人民幣存款利率是影響居民儲蓄行為和企業資金配置的關鍵因素,也是宏觀經濟調控的重要工具。中國銀行根據中國人民銀行的指導政策,結合市場情況與自身經營策略,定期調整并公布人民幣存款利率標準。這些利率信息主要涵蓋活期存款、定期存款(如整存整取、零存整取、通知存款、協定存款等)等多個產品類別,覆蓋三個月、半年、一年、二年、三年、五年等不同存期,全面反映銀行對不同期限資金的定價策略。
為提升信息透明度與數據可用性,本文將探討如何通過程序化方式,利用 GET 請求從中國銀行官方網站的公開頁面中獲取人民幣存款利率數據。通過 Python 編程語言中的 requests 庫發送 HTTP 請求,模擬瀏覽器行為訪問利率公告頁面,并結合 BeautifulSoup 或 json 模塊解析返回的 HTML 或結構化數據,實現對利率信息的自動化采集。采集內容包括利率發布日期、各存期對應的年利率數值、利率調整說明等關鍵字段,形成結構化的數據集。
此類數據采集方法不僅有助于實時跟蹤中國銀行的利率變動趨勢,還可用于分析其利率定價策略的周期性規律、與其他商業銀行的利率差異以及與宏觀經濟指標(如CPI、LPR、貨幣政策)之間的關聯性。通過對歷史利率數據的清洗、整理與可視化分析,可為個人投資者的資產配置決策、金融機構的市場研究以及學術領域的金融政策評估提供有力的數據支持。此外,構建自動化的利率監控系統,也有助于提升金融信息獲取的效率與準確性,助力智慧金融生態的發展。
中國銀行人民幣存款利率列表:中國銀行網站_金融市場_存/貸款利率_人民幣存款利率
首先,我們找到門店數據的存儲位置,然后看3個關鍵部分標頭、負載、?預覽;
標頭:通常包括URL的連接,也就是目標資源的位置;
負載:對于GET請求:負載通常包含了傳遞的參數,有些網頁負載可能為空,或者沒有負載,因為所有參數都通過URL傳遞,這里我們可以看到并沒有負載;
預覽:指的是對響應內容的快速查看或摘要顯示,可以幫助用戶快速了解返回的數據結構或內容片段;

接下來就是數據獲取部分,先講一下方法思路,一共三個步驟;
方法思路
- 找到對應數據存儲位置,獲取所有店鋪列表的相關標簽數據;
- 我們通過改變店鋪id和店鋪name,來遍歷全國門店數據;
- 地址轉經緯度,通過coord-convert庫實現GCJ-02轉WGS84;
這里,我們找到數據的位置之后,我們發現這個人民幣存款利率數據每個都是一個單獨的html,我們需要遍歷所有的html,才能獲取完整的數據;
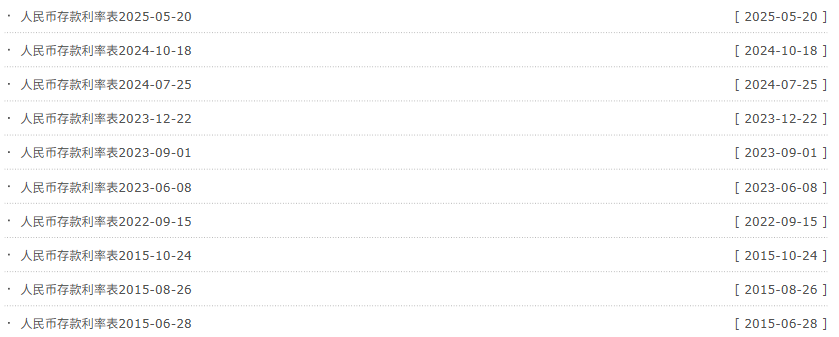
那么,我們先要找到這頁面對應的URL的儲存位置,因為每個html對應的頁面url都不一樣,這里我們以人民幣存款利率表2025-05-20的html為例,我們通過Ctrl + F 檢索20250520,就可以在響應里找到數據對應的儲存位置;
![]()
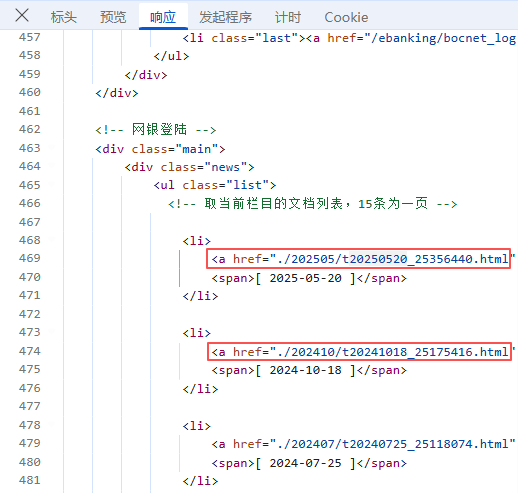
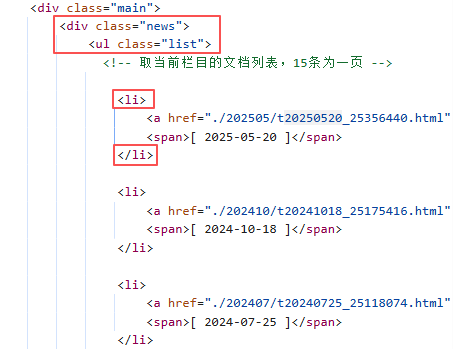
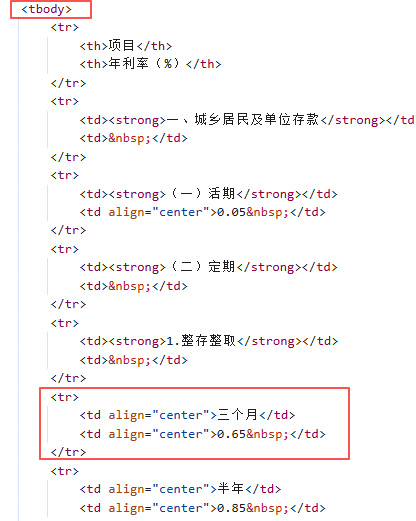
接下來,我們就需要找到數據儲存的特定標簽,先定位到包含主要內容的 <div class="news"> 容器,從該容器中找到存放所有歷史鏈接的無序列表 <ul class="list">。遍歷每個 <li> 條目,從中提取出鏈接和日期信息;
還有一個問題,數據是包含2頁的,我們訪問第二頁的時候是需要通過另外一個html,我們先來觀察規律,可以看到URL由index.html →index_1.html;
第一頁 (current_page = 1): page_url = base_url + "index.html" → https://www.bankofchina.com/fimarkets/lilv/fd31/index.html
第二頁 (current_page = 2): page_url = base_url + "index_1.html" → https://www.bankofchina.com/fimarkets/lilv/fd31/index_1.html
第一步:那么我們先獲取包含中國銀行人民幣存款利率列表所有日期和URL的響應數據,并另存為csv;
