序言
網上看到的面試題:Redis有1億個key,其中10w個key是以某個固定的前綴開頭,如何將它們全部找出來?一般有兩種命令可以實現:
- Keys命令
- Scan命令
下面具體分析一下兩種命令
Keys命令
Keys pattern
如下圖所示,建了一些不同數據結構(String、Hash、List、Set、ZSet)的Key,使用命令找出前綴為prefix的Key(key區分大小寫),
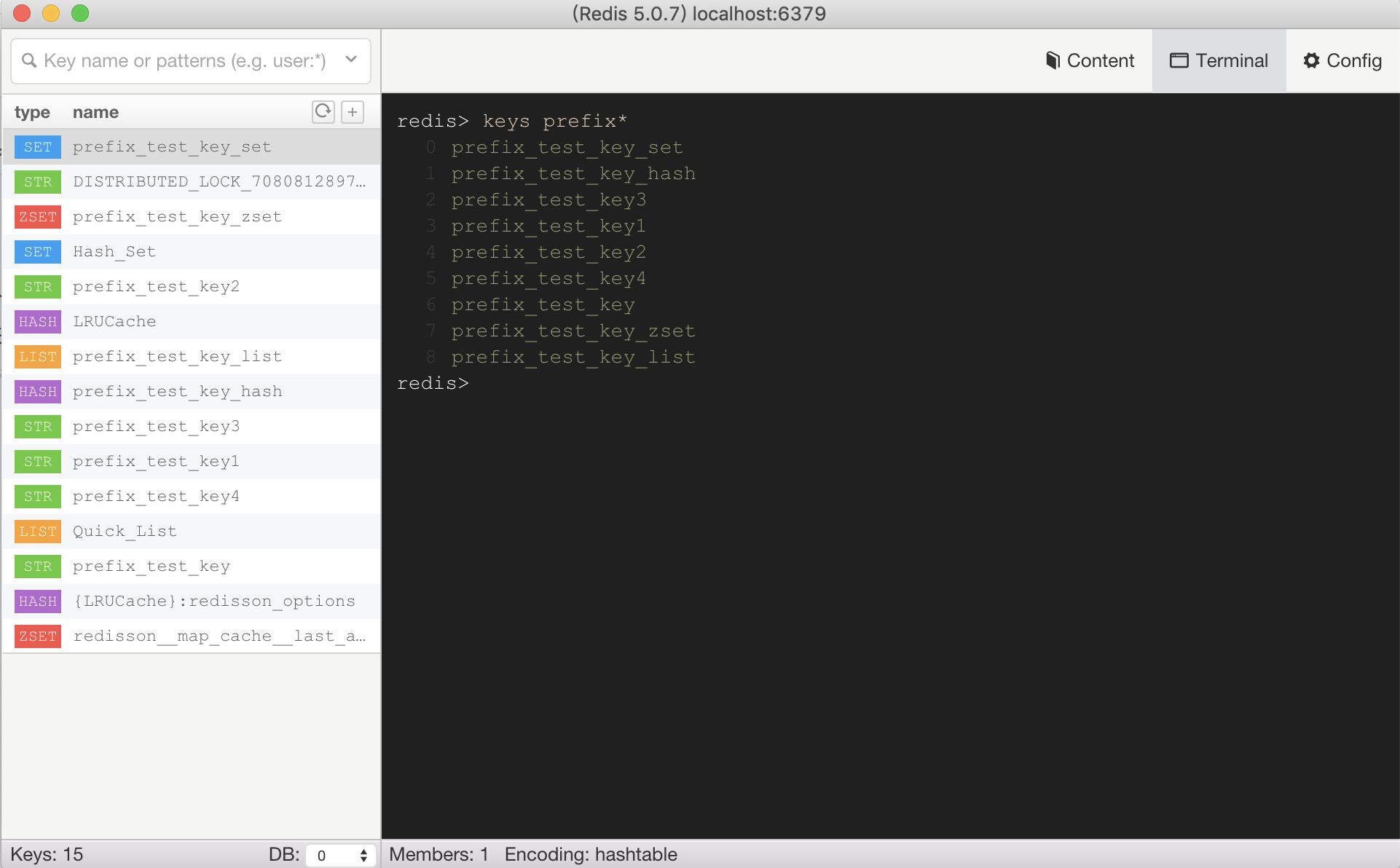
- 時間復雜度O(n);
- 筆記本電腦40毫秒內可以查100w個鍵值對;
- 生產環境慎用,大型數據庫上執行會影響性能;
那么在大型數據庫場景下為什么不能使用該命令呢?
