作者:來自 Elastic?James Baiera?及?Graham Hudgins
了解失敗存儲,這是 Elastic Stack 的一項新功能,用于捕獲和索引之前丟失的事件。
想獲得 Elastic 認證嗎?看看下一期 Elasticsearch Engineer 培訓什么時候開始!
Elasticsearch 擁有豐富的新功能,幫助你為自己的用例構建最佳搜索解決方案。深入學習我們的示例筆記本,開始免費的云試用,或立即在本地運行 Elastic。
如果一棵樹在森林里倒下,而周圍沒有人,它會發出聲音嗎?答案是會的。就像一條日志消息被發出但未能處理進你的可觀測性平臺時,這條日志確實發生了 —— 而且如果它很重要,你幾乎肯定最終會聽說它。
Elastic 能夠適應系統發出的各種數據:日志、指標、跟蹤、自定義遙測等。但當這些數據因為模式變化、代理配置錯誤或某個異常服務發出意外字段而不符合預期格式時,它可能無法處理,并會悄無聲息地消失。
這種缺失本身就是一種信號。但它很難被檢測、很難調試、也很難報告。更糟的是,它把問題甩給了客戶端去查明原因。
這就是我們構建 失敗存儲 的原因:一種全新的方式,可以直接在 Elastic Stack 中捕獲、調試和分析失敗的事件。在這篇博客中,我們將介紹 Elastic 的失敗存儲,并解釋它如何提供數據攝取問題的可見性、幫助調試模式變化、讓團隊能夠監控數據質量并精準定位失敗模式。
關于失敗存儲
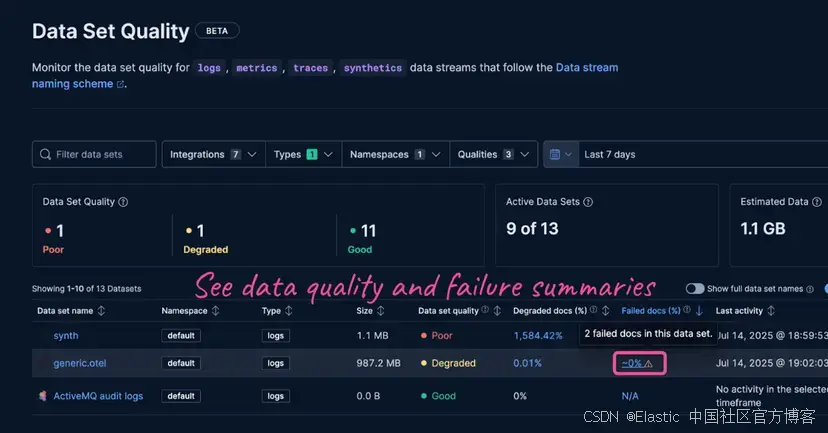
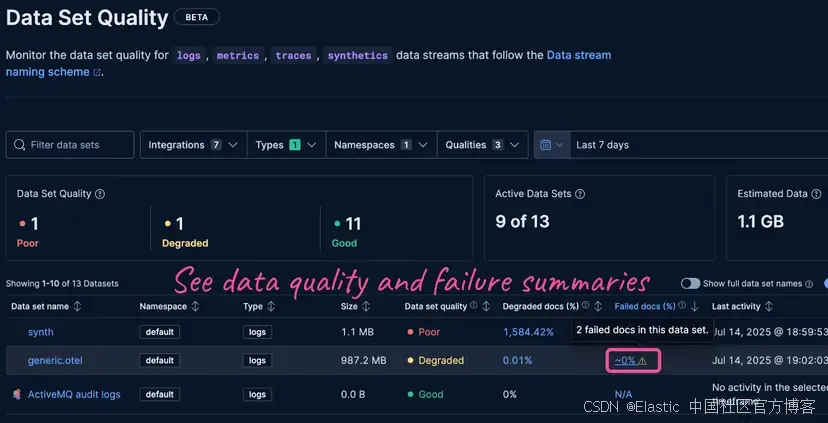
失敗存儲讓你能夠看到以前只有發送數據的客戶端和死信隊列才能看到的失敗事件。它通過將失敗的文檔捕獲并索引到專用的 ::failures 索引中來工作,這些索引與生產數據一起存在于你的數據流中。你可以按數據流啟用它,也可以通過一個集群設置在多個數據流中啟用。
重要性
團隊通常處于真實數據源的下游。他們不寫代碼,只是維持系統運行。當上游團隊發布的更改破壞了映射或引入了意外字段時,就會發生失敗。但如果無法訪問原始的失敗數據,調試就只能靠猜。
更糟的是,當數據無法被索引時,它就不存在于你的索引中 —— 這意味著更難評估影響。你無法追蹤哪個數據流失敗最頻繁,也無法量化管道損壞的程度。如果平臺從未接收到這些數據,你當然無法對缺失內容發出告警(除了當數據缺失時的告警)。
故障存儲使開發人員能夠了解哪些數據索引失敗以及失敗原因,從而為可觀測性工程師提供快速了解和修復數據提取故障所需的工具。由于故障存儲在 Elasticsearch 中,因此分類也非常迅速,無需從遠程客戶端或數據采集器收集信息。
開始使用
為新的數據流進行設置…
PUT _index_template/my-index-template
{"index_patterns": ["my-datastream-*"],"data_stream": { },"template": {"data_stream_options": {"failure_store": { // ?"enabled": true } }}
