1. 緒論
1.1. 程序的執行與狀態機
在計算機科學中,任何程序都可以被抽象為一個狀態機,無論是我們熟知的日常工具(LibreOffice,Chrome)還是開發工具(IDE,GCC,GDB),它們本質沒有任何區別。
- 程序狀態?= 處理器狀態(寄存器值)+?內存狀態?+?操作系統狀態(文件描述符、信號處理等
- 每次 CPU 執行一條指令 = 狀態機的一次遷移
程序的執行過程本質上是狀態的不斷變化。具體而言:
- 狀態由以下兩部分組成:
- 變量數值:包括全局變量和局部變量的值。
- 棧:程序執行過程中函數調用的上下文信息。
- 初始狀態:當程序啟動時,初始狀態由?
main?函數的第一條語句決定。此時,棧中僅包含一個?StackFrame,表示?main?函數的初始調用,全局變量也被初始化為預設的初始值。
--- 程序通過操作系統的?execve?系統調用被加載到內存中,并初始化為一個獨立的進程。
- 狀態遷移:程序的執行可以看作是由一條條語句驅動的狀態遷移。每一步執行都會導致狀態的變化,例如變量值的更新或棧的修改。
--- 程序在內存中運行,經歷一系列的狀態遷移,完成計算任務,并通過系統調用與操作系統交互(如文件操作、進程管理、存儲管理等)。程序通過調用?exit?或?exit_group?系統調用終止執行,操作系統回收其占用的資源。
---?model checking?可以在給定一個系統和一個我們希望它擁有的性質的前提下,model checking 算法會探索這個系統的每個狀態,驗證系統是否滿足這個性質。舉個例子:如果我們希望系統滿足“無死鎖”這個性質,那么 model checking 算法就會遍歷系統的每個狀態。如果它發現存在一個從初始狀態可達的狀態沒有后繼狀態,那么它就找到了系統不滿足“無死鎖”的證據,然后給用戶報錯,否則它就可以告訴我們,這個系統確實是滿足“無死鎖”這個性質的。
一個直觀的狀態機遷移:
int main() {int sum = 0;for (int i = 0; i < 1000000; i++) { // 用戶態循環sum += i; // 用戶態加法}printf(「Sum: %d\n」, sum); // 庫函數(內部含系統調用)return 0;
}在這個程序中:
- 執行了約?200 萬條?用戶態指令(循環+加法)
- 只發生了?1-2 次?系統調用(通過?
printf?的?write?系統調用)
用戶態執行
┌───────────────────────┐ 系統調用入口
│ 指令 1: mov eax, 0 │ │
│ 指令 2: add ebx, ecx │ ▼
│ 指令 3: cmp edx, 100 │ ┌───────────┐
│ ... (百萬條指令) │ │ 內核態執行 │
│ │ │ sys_read │
│ 指令 N: call printf ├─────?│ sys_write │
└───────────────────────┘ └───────────┘▲ ││ ▼└───────┘系統調用返回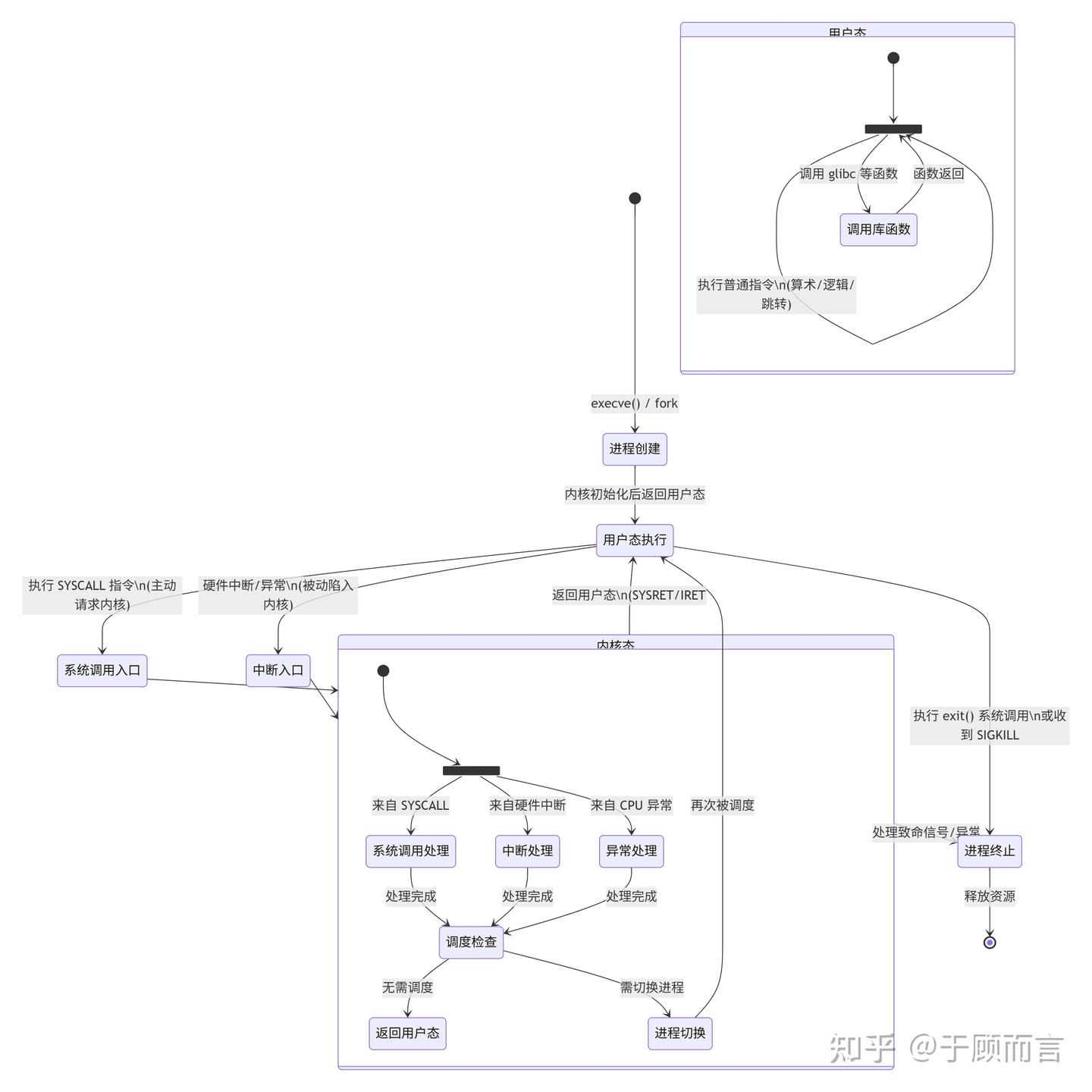
怎么獲得一個?Linux 進程的系統調用序列?
# 啟動新進程并跟蹤
strace <命令> [參數]
# 示例:跟蹤 `ls -l`
strace ls -l# 跟蹤已運行的進程(按 PID)
strace -p <PID>
# 示例:跟蹤 PID 為 1234 的進程
strace -p 1234# 常用選項:
strace -f # 跟蹤子進程(適用于多進程程序)
strace -o log.txt # 將輸出保存到文件(避免刷屏)
strace -T # 顯示系統調用耗時
strace -s 1024 # 顯示更長的參數內容(默認只顯示 32 字節)
strace -e trace=<類別> # 只跟蹤特定系統調用(如文件操作:`-e trace=file`)系統調用指令
進程管理: fork, execve, exit, waitpid, getpid, ...
操作系統對象和訪問: open, close, read, write, pipe, mount, mkfifo, mknod, stat, socket, ...
地址空間管理: mmap, sbrk (mmap 的前身)
以及一些其他的機制: pivot_root, chmod, chown, ..1.2. 如何證明程序的正確性
狀態機是一個具有嚴格數學定義的概念。這意味著我們可以用形式化的方法來描述和分析程序的行為。這種形式化的方法為程序的正確性驗證和優化提供了理論基礎。
Curry-Howard Correspondence:
- 命題即類型:邏輯中的命題 (如 A→B→A→B) 對應函數類型 A→B→A→B。
- 證明即程序:命題的構造性證明過程對應該類型的一個具體程序(例如,一個實現 A→BA→B?的函數即為 “AA?蘊含 BB” 的證明)。
邏輯中的蘊含消除規則對應函數調用:若有一個類型為 A→BA→B?的函數 (證明),且輸入類型 AA?的值 (前提),則輸出類型 BB?的值 (結論)。而對于一階謂詞,例如 ?x.P(x)?x.P(x),就必須提供一個 xx?的實例,這構成了基于構造的 “直覺邏輯” 的基礎
1.3. 操作系統的最大職責
操作系統的最大職責是為程序提供一個透明的運行環境。從程序的角度來看,它似乎“獨占”了整個計算機的資源,并按順序執行每一條指令。然而,實際情況并非如此:操作系統在后臺持續運行,管理著硬件資源、進程調度、文件操作等復雜任務。
當程序執行系統調用(如?read、write、fork?等)時,程序的執行會被暫時掛起,而操作系統接管控制權,完成相應的任務(如與硬件交互或管理進程)。完成任務后,操作系統會將控制權交還給程序,使其繼續執行。對于程序而言,這一過程是完全透明的,程序不會感知到時間的流逝或操作系統的干預。
一個最基本的 Unix 模型應該包含:
- 進程
- 系統調用
- 上下文切換
- 調度
1.4. 程序與操作系統的溝通橋梁
程序與操作系統之間的唯一通信橋梁是系統調用。系統調用是操作系統提供給程序的一組接口,允許程序請求操作系統完成特定任務(如文件讀寫、進程創建等)。例如,在 x86-64 架構中,程序可以通過?syscall?指令發起系統調用。
系統調用的重要性體現在以下幾個方面:
- 橋梁作用:系統調用是程序與操作系統之間的接口,沒有它,程序無法與外界進行交互。
- 安全性:系統調用提供了一種安全的機制,確保程序無法直接訪問硬件資源,從而保護系統的穩定性和安全性。
操作系統提供了許多工具(如?strace)來分析和調試程序的系統調用行為,幫助開發者理解程序的運行機制。
2. 虛擬化
2.1. 進程和程序
程序是狀態機的靜態描述,它描述了所有可能的程序狀態,程序 (動態) 運行起來,就成了進程 (進行中的程序)。
操作系統作為進程(狀態機)的管理者,一個直觀的想法就如同 Windows api 一樣,spawn 用來創建狀態機,exit 用來銷毀狀態機,但 Unix 的答案是 fork 用來復制狀態機,execve 用來復位狀態機。
fork 的行為:
立即復制狀態機,包括所有狀態的完整拷貝,寄存器 & 每一個字節的內存,新創建進程返回 0,執行 fork 的進程返回子進程的進程號——“父子關系”。
Tips:
創建一棵層的進程樹(A->B->C),并隨機退出其中的一些進程——我們可以觀察進程退出前后父子進程的關系。
----父進程(B)終止后,子進程(C)成為“孤兒”,操作系統內核(而非用戶進程)負責回收終止進程的資源,并重置其子進程的父進程。這一機制確保所有進程最終都有有效的父進程,避免資源泄露。
int pid = fork();
if (pid == -1) { // 錯誤perror(「fork」); goto fail;
} else if (pid == 0) { // 子進程execve(...);perror(「execve」); exit(EXIT_FAILURE);
} else { // 父進程...int status;waitpid(pid, &status, 0); // testkit.C 中有
}2.2. 進程地址空間
我們可以使用?pmap?查看某個進程的地址空間,pmap?命令通過讀取?/proc/[pid]/maps?和?/proc/[pid]/smaps?文件來獲取進程的內存映射信息。Linux 內核將這些信息以文本形式暴露在?/proc?文件系統中,pmap?通過解析這些文件實現功能,而無需直接調用特定的系統調用。
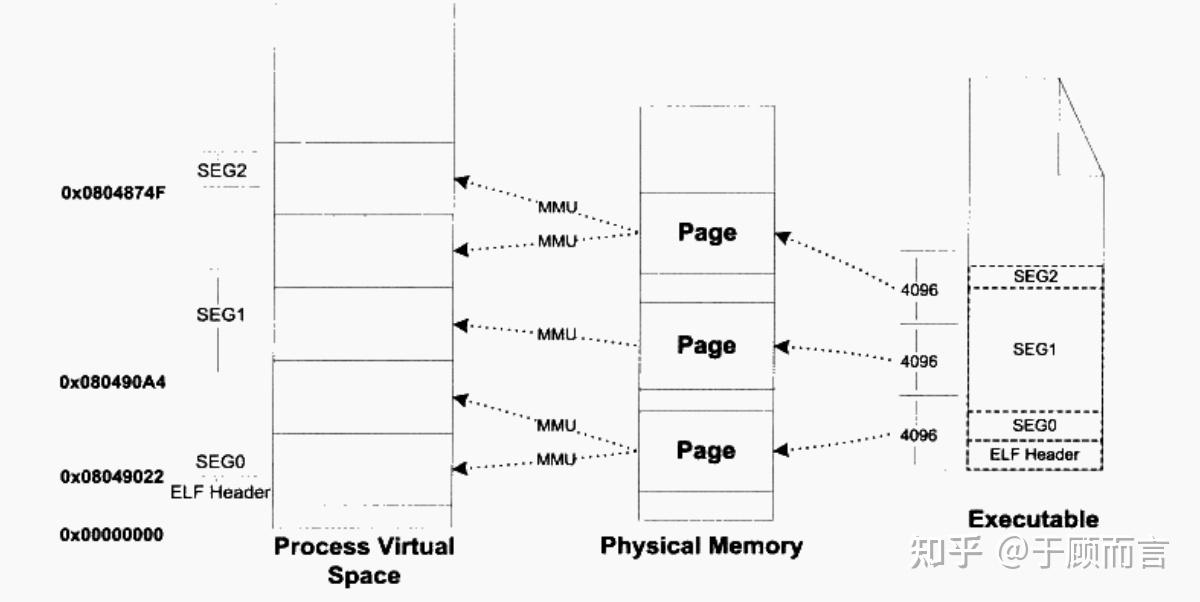
進程創建開始時,有一個初始狀態,System V ABI?規定了部分寄存器和棧,Binary 中指定的 PT_LOAD 段,內存分為一段一段,每一段有訪問權限。
區域地址范圍用途內核空間?0xC0000000~0xFFFFFFFF 操作系統內核代碼和數據(所有進程共享)棧(Stack)向下增長存儲局部變量、函數調用信息(如返回地址、參數)堆(Heap)向上增長動態內存分配(malloc/free)共享庫映射區固定存放動態鏈接庫(如
| 區域 | 地址范圍 | 用途 |
| 內核空間 | 0xC0000000~0xFFFFFFFF | 操作系統內核代碼和數據(所有進程共享) |
| 棧(Stack) | 向下增長 | 存儲局部變量、函數調用信息(如返回地址、參數) |
| 堆(Heap) | 向上增長 | 動態內存分配(malloc/free) |
| 共享庫映射區 | 固定 | 存放動態鏈接庫(如libc.so),多個進程可共享同一份代碼。文件映射,匿名映射 |
| 數據段(Data) | 固定 | 存放全局變量、靜態變量 |
| 代碼段(Text) | 固定 | 存放可執行指令(只讀) |
libc.so),多個進程可共享同一份代碼。
現代 OS 的主流方式,將地址空間劃分為固定大小的頁(Page,通常 4KB),物理內存劃分為頁幀(Page Frame)。
- 頁表(Page Table)?負責虛擬地址→物理地址的映射:
- 多級頁表(如 x86-64 采用 4 級頁表:PML4→PDP→PD→PT)。
- TLB(快表):緩存常用頁表項,加速地址轉換。
- 缺頁異常(Page Fault):
- 訪問未映射的頁時觸發,OS 可能從磁盤(Swap 分區)加載數據。
進程的初始狀態:
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
- able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
-
名稱 狀態 特殊寄存器 (浮點單元狀態) 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 rFLAGS 寄存器 DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 堆棧狀態 High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses 線程狀態 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。
able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
M,?UM,?OM,?ZM,?DM,?IM=1: 所有的浮點異常處于屏蔽 (Masked)?狀態。這意味著如果發生這些錯誤,FPU 會自動處理
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
rFLAGS 寄存器
able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">able?data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">ZF=0: 沒有結果為 0
的比較(相當于還沒開始比較)。名稱 狀態 特殊寄存器 (浮點單元狀態) 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 rFLAGS 寄存器 DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 堆棧狀態 High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses 線程狀態 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 SF=0: 結果是非負數(或者理解為結果的高位不是
1)。名稱 狀態 特殊寄存器 (浮點單元狀態) 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 rFLAGS 寄存器 DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 堆棧狀態 High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses 線程狀態 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 able data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
le data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
| 名稱 | 狀態 |
| 特殊寄存器 (浮點單元狀態) | 所有錯誤狀態標志都清零控制字設置 :RC=0: 默認的舍入方式:四舍五入PC=11: 默認使用最高的 雙擴展精度M, UM, OM, ZM, DM, IM=1: 所有的浮點異常處于屏蔽 (Masked) 狀態。這意味著如果發生這些錯誤,FPU 會自動處理 |
| rFLAGS 寄存器 | DF=0: 方向標志向前(很多內存操作會向高地址增長)。CF=0: 沒有進位/借位發生(就像剛重置了計算器)。PF, AF=0: 沒有特定的奇偶校驗位或半字節進位標志被設置(可以忽略)。ZF=0: 沒有結果為0的比較(相當于還沒開始比較)。SF=0: 結果是非負數(或者理解為結果的高位不是1)。OF=0: 沒有發生有符號數的溢出(計算結果沒有超出范圍)。 |
| 堆棧狀態 | High Addresses ... ...Auxiliary vector entries ... 0 Environment pointers ... 8+8*argc+%rsp 0 8+%rsp 參數數組 %rsp 參數個數 --- 它指向當前棧頂... ... Low Addresses |
| 線程狀態 | 這個新線程會繼承父線程當前的所有浮點單元狀態在此之后,新線程的浮點狀態就是其私有 (private) 的了。任何修改(例如更改舍入模式或屏蔽位)只影響該線程自身,不會影響父線程或其他線程。 |
?
