目錄
一. hash哈希
1.1.常用命令
1.1.1.HSET ?
1.1.2.HGET
1.1.3.HEXISTS ?
1.1.4.HDEL ?
1.1.5.HKEYS ?
1.1.6.HVALS ?
1.1.7.HGETALL ?
1.1.8.HMGET ?
1.1.9.HLEN
1.1.10.HSETNX ?
1.1.11.HINCRBY ?
1.1.12.HINCRBYFLOAT ?
1.2. 內部編碼
1.3.?使用場景
1.4. 緩存方式對比
二 . List列表
2.1.常用命令
2.1.1.LPUSH(頭插)
2.1.2.LPUSHX(存在時頭插)
2.1.3.RPUSH(尾插)
2.1.4.RPUSHX(存在時尾插)
2.1.5.LRANGE(獲取元素)
2.1.6.LPOP(頭刪)
2.1.7.RPOP(尾刪)
2.1.8.LINDEX ?
2.1.9.LINSERT ?
2.1.10.LLEN ?
2.2 阻塞版本命令
2.2.1.BLPOP(阻塞版頭刪)
2.2.2.BRPOP(阻塞版尾刪)
2.3. 內部編碼
2.4.?使用場景
2.4.1.消息隊列
2.4.2.分頻道的消息隊列
2.4.3.微博 Timeline
三. 漸進式遍歷
3.1.為什么需要漸進式遍歷
3.2.SCAN
一. hash哈希
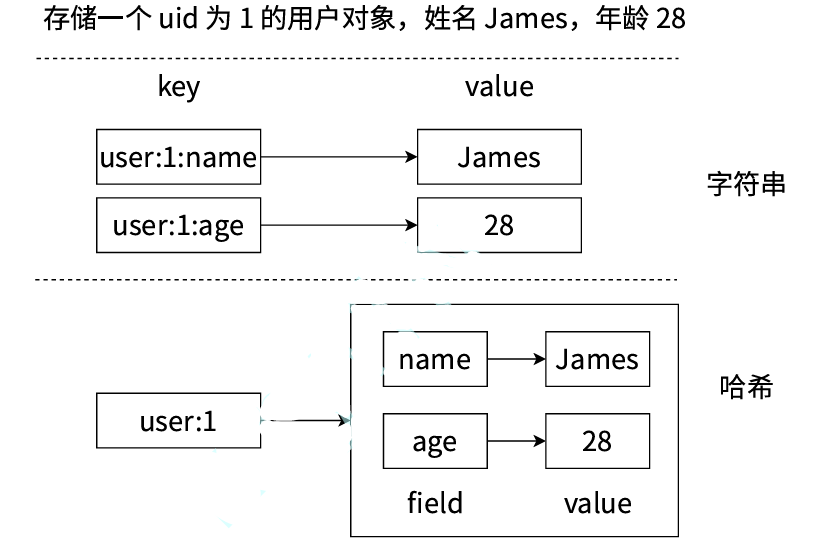
?乎所有的主流編程語?都提供了哈希(hash)類型,它們的叫法可能是哈希、字典、關聯數 組、映射。在Redis中,哈希類型是指值本??是?個鍵值對結構,形如key="key",value={{ field1, value1 }, ..., {fieldN, valueN } },Redis 鍵值對和哈希類型?者的關系可以?下面這個圖來表?。
1.1.常用命令
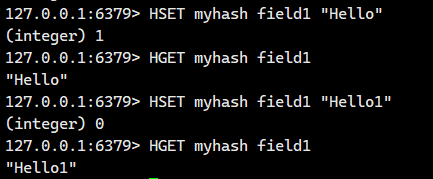
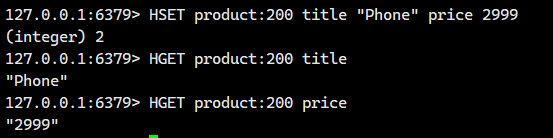
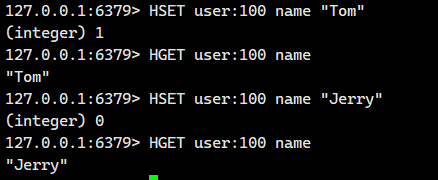
1.1.1.HSET ?
設置哈希表中指定字段的值。若字段已存在則更新其值;若字段不存在則創建新字段。
value得是字符串啊!!
語法: ?
HSET key field value [field value ...] ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:插入一組 field 為 O(1),插入 N 組 field 為 O(N) ?
- 返回值:添加的字段的個數。
示例 1:設置單個字段
示例 2:設置多個字段,同時設置兩個字段(注意空格分隔)
示例 3:更新已有字段
示例 4:混合操作(新增 + 更新)
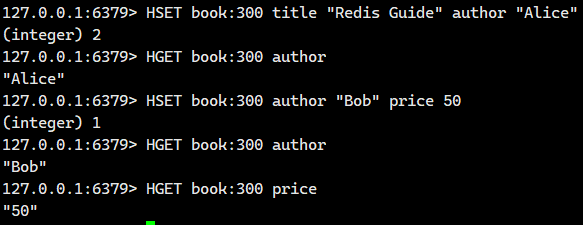
示例 5:鍵不存在時自動創建,對不存在的鍵操作會自動創建哈希表
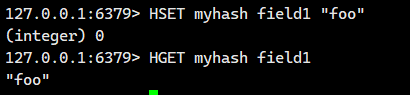
1.1.2.HGET
獲取 hash 中指定字段的值。
語法:
HGET key field- 命令有效版本:2.0.0 之后
- 時間復雜度:O(1)
- 返回值:字段對應的值或者 nil。
鍵不存在時
![]()
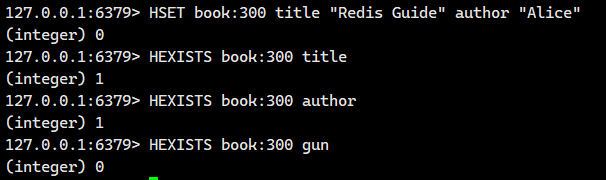
1.1.3.HEXISTS ?
判斷 hash 中是否有指定的字段。 ?
語法: ?
HEXISTS key field ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:1 表示存在,0 表示不存在。
1.1.4.HDEL ?
刪除 hash 中指定的字段。 ?
語法: ?
HDEL key field [field ...] ?DEL刪除的是key,field刪除的是field
- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:刪除一個元素為 O(1),刪除 N 個元素為 O(N)。 ?
- 返回值:本次操作刪除的字段個數。
話不多說,直接看例子
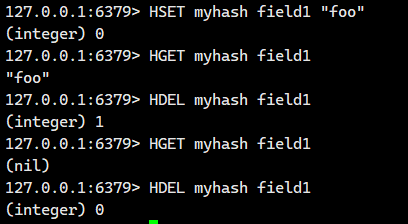
有的人想說,我想直接將整個鍵給刪除掉,那怎么辦?其實很簡單,別忘記了我們最開始講的全局命令,我們使用DEL命令即可。
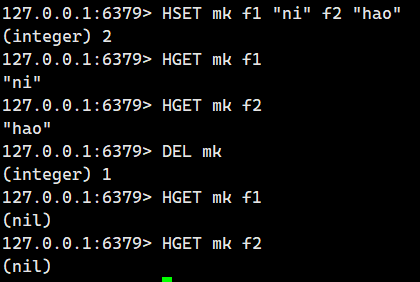
Redis 的?DEL?和?HDEL?命令操作的對象確實不同:
DEL?(刪除鍵):
-
作用對象:?整個 Redis?鍵 (key)。
-
功能:?刪除一個或多個指定的鍵及其關聯的所有數據(無論這個鍵存儲的是字符串、哈希、列表、集合、有序集合還是其他類型)。
-
語法:?
DEL key [key ...] -
返回值:?被成功刪除的鍵的數量。
-
示例:
-
DEL user:1000?刪除鍵?user:1000(如果它存儲的是一個哈希,整個哈希結構及其所有字段/值都會被刪除)。 -
DEL cache:itemA cache:itemB?刪除鍵?cache:itemA?和?cache:itemB。
-
HDEL?(刪除哈希字段):
-
作用對象:?哈希 (Hash) 類型鍵內部的?字段 (field)。
-
功能:?刪除存儲在指定哈希鍵中的一個或多個字段及其關聯的值。它只刪除哈希內部的特定字段,不會刪除整個哈希鍵本身(除非你刪除了該哈希的所有字段)。
-
語法:?
HDEL key field [field ...] -
返回值:?被成功刪除的字段數量(如果嘗試刪除的字段不存在,則不計入)。
-
示例:
-
HDEL user:1000 email?刪除鍵?user:1000?這個哈希中的?email?字段。 -
HDEL user:1000 phone address?刪除鍵?user:1000?這個哈希中的?phone?和?address?兩個字段。
-
1.1.5.HKEYS ?
獲取 hash 中的所有字段。
語法:
HKEYS key- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(N),N 為 field 的個數。 ?
- 返回值:字段列表。
這個操作會先找到key,根據key找到哈希,然后再遍歷哈希
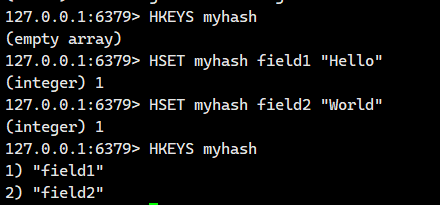
注意:這個命令也是存在一定風險的,因為我們不知道有沒有這么一個hash里面會存儲大量的field。
1.1.6.HVALS ?
獲取 hash 中的所有的值。 ?
語法: ?
HVALS key ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(N), N 為 field 的個數。 ?
