摘要:盡管鏈式思維(CoT)推理能提升模型性能,卻因離散 CoT 標記(DCoT)的生成而帶來顯著時間開銷。連續 CoT(CCoT)是更高效的替代方案,但現有方法受限于間接微調、對齊不足或目標不一致。為此,我們提出創新高效的推理框架 SynAdapt:首先合成高質量 CCoT,作為大模型精確且有效的對齊目標,使其直接學會連續推理并給出正確答案;其次,僅憑 CCoT 難以解決難題,SynAdapt 引入難度分類器,結合問題上下文與 CCoT 在簡短推理后識別困難樣本,再自適應提示模型重新思考,以進一步提升表現。跨不同難度基準的大量實驗充分驗證了該方法的有效性,在準確率和效率之間實現了最佳平衡。
論文信息
論文標題: "SynAdapt: Learning Adaptive Reasoning in Large Language Models via Synthetic Continuous Chain-of-Thought"
作者: "Jianwei Wang, Ziming Wu, Fuming Lai, Shaobing Lian, Ziqian Zeng"
會議/期刊: "arXiv preprint arXiv:2508.00574v1"
發表年份: 2025
原文鏈接: "https://arxiv.org/pdf/2508.00574v1"
代碼鏈接: ""
關鍵詞: ["連續思維鏈", "自適應推理", "大語言模型", "效率優化", "難度分類"]
核心要點
