shards_activePrimary | 活動主分區數 | Int |
| Shards_unassigned | 未分配給集群中節點的分區數 | Int |
| Shards_initializing | 正在初始化的分區數 | Int |
| SearchableDocuments | 跨集群中所有數據節點的可搜索文檔的總數 | Int |
| Shards_active | 活動主分區和副本分區的總數 | Int |
| Shards_delayedUnassigned | 其節點分配因超時設置已延遲的分區數 | Int |
| Shards_relocating | 正在重新定位的分區數 | Int |
| DeletedDocuments | 跨集群的所有數據節點已標記為刪除的文檔總數 | Int |
| Nodes | OpenSearch 集群中的節點數 | Int |
| CPUUtilization | 集群中數據節點的 CPU 利用率百分比 | Int |
| FreeStorageSpace | 集群中各數據節點的可用空間 | Int |
| ClusterUsedSpace | 集群的已使用空間總量 | Int |
| 2xx | 指定的 HTTP 響應代碼 2xx 的對域的請求數 | Int |
| 3xx | 指定的 HTTP 響應代碼 3xx 的對域的請求數 | Int |
| 4xx | 指定的 HTTP 響應代碼 4xx 的對域的請求數 | Int |
| 5xx | 指定的 HTTP 響應代碼 5xx 的對域的請求數 | Int |