輔助向量 (Auxiliary Vector)
操作系統通過這個表向新進程傳遞一些關鍵的系統信息或運行時參數。這些信息對于程序正常啟動、動態鏈接器 (ld-Linux) 工作等都至關重要。
| 類型名稱 (a_type) | 值 (Value) | 信息內容 (a_un) | 含義解釋 |
| AT_NULL | 0 | ignored | 輔助向量的結束標記! 遇到這個類型,表示后面沒有有效條目了,輔助向量結束。 |
| AT_IGNORE | 1 | ignored | 忽略此條目。 這個條目沒有意義,里面的值(a_un)也不用管。 |
| AT_EXECFD | 2 | a_val (整數值) | 解釋器程序可用的文件描述符。 如果程序需要一個解釋器(如 ld-linux,負責動態鏈接),系統可能會將這個文件描述符傳給解釋器,解釋器可以用它來直接讀取真正要運行的程序文件(比如你的 ./myprogram)。 |
| AT_PHDR | 3 | a_ptr (指針) | 程序在內存中的程序頭表 (Program Header Table) 位置。 如果系統已經把你的程序加載到內存里了,這個指針就指向 ELF 文件結構中程序頭表的起始地址。告訴解釋器(如果需要的話)去哪里找內存映射信息。 |
| AT_PHENT | 4 | a_val (整數值) | 每個程序頭表條目的大小 (字節)。 告訴解釋器上面提到的程序頭表(AT_PHDR)中,每個條目的長度是多少字節(通常是 sizeof(Elf64_Phdr) = 56 字節)。 |
| AT_PHNUM | 5 | a_val (整數值) | 程序頭表條目的個數。 告訴解釋器上面提到的程序頭表(AT_PHDR)里總共有多少個條目。 |
| AT_PAGESZ | 6 | a_val (整數值) | 系統內存分頁大小 (字節)。 告訴程序操作系統管理內存的基本單位有多大(比如 4KB = 4096 字節)。很多內存操作需要對齊到這個大小。 |
| AT_BASE | 7 | a_ptr (指針) | 解釋器程序自身在內存中的加載基地址。 如果程序是通過解釋器運行(如 ld-linux),這個指針指向解釋器自己代碼在內存里的起始地址。 |
| AT_FLAGS | 8 | a_val (位掩碼) | 解釋器相關的標志位 (位掩碼)。 給解釋器(如 ld-linux)使用的特定標志位組合。未定義的位是0。應用程序一般不需要關心。 |
| AT_ENTRY | 9 | a_ptr (函數指針) | 程序真正的入口地址 (Entry Point)。 指向程序可執行文件的入口點地址(在 ELF 文件中標記為 e_entry)。這是程序的代碼開始執行的地方(比如 _start 符號位置)。解釋器最終要把控制權交給這里。這是最重要的指針之一。 |
| AT_NOTELF | 10 | a_val (整數值) | 非 ELF 文件標志。 如果值 非0,就表示當前運行的程序 不是 標準的 ELF 格式文件(可能是其他格式如 a.out, PE等)。如果是 0,就是標準的 ELF 格式。 |
| AT_UID / AT_EUID / AT_GID / AT_EGID | 11 / 12 / 13 / 14 | a_val (整數值) | 用戶和組標識符。 AT_UID: 進程的實際用戶ID (啟動進程的用戶)。 AT_EUID: 進程的有效用戶ID (通常與 AT_UID 相同,或受 setuid 程序影響)。 AT_GID: 進程的實際組ID。 AT_EGID: 進程的有效組ID。 |
| AT_PLATFORM | 15 | a_ptr (字符串指針) | 硬件平臺標識字符串。 指向一個描述底層硬件平臺架構的字符串(例如 "x86_64")。 |
| AT_HWCAP | 16 | a_val (位掩碼) | CPU 硬件能力位掩碼。 一個整數值,其中的位代表 CPU 支持的特定擴展指令集或功能(例如 MMX, SSE, SSE2, AVX 等)。這個值對應于 CPUID 指令(功能號1)返回的 EDX 寄存器中的一部分特征位。 |
| AT_CLKTCK | 17 | a_val (整數值) | 系統時鐘節拍頻率 (clock tick)。 每秒有多少次 times() 函數會增加時鐘計數(通常是 100)。 |
| AT_SECURE | 23 | a_val (整數值) | 安全模式標志。 如果值是 1,表示程序是以提升權限模式啟動的(例如用戶執行了一個設置了 suid 或 sgid 位的程序)。值是 0 則表示沒有特殊權限。安全敏感的程序需要注意這個標志。 |
| AT_BASE_PLATFORM | 24 | a_ptr (字符串指針) | 基礎平臺標識字符串。 與 AT_PLATFORM 類似,但指向的字符串描述的是更基礎、更通用的平臺架構,可能與硬件平臺字符串不同(例如 AT_PLATFORM 是 "i686", AT_BASE_PLATFORM 可能是 "i386")。 |
| AT_RANDOM | 25 | a_ptr (指針) | 16字節安全隨機數 (Securely Generated Random Bytes)。 指向操作系統提供的、專門用于增強安全性的 16 字節隨機數據(通常由內核的安全隨機數生成器產生)。程序可以使用這個隨機數作為密鑰種子或 ASLR 的加強。 |
| AT_HWCAP2 | 26 | a_val (位掩碼) | 擴展 CPU 硬件能力位掩碼。 未來可用的額外 CPU 特性位掩碼(當前 AMD64 ABI 定義中該值為 0,保留給未來擴展)。可能對應 CPUID 后續指令或不同寄存器的特征位。 |
| AT_EXECFN | 31 | a_ptr (字符串指針) | 被執行的程序的文件名。 指向一個字符串,該字符串保存了用戶(或 shell)傳遞給 exec() 系列函數的原始程序路徑名(例如 "/usr/bin/ls" 或 "./hello")。與 argv[0] 不同,argv[0] 可能是修改過的(例如通過符號鏈接啟動),而 AT_EXECFN 通常指向實際被執行的文件路徑。 |
2.3. 地址空間管理
mmap 系統調用,可以在狀態機狀態上增加/刪除/修改一段可訪問的內存:
- MAP_ANONYMOUS: 匿名 (申請) 內存
- fd: 把文件 “搬到” 進程地址空間中 (例子:加載器)
ptrace/process_vm_writev,可以修改另一個進程的地址空間
ptrace?系統調用
通過?PTRACE_PEEKDATA?和?PTRACE_POKEDATA?請求讀寫目標進程內存。調試工具(如 GDB)即依賴此機制,但需附加到目標進程(可能暫停其執行)。process_vm_writev?系統調用
允許直接向目標進程寫入數據,效率高于?ptrace,且無需暫停目標進程。需要?CAP_SYS_PTRACE?能力或權限配置。
適用場景:
- 高效進程間通信:需要跨進程批量傳輸數據時(如共享內存的替代方案)
- 動態熱補丁:運行時修改目標進程的代碼/配置
- 調試/監控工具:注入代碼或修改內存狀態進行調試
- 性能敏感操作:相比?
ptrace?無需頻繁暫停目標進程,延遲更低
2.4. 一切皆文件
文件描述符是指向操作系統對象的 “指針”——系統調用通過這個指針 (fd) 確定進程希望訪問操作系統中的哪個對象。我們有 open, close, read/write, lseek, dup 管理文件描述符。
//openp = malloc(sizeof(FileDescriptor));
//closedelete(p);
//read/write*(p.data++);
//lseekp.data += offset;
//dupq = p;任何可以讀寫的東西都可以是文件,比如:
真實的設備
- /dev/sda
