一、概要
1.分布式爬蟲概念
????????分布式爬蟲是一種利用多臺機器協同工作的網絡爬蟲系統,通過任務分解、并行處理和資源共享,高效抓取并處理海量網頁數據。其核心在于將爬取任務分配到不同節點,避免單點性能瓶頸,同時支持動態擴展和容錯機制,適用于大規模數據采集場景。
? ? ? ? 在爬蟲眾多框架中,scrapy-redis是最常用的實現分布式爬蟲的框架,它區別于之前我們學習的scrapy,它將Redis作為他的調度器隊列,所有的請求對象均從Redis獲取,Redis的set集合會自動對所有請求對象進行去重,從實現了多臺機器同時爬取和斷點續爬的功能。
2.分布式爬蟲流程
? ? ? ? 下圖形象的展示了scrapy-redis的工作流程,可以看到和我們之前的scrapy的spider,schedule換了個方向,spider被放到了最上方。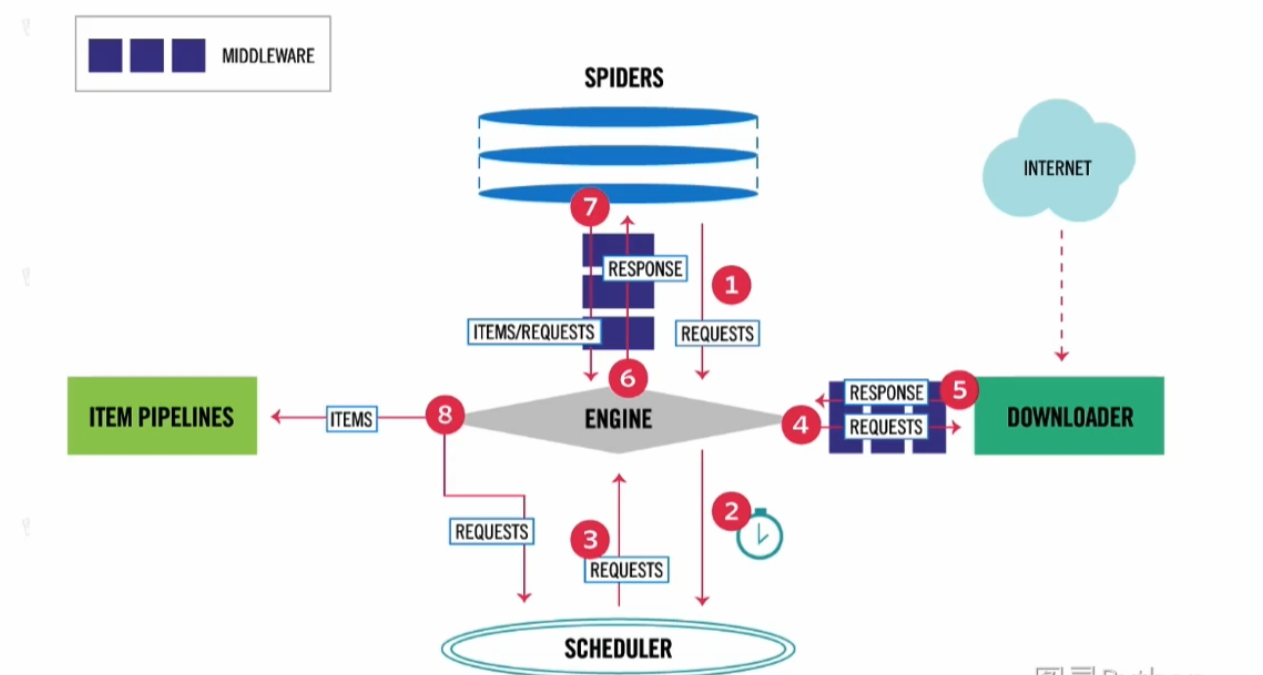
? ? ? ? 下面這個圖更加形象的展示四臺主機同時連接Redis服務器進行爬蟲的過程。當然我們也可以擴充到多臺主機的情況。在scrapy-redis中,Redis服務端被稱作master主機,而把用于跑爬蟲程序的機器稱為slave。
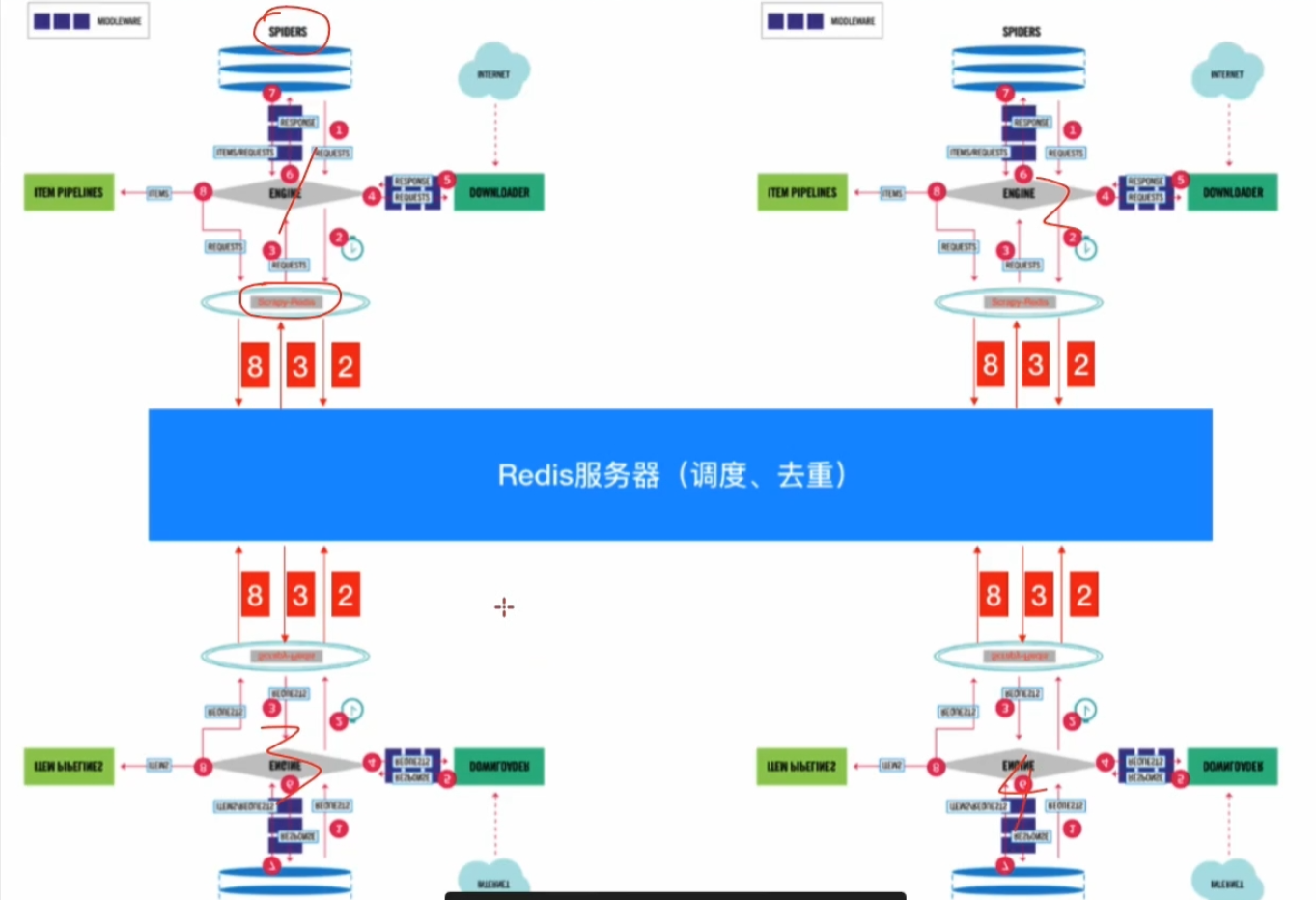
? ? ? ? 簡要概括,scrapy-redis的工作流程如下:
- 調度器共享:所有爬蟲實例共享同一個 Redis 中的請求隊列,新發現的 URL 會被統一存入隊列。