| ThroughputThrottle | 指示磁盤是否受到節流 | Int |
| IopsThrottle | 指示該域每秒進行讀寫操作的次數(IOPS)是否已被節流 | Int |
| JVMMemoryPressure | 用于集群中所有數據節點的 Java 堆的最大百分比 | Int |
| JVMGCYoungCollectionCount | “年輕代”垃圾回收的運行次數 | Int |
| JVMGCOldCollectionCount | “年老代”垃圾回收的運行次數 | Int |
| OldGenJVMMemoryPressure | 集群中所有數據節點上用于“上一代”的 Java 堆的最大百分比 | Int |
| JVMGCYoungCollectionTime | 集群執行“年輕代”垃圾回收所花費的時間,以毫秒為單位 | Int |
| JVMGCOldCollectionTime | 集群執行“年老代”垃圾回收所花費的時間,以毫秒為單位 | Int |
| IndexingLatency | 節點中所有索引操作所用的總時間差(以毫秒為單位) | Int |
| IndexingRate | 每分鐘的索引操作數 | Int |
| SearchLatency | 節點中所有搜索的總時間差(以毫秒為單位) | Int |
| SearchRate | 數據節點上所有分片的每分鐘搜索請求總數 | Int |
| SegmentCount | 數據節點上的分段數。您擁有的分段越多,每次搜索所花費的時間就越長 | Int |
