01 引言
在端到端自動駕駛的研發競賽中,算法的迭代速度遠超物理世界的測試能力。單純依賴路測不僅成本高昂、周期漫長,更無法窮盡決定系統安全性的關鍵邊緣場景(Corner Cases)。
因此,硬件在環(HIL)仿真測試成為唯一的出路。然而,將仿真數據閉環注入域控制器流程中存在諸多技術難度,特別是高像素相機原始數據,如何無損、無延遲地將數據灌入對時序和信號要求極為苛刻的域控制器中成為了當前調試HiL系統的主要挑戰!
針對這些問題,康謀也有一些思考、經驗與看法,本文將與大家一起交流。下文將介紹高保真實時注入系統架構、核心技術、I2C 作用及實踐挑戰的相關經驗!
02 系統架構概覽
高保真實時仿真注入系統的核心目標,是將仿真環境中生成的傳感器數據,以極低的延遲和與真實傳感器別無二致的物理信號特性,注入到待測的設備(DUT)中。這套系統的典型架構由三個關鍵部分組成:仿真主機(Simulation Host)、數據注入設備(Injection Device)和待測設備(DUT, Device Under Test)。
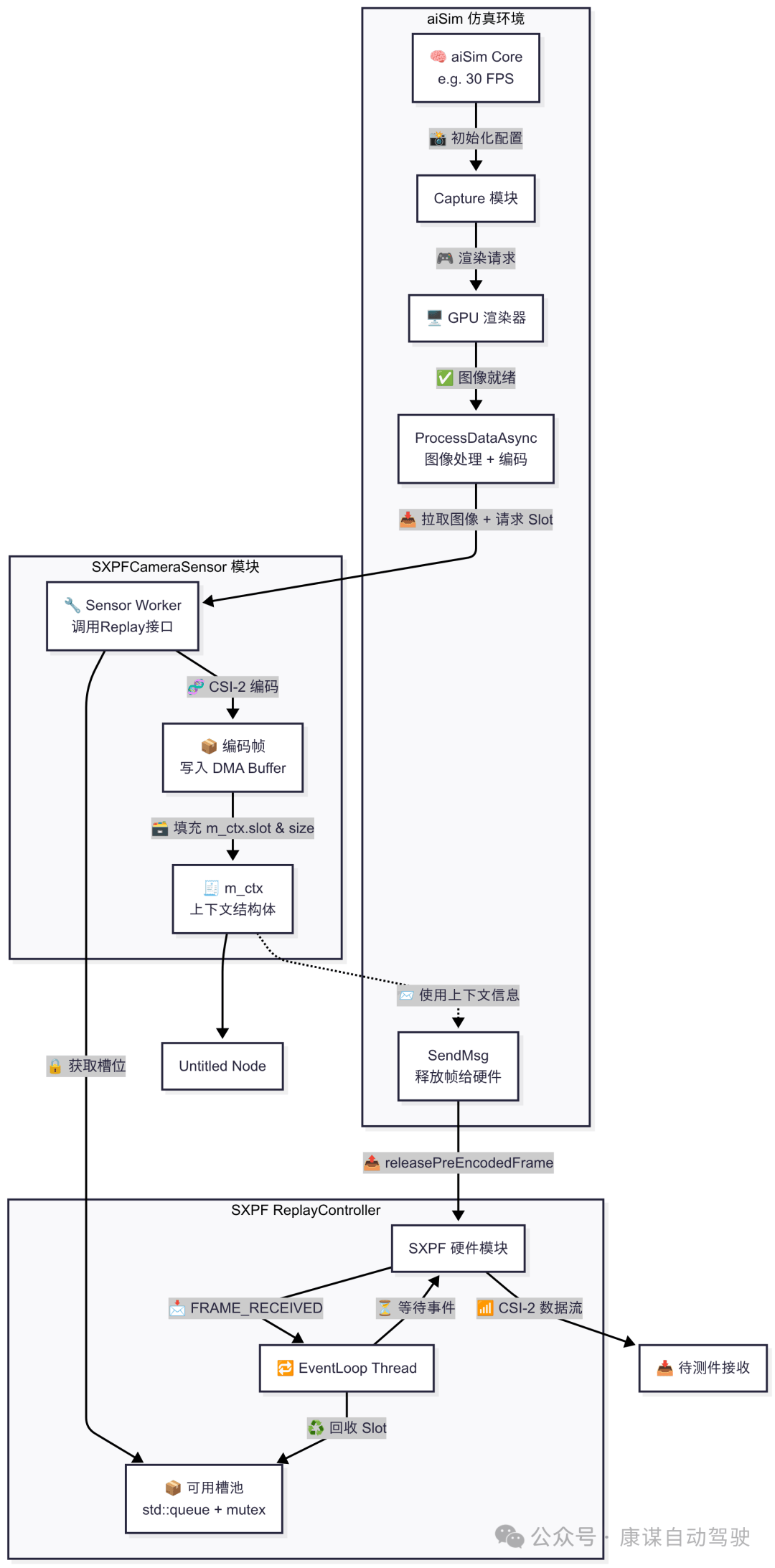
數據流的完整流程如下:
數據生成:仿真軟件aiSim在仿真主機上根據預設場景生成相機的原始圖像幀數據;
數據傳輸:這些原始數據通過網絡被發送到數據注入設備;
數據處理與編碼:注入設備上的應用程序(如camera_sensor.cpp中的邏輯)接收數據。為了實現最低延遲,數據被直接送入一塊專用的硬件板卡(proFRAME);
DMA/RDMA傳輸:數據通過PCIe總線,利用直接內存訪問(DMA)或遠程直接內存訪問(RDMA)技術,被高效地傳輸到注入板卡的內存或板載GPU內存中,此過程最大限度地減少了CPU的干預;
CSI-2/GMSL2封裝:板卡上的FPGA或專用處理器(ASIC)將內存中的圖像數據打包成CSI-2協議格式,并驅動GMSL2序列化器(Serializer)芯片將其轉換為高速串行信號;
物理注入:GMSL2信號通過同軸電纜傳輸到DUT的GMSL2解串器(Deserializer),DUT的處理器(SoC)通過其CSI-2接口接收到圖像數據,就像從一個真實的相機接收一樣。