- 返回值:所有的值。
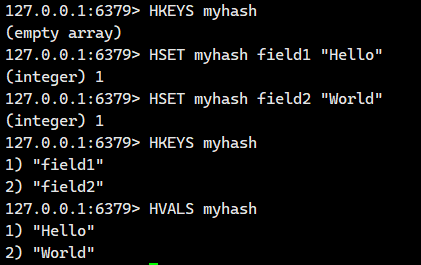
注意:這個操作的時間復雜度是O(N),N是哈希的元素個數,如果哈希非常大,這個操作就可能導致redis被阻塞住。
1.1.7.HGETALL ?
獲取 hash 中的所有字段以及對應的值。 ?
語法: ?
HGETALL key ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(N), N 為 field 的個數。 ?
- 返回值:字段和對應的值。
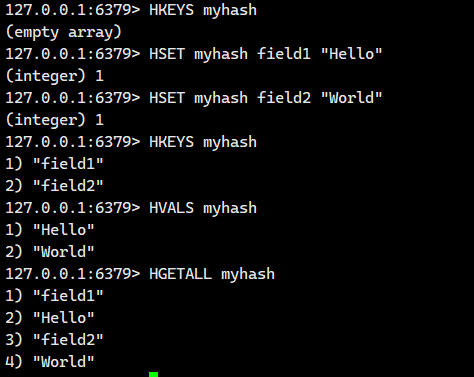
有HMGET,為啥沒有HMSET?
其實是有的,事實上我們的HSET就已經支持了一次設置多個字段的功能,完全沒有必要再去用HMSET
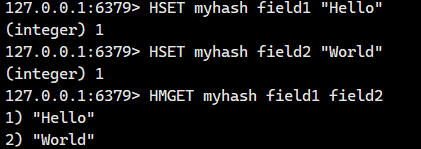
1.1.8.HMGET ?
一次獲取 hash 中多個字段的值。 ?
語法: ?
HMGET key field [field ...] ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:只查詢一個元素為 O(1),查詢多個元素為 O(N),N 為查詢元素個數。 ?
- 返回值:字段對應的值或者 nil。
![]()
??HKEYS、HVALS?和?HGETALL?命令存在潛在風險:當 Hash 的元素數量過多時,執行耗時顯著增加,可能導致 Redis 實例阻塞(因其單線程模型)。????????如果開發人員只需要獲取部分 field,可以使用 HMGET,如果一定要獲取全部 field,可以嘗試使用 HSCAN 命令,該命令采用漸進式遍歷哈希類型,HSCAN 會在后續文章介紹。
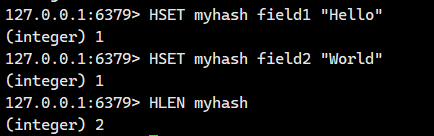
1.1.9.HLEN
獲取 hash 中的所有字段的個數。
語法:
HLEN key- 命令有效版本:2.0.0 之后
- 時間復雜度:O(1)
- 返回值:字段個數。
1.1.10.HSETNX ?
在字段不存在的情況下,設置 hash 中的字段和值。 ?
語法: ?
HSETNX key field value ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(1)? ,這個是因為獲取哈希的元素個數,是不需要進行遍歷的
- 返回值:1 表示設置成功,0 表示失敗。
我們看看字段不存在的情況
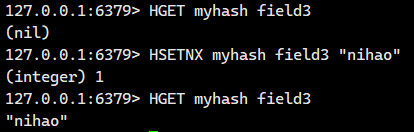
我們看看字段存在的情況
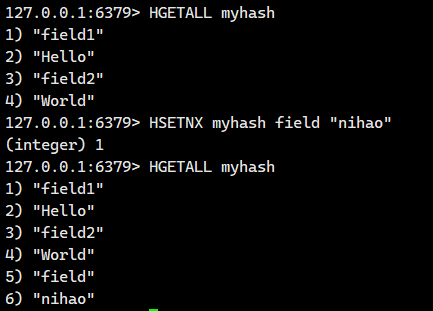
沒有更新成功。
1.1.11.HINCRBY ?
將 hash 中字段對應的數值添加指定的值。 ?
語法: ?
HINCRBY key field increment ?- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:該字段變化之后的值。
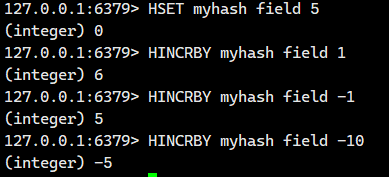
1.1.12.HINCRBYFLOAT ?
HINCRBY 的浮點數版本。
語法:
HINCRBYFLOAT key field increment- 命令有效版本:2.6.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:該字段變化之后的值。
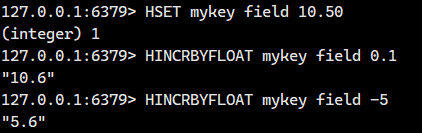
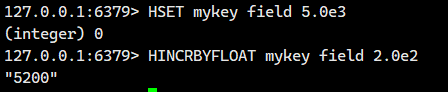
1.2. 內部編碼
Redis 哈希結構的內部編碼有兩種實現方式:
1.ziplist(壓縮列表)
-
適用條件:同時滿足
-
哈希字段數量 ≤?
hash-max-ziplist-entries(默認值:512) -
所有字段值的字節長度 ≤?
hash-max-ziplist-value(默認值:64 字節)
-
-
優勢:
采用連續內存存儲,通過緊湊排列消除元數據開銷,內存利用率顯著高于 hashtable。 -
典型場景:
存儲小型配置信息、輕量級對象屬性(如短字符串、數值等)。
2.hashtable(哈希表)
-
觸發條件:
任意字段數量或值大小突破 ziplist 的閾值上限。 -
特性:
-
標準字典結構(數組 + 鏈表/紅黑樹)
-
讀寫操作平均時間復雜度 O(1),性能穩定
-
-
優勢:
數據規模較大時,避免 ziplist 的線性操作開銷(如插入時連鎖更新)。
說的直白一點就是
- 哈希的元素個數比較少,使用ziplist表示,元素個數比較多,則使用hashtable
- 每個value的值長度比較短,使用ziplist表示,如果某個value的值長度比較長,也會使用hashtable表示。
下面的示例演示了哈希類型的內部編碼,以及響應的變化。
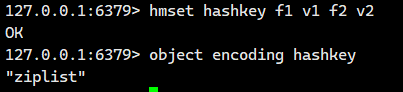
1) 當 field 個數比較少且沒有大的 value 時,內部編碼為 ziplist:
2) 當有 value 大于 64 字節時,內部編碼會轉換為 hashtable:

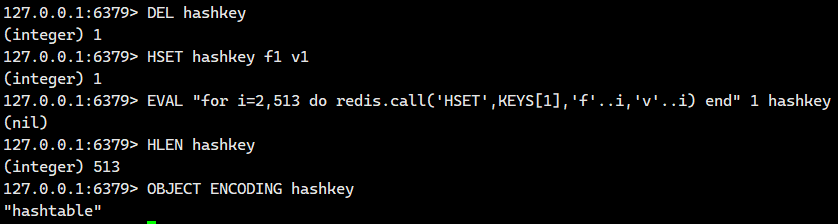
3) 當 field 個數超過 512 時,內部編碼也會轉換為 hashtable:
1.3.?使用場景
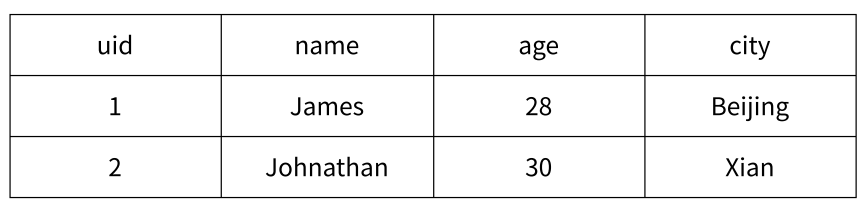
下圖 為關系型數據表記錄的兩條用戶信息,用戶的屬性表現為表的列,每條用戶信息表現為行。
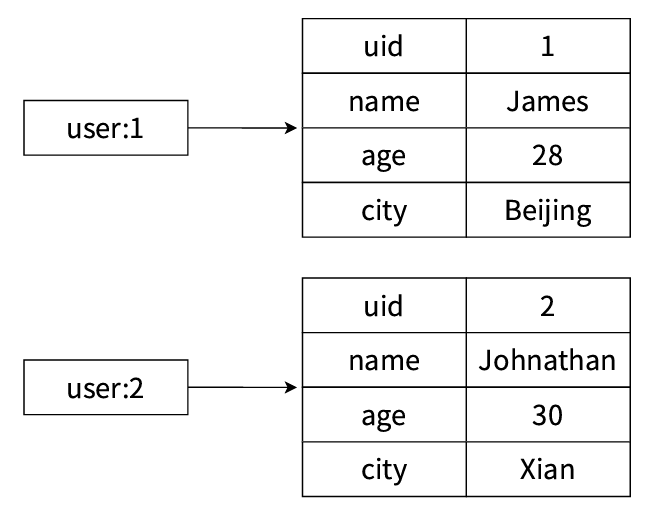
如果映射關系表示這兩個用戶信息,則如下圖所示。
上面這個場景用string其實也可以做到:
如果使用 string (json) 的格式來表示 UserInfo
- 萬一只想獲取其中的某個 field, 或者修改某個 field ~~
- 就需要把整個 json 都讀出來, 解析成 對象, 操作 field, 再重寫轉成 json 字符串, 再寫回去~~
如果使用 hash 的方式來表示 UserInfo
- 就可以使用 field 表示對象的每個屬性 (數據表的每個列)
- 此時就可以非常方便的修改/獲取任何一個屬性的值了~~
使用 hash 的方式, 確實讀寫 field 更直觀高效, 但是付出的是空間的代價~~
- 需要控制哈希在 ziplist 和 /hashtable 兩種內部編碼的轉換,可能會造成內存的較大消耗。
相比于使用 JSON 格式的字符串緩存用戶信息,哈希類型變得更加直觀,并且在更新操作上變得更靈活。可以將每個用戶的 id 定義為鍵后綴,多對 field-value 對應用戶的各個屬性,類似如下偽代碼:
UserInfo getUserInfo(long uid) {// 根據 uid 得到 Redis 的鍵String key = "user:" + uid;// 嘗試從 Redis 中獲取對應的值userInfoMap = Redis 執行命令: hgetall key;// 如果緩存命中 (hit)if (value != null) {// 將映射關系還原為對象形式UserInfo userInfo = 利用映射關系構建對象(userInfoMap);return userInfo;}// 如果緩存未命中 (miss)// 從數據庫中,根據 uid 獲取用戶信息UserInfo userInfo = MySQL 執行 SQL: select * from user_info where uid = <uid>// 如果表中沒有 uid 對應的用戶信息if (userInfo == null) {響應 404return null;}// 將緩存以哈希類型保存Redis 執行命令: hmset key name userInfo.name age userInfo.age city userInfo.city// 寫入緩存,為了防止數據腐爛 (rot),設置過期時間為 1 小時 (3600 秒)Redis 執行命令: expire key 3600// 返回用戶信息return userInfo;
}但是需要注意的是哈希類型和關系型數據庫有兩點不同之處:
- 哈希類型是稀疏的,而關系型數據庫是完全結構化的,例如哈希類型每個鍵可以有不同的 field,而關系型數據庫一旦添加新的列,所有行都要為其設置值,即使為 null,如圖 2-18 所示。
- 關系數據庫可以做復雜的關系查詢,而 Redis 去模擬關系型復雜查詢,例如聯表查詢、聚合查詢等基本不可能,維護成本高。
1.4. 緩存方式對比
截至目前為止,我們已經能夠用三種方法緩存用戶信息,下面給出三種方案的實現方法和優缺點分析。
1. 原生字符串類型——使用字符串類型,每個屬性一個鍵。
set user:1:name James ?
