ps:本文內容較干,建議收藏后反復邊跟進源碼邊思考設計思想。
壹
渲染管線的基礎架構
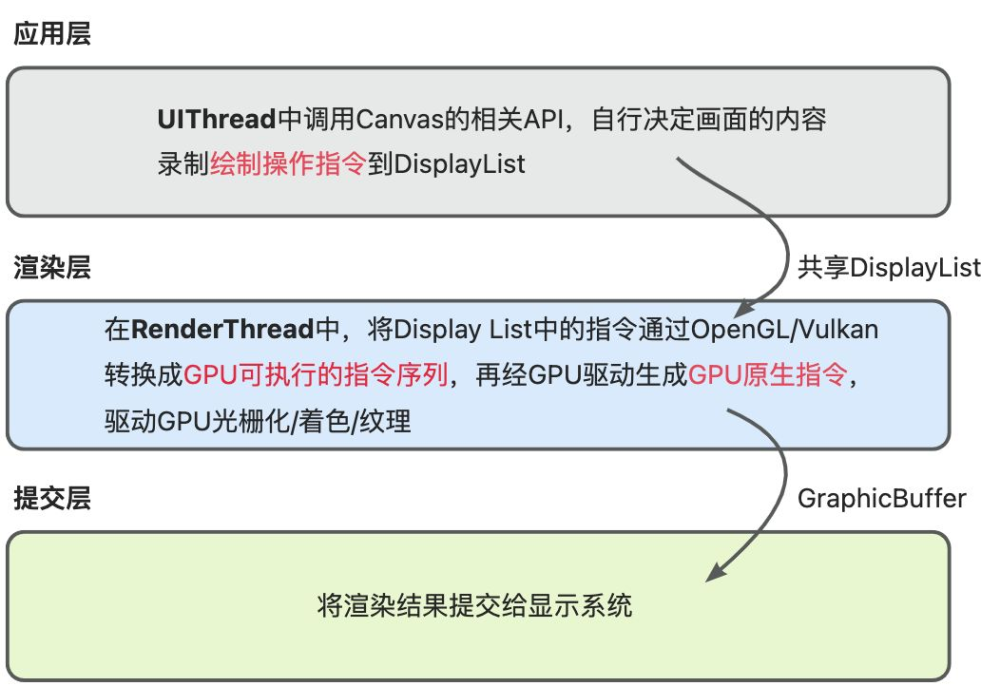
為什么叫渲染管線?這里是因為整個渲染的過程涉及多道工序,像管道里的流水線一樣,一道一道的處理數據的過程,所以使用渲染管線還是比較形象的。接下來我們來看下渲染的整個架構。
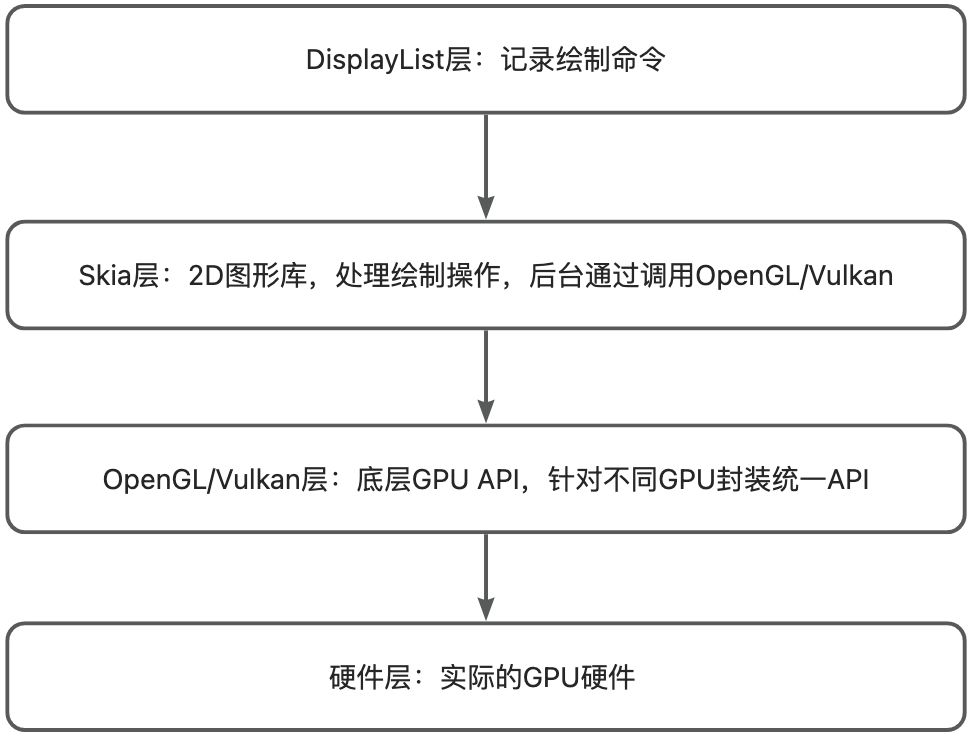
Android的渲染過程需要按照是否開啟硬件加速分別看待,默認是開啟硬件加速的,那么在應用層使用Canvas的一些繪圖API會預先轉換成OpenGL指令或者Vulkan指令,然后由OpenGL/Vulkan直接操作GPU執行像素化的過程。而如果不開啟硬件加速,Canvas的繪圖指令就會調用skia庫直接利用CPU繪制Bitmap圖。
1、開啟硬件加速
DisplayList到底是什么?