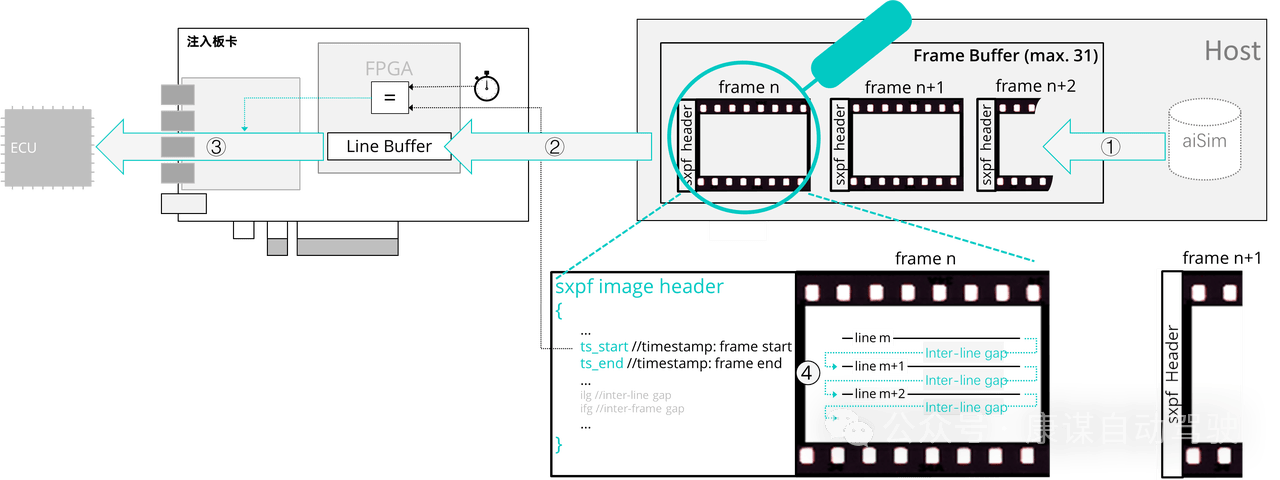
① 仿真主機aiSim高保真相機數據傳輸到幀緩沖區(DMA);
② 逐行傳輸到proFRAME硬件(PCIe);
③ 基于時間戳/行間隙的時鐘周期數發送圖像幀(CSI-2幀);
④ 基于行間隙定義圖像幀行間時序。
03 技術深度解析
仿真源數據與準備
仿真注入的起點是仿真軟件生成的源數據。在我們的案例中,仿真軟件aiSim輸出的是原始的相機圖像幀(RAW12)。這些數據在注入前,必須經過精心的預處理,以確保DUT能夠正確解析。
核心的預處理步驟是在Host端完成的。這個過程并非簡單的格式轉換,而是嚴格按照待測件的需求,將aiSim生成的裸數據(payload)封裝成一個完整的、符合物理層規范的數據包。具體來說:
數據拷貝:將aiSim生成的圖像數據src_image.m_data拷貝到一個臨時的暫存緩沖區staging_buffer中;
CSI-2編碼:調用核心編碼函數csi2_single_encode,將暫存區中的裸數據打包成CSI-2格式。這一步會根據配置添加CSI-2的包頭(Packet Header)、數據負載(Data Payload)、錯誤校驗碼(ECC)等;
proFRAME頭部填充:在編碼后的CSI-2數據包前,附加一個sxpf_image_header_t頭部。這個頭部包含了注入任務所需的關鍵元數據,例如圖像的寬、高、每像素位數(bpp)、時間戳,以及兩個至關重要的時序參數:ilg (Image Line Gap) 和 ifg (Image Frame Gap);
- ilg:行間隙,定義了上一行圖像數據傳輸完成到下一行開始之間的精確時間間隔。
- ifg:幀間隙,定義了上一幀圖像數據傳輸完成到下一幀開始之間的精確時間間隔。
這兩個參數直接控制了數據在GMSL2鏈路上的“微觀時序”。如果設置不當,即使數據內容完全正確,DUT的解串器也可能因為不符合預期的時序而無法鎖定信號或正確接收數據,導致回放幀率異常波動甚至鏈路失敗。
零拷貝與低延遲的基石:DMA與RDMA