- /dev/tty
虛擬的設備 (文件)
- /dev/urandom (隨機數), /dev/null (黑洞), ...
- 它們并沒有實際的 “文件”
- 操作系統為它們實現了特別的 read 和 write 操作
- /drivers/char/mem.C
- 甚至可以通過 /sys/class/backlight 控制屏幕亮度
- procfs 也是用類似的方式實現的
優點
- 統一的編程模型
- 開發人員只需掌握?
open()/read()/write()/close()等少量 API - 例如:
echo 「hello」 > /dev/pts/0?直接寫入終端
- 強大的組合能力
- 管道操作:
ls | grep txt | sort | uniq - 流重定向:
program 2>&1 > log.txt
- 抽象層次清晰
- VFS 虛擬文件系統(Linux 核心組件)
- FUSE 框架允許用戶態文件系統實現
- 透明的資源訪問
/proc/pid/maps?查看進程內存映射/sys/class/net?管理網絡設備
缺點
- 文件操作需要用戶/內核態切換(昂貴)
- 網絡通信用文件 API 效率低下
- 額外的延遲和內存拷貝
- 單線程 I/O
解決方案
分層 API 架構,操作系統通過「內核基礎 API + 用戶態封裝」來解決這些矛盾:
Windows NT
┌───────────────────────┐
│ Win32 API │ ← 圖形/多媒體/COM 等高級接口
├───────────────────────┤
│ POSIX 子系統層 │ ← 翻譯 Unix API 調用,兼容層適配傳統抽象
├───────────────────────┤
│ NT 內核基礎 API │
│ (Objects, Handles) │ ← 微內核設計:進程/線程/虛擬內存等基本對象
└───────────────────────┘
WSL (Windows Subsystem for Linux)
┌───────────────────────┐
│ Linux 二進制 (ELF) │
├───────────────────────┤
│ lxss.sys (翻譯層) │ ← 轉換 Linux 系統調用→NT API
├───────────────────────┤
│ Windows NT 內核 │
└───────────────────────┘
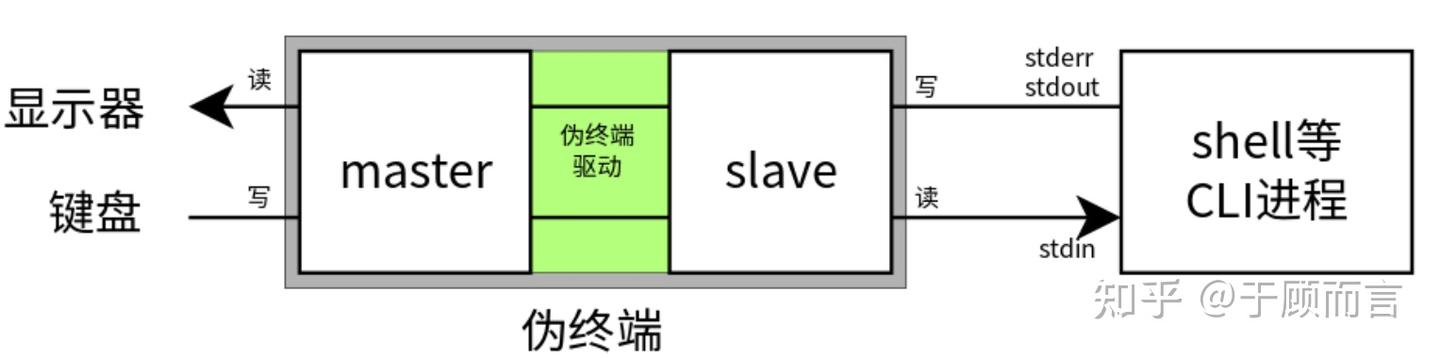
甚至連我們與電腦交互的終端也都是文件,pty:
偽終端(pseudo terminal,有時也被稱為 pty)是指偽終端 master 和偽終端 slave 這一對字符設備。其中的 slave 對應 /dev/pts/ 目錄下的一個文件,而 master 則在內存中標識為一個文件描述符(fd)。偽終端由終端模擬器提供,終端模擬器是一個運行在用戶態的應用程序。
Master 端是更接近用戶顯示器、鍵盤的一端,slave 端是在虛擬終端上運行的 CLI(Command Line Interface,命令行接口)程序。Linux 的偽終端驅動程序,會把 master 端(如鍵盤)寫入的數據轉發給 slave 端供程序輸入,把程序寫入 slave 端的數據轉發給 master 端供(顯示器驅動等)讀取。請參考下面的示意圖(此圖來自互聯網):
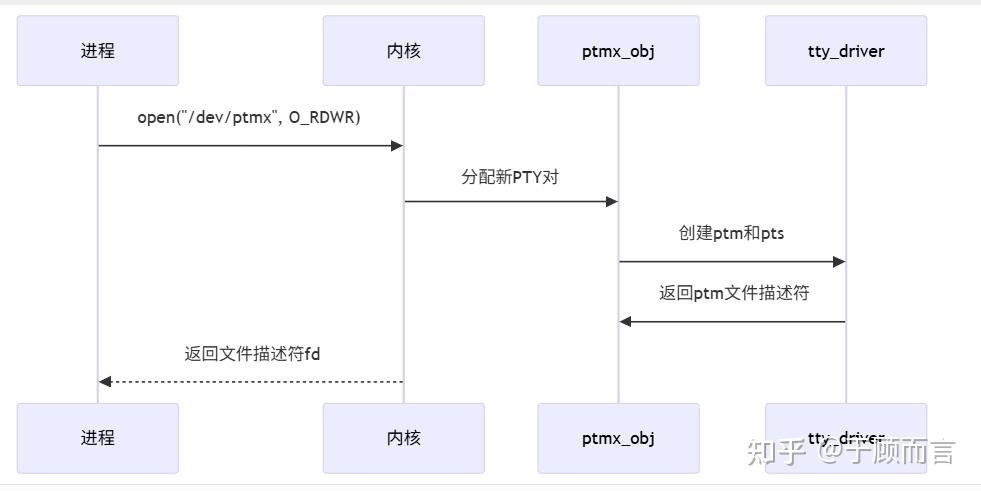
我們打開的終端桌面程序,比如 GNOME Terminal,其實是一種終端模擬軟件。當終端模擬軟件運行時,它通過打開 /dev/ptmx 文件創建了一個偽終端的 master 和 slave 對,并讓 shell 運行在 slave 端。當用戶在終端模擬軟件中按下鍵盤按鍵時,它產生字節流并寫入 master 中,shell 進程便可從 slave 中讀取輸入;shell 和它的子程序,將輸出內容寫入 slave 中,由終端模擬軟件負責將字符打印到窗口中。
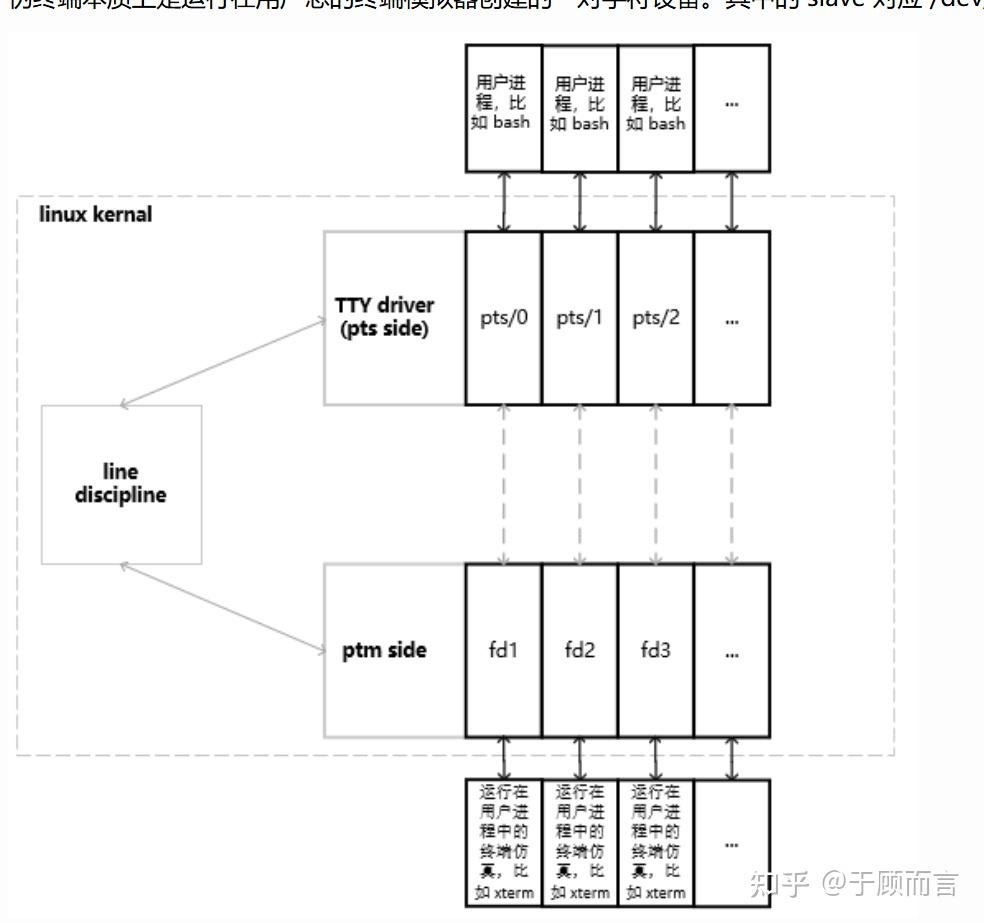
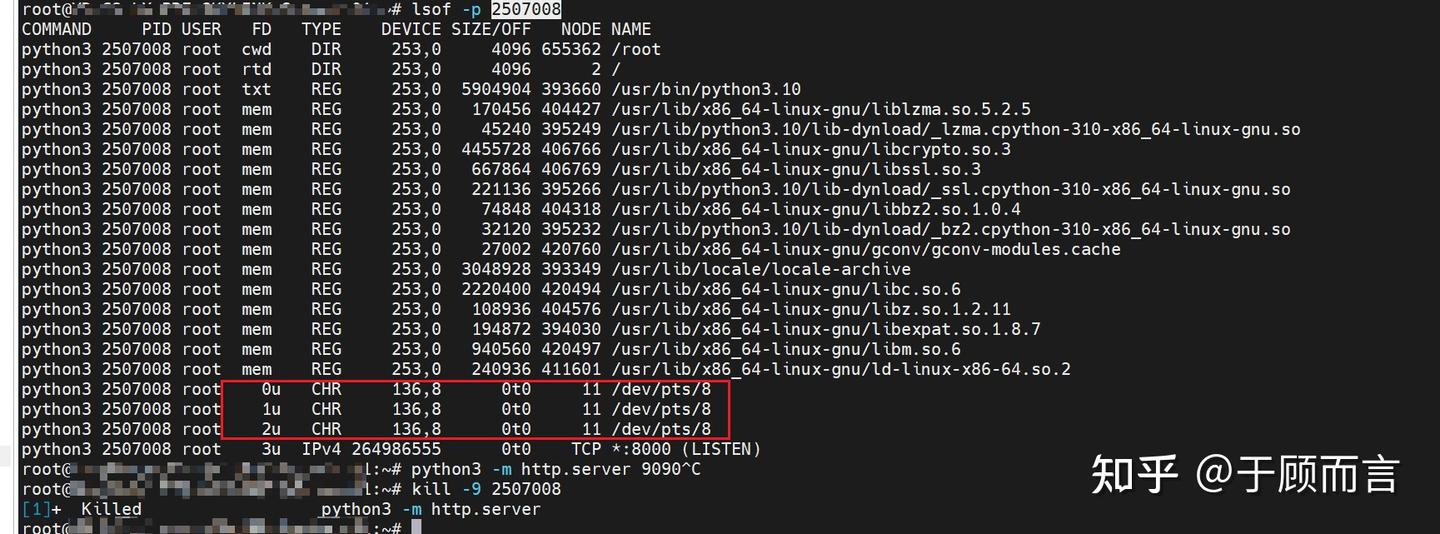

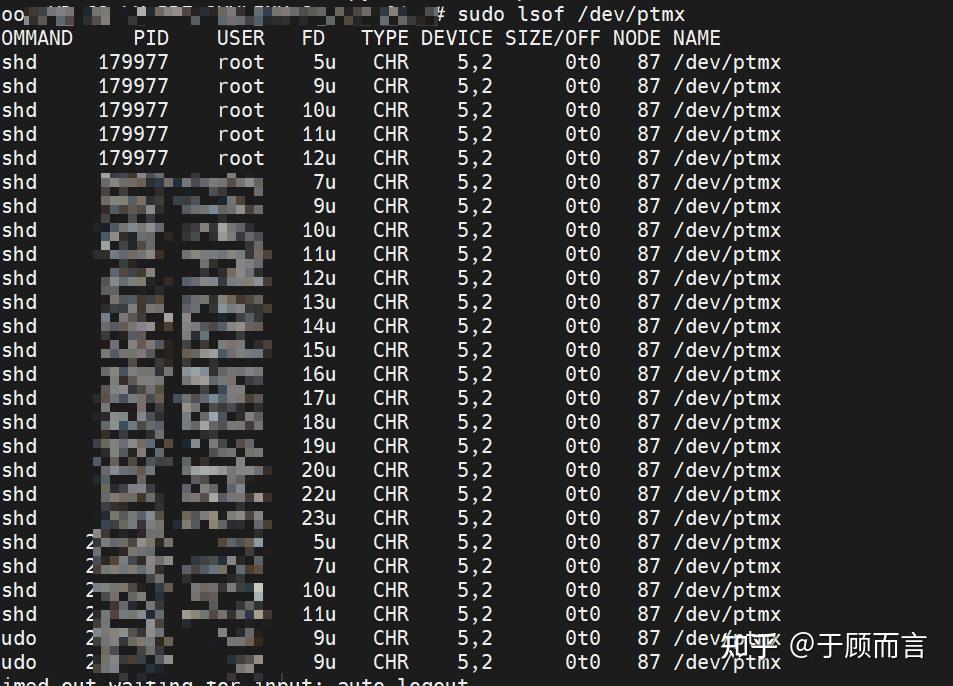
/dev/ptmx 是一個字符設備文件,當進程打開 /dev/ptmx 文件時,進程會同時獲得一個指向 pseudoterminal master(ptm)的文件描述符和一個在 /dev/pts 目錄中創建的 pseudoterminal slave(pts) 設備。通過打開 /dev/ptmx 文件獲得的每個文件描述符都是一個獨立的 ptm,它有自己關聯的 pts,ptmx(可以認為內存中有一個 ptmx 對象)在內部會維護該文件描述符和 pts 的對應關系,對這個文件描述符的讀寫都會被 ptmx 轉發到對應的 pts。我們可以通過 lsof 命令查看 ptmx 打開的文件描述符。
可以看到進程的 0u(標準輸入)、1u(標準輸出)、2u(標準錯誤輸出)都綁定到了偽終端 /dev/pts/8 上,這樣一來對這個文件描述符的讀寫都會被 ptmx 轉發到對應的 pts。
查看具體的關聯
# 查看偽終端主從設備
$ ps -ef | grep pts
user 5678 1234 0 10:00 pts/1 00:00:00 bash# 查看文件描述符指向
$ ls -l /proc/1234/fd/12
lrwx------ 1 user user 64 Jan 01 12:34 12 -> /dev/ptmx$ ls -l /dev/pts/1
crw--w---- 1 user tty 136, 1 Jan 01 10:00 /dev/pts/1完整數據流轉示例(以執行?ls -l?為例)
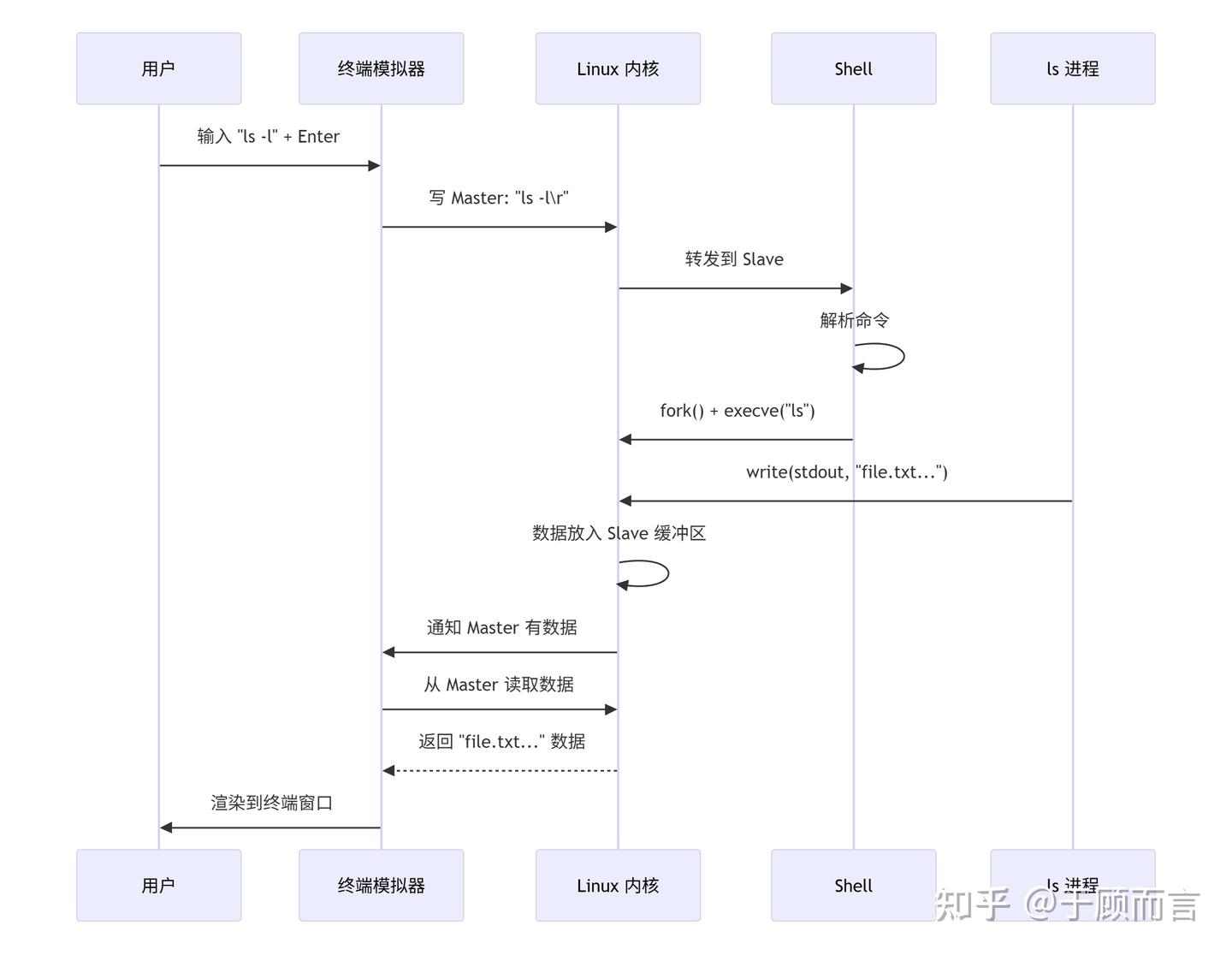
當我們對當前終端進行操作,或者運行程序時:
- 在同一個會話里,相關的進程會被放進同一個或不同的進程組。比如,你在 shell 里敲?
ls | grep txt &,這個管道命令里的?ls?和?grep?通常就在同一個新的后臺進程組里。而 shell 自己在另一個進程組。 - 為什么重要??信號(如?
Ctrl-C?產生的?SIGINT)通常是發給整個前臺進程組的!這就是為什么?Ctrl-C?能殺掉一個正在運行的復雜命令(比如包含管道的命令)里的所有相關進程。Ctrl-Z(發送?SIGTSTP?暫停信號)也是發給整個前臺進程組。
為什么我們需要 sigaction 替代 Unix 的信號機制?
- 跨平臺兼容性
- 易導致信號丟失
- 防止嵌套信號干擾
// 傳統 signal 的脆弱實現
void handler(int sig) {signal(SIGINT, handler); // 必須手動重新注冊// 處理邏輯
}
signal(SIGINT, handler);// 使用 sigaction 的可靠實現
struct sigaction sa;
sa.sa_handler = handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART; // 自動重啟系統調用
sigaction(SIGINT, &sa, NULL);2.5. 加載器和鏈接器
為了這一章,我直接看了一本書,寫的很好,相見恨晚:

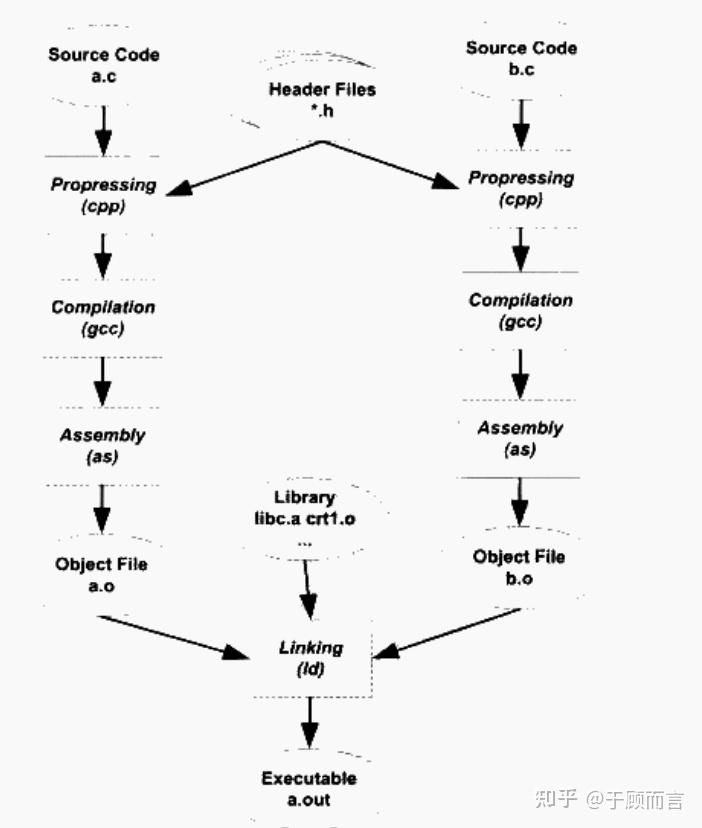
加載器:
- 在程序運行時激活。
- 核心任務:
- 內存映射:解析可執行文件格式(如 ELF),將代碼/數據段加載到虛擬內存的指定位置(如
.text?段只讀,.data?段可讀寫)。 - 動態鏈接:若程序依賴動態庫(如?