class DisplayListData {
? // 基礎繪制指令
? Vector<DisplayListOp*> displayListOps;
? // 子視圖的應用
? Vector<DrawRenderNodeOp*> children;
? // 命令分組<用于 Z 軸排序>
? Vector<Chunk> chunks;
}
這里說的DisplayList中的指令、GPU可執行的指令序列和GPU原生指令有什么不同呢?
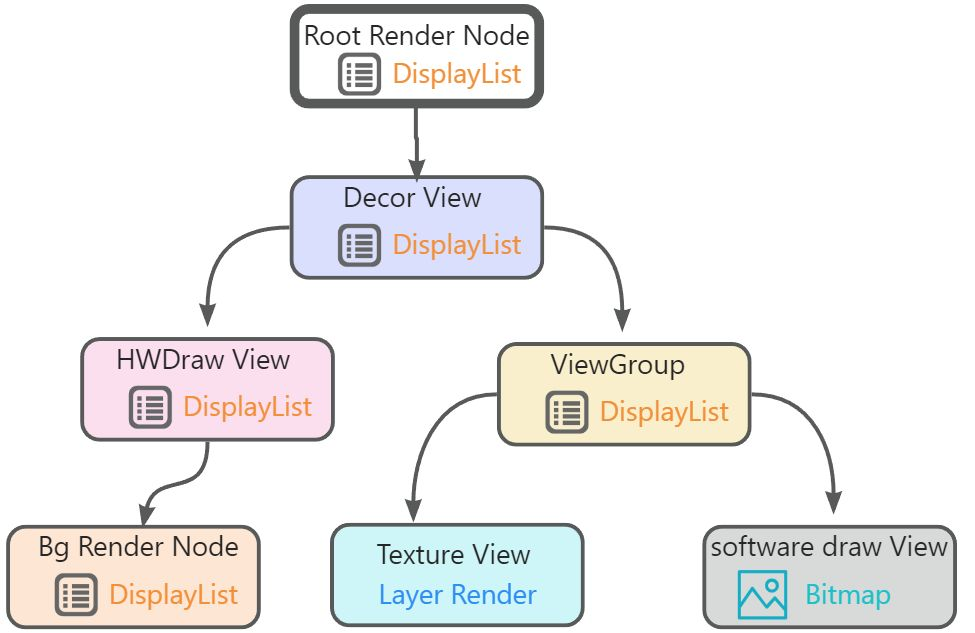
Android應用程序窗口的根視圖是虛擬的,抽象為一個Root Render Node。此外,一個視圖如果設置有Background,那么這個Background也會抽象為一個Background Render Node。Root Render Node、Background Render Node和其它真實的子視圖,除了TextureView和軟件渲染的子視圖之外,都具有Display List,并且是通過一個稱為Display List Renderer的對象進行構建的。
TextureView不具有Display List,它們是通過一個稱為Layer Renderer的對象以Open GL紋理的形式來繪制的,不過這個紋理也不是直接就進行渲染的,而是先記錄在父視圖的Display List中以后再進行渲染的。同樣,軟件渲染的子視圖也不具有Display List,它們先繪制在一個Bitmap上,然后這個Bitmap再記錄在父視圖的Display List中以后再進行渲染的。
DisplayList中的指令是一種抽象化的GPU繪制指令(GPU是無法直接使用的,每個View對應一個),包含這些類型的指令(了解即可):
基礎繪制操作
位圖繪制:DrawBitmapOp(無法硬件渲染只能軟件渲染的視圖的Bitmap)
紋理繪制:DrawLayerOp(如TextureView的OpenGL 紋理)
圖形繪制:DrawPathOp、DrawRectOp等(由Canvas.drawXXX()生成)
視圖層級操作
子視圖引用:DrawRenderNodeOp,封裝子視圖的RenderNode,遞歸執行其Display List
背景繪制:Background Render Node的繪制指令(獨立DisplayList)
狀態控制指令
ReorderBarrier:標記后續子視圖需要按照Z軸排序(用于重疊視圖)
InorderBarrier:標記后續子視圖按默認順序排序(無重疊)
Save/Restore:保存/恢復畫布狀態等等
概括起來說,DisplayList存儲的指令=OpenGL/Vulkan命令的預處理抽象,這些指令在渲染線程中被轉換為GPU可執行的OpenGL/Vulkan指令。
CPU可執行的指令序列是指在Render Thread中將Displaylist中的抽象指令轉換成OpenGL/Vulkan的指令。
GPU原生指令是根據不同硬件生成的最基礎的硬件操作指令,比如操作寄存器等。