set user:1:age 23 ?
set user:1:city Beijing ?- 優點:實現簡單,針對個別屬性變更也很靈活。 ?
- 缺點:占用過多的鍵,內存占用量較大,同時用戶信息在 Redis 中比較分散,缺少內聚性,所以這種方案基本沒有實用性。
2. 序列化字符串類型,例如 JSON 格式
set user:1 經過序列化后的用戶對象字符串- 優點:針對總是以整體作為操作的信息比較合適,編程也簡單。同時,如果序列化方案選擇合適,內存的使用效率很高。
- 缺點:本身序列化和反序列需要一定開銷,同時如果總是操作個別屬性則非常不靈活。
3. 哈希類型
hmset user:1 name James age 23 city Beijing- 優點:簡單、直觀、靈活。尤其是針對信息的局部變更或者獲取操作。
- 缺點:需要控制哈希在 ziplist 和 hashtable 兩種內部編碼的轉換,可能會造成內存的較大消耗。
二 . List列表
????????列表類型是?來存儲多個有序的字符串,如圖所?,a、b、c、d、e五個元素從左到右組成 了?個有序的列表,列表中的每個字符串稱為元素(element),?個列表最多可以存儲個元 素。
????????在Redis中,可以對列表兩端插?(push)和彈出(pop),還可以獲取指定范圍的元素列表、 獲取指定索引下標的元素等。列表是?種?較靈活的數據結構,它可以 充當棧和隊列的??,在實際開發上有很多應?場景。
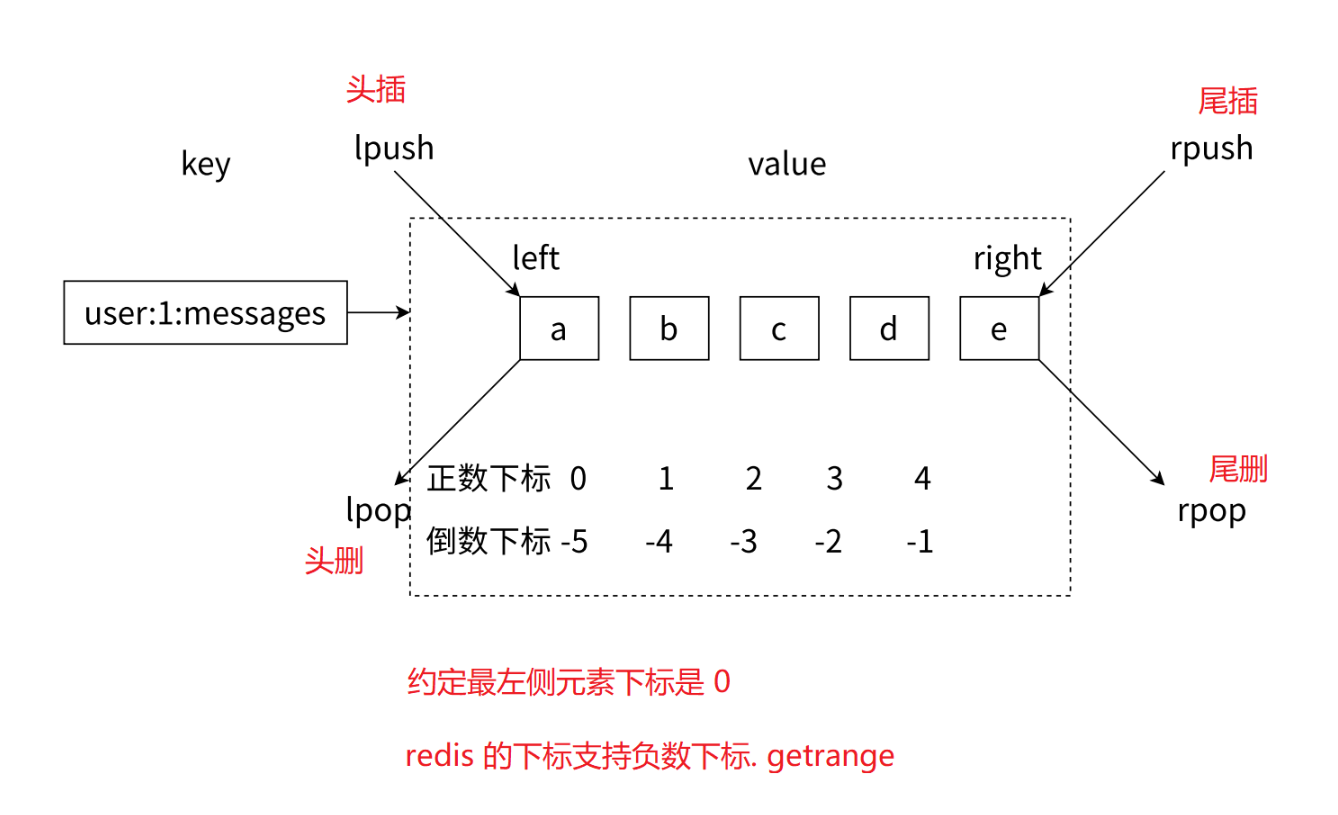
列表類型的特點:
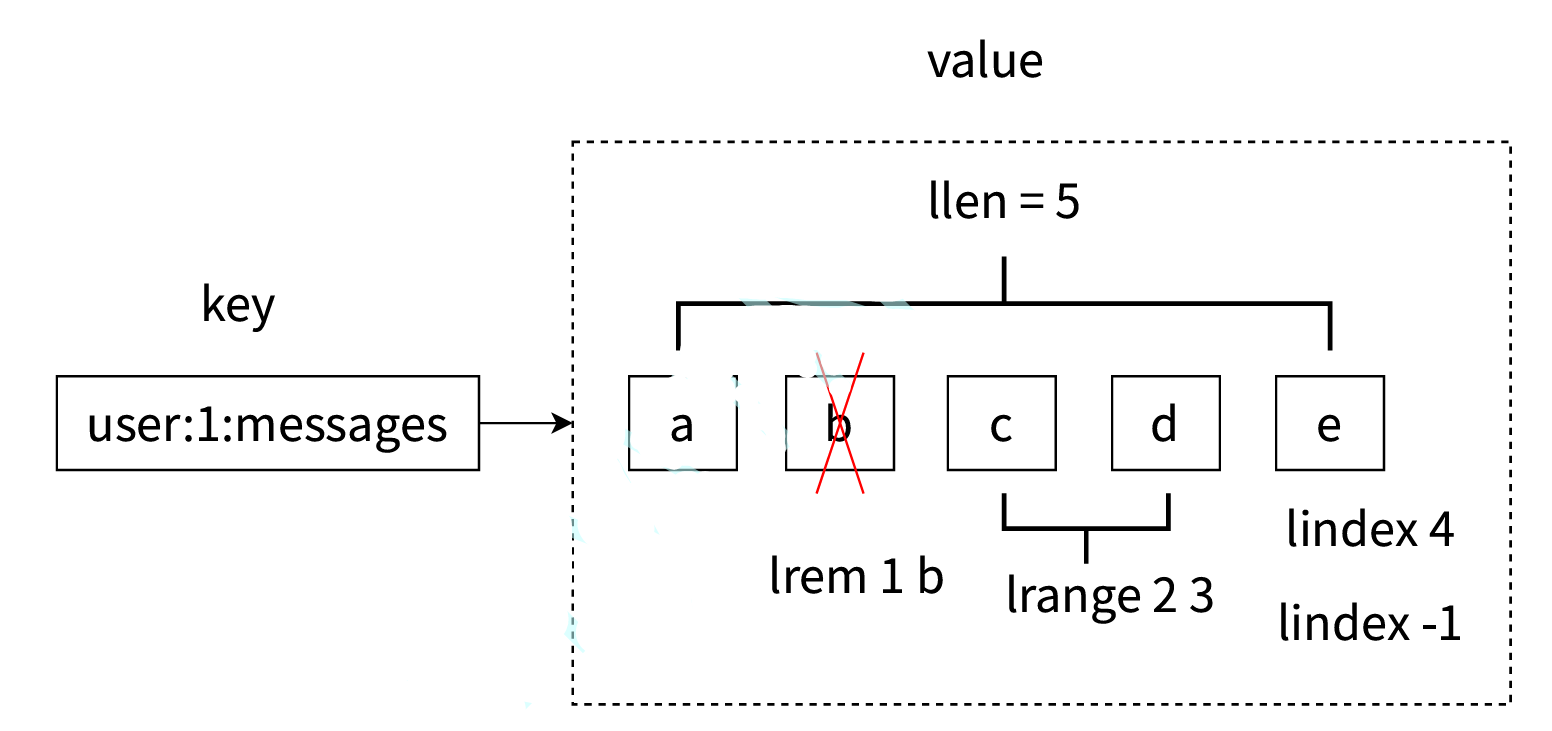
- 第?、列表中的元素是有序的,這意味著可以通過索引下標獲取某個元素或者某個范圍的元素列表, 例如要獲取圖2-20的第5個元素,可以執?lindexuser:1:messages4或者倒數第1個元素,lindex user:1:messages-1 就可以得到元素e。
- 第?、區分獲取和刪除的區別,例如圖2-20中的lrem1b是從列表中把從左數遇到的前1個b元素刪 除,這個操作會導致列表的?度從5變成4;但是執?lindex4只會獲取元素,但列表?度是不會變化 的。
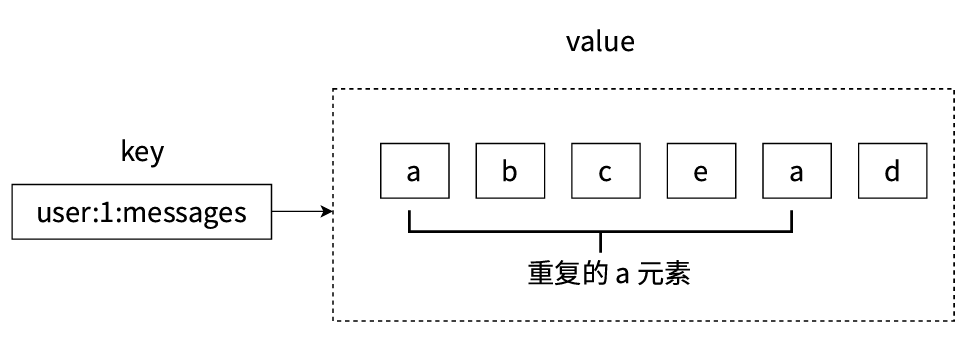
- 第三、列表中的元素是允許重復的,例如下圖中的列表中是包含了兩個a元素的。像hash里面的field是不能重復的
因為當前的List頭和尾都能高效的插入刪除元素,所以我們完全可以將List當成一個隊列/棧來使用。
2.1.常用命令
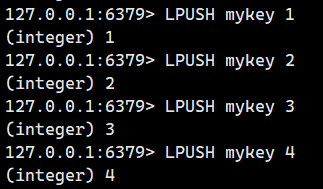
2.1.1.LPUSH(頭插)
LPUSH我們可以理解為left push,我們一般將左邊視為頭!所以為頭插
將一個或者多個元素從左側放入(頭插)到 list 中。
一次可以插入一個或者多個元素
語法:
LPUSH key element [element ...]- 命令有效版本:1.0.0 之后
- 時間復雜度:只插入一個元素為 O(1), 插入多個元素為 O(N), N 為插入元素個數.
- 返回值:插入后 list 的長度。
注意這個是頭插,我們按順序插入1234,事實上得到的是4321.
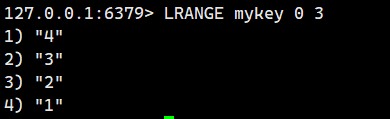
如果key已經存在,而且key對應的類型不是List,那么對這個key執行LPUSH則會報錯

2.1.2.LPUSHX(存在時頭插)
在 key 存在時,將一個或者多個元素從左側放入(頭插)到 list 中。
不存在,直接返回。
