在 2D 自然圖像和視頻的交互式分割領域,基礎模型已引發廣泛關注,這也促使人們開始構建用于醫學成像的 3D 基礎模型。然而,3D 醫學成像存在的領域差異以及臨床應用場景,要求開發一種有別于現有 2D 解決方案的專用模型。具體而言,這類基礎模型應支持一套完整的工作流程,切實減少人工操作。
將 3D 醫學圖像視為 2D 切片序列,并復用交互式 2D 基礎模型,看似簡單直接,但在 3D 任務中,2D 標注過于耗時。此外,對于大規模隊列分析,高精度的自動分割模型才能最大程度減少人工工作量。然而,這些模型缺乏對交互式修正的支持,也不具備對新型結構的零樣本處理能力 —— 而這正是 “基礎模型” 的關鍵特性。盡管在 3D 模型中復用預訓練的 2D 骨干網絡能增強零樣本潛力,但它們在處理復雜 3D 結構時的性能仍落后于頂尖的 3D 模型。
2025年6月,英偉達公司聯合牛津大學在CVPR 2025?在線發表題為“VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging”的研究論文。該研究提出了 VISTA3D(多功能成像分割與標注模型),旨在通過一個統一的基礎模型應對所有這些挑戰和需求。
VISTA3D 基于成熟的 3D 分割流程構建,是首個在 3D 自動分割(支持 127 個類別)和 3D 交互式分割兩方面均達到最先進性能的模型,即便在大型多樣化基準測試中與頂尖的 3D 專業模型相比也是如此。此外,VISTA3D 的 3D 交互式設計支持高效的人工修正,而其創新的 3D 超體素方法(通過提煉 2D 預訓練骨干網絡構建)則賦予了 VISTA3D 頂尖的 3D 零樣本性能。作者認為,該模型、其構建方法以及相關見解,代表著在邁向具有臨床實用性的 3D 基礎模型道路上邁出了充滿希望的一步。
由于促炎巨噬細胞向抗炎巨噬細胞的復極化受損,傳統的骨組織工程材料難以在糖尿病期間恢復生理性骨重塑。
三維醫學成像技術,如計算機斷層掃描(CT),被廣泛用于生成人體各部位的橫截面體素圖像。作為一種主要的解剖成像方式,它能夠清晰呈現人體結構和異常組織的詳細形態信息。在臨床實踐中,手動分割既耗時又繁瑣,因此開發更優的自動分割模型一直是研究的熱點領域之一。其中一個典型方向是改進網絡架構,并為特定任務定制訓練方案。針對每個任務,通常需要精心準備特定的訓練數據集并訓練專業模型,這對工程技術能力提出了較高要求。因此,一種能夠 “開箱即用” 解決多種任務的模型更具應用價值。