2、關閉硬件加速

貳
渲染階段過程(硬件加速)
1、UI線程DisplayList生成
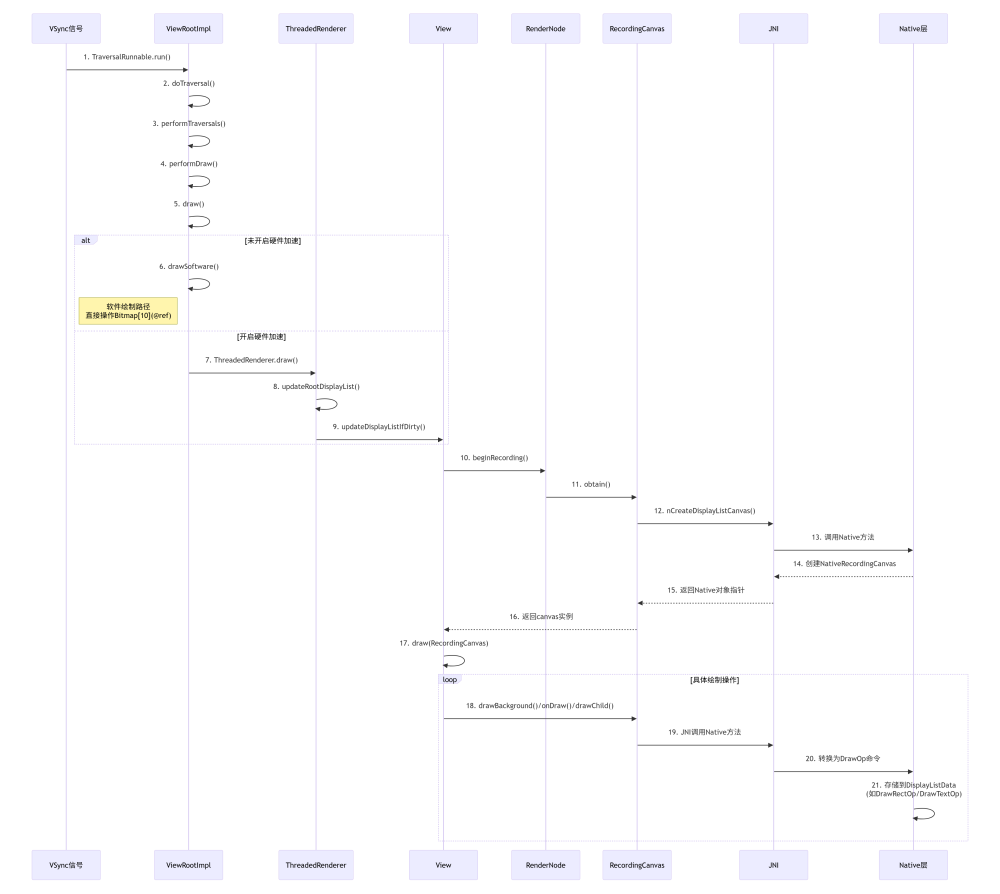
當需要進行畫面繪制的時候(VSync信號來臨)ViewRootImpl.TraversalRunnable.run()收到回調,調用ViewRootImpl.doTraversal()方法,這個方法中調用ViewRootImpl中的performTraversal()方法到performDraw()再到draw()方法,判斷是否開啟硬件加速,如果不開啟就調用drawSoftware();
如果開啟就調用ThreadRenderer.draw()方法,再繼續調用ThreadRenderer的updateRootDisplayList(),然后調到View的updateDisplayListDirty(),然后調到RenderNode.beginRecording()方法,這里面調到RecordingCanvas.obtain()方法,obtain()方法里面通過new RecordingCanvas(),然后通過JNI調用nCreateDisplayListCanvas()具體是調用Native哪個類?方法創建Native層的RecordingCanvas。
回到View的updateDisplayListDirty()方法里,執行完RenderNode.beginRecording()方法后得到RecordingCanvas的實例canvas,然后繼續執行View里面的draw()方法,根據實際情況drawBackground(),再調onDraw(),以及draw子視圖,里面都是調用RecordingCanvas的api,最終這些API都是JNI調用,在Native層調用的時候會將各種操作記錄為各種抽象命令,并不直接進行畫圖。
2、渲染線程的并行化處理
上一步已經構建好DisplayList數據,ThreadedRenderer調用父類(HardwareRenderer)函數syncAndrDrawFrame(),函數里使用JNI調用nSyncAndDrawFrame(...),也就調用到android_graphics_HardwareRenderer.cpp中的android_view_ThreadedRenderer_syncAndDrawFrame()函數。
這個函數里調用RenderProxy.cpp的syncAndDrawFrame()函數,syncAndDrawFrame()函數里調用DrawFrameTask.cpp的drawFrame()函數,此函數調用函數當前類的postAndWait()函數,然后函數里調用RenderThread的queue()函數,將當前Task入到渲染線程的隊列;當任務執行時,回調到DrawFrameTask.cpp中的run()函數,這個函數就是渲染的核心函數:
void DrawFrameTask::run() {
? ...