完整代碼#運行環境 Python 3.1
import requests
from bs4 import BeautifulSoup
import csv
from datetime import datetime# --- 請求頭 ---
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Mobile Safari/537.36 Edg/139.0.0.0'
}# --- 兩個頁面的URL ---
urls = ["https://www.bankofchina.com/fimarkets/lilv/fd31/index.html", # 第一頁"https://www.bankofchina.com/fimarkets/lilv/fd31/index_1.html" # 第二頁
]def extract_links_from_url(page_url):"""從單個頁面URL中提取所有利率表鏈接。"""print(f"正在抓取: {page_url}")try:response = requests.get(page_url, headers=headers, timeout=10)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')links = []# 直接定位到新聞列表中的每個條目for li in soup.select('div.news ul.list li'):a_tag = li.find('a')span_tag = li.find('span')if a_tag and span_tag:# 構建完整URLhref = a_tag['href']# 處理相對路徑和絕對路徑if href.startswith("http"):full_url = hrefelif href.startswith("/"):full_url = "https://www.bankofchina.com" + hrefelse:full_url = "https://www.bankofchina.com/fimarkets/lilv/fd31/" + href.lstrip("./")date = span_tag.get_text(strip=True).strip('[] ')links.append({'date': date, 'url': full_url})print(f"從該頁面找到 {len(links)} 個鏈接。")return linksexcept Exception as e:print(f"抓取 {page_url} 時出錯: {e}")return []# --- 主執行流程 ---
if __name__ == "__main__":print("開始抓取中國銀行人民幣存款利率表鏈接...\n")all_links = []for url in urls:page_links = extract_links_from_url(url)all_links.extend(page_links)# 去重 (基于URL)seen_urls = set()unique_links = []for link in all_links:if link['url'] not in seen_urls:seen_urls.add(link['url'])unique_links.append(link)# 按日期倒序排列 (假設日期格式為 YYYY-MM-DD)unique_links.sort(key=lambda x: x['date'], reverse=True)# --- 保存為CSV ---filename = f"中國銀行存款利率鏈接_{datetime.now().strftime('%Y%m%d')}.csv"try:with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: # utf-8-sig 防止Excel亂碼fieldnames = ['日期', 'URL']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for link in unique_links:writer.writerow({'日期': link['date'], 'URL': link['url']})print(f"\n數據已成功保存到: {filename}")print(f"文件包含 {len(unique_links)} 條記錄。")except Exception as e:print(f"保存CSV文件時出錯: {e}")print("\n抓取與保存任務全部完成。")數據會以csv表格的形式,保存在運行腳本的目錄下,數據標簽包括:日期、中國銀行人民幣存款利率列表的URL;