與自然圖像中存在無限多目標類別不同,CT 或 MRI 所呈現的臨床相關人體正常解剖結構是有限的(如肝臟、胰腺等),因此從技術層面而言,訓練一個能夠支持大多數標準人體解剖結構的自動分割模型是可行的。然而在實際應用中,臨床醫生可能更關注罕見病變或動物數據,而由于數據稀缺,這些通常不在現有模型的支持范圍內。缺乏處理這類場景的零樣本能力,成為了模型的一大局限性。同時,對于手術規劃等流程,模型還需支持人工介入進行修正,這一點也至關重要。
近年來,大型語言模型在各類任務中展現出強大的泛化能力,被視為基礎模型。“可提示” 系統的理念隨之提出,旨在實現一種能夠 “開箱即用” 解決不同任務的靈活模型。在圖像分割領域,“萬物分割”(Segment Anything,SAM)引發了廣泛關注,并取得了令人矚目的零樣本性能。在醫學領域,近期研究通過模型微調,將 SAM 適配到醫學成像模態中。這些基于 SAM 的方法在 2D 場景中借助交互式用戶輸入,取得了頗具前景的成果。但對于 3D 醫學圖像,此類提示(如點提示)需要綁定到每個類別、每個切片和每個掃描圖像,這往往需要大量人工操作,難以應用于大規模隊列數據分析。
近期的 “視頻萬物分割”(Segment Anything in Video,SAM2)引發了更大關注,因為 3D 掃描圖像可表示為 2D 橫截面圖像(切片)的堆疊,而視頻也是 2D 圖像(幀)的堆疊。然而,實驗表明,即使在 3D 醫學數據集上進行了充分微調,SAM2 框架仍無法與 VISTA3D 相比,尤其是在處理復雜 3D 結構時(詳見補充材料)。SAM2 主要用于追蹤隨時間變化的目標,但醫學成像需要對體素輸入進行空間一致性處理。例如,不同時間幀中的汽車仍是同一輛,但其實時 2D 橫截面圖像可能對應完全不同的物體,如座椅和發動機。這體現了 2D 自然圖像或視頻與橫截面醫學圖像之間的巨大差異。類似地,SAM3D 通過 2D SAM 編碼器逐切片提取 3D 體素特征,并結合 3D 解碼器,但結果遠遜于專業 3D 模型。簡單地將自然圖像領域的方法應用于 3D 醫學圖像,顯然是不夠的。