Keys命令是一個阻塞式操作。
- 單線程模型:Redis的命令處理是基于單線程的。一個命令在執行時,其他所有客戶端的請求都必須等待;
- 全量遍歷:Keys為了找出所有匹配的key,會遍歷數據庫(NoSQL)中所有的key,遍歷完成之前,Redis無法處理任何其他命令。
- 生產環境災難:如果正在有1億個key的實例上執行
Keys命令,會導致Redis服務卡頓數十秒甚至數分鐘,所有依賴Redis的業務都會出現超時和雪崩,會導致嚴重的生產事故。
Scan命令
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
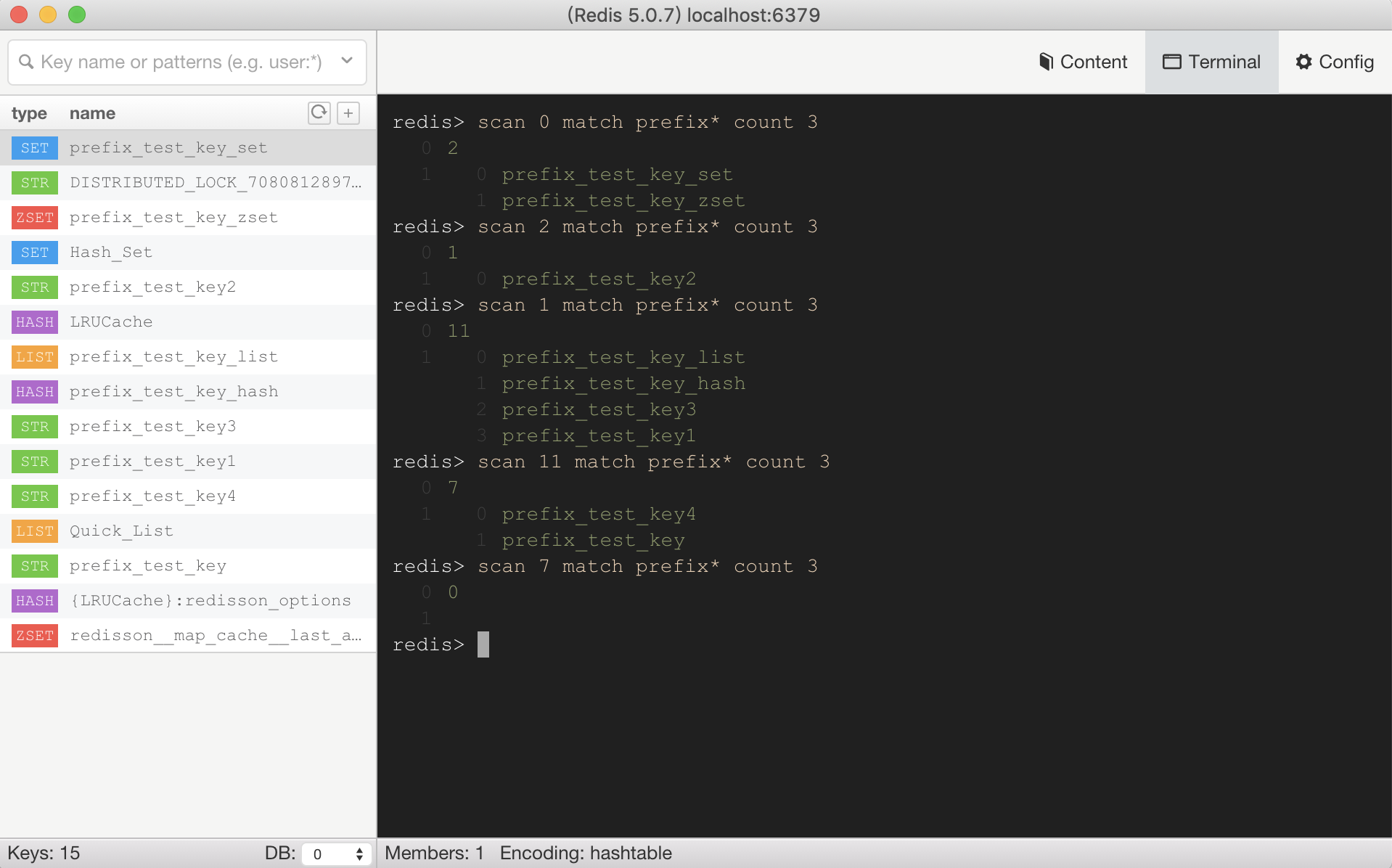
- 單次調用時間復雜度O(1),完整迭代時間復雜度O(n);所以單次調用不會長時間阻塞線上服務;
- 非阻塞式(漸進式)迭代:該命令允許增量迭代,每次調用返回少量數據,然后返回一個游標(cursor),下次傳入這個游標,Redis就會接著上次結束的地方繼續掃描,如上圖
scan xxx match prefix* count 3每次返回的游標不一定按照順序; - COUNT參數:
COUNT是一個建議值,告訴Redis希望每次迭代返回大約多少個key。但不是精確的,有時多有時少,但是可以控制單次掃描的粒度。如上圖scan xxx match prefix* count 3每次返回的數據量不一定都是3;