| SysMemoryUtilization | 使用中的實例內存的百分比。此指標的值較高是正常的,通常不表示集群存在問題 | Int |
| ThreadpoolForce_mergeQueue | 強制合并線程池中的排隊任務數。如果隊列大小一直很大,請考慮擴展您的集群 | Int |
| ThreadpoolForce_mergeRejected | 強制合并線程池中的已拒絕任務數。如果此數字持續增長,請考慮擴展您的集群 | Int |
| ThreadpoolForce_mergeThreads | 強制合并線程池的大小 | Int |
| ThreadpoolSearchQueue | 搜索線程池中的排隊任務數。如果隊列大小一直很大,請考慮擴展您的集群 | Int |
| ThreadpoolSearchRejected | 搜索線程池中的已拒絕任務數。如果此數字持續增長,請考慮擴展您的集群 | Int |
| ThreadpoolSearchThreads | 搜索線程池的大小 | Int |
| Threadpoolsql-workerQueue | SQL 搜索線程池中的排隊任務數。如果隊列大小一直很大,請考慮擴展您的集群 | Int |
| Threadpoolsql-workerRejected | SQL 搜索線程池中的已拒絕任務數。如果此數字持續增長,請考慮擴展您的集群 | Int |
| Threadpoolsql-workerThreads | SQL 搜索線程池的大小 | Int |