SynAdapt創新性地通過生成合成連續思維鏈(Synthetic CCoT) 作為精準對齊目標,并結合難度分類器動態調整推理策略,在保持高精度的同時顯著提升推理效率,實現了準確性與效率的最優平衡。
研究背景:思維鏈推理的效率困境
近年來,思維鏈(Chain-of-Thought, CoT) 推理已成為提升大語言模型(LLM)復雜任務解決能力的關鍵技術。然而,傳統離散思維鏈(DCoT)生成大量自然語言 tokens,導致推理速度慢、計算成本高的問題。為解決這一痛點,連續思維鏈(Continuous CoT, CCoT) 應運而生,它通過LLM的隱藏狀態進行推理,跳過冗余的token生成,理論上能在保持推理能力的同時提升效率。
現有CCoT方法卻面臨三大挑戰:
- 間接微調(Indirect Training):如Coconut通過課程學習逐步替換DCoT,但缺乏顯式對齊,導致推理能力損失
- 對齊不充分(Partial Alignment):如CODI僅對齊DCoT和CCoT的最后一個token狀態,忽略中間推理過程
- 目標不一致(Incoherent Target):如CompressCoT僅對齊部分"重要token",破壞了推理鏈的連貫性
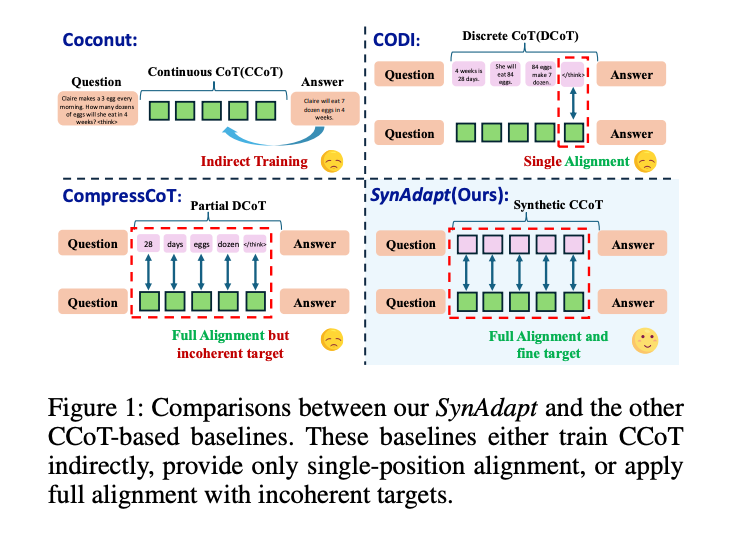
圖1:SynAdapt與其他CCoT方法的對比。SynAdapt通過合成CCoT實現完全對齊且目標一致,而其他方法存在間接訓練、單一對齊或目標不一致等問題
方法總覽:SynAdapt的雙階段自適應推理框架
SynAdapt提出了一個兩階段框架,通過合成CCoT生成和自適應推理策略,同時解決準確性和效率問題。
核心創新點