- 請求去重:利用 Redis 的集合結構(Set)對請求 URL 進行全局去重,避免重復爬取。
- 任務分配:各爬蟲從 Redis 隊列中競爭獲取待爬 URL,實現負載均衡。
- 數據存儲:爬取到的數據可統一存入 Redis 或其他存儲系統(如數據庫)。
- 斷點續傳:Redis 持久化保存爬取進度,支持暫停后恢復。
二、分布式爬蟲準備
1.準備工作
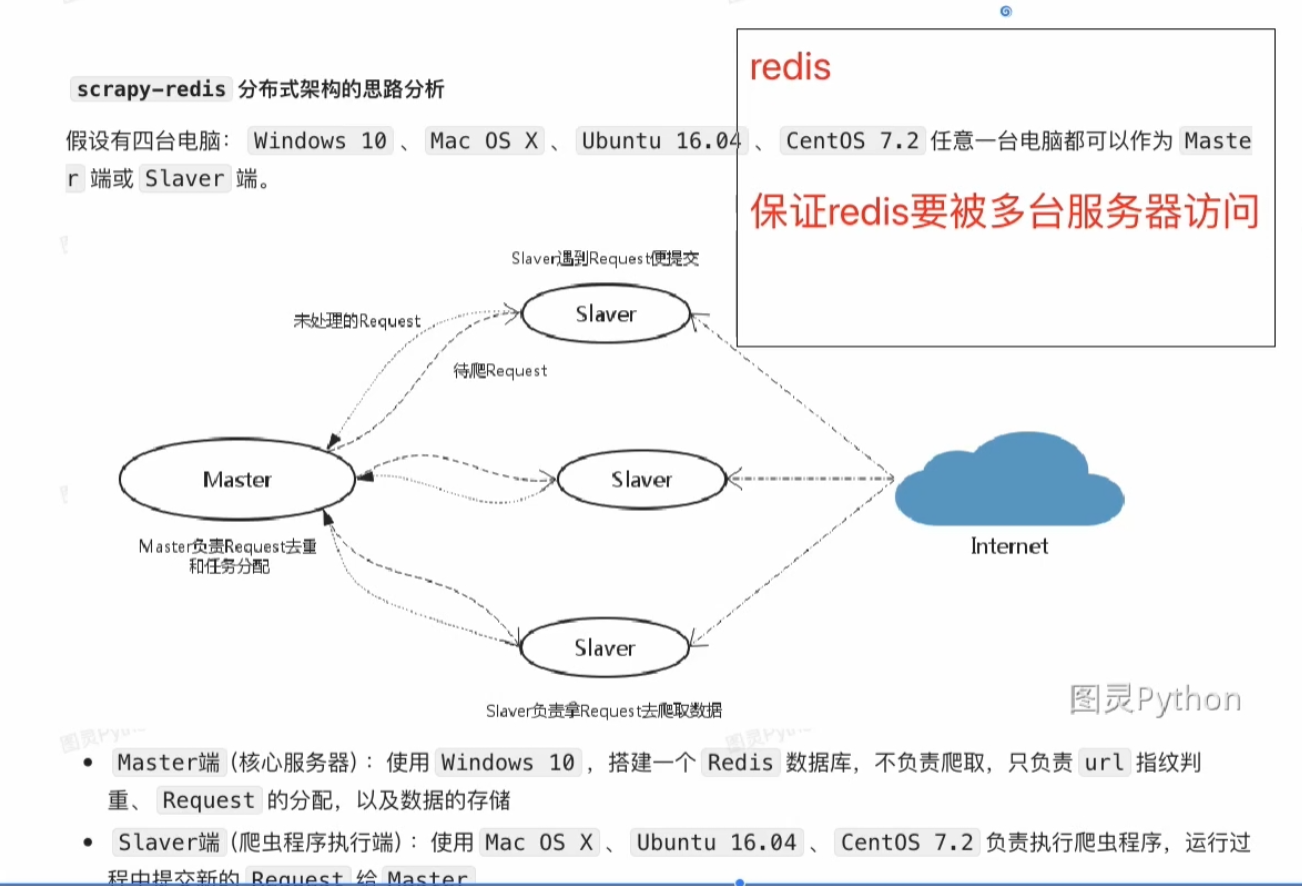
? ? ? ? 我們準備三臺電腦進行分布式爬取,(忽略圖中的centos),其中遠程Ubuntu16.04作為我們的Redis服務器(master端),不負責爬取,只負責數據的分配。而使用Windows和另外一臺本地虛擬機Ubuntu16.04作為slaver端進行爬蟲的執行。
????????
???????????
2.Master端配置
? ? ? ? 首先我們在遠程ubuntu服務器上安裝Redis,命令如下:
sudo apt install redis-server? ? ? ? 接下來我們嘗試打開redis-cli,并ping,如果返回pong就說明安裝成功了。命令如下:
redis-cli
ping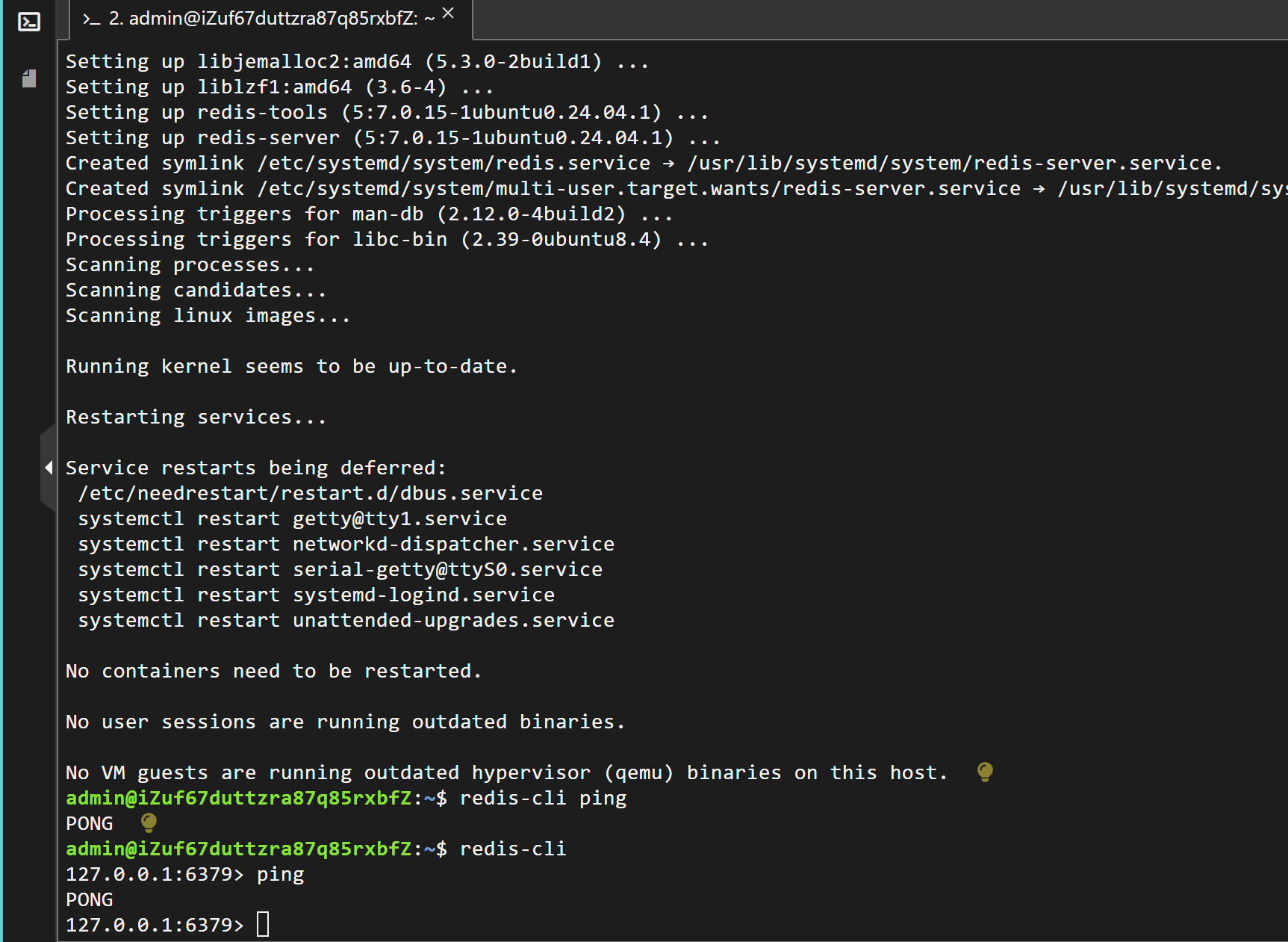
? ? ? ? 接下來我們要配置Redis,允許遠程主機連接。操作如下:
sudo vi /etc/redis/redis.conf? ? ? ? ? ? ?? 第一步,將bind 127.0.0.1注釋掉。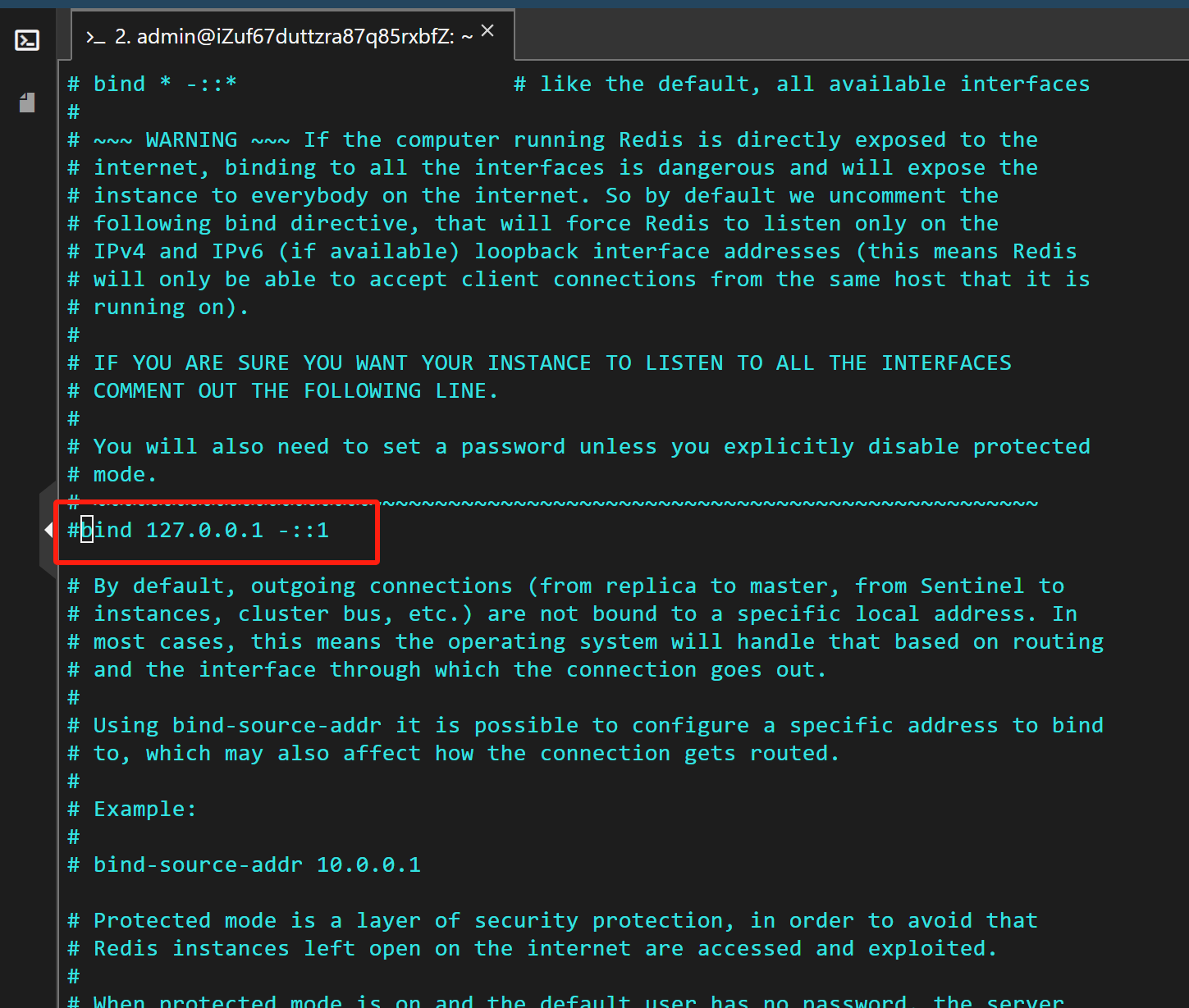