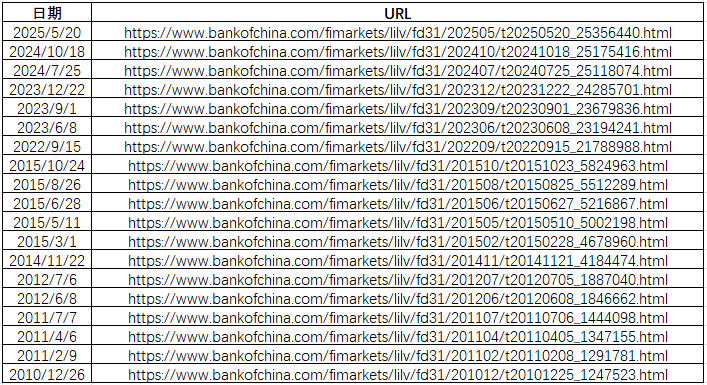
接下來,我們就來獲取每個網頁的整存整取利率表,這里僅選取1年—5年利率作為數據源,先找到 <table>,遍歷所有 <tr> 行,設置一個標志 in_fixed_deposit = False,當遇到 <strong>1.整存整取</strong> 時,將其設為 True,在 in_fixed_deposit 為 True 的狀態下,如果某行的第一個 <td> 文本是 '一年', '二年', '三年','五年',則提取第二個 <td> 的文本作為利率;
第二步:遍歷所有URL,并利用GET請求獲取所有整存整取1年—5年利率表,并根據標簽進行保存,另存為csv;
完整代碼#運行環境 Python 3.11
import requests
from bs4 import BeautifulSoup
import csv
from datetime import datetime
import re
import time# 配置
INPUT_CSV = "中國銀行存款利率鏈接_20250825.csv"
OUTPUT_CSV = f"整存整取利率_中國銀行_{datetime.now().strftime('%Y%m%d')}.csv"HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}def read_links():"""讀取CSV鏈接"""with open(INPUT_CSV, encoding='utf-8-sig') as f:return [row for row in csv.DictReader(f)]def extract_rates(url):"""提取利率"""res = requests.get(url, headers=HEADERS, timeout=10)res.encoding = 'gbk' if 'gbk' in res.headers.get('Content-Type', '') else 'utf-8'soup = BeautifulSoup(res.text, 'html.parser')table = soup.find('table')if not table:return {'一年': 'N/A', '二年': 'N/A', '三年': 'N/A', '五年': 'N/A'}rates = {}in_fixed = Falsefor row in table.find_all('tr'):cols = row.find_all('td')if len(cols) < 2: continuet1 = re.sub(r'\s+', '', cols[0].get_text(strip=True))t2 = re.sub(r'\s+', '', cols[1].get_text(strip=True))if "1.整存整取" in t1:in_fixed = Truecontinueif in_fixed and t1 in ['一年', '二年', '三年', '五年']:rate = re.search(r'(\d+\.?\d*)', t2)rates[t1] = rate.group(1) if rate else 'N/A'if in_fixed and any(k in t1 for k in ["2.零存整取", "3.定活兩便"]):break # 提前退出,提高效率return {k: rates.get(k, 'N/A') for k in ['一年', '二年', '三年', '五年']}# 主程序
print("開始提取...")