- 合成連續思維鏈(Synthetic CCoT):生成高質量連續思維鏈作為對齊目標,替代傳統DCoT
- 動態難度感知:訓練難度分類器,根據問題復雜度動態選擇推理策略
- 全對齊微調:通過多損失函數優化,實現思維鏈的完整對齊
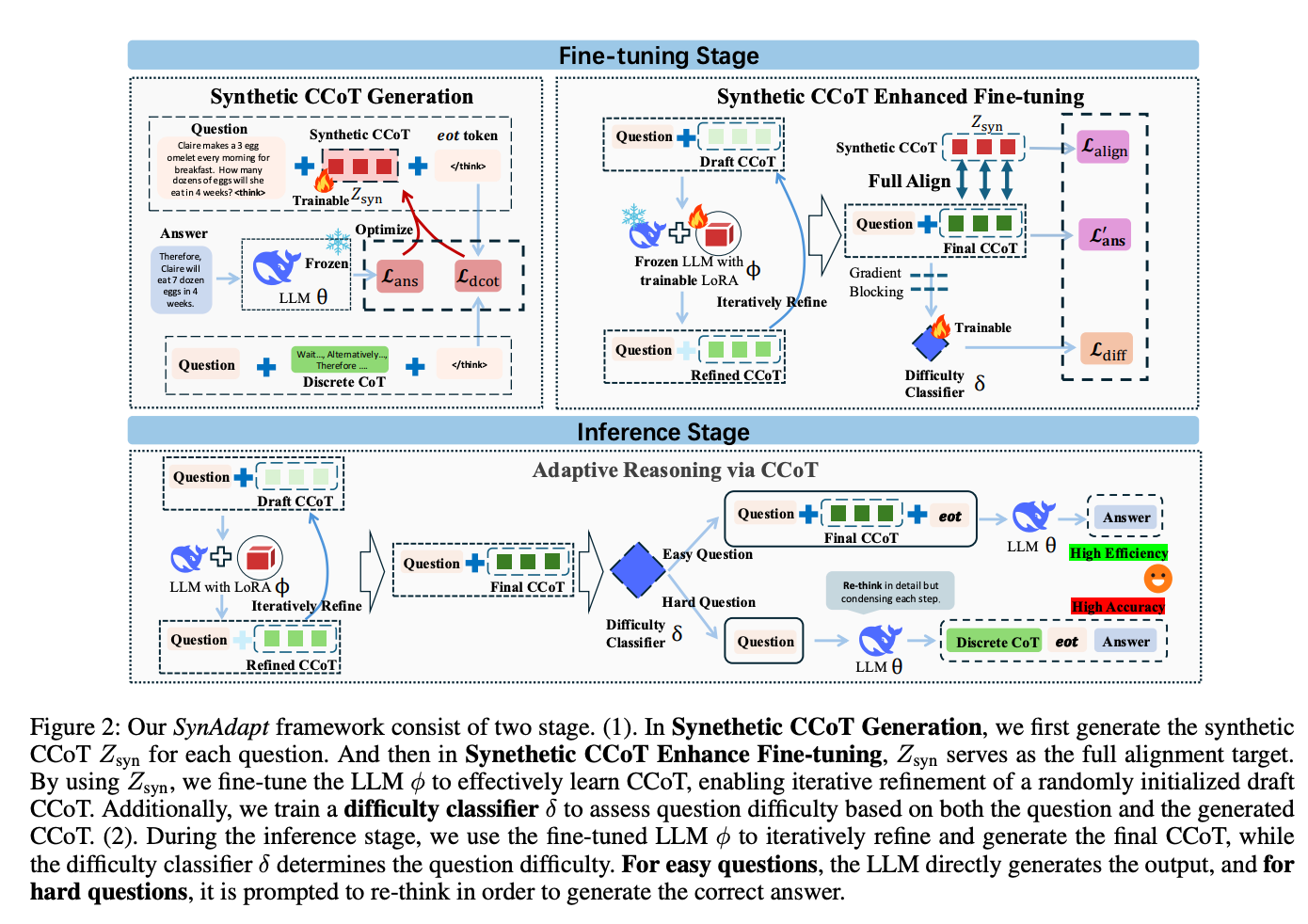
圖2:SynAdapt框架分為微調階段(上)和推理階段(下)。微調階段生成合成CCoT并訓練難度分類器;推理階段根據問題難度動態調整推理策略
關鍵技術解析
1. 合成CCoT生成:精準對齊的基礎
SynAdapt首先為每個問題生成合成連續思維鏈(Z_syn),作為后續微調的"黃金標準"。具體步驟:
- 隨機初始化一個長度為m的連續向量Z_syn
- 固定LLM參數,僅優化Z_syn,使LLM能基于問題和Z_syn生成正確答案
- 通過兩個損失函數優化:
- 答案損失(L_ans):確保Z_syn引導LLM生成正確答案
- DCoT對齊損失(L_dcot):使Z_syn的隱藏狀態與真實DCoT的隱藏狀態對齊
這一過程類似為LLM定制"思維導航圖",確保模型學習到高效且準確的推理路徑。
2. 增強微調:迭代優化思維鏈
微調階段采用迭代優化策略,訓練LLM將隨機初始化的"草稿思維鏈"(Draft CCoT)逐步優化為與合成CCoT對齊的最終思維鏈:
- 從無意義的重復token序列初始化草稿思維鏈
- 通過LoRA模塊微調LLM,迭代精煉草稿思維鏈(默認4輪迭代)
- 多損失函數聯合優化:
- 對齊損失(L_align):使最終思維鏈與合成CCoT對齊
- 答案損失(L’_ans):確保最終思維鏈能引導LLM生成正確答案