? if (CC_LIKELY(canDrawThisFrame)) {
? ? ? ? // 渲染上下文CanvasContext.draw()
? ? ? ? context->draw();
? ? } else {
? ? ? ? // wait on fences so tasks don't overlap next frame
? ? ? ? context->waitOnFences();
? ? }
? ...
}
真正的繪制是通過調用ContextCanvas的draw()函數,里面再通過mRenderPipeline->draw()函數將DisplayList命令轉換成GPU命令,mRenderPipeLine這個就是實際實現渲染的管線,他有可能是通過OpenGL來實現或者通過Vulkan來實現,代碼中有三種渲染管線類型(不同Android版本有一些區別):
SkiaOpenGLPipeline:基于OpenGL的Skia渲染管線
使用OpenGL API進行GPU渲染
兼容性好,支持大多數GPU
性能穩定
SkiaVulkanPipeline:基于Vulkan的Skia渲染管線
使用Vulkan API進行GPU渲染
更低的CPU開銷
更好的多線程支持
更現代的GPU API
SkiaCpuPipeline:基于CPU的Skia渲染管線
用于非Android平臺
純CPU渲染,不依賴GPU
用于調試或者特殊環境
那么Android源碼中是怎么選擇使用哪種渲染管線呢,我們看CanvasContext的create()函數:
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?RenderNode* rootRenderNode, IContextFactory* contextFactory,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?pid_t uiThreadId, pid_t renderThreadId) {
? ? // 根據系統屬性配置獲取使用的渲染管線類型
? ? auto renderType = Properties::getRenderPipelineType();
? ? switch (renderType) {
? ? ? ? case RenderPipelineType::SkiaGL:
? ? ? ? ? ? return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?std::make_unique<skiapipeline::SkiaOpenGLPipeline>(thread),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?uiThreadId, renderThreadId);
? ? ? ? case RenderPipelineType::SkiaVulkan:
? ? ? ? ? ? return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?std::make_unique<skiapipeline::SkiaVulkanPipeline>(thread),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?uiThreadId, renderThreadId);
#ifndef __ANDROID__
? ? ? ? case RenderPipelineType::SkiaCpu:
? ? ? ? ? ? return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?std::make_unique<skiapipeline::SkiaCpuPipeline>(thread),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?uiThreadId, renderThreadId);
#endif
? ? ? ? default:
? ? ? ? ? ? LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t)renderType);
? ? ? ? ? ? break;
? ? }
? ? return nullptr;
}
目前官方已經全方面切換到Vulkan庫,那我們就以Vulkan庫繼續分析。那么上文中的mRenderPipeline->draw()函數實際就是SkiaVulkanPipeline->draw()函數調用,draw()函數中調用到父類SkiaGpuPipeline的父類SkiaPipeline的renderFrame()函數mark1:下方尋找SkCanvas實例時機時返回到這里,然后繼續調到SkiaPipeline->renderFrameImpl()函數。這個函數里調用RenderNodeDrawable的基類SkDrawable->draw()函數,draw()函數又調到子類RenderNodeDrawable->onDraw()函數;
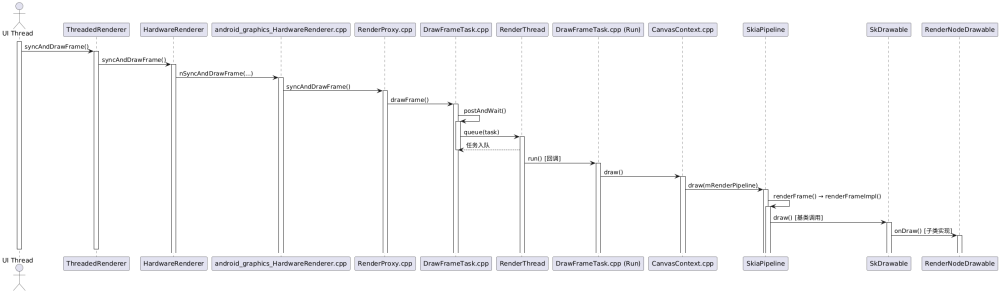
渲染線程階段時序圖1
接著繼續調到RenderNodeDrawable->forceDraw()函數再到drawContent()函數,函數調用SkiaDisplaylist->draw()函數,draw()函數委托給DisplayListData->draw()函數,DisplayListData的定義在RecordingCanvas.h文件中,實現在RecordingCanvas.cpp文件中,也就是DisplayListData->draw()在RecordingCanvas.cpp的DisplayListData::draw()函數。
?void DisplayListData::draw(SkCanvas* canvas) const {
? ? ?SkAutoCanvasRestore acr(canvas, false);
? ? ?this->map(draw_fns, canvas, canvas->getTotalMatrix());
?}
inline void DisplayListData::map(const Fn fns[], Args... args) const {
