目錄
前言
一、vLLM簡介:為什么它如此重要?
二、核心技術一:PagedAttention — 顯存管理的革命
2.1?傳統注意力緩存的缺陷
2.2 分頁式存儲管理
三、核心技術二:張量并行 — 多GPU推理的基石
3.1 什么是張量并行?
3.2 vLLM 的實現方式
四、核心技術三:連續批處理 — 動態合并請求
4.1 傳統批處理
4.2 連續批處理(Continuous Batching)
五、實際性能表現
六、vLLM 工作流程
總結:vLLM 的價值與未來
附錄:快速開始示例

前言
在大語言模型(LLM)推理任務中,顯存管理和計算效率一直是制約其實際部署的關鍵問題。尤其是隨著模型規模越來越大、請求并發數不斷增加,如何高效地利用GPU資源成為技術團隊亟需解決的挑戰。而vLLM 作為一個高性能推理引擎,依托其創新的?PagedAttention?機制、張量并行?技術和連續批處理能力,顯著提升了推理吞吐量并降低了響應延遲,成為當前LLM服務化部署的重要選擇。
一、vLLM簡介:為什么它如此重要?
vLLM是由加州大學伯克利分校的研究者開發的開源框架,旨在為LLM提供高效的在線服務。它不像傳統的推理框架那樣局限于單機或小規模部署,而是針對生產級場景設計,支持高吞吐量和低延遲。想象一下,你有一個70B參數的模型,需要處理成千上萬的并發請求——傳統的PyTorch或TensorFlow可能因顯存碎片或計算瓶頸而崩潰,而vLLM通過智能的資源管理,讓這一切變得高效。
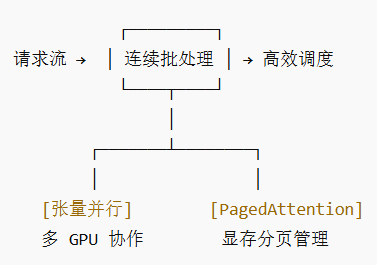
核心在于三個機制:張量并行實現模型拆分多卡運行;PagedAttention優化KV緩存的存儲;連續批處理動態調度請求。這些技術相結合,不僅降低了顯存占用,還提升了整體吞吐量,讓多GPU推理變得簡單可靠。接下來,我們逐一拆解。
在傳統LLM推理中,以下幾個方面尤其影響效率:
顯存碎片化:每個請求的鍵值緩存(KV Cache)長度不定,容易產生顯存碎片。
靜態批處理限制:通常只能將相同長度的請求拼成一批,容易造成GPU計算資源浪費。
單卡顯存限制:大模型即使推理也需大量顯存,單卡難以承載高并發請求。
vLLM 通過如下三大核心技術,系統性解決了上述問題。
二、核心技術一:PagedAttention — 顯存管理的革命
PagedAttention 是 vLLM 中最重要的貢獻之一,其設計靈感來自操作系統中的虛擬內存與分頁機制。
2.1?傳統注意力緩存的缺陷
在標準的注意力計算中,每個序列生成過程中都需要存儲鍵值向量(KV Cache)。由于序列長度可變,容易導致顯存碎片化,利用率低。
2.2 分頁式存儲管理
vLLM 將不同請求的 KV Cache 劃分為固定大小的塊(block),每個塊可被多個請求共享(如并行采樣時),由一個中央管理單元統一調度。這樣一來:
顯著減少顯存碎片;
支持更靈活的內存分配與釋放;
提升整體顯存利用率,尤其是在處理長文本和多樣化請求時效果顯著。
三、核心技術二:張量并行 — 多GPU推理的基石
vLLM 原生支持張量并行(Tensor Parallelism),用戶只需通過?tensor_parallel_size?參數即可指定使用的 GPU 數量,模型會自動拆分并分布到多卡上。
3.1 什么是張量并行?
與數據并行不同,張量并行是將模型本身的層結構(如矩陣乘)進行切分,分布到多個設備上分別計算,再通過通信整合結果。這種方式特別適合超大模型推理。
3.2 vLLM 的實現方式
-
模型權重均勻分布在各GPU上;
-
每張卡僅計算部分結果,通過 collective 通信(如All-Reduce)聚合;
-
推理過程中自動處理設備間通信,用戶無需關心模型切分細節。
這一機制使得vLLM能夠輕松擴展至多卡甚至多機環境,有效突破單卡顯存限制。
四、核心技術三:連續批處理 — 動態合并請求
目的:減少 GPU 空閑時間,提升吞吐量