? ? ? ? 第二步,將protected mode從yes改成no。關閉保護模式。
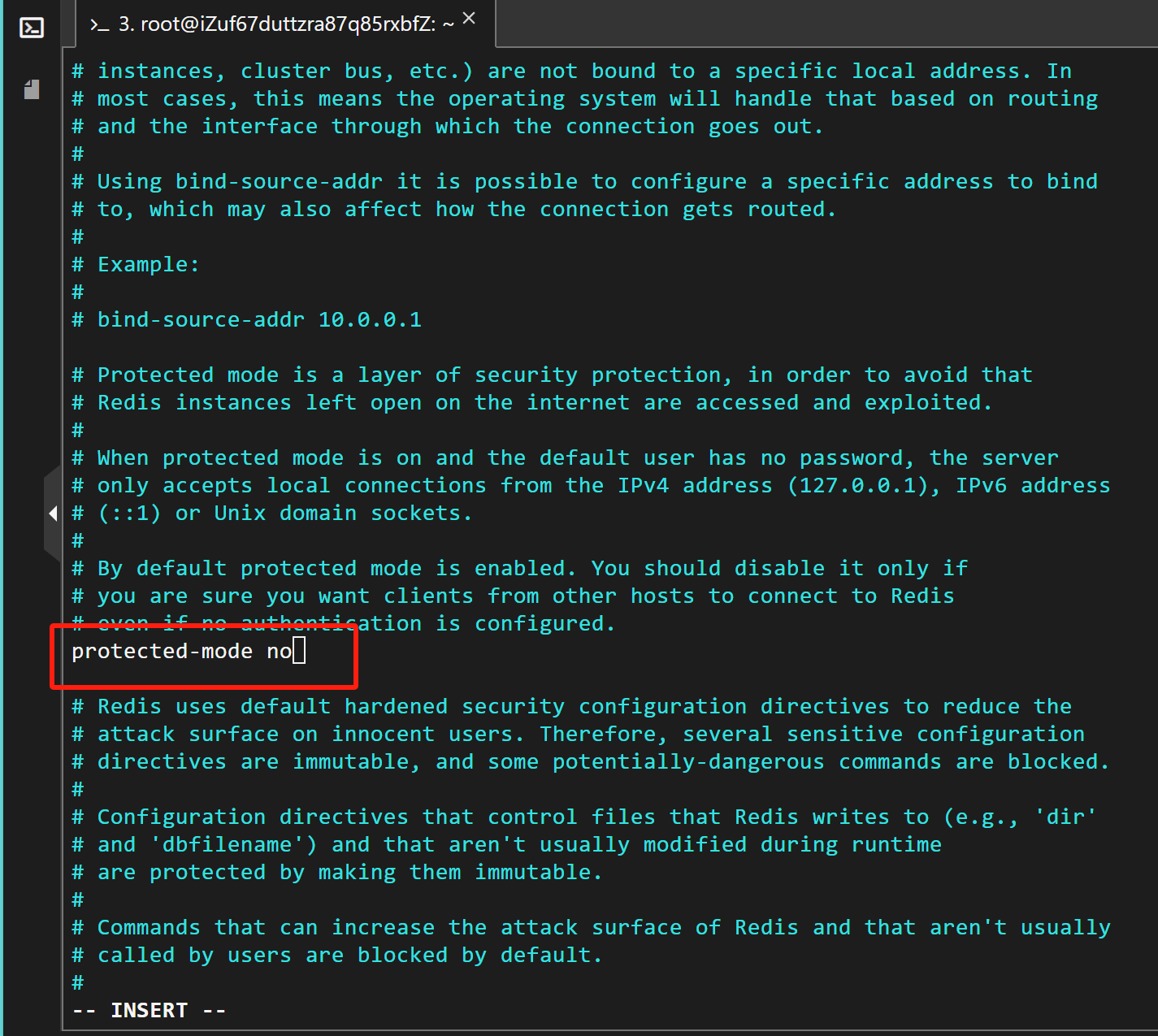
? ? ? ? 然后按ESC,輸入:wq!保存,輸入下面命令重啟Redis即可。
sudo systemctl restart redis-server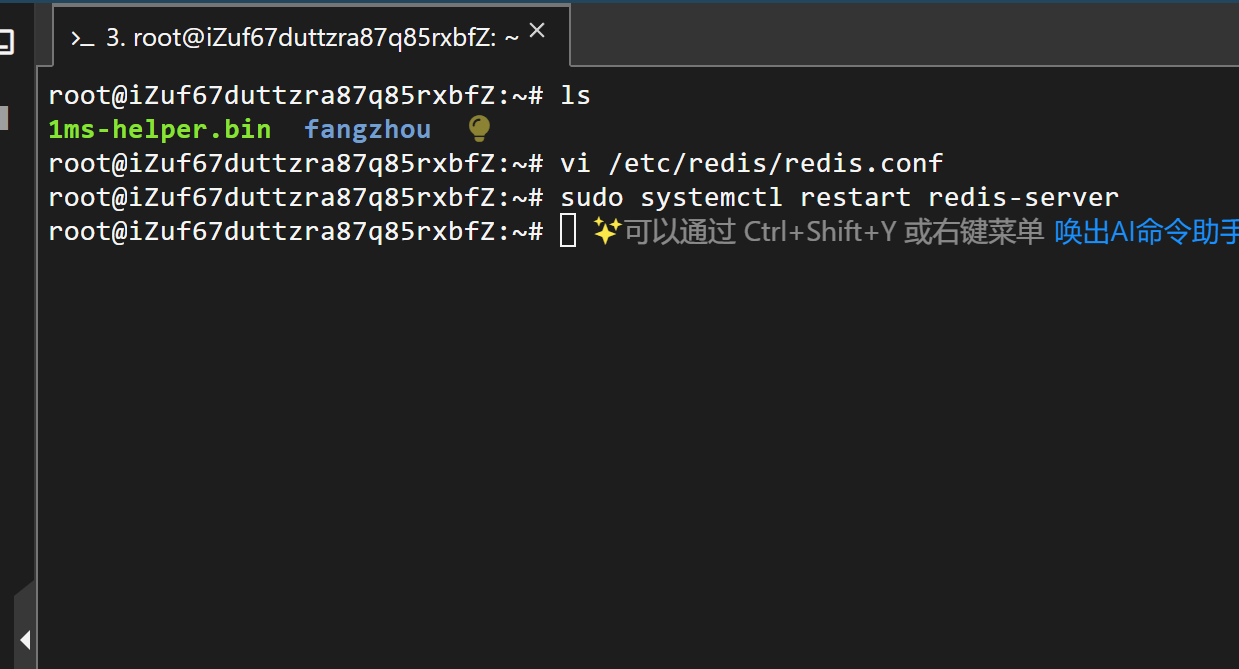
? ? ? ?然后準備好Redis的主機IP地址,后續連接需要要到。
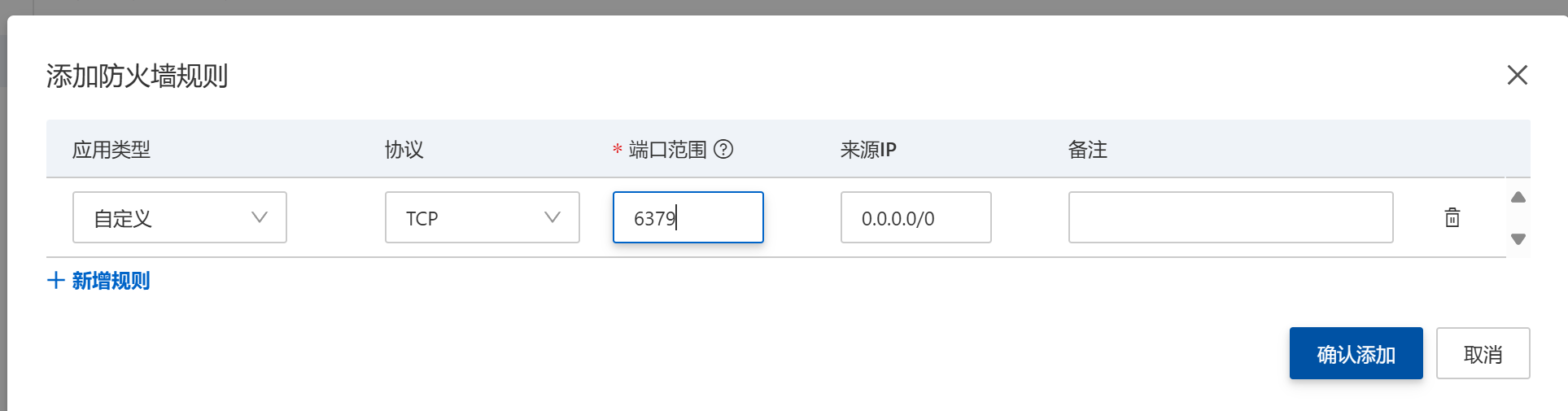
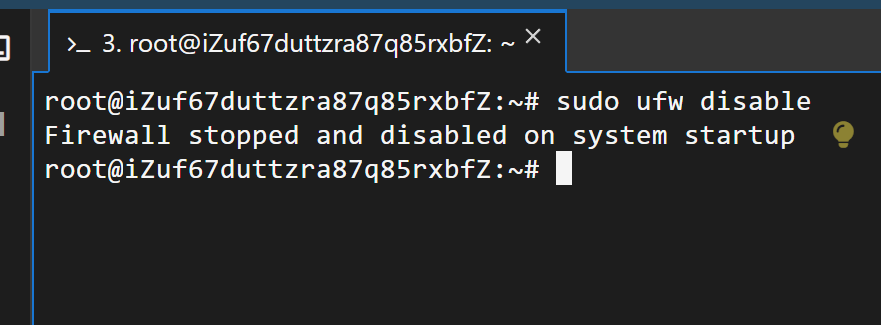
????????如果你是遠程Redis的話,不要忘了關閉防火墻,并開放相應的6379端口。本地的話就不用了。
3.Slaver端配置
? ? ? ? 首先我們給兩臺slaver分別安裝上scrapy和scrapy-redis,注意scrapy安裝2.8以下的版本,這樣才能和scrapy-redis兼容,scrapy-redis安裝最新版本即可。輸入以下命令即可安裝。
? ? ? ? 注意!!!這里一定要重新安裝twisted舊版本,因為新版本的scrapy不兼容。所以下圖的命令還要再加一個。
pip install twisted==22.10.0
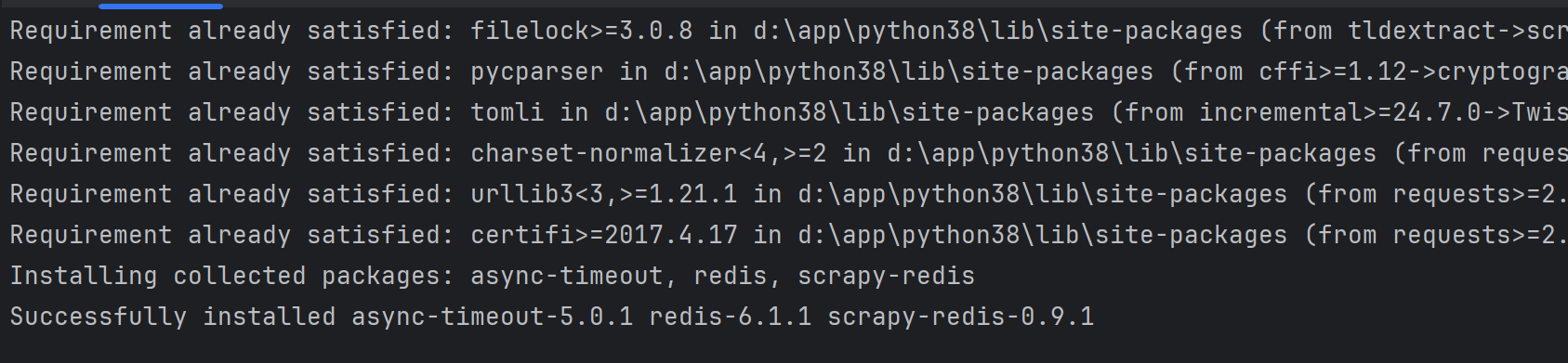
? ? ? ? 安裝完成之后接下來我們測試一下兩臺slaver能否正常連接Redis服務器。