要實現“實時”注入,數據在注入設備內部的搬運效率至關重要。DMA和RDMA正是解決此問題的關鍵。
- DMA (Direct Memory Access):DMA是現代計算機系統的基本特性。它允許外設(如proFRAME板卡)在沒有CPU干預的情況下,直接與主內存進行數據讀寫。在默認的注入流程中,proFRAME從相機或網絡獲取數據后,通過PCIe總線直接將數據寫入由CPU預先分配好的內存緩沖區(Buffer)。這避免了CPU逐字節拷貝數據的開銷,顯著提升了吞吐量。通常,基于DMA的PCIe Gen3 x8鏈路,可以將延遲控制在1毫秒級別。
- NVIDIA GPUDirect RDMA:GPUDirect RDMA允許將仿真的圖像數據直接從NVIDIA GPU發送到proFrame中,完全無需占用主系統內存(RAM)的帶寬,也無需CPU進行任何數據中轉。整個數據鏈路變為:aiSim -> GPU顯存 -> PCIe -> proFRAME 。這消除了內存與顯存之間的拷貝開銷,也為CPU節約了寶貴的內存帶寬資源,是構建微秒級延遲注入系統的核心技術。
物理鏈路注入:GMSL2與CSI-2協議棧
GMSL2 (Gigabit Multimedia Serial Link 2):作為物理層載體,是專為汽車應用設計的高速串行接口。在仿真注入中,它的角色就是將編碼好的數字圖像信號,轉換為能在物理線纜上傳輸的電信號。
CSI-2 (Camera Serial Interface 2):CSI-2是在GMSL2之上傳輸的數據協議。它定義了數據如何被組織和打包。
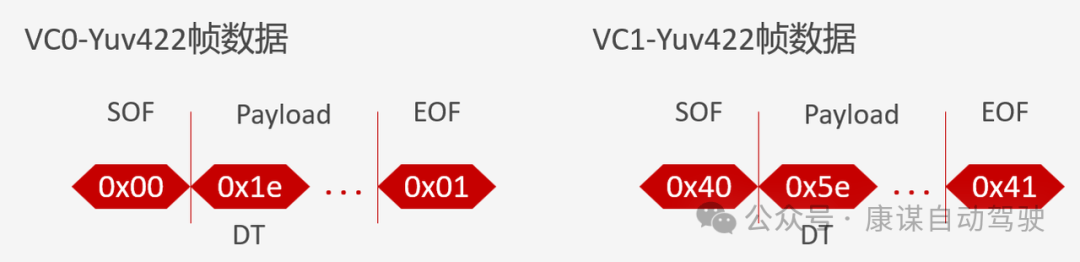
數據包結構
一個CSI-2數據包通常由幀起始符(SOF - Start of Frame)、包頭(Packet Header)、數據負載(Payload)和幀結束符(EOF - End of Frame)組成。如資料所示,SOF和EOF的值可以用來區分不同的虛擬通道(Virtual Channel, VC)。例如,VC0的SOF/EOF值為0x00/0x01,而VC1則為0x40/0x41。
實現關鍵