語法:
LPUSHX key element [element ...]- 命令有效版本:2.0.0 之后 ?
- 時間復雜度:只插入一個元素為 O(1),插入多個元素為 O(N),N 為插入元素個數。 ?
- 返回值:插入后 list 的長度。
我們看看鍵存在的情況
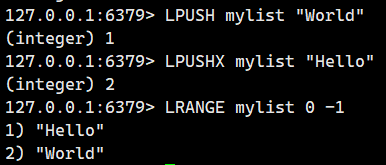
我們再看看鍵不存在的時候
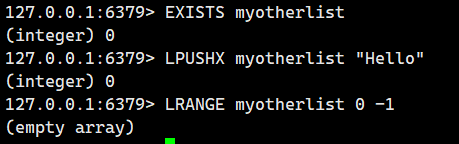
2.1.3.RPUSH(尾插)
RPUSH我們可以理解為right?push,我們一般將右邊視為尾!
將一個或者多個元素從右側放入(尾插)到 list 中。
語法:
RPUSH key element [element ...]- 命令有效版本:1.0.0 之后
- 時間復雜度:只插入一個元素為 O(1), 插入多個元素為 O(N), N 為插入元素個數.
- 返回值:插入后 list 的長度。
注意這個是尾插啊!!!
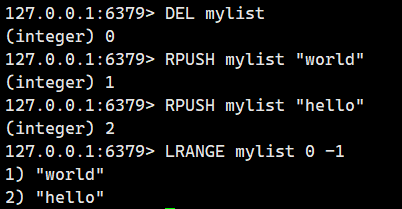
2.1.4.RPUSHX(存在時尾插)
在 key 存在時,將一個或者多個元素從右側放入(尾插)到 list 中。
語法:
RPUSHX key element [element ...]- 命令有效版本:2.0.0 之后
- 時間復雜度:只插入一個元素為 O(1),插入多個元素為 O(N),N 為插入元素個數。
- 返回值:插入后 list 的長度。
我們看看鍵存在時的情況
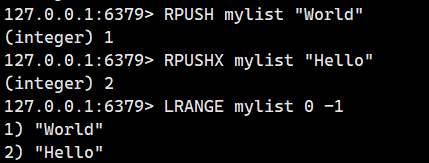
我們看看鍵不存在的情況
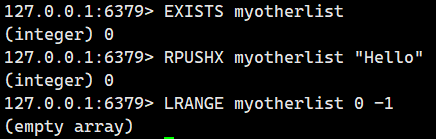
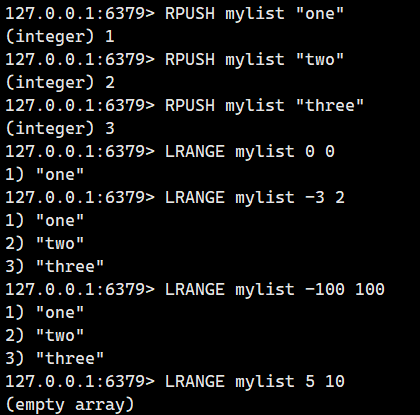
2.1.5.LRANGE(獲取元素)
獲取列表(list)中指定區間 [start, stop] 的所有元素,區間為左閉右閉(包含 start 和 stop 位置的元素)。
語法: ?
LRANGE key start stop ?- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(N) ?
- 返回值:指定區間的元素。
注意:START和STOP可以是數字,數字的含義如下:
- 支持索引:0表示第一個元素,1表示第2個元素,以此類推
- 支持負數索引:
-1?表示最后一個元素,-2?表示倒數第二個,依此類推
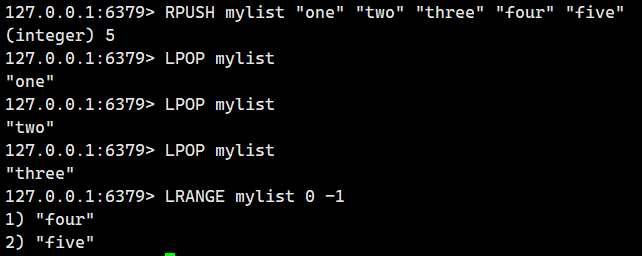
2.1.6.LPOP(頭刪)
從 list 左側取出元素(即頭刪)。 ?
語法: ?
LPOP key ?- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:取出的元素或者 nil。
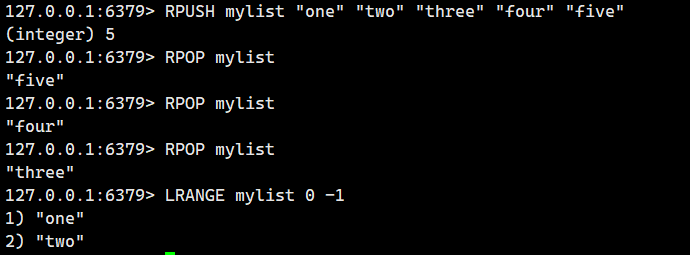
2.1.7.RPOP(尾刪)
從 list 右側取出元素(即尾刪)。
語法:
RPOP key- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:取出的元素或者 nil。
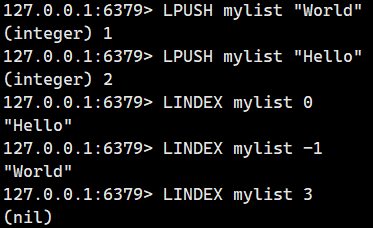
2.1.8.LINDEX ?
獲取從左數第 index 位置的元素。 ?
語法: ?
LINDEX key index ?- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(N) ?