| ThreadpoolWriteQueue | 寫入線程池中的排隊任務數 | Int |
| ThreadpoolWriteRejected | 寫入線程池中的已拒絕任務數 | Int |
| ThreadpoolWriteThreads | 寫入線程池的大小 | Int |
| CoordinatingWriteRejected | 由于索引壓力而在協調節點上發生的拒絕總數 | Int |
| PrimaryWriteRejected | 由于索引壓力而在主分區上發生的拒絕總數 | Int |
| ReplicaWriteRejected | 由于索引壓力而在副本分區上發生的拒絕總數 | Int |
| ReadLatency | EBS 卷上讀取操作的延遲(以秒為單位) | Int |
| WriteLatency | EBS 卷上寫入操作的延遲(以秒為單位) | Int |
| ReadThroughput | EBS 卷上讀取操作的吞吐量(以字節/秒為單位) | Int |
| WriteThroughput | EBS 卷上寫入操作的吞吐量(以字節/秒為單位) | Int |
| ReadIOPS | 針對 EBS 卷上的讀取操作的每秒輸入和輸出 (I/O) 操作數 | Int |
| WriteIOPS | 針對 EBS 卷上的寫入操作的每秒輸入和輸出 (I/O) 操作數 | Int |
| BurstBalance | 一個 EBS 卷的可爆發存儲桶中剩余輸入和輸出(I/O)積分的百分比。值為 100 表示該卷積累的積分數量已達最大數量 | Int |