glibc),加載器調用動態鏈接器(ld-Linux.so)加載共享庫并解析符號地址(運行時完成)。 - 環境初始化:設置棧/堆空間,傳遞命令行參數,跳轉到程序入口點(如
_start)。
- 內存映射:解析可執行文件格式(如 ELF),將代碼/數據段加載到虛擬內存的指定位置(如
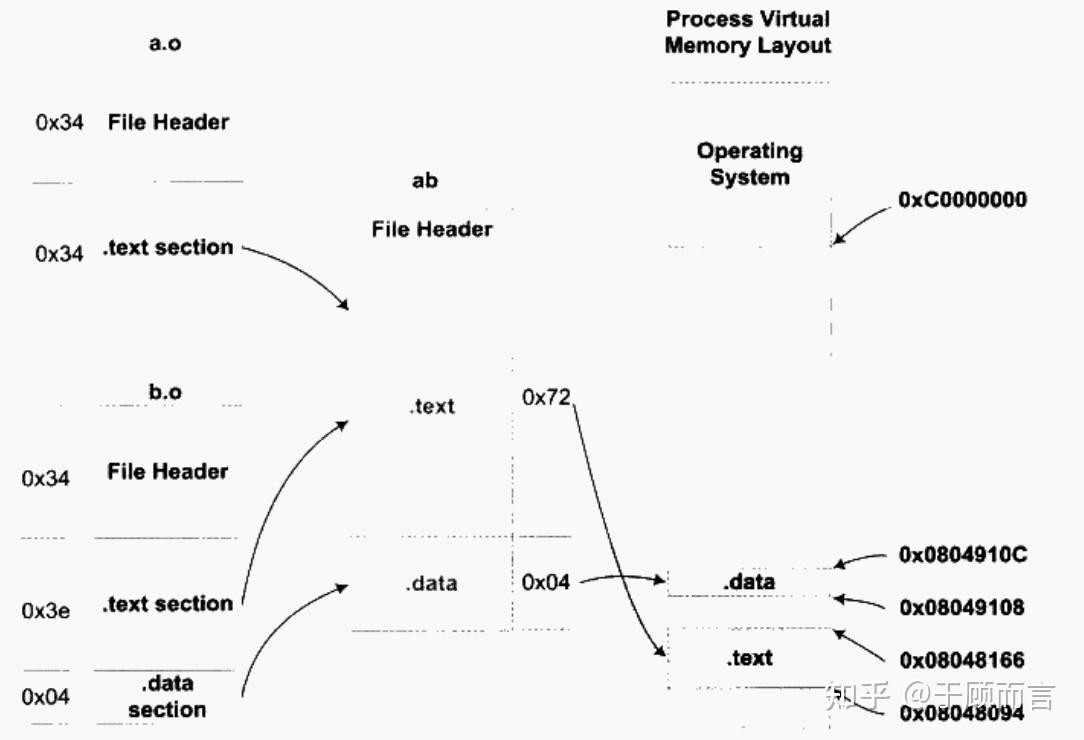
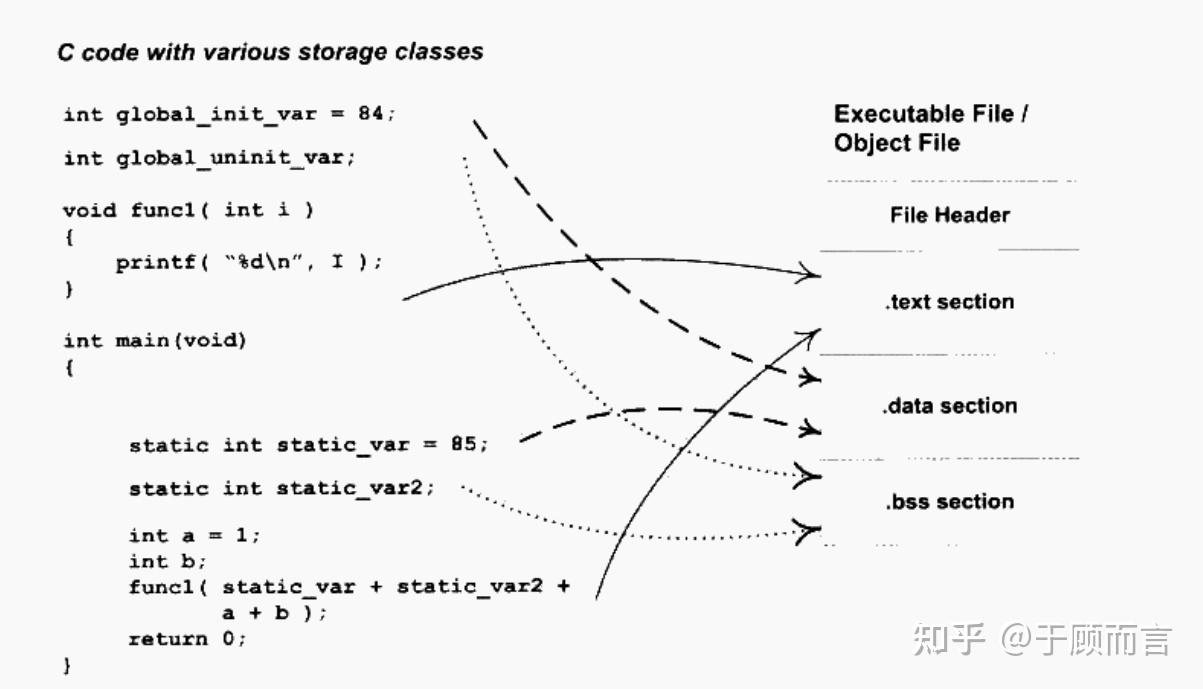
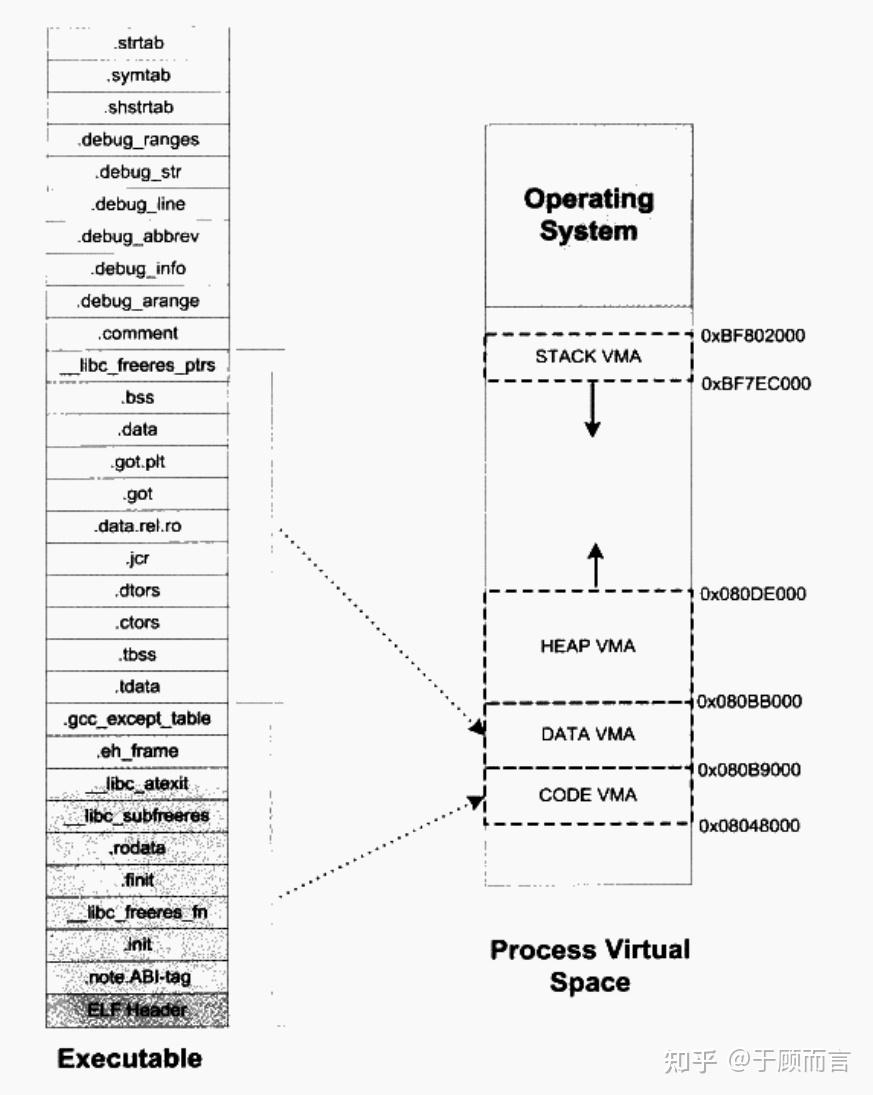

連接器:
- 程序構建階段(編譯后)的工具,由編譯器(如 GCC)調用。
- 核心任務:
- 符號解析:將不同目標文件(
.o/.obj)中的函數/變量引用與其定義匹配(例如,main.C?調用?printf()時,鏈接器在?libc.a?中查找其實現)。 - 重定位:為所有代碼段(
.text)、數據段(.data)分配內存地址,并修正代碼中的相對地址引用。 - 庫整合:將靜態庫(如
.a)代碼直接復制到可執行文件中,或記錄動態庫(如.so)的引用信息。
- 符號解析:將不同目標文件(
- 輸出:生成可執行文件(如 ELF 格式),包含完整的程序邏輯和元數據(符號表、重定位表)。
動態鏈接核心:
- 延遲綁定(Lazy Binding):
- 僅在函數首次調用時解析地址,減少程序啟動時的開銷。
- 未調用的函數不解析,節省內存和 CPU 資源。
- 位置無關代碼(PIC):
- GOT 存儲絕對地址,PLT 通過相對跳轉訪問 GOT,使共享庫可加載到任意內存地址。
- 讀寫分離:
- PLT(代碼段)只讀,GOT(數據段)可寫,符合現代操作系統的內存保護機制。
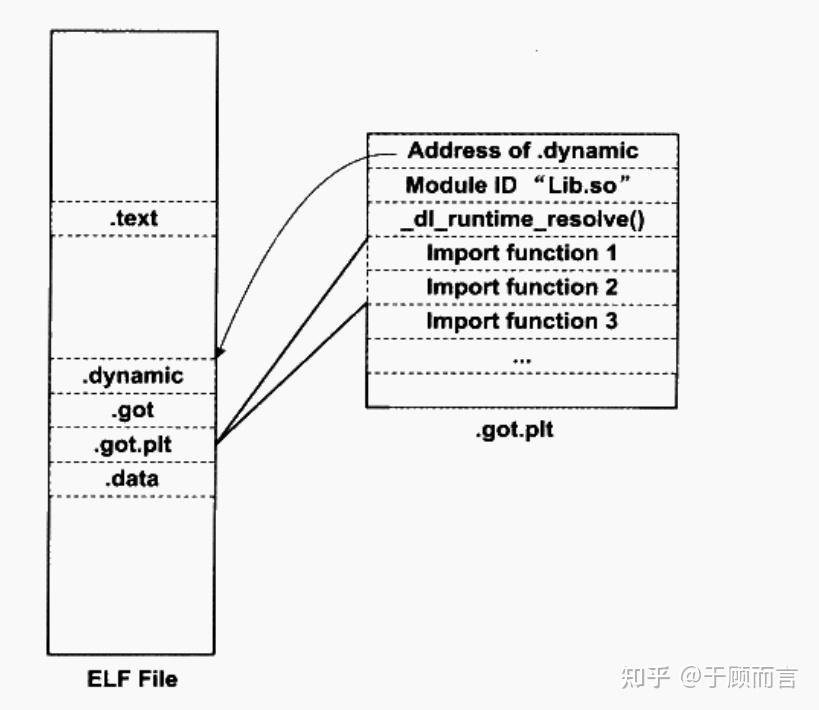
GOT(全局偏移表)
- 定位:位于數據段(
.got?或?.got.plt?節區),內容在運行時動態修改。 - 作用:
- 存儲外部符號(如共享庫函數、全局變量)的絕對地址。
- 首次調用函數時,由動態鏈接器(
ld-Linux.so)解析符號地址并填入 GOT。 - 后續調用直接通過 GOT 跳轉,避免重復解析。
- 結構:
GOT[0]:.dynamic?段的地址(動態鏈接元數據)。GOT[1]:link_map?結構指針(描述已加載共享庫的鏈表)。GOT[2]:_dl_runtime_resolve?函數地址(符號解析入口)。GOT[3..n]:存儲實際函數地址(如?printf、scanf)。
PLT(過程鏈接表)
- 定位:位于代碼段(
.plt?節區),內容在編譯后固定不變。 - 作用:
- 作為跳轉到外部函數的代理代碼,首次調用時觸發地址解析。
- 通過間接跳轉(
jmp *GOT[n])實現延遲綁定。
- 結構:
PLT[0]:公共樁代碼,調用?GOT[2](_dl_runtime_resolve)。PLT[1..n]:每個外部函數對應一項,包含:jmp *GOT[n](首次指向 PLT 內部的?push?指令)。push 序號(符號在重定位表中的索引)。jmp PLT[0](觸發解析流程)。
| 步驟 | 行為 |
| ① | 程序調用 call printf@plt(跳轉到 PLT[n])。 |
| ② | PLT[n] 執行 jmp *GOT[n],此時 GOT[n] 指向 PLT[n] 的第二條指令(push 序號)。 |
| ③ | 執行 push 序號(壓入符號索引),再 jmp PLT[0]。 |
| ④ | PLT[0] 將 GOT[1](link_map)壓棧,跳轉至 GOT[2](_dl_runtime_resolve)。 |
| ⑤ | _dl_runtime_resolve 解析符號地址,寫入 GOT[n],跳轉到目標函數。 |
| 結果:符號地址被緩存至GOT,后續調用直接跳轉。 | call printf@plt → jmp *GOT[n] → 直接跳轉至目標函數地址(無需解析)。 |
3. 并發
我們可以很容易地把狀態機模型擴展為共享內存上的多線程模型——只是每次選擇一個狀態機執行一步,通過提供 spawn 和 join 兩個 API 來利用現有多處理器系統的共享內存能力。
然而,由于編譯優化的 “無處不在” (處理器也是編譯器),共享內存并發的行為十分復雜。與此同時,人類又恰好是物理世界 (宏觀時間) 中的 “sequential creature”,編程語言的直覺 (順序/選擇/循環結構) 也是圍繞順序程序設計,因此共享內存上的并發編程是非常具有挑戰性的 “底層技術”。
互斥:別的我沒學會,一把大刀保平安,我用的可熟了

我們希望控制事件發生的先后順序,比如 A->B->C,互斥鎖只是確保分開 A,B,C,但做不到順序控制,這里邊得需要同步。
// 萬能消費者生產者公式
// 想清楚生產/消費的條件是什么?void fish_before(char ch) {mutex_lock(&lk);while (!can_print(ch)) {cond_wait(&cv, &lk);}quota--;mutex_unlock(&lk);
}void fish_after(char ch) {mutex_lock(&lk);quota++;current = next(ch);assert(current);cond_broadcast(&cv);mutex_unlock(&lk);
}如何避免死鎖?
Lock ordering1. 任意時刻系統中的鎖都是有限的2. 給所有鎖編號 (Lock Ordering)3. 嚴格按照從小到大的順序獲得鎖
任意時刻,總有一個線程獲得 “編號最大” 的鎖,這個線程總是可以繼續運行,因為他已經有了所有需要的小鎖# 例子
假設 5 個哲學家(線程)和 5 把筷子(鎖),編號為 1~5。規則要求:哲學家必須先拿編號小的筷子,再拿編號大的筷子(如必須先拿 3 號筷才能拿 4 號筷)。運行過程:哲學家 A 拿起筷子 1 和 2(鎖 1、2),哲學家 B 拿起筷子 1 和 3(鎖 1、3)。
此時系統中最大編號為 3(被哲學家 B 持有)。
哲學家 B 無需等待更大編號的鎖(已持有所有小于 3 的鎖),可吃完后釋放鎖 1 和 3。
釋放后,其他哲學家(如等待鎖 3 的哲學家 C)可繼續獲取鎖 3 并推進任務。Do not communicate by sharing memory; instead, share memory by communicating.
——Effective Go
4. 持久化
4.1. 設備和驅動程序
我們拿優盤插到電腦中,然后就看了這個盤符,我們可以進去查看文件和拷貝文件,這里面發生了什么?