}…或為現有數據流啟用
在 Kibana 的 Stack 管理中為單個數據流啟用失敗存儲,或使用 _data_stream API:
PUT _data_stream/my-existing-datastream/_options
{"failure_store": {"enabled": true}
}通過集群設置啟用失敗存儲
如果你有大量現有數據流,可能希望在一個地方統一啟用它們的失敗存儲。無需單獨更新每個數據流的選項,只需在集群設置中將 data_streams.failure_store.enabled 設置為索引模式列表。任何匹配這些模式的數據流都將啟用失敗存儲。
PUT _cluster/settings
{"persistent" : {"data_streams.failure_store.enabled" : [ "my-datastream-*", "logs-*" ]}
}失敗文檔響應
啟用失敗存儲后,以前會失敗的請求現在會有不同的處理方式。客戶端現在會收到 201 Created,而不是 400 Bad Request。特別是如果你使用自定義應用或我們的語言客戶端,請確保相應更新代碼。當文檔進入失敗存儲時,響應中會包含 failure_store: used 屬性。
{"_index": ".fs-logs-generic.otel-default-2025.07.31-000010","_id": "2K9IYpgBfukt97YIaUPG","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1,"failure_store": "used"
}像處理其他日志一樣搜索和篩選失敗數據,支持 ES|QL 和 Kibana 工具:
FROM logs-generic.otel-default::failures失敗存儲中的數據包含所有上下文信息,使調試更簡單。每個 ::failures 索引都包含管道失敗的信息,以及具體的錯誤消息、堆棧跟蹤和錯誤類型,幫助你識別模式。
如果你遇到大量錯誤,不知道從哪里開始,可以使用 ES|QL 和 ML 功能。通過 ES|QL 暴露的數據,可以利用 ML 功能(如 CATEGORIZE)分析錯誤,幫助解析錯誤并提取模式。在我們的文檔中可以關于數據修復的技術。

使用你已經用于其他數據的數據流生命周期來控制成本和保留時間。如果沒有自定義保留策略,失敗存儲數據將保留 30 天。
通過失敗指標和按失敗百分比可排序的儀表板隨時間監控數據質量,發現需要調查的新問題區域。在文檔中可以關于數據質量監控的內容。
了解更多
失敗存儲從 Elastic 9.1 和 8.19 開始可用,并將在即將發布的版本中默認在 logs-*-* 索引上啟用。想了解更多,請查閱文檔獲取設置說明和最佳實踐。
原文:Failure store: see what didn’t make it - Elasticsearch Labs

)











-正則化方法價格分類案例)





---自動識別設備,并導出配置)