3. 難度分類器:智能任務分診
為解決簡單問題過度推理和復雜問題推理不足的矛盾,SynAdapt訓練了一個難度分類器(δ):
- 輸入:問題本身和對應的CCoT
- 輸出:0-1之間的難度分數
- 訓練策略:構造難易問題對,通過對比損失(L_diff)訓練分類器
推理時,根據難度分數動態調整策略:
- 簡單問題(分數<τ):直接基于CCoT生成答案,追求效率
- 困難問題(分數≥τ):丟棄CCoT,提示LLM重新進行詳細推理,確保準確性
實驗結果:全面超越現有基線
1. 準確性-效率權衡優勢
在五大數學推理基準測試(AIME25、AIME24、AMC23、MATH500、GSM8K)上,SynAdapt展現出顯著優勢:
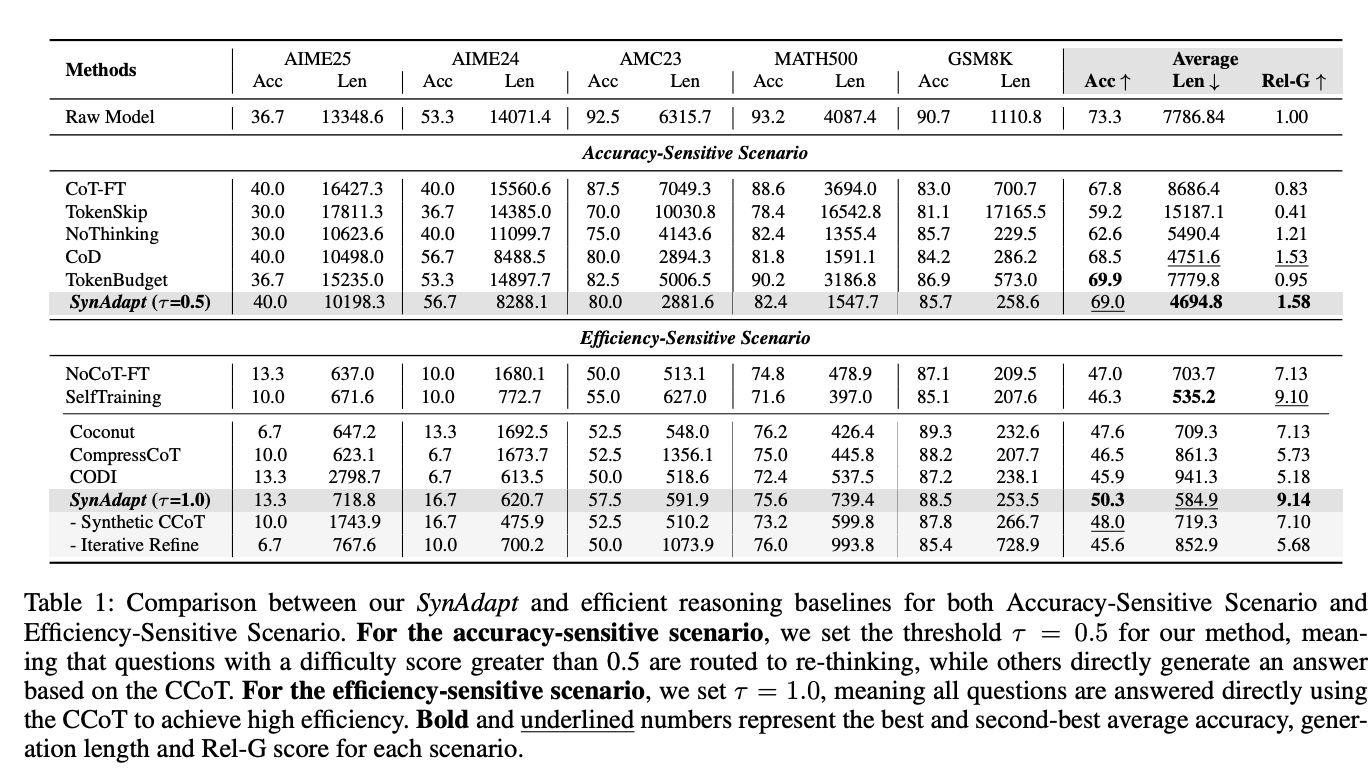
表1:SynAdapt與各基線方法在準確性敏感場景和效率敏感場景的對比
-
準確性敏感場景(τ=0.5):
- 平均準確率達69.0%,與原始模型相當
- 平均生成長度縮短39.7%(從7786.8→4694.8 tokens)
- Rel-G指標達1.58,顯著優于CoD(1.53)和NoThinking(1.21)
-
效率敏感場景(τ=1.0):
- 平均長度僅584.9 tokens,比原始模型縮短92.5%
- 準確率保持50.3%,遠超Coconut(47.6%)和CODI(45.9%)
- Rel-G指標達9.14,為所有方法最高
2. 準確率-效率權衡曲線
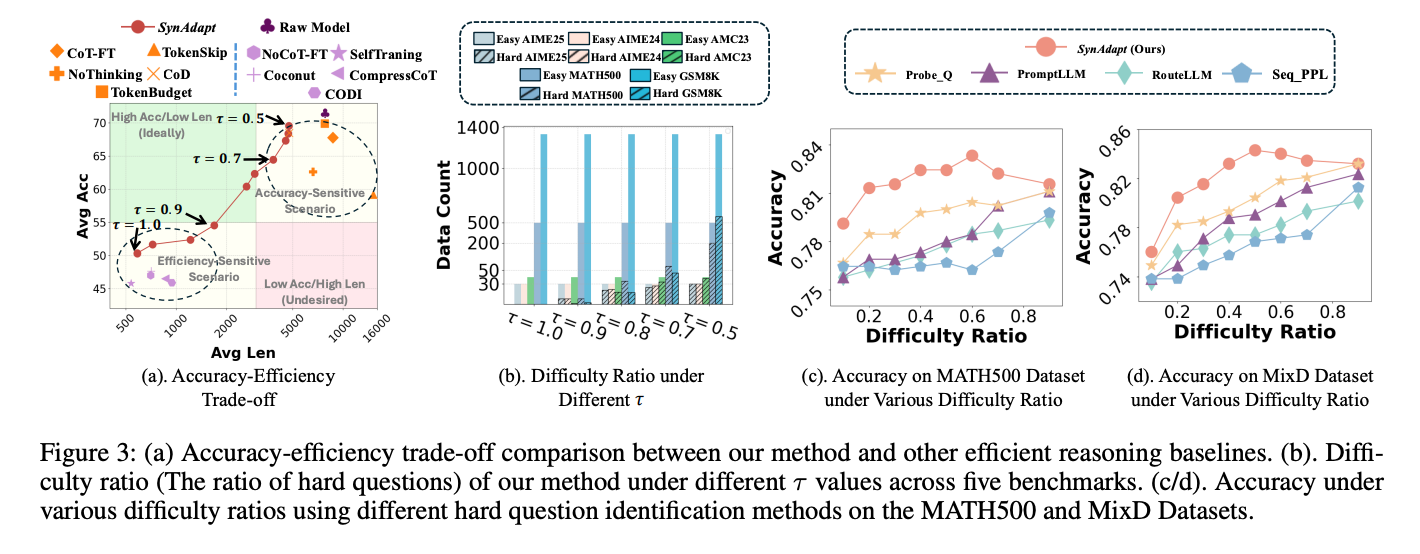