? ? ?auto end = fBytes.get() + fUsed;
? ? ?for (const uint8_t* ptr = fBytes.get(); ptr < end;) {
? ? ? ? ?auto op = (const Op*)ptr;
? ? ? ? ?auto type = op->type;
? ? ? ? ?auto skip = op->skip;
? ? ? ? ?if (auto fn = fns[type]) { ?// We replace no-op functions with nullptrs
? ? ? ? ? ? ?fn(op, args...); ? ? ? ?// to avoid the overhead of a pointless call.
? ? ? ? ?}
? ? ? ? ?ptr += skip;
? ? ?}
?}
作為一個Java開發者,這代碼看過去可能會一臉懵。別急讓我們來稍微拆解下代碼,首先看:【this->map(draw_fns, canvas, canvas->getTotalMatrix());】這一行,調用map函數時傳入的draw_fns是啥?
#define X(T) \?
? ? [](const void* op, SkCanvas* c, const SkMatrix& original) { \?
? ? ? ? ((const T*)op)->draw(c, original); \?
? ? },?
static const draw_fn draw_fns[] = {?
? ? #include "DisplayListOps.in"?
};?
#undef X?
這是C++中的一個X宏(X Macro)技術,為了避免造成更多的困惑不再細講,便于Java開發者理解可粗略的認為draw_fns就是一個數組,里面存儲了繪制相關的操作類型函數指針,具體存儲了哪些操作,定義在DisplayListOps.in文件中:
X(Save)
X(Restore)
X(SaveLayer)
X(SaveBehind)
X(Concat)
X(SetMatrix)
X(Scale)
X(Translate)
X(ClipPath)
X(ClipRect)
X(ClipRRect)
X(ClipRegion)
X(ClipShader)
X(ResetClip)
X(DrawPaint)
X(DrawBehind)
X(DrawPath)
X(DrawRect)
X(DrawRegion)
X(DrawOval)
X(DrawArc)
X(DrawRRect)
X(DrawDRRect)
X(DrawAnnotation)
X(DrawDrawable)
X(DrawPicture)
X(DrawImage)
X(DrawImageRect)
X(DrawImageLattice)
X(DrawTextBlob)
X(DrawPatch)
X(DrawPoints)
X(DrawVertices)
X(DrawAtlas)
X(DrawShadowRec)
X(DrawVectorDrawable)
X(DrawRippleDrawable)
X(DrawWebView)
X(DrawSkMesh)
X(DrawMesh)
回到map()函數中,結合上面的分析可以理解為fBytes.get()是DisplayList繪圖指令的內存地址塊的首地址,然后不斷遍歷這塊內存取出指令,根據指令的type,結合fns[]函數指針數組,匹配到指令對應的函數指針然后調用對應的函數,我們這里以DrawPath()為例,回到RecordingCanvas.cpp文件中,根據宏定義會調用【((const T*)op)->draw(c, original)】,對應到:
struct DrawPath final : Op {
? ? static const auto kType = Type::DrawPath;
? ? DrawPath(const SkPath& path, const SkPaint& paint) : path(path), paint(paint) {}
? ? SkPath path;
? ? SkPaint paint;
? ? void draw(SkCanvas* c, const SkMatrix&) const { c->drawPath(path, paint); }
};
然后調到SkCanvas->drawPath(),函數里繼續調用onDrawPath()函數:
?void SkCanvas::onDrawPath(const SkPath& path, const SkPaint& paint) {
? ? ?if (!path.isFinite()) {
? ? ? ? ?return;
? ? ?}
? ? ?const SkRect& pathBounds = path.getBounds();
? ? ?if (!path.isInverseFillType() && this->internalQuickReject(pathBounds, paint)) {
? ? ? ? ?return;
? ? ?}
? ? ?if (path.isInverseFillType() && pathBounds.width() <= 0 && pathBounds.height() <= 0) {
? ? ? ? ?this->internalDrawPaint(paint);
? ? ? ? ?return;
? ? ?}
? ? ?auto layer = this->aboutToDraw(paint, path.isInverseFillType() ? nullptr : &pathBounds);
? ? ?if (layer) {
? ? ? ? ?this->topDevice()->drawPath(path, layer->paint(), false);
? ? ?}
?}
關鍵的一行:this->topDevice()->drawPath(path, layer->paint(), false);?mark0那么topDevice()獲取到的設備是什么呢?代碼跟到這里,我們心中是否有個疑問,從開始渲染的時候選擇Vulkan渲染管線進行渲染,怎么跳來跳去都是在Skia庫中呢?Vulkan不是要直接轉換GPU命令的嗎?在哪里去轉的?