其實,這里面用到了?udev?技術,監聽內核發出的設備事件(如插入、拔出、狀態變化),在 Linux 系統中用戶空間(Userspace)的動態設備管理?/dev?目錄下的設備文件。
關鍵流程如下:
- 當設備插入、移除或狀態變化時,比如優盤,內核識別設備然后加載對應的 USB 驅動(如?
usb-storage),udev 依賴驅動已成功加載,否則無法獲取設備信息,驅動程序工作在內核空間(Kernel Space),直接與硬件交互,比如聲卡驅動將音頻數據轉換為電信號驅動揚聲器發聲 - 內核通過?
netlink?套接字發送?uevent?事件(包含設備路徑、子系統類型、屬性等元數據) udevd?守護進程(用戶空間)監聽?uevent,解析事件內容并匹配預定義的規則udevd?讀取?/etc/udev/rules.d/?和?/lib/udev/rules.d/?下的規則文件,按文件名數字優先級升序執行匹配
# /etc/udev/rules.d/99-usb.rules
SUBSYSTEM==「block」, KERNEL==「sd*」, ATTRS{idVendor}==「0781」, ATTRS{idSerial}==「A1B2C3D4」, SYMLINK+=「backup_disk」, MODE=「0660」, GROUP=「storage」匹配鍵(條件):
SUBSYSTEM(設備類型)、KERNEL(內核設備名)、ATTRS{...}(/sys 中的設備屬性,如廠商 ID)操作鍵(動作):
SYMLINK(創建軟鏈接)、MODE(權限)、GROUP(歸屬組)、RUN(執行腳本)- 根據規則匹配結果執行操作:
- 命名控制:自定義設備名(如將 USB 磁盤固定為?
/dev/backup_disk)。 - 權限設置:通過?
MODE=「0666」、GROUP=「users」?修改設備文件權限。 - 符號鏈接:創建軟鏈接(如?
SYMLINK+=「cdrom」?指向?/dev/sr0)。 - 腳本執行:設備插入時自動掛載(
RUN+=「/bin/mount /dev/sdb1 /mnt」)
- 最終在?
/dev?下生成設備文件,完成設備可用性配置
這樣我們就可以以文件的形式使用設備了。
好滴,那么為啥我們就能以文件的形式去使用這些設備的,關鍵就在于驅動程序:
Everything Is a File, 通過執行操作系統對象的指針可以訪問一切,open/close,read/write,lseek。
驅動程序實現了當前設備的 struct file_operations 的實現,它把系統調用翻譯成與設備能聽懂的數據,甚至包含如/dev/null 和 proc/stat 這種虛擬文件。
- 驅動通過?
ioremap()將 BAR 映射的物理地址轉為內核虛擬地址,直接讀寫設備寄存器 - 設備直接寫內存地址(MSI Data)觸發中斷,支持多向量和定向投遞,驅動注冊中斷處理函數
- 應用程序,通過?
read()/write()或?ioctl()發送控制命令
沒想到吧,連虛擬機都是文件,KVM 的所有關鍵操作(虛擬機生命周期管理、CPU 調度、內存映射)均通過?ioctl?實現用戶態與內核態的交互:
kvm_fd = open(「/dev/kvm」, O_RDWR); // 打開 KVM 設備
vm_fd = ioctl(kvm_fd, KVM_CREATE_VM, 0); // 創建虛擬機
vcpu_fd = ioctl(vm_fd, KVM_CREATE_VCPU, 0); // 創建 vCPU
ioctl(vcpu_fd, KVM_RUN, 0); // 運行 vCPU當調用?KVM_RUN?后,虛擬 CPU 開始執行客戶機指令。若客戶機觸發 I/O 操作或特權指令(如訪問設備寄存器),CPU 會通過硬件虛擬化技術(Intel VT/AMD-V)退出到宿主機內核模式(VM-Exit)。KVM 內核模塊捕獲退出原因(如?KVM_EXIT_IO),并通過?ioctl?的返回值通知用戶態 QEMU 處理 I/O 模擬
4.2. 存儲設備原理
存儲的本質在于通過改變物理介質的狀態來記錄信息,該介質需具備至少兩種可穩定區分的狀態。
存儲經歷了百年的發展歷史,從磁帶,磁鼓,到磁盤,軟盤,到 CD 光盤,Flash memory 閃存和 U 盤,flash memory 活到了今天,配合 FTL 技術(軟件定義磁盤)成為了存儲界的版本答案,讓我們來一一回顧,存儲的前世今生。
4.2.1. 磁帶

磁帶存儲的本質是磁場與磁性材料的可控相互作用:電流脈沖定向磁化介質,剩磁狀態固化信息,電磁感應逆向解碼。其高密度、低成本的特性,使其在云備份(如 AWS Glacier)、科研歸檔等場景仍不可替代。隨著 HAMR(熱輔助磁記錄)等技術的發展,磁帶存儲密度正邁向 100Gb/in2以上,持續拓展數字歷史的承載邊界。
寫入原理:電信號→磁化狀態
- 輸入數據(如數字信號)轉換為電流脈沖序列。當電流通過磁頭線圈時,根據安培定律產生磁場
- 磁帶表面涂覆硬磁性材料(如γ-Fe?O?或 CrO?),磁頭縫隙處的磁場作用于勻速運動的磁帶,使磁性顆粒按特定方向磁化。
讀取原理:磁化狀態→電信號
- 磁化區域經過讀取磁頭時,磁力線穿過磁頭鐵芯,在線圈中感應電動勢
- 磁通翻轉(代表 1)→ 產生正向/負向脈沖電壓,無翻轉(代表 0)→ 無顯著電壓變化
- 信號經放大器鑒別后還原為原始數據
- 讀取過程不改變磁化狀態,數據可重復讀取,磁帶壽命約 30 年
擦除原理:退磁還原
- 磁帶通過消磁磁頭,施加高頻交變磁場,使磁性顆粒磁疇方向隨機化,整體剩磁歸零
工作方式
- 順序存取:數據按物理順序排列,讀取需遍歷前方數據(平均延遲秒級),適合備份等低頻訪問場景
- 流式傳輸:現代數據流磁帶機(如 LTO-9)通過單主動輪驅動,磁帶勻速運動(4-10m/s),磁頭靜止接觸
優劣勢:
- 容量大:LTO-9 單卷 45TB,成本$0.01/GB;
能耗低:脫機保存無需供電;
壽命長:抗電磁干擾,適合冷數據歸檔 - 順序訪問:隨機讀寫效率極低;
4.2.2. 磁鼓
磁帶(1928 年由 Fritz Pfleumer 發明)本質是線性一維存儲介質:數據按順序記錄在磁性涂層上,讀寫需順序掃描。其優勢是成本低、容量大,但隨機訪問效率極低(如讀取末端數據需遍歷整盤磁帶)
1932 年奧地利工程師 Gustav Tauschek 發明的磁鼓采用圓柱形旋轉結構:數據分布在鼓面磁道上,通過固定磁頭與高速旋轉(>3000 RPM)實現毫秒級延遲訪問。以 IBM 701 計算機(1953 年)為例,磁鼓作為內存使用,容量 62.5KB,遠超同期磁帶。

線性移動 -> 旋轉掃描,帶來革命: 錄音 -> 實時計算
- 并行磁頭:多磁頭同時讀寫不同磁道,提升吞吐量
- 旋轉尋址:數據隨鼓面旋轉周期性經過磁頭,平均延遲僅 5ms
4.2.3. 磁盤
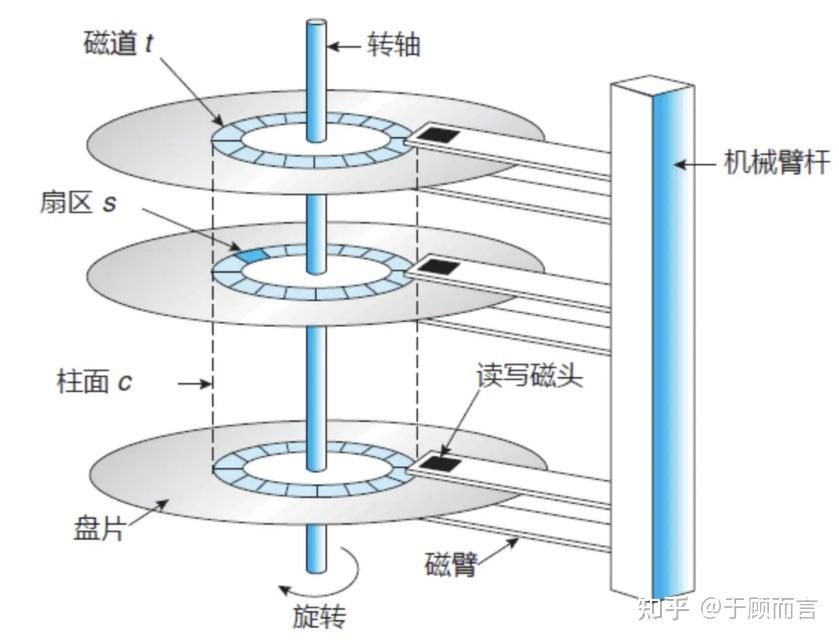
磁鼓有兩個核心局限:
- 磁鼓僅能利用圓柱體單表面存儲數據(磁性涂層覆蓋外表面),內部空間完全浪費。而磁盤采用雙面盤片+多盤片堆疊設計(如 IBM RAMAC 350 含 50 張 24 英寸盤片),存儲密度提升數十倍
- 磁鼓依賴固定磁頭+鼓面旋轉實現數據定位,雖比磁帶順序讀寫快(平均延遲 5ms),但無法實現真正隨機尋址,磁盤通過可移動懸臂磁頭(如 RAMAC 的液壓驅動臂)直接定位任意磁道,尋址時間縮短至毫秒級
磁盤有一些工程優化的突破:
- 磁盤引入空氣軸承技術(IBM 1301,1962 年),磁頭懸浮于盤面之上,間隙縮小至亞微米級,提升密度且降低磨損
- 1973 年 IBM 推出溫徹斯特架構(Winchester),盤片與磁頭密封在無塵腔體內,避免粉塵污染,磁頭停泊區設計,斷電時自動歸位,防止盤面刮傷
- 磁鼓表面電鍍磁介質易剝落,磁盤采用濺鍍工藝生成納米級磁性合金層(如鈷鉻鉭合金),耐磨性提升 10 倍,支持更高轉速
4.2.4. 軟盤
磁盤到軟盤的演進,主要是便攜性需求驅動帶來的。
磁盤的固有限制
- 體積與成本:1956 年 IBM 推出的首款硬盤 RAMAC 305 重達 1 噸,容量僅 5MB,價格高昂且需專用機房。
- 不可移動性:早期硬盤為封閉式設計,數據無法跨設備傳輸,限制了個人計算機(PC)的普及。
軟盤的技術突破
- 便攜性設計:1967 年 IBM 開發出直徑 32 英寸軟盤,目標是為大型機提供成本低于 5 美元的可更換微代碼載體。
- 小型化迭代:
- 1971 年:8 英寸軟盤(81KB);
- 1976 年:5.25 英寸軟盤(360KB),成為 IBM PC 標配;
- 1983 年:3.5 英寸軟盤(1.44MB),索尼設計保護殼提升耐用性。
- 核心優勢:輕便、可拆卸、低成本,滿足個人數據交換需求(如軟件分發、文件傳輸)。
市場催化
- PC 普及浪潮:1980 年代 IBM PC 和 Apple II 興起,軟盤成為唯一通用移動存儲介質,1996 年全球用量達 50 億片
4.2.5. CD 光盤
軟盤到 CD 光盤:容量危機與多媒體需求升級
- 容量限制:1.44MB 無法滿足軟件/媒體文件增長, Windows 95 安裝需 13 張軟盤
- 速度低下:讀寫速率僅 100KB/s,大型文件傳輸耗時過長
- 易受磁場干擾、物理損壞,數據丟失風險高
隨著激光技術的發展,我們可以利用光學反射進行相位差解碼:
- 激光發射:光頭發射波長 780nm 的近紅外激光束,聚焦為直徑約 1μm 的光點。
- 反射差異:
- 平坦區域(Land):激光垂直反射回光電探測器,光強高(代表二進制「0」序列)。
- 凹坑區域(Pit):凹坑深度設計為激光波長的 1/4(約 0.12μm),使反射光與入射光相位差 180°,產生相消干涉,反射光強顯著減弱。
- 信號轉換:光電探測器將反射光強差異轉換為電信號(高電平=「0」,低電平=「1」),再經解碼電路還原為數字信息。
這就帶來了兩個技術飛躍:
- 容量躍遷:CD-ROM(700MB)為軟盤的 486 倍,單盤可存儲百科全書或多媒體軟件,DVD(4.7GB)進一步支持高清視頻
- 大規模量產:聚碳酸酯注塑成型實現大規模量產,坑點刻蝕精度達納米級,有了母盤,可以 3s 中快速注塑成型一個 CD 光盤,如果是車間流水線,可想而知數據拷貝的速率有多快。
CD 盤片從下至上分層構成
層級材料與功能厚度/特性聚碳酸酯基板透明塑料,承載凹坑結構 1.2mm,折射率 1.55?反射層鋁或金膜,反射激光(鋁=「銀盤」,金=「金盤」)0.05μm,反射率>70%
| 層級 | 材料與功能 | 厚度/特性 |
| 聚碳酸酯基板 | 透明塑料,承載凹坑結構 | 1.2mm,折射率1.55 |
| 反射層 | 鋁或金膜,反射激光(鋁="銀盤",金="金盤") | 0.05μm,反射率>70% |
| 保護層 | 丙烯酸樹脂,防氧化與物理損傷 | 提升盤面硬度和耐刮性 |
| 封面層 | 印刷標簽層 | 不影響光學讀取 |
保護層丙烯酸樹脂,防氧化與物理損傷提升盤面硬度和耐刮性封面層印刷標簽層不影響光學讀取
4.2.6. flash memory
開始聊聊當前的版本答案---閃存,從光學機械式向固態電子式躍遷,“你還能比電快啊?”。
CD 光盤的固有缺陷
- 機械脆弱性:CD 依賴精密光學頭與旋轉盤片,易受劃痕、灰塵影響,誤碼率高達 10?12;
- 讀寫性能低下:恒定線速度(CLV)設計導致內圈讀取僅 150KB/s,且不支持隨機訪問;
- 不可動態更新:CD-RW 擦寫需全盤擦除,耗時長達 10 分鐘,擦寫壽命僅約 1000 次;
- 容量天花板:紅光激光波長 780nm 限制最小凹坑尺寸,單碟最大 700MB,無法匹配數據爆炸需求。
閃存技術的顛覆性創新
- 非機械結構:浮柵晶體管(Floating Gate MOSFET)通過電子隧穿存儲數據,無移動部件,抗振動性提升 100 倍;
- 高速讀寫:NAND 閃存隨機訪問延遲<100μs,連續讀寫速度>500MB/s(CD 的 3000 倍以上);
- 動態擦寫能力:支持頁級寫入(4KB)和塊級擦除(256KB),擦寫壽命達 10 萬次(QLC 閃存);
- 三維堆疊擴容:3D NAND 技術實現 200+層堆疊,單芯片容量突破 1Tb,成本降至$0.01/GB(2025 年)
閃存的基本存儲單元是浮柵晶體管,由控制柵(Control Gate)、浮柵(Floating Gate)、源極(Source)和漏極(Drain)構成
。浮柵被二氧化硅(SiO?)絕緣層包裹,形成電荷“陷阱”,其電荷狀態決定數據值(0 或 1):
- 浮柵:懸浮于氧化層中,用于捕獲電子,電荷可長期保留(斷電后不丟失)。
- 控制柵:施加電壓以操控電子運動。
- 氧化層:隧穿氧化層(Tunnel Oxide)厚度僅 5-10nm,是電子隧穿的關鍵通道
寫入(Program)
- 電子注入:向控制柵施加高電壓(15-20V),電子通過?Fowler-Nordheim 隧穿效應穿越氧化層,被浮柵捕獲。
- 電荷效應:浮柵帶負電后,晶體管的閾值電壓(Threshold Voltage)升高,讀取時被識別為“0”。
擦除(Erase)
- 電子釋放:在源極施加反向高壓(約 20V),浮柵電子被拉出,電荷消散,閾值電壓降低,狀態變為“1”。
- 操作單位:擦除以塊(Block)為單位(通常 256KB-4MB),而非單個字節。
讀取(Read)
- 電壓檢測:向控制柵施加中等電壓,若浮柵有電荷(閾值電壓高),晶體管不導通(輸出“0”);無電荷則導通(輸出“1”)。
- NOR/NAND 差異:
- NOR:支持隨機訪問,可直接讀取任意字節。
- NAND:需按頁(Page,通常 4-16KB)順序讀取。
4.2.7. FTL 技術
閃存是有擦寫限制的,SLC 閃存約 10 萬次,QLC 閃存僅 100 次。若頻繁寫入同一物理塊,會導致局部快速損壞。
傳統文件系統(如 EXT4、NTFS)和塊設備驅動(如 Linux 的?block_device_operations)基于扇區(512B)或塊(通常 4KB)?的覆蓋寫入設計。操作系統通過 BIO(Block I/O)接口提交讀寫請求,默認支持原地更新(in-place update)。
FTL 的本質是在閃存物理限制與傳統系統之間構建的“翻譯層”,(操作系統->BIO->閃存)通過三大創新解決結構性矛盾:
- 虛擬化覆蓋寫?→ 適配操作系統;
FTL 的映射機制
邏輯地址(LBA)→物理地址(PBA)轉換:FTL 維護動態映射表,將操作系統的扇區請求轉換為閃存的頁操作。當數據更新時,FTL 將新數據寫入空白頁,并更新映射表指向新位置,原位置標記為“無效”(Invalid),通過“異地更新”(Out-of-Place Update)模擬磁盤的覆蓋寫行為,避免物理擦除延遲
- 動態磨損均衡?→ 對抗壽命短板;
新數據優先寫入擦寫次數少的“年輕塊”(Low EC)
- 寫入聚合(Write Coalescing):
緩存多個小 BIO,合并為整頁寫入
- 自動垃圾回收?→ 提升空間利用率。