整個注入鏈路的最后一公里,就是將內存中(通過DMA/RDMA獲取)準備好的、包含sxpf_image_header_t和CSI-2編碼后負載的完整數據幀,交給proFRAME板卡。板卡上的邏輯會解析這些數據,驅動GMSL2序列化器芯片,嚴格按照ilg和ifg定義的時序,將CSI-2數據包序列化后發送出去,即通過sxpf_release_frame()函數將準備好的數據緩沖區slot句柄和數據大小交給硬件,硬件隨后便接管了發送任務。
04 I2C調試與驗證
在GMSL2鏈路中,I2C是配置和調試不可或缺的生命線。它負責在主機(proFRAME)和遠端設備(DUT)的SerDes(Serializer/Deserializer)芯片之間建立一條雙向控制通道。
調試實踐
調試GMSL2鏈路問題時,I2C是最直接的突破口。proFRAME提供的初始化序列文件(.ini文件)就是I2C調試實踐的絕佳范例。
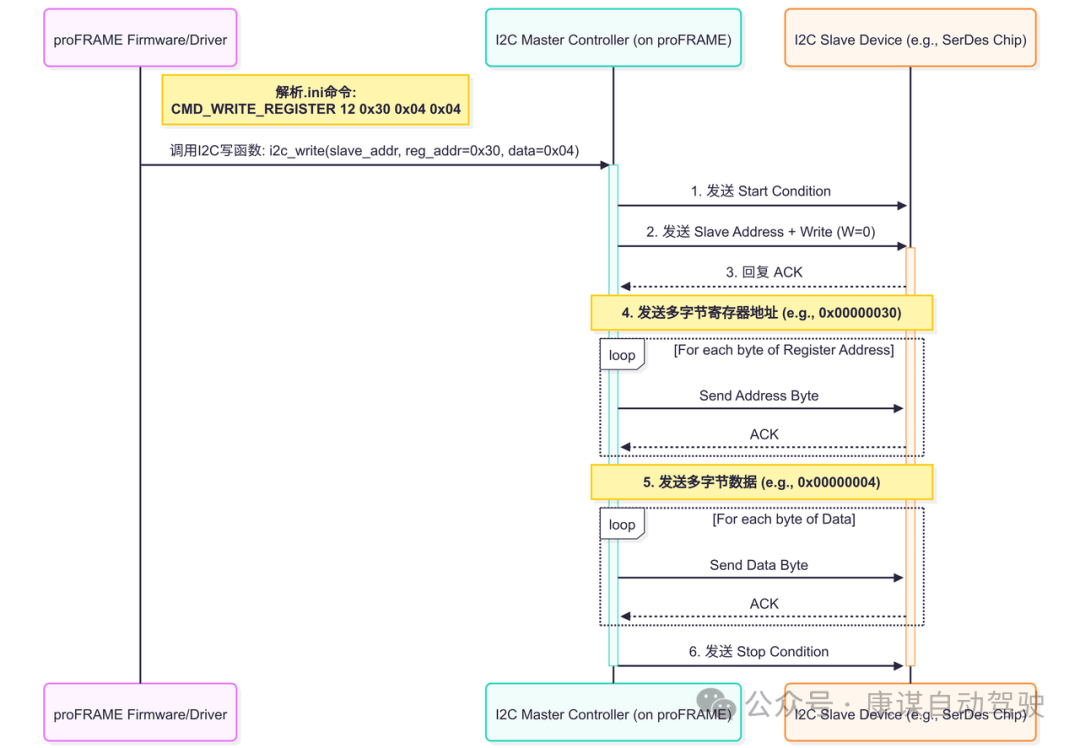
上述序列圖直觀地展示了.ini文件中的一條高級命令到底層I2C總線時序的完整轉換過程。
解析與調用:proFRAME的固件或驅動作為控制大腦,首先解析.ini文件中的CMD_WRITE_REGISTER命令,并提取出目標從設備地址、寄存器地址和要寫入的數據;
啟動通信:固件調用板載的I2C主控制器,發起一次寫操作。控制器首先發送“起始信號”,并在總線上廣播目標從設備的地址及寫操作位;
地址與數據傳輸:在收到從設備的“應答信號”(ACK)確認設備存在后,主控制器嚴格按照順序,逐字節地發送多字節的寄存器地址和數據。每一次字節傳輸完成后,都會等待從設備的ACK,以確保數據被成功接收;
結束通信:所有數據發送完畢后,主控制器發送“停止信號”,釋放I2C總線,完成本次操作。
05 實踐中的挑戰與考量
在搭建和運行一套高保真實時注入系統的過程中,會遇到諸多工程挑戰
時鐘同步與時序精準:嚴格來說,仿真主機、注入設備和DUT工作在各自的時鐘域下。雖然物理層時鐘可以由GMSL2鏈路恢復,但數據流的宏觀時序必須嚴格受控。正如前述,ilg和ifg參數的精確計算和配置至關重要。需要通過工具分析目標相機真實的數據流特性,或通過專用計算表格,調整這些參數,使得注入設備輸出的數據速率(Data Lane Rate)與DUT的期望值精確匹配,從而確保時序上的“保真”