- 返回值:取出的元素或者 nil。
注意:index可以取下面這些值
正數索引(從左向右)
-
0?→ 第一個元素 -
1?→ 第二個元素 -
n?→ 第 n+1 個元素
負數索引(從右向左)
-
-1?→ 最后一個元素 -
-2?→ 倒數第二個元素 -
-n?→ 倒數第 n 個元素
話不多說我們直接看例子
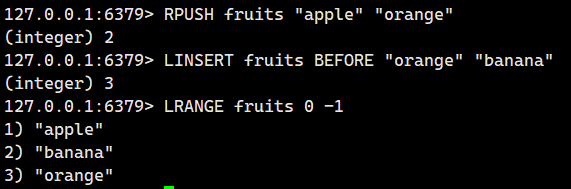
2.1.9.LINSERT ?
在特定位置插入元素。 ?
語法: ?
LINSERT key <BEFORE | AFTER> pivot element ?版本支持
2.2.0 及以上版本
時間復雜度
O(N),其中 N 為查找基準元素需遍歷的長度
-
最佳情況(基準在頭部):O(1)
-
最壞情況(基準在尾部):O(N)
返回值
-
成功插入:返回更新后的列表長度
-
基準不存在:返回?
-1 -
key 不存在:返回?
0
大家注意下面這2點:
-
位置標識符
-
BEFORE?→ 插入到基準元素之前 -
AFTER?→ 插入到基準元素之后
-
-
基準元素(pivot)
-
必須精確匹配列表中的現有元素值(區分大小寫)
-
若列表存在多個相同值,以最先遍歷到的為準
-
話不多說,直接看例子
示例 1:基礎插入
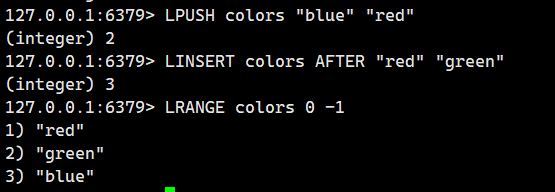
示例 2:在元素后插入
示例 3:處理重復值
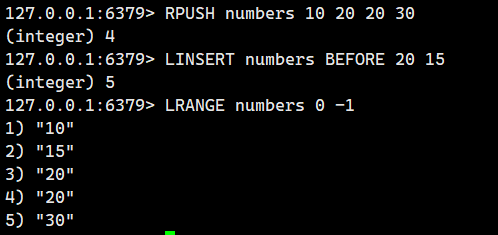
在第一個 "20" 前插入 "15"
示例 4:基準元素不存在
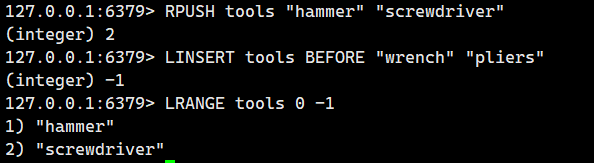
2.1.10.LLEN ?
獲取 list 長度。 ?
語法: ?
LLEN key ?- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:list 的長度。
2.2 阻塞版本命令
blpop 和 bropp 是 lpop 和 rpop 的阻塞版本,和對應非阻塞版本的作用基本一致,
但是阻塞版本還是有一些特點的:
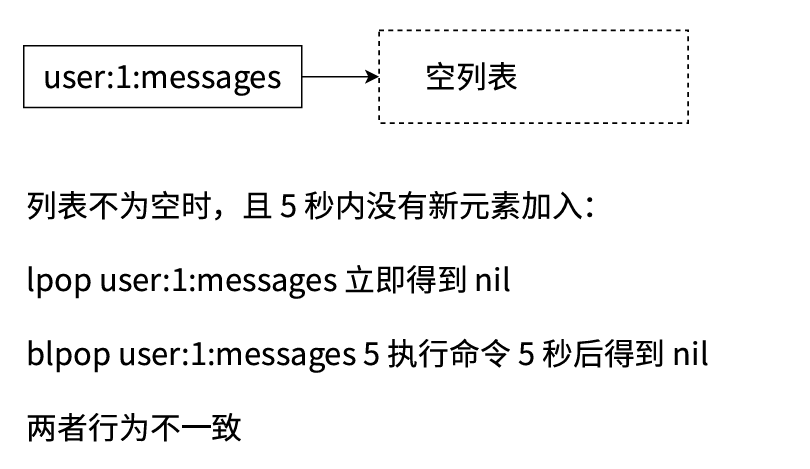
1. 空列表處理機制對比
-
非阻塞版本(LPOP/RPOP):當列表為空時立即返回?
nil -
阻塞版本(BLPOP/BRPOP):
-
列表為空時阻塞客戶端連接
-
阻塞時長由?
timeout?參數控制(單位:秒) -
阻塞期間 Redis 服務端可處理其他命令,但該客戶端連接無法執行其他操作
-
超時后返回?
nil,或在新元素到達時立即返回該元素
-
2. 多鍵監聽機制
-
支持同時監聽多個列表鍵:
BLPOP list1 list2 list3 10 # 按序檢查 list1→list2→list3 -
執行流程:
-
從左向右掃描鍵列表
-
遇到第一個非空列表時,彈出其首元素并返回
-
若所有列表均為空,進入阻塞狀態
-
3. 客戶端競爭規則
-
當多個客戶端同時阻塞監聽同一個鍵時:
-
新元素到達后,最早發起監聽的客戶端優先獲取
-
其他客戶端繼續阻塞等待
-
4. 阻塞原理深度解析
-
服務端行為:
-
將阻塞客戶端加入監控隊列
-
收到?
LPUSH/RPUSH?等寫入命令時喚醒對應客戶端
-
-
客戶端表現:
-
TCP 連接保持但無數據流動
-
命令超時前無法執行其他操作
-
-
典型超時設置:
-
0?= 無限等待(慎用) -
5-30?= 常規業務超時 -
>60?= 長輪詢場景
-

2.2.1.BLPOP(阻塞版頭刪)
BLPOP?是?LPOP?的阻塞版本,用于從列表左側(頭部)刪除元素。
- 當列表不為空時行為與?
LPOP?一致; - 當列表為空時,客戶端連接將進入阻塞狀態直到新元素到達或超時。
注意:在阻塞期間Redis其實是可以執行其他命令的,這里的BLPOP和BRPOP看起來耗時很久,但是實際上并不會對redis服務器產生負面影響。
語法: ?
BLPOP key [key ...] timeout ?版本支持
1.0.0 及以上版本
時間復雜度
O(1) - 無論列表長度如何,彈出操作均為常數時間復雜度
核心特性深度解析
1. 阻塞機制
-
列表有元素:立即彈出最左側元素
-
列表為空:
-
阻塞客戶端連接,暫停后續命令執行
-
阻塞時長由?
timeout?參數指定(單位:秒) -
期間若其他客戶端向列表寫入數據,立即喚醒并返回元素
-
超時后返回?
nil
-
2. 多鍵監聽模式
-
可同時監控多個列表:
BLPOP orders alerts notifications 10 -
執行優先級:
-
從左向右檢查列表
-
遇到第一個非空列表時彈出元素
-
返回格式:
[列表名, 元素值]
["alerts", "urgent:server_down"] # 示例返回值 -
3. timeout參數特殊值
-
0:無限阻塞(生產環境慎用) -
>0:阻塞指定秒數 -
支持小數精度(如?
0.5?表示 500 毫秒)
示例
話不多說,直接看例子
示例 1:從一個有元素的列表中阻塞式彈出元素。
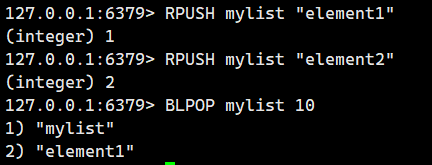
大家注意到我這個mylist里是有元素的,所以我一執行BLPOP,就立即返回結果了。
示例 2:從一個空的列表中阻塞式彈出元素。
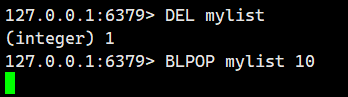
大家可以看到我這mylist里面可是沒有任何元素的,當我一執行BLPOP,就立即阻塞住了。
這個時候會一直阻塞到timeout設置的10秒之后。
我們在這個期間對mylist不做任何操作,10S之后發現停止阻塞,直接返回了nil,代表沒有刪除任何元素。
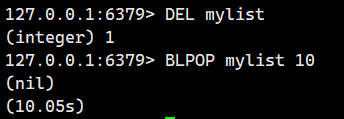
示例 3:從一個空的列表中阻塞式彈出元素。
這個時候,我們打開另外一個客戶端,往mylist里面插入一個元素

這個時候我們回到原來那個客戶端
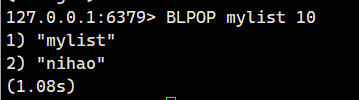
就會發現阻塞停止了。直接返回了。
我們這個時候看看
![]()
里面什么元素都沒有,這很符合我們的預期!!!
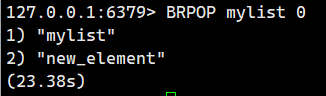
2.2.2.BRPOP(阻塞版尾刪)
BRPOP 是 RPOP 的阻塞版本,用于從列表右側(尾部)刪除元素。
- 當列表不為空時行為與 RPOP 一致;
- 當列表為空時,客戶端連接將進入阻塞狀態直到新元素到達或超時。
語法:
BRPOP key [key ...] timeout- 命令有效版本:1.0.0 之后 ?
- 時間復雜度:O(1) ?