所以我們回到選擇Vulkan渲染管線的代碼的前面,先回到標注為mark1的位置SkiaPipeline的renderFrame()函數:
void SkiaPipeline::renderFrame() {
? ? bool previousSkpEnabled = Properties::skpCaptureEnabled;
? ? if (mPictureCapturedCallback) {
? ? ? ? Properties::skpCaptureEnabled = true;
? ? }
? ? // Initialize the canvas for the current frame, that might be a recording canvas if SKP
? ? // capture is enabled.
? ? SkCanvas* canvas = tryCapture(surface.get(), nodes[0].get(), layers);
? ? // draw all layers up front
? ? renderLayersImpl(layers, opaque);
? ? renderFrameImpl(clip, nodes, opaque, contentDrawBounds, canvas, preTransform);
? ? endCapture(surface.get());
? ? if (CC_UNLIKELY(Properties::debugOverdraw)) {
? ? ? ? renderOverdraw(clip, nodes, contentDrawBounds, surface, preTransform);
? ? }
? ? Properties::skpCaptureEnabled = previousSkpEnabled;
}
我們找到canvas是怎么得到的tryCapture(surface.get(), nodes[0].get(), layers);mark2這個函數也就是通過surface中獲取的,那么surface是怎么實例化的?
再往上回到SkiaVulkanPipeline->draw()函數中,
IRenderPipeline::DrawResult SkiaVulkanPipeline::draw(
? ? ? ? const Frame& frame, const SkRect& screenDirty, const SkRect& dirty,
? ? ? ? const LightGeometry& lightGeometry, LayerUpdateQueue* layerUpdateQueue,
? ? ? ? const Rect& contentDrawBounds, bool opaque, const LightInfo& lightInfo,
? ? ? ? const std::vector<sp<RenderNode>>& renderNodes, FrameInfoVisualizer* profiler,
? ? ? ? const HardwareBufferRenderParams& bufferParams, std::mutex& profilerLock) {
? ? sk_sp<SkSurface> backBuffer;
? ? SkMatrix preTransform;
? ? if (mHardwareBuffer) {
? ? ? ? backBuffer = getBufferSkSurface(bufferParams);
? ? ? ? preTransform = bufferParams.getTransform();
? ? } else {
? ? ? ? backBuffer = mVkSurface->getCurrentSkSurface();
? ? ? ? preTransform = mVkSurface->getCurrentPreTransform();
? ? }?
? ? ...
? ? renderFrame(*layerUpdateQueue, dirty, renderNodes, opaque, contentDrawBounds, backBuffer,
? ? ? ? ? ? ? ? preTransform);
? ? ...
? ? return {true, drawResult.submissionTime, std::move(drawResult.presentFence)};
}
省略了其他的干擾代碼,backBuffer = getBufferSkSurface(bufferParams);?這一行是獲取SkSurface的,我們一直將代碼跟進去,這里省略了,有興趣的同學自行去跟下源碼,跳轉實在是太多了。最終跳到SkSurface_Ganesh.cpp類中:
sk_sp<SkSurface> WrapBackendTexture() {
? ? ...
? ? auto device = rContext->priv().createDevice(grColorType,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? std::move(proxy),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? std::move(colorSpace),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? origin,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? SkSurfacePropsCopyOrDefault(props),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? skgpu::ganesh::Device::InitContents::kUninit);
? ? ...
? ? return sk_make_sp<SkSurface_Ganesh>(std::move(device));
}
可以看到device實例的創建代碼了,繼續跟進調進了GrRecordingContextPriv.cpp這個類:
sk_sp<skgpu::ganesh::Device> GrRecordingContextPriv::createDevice() {
? ? return skgpu::ganesh::Device::Make(this->context(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?budgeted,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ii,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fit,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?sampleCount,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?mipmapped,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?isProtected,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?origin,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?props,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?init);
}
可以看到是創建skgpu::ganesh::Device實例,讓我們再回到SkCanvas.cpp中的onDrawPath()函數中的this->topDevice()->drawPath(path, layer->paint(), false);這里的device和topDevice是不是同一個東西呢?
topDevice()函數中是通過fMCRec->fDevice返回,fMCRec的實例是在SkCanvas->init()函數中實例化的:
void SkCanvas::init(sk_sp<SkDevice> device) {
? ? ...