links = read_links()
results = []for i, link in enumerate(links, 1):print(f"[{i}/{len(links)}] {link['日期']}")rates = extract_rates(link['URL'])results.append({'日期': link['日期'],'一年利率(%)': rates['一年'],'二年利率(%)': rates['二年'],'三年利率(%)': rates['三年'],'五年利率(%)': rates['五年']})time.sleep(0.3)# 保存
with open(OUTPUT_CSV, 'w', newline='', encoding='utf-8-sig') as f:w = csv.DictWriter(f, ['日期', '一年利率(%)', '二年利率(%)', '三年利率(%)', '五年利率(%)'])w.writeheader()w.writerows(results)print(f"完成!結果已保存至: {OUTPUT_CSV}")
數據會以csv表格的形式,保存在運行腳本的目錄下,數據標簽包括:日期、一年利率(%)、二年利率(%)、三年利率(%)、五年利率(%);
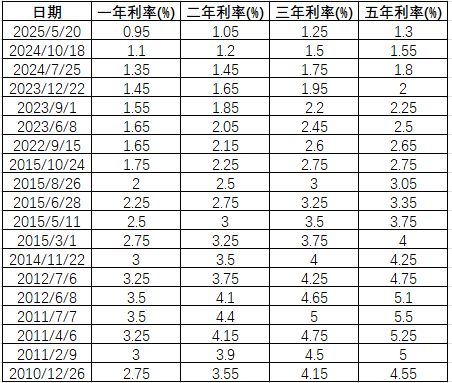
接下來,我們繪制成可視化的效果來觀察人民幣存款利率變化情況;
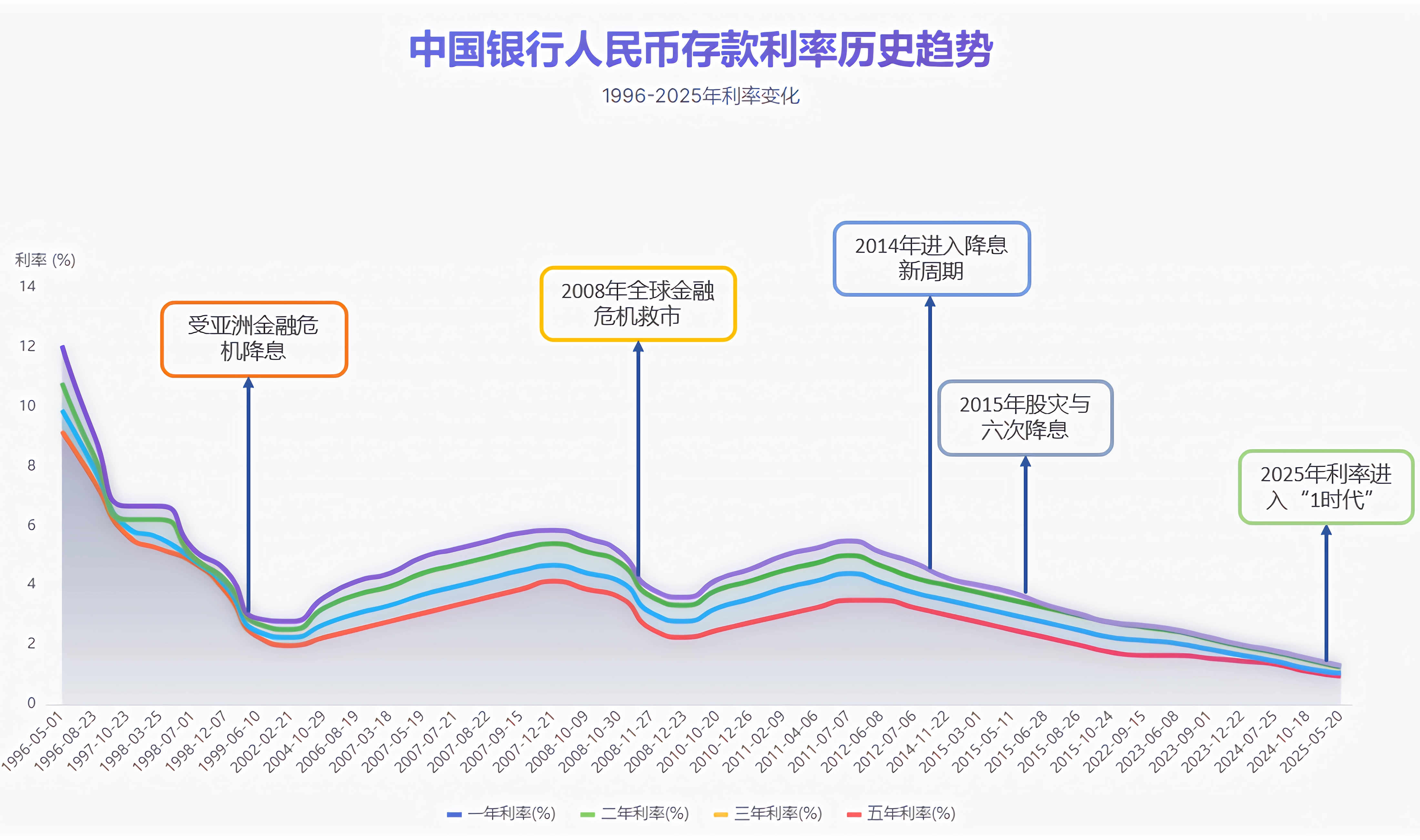
接下來,我們進行看圖說話:
從1996年至2025年,中國銀行人民幣存款利率經歷了深刻而顯著的演變過程,整體呈現出一條清晰的長期下行軌跡。 這一趨勢貫穿了近三十年的經濟變遷,反映出中國宏觀經濟環境的深刻轉型以及貨幣政策在不同發展階段的調控邏輯。在1996年初期,存款利率處于歷史高位,五年期利率一度接近12%,一年期利率也高達9%以上,顯示出當時高通脹背景下的資金成本水平和較為緊縮的金融環境。
進入1998年后,受亞洲金融危機及國內通縮壓力影響,央行多次下調利率,標志著高利率時代的結束。 利率迅速回落,五年期利率降至5%以下,三年期和一年期利率也同步下行。這一階段的降息不僅是為了應對外部沖擊,更是推動國有企業改革、化解銀行不良資產和促進經濟結構調整的重要手段。此后直至2007年,利率進入一個相對平穩的波動期,各期限利率在3%至6%區間內小幅震蕩,反映出經濟高速增長背景下貨幣政策的審慎與穩定。