圖2:不同方法的準確率-效率權衡曲線。SynAdapt(紅點)位于"高準確率-低長度"的理想區域
通過調整閾值τ,SynAdapt可靈活適應不同場景需求:
- τ=0.5時優先保證準確率(適合科研、醫療等高風險場景)
- τ=1.0時最大化效率(適合實時交互、邊緣設備等資源受限場景)
3. 難題識別能力
SynAdapt的難度分類器在MATH500和MixD數據集上表現優異:
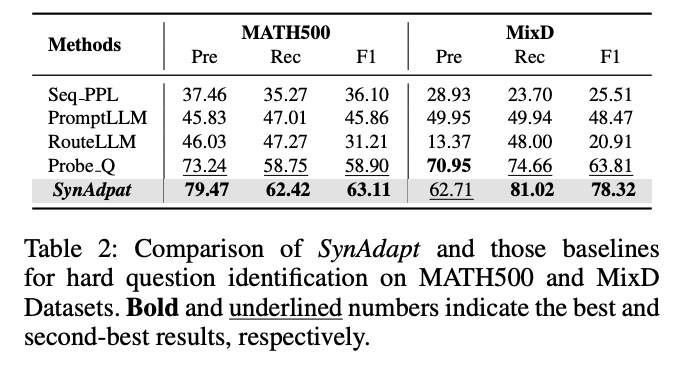
表2:SynAdapt與基線方法在難題識別任務上的對比(F1值)
- 在MATH500數據集上,F1值達63.11,遠超PromptLLM(45.86)和RouteLLM(31.21)
- 在MixD數據集上,F1值達78.32,顯著優于Probe.Q(63.81)
4. 訓練效率分析
盡管增加了合成CCoT生成步驟,SynAdapt的整體訓練成本仍具競爭力:
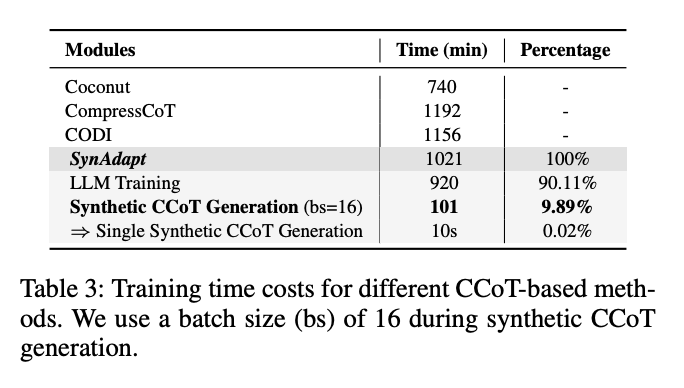
表3:不同CCoT方法的訓練時間對比
- 總訓練時間1021分鐘,僅比CODI(1156分鐘)少11.6%
- 合成CCoT生成僅占總時間的9.89%,單條合成CCoT生成僅需10秒
5. 跨模型泛化能力
在不同規模的LLM骨干模型上,SynAdapt均保持穩定優勢:
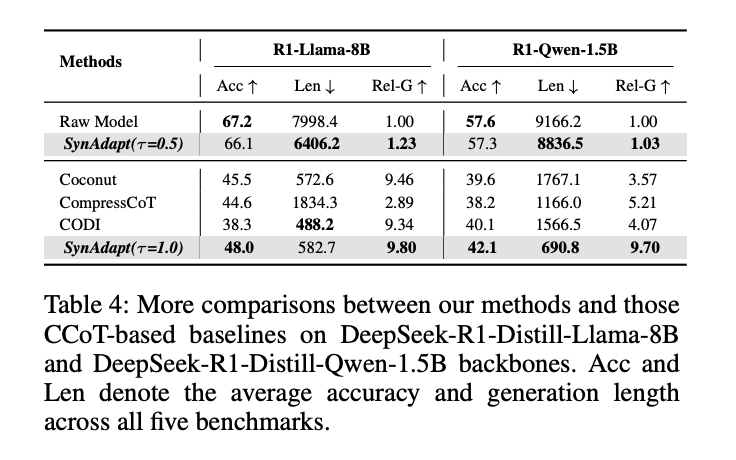
表4:SynAdapt在不同LLM骨干上的表現
- 在R1-Llama-8B上,τ=1.0時Rel-G達9.80,遠超Coconut(9.46)