參看官網,相關的還有其他的一些掃描指令:
- SSCAN:iterates elements of Sets types.(針對Set數據結構)
- HSCAN:iterates fields of Hash types and their associated values.(針對Hash數據結構)
- ZSCAN:iterates elements of Sorted Set types and their associated scores.(針對ZSet數據結構)
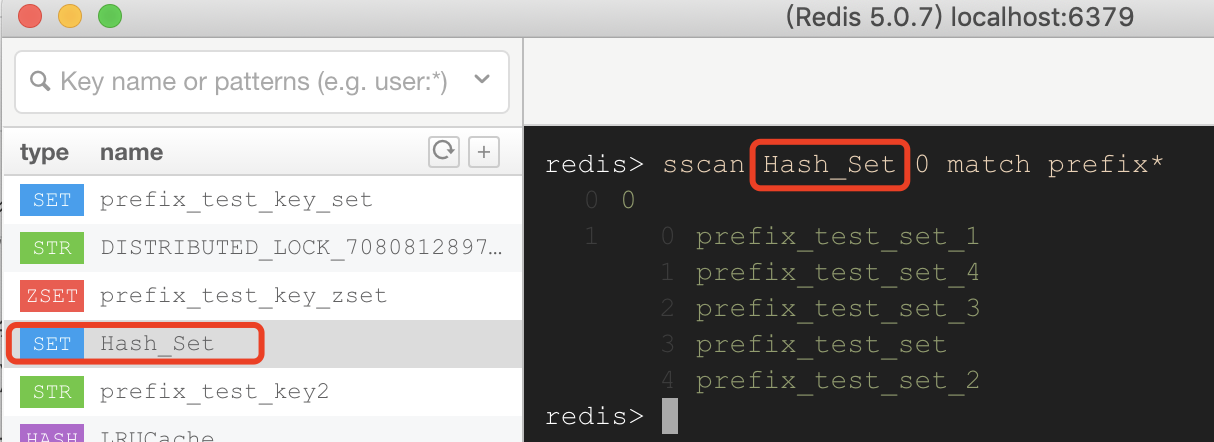
實際操作
實際項目中可能會通過python腳本或者LUA腳本去執行查找,下面是使用python代碼去執行的示例代碼,
import redisr = redis.Redis(host='localhost', port=6379)
cursor = 0
prefix = 'your_prefix:*'
found_keys = []while True:cursor, keys = r.scan(cursor, match=prefix, count=10000)found_keys.extend(keys)if cursor == 0:break
可以使用Lua腳本在Redis服務器端直接處理,減少網絡往返:
local keys = redis.call('SCAN', ARGV[1], 'MATCH', ARGV[2], 'COUNT', ARGV[3])
return keys
其他思路
空間換時間
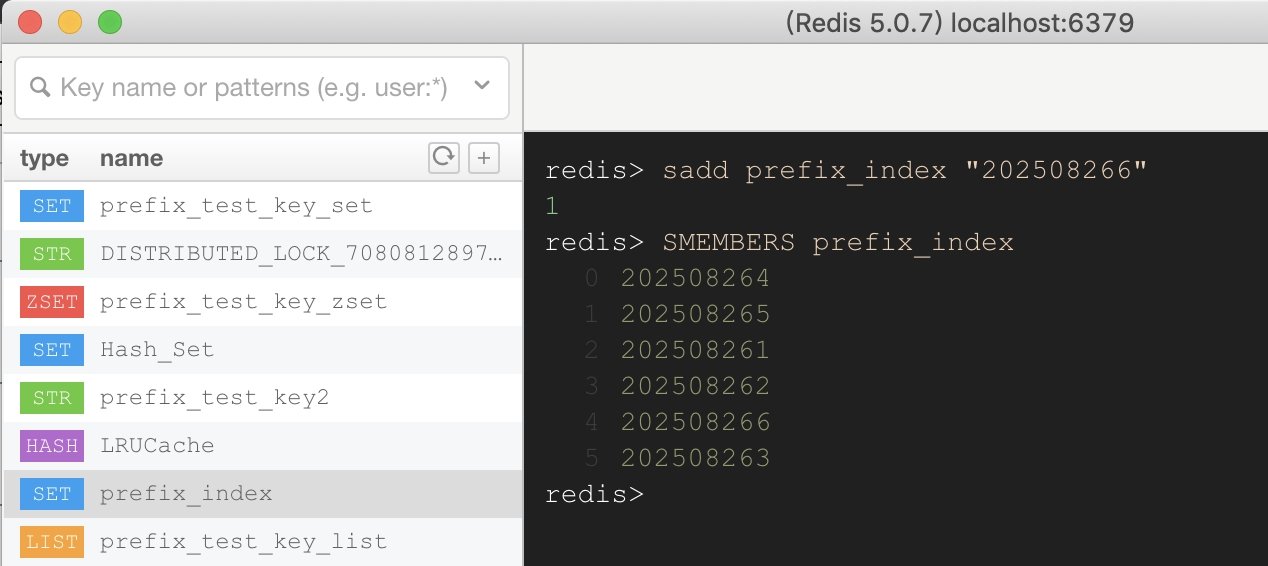
另外維護一個“索引”:
- 創建Key時,將key添加到前綴索引的Set集合中;
- 查找Key時,直接讀取索引Set的所有成員,這樣時間復雜度即使是O(n),遍歷的也是10w數據,而非NoSQL數據庫中的1億條數據;
- 刪除時,除了刪除原始key,還需要從索引Set中移除對應的成員;
從節點(Replica)執行
假設這是一個低頻且用于離線分析的需求,并且不想修改現有的數據結構,可以考慮在Redis集群(主從、哨兵、集群模式)的從節點去執行SCAN命令操作(甚至Keys命令),避免長時間耗時影響主節點(Master)的正常讀寫。
)


)
![BigFoot (Method Raid Tools)[MRT] (Event Alert Mod)[EAM]](http://pic.xiahunao.cn/BigFoot (Method Raid Tools)[MRT] (Event Alert Mod)[EAM])
)

環境配置(Linux))








-在機器學習(ML)浪潮中何去何從?)