傳統批處理策略需要等一批請求全部計算完成才能進行下一批,容易造成GPU空閑。
4.1 傳統批處理
時間軸: [等待請求1/2/3對齊] → [統一推理] → [等待下一批]
4.2 連續批處理(Continuous Batching)
vLLM 實現了動態批處理機制,允許:
時間軸: 請求1進入 → 請求2進入(直接插入批次) → 請求3進入(繼續拼接)
動態合并:不同長度的請求可以拼在一起,不用等齊。
在線插入:新請求隨時加入已有批次,GPU 幾乎無空閑。
吞吐量提升:在高并發場景下尤為明顯。
🛠 比喻:像地鐵一樣,隨到隨上,不必等所有人都到齊再發車。
新請求隨時加入已運行的批次中;
完成推理的請求及時退出,釋放資源;
自動優化不同長度請求的組合方式,最大化GPU使用率。
該技術尤其適合實時推理場景,如聊天機器人、代碼補全等需低延遲響應的應用。
五、實際性能表現
在實際測試中,vLLM 相比傳統推理方案(如 Hugging Face Transformers)可實現:
最高提升24倍的吞吐量;
更低的響應延遲;
更好的長上下文支持能力。
尤其是在處理多用戶、高并發、不同請求長度的場景中,vLLM 表現出了顯著的性能優勢。
六、vLLM 工作流程
想象一個高效工廠處理訂單(你的請求):
🧩 第1步:準備工廠(初始化)
張量并行:把大模型像切蛋糕一樣分到多個GPU上。每個GPU只負責一部分計算。
內存池:在顯存里預先劃出一堆固定大小的空位(Block),準備存放“記憶”。
📥 第2步:訂單到達(請求接入)
你的請求(如“寫一首詩”)進入等待隊列。
🚌 第3步:靈活拼車(連續批處理)
調度器不會傻等“滿員發車”。
它會實時把新訂單動態插入到正在進行的計算中,確保GPU永不空閑。
💾 第4步:高效管理記憶(PagedAttention)
為你請求的“記憶”(KV Cache)分配剛才準備好的空位(Block)。
這些記憶可以分散存儲,通過一個“目錄”快速查找。杜絕浪費,毫無碎片。
? 第5步:協同生產(計算與通信)
拆分計算:每個GPU用自己那部分模型權重并行計算。
匯總結果:通過高速連接通信,匯總所有GPU的部分結果,得到最終輸出(下一個詞)。
循環:重復這個過程,直到生成完整回復。
🧹 第6步:交付與清場(返回與釋放)
結果返回給你。
它占用的所有空位(Block)?被立刻回收,放入池中等待下一個訂單。
總結:vLLM 的價值與未來
vLLM 不僅是一套技術解決方案,更為LLM的高效推理設立了新標準。其通過:
PagedAttention?解決顯存碎片問題(確保每張GPU的顯存高效使用,優化整體性能);
張量并行?實現多卡擴展;
連續批處理?提升GPU利用率,
技術 解決了什么痛點 帶來的好處 張量并行 單卡裝不下大模型 橫向擴展,支持更大模型、更多GPU PagedAttention 顯存碎片化,浪費嚴重 顯存利用率極高,同等顯存下并發量提升數倍 連續批處理 GPU等請求,湊齊一批才干活 吞吐量巨高,GPU幾乎時刻滿負荷工作 最終效果:?用更少的卡,以更快的速度,同時服務更多的人。
📊 整體示意圖
最終效果:在相同硬件條件下,vLLM 可以承載更多請求、更長上下文、更快響應,成為大規模模型部署的核心引擎。
這三者協同工作,打造出一個極其高效且靈活的推理系統。
未來,隨著模型規模的進一步增長和應用場景的復雜化,vLLM 及其背后思想無疑將會影響更多推理系統的設計,成為大規模LLM服務化部署的核心基礎設施。
附錄:快速開始示例
?查看官方文檔了解更多用法:vLLM Documentation
pip install vllm# 指定張量并行大小,使用2個GPU
python -m vllm.entrypoints.api_server \--model meta-llama/Llama-2-7b-hf \--tensor-parallel-size 2











)

)

論文解析技巧)

Flink的機制)
)