| AsynchronousSearchInitializedRate | 過去 1 分鐘內初始化的異步搜索數 | Int |
| AsynchronousSearchRunningCurrent | 當前正在運行的異步搜索數 | Int |
| AsynchronousSearchCompletionRate | 過去 1 分鐘內成功完成的異步搜索數 | Int |
| AsynchronousSearchFailureRate | 最后一分鐘內完成和失敗的異步搜索數 | Int |
| AsynchronousSearchPersistRate | 過去 1 分鐘內持續存在的異步搜索數 | Int |
| AsynchronousSearchRejected | 自節點啟動時間以來拒絕的異步搜索總數 | Int |
| AsynchronousSearchCancelled | 自節點啟動時間以來取消的異步搜索總數 | Int |
| SQLRequestCount | 對 _sql API 的請求數 | Int |
| SQLUnhealthy | 值為 1 表示 SQL 插件將返回 5xx 響應代碼或將無效的查詢 DSL 傳遞到 OpenSearch 來響應特定請求。其他請求將繼續成功。值為 0 表示最近未失敗。如果您看到持續值為 1,請排查您的客戶端對插件發出的請求的問題。 | Int |
| SQLDefaultCursorRequestCount | 類似于 SQLRequestCount,但僅統計分頁請求 | Int |