刪除操作是對一個塊的,而塊包含多個頁面,操作系統如果只刪除某個頁面時,就會出現一個塊部分頁面為有效,部分為無效,所以將無法刪除,因為擦除操作需作用于整個塊,且僅當塊內所有頁均為“無效”狀態時才能執行,這樣那部分無效空間就完全沒法利用了。所以回收機制就是,先遷移有效頁到新塊,再擦除原塊。
- 可靠性增強
閃存出廠即含壞塊,使用中還會新增壞塊。FTL 通過映射表屏蔽壞塊,將數據重定向到備用塊
FTL 利用 RAM 緩存映射表,并通過多通道并發訪問閃存芯片提升吞吐量
ECC 糾錯:集成 BCH/LDPC 算法修復位翻轉(Bit Flip)
沒有 FTL,閃存將無法被現有操作系統直接使用,其壽命和性能會因物理限制而大幅縮水。
4.3. 目錄樹管理
4.3.1. 隱藏文件
Linux 系統中以.開頭的隱藏文件機制起源于 Unix 系統的設計哲學。在早期 Unix 系統中,ls?命令存在一個顯示邏輯缺陷:默認不顯示名稱以.開頭的文件。這個設計最初是為了隱藏系統關鍵文件(如.和..),后來逐漸演變為隱藏用戶配置文件的通用方案。
# 顯示所有隱藏文件(含系統級)
ls -a # 輸出示例:.bashrc .cache .git/# 創建隱藏文件/目錄
touch .secret_config
mkdir .config# 修改現有文件為隱藏
mv config .config隱藏文件有如下應用場景:
# 典型隱藏配置文件
.bashrc # 用戶 Shell 配置
.gitconfig # Git 全局配置# 熱加載機制:修改后立即生效
source ~/.bashrc# 隱藏 SSH 密鑰
chmod 600 ~/.ssh/id_rsa# 防止配置泄露
echo 「export SECRET_KEY=...」 >> .env內核實現邏輯如下:
// fs/ext4/dir.C 中的關鍵函數
int ext4_readdir(struct file *file, struct dir_context *ctx) {struct ext4_dir_entry_2 *de;while ((de = ext4_next_dir_entry(file, ctx->pos)) != NULL) {if (de->name[0] == 『.』) continue; // 跳過隱藏文件ctx->pos = de->inode;if (!dir_emit(ctx, de->name, de->name_len, de->inode, DT_UNKNOWN))return 0;}return 0;
}4.3.2. 約定俗成的目錄結構
Linux 目錄結構遵循文件系統層次標準(FHS)
,其核心設計理念源于 Unix 的「一切皆文件」哲學。這種樹狀結構通過嚴格的層級劃分實現:
- 單一根目錄:所有路徑以
/為起點 - 功能隔離:不同類別文件嚴格分區存放
- 標準化擴展:通過
/usr?和/opt?實現軟件生態擴展
目錄功能定位典型內容示例訪問權限特殊屬性/bin?基礎用戶命令存放區?ls,?cp,?mv,?rm,?chmod755 靜態鏈接二進制文件,單用戶模式可用/sbin?系統管理命令存放區?fdisk,?ifconfig,?reboot,?service750 僅 root 可執行,包含硬件管理工具/boot?系統啟動關鍵文件存儲?vmlinuz,?initrd.img,?grub.cfg,?System.map755 內核鏡像存放區,需保留足夠空間(建議≥2GB)/dev?設備文件集散地/dev/sda1,?/dev/tty,?/dev/null,?/dev/zero755 虛擬設備文件,按需動態創建/etc?系統配置中樞?passwd,?fstab,?hosts,?ssh/sshd_config644 關鍵配置文件集群,修改需謹慎/home?用戶主目錄容器/home/user1,?/home/developer755 每個用戶獨立目錄,支持配額管理/lib32 位系統庫文件存儲?libc.so.6,?libstdc++.so.6755 靜態庫與內核模塊存放區/lib6464 位系統庫文件存儲?libc-2.31.so,?libcrypto.so.3755 動態鏈接庫主要存放位置/media?可移動設備自動掛載點/media/usb,?/media/cdrom755udev 自動掛載,支持熱插拔/mnt?臨時掛載點/mnt/backup,?/mnt/data755 手動掛載專用,推薦使用?systemd-mount/opt?第三方軟件安裝區/opt/Docker,?/opt/postgresql755 商業軟件標準安裝路徑,建議保持獨立/proc?內核狀態鏡像/proc/cpuinfo,?/proc/meminfo,?/proc/net/dev?動態權限虛擬文件系統,反映實時系統狀態/root?超級用戶主目錄/root/.bashrc,?/root/scripts700 僅 root 可訪問,存放敏感配置/run?運行時數據暫存區/run/user/1000,?/run/Docker.sock1777tmpfs 文件系統,重啟數據清空/srv?服務數據存儲/srv/www,?/srv/nfs755FHS 標準服務數據存儲區/sys?內核對象樹/sys/devices,?/sys/bus,?/sys/class/net?動態權限 sysfs 文件系統,展示硬件拓撲/tmp?臨時文件回收站/tmp/cache,?/tmp/uploads1777 自動清理機制,建議配合?tmpreaper
目錄 | 功能定位 | 典型內容示例 | 訪問權限 | 特殊屬性 |
/bin | 基礎用戶命令存放區 | ls, cp, mv, rm, chmod | 755 | 靜態鏈接二進制文件,單用戶模式可用 |
/sbin | 系統管理命令存放區 | fdisk, ifconfig, reboot, service | 750 | 僅root可執行,包含硬件管理工具 |
/boot | 系統啟動關鍵文件存儲 | vmlinuz, initrd.img, grub.cfg, System.map | 755 | 內核鏡像存放區,需保留足夠空間(建議≥2GB) |
/dev | 設備文件集散地 | /dev/sda1, /dev/tty, /dev/null, /dev/zero | 755 | 虛擬設備文件,按需動態創建 |
/etc | 系統配置中樞 | passwd, fstab, hosts, ssh/sshd_config | 644 | 關鍵配置文件集群,修改需謹慎 |
/home | 用戶主目錄容器 | /home/user1, /home/developer | 755 | 每個用戶獨立目錄,支持配額管理 |
/lib | 32位系統庫文件存儲 | libc.so.6, libstdc++.so.6 | 755 | 靜態庫與內核模塊存放區 |
/lib64 | 64位系統庫文件存儲 | libc-2.31.so, libcrypto.so.3 | 755 | 動態鏈接庫主要存放位置 |
/media | 可移動設備自動掛載點 | /media/usb, /media/cdrom | 755 | udev自動掛載,支持熱插拔 |
/mnt | 臨時掛載點 | /mnt/backup, /mnt/data | 755 | 手動掛載專用,推薦使用systemd-mount |
/opt | 第三方軟件安裝區 | /opt/docker, /opt/postgresql | 755 | 商業軟件標準安裝路徑,建議保持獨立 |
/proc | 內核狀態鏡像 | /proc/cpuinfo, /proc/meminfo, /proc/net/dev | 動態權限 | 虛擬文件系統,反映實時系統狀態 |
/root | 超級用戶主目錄 | /root/.bashrc, /root/scripts | 700 | 僅root可訪問,存放敏感配置 |
/run | 運行時數據暫存區 | /run/user/1000, /run/docker.sock | 1777 | tmpfs文件系統,重啟數據清空 |
/srv | 服務數據存儲 | /srv/www, /srv/nfs | 755 | FHS標準服務數據存儲區 |
/sys | 內核對象樹 | /sys/devices, /sys/bus, /sys/class/net | 動態權限 | sysfs文件系統,展示硬件拓撲 |
/tmp | 臨時文件回收站 | /tmp/cache, /tmp/uploads | 1777 | 自動清理機制,建議配合tmpreaper使用 |
使用
4.3.3. 目錄樹實現
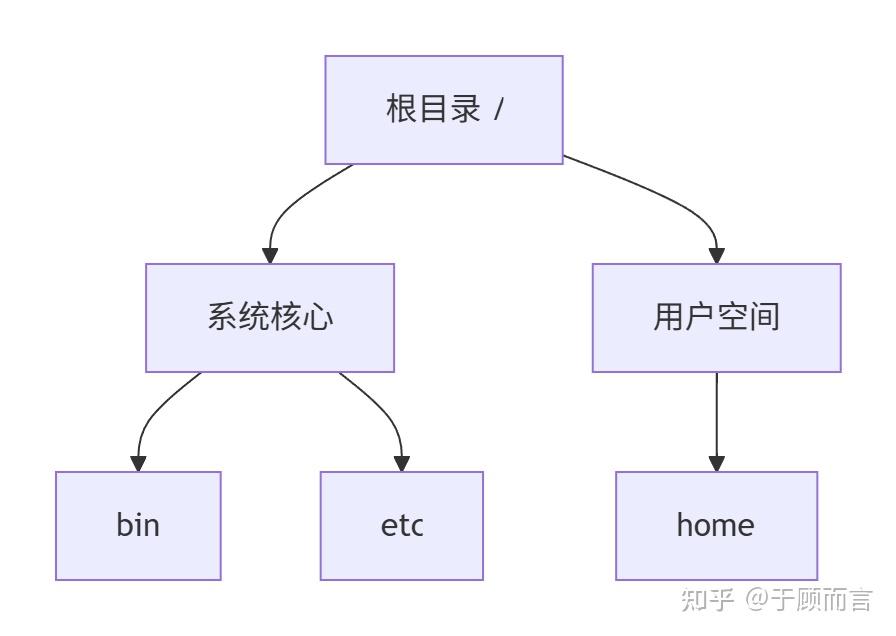
目錄樹本質上是多叉樹(N-ary Tree)的變種,每個節點包含:
- 數據域:存儲名稱(目錄名/文件名)、元數據(權限、時間戳等)
- 子節點指針:指向直接子目錄或文件
- 父節點引用:維護層級關系(非必需,常見于內存結構)
// Linux 內核目錄項結構體示例
struct dentry {/* RCU lookup touched fields */unsigned int d_flags; /* protected by d_lock */seqcount_t d_seq; /* per dentry seqlock */struct hlist_bl_node d_hash; /* lookup hash list */struct dentry *d_parent; /* parent directory 父目錄*/struct qstr d_name;struct inode *d_inode; /* Where the name belongs to - NULL is* negative 與該目錄項關聯的 inode */unsigned char d_iname[DNAME_INLINE_LEN]; /* small names 短文件名*//* Ref lookup also touches following */struct lockref d_lockref; /* per-dentry lock and refcount */const struct dentry_operations *d_op; /* 目錄項操作 */struct super_block *d_sb; /* The root of the dentry tree 這個目錄項所屬的文件系統的超級塊(目錄項樹的根)*/unsigned long d_time; /* used by d_revalidate 重新生效時間*/void *d_fsdata; /* fs-specific data 具體文件系統的數據 */struct list_head d_lru; /* LRU list 未使用目錄以 LRU 算法鏈接的鏈表 *//** d_child and d_rcu can share memory*/union {struct list_head d_child; /* child of parent list 目錄項通過這個加入到父目錄的 d_subdirs 中*/struct rcu_head d_rcu;} d_u;struct list_head d_subdirs; /* our children 本目錄的所有孩子目錄鏈表頭 */struct hlist_node d_alias; /* inode alias list 索引節點別名鏈表*/
};一個有效的 dentry 結構必定有一個 inode 結構,這是因為一個目錄項要么代表著一個文件,要么代表著一個目錄,而目錄實際上也是文件。所以,只要 dentry 結構是有效的,則其指針 d_inode 必定指向一個 inode 結構。但是 inode 卻可以對應多個(硬鏈接)。
整個結構其實就是一棵樹,如果看過我的設備模型 kobject 就能知道,目錄其實就是文件(kobject、inode)再加上一層封裝,這里所謂的封裝主要就是增加兩個指針,一個是指向父目錄,一個是指向該目錄所包含的所有文件(普通文件和目錄)的鏈表頭。
這樣才能有我們的目錄操作(比如回到上次目錄,只需要一個指針步驟【..】,而進入子目錄需要鏈表索引需要多個步驟)
功能特性:
- 緩存機制:LRU 算法管理活躍目錄項(命中率>95%)
- 路徑解析:通過父指針快速構建完整路徑
- 符號鏈接:支持跨文件系統鏈接解析
4.3.4. 硬鏈接和軟鏈接
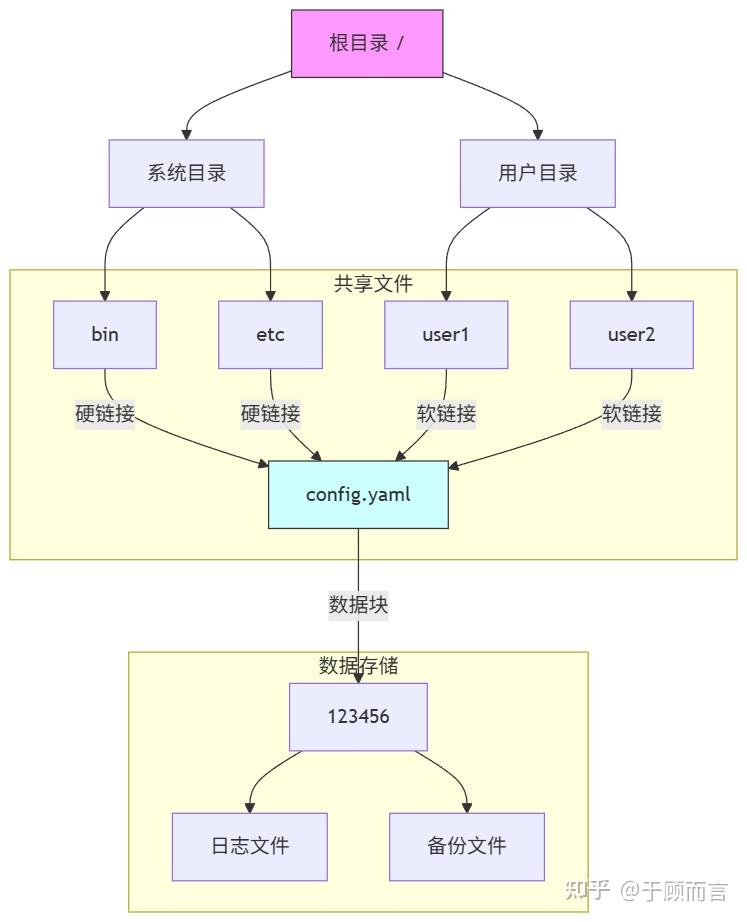
傳統文件系統的目錄樹本質上是帶標簽的多叉樹,但隨著現代文件系統通過引入共享機制,使目錄樹演變為有向無環圖(DAG):
- 多父節點支持:文件/目錄可被多個父目錄引用
- 共享計數器:記錄每個節點的引用數量
- 循環防范:通過拓撲排序確保無環路
多叉樹適用場景
- 傳統文件系統:如 ext4、XFS 的默認目錄結構
- 簡單存儲需求:不需要跨用戶共享文件的場景
- 快速遍歷需求:通過父節點快速定位子節點
有向無環圖適用場景
- 企業級存儲系統:需要多部門共享文檔的場景
- 容器化環境:Docker 鏡像層間的目錄共享
- 分布式系統:GlusterFS 等分布式文件系統
節點與邊的數據結構定義
typedef struct dag_inode {uint64_t cid; // 內容尋址標識(基于 SHA-256 哈希值)vector_t parent_dirs; // 父目錄指針數組(核心:支持多父節點)inode_meta_t meta; // 元數據(權限、時間戳等)block_ref_t data_ref; // 數據塊指針(指向實際文件內容)
} dag_inode_t;- 節點本質:每個?
dag_inode_t?結構體代表一個文件或目錄節點。 - 關鍵字段:
cid:文件內容的唯一標識(通過哈希計算),相同內容的文件共享同一個 cid,實現數據去重。parent_dirs:存儲所有父目錄的指針(傳統文件系統僅支持單父目錄,此設計實現多目錄硬鏈接)。data_ref:指向文件數據塊的指針(若為目錄則可能為空)。
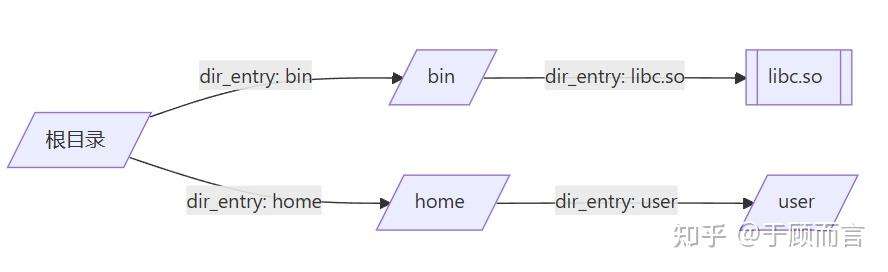
邊(隱式存在于?dir_entry_t)
typedef struct {dag_inode_t* inode; // 指向目標節點的指針(定義邊的方向)char name[256]; // 目錄項名稱(邊的標簽)
} dir_entry_t;- 邊的本質:
- 目錄到文件的邊:通過?
dir_entry_t?表示。inode?字段指向目標節點(文件或子目錄),形成有向邊(目錄 → 文件)。name?是邊在父目錄中的名稱(例如?libc.so)。
- 文件到數據塊的邊:通過?
block_ref_t?實現(圖中未展開)。 - 目錄間的邊:通過?
parent_dirs?中的指針連接(例如?/home/user?指向其父目錄?/home)。
- 目錄到文件的邊:通過?