- 返回值:取出的元素或者 nil。
關鍵特性講解
1. 阻塞機制
-
當指定的所有列表都為空時,客戶端將被阻塞
-
一旦有指定列表被推入新元素(例如使用LPUSH/RPUSH),客戶端立即從該列表的尾部彈出一個元素
-
如果超時時間(timeout)到達,則返回nil
2. 多鍵監聽模式
可以同時監聽多個鍵,按照從左到右的順序檢查列表,一旦有列表非空,則從該列表的尾部彈出元素。
示例命令:
BRPOP orders alerts notifications 10-
此命令會依次檢查
orders、alerts、notifications三個列表 -
如果在10秒內,
alerts列表被添加了元素,則立即從alerts的尾部彈出元素:1) "alerts"??????????? # 鍵名 2) "urgent:server_down" # 彈出的值
3. timeout參數特殊值
-
timeout為0:表示無限期阻塞,直到有元素可彈出 -
timeout為正整數:表示阻塞的最長等待時間(單位為秒),支持小數(如0.1表示100毫秒)
話不多說,直接看例子
示例 1:從一個有元素的列表中阻塞式彈出尾部元素
大家注意到我這個mylist里是有元素的,所以一執行BRPOP就立即返回了尾部元素"cherry"。
示例 2:從一個空的列表中阻塞式彈出尾部元素
大家可以看到mylist是空的,執行BRPOP后立即阻塞。
10秒內沒有任何操作,超時后返回nil。
示例 3:阻塞過程中另一個客戶端向列表添加元素
客戶端A(阻塞狀態):
在阻塞期間,客戶端B執行:
![]()
客戶端A立即返回:
檢查列表狀態:

列表已為空,這完全符合預期!
2.3. 內部編碼
Redis 列表(List)的內部編碼機制經歷了重要的優化。早期版本主要依賴兩種結構,根據元素數量和大小自動切換:
-
ziplist (壓縮列表)
-
觸發條件:?需同時滿足:
-
列表元素個數 ≤?
list-max-ziplist-entries?(默認值:512) -
每個元素值的長度(字節數) ≤?
list-max-ziplist-value?(默認值:64 字節)
-
-
優勢:?將元素和長度信息緊湊、連續地存儲在一塊內存中,顯著減少內存碎片,對于小型列表特別高效。
-
配置調整 (
redis.conf):list-max-ziplist-entries 512 # 可調整元素數量閾值 list-max-ziplist-value 64 # 可調整元素長度閾值(單位:字節)
-
-
linkedlist (雙向鏈表)
-
觸發條件:?當列表不滿足?ziplist 的任意一個條件(元素數量過多或單個元素過大)時自動切換。
-
優勢:?支持在列表任意位置進行高效的 O(1) 時間復雜度元素插入和刪除,尤其適合大型列表。
-
特點:?每個元素作為獨立的節點存儲(包含指向前后節點的指針和實際值),可以存儲任意長度的數據。缺點是每個節點有額外的內存開銷(指針),且內存不連續。
-
重要更新:新版本中的 Quicklist
在較新的 Redis 版本(大約從 3.2 開始)中,ziplist?和?linkedlist?已不再是列表類型的默認或主要內部編碼實現。它們被一個更優的結構所取代:quicklist。
-
設計理念:?
quicklist?本質上是一個?ziplist?的?linkedlist。它巧妙地結合了兩種舊結構的優點。 -
結構描述:
-
quicklist?的整體結構是一個雙向鏈表。 -
這個鏈表中的每個節點 (entry) 不再是一個單獨的元素,而是一個?
ziplist。 -
每個節點內的?
ziplist?被限制在一定的大小范圍內(通常受?list-max-ziplist-size?配置控制,可正可負,例如?-2?表示 8KB),確保單個 ziplist 不會過大而失去其緊湊的優勢。 -
多個這樣的?
ziplist?節點通過鏈表指針連接起來,形成一個邏輯上的大列表。
-
-
核心優勢:
-
內存效率:?在節點內部使用?
ziplist?存儲多個元素,保持了緊湊存儲,減少了小元素帶來的內存碎片和指針開銷。 -
訪問性能:?對于按索引訪問,可以通過鏈表快速定位到目標節點(ziplist),再在 ziplist 內部進行(相對)快速的偏移訪問。
-
插入/刪除性能:?在列表兩端(頭/尾)的插入/刪除通常非常高效(可能發生在頭/尾節點的 ziplist 內或創建新節點)。在列表中間插入/刪除時,如果發生在某個 ziplist 節點內部且該節點未滿,也能利用 ziplist 的緊湊性獲得較好性能;如果導致節點分裂或合并,則成本稍高,但整體上通過限制單個 ziplist 的大小,將大列表操作的性能波動控制在可接受范圍內。
-
靈活性:?能夠高效地存儲從小型到超大型的列表,并適應不同大小的元素。
-
-
配置 (
redis.conf):-
list-max-ziplist-size:這是控制?quicklist?行為的關鍵參數。它決定了每個 quicklist 節點(即一個 ziplist)所能包含的字節數或元素個數的上限(取決于配置值的正負)。-
正值:表示每個 ziplist 節點最多包含的元素個數。例如?
5?表示每個節點最多 5 個元素。 -
負值:表示每個 ziplist 節點占用的最大內存字節數(近似值):
-
-1: 4KB -
-2: 8KB?(默認值) -
-3: 16KB -
-4: 32KB -
-5: 64KB
-
-
-
list-compress-depth:控制列表兩端節點的 LZF 壓縮深度,以進一步節省內存(0 表示不壓縮,默認值)。
-
編碼切換示例演示
? 案例 1:小元素+少量數據,這個情況本來是ziplist的,但是現在在新版本里面就只能是quicklist的
?? 案例 2:批量插入513個元素(使用Lua腳本避免手動輸入),這個本來是會切換 linkedlist(元素數量超標)的,但是現在只有quicklist!!

?? 案例 3:插入70字節的長字符串(超過默認64字節)這個本來是應該是會切換 linkedlist(元素尺寸超標)的,但是現在還是quicklist
2.4.?使用場景
2.4.1.消息隊列
Redis 的列表(List)數據結構,結合?LPUSH?和?BRPOP?命令,是實現經典阻塞式生產者-消費者隊列模型的有效方案。
-
生產者:使用?
LPUSH?命令將新元素插入到列表的左側(隊尾)。 -
消費者:多個消費者客戶端使用?
BRPOP?命令,以阻塞方式嘗試從列表的右側(隊首)移除并獲取元素。
這種設計的關鍵優勢在于實現了負載均衡和高可用性:
-
負載均衡:多個消費者客戶端可以同時監聽同一個隊列。
-
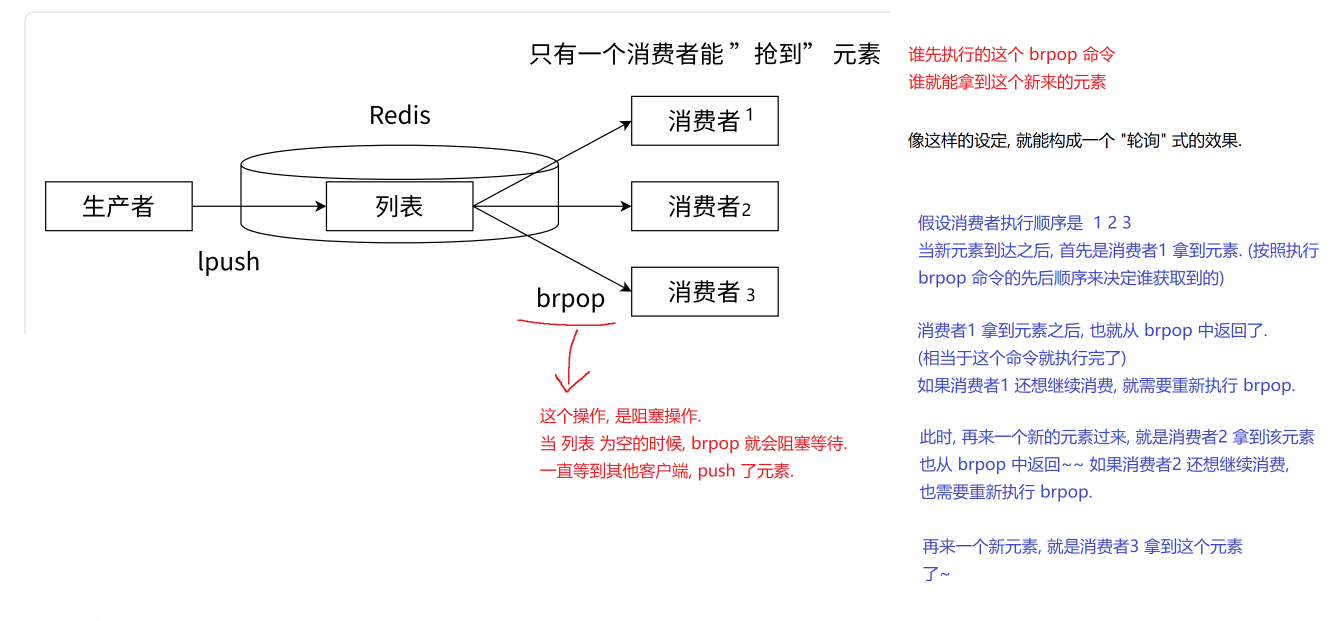
阻塞與競爭:
BRPOP?命令是阻塞的。如果隊列為空,消費者會一直等待,直到有元素可用或超時。當新元素被生產者 (LPUSH) 推入隊列時,所有正在阻塞等待 (BRPOP) 的消費者會同時被喚醒。 -
“爭搶”與輪詢:被喚醒的消費者會競爭獲取這個新元素。Redis 內部處理這些并發請求時,大致遵循消費者發起?
BRPOP?命令的先后順序來決定誰獲得元素(盡管實際順序會受到網絡延遲、Redis 事件循環等細微影響,但整體呈現輪詢效果)。
輪詢過程示例:
假設有三個消費者客戶端:C1, C2, C3。它們按順序執行了?BRPOP myqueue 0?(0 表示無限期阻塞) 命令并處于等待狀態。
-
新元素 A 到達 (生產者?