- 在R1-Qwen-1.5B(輕量級模型)上,τ=1.0時Rel-G達9.70,為所有方法最高
實際案例:推理質量對比
以"不同進制轉換"問題為例,SynAdapt展現出簡潔且準確的優勢:
- Coconut:生成冗長推理過程,但答案錯誤
- CompressCoT:推理簡潔但遺漏關鍵步驟,答案錯誤
- CODI:推理正確但包含大量冗余內容(768 tokens)
- SynAdapt:僅用47 tokens完成準確推理,實現"又快又好"
未來工作與思考
1. 方法改進方向
- 合成CCoT優化:探索動態長度CCoT,避免固定長度帶來的信息浪費或不足
- 多粒度難度分類:當前二分類(難易)可擴展為多級別分類,實現更精細的推理資源分配
- 領域適應:目前主要驗證數學推理任務,需擴展到代碼生成、邏輯推理等更多領域
2. 實際應用挑戰
- 閾值τ的選擇:不同應用場景需要不同的τ值,如何自適應調整仍是開放問題
- 計算資源消耗:合成CCoT生成雖高效,但對顯存要求較高(尤其長序列)
- 錯誤傳遞風險:合成CCoT的質量直接影響后續微調效果,需進一步提升魯棒性
3. 更廣泛的影響
SynAdapt的思想可啟發更廣泛的研究方向:
- 通用AI效率優化:不僅限于LLM推理,可擴展到多模態模型、強化學習等領域
- 人機協作新模式:難度感知機制可用于動態調整人機分工,提升協作效率
- 邊緣設備部署:通過CCoT壓縮推理過程,為LLM在邊緣設備部署提供可能









)






)
——工具欄和選擇網格、滾動列表和分組、窗口、自定義皮膚樣式、自動布局)