通過內容尋址建立節點間的有向關系:
- 硬鏈接邊:共享相同數據塊(
data?字段相同),多個目錄項指向同一 inode(引用計數管理) - 軟鏈接邊:創建特殊節點存儲目標路徑解析信息
- 目錄邊:建立父子目錄關系
1. 硬鏈接的 DAG 特性
- 自動去重機制:相同內容的文件在 DAG 中僅存儲一次,所有硬鏈接指向同一 CID 節點。
- 引用計數管理:刪除操作僅減少引用計數,數據節點在所有硬鏈接刪除后才釋放。
- 無路徑依賴性:移動或重命名源文件不影響硬鏈接訪問(因依賴 CID 而非路徑)。
2. 軟連接的 DAG 特性
- 路徑解析開銷:訪問時需遞歸解析路徑字符串,可能跨越多個 DAG 子圖。
- 失效風險:若目標路徑被刪除或移動,軟連接變為“死鏈”(Dangling Link)。
- 元數據獨立:擁有獨立的創建時間、權限等屬性(與目標文件無關)
組件傳統樹結構 DAG 結構優化收益元數據存儲線性 inode 表 B+樹索引查詢速度提升 5x?數據塊引用直接/間接指針內容尋址(CID)冗余數據減少 70%
| 組件 | 傳統樹結構 | DAG結構 | 優化收益 |
| 元數據存儲 | 線性inode表 | B+樹索引 | 查詢速度提升5x |
| 數據塊引用 | 直接/間接指針 | 內容尋址(CID) | 冗余數據減少70% |
| 鏈接機制 | 僅符號鏈接 | 硬鏈接+軟鏈接+跨卷鏈接 | 跨設備共享實現 |
鏈接機制僅符號鏈接硬鏈接+軟鏈接+跨卷鏈接跨設備共享實現
4.3.5. 文件的元數據
文件元數據(Metadata)是數字世界的「身份檔案」,它以結構化形式記錄著文件的全部非內容屬性。在 Linux 系統中,每個文件至少包含 46 項元數據字段,構成其數字身份的核心要素
// ext4 文件系統 inode 結構體(簡化版)
struct ext4_inode {__le16 i_mode; // 文件類型與權限(0644)__le16 i_uid; // 所有者 ID(0=root)__le32 i_size; // 文件大小(字節)__le32 i_atime; // 訪問時間戳__le32 i_mtime; // 修改時間戳__le32 i_ctime; // 狀態變更時間戳__le16 i_gid; // 所屬組 ID__le16 i_links_count; // 硬鏈接數__le32 i_blocks; // 占用數據塊數__le32 i_flags; // 文件特性標志__le64 i_block[15]; // 數據塊指針數組__le32 i_extra_isize; // 擴展元數據長度// ...(其他擴展字段)
};以上為傳統的元數據,現在又出現了一種很牛的設計叫 xattr。
擴展屬性(xattr)是突破傳統文件元數據限制的革命性設計,允許用戶以鍵值對形式附加任意元數據到文件/目錄上,突破 POSIX 標準定義的 12 個基礎屬性限制。其核心特性包括:
- 命名空間隔離
user:普通用戶可讀寫(如?user.version)security:安全框架專用(如 SELinux 標簽)system:系統級元數據(如文件編碼)trusted:需 root 權限訪問
- 跨對象支持:文件、目錄、符號鏈接均可附加屬性
- 獨立演化:屬性值與文件內容解耦,支持獨立修改
典型場景:在 Linux ext4 中單文件 xattr 容量達 4KB,支持數萬屬性條目;而 macOS HFS+通過 B*樹內聯存儲,限制單屬性大小但支持無限數量
4.3.6. mount
Linux 中的 mount 操作是連接外部存儲設備到文件系統的核心機制。其過程涉及用戶空間命令到內核的系統調用、數據結構構建和資源管理。以下是詳細解析:
一、用戶空間:mount 命令的解析
當執行 mount /dev/sdb1 /mnt 時:
參數解析
-t 指定文件系統類型(如 ext4、nfs)
-o 定義掛載選項(如 ro 只讀、rw 讀寫、noexec 禁用執行)
設備路徑(如 /dev/sdb1)和掛載點(如 /mnt)
系統調用觸發
命令通過 glibc 庫調用內核的 sys_mount() 系統調用,傳遞參數到內核空間
二、內核空間:掛載的核心流程
1. 系統調用入口:sys_mount()
將用戶空間參數(設備路徑、掛載點、文件系統類型)復制到內核空間。
2. 文件系統類型識別
調用 get_fs_type(),根據 type 參數(如 ext4)查找已注冊的 file_system_type 結構體。該結構體包含文件系統操作函數指針(如 mount 回調)。
3. 創建源文件系統:vfs_kern_mount()
分配 vfsmount**:內核創建 vfsmount 結構,記錄掛載元數據(如設備名、掛載標志)。
填充超級塊:調用文件系統特定的 get_sb() 函數(如 ext4_fill_super()),從設備讀取超級塊(super_block),初始化根目錄的 dentry(目錄項)和 inode(索引節點)。
4. 掛載點查找與鎖定:lock_mount()
檢查掛載點目錄(如 /mnt)是否有效,并防止并發掛載沖突。
若掛載點已被其他文件系統覆蓋(如嵌套掛載),需找到最頂層的掛載點。
5. 關聯源文件系統:graft_tree()
將新創建的 vfsmount 鏈接到掛載點,更新全局掛載哈希表 mount_hashtable,建立父子關系。
6. 命名空間集成
將新掛載的文件系統添加到當前進程的掛載命名空間(namespace),使掛載對所有共享該命名空間的進程可見。
掛載操作的核心是?將存儲設備關聯到文件系統樹:
- 用戶命令?→?系統調用?→?內核數據結構構建(
vfsmount、super_block)→?命名空間集成。 - 關鍵創新點:
- 統一抽象:通過 VFS 層兼容不同文件系統(ext4/NFS/tmpfs)。
- 動態擴展:支持物理設備、虛擬文件(ISO)、網絡存儲的透明接入。
通過?mount,Linux 將異構存儲轉化為統一的文件樹,這正是?“一切皆文件”?哲學的基石。
pivot_root?是 Linux 系統調用,用于將進程的根文件系統切換到新路徑,同時將舊根移動到新根下的子目錄。其核心目標是實現強隔離的根文件系統切換,避免傳統?chroot?的掛載泄漏問題。,單純的?chroot?僅重定向路徑解析,進程仍共享主機的掛載命名空間(如?/proc)。而?pivot_root?結合 Mount Namespace 可創建完全獨立的文件系統視圖--------Docker 的感覺是不是出來了
4.3.7. overlayfs
OverlayFS 是一種?聯合掛載文件系統,通過疊加多個目錄(稱為“層”)形成單一視圖,實現文件系統的動態合并與隔離。其核心結構包含三個目錄:
- Lower Directory(下層)
- 只讀層:存儲基礎文件(如容器鏡像或系統固件),不可修改。
- 支持多個層級(如?
lowerdir=/dir1:/dir2),優先級從左到右遞減。
- Upper Directory(上層)
- 可讀寫層:存儲用戶新增或修改的文件,所有變更在此層生效。
- Work Directory(工作目錄)
- 臨時目錄:用于文件系統內部操作(如文件重命名時的原子操作),用戶無需直接訪問。
- Merged Directory(合并視圖)
- 最終呈現的統一目錄,合并所有層內容,用戶通過此目錄訪問文件。
關鍵機制
- 寫時復制(Copy-on-Write, CoW):
當修改?lower?層文件時,OverlayFS 自動將其復制到?upper?層再修改,保持底層只讀性。 - 文件刪除與隱藏:
- Whiteout 文件:刪除?
lower?層文件時,在?upper?層創建特殊標記(字符設備文件),使文件在合并視圖中“消失”。 - Opaque 目錄:標記目錄為不透明,隱藏下層同名目錄內容。
- Whiteout 文件:刪除?
- 同名文件沖突處理:
優先顯示?upper?層文件,其次是?lower?層中靠左的目錄(后寫入者優先)。
OverlayFS 一大應用就是 Docker 鏡像層,Docker 鏡像由多層只讀文件(鏡像層)組成,容器運行時需將這些層疊加為統一視圖。聯合文件系統(如 OverlayFS)依賴底層塊設備接口實現分層管理:
- 分層疊加:塊設備(如?
/dev/loop0)將鏡像層文件虛擬化為獨立的“磁盤”,供 OverlayFS 掛載為?lowerdir(只讀層)和?upperdir(可寫層)。 - 直接使用文件的缺陷:普通文件無法被聯合文件系統直接識別為可掛載的存儲單元,需轉換為塊設備才能被掛載。
啟用寫時復制(CoW)機制
- 容器內修改文件時,CoW 機制需將原始文件從只讀層復制到可寫層再修改。塊設備提供原子化的數據塊操作接口,使復制過程高效且不破壞底層鏡像。
- 若直接操作文件:頻繁復制大文件(如數據庫)將導致 I/O 性能驟降,而塊設備通過按需復制數據塊(而非整個文件)顯著優化性能。
4.3.8. lvm
LVM(Logical Volume Manager,邏輯卷管理器)是 Linux 環境下對物理磁盤進行抽象化管理的核心機制,通過邏輯層動態分配存儲資源,解決傳統分區僵化問題。
LVM 在物理磁盤和文件系統之間構建邏輯層,將存儲資源池化并動態分配,其核心組件如下:
- 物理卷(PV, Physical Volume)
- 本質:物理磁盤(如?
/dev/sda1)、RAID 設備或整個硬盤。 - 管理單元:PV 被劃分為?PE(Physical Extent),默認大小?4MB,是 LVM 的最小存儲單元。
- 初始化命令:
pvcreate /dev/sdb1(將分區初始化為 PV)。
- 卷組(VG, Volume Group)
- 本質:多個 PV 的存儲池,整合物理資源形成統一空間(如將 50GB + 60GB 磁盤合并為 110GB 的 VG)。
- 管理機制:VG 中的 PE 可跨物理磁盤分配,打破物理邊界。
- 邏輯卷(LV, Logical Volume)
- 本質:從 VG 中劃分的虛擬分區(如?
/dev/vg_data/lv_home)。 - 組成單元:LV 由?LE(Logical Extent)?構成,LE 與 PE?一一對應且大小相同。
- 創建命令:
lvcreate -L 20G -n lv_data vg_data。
- 文件系統(FS)
- 建立在 LV 之上(如 ext4/XFS),通過?
mount?掛載使用。
有了 lvm,可以很輕松進行磁盤的動態管理:
// 擴容
lvextend -L +5G /dev/vg_data/lv_data # 增加 5GB 空間
resize2fs /dev/vg_data/lv_data # 調整文件系統大小(在線生效)// 縮容
umount /data # 卸載文件系統
resize2fs /dev/vg_data/lv_data 15G # 先縮小文件系統
lvreduce -L 15G /dev/vg_data/lv_data # 再縮小 LV// 快照(Snapshot)
創建 LV 的只讀時間點副本,僅記錄變更數據(CoW 機制)
備份數據庫時創建快照,避免服務中斷。
lvcreate -s -n lv_snap -L 2G /dev/vg_data/lv_data典型應用場景
- 數據庫存儲:動態擴展數據庫空間(如 MySQL 數據目錄)。
- 云服務器:按需調整云硬盤容量,適配業務增長。
- 虛擬化平臺:為虛擬機提供彈性磁盤,支持快照備份。
- 混合磁盤管理:整合 SSD(高速緩存)與 HDD(冷數據存儲)
4.4. 數據庫系統
4.4.1. 文件目錄
文件目錄其實也可以當數據庫使用:
# 目錄結構
db/
├── users/
│ ├── .schema # id:int, name:string
│ ├── 1.txt # {「id」:1, 「name」:「Alice」}
│ └── by_role/ # 索引目錄
│ └── 3/ → ../1.txt # 按角色 ID 分類
└── orders/├── 100.txt # {「id」:100, 「user_id」:1}└── 100_user.txt → ../users/1.txt # 關聯用戶表結構映射
- 目錄 = 表:每個目錄對應一張表(如?
users/?目錄即?users?表)。 - 文件 = 記錄:目錄內的文件對應表中的一行記錄(如?
users/1.txt?表示?id=1?的用戶)。 - 文件內容 = 字段值:文件內容以鍵值對或 JSON 格式存儲字段數據,例如:
// users/1.txt
{「id」:1, 「name」:「Alice」, 「role_id」:3}軟鏈接實現表關聯:
一對一雙向軟鏈接互指?profile/1.txt → users/1.txt(反之亦然)一對多在“多”方目錄創建指向“一”方的軟鏈接?orders/100.txt → users/1.txt?多對多建立中間目錄存儲關聯對
| 一對一 | 雙向軟鏈接互指 | profile/1.txt → users/1.txt(反之亦然) |
| 一對多 | 在“多”方目錄創建指向“一”方的軟鏈接 | orders/100.txt → users/1.txt |
| 多對多 | 建立中間目錄存儲關聯對 | user_role/1_3.txt(軟鏈接至 users/1 和 roles/3) |
user_role/1_3.txt(軟鏈接至?users/1?和?roles/3)
查詢操作的實現
- 條件查詢
grep?模擬 WHERE:
grep -l 『「role_id」:3』 users/*.txt # 查找角色 ID 為 3 的用戶find?模擬 JOIN:
find orders/ -lname 『*users/1.txt』 # 查找用戶 1 的所有訂單- 聚合計算,使用?
awk?統計:
awk -F: 『{sum += $2} END {print sum}』 orders/*.txt # 計算訂單總金額4.4.2. SQL
關系型數據庫通過表結構和指針機制重構目錄樹邏輯:
- Everything is Table
- 對象表化:每個實體(用戶、訂單)對應一張表,每行代表一個對象實例
- ID 即指針:外鍵(如?
user_id)是跨表索引的內存地址映射
SELECT orders.* FROM users
JOIN orders ON users.id = orders.user_id -- ID 的指針跳轉
WHERE users.name = 『Alice』;SQL 本質:JOIN 操作即指針配對(users.id?→?orders.user_id)
事務與 ACID:指針操作的原子保障
ACID 確保指針跳轉的可靠性:
ACID 屬性指針操作意義實現機制原子性指針批量更新要么全成功要么全失敗 Undo Log 回滾一致性指針始終指向有效內存地址外鍵約束+鎖機制隔離性并發指針互不干擾 MVCC 多版本控制持久性指針變更永久有效 Redo Log
| ACID屬性 | 指針操作意義 | 實現機制 |
| 原子性 | 指針批量更新要么全成功要么全失敗 | Undo Log回滾 |
| 一致性 | 指針始終指向有效內存地址 | 外鍵約束+鎖機制 |
| 隔離性 | 并發指針互不干擾 | MVCC多版本控制 |
| 持久性 | 指針變更永久有效 | Redo Log持久化 |
持久化
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- 指針 A
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- 指針 B
COMMIT; -- 原子提交兩個指針更新海量優化:當關系模型遇到性能瓶頸
隨著數據量增長,傳統關系模型需針對性優化:
- 查詢優化策略
- 索引即快捷指針:B+樹索引將全表掃描 O(n)降至 O(log n)
- 覆蓋索引:在索引中內聯數據,避免回表查詢(如?