2008年全球金融危機成為又一個關鍵轉折點,利率波動顯著加劇。 為應對外部沖擊,中國實施了大規模經濟刺激計劃,利率再次大幅下調,一年期利率一度跌破2%。隨后隨著經濟復蘇和通脹回升,利率在2010年至2011年期間出現短暫反彈,三年期利率一度接近5%。這一階段顯示出貨幣政策強烈的逆周期調節特征,利率成為穩定經濟增長的重要工具。
自2015年起,利率進入新一輪持續下行通道,反映出經濟增速換擋與結構性調整的新常態。 隨著人口紅利減弱、房地產市場調整以及外部環境不確定性上升,貨幣政策持續寬松,各期限利率普遍回落。至2025年,一年期利率已降至不足1%,五年期利率也降至2%左右,表明當前處于低增長、低通脹背景下的長期寬松格局。這一階段的降息不僅旨在降低實體經濟融資成本,也體現了金融讓利實體經濟的政策導向。
從期限結構看,短期利率波動更為劇烈,而中長期利率相對平穩。 一年期和二年期利率對政策調整和經濟周期反應靈敏,常作為貨幣政策操作的先導指標;而三年期和五年期利率則更多體現市場對未來經濟走勢的長期預期,其走勢相對平緩,利差結構基本穩定,未出現明顯倒掛,說明銀行體系的期限溢價機制仍在正常運行。
綜合來看,過去近三十年的利率走勢,是中國從高速增長邁向高質量發展轉型過程的金融映射。 利率的逐步降低既是對實體經濟融資成本的讓利,也是金融深化與市場化改革推進的結果。展望未來,在人口老齡化、潛在增長率下降和全球低利率環境的大背景下,存款利率或將維持低位運行,但其變化仍將緊密跟隨宏觀經濟復蘇節奏與政策導向,成為觀察中國經濟健康狀況的重要窗口。
文章僅用于分享個人學習成果與個人存檔之用,分享知識,如有侵權,請聯系作者進行刪除。所有信息均基于作者的個人理解和經驗,不代表任何官方立場或權威解讀。




)


)
![BigFoot (Method Raid Tools)[MRT] (Event Alert Mod)[EAM]](http://pic.xiahunao.cn/BigFoot (Method Raid Tools)[MRT] (Event Alert Mod)[EAM])
)

環境配置(Linux))