| SQLFailedRequestCountByCusErr | 由于客戶端問題而失敗的對 _sql API 的請求數 | Int |
| SQLFailedRequestCountBySysErr | 由于服務器問題或功能限制而失敗的對 _sql API 的請求數 | Int |
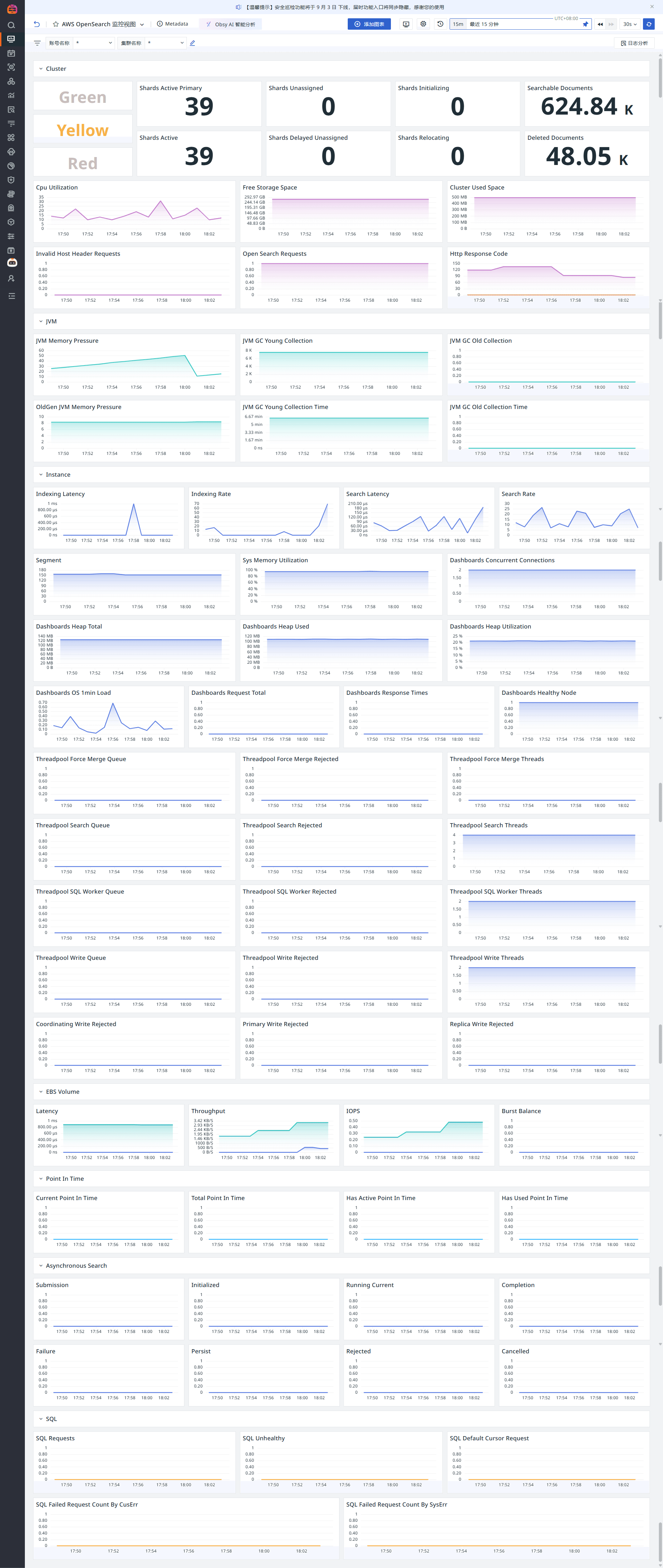
場景視圖
登錄觀測云控制臺,點擊「場景」 -「新建儀表板」,輸入 “opensearch”, 選擇 “AWS OpenSearch 監控視圖”,點擊 “確定” 即可添加視圖。
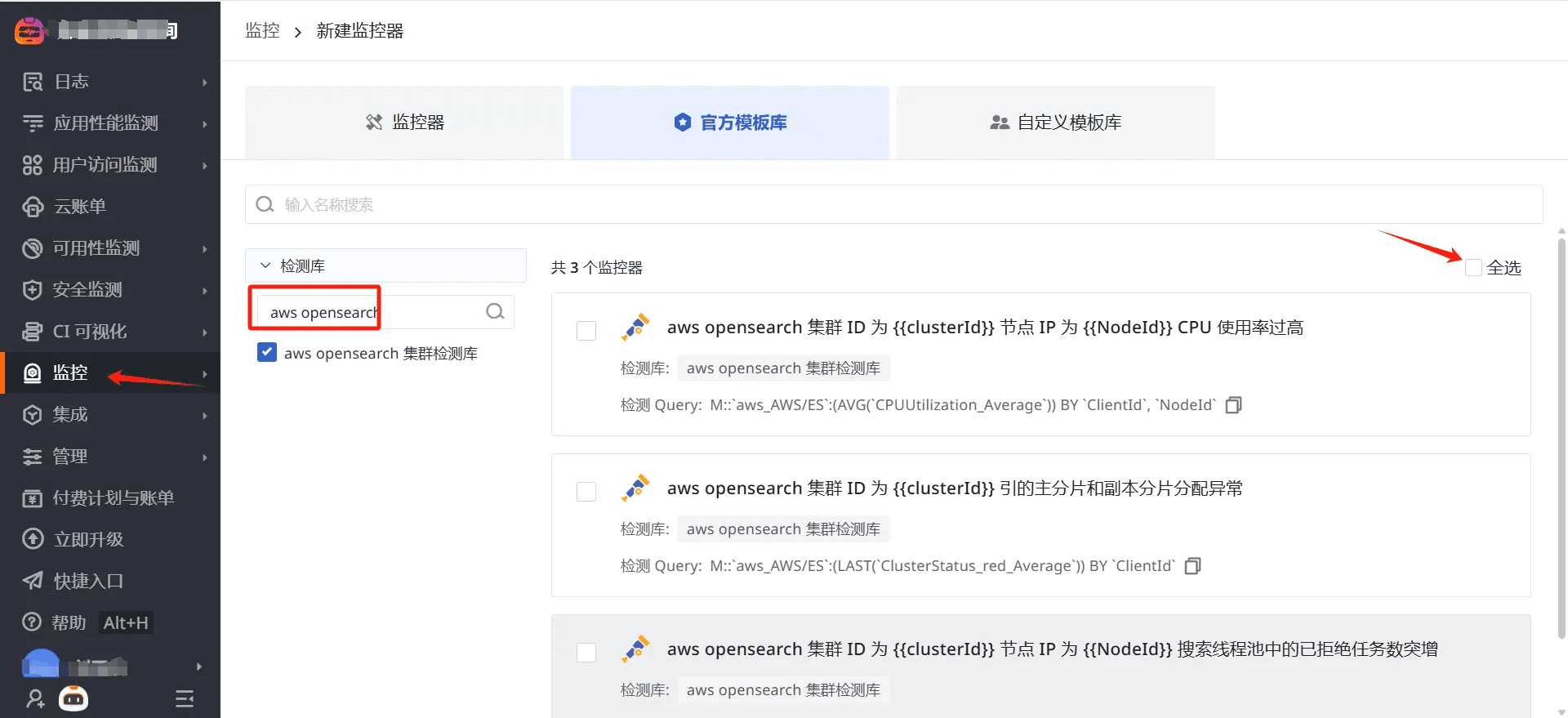
監控器(告警)
觀測云內置了監控器模板,可以選擇從模版創建監控器,并開啟適合業務的監控器以及時通知相關成員關注問題,觸發條件、頻率等信息可以依據實際業務進行調整。
登錄觀測云控制臺,點擊「監控」 -「新建監控器」,輸入 “aws opensearch”, 選擇對應的監控器,點擊 “確定” 即可添加。
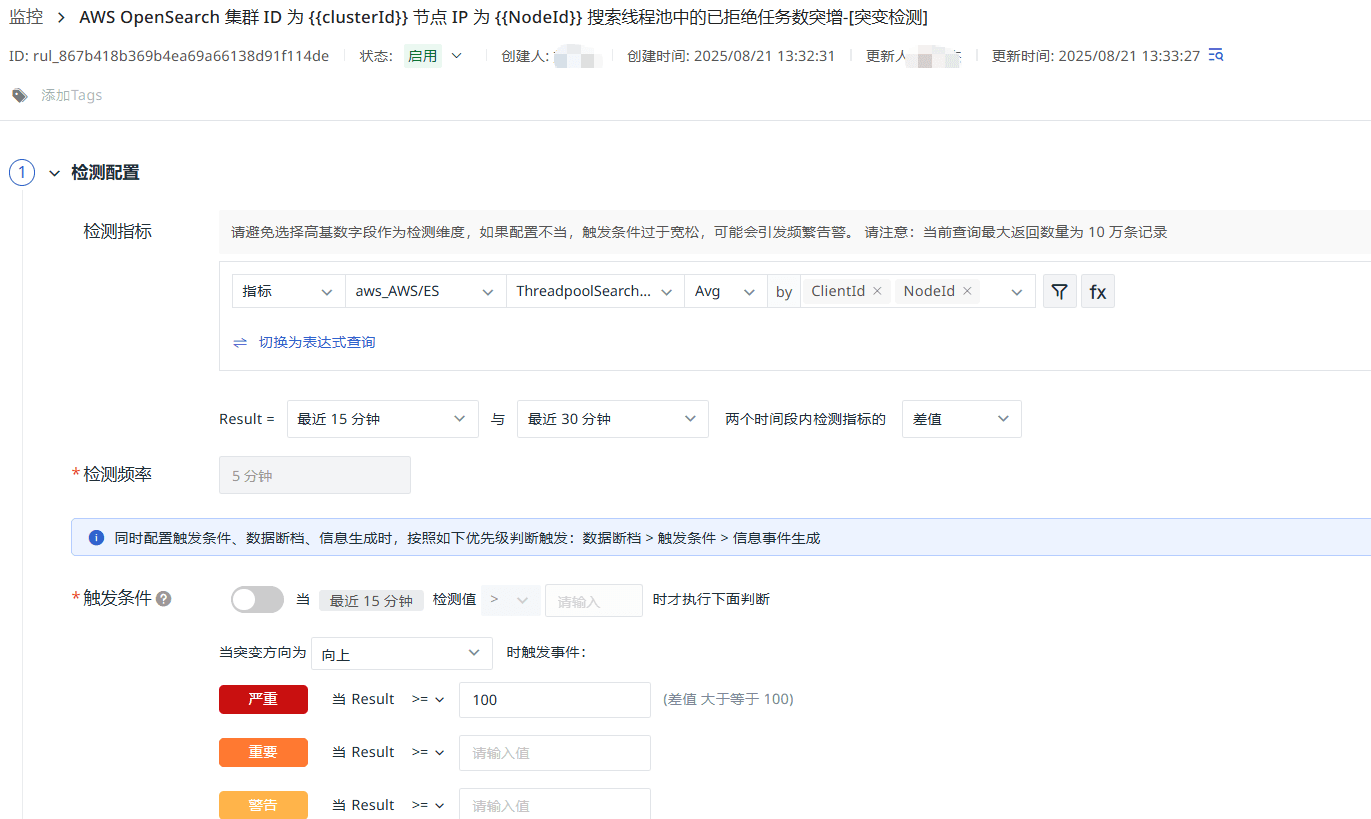
搜索線程池已拒絕任務數突增
ThreadpoolSearchRejected_Average:表示在一定時間內,OpenSearch 集群中搜索線程池中被拒絕的任務數量的平均值。該指標反映了搜索請求由于線程池隊列已滿而被拒絕的情況。最近 15 分鐘被拒絕數大于等于 100 時,發出嚴重告警。