? ? ? ? 可以直接在slaver端裝上Redis的圖形化界面控制端,用來測試Redis的連接。當然,如果是ubuntu,也可以通過運行Python腳本來測試是否能夠正常連接Redis。這里給出方法:
- ?對于Windows
????????安裝包:https://wwql.lanzout.com/b052o0lmf,密碼:3rsj。
????????鏈接中包含redis圖形化界面和redis安裝包,我們只需要安裝圖形化界面即可。我這里臨時測試,就不下載工具了,直接用PyCharm的自帶的Redis鏈接工具連接了。如果你對PyCharm不太熟悉,建議直接使用圖形化界面。
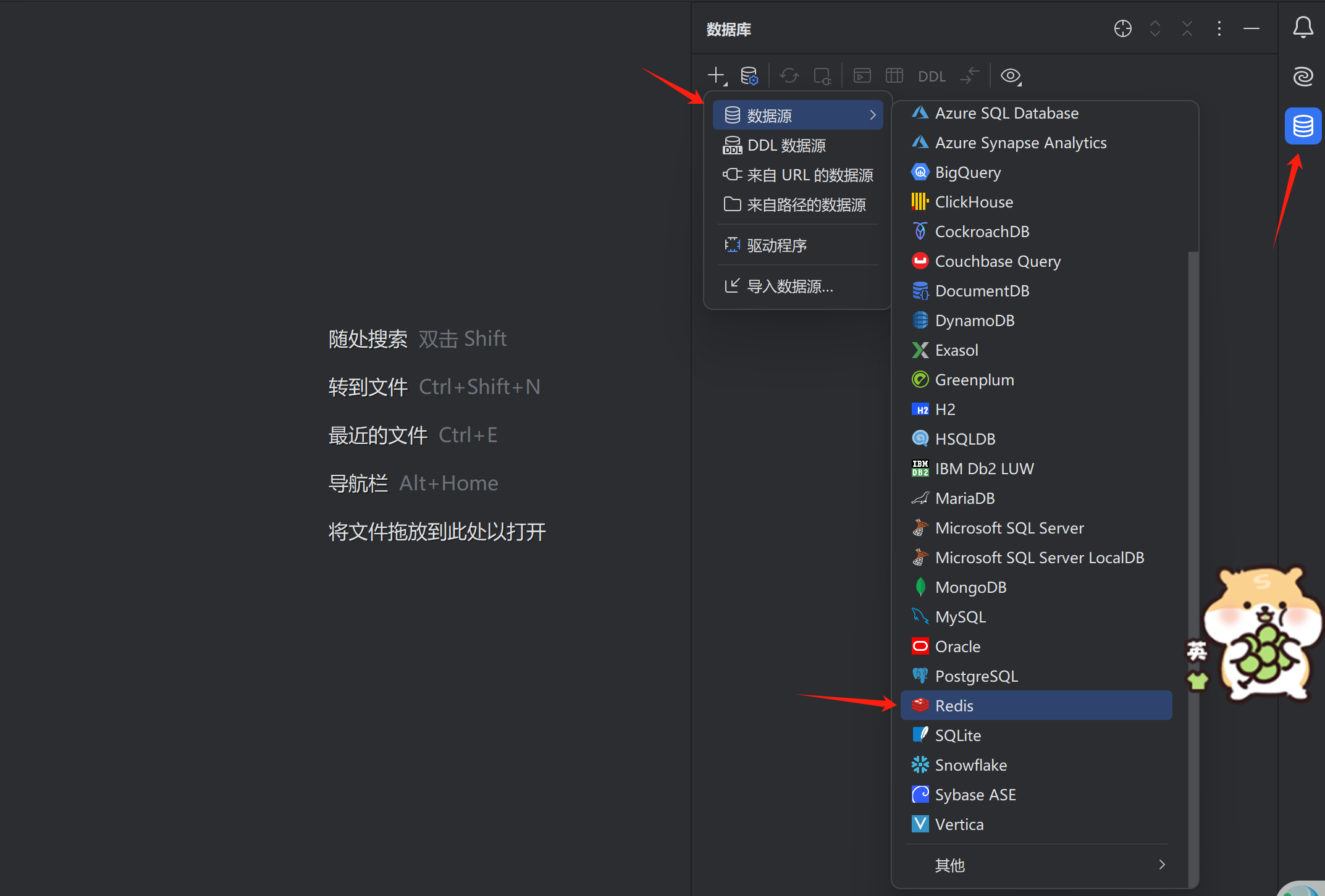
? ? ? ? 下面給出在PyCharm中鏈接Redis的方法:
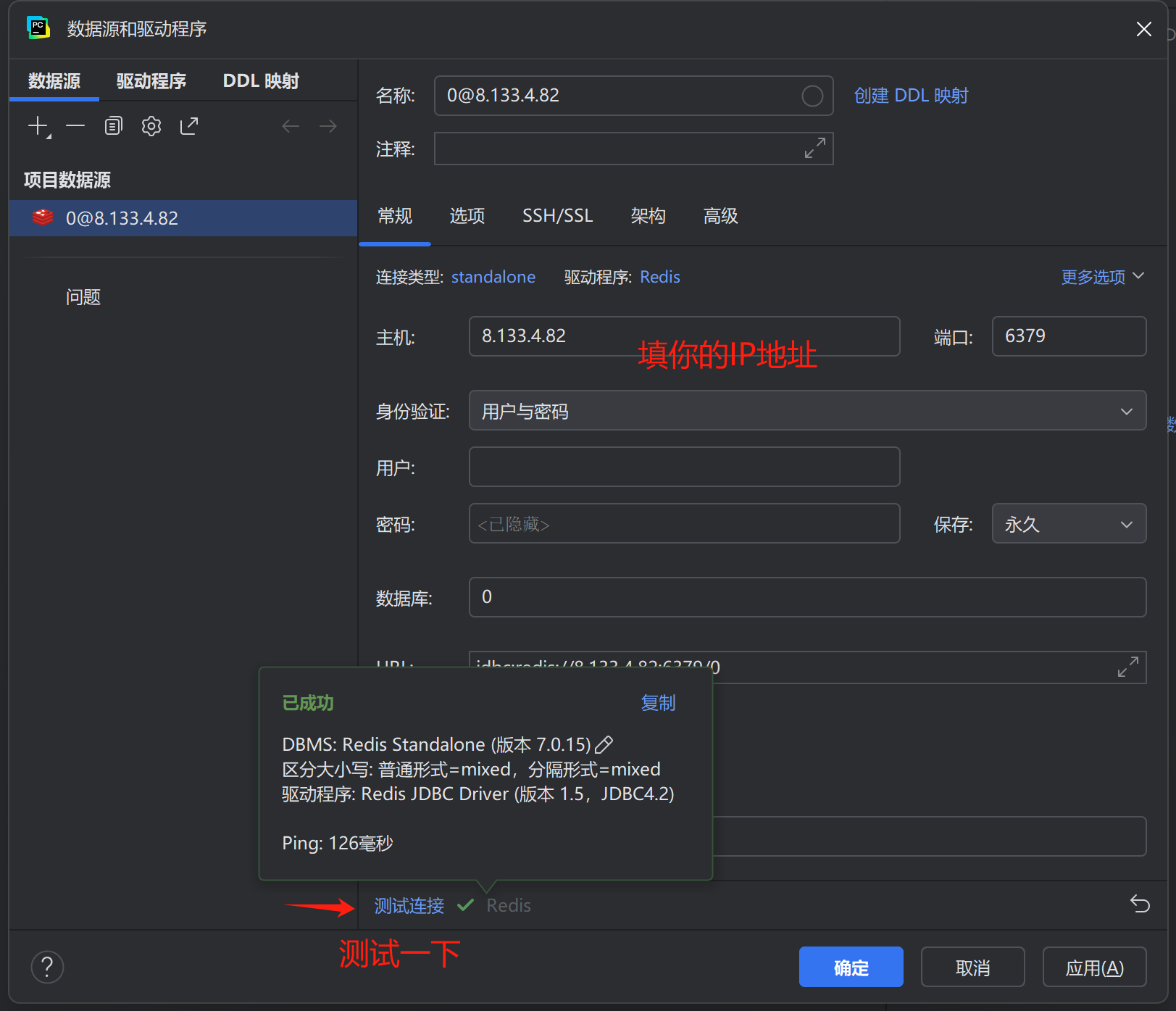
- 對于Ubuntu
? ? ? ? 我們采用一個簡單的Python腳本來測試是否能夠正常連接Redis服務器。腳本如下,注意主機和其它選項要改成你自己的:
import redisdef test_redis_connection(host, port=6379, password=None, db=0):"""測試Redis連接:param host: Redis服務器地址:param port: 端口 (默認6379):param password: 密碼 (可選):param db: 數據庫編號 (默認0)"""try:# 創建Redis連接r = redis.Redis(host=host,port=port,password=password,db=db,socket_timeout=3 # 3秒超時)# 發送PING命令測試連接response = r.ping()if response:print(f"? 連接成功!Redis版本: {r.info()['redis_version']}")return Trueexcept Exception as e:print(f"? 連接失敗: {str(e)}")return Falseif __name__ == "__main__":# 在此處填寫Redis連接信息HOST = "your_redis_host" # 替換為實際主機IP/域名PORT = 6379 # 替換為實際端口PASSWORD = None # 如有密碼,替換為字符串(如: "mypassword")DB = 0 # 替換為實際數據庫編號# 執行測試test_redis_connection(host=HOST,port=PORT,password=PASSWORD,db=DB)三、分布式爬蟲實現
? ? ? ? scrapy-redis的分布式爬蟲實現步驟可以總結為以下幾步:
- ? ? ? ? 編寫scrapy爬蟲項目
- ????????更換默認spider父類為Redis類
- ? ? ? ? 修改配置文件setting.py
- ? ? ? ? 設置起始url的key 為[top250:start_urls]??