? ? fMCRec = new (fMCStack.push_back()) MCRec(device.get());
? ? ...
}
而init()函數是在SkCanvas的構造函數中調用的,這里又回到上面mark2的位置,SkCanvas的獲得過程SkiaPipeLine->tryCapture()函數中,通過surface->getCanvas()獲得canvas,一直調到SkSurface_Base.h中定義的onNewCanvas()函數,這個是基類,實現類也就回到了上面的surface的創建過程的分析過程知道為SkSurface_Ganesh.cpp文件,
我們看里面的onNewCanvas()函數的實現,里面的device就是在SkSurface_Ganesh的構造函數中傳入的,也就是我們WrapBackendTexture()函數中創建的device,到這里終于閉環了,所以topDevice()就是skgpu::ganesh::Device實例,
那么繼續skgpu::ganesh::Device->drawPath(),然后調到SurfaceDrawContext->drawPath();因為調用過程比較多,這里省略部分調用鏈,一直到獲得一個適合的Renderer進行渲染,這里我們以畫虛線為例,使用DashLinePathRenderer.cpp->onDrawPath()函數:
bool DashLinePathRenderer::onDrawPath(const DrawPathArgs& args) {
? ? ...
? ? GrOp::Owner op = DashOp::MakeDashLineOp(args.fContext, std::move(args.fPaint),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? *args.fViewMatrix, pts, aaMode, args.fShape->style(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? args.fUserStencilSettings);
? ? if (!op) {
? ? ? ? return false;
? ? }
? ? args.fSurfaceDrawContext->addDrawOp(args.fClip, std::move(op));
? ? return true;
}
這里將繪制指令封裝在DashOp中。至此本階段過程分析完成。
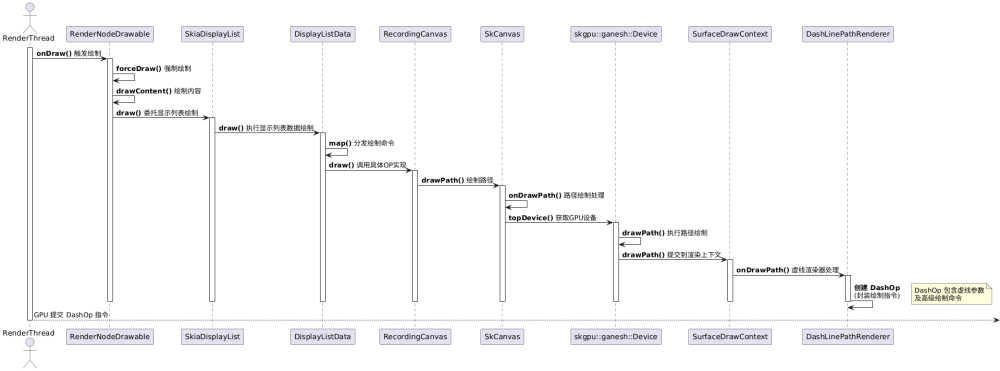
渲染線程階段時序圖2
3、提交的GPU操作命令
接上面生成的命令封裝實例后,調用:
args.fSurfaceDrawContext->addDrawOp(args.fClip, std::move(op));
看方法名猜測是將封裝的操作加到什么地方去,我們繼續跟蹤代碼,即SurfaceDrawContex->addDrawOp函數中,
void SurfaceDrawContext::addDrawOp(const GrClip* clip,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?GrOp::Owner op,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?const std::function<WillAddOpFn>& willAddFn) {
? ? ...
? ? opsTask->addDrawOp(this->drawingManager(), std::move(op), drawNeedsMSAA, analysis,std::move(appliedClip), dstProxyView,GrTextureResolveManager(this->drawingManager()), *this->caps());
? ? ...