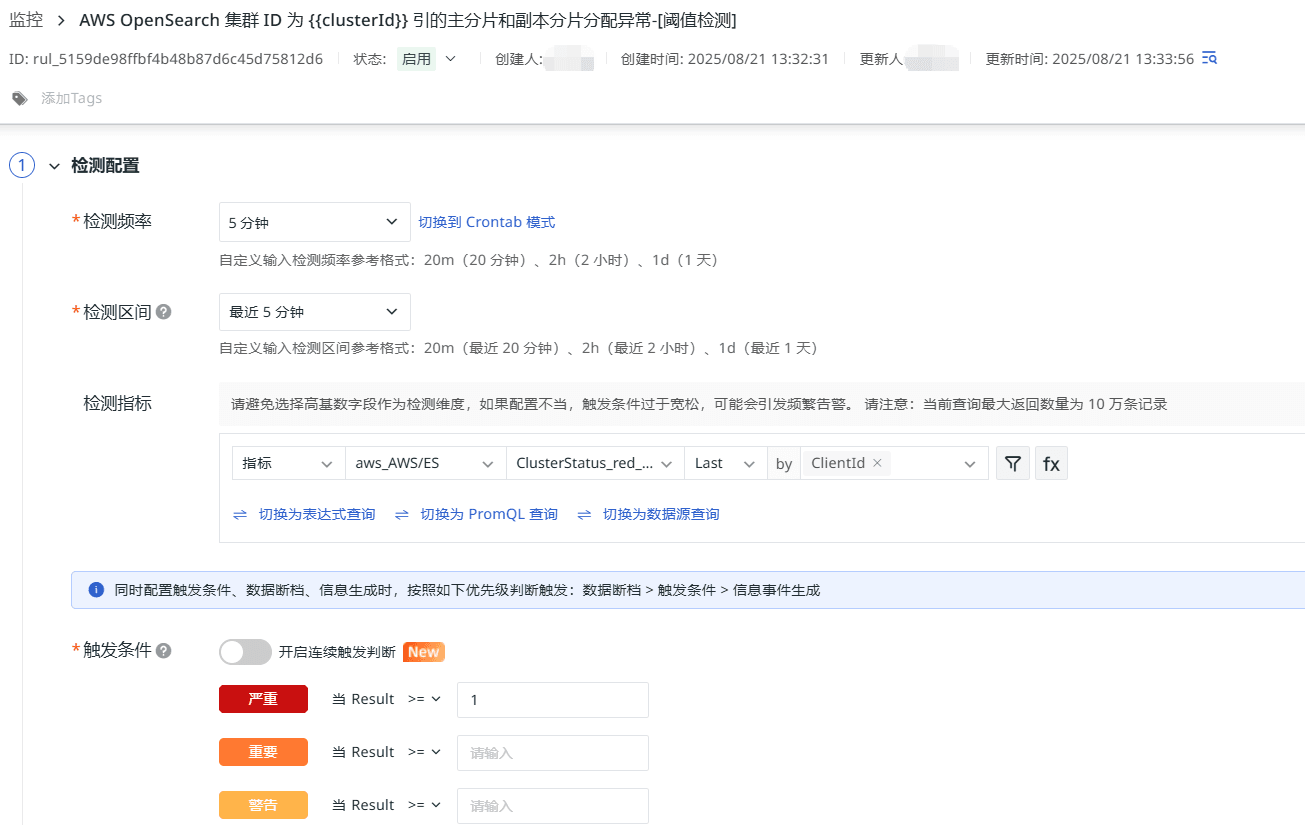
主分片和副分片分配異常
ClusterStatus_red_Average:表示 OpenSearch 集群處于紅色狀態的平均時間占比,紅色狀態意味著集群中至少有一個主分片及其副本未分配給任何節點,值為 0 表示集群運行正常,值大于 0 表示集群有部分時間處于紅色狀態。當集群完全處于紅色狀態時發出嚴重告警。
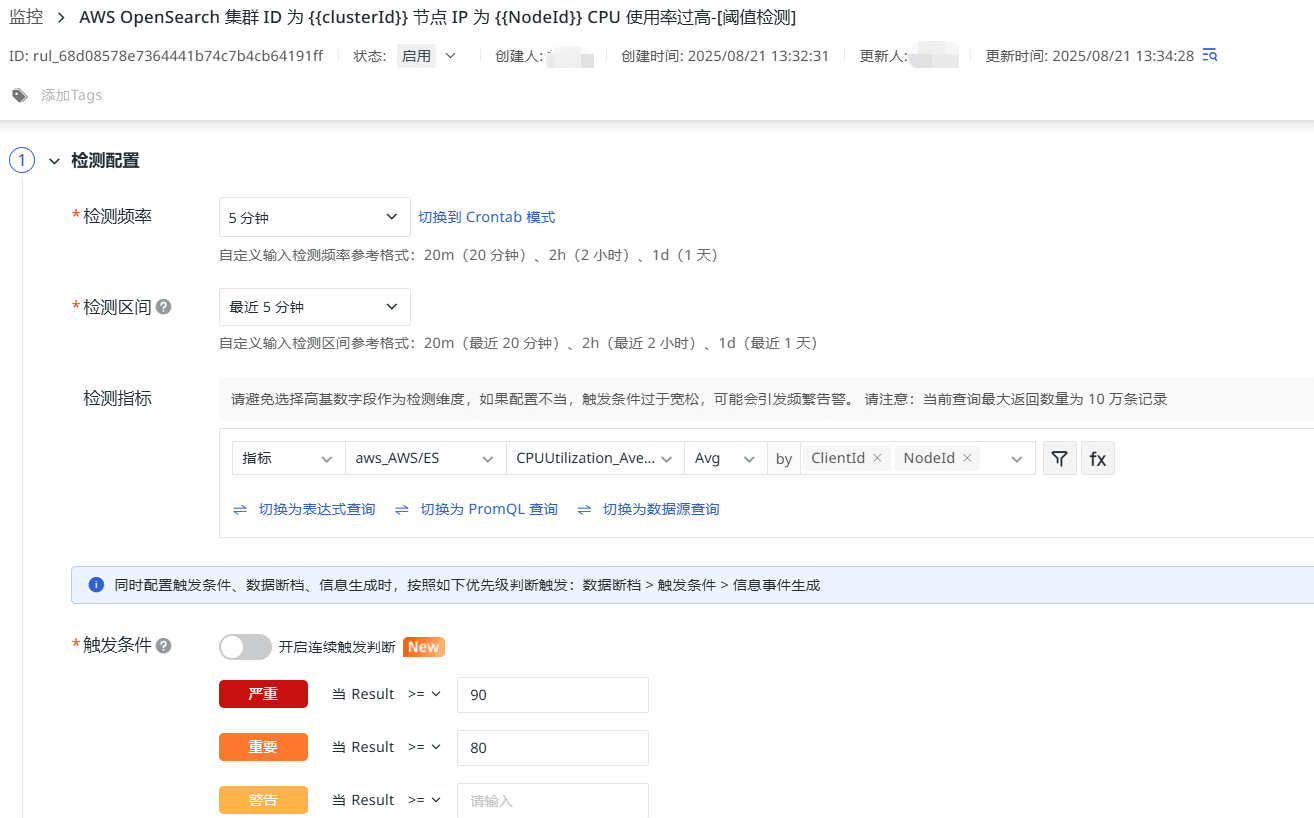
節點 CPU 使用率過高
CPUUtilization_Average 用于衡量 OpenSearch 集群中節點的平均 CPU 使用率,當節點的 CPU 使用率大于等于 90% 時,發出嚴重告警,當 CPU 使用率大于等于 80% 小于 90% 時,發出重要告警。
總結
通過將 AWS OpenSearch 的原生監控數據集成到觀測云平臺,用戶可以實現對 OpenSearch 的實時性能監控、資源使用分析以及安全事件的可視化。觀測云的高級分析和可視化功能,如實時儀表板、智能告警和根因分析,能夠幫助用戶快速定位問題、優化成本,并確保數據的高可用性和安全性。這種結合不僅提升了監控的效率和準確性,還通過集中管理的方式簡化了運維流程,使用戶能夠更好地應對復雜的云環境挑戰。




)




)
:等價類和判定表)
![week5-[二維數組]翻轉](http://pic.xiahunao.cn/week5-[二維數組]翻轉)



Python異步爬蟲與K8S彈性伸縮:構建百萬級并發數據采集引擎)