1.爬蟲生成
? ? ? ? 這里我們用最經典的豆瓣電影top250作為示例。首先在控制臺輸入下面命令生成爬蟲項目。
#創建項目
scrapy startproject douban
cd douban
#創建Spider
scrapy genspider movie_rank movie.douban.com
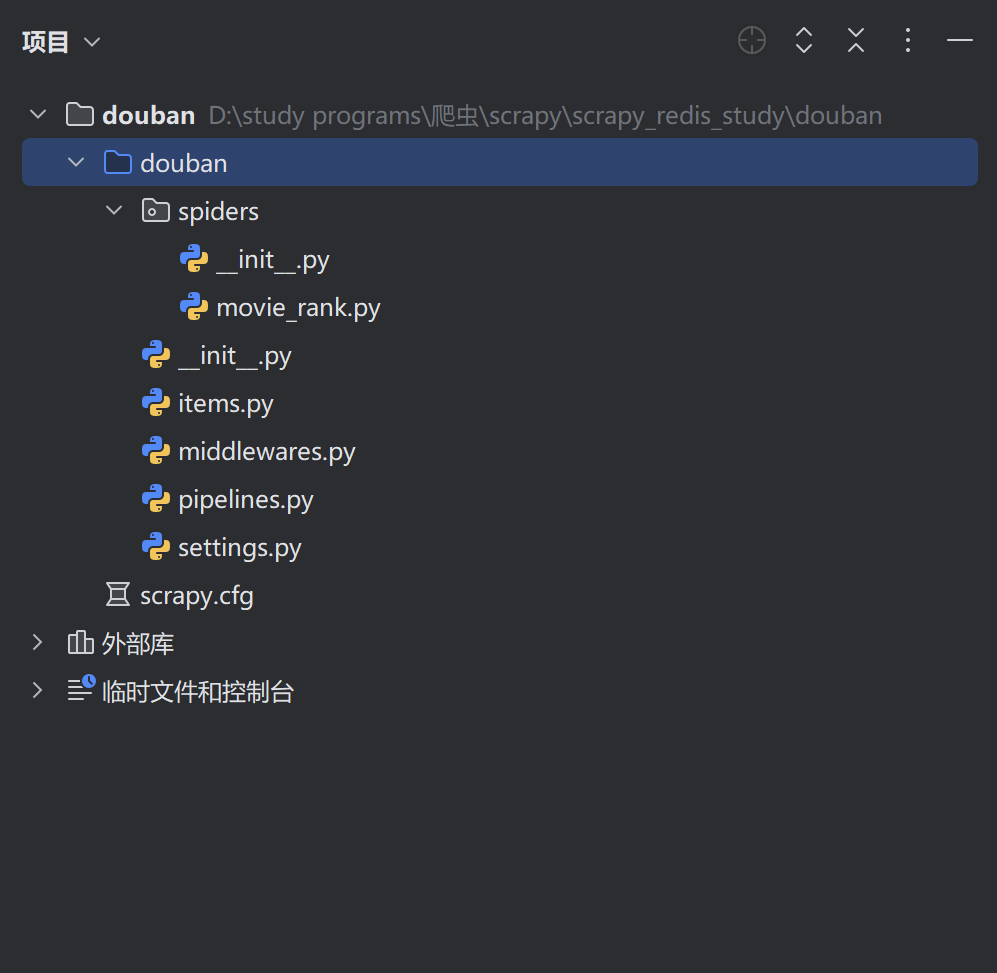
? ? ? ? 生成的項目目錄如下:
? ? ? ? 接著這里我直接復制使用之前已經寫好了的豆瓣top250爬蟲邏輯,建議先提前將基礎爬蟲邏輯用scrapy寫完,然后修改成scrapy-redis即可。
? ? ?具體的代碼邏輯可以直接參考我之前的文章,scrapy爬取豆瓣250。
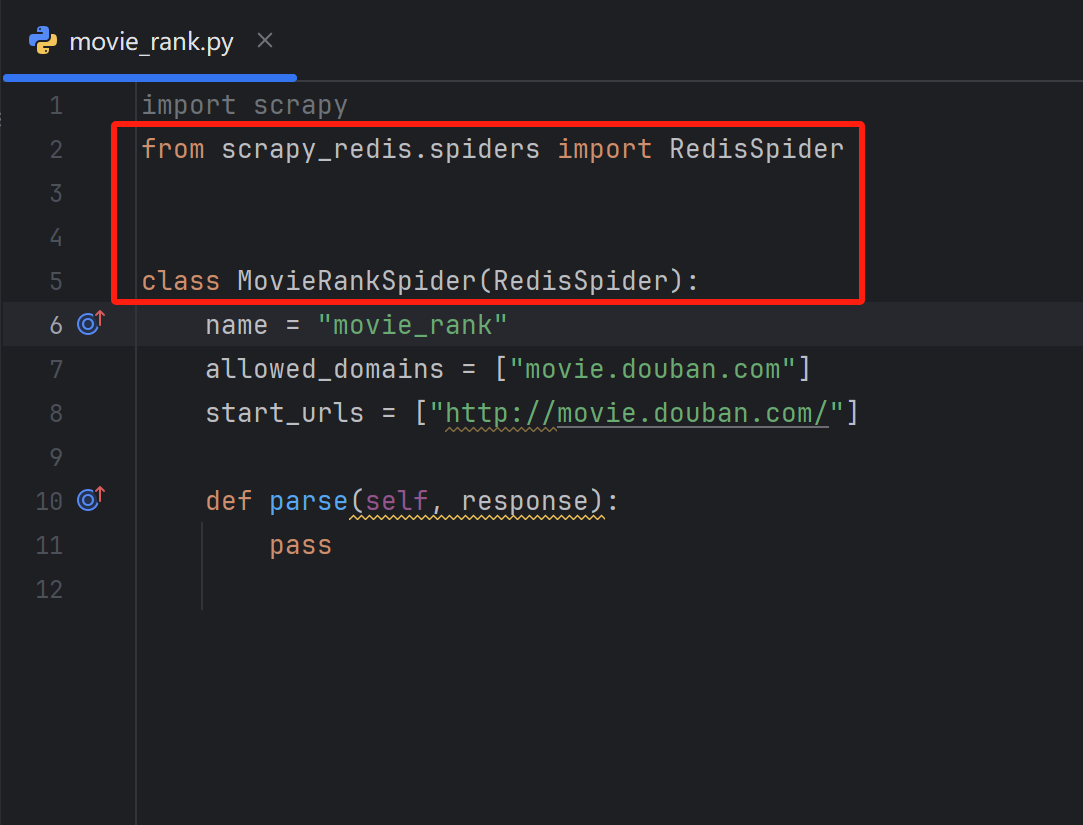
2.修改父類
? ? ? ? 打開movie_rank.py,導入Scrapy_redis的redis-spider,然后讓爬蟲類繼承它。
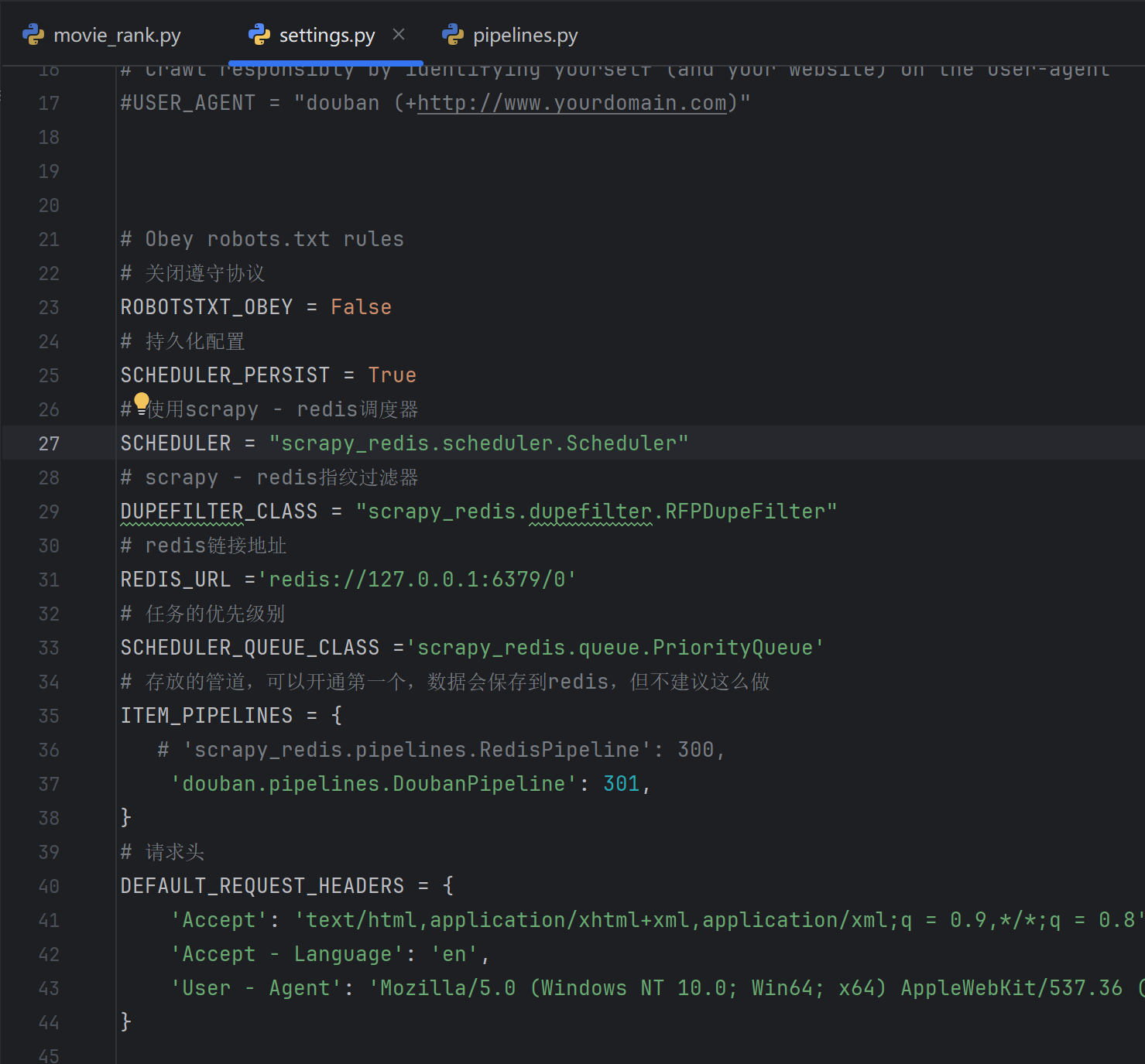
3.修改setting.py
? ? ? ? 打開settings.py文件,將以下設置覆蓋掉,使用scrapy-redis的配置,不建議將管道添加Redis,因為Redis適合存取常用數據。Redis地址要記得換成自己的。
# Obey robots.txt rules
# 關閉遵守協議
ROBOTSTXT_OBEY = False
# 持久化配置
SCHEDULER_PERSIST = True
# 使用scrapy - redis調度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# scrapy - redis指紋過濾器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# redis鏈接地址
REDIS_URL ='redis://127.0.0.1:6379/0'
# 任務的優先級別
SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.PriorityQueue'
# 存放的管道,可以開通第一個,數據會保存到redis,但不建議這么做
ITEM_PIPELINES = {# 'scrapy_redis.pipelines.RedisPipeline': 300,'douban.pipelines.DoubanPipeline': 301,
}
# 請求頭
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q = 0.9,*/*;q = 0.8','Accept - Language': 'en','User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
4.設置起始url的key
? ? ? ? 因為我們的爬取URL都是要從Redis獲取的,所有我們不需要手動設置起始的URL,也就是START_URL,在scrapy-Redis中,只需要設置redis-key,scrapy就會自動去Redis中尋找起始的url。操作如下:
????????