LPUSH myqueue A):-
所有阻塞的消費者 (C1, C2, C3) 被喚醒競爭元素 A。
-
按照大致順序,消費者 C1 成功獲取到元素 A?并從?
BRPOP?命令返回。 -
C1 處理元素 A。如果 C1 想繼續消費,它必須重新執行?
BRPOP myqueue 0?命令以再次進入阻塞等待狀態。
-
-
新元素 B 到達 (生產者?
LPUSH myqueue B):-
此時阻塞的消費者是 C2, C3 以及剛剛重新執行了?
BRPOP?的 C1(如果它動作夠快)。 -
再次競爭后,消費者 C2 成功獲取到元素 B?并從?
BRPOP?返回。 -
C2 處理元素 B,之后同樣需要重新執行?
BRPOP?才能繼續消費。
-
-
新元素 C 到達 (生產者?
LPUSH myqueue C):-
阻塞的消費者現在是 C3, C1 (已重新阻塞), C2 (可能剛處理完 B 正在重新阻塞)。
-
按照輪詢邏輯,消費者 C3 成功獲取到元素 C。
-
C3 處理元素 C,然后重新執行?
BRPOP。
-
關鍵總結:
-
輪詢機制:通過消費者在獲取元素后必須顯式地重新發起?
BRPOP?命令這一行為,自然地實現了在活躍消費者之間的輪詢式負載分發。哪個消費者剛消費完并最快重新進入等待狀態,它在下一次元素到達時被選中的概率就更高(結合初始發起順序)。 -
高并發處理:多個消費者并行阻塞等待和處理,顯著提高了系統的吞吐量和響應能力。
-
資源高效:消費者的阻塞等待不消耗 CPU 資源,只在有消息到達時才被喚醒工作。
-
簡單可靠:利用 Redis 單命令的原子性和列表的 FIFO(先進先出,LPUSH/BRPOP 組合下是左進右出)特性,構建了一個簡單而可靠的消息隊列。
2.4.2.分頻道的消息隊列
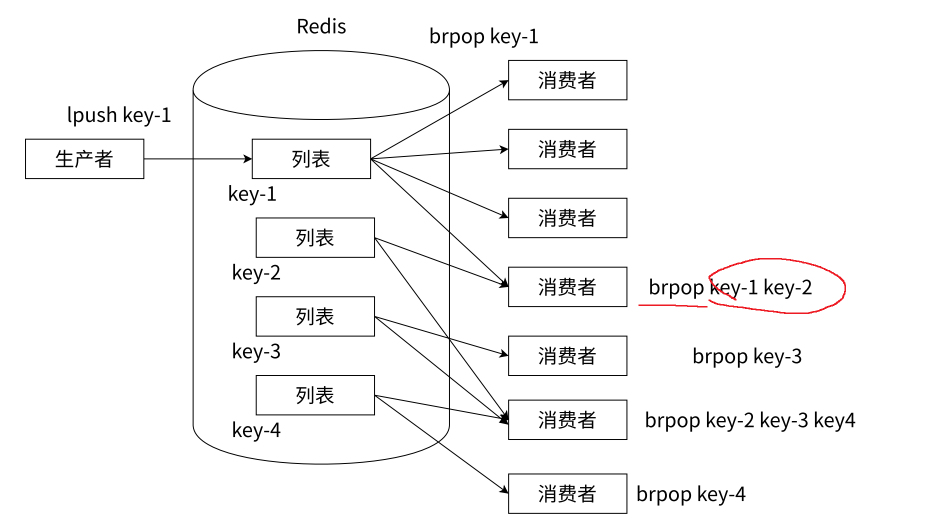
Redis 利用其?列表(List)?數據結構,結合?LPUSH?和?BRPOP?命令,可以構建一個強大的多頻道(Channel)或多主題(Topic)消息系統。其核心機制如下:
-
頻道即鍵(Key as Channel):
-
核心思想是將不同的邏輯頻道或主題直接映射到不同的 Redis 列表鍵(Key)上。
-
每個獨立的鍵代表一個獨立的通信管道。
-
-
生產者定向推送(Directed Production):
-
生產者根據消息所屬的業務類型、主題或頻道,使用?
LPUSH?命令,將消息精確地推送到對應的頻道鍵的頭部。
-
-
消費者訂閱消費(Subscription Consumption):
-
消費者通過執行?
BRPOP?命令來監聽一個或多個頻道鍵,實現“訂閱”。 -
BRPOP key [key ...] timeout:消費者阻塞等待指定的一個或多個鍵(頻道),直到其中任何一個鍵有新的元素(消息)到達。timeout?為 0 表示無限期阻塞等待。 -
當指定的某個鍵有消息到達時,
BRPOP?會返回該鍵名以及彈出的消息內容。 -
單個消費者可以同時監聽多個頻道鍵(
BRPOP chan1 chan2 chan3 0),哪個鍵先有消息就消費哪個,實現混合訂閱。
-
我們舉個例子好了
舉例
1. 頻道定義舉例(頻道即鍵)
-
videos:feed:傳輸短視頻推薦流數據。 -
live:danmu:12345:傳輸特定直播間(房間 ID 為 12345)的彈幕消息。 -
interactions:likes:傳輸用戶點贊事件數據。 -
interactions:comments:傳輸用戶評論數據(或新評論通知)。 -
interactions:shares:傳輸用戶轉發/分享事件數據。 -
notifications:system:傳輸系統廣播或全局通知。 -
tasks:image_processing:傳輸需要后臺處理的圖片任務。
2. 生產者行為舉例(定向推送)
-
一個用戶發送了一條彈幕到房間?
12345:LPUSH live:danmu:12345 "{"user": "張三", "text": "主播666!", "color": "#FF0000"}" -
用戶?
李四?點贊了視頻?video_67890:LPUSH interactions:likes "{"user_id": "li_si_uid", "video_id": "video_67890", "timestamp": 1722934567}" -
用戶?
王五?發表了一條評論:LPUSH interactions:comments "{"user_id": "wang_wu_uid", "content": "這個視頻太棒了!", "video_id": "video_abc123"}" -
后端系統生成了一個需要處理的圖片任務:
LPUSH tasks:image_processing "{"task_id": "img_task_987", "image_url": "https://...", "operation": "thumbnail"}"
3. 消費者行為舉例(訂閱消費)
-
彈幕處理服務(只關心特定房間的彈幕):
BRPOP live:danmu:12345 0? # 阻塞等待并只消費房間 12345 的彈幕 -
點贊事件處理服務:
BRPOP interactions:likes 0? # 阻塞等待并只消費點贊事件 -
互動事件聚合服務(同時處理點贊、評論、分享):
BRPOP interactions:likes interactions:comments interactions:shares 0 # 阻塞等待,哪個互動頻道有事件就先處理哪個(點贊、評論或分享) -
圖片處理后臺Worker:
BRPOP tasks:image_processing 0? # 阻塞等待并消費圖片處理任務 -
通知推送服務(只關心系統通知):
BRPOP notifications:system 0
4. 故障隔離舉例
-
場景:?
interactions:comments?頻道的消費者服務因為一個評論內容的解析 Bug 而崩潰重啟。 -
隔離效果:
-
interactions:comments?隊列中的消息會暫時堆積(因為消費者掛了)。 -
但是:
-
彈幕服務(消費?
live:danmu:12345)完全不受影響,繼續正常收發彈幕。 -
點贊服務(消費?
interactions:likes)完全不受影響,繼續正常處理點贊。 -
視頻流服務(消費?
videos:feed)完全不受影響,繼續推送視頻。 -
圖片處理服務(消費?
tasks:image_processing)完全不受影響,繼續處理任務。 -
系統通知服務(消費?
notifications:system)完全不受影響。
-
-
-
恢復:?當評論服務的 Bug 被修復并重新啟動后,它會繼續從?
interactions:comments?隊列中消費堆積的消息,其他服務在整個過程中毫不知情且未受影響。
這種基于不同 Redis 鍵實現多頻道的模式,其核心優勢在于提供了強大的解耦與隔離能力:
-
邏輯解耦 (Decoupling):
-
不同的業務數據類型(如視頻流、彈幕、點贊、評論、分享)被清晰地劃分到獨立的處理管道(頻道鍵)中。
-
生產者和消費者只需關注自身負責的頻道鍵,無需了解其他頻道的數據格式、處理邏輯或存在狀態。降低了系統復雜度。
-
-
故障隔離 (Fault Isolation) - 關鍵優勢:
-
這是多頻道設計最重要的價值之一。某個頻道的故障(如數據處理異常、消息積壓、消費者服務崩潰)會被嚴格限制在該頻道自身及其相關的消費者上。
-
其他頻道(鍵)的生產、消費、以及關聯的服務完全不受影響,能繼續正常運作。例如,彈幕處理服務宕機不會阻塞視頻流推送或點贊通知的處理。
-
極大地提升了整個系統的魯棒性(Robustness)和可用性。
-
-
資源隔離與擴展性 (Resource Isolation & Scalability):
-
不同頻道的消息通常具有不同的特性(吞吐量、處理時延要求、重要性)。
-
獨立的頻道鍵使得可以:
-
按需擴展:?為高吞吐量頻道(如彈幕)部署更多的消費者實例。
-
優先級管理:?為低延遲要求高的頻道(如實時點贊通知)分配更高優先級的計算資源(更快的消費者、更好的服務器)。
-
獨立監控:?單獨監控每個頻道隊列的長度(LLEN)、生產速率(監控 LPUSH)、消費速率(監控 BRPOP)等關鍵指標,便于發現瓶頸和優化。
-
-
-
關注點分離 (Separation of Concerns):
-
開發、測試、運維和調試變得更加清晰。不同的團隊或模塊可以專注于特定頻道的數據流和處理邏輯。
-
系統架構更易于理解和維護。
-
2.4.3.微博 Timeline
每個用戶都有屬于自己的 Timeline(微博列表),現需要分頁展示文章列表。
此時可以考慮使用列表,因為列表不但是有序的,同時支持按照索引范圍獲取元素。
為了給用戶提供分頁展示的微博列表(Timeline),我們采用 Redis 的?列表(List)?數據結構作為核心存儲方案。列表的有序特性(按插入時間逆序)天然支持按時間線展示微博,并且其?LRANGE?命令能高效地按索引范圍獲取元素,非常適合分頁需求。
具體實現方案如下:
1.單條微博存儲:
-
每條微博使用一個?Redis 哈希(Hash)?存儲其核心屬性(如?
title,?timestamp,?content)。 -
示例命令:
HMSET mblog:1 title "xx" timestamp 1476536196 content "xxxxx" HMSET mblog:n title "xx" timestamp 1476536196 content "xxxxx"
2.用戶 Timeline 構建:
-
為每個用戶創建一個專屬列表,鍵名格式為?
user:<uid>:mblogs。 -
當用戶發布新微博或微博被加入其 Timeline(例如,關注的人發微博)時,使用?