SELECT id,name FROM users)
游標:精細化指針控制器
游標(Cursor)實現逐行精準控制,避免內存溢出
DECLARE user_cursor CURSOR FOR
SELECT id FROM users WHERE status = 『active』; -- 定義結果集指針
OPEN user_cursor;
FETCH NEXT FROM user_cursor; -- 指針向前移動
WHILE @@FETCH_STATUS = 0 DO-- 處理當前行數據FETCH NEXT FROM user_cursor;
END WHILE;
CLOSE user_cursor;- 分布式改造方案
優化方向實現方式典型案例水平分片按 ID 哈希分布到不同物理節點 MySQL 分庫分表讀寫分離寫主庫→讀從庫(異步指針同步)AWS RDS Proxy?列式存儲按列組織數據,提升聚合查詢速度
| 優化方向 | 實現方式 | 典型案例 |
| 水平分片 | 按ID哈希分布到不同物理節點 | MySQL分庫分表 |
| 讀寫分離 | 寫主庫→讀從庫(異步指針同步) | AWS RDS Proxy |
| 列式存儲 | 按列組織數據,提升聚合查詢速度 | Google BigQuery |
Google BigQuery
4.4.3. NoSQL
關系型數據庫的瓶頸無法滿足 Web 2.0 需求
- 海量數據處理能力不足
互聯網應用(如社交網絡、電商平臺)產生的數據量呈指數級增長,關系型數據庫在單機或集群模式下難以高效存儲和查詢 PB 級數據。例如,頻繁的多表關聯查詢或復雜事務操作在高并發場景下性能急劇下降 - 擴展性受限
關系型數據庫依賴縱向擴展(升級硬件),但單臺服務器的性能存在物理上限。橫向擴展(增加節點)則因事務一致性(ACID)和復雜關聯查詢的約束難以實現,導致成本高昂且運維復雜 - 高并發讀寫延遲
如電商秒殺或社交平臺熱點事件,關系型數據庫的鎖機制和事務管理易引發死鎖,導致響應延遲,無法支撐百萬級并發請求
數據模型的革新需求
- 非結構化/半結構化數據的爆發
用戶生成內容(圖片、日志、地理位置)、物聯網傳感器數據等多為動態、無固定結構。關系型數據庫的嚴格模式(Schema)需預先定義表結構,無法靈活適應數據類型的變化 - 靈活性與開發效率
NoSQL 的文檔型(如 MongoDB)、鍵值對(如 Redis)等數據模型允許動態增減字段,無需停機修改表結構,加速了迭代開發周期
當數據模型突破二維結構,NoSQL 提供新思路:
- 數據模型對比
類型數據結構指針邏輯適用場景鍵值數據庫?Key-ValueKey 即數據地址指針緩存(Redis)文檔數據庫?JSON
| 類型 | 數據結構 | 指針邏輯 | 適用場景 |
| 鍵值數據庫 | Key-Value | Key即數據地址指針 | 緩存(Redis) |
| 文檔數據庫 | JSON文檔 | 文檔內嵌指針(_id) | 內容管理(MongoDB) |
| 列族數據庫 | 列簇+行鍵 | 行鍵定位列簇指針 | 日志分析(HBase) |
| 圖數據庫 | 節點+邊 | 邊即關系指針 | 社交網絡(Neo4j) |
文檔文檔內嵌指針(_id)內容管理(MongoDB)列族數據庫列簇+行鍵行鍵定位列簇指針日志分析(HBase)圖數據庫節點+邊邊即關系指針社交網絡(Neo4j)
- ACID 與 BASE 的權衡
- 關系型數據庫:強一致性保障指針精確(ACID)
- NoSQL:最終一致性換取吞吐量(BASE 原則)
BASE: Basically Available(基本可用)Soft-state(軟狀態)Eventually consistent(最終一致)例:微信朋友圈使用 HBase 實現寫擴散,異步同步到好友時間線
4.5. 計算機系統安全
4.5.1. 訪問控制
UID(用戶標識符)
- UID 是內核中用戶的唯一整數標識(0~65535),用于判定進程對文件、設備等資源的訪問權限。
- 根用戶(UID 0):擁有系統最高權限,可繞過所有權限檢查。
- 系統用戶(UID 1–499):供守護進程使用,權限受限。
- 普通用戶(UID ≥500):常規用戶權限范圍。
- 生成方式:
- 本地系統:通過?
/etc/passwd?靜態分配,或 LDAP 動態映射。 - 分布式系統:采用 Snowflake、號段模式、Redis 自增等算法生成全局唯一 UID
- 本地系統:通過?
GID(組標識符)
- 定義與作用:
將多個 UID 歸為一組,統一分配權限(如共享目錄的讀寫權限)。 - 附屬組:
用戶可屬于多個組(通過?/etc/group?配置),進程的權限取所有所屬組的并集
Linux 進程實際運行時涉及四類身份標識:
標識類型縮寫作用實際用戶 IDruid 進程啟動者的原始 UID 有效用戶 IDeuid 權限檢查的依據,決定文件訪問能力保存用戶 IDsuid 臨時存儲 euid,用于權限恢復文件系統用戶 IDfuid
| 標識類型 | 縮寫 | 作用 |
| 實際用戶ID | ruid | 進程啟動者的原始 UID |
| 有效用戶ID | euid | 權限檢查的依據,決定文件訪問能力 |
| 保存用戶ID | suid | 臨時存儲 euid,用于權限恢復 |
| 文件系統用戶ID | fuid | 文件操作時的最終權限標識(通常等于 euid) |
文件操作時的最終權限標識(通常等于 euid)
當進程嘗試訪問文件時,內核比較?euid?和文件屬主的 UID,并檢查文件模式(mode)中的權限位
文件模式(mode):權限規則的載體
文件模式是一個 12 位整數(如?0o40755),分為兩部分:
- 基礎權限(9 位):
rwxr-xr-x:分別定義屬主、屬組、其他用戶的讀/寫/執行權限。
- 特殊權限位(3 位):
- SetUID(4):以文件屬主身份運行進程(euid = 文件屬主 UID)。
- SetGID(2):對文件以屬組身份運行;對目錄則新建文件繼承目錄屬組。
- Sticky Bit(1):目錄內文件僅屬主可刪除(如?
/tmp)
chmod u+s /usr/bin/passwd 此時普通用戶執行 passwd 時,進程 euid 臨時變為 0(root),從而修改 /etc/shadow程序權限需求 SetUID 作用?passwd?修改 /etc/shadow 臨時賦予 root 寫權限?ping?發送 ICMP 包獲取 RAW Socket 權限?sudo
程序 | 權限需求 | SetUID 作用 |
passwd | 修改 /etc/shadow | 臨時賦予 root 寫權限 |
ping | 發送 ICMP 包 | 獲取 RAW Socket 權限 |
sudo | 切換用戶 | 以目標用戶身份執行命令 |
切換用戶以目標用戶身份執行命令
4.5.2. 攻破一個進程
緩沖區溢出
高地址
┌─────────────────┐
│ 參數 │ ← 調用者壓入的參數(若參數過多)
├─────────────────┤
│ 返回地址(EIP)│ ← 函數執行完后跳轉的位置
├─────────────────┤
│ 舊 EBP │ ← 保存調用者的棧幀基址
├─────────────────┤
│ 局部變量 │ ← 當前函數的變量(如 buffer[64])
└─────────────────┘
低地址(棧頂) → ESPESP(棧指針):始終指向當前棧頂(最低地址)
EBP(基址指針):指向當前棧幀的基地址,用于定位參數和局部變量(如[EBP-4]表示第一個局部變量)
EIP(指令指針):存儲下一條待執行指令的地址,被覆蓋后程序將跳轉到攻擊者指定的地址#include <stdio.h>
#include <string.h>void vulnerable() {char buffer[64]; // 局部變量,位于棧幀底部gets(buffer); // 無邊界檢查的輸入函數
}int main() {vulnerable();return 0;
}溢出過程分析
- 棧幀初始化:
- 調用?
vulnerable()時,棧中壓入?main?的返回地址(EIP)和舊 EBP。 - 局部變量?
buffer?分配在舊 EBP 下方(如地址?0xbffff2c0)。
- 輸入超量數據:
- 若用戶輸入 70 字節(如
「A」*68 + 「\xef\xbe\xad\xde」):- 前 64 字節填滿?
buffer。 - 后續 4 字節覆蓋舊 EBP(破壞棧幀鏈)。
- 最后 4 字節覆蓋返回地址(EIP)(如?
0xdeadbeef)。
- 前 64 字節填滿?
- 函數返回時的劫持:
vulnerable()執行?RET?指令時,從棧頂彈出覆蓋后的 EIP?到指令寄存器。- CPU 跳轉到?
0xdeadbeef?執行(可能是攻擊代碼入口)。
攻擊者如何利用此漏洞
攻擊載荷構造
plaintext復制| 填充數據(64 字節) | 覆蓋的 EBP(4 字節) | 惡意代碼地址(4 字節) | Shellcode(惡意指令) |- Shellcode:一段機器碼(如啟動
/bin/sh),通常注入到?buffer?起始位置。 - 覆蓋的 EIP:指向?
buffer?起始地址(需預測地址,或通過 NOP 雪橙增加命中率)。
實際攻擊步驟
- 定位偏移量:
- 通過調試器(如 GDB)確定?
buffer?到 EIP 的偏移(如 72 字節)。
- 繞過保護機制:
- 若系統啟用 ASLR,需結合內存泄露漏洞獲取地址。
- 若啟用棧不可執行(NX),需改用 ROP 鏈(復用已有代碼片段)
防御機制與最佳實踐
編程層防護
- 替換危險函數:
- 用?
fgets(buffer, sizeof(buffer), stdin)替代?gets(),限制輸入長度。
- 用?
- 編譯器增強:
- GCC 的
-fstack-protector:插入金絲雀值(Canary)于 EBP 和局部變量之間,函數返回前校驗其完整性。
- GCC 的
操作系統級防護
機制原理效果?ASLR?隨機化棧/堆/庫的基址,增加預測 EIP 的難度迫使攻擊者需地址泄露漏洞?DEP/NX?標記棧內存為“不可執行”,阻止 Shellcode 運行需結合 ROP 繞過?KPTI?隔離用戶/內核頁表,阻止 Meltdown
| 機制 | 原理 | 效果 |
| ASLR | 隨機化棧/堆/庫的基址,增加預測EIP的難度 | 迫使攻擊者需地址泄露漏洞 |
| DEP/NX | 標記棧內存為“不可執行”,阻止Shellcode運行 | 需結合ROP繞過 |
| KPTI | 隔離用戶/內核頁表,阻止Meltdown類攻擊竊取內核數據 | 緩解旁路攻擊 |
類攻擊竊取內核數據緩解旁路攻擊
硬件漏洞 meltdown
利用 CPU?亂序執行和推測執行的優化缺陷:
- 權限繞過:用戶態程序訪問內核內存(如?
0xffffffffc0000000)觸發異常,但亂序執行已讀取數據。 - 旁路泄露:通過緩存時序攻擊(Cache Timing)推斷內核數據值。例如,根據數組?
array[data*4096]的加載時間差異泄露字節內容
KPTI(內核頁表隔離)防御機制
- 地址空間分割:
- 舊模式:用戶態與內核態共享頁表,用戶可映射內核地址。
- KPTI 模式:用戶進程維護兩份頁表:
- 用戶頁表:僅含用戶空間地址,無內核映射。
- 內核頁表:完整映射內核,僅在陷入內核時切換。
- 性能代價:每次系統調用/中斷需切換頁表(TLB 刷新),導致性能下降 10–20%。
4.6. 虛擬機,容器,微服務
之前 nemu 運行程序只有原來本機性能的 1/10,vmware 做到了什么?使虛擬機成為了商用的產品,即 1 臺 pc 可以虛擬化出 100 臺賣給你,ISP 廠商狂喜。
guest ring3 -> host ring3
- 指令捕獲
- Guest OS 的內核代碼(原需 Ring0)被置于?Host Ring3?執行。
- 當 Guest 執行敏感指令時,CPU 觸發異常(如
#GP),控制權移交 VMware Hypervisor。
- 指令翻譯與模擬
- Hypervisor 截獲異常,解析觸發異常的指令。
- 通過二進制翻譯引擎動態重組代碼塊:
- 將敏感指令(如?
IN/OUT?端口操作)替換為調用 Hypervisor 模擬函數的跳轉指令。 - 生成安全的“重組指令塊”(Translated Code Block),在 Host Ring3 執行模擬邏輯。
- 將敏感指令(如?
- 執行環境隔離
- Guest Ring3 應用:直接運行于 Host Ring3(無需翻譯),性能接近原生。
- Guest Ring0 代碼:翻譯后在 Host Ring3 模擬執行,實現“Ring0 行為”的軟模擬
x86 硬件虛擬化,8 級頁表
影子頁表(Shadow Page Table)的復雜化處理
- 傳統挑戰:
在 4 級頁表時代,VMware 的影子頁表技術已需維護兩套頁表(Guest 頁表 + 影子頁表),并通過缺頁異常同步映射關系。8 級頁表使頁表項數量指數級增長,同步開銷劇增。 - VMware 的優化:
- 選擇性同步機制:僅監控 Guest 修改頁表的行為(如?
mov cr3?指令),而非全量同步,減少 VM Exit 次數。 - 跳轉緩存(Jump Cache):緩存已翻譯的頁表項,避免重復處理相同路徑的頁表遍歷。
- 選擇性同步機制:僅監控 Guest 修改頁表的行為(如?
硬件輔助內存虛擬化(EPT/NPT)的深度整合
- 技術原理:
Intel EPT(Extended Page Tables)和 AMD NPT(Nested Page Tables)允許 CPU 硬件直接處理“Guest 虛擬地址 → Host 物理地址”的兩級轉換,無需 Hypervisor 介入。 - VMware 的創新應用:
- 動態切換機制:默認啟用 EPT/NPT,但在嵌套虛擬化或特殊指令(如?
invvpid)場景下動態切換回影子頁表,兼顧性能與兼容性。 - 大頁(Huge Page)支持:通過 EPT/NPT 直接映射 2MB/1GB 大頁,減少 8 級頁表的遍歷層級,降低 TLB 未命中率
- 動態切換機制:默認啟用 EPT/NPT,但在嵌套虛擬化或特殊指令(如?
操作系統虛擬化---namespace+cggroups - Docker
云時代-微服務-- k8s
serverless--容器的概念也不要了-faas
oversubscribed -》 流量計費 qps
cicd
5. Reference
Model checking 簡述
操作系統原理 (2025 春季學期)
HTTPS://jyywiki.cn/OS/manuals/sysv-abi.pdf
HTTPS://www.cnblogs.com/yubo-guan/p/18804432
HTTPS://www.cnblogs.com/sparkdev/p/11605804.HTML
深入了解之鏈接器與加載器_加載器_邱學喆_InfoQ 寫作社區
HTTPS://book.douban.com/subject/3652388/、
HTTPS://www.cnblogs.com/yikoulinux/p/14470713.HTML

)




)
:等價類和判定表)
![week5-[二維數組]翻轉](http://pic.xiahunao.cn/week5-[二維數組]翻轉)



Python異步爬蟲與K8S彈性伸縮:構建百萬級并發數據采集引擎)




:面向工業運營的全自動無人機解決方案)