# 前面是爬蟲名,后面是固定start_urls
redis_key = 'movie_rank:start_urls'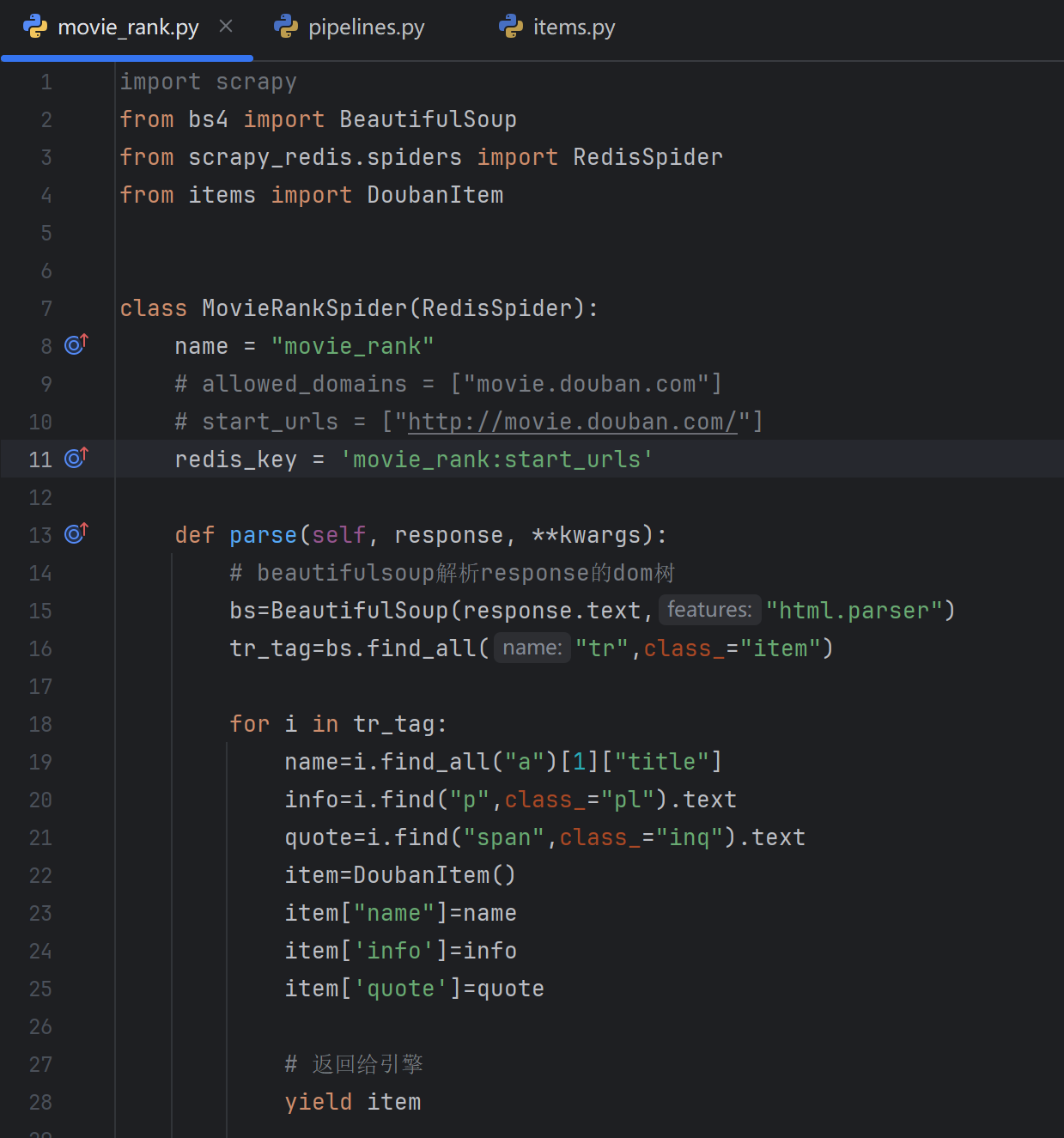
5.slaver1測試
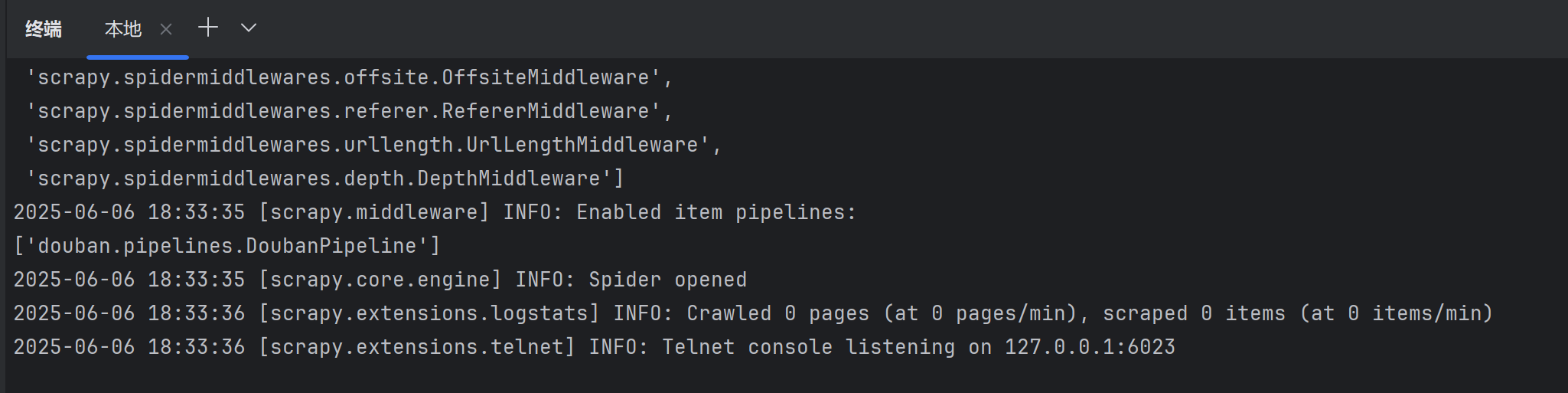
? ? ? ? 接下來我們可以嘗試運行slaver1的scrapy-redis項目。
scrapy crawl movie_rank????????可以看到卡在了此處,因為程序正在等待我們向Redis中添加起始URL。
? ? ? ? ?我們現在嘗試使用Python腳本在Redis中添加Redis_key作為起始URL。
import redis# 連接到Redis
r = redis.Redis(host='127.0.0.1', port=6379)# 添加起始URL
r.lpush('movie_rank:start_urls', 'https://book.douban.com/top250')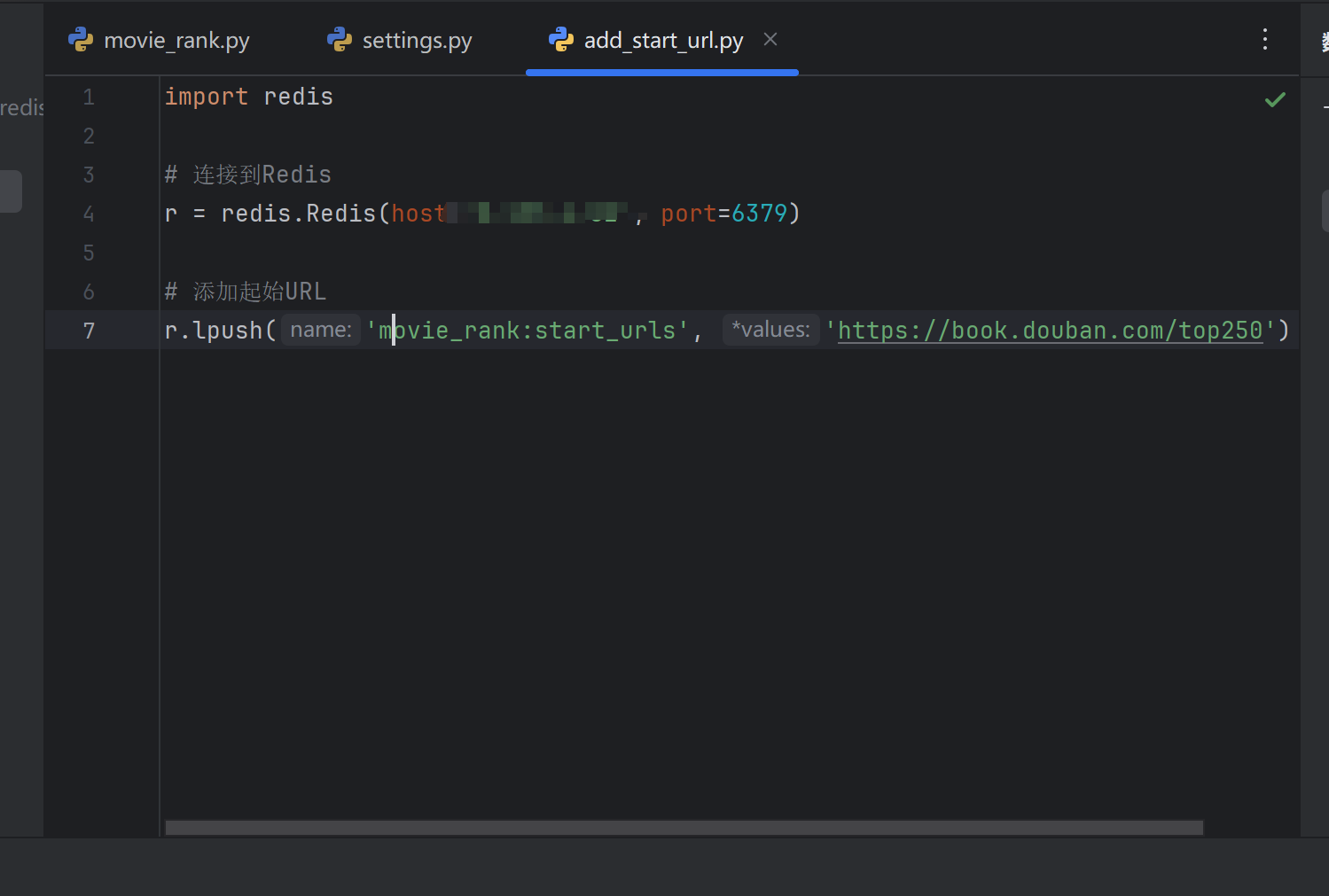
? ? ? ? 可以看到爬蟲自動讀取到了我們添加的URL,不過抓取失敗了,因為400錯誤碼,我們的請求頭有問題。在scrapy-Redis中,默認的請求頭是scrapy-Redis,我們需要修改它。
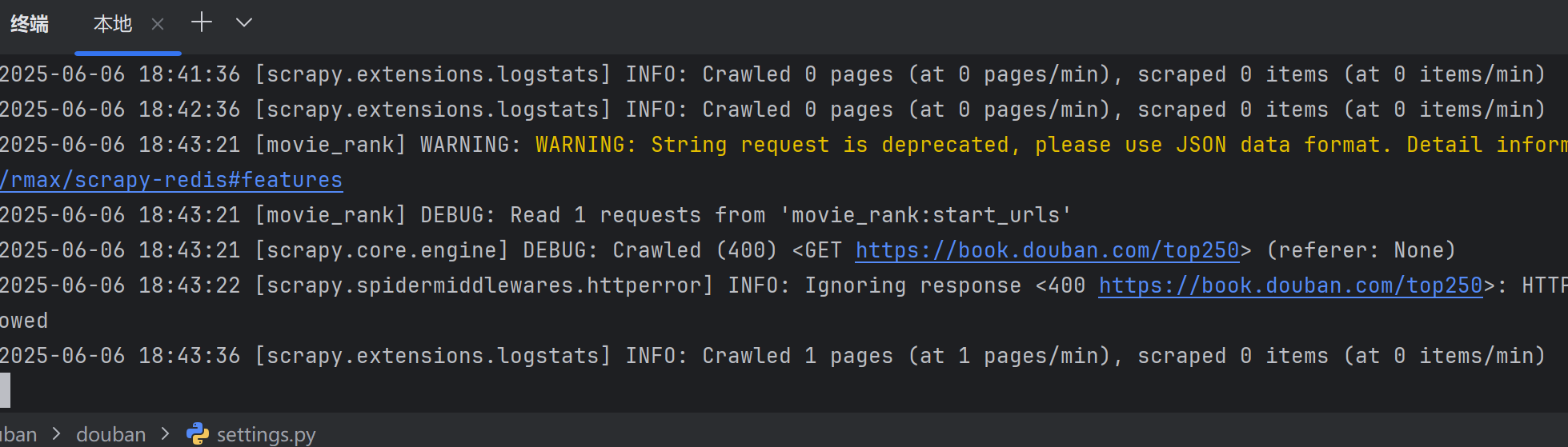
? ? ? ? 我們在中間件中重寫下載器中間件的請求頭,示例代碼如下:
class DoubanDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledrequest.headers.setdefault('User-Agent', self.get_random_ua())print(request.headers)return Nonedef get_random_ua(self):# 隨機 User-Agent 列表user_agents = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36']return random.choice(user_agents)? ? ? ? 然后再設置中啟用中間件,再次運行可以看到成功拿到數據了。
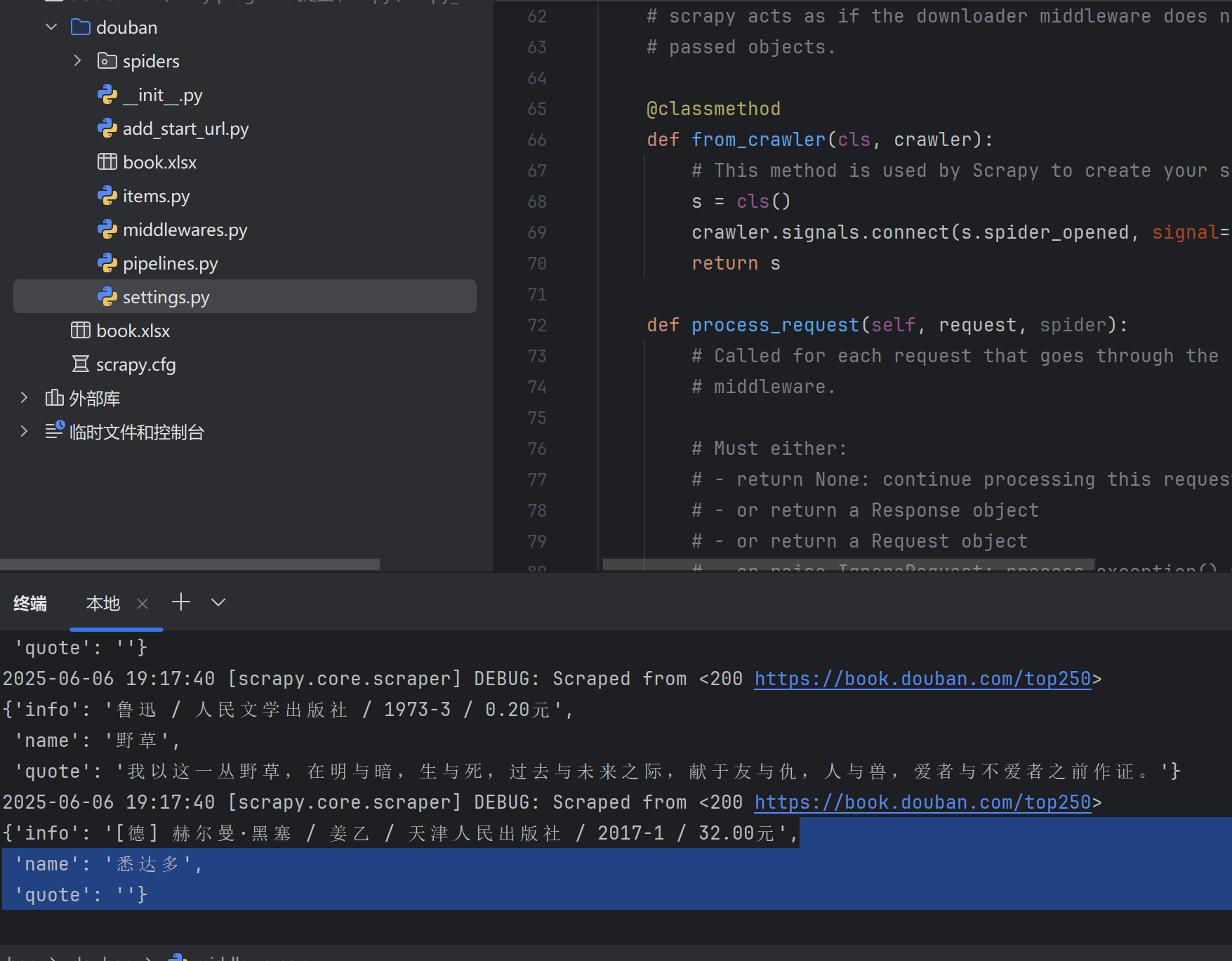
6.slaver2測試
? ? ? ? 接下來我們來調試slaver2,slaver2使用的是Ubuntu16.04操作系統,所以需要提前準備好Python解釋器和其他配置項。這里就不多加贅述了。
????????然后將我們之前的項目全部打包放入任意位置。不需要做任何修改,直接運行爬蟲即可。這里就不再演示,大家可以自己嘗試一下。
四、總結
最后附上源碼地址:豆瓣讀書分布式爬蟲: 采用scrapy-Redis實現豆瓣閱讀分布式爬蟲。

環境配置(Linux))








-在機器學習(ML)浪潮中何去何從?)





)