帶寬瓶頸分析:整條鏈路的有效帶寬受限于最慢的一環。
- 仿真側:仿真主機的渲染能力和網絡出口帶寬;
- 注入設備:PCIe總線帶寬(例如,x8 Gen3理論值為~7.8 GB/s)、DMA/RDMA的實際效率、CPU到GPU的拷貝速度(在使用DMA時);
- 物理鏈路:GMSL2本身的帶寬上限。
在設計方案時,必須對每個環節的帶寬進行評估,確保沒有明顯的瓶頸。例如,即使GMSL2帶寬足夠,但如果采用DMA方式且CPU到GPU的拷貝速度跟不上,同樣會造成幀率下降和延遲增加。
系統穩定性:硬件在環測試通常需要長時間(數小時甚至數天)連續運行。
- 內存管理:必須杜絕內存泄漏。在上層實現中,通過一個固定大小的緩沖區池(m_availableSlots隊列)和嚴謹的申請(acquirePlaybackSlot)釋放(releasePreEncodedFrame)邏輯來循環使用內存。當硬件處理完一幀數據后,會通過事件(SXPF_EVENT_FRAME_RECEIVED)通知上層軟件,軟件再將被釋放的緩沖區重新加入可用隊列。這種機制保證了內存使用量的恒定。
- CPU/GPU資源:要避免CPU的忙等待。在acquirePlaybackSlot的實現中,當沒有可用緩沖區時,線程會進行短暫休眠(sleep_for),而不是持續空轉,這降低了CPU占用率。
06 總結
一套成功的高保真實時仿真注入系統,本質上是一個解決了計算、傳輸和物理接口三大領域深度集成問題的系統工程。
通過將DMA/RDMA的零拷貝能力、GMSL2?的高帶寬物理層以及?I2C?的精確控制能力有機結合,可以有效攻克傳統HIL測試中存在的帶寬、延遲和保真度瓶頸,從而在實驗室環境中構建起連接虛擬仿真與物理ECU的堅實橋梁。這套技術棧,是加速自動駕駛算法迭代和保障其功能安全的關鍵賦能技術。

openlayers結合canva繪制矩形繪制線)

基礎)
)

 數據交互延伸)








)