}
是通過調用OpsTask->addDrawOp()函數進行添加的,addDrawOp函數中調用recordOp()函數將操作指令記錄到操作鏈OpChains中(包含一些合并優化操作,減少GPU命令的數量),等待flush指令執行任務OpsTask的onExcute函數,flush發生的時機可能有以下幾個:
自動觸發:AutoCheckFlush析構函數,資源壓力檢測,幀緩沖區交換前
手動觸發:SkSurface::flush(),GrContext::flush(),顯示API調用
當GrDrawingManager->flush()函數被調用,函數里調用GrRenderTask->execute()函數,實際調用的是其實現類OpsTask->onExecute()函數:
bool OpsTask::onExecute(GrOpFlushState* flushState) {
? ? const GrCaps& caps = *flushState->gpu()->caps();
? ? GrRenderTarget* renderTarget = proxy->peekRenderTarget();
? ? SkASSERT(renderTarget);
? ? // 創建渲染通道
? ? GrOpsRenderPass* renderPass = create_render_pass(flushState->gpu(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?proxy->peekRenderTarget(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fUsesMSAASurface,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?stencil,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fTargetOrigin,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fClippedContentBounds,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fColorLoadOp,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fLoadClearColor,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?stencilLoadOp,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?stencilStoreOp,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fSampledProxies,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?fRenderPassXferBarriers);
? ? flushState->setOpsRenderPass(renderPass);
? ? renderPass->begin();
? ? GrSurfaceProxyView dstView(sk_ref_sp(this->target(0)), fTargetOrigin, fTargetSwizzle);
? ? // Draw all the generated geometry.
? ? for (const auto& chain : fOpChains) {
? ? ? ? if (!chain.shouldExecute()) {
? ? ? ? ? ? continue;
? ? ? ? }
? ? ? ? GrOpFlushState::OpArgs opArgs(chain.head(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? dstView,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? fUsesMSAASurface,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? chain.appliedClip(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? chain.dstProxyView(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? fRenderPassXferBarriers,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? fColorLoadOp);
? ? ? ? flushState->setOpArgs(&opArgs);
? ? ? ? // 遍歷指令將其轉換成GPU指令
? ? ? ? chain.head()->execute(flushState, chain.bounds());
? ? ? ? flushState->setOpArgs(nullptr);
? ? }
? ? renderPass->end();
? ? // 提交給GPU執行指令
? ? flushState->gpu()->submit(renderPass);
? ? flushState->setOpsRenderPass(nullptr);
? ? return true;
}
chain.head()->execute(flushState, chain.bounds());這一行將按畫虛線為例會調到DashOpImpl->onExecute()函數:
? ? void onExecute(GrOpFlushState* flushState, const SkRect& chainBounds) override {
? ? ? ? if (!fProgramInfo || !fMesh) {
? ? ? ? ? ? return;
? ? ? ? }
? ? ? ? flushState->bindPipelineAndScissorClip(*fProgramInfo, chainBounds);
? ? ? ? flushState->bindTextures(fProgramInfo->geomProc(), nullptr, fProgramInfo->pipeline());
? ? ? ? flushState->drawMesh(*fMesh);
? ? }
onExecute函數中調用flushState->drawMesh()函數,然后一直調用到GrVkOpsRenderPass.cpp->onDraw()函數,繼續調用到GrVkCommandBuffer.cpp->draw()函數生成Vulkan 的GPU命令,然后回到OpsTask->onExecute()這個函數繼續往下看,通過flushState->gpu()->submit(renderPass);提交到GPU中執行渲染命令。剩下的就交給GPU去執行命令繪制像素了。
叁
總結與展望
Android通過分層抽象,在兼容性與性能間取得完美平衡。每層只需關注相鄰接口,使Vulkan等新技術可無縫接入現有架構。Vulkan通過瓦解GPU驅動瓶頸,將CPU渲染開銷從15ms壓縮至3ms,釋放出12ms/幀的GPU算力空間:
- 1.
指令編譯革命
- ?
DisplayList → SPIR-V中間指令(預編譯避免運行時解析)
- ?
對比OpenGL:減少80%驅動層校驗指令
- 2.
并行化引擎
- ?
OpsTask.onExecute()實現OpChain多核分發
- ?
渲染通道(RenderPass)無鎖提交使DrawCall并發量提升8倍
- ?
- 3.
零拷貝控制
- ?
GrVkCommandBuffer直接操作設備內存
- ?
消除OpenGL的顯存二次拷貝(省去3ms/幀)
現代圖形架構的核心矛盾是繪制復雜度與幀時間確定性的對抗。Android的解法是:將非確定操作提前(指令編譯),將確定操作并發(管線并行),最終馴服GPU這頭性能猛獸。
此刻我們正站在渲染技術的奇點:當Vulkan封印揭開,幀率已不是終點,而是重構視覺體驗的起點。未來會有哪些期待?
DisplayList預測生成(LSTM模型預判下幀指令)?
將Path計算卸載到DSP處理(節省GPU 30%負載)?
實時光追管線(Vulkan Ray-Tracing擴展)?
點贊+關注,下一期更精彩!
本文分析源碼基于最新的AOSP:https://cs.android.com/android/platform/superproject?hl=zh-cn
- ?
)
 配置為公網訪問(監聽 0.0.0.0))

實戰二——圖像邊界擴展cv2.copyMakeBorder())













-地形可視化處理)
 的優雅之道》)
