? ? ? ?為了進一步了解模型的能力,我們需要某個指標來衡量,這就是性能度量的意義。有了一個指標,我們就可以對比不同的模型了,從而知道哪個模型相對好,哪個模型相對差,并通過這個指標來進一步調參以逐步優化我們的模型。
1. 正確率、精確率和召回率
? ? ? ?假設你有一臺用來預測某種疾病的機器,這臺機器需要用某種疾病的數據作為輸入,輸出只可能是兩種信息之一:有病或者沒病。雖然機器的輸出只有兩種,但是其內部對疾病的概率估計p是一個實數。機器上還有一個旋鈕用來控制靈敏度閾值a。因此預報過程是這樣子:首先用數據計算出p,然后比較p和a的大小,p>a輸出有病(檢測結果為陽性),p<a就輸出沒病(檢測結果為陰性)。
? ? ? ?如何評價這臺機器的疾病預測性能呢?這里就要注意了,并不是每一次都能準確預報的機器就是好機器,因為它可以次次都預報有疾病(把a調很低),自然不會漏掉,但是在絕大多數時候它都只是讓大家虛驚一場,稱為虛警;相反,從不產生虛警的機器也不一定就是好機器,因為它可以天天都預報沒有病(把a調很高)——在絕大數時間里這種預測顯然是正確的,但也必然漏掉真正的病癥,稱為漏報。一臺預測能力強的機器,應該同時具有低虛警和低漏報。精確率高意味著虛警少,能保證機器檢測為陽性時,事件真正發生的概率高,但不能保證機器檢測為陰性時,事件不發生。相反,召回率高意味著漏報少,能保證機器檢測為陰性時,事件不發生的概率高,但不能保證機器檢測為陽性時,事件就一定發生。
? ? ? ? 先介紹幾個常見的模型評估術語,現在假設分類目標只有兩類,正例(Positive)和負例(Negative)分別是:
- 真正例(True Positives, TP):模型正確預測為正類的樣本數。
- 真負例(True Negatives, TN):模型正確預測為負類的樣本數。
- 假正例(False Positives, FP):模型錯誤預測為正類的樣本數(實際上是負類)。
- 假負例(False Negatives, FN):模型錯誤預測為負類的樣本數(實際上是正類)。
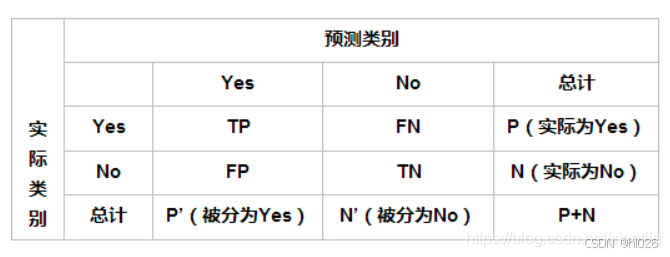
? ? (1)正確率(Accuracy)=(TP+TN)/(所有樣本數P+N),最常見的評價指標,適用于樣本均衡分布的情況,衡量整體分類準確性,即所有正確預測的樣本數占總樣本數的比例。
? ? (2)錯誤率(Error Rate)=(FP+FN)/(所有樣本數P+N),與正確率相反,描述被分類器錯分的比例,對某一個實例來說,分對與分錯是互斥事件。
? ? (3)靈敏度(Sensitive)=TP/P,表示的是所有正例中被分對的比例,衡量了分類器對正例的識別能力。
? ??(4)特效度(Specificity)=TN/N,表示的是所有負例中被分對的比例,它衡量了分類器對負例的識別能力。
? ? ?(5)精確度(Precision)=TP/(TP+FP),也叫精度,針對預測結果而言,衡量模型預測為正類的樣本中實際為正類的比例,反映了預測為正類的準確性。
? ? ?(6)召回率(Recall)=TP/(TP+FN)=TP/P=靈敏度Sensitive,針對原來的樣本而言,表示的是樣本中的正例有多少被預測正確了,度量有多少個正例被分為正例。
? ? ? ?比如我們一個模型對15個樣本進行預測,然后結果如下:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?真實值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?預測值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1

精度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)= 5 / (5+4) = 0.556
召回(recall, 或者敏感度,sensitivity,真陽性率,TPR,True Positive Rate) = TP / (TP + FN)
在上面的例子中,召回 = 5 / (5+2) = 0.714
特異度(specificity,或者真陰性率,TNR,True Negative Rate) = TN / (TN + FP)
在上面的例子中,特異度 = 4 / (4+2) = 0.667

)




)






)