近期探索醫學圖像分割上下文學習的研究,能夠在示例圖像或文本的引導下分割任意類別。這看似是一種理想方案,因為它無需模型微調或耗時的人工輸入。但這類方法的性能遠落后于特定數據集的有監督模型(如 nnU-Net)。
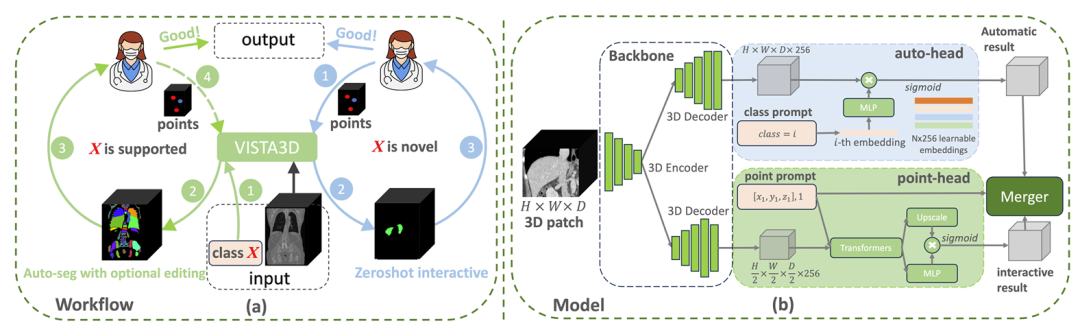
圖 1. 圖 (a) 展示了 VISTA3D 支持的完整人機協同工作流程。如果分割任務 X 屬于 127 個支持類別(左側綠色圓圈),VISTA3D 會執行高精度自動分割。醫生可對結果進行檢查,必要時借助 VISTA3D 高效編輯。如果 X 是新型類別(右側藍色圓圈),VISTA3D 會執行 3D 交互式零樣本分割。圖 (b) 展示了 VISTA3D 的架構,它包含兩個分支,共享同一個圖像編碼器。若用戶提供的類別提示屬于 127 個支持類別,頂部的自動分支會啟動 “開箱即用” 的自動分割功能;若用戶提供 3D 點選提示,底部的交互分支會啟動交互式分割功能。若兩個分支同時啟動,基于算法 1 的合并模塊會利用交互結果對自動分割結果進行編輯。
作者認為,3D 醫學圖像分割基礎模型應支持一套完整的工作流程(圖 1 (a)),以減少人工操作,其核心能力包括:1)對常見器官或結構進行高精度自動分割;2)支持與專家的交互,以便對現有分割結果進行有效優化;3)具備零樣本能力,既允許用戶交互式標注未見過的類別,也能通過文本或示例引導進行上下文學習。模型應在 3D 空間中運行,因為 2D 逐切片方法不僅耗時,還可能無法充分利用 3D 視覺上下文;4)具備少樣本 / 遷移學習能力,允許用戶在新類別上快速微調模型,以實現精確的自動分割 —— 鑒于現有上下文學習或開放詞匯分割在精度上仍落后于專業 3D 模型。
為支持這一工作流程并達到與頂尖專業模型相當的性能,模型應基于成熟的 3D 流程構建,依賴 3D 骨干網絡和滑動窗口推理。但這一方向未能充分利用現有具備強大零樣本能力的 2D 預訓練權重(如 SAM)。復用 SAM 權重并添加輕量級 3D 適配模塊看似可行,但由于凍結了大部分權重,其在多類別上的自動分割性能(與 TotalSegmentator 相比)受到限制。因此,面臨的挑戰是:如何構建一個既具備成熟 3D 流程優勢,又能利用 2D 自然圖像領域的見解和檢查點來解決 3D 問題的模型。基于此目標,提出了 VISTA3D,主要貢獻如下:
1.首個支持完整標注工作流程的統一基礎模型,在 14 個具有挑戰性的數據集(含 127 個類別)上進行基準測試,與成熟基線模型相比,在 3D 可提示自動分割和交互式編輯方面均達到最先進性能。
2.提出一種新穎的超體素方法,用于提煉 2D 基礎模型以適配 3D 醫學成像,將 VISTA3D 的零樣本性能提升 50%,在大幅減少標注工作量的情況下,實現了最先進的 3D 零樣本性能。
3.構建了一個包含 11454 次掃描的大型 CT 數據集,結合部分手動標簽、偽標簽和超體素,提出一種新穎的四階段訓練方案,以應對挑戰,實現最先進的性能和編輯體驗。
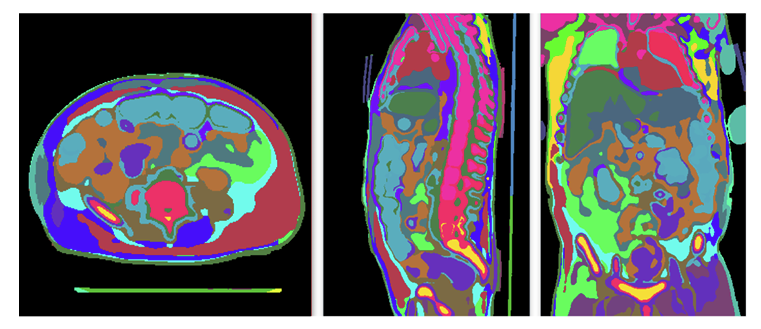
圖 2. 由算法 2 生成的超體素,展示了軸位、矢狀位和冠狀位視圖的示例。不同顏色代表不同的超體素。
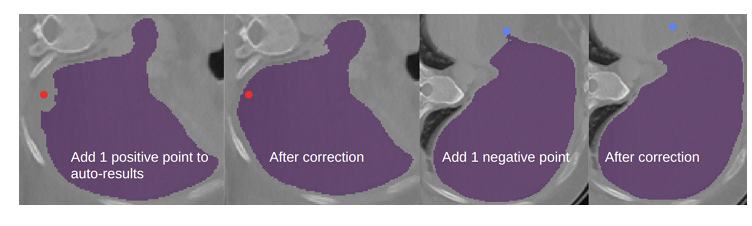
圖 3. 用點修正自動分割結果。左圖為肝臟自動分割結果,存在一個假陰性區域。在添加一個正點后,該假陰性區域得到了修正。第三幅圖顯示了另一個切片,其中存在一個假陽性區域,在添加一個負點后,該區域在最后一幅圖中被移除。
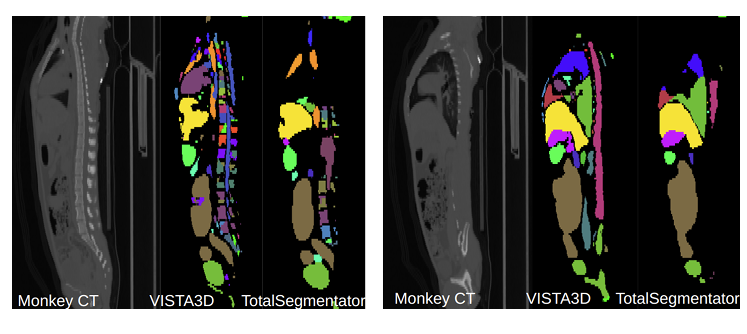
圖 4. 猴類 CT 掃描的一個示例(2 個矢狀位切片)。可以看出,VISTA3D 實現了更穩健的分割。
卓越性能
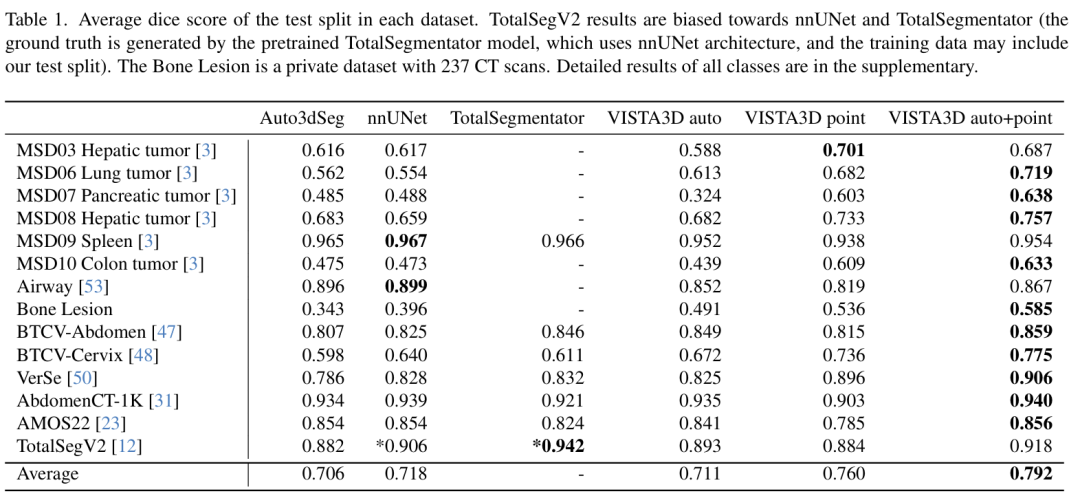
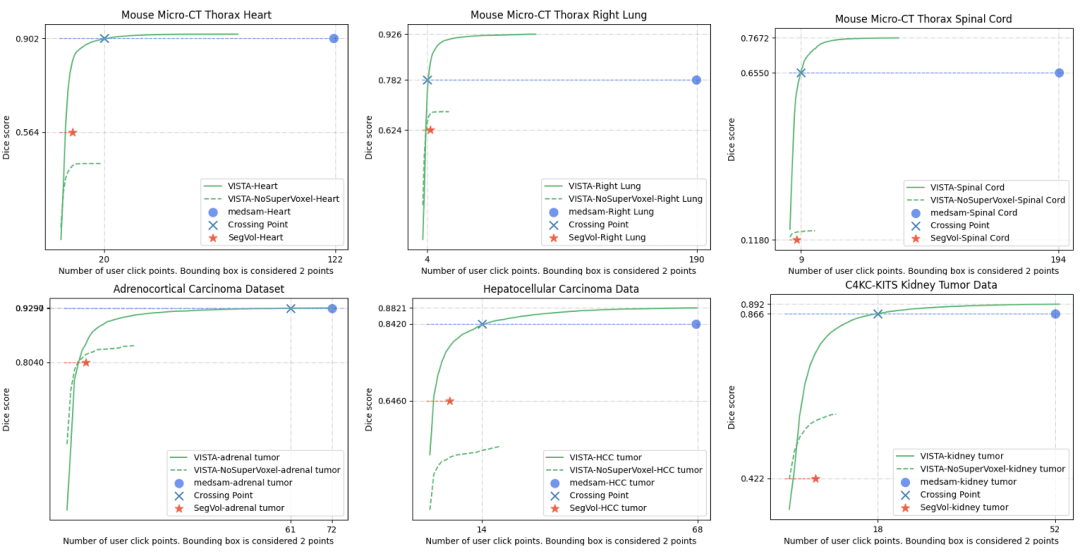
圖 5. 零樣本 Dice 評分。X 軸為點擊點數,Y 軸為整個數據集的平均 Dice 評分。

圖 6. 腎臟腫瘤的細粒度零樣本交互式分割。第一幅圖顯示了腫瘤區域。步驟 1:在腫瘤上點擊一個正點(紅色)并得到結果。步驟 2:點擊更多點以細化細節。此時結果存在過分割,步驟 3:添加一個負點(藍色),得到最終結果。
參考:
https://arxiv.org/pdf/2406.05285
https://github.com/Project-MONAI/VISTA







)

保姆級教)

:從注解、AOP到底層原理與整合實戰)

)





)