LPUSH?命令將對應的微博哈希鍵(如?mblog:1)?插入到列表的頭部。這保證了最新的微博總是位于列表最前面。 -
示例命令:
LPUSH user:1:mblogs mblog:1 mblog:3 LPUSH user:k:mblogs mblog:9
3.分頁獲取 Timeline:
獲取用戶(例如用戶ID?1)第?1?頁(前?10?條)微博的基本流程:
-
使用?
LRANGE?獲取列表指定索引范圍內的微博鍵名:LRANGE user:1:mblogs 0 9 # 獲取索引 0 到 9 的元素 (共10條) -
遍歷返回的鍵名列表 (
keylist),對每個鍵執行?HGETALL?來獲取該微博的完整詳細信息:for key in keylist {HGETALL key }
該方案潛在的問題與優化考慮:
1 + N 查詢問題 (性能瓶頸):
-
問題描述:?當前的分頁獲取流程存在顯著性能問題。第一步?
LRANGE?獲取?N?個微博鍵名只需要?1?次 Redis 請求。然而,第二步需要為這?N?個鍵中的每一個單獨發起一次?HGETALL?請求,總共產生?N?次請求。當?N(即每頁顯示的微博數量)較大時,會產生大量的網絡往返(Round-Trip Time, RTT)和 Redis 服務器處理開銷,嚴重影響響應速度和系統吞吐量。 -
優化方案:
-
使用 Pipeline(流水線):?將第二步中對?
N?個鍵的?HGETALL?命令放入一個 Pipeline 中一次性發送給 Redis 服務器。Redis 會按順序執行所有命令,但只將最終結果一次性返回給客戶端。這將?N?次網絡往返和請求/響應開銷減少到接近?1?次,是解決此問題的首選高效方法。 -
使用序列化字符串 + MGET:?另一種思路是改變單條微博的存儲方式。不再使用 Hash,而是將整個微博對象序列化(如 JSON, MessagePack)后作為一個字符串值存儲(例如?
SET mblog:1 "{serialized_data}")。在分頁獲取時,第一步?LRANGE?拿到?N?個鍵名后,第二步改用?MGET?命令一次性獲取這?N?個鍵對應的序列化字符串值。客戶端收到后再反序列化。這同樣只需要?2?次請求(LRANGE?+?MGET)。優點:?請求次數少。缺點:?失去了 Hash 結構的部分優勢(如單獨更新某個字段不方便,需反序列化整個對象),序列化/反序列化增加客戶端 CPU 開銷。選擇哪種方式需權衡業務需求(更新頻率、讀取模式)和性能要求。
-
長列表中間元素訪問效率問題:
-
問題描述:?Redis 的 List 底層實現是鏈表(LinkedList)。
LRANGE?命令在訪問列表兩端(頭部或尾部附近)?的元素時效率很高(時間復雜度 O(n),n 是獲取的元素個數)。然而,當需要獲取列表中間位置的元素時(例如,用戶跳轉到第 1000 頁),LRANGE?需要從鏈表頭部開始遍歷,直到找到目標索引的起點,時間復雜度為 O(n),n 是起始索引的位置。對于一個非常大的列表(例如,存儲了數萬條微博),獲取中間頁的數據會變得很慢。 -
優化方案:
-
列表分片(Sharding):?將單個超長的用戶 Timeline 列表拆分成多個較小的子列表(Shards)。例如,可以為每個用戶維護多個列表鍵:
user:1:mblogs:0,?user:1:mblogs:1, ...,?user:1:mblogs:k。每個子列表存儲一定數量(如 1000 條)的微博鍵。優點:?將一個大列表的 O(n) 訪問復雜度分散到多個小列表上,每個小列表的?LRANGE?操作都很快(因為 n 變小了)。關鍵點:?需要額外維護元信息(如一個小的 Hash 或 ZSET)來記錄當前有哪些分片以及每個分片的大致時間范圍或索引范圍,以便在分頁時快速定位目標數據在哪一個或哪幾個分片中。這增加了實現的復雜度,但能有效解決超長列表的中間訪問瓶頸。
-
補充說明:
-
Pipeline 的必要性:?在未使用 Pipeline 或?
MGET?的原始方案中,“for key in keylist { hgetall key }” 循環確實會為每一頁數據(假設每頁 N 條)觸發 N 次單獨的 Redis 請求。對于高并發場景或大分頁(N 較大),這會造成嚴重的性能問題和 Redis 連接壓力。強烈建議在生產環境中使用 Pipeline 或?MGET(如果采用序列化存儲)來優化。 -
分片策略:?列表分片主要針對的是歷史數據訪問(用戶瀏覽很靠后的頁)的性能優化。對于最新的幾頁數據(通常是最常訪問的),即使列表很長,訪問頭部(
LRANGE 0 9)依然是高效的。因此,分片策略需要根據實際的用戶訪問模式(通常是長尾分布,最新數據訪問頻繁)來設計分片大小和粒度。
選擇列表類型時,請參考:
- 同側存取(lpush + lpop 或者 rpush + rpop)為棧
- 異側存取(lpush + rpop 或者 rpush + lpop)為隊列
三. 漸進式遍歷
3.1.為什么需要漸進式遍歷
直接使用?KEYS *?命令一次性獲取 Redis 中的所有 key 存在顯著風險。當數據庫包含大量 key 時,此操作會嚴重阻塞 Redis 服務器,因為 Redis 是單線程模型,KEYS *?需要遍歷整個鍵空間才能返回結果,在此期間無法處理其他任何請求,可能導致服務暫時不可用。
為了避免這種阻塞風險,Redis 提供了漸進式遍歷(Scan)?機制。其核心思想是分批、多次地檢索 key,而不是一次性獲取全部。
核心優勢與工作原理:
-
分批處理:?通過?
SCAN?命令及其相關變體(如?SSCAN,?HSCAN,?ZSCAN),每次執行僅返回一小部分 key(數量可大致控制)。 -
游標機制:?每次調用?
SCAN?會返回一個游標(cursor)。使用下一次調用時傳入這個游標,即可繼續從上一次結束的位置開始遍歷。 -
避免阻塞:?由于每次操作只處理一小部分 key,耗時很短,對服務器性能的影響微乎其微,不會造成顯著阻塞。
-
獲取全部 Key:?通過循環執行?
SCAN?命令,并傳遞每次返回的新游標,直到游標返回?0(表示遍歷完成),即可累積獲取到數據庫中的所有 key(或其子集,如特定模式的 key)。
重要注意事項:
-
非原子快照:?漸進式遍歷過程中,如果數據庫的 key 被添加或刪除,可能會觀察到重復的 key 或漏掉部分 key(尤其是在遍歷時間長且數據變化頻繁時)。它提供的是一個“盡力而為”的視圖,而非某個精確時間點的原子快照。
-
多次請求:?獲取全部 key 確實需要執行多次命令,但這正是其避免單次操作長時間阻塞的代價。
3.2.SCAN
核心作用
安全遍歷 Redis 鍵空間,替代阻塞式的?KEYS *?命令,避免單次操作造成服務卡頓。
版本支持:2.8.0+
時間復雜度:單次調用 O(1)(完整遍歷為 O(N),N 為鍵總數)
???命令語法
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]參數解析
| 參數 | 說明 | 默認值 | 注意事項 |
|---|---|---|---|
cursor | 遍歷游標,起始必須為?0,返回?0?表示遍歷結束 | 必填 | 每次調用需傳遞前次返回的游標 |
MATCH pattern | 鍵名模式匹配(如?user:*?匹配所有?user:?開頭的鍵) | 所有鍵 (*) | 支持通配符?*???[] |
COUNT count | 建議返回的鍵數量(實際數量可能浮動) | 10 | 非強制約束,可能返回更多/更少鍵 |
TYPE type | 按數據類型過濾(如?hash/zset/stream),Redis 6.0+ 支持 | 所有類型 | 精確匹配數據類型名 |

示例
示例 1:基礎遍歷(獲取所有鍵)
第一次遍歷(從游標 0 開始)
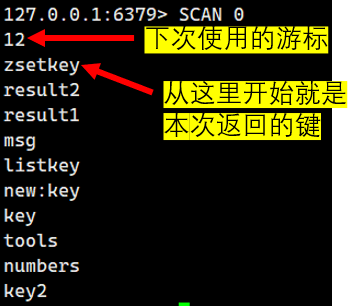
下一下遍歷,我們就得用返回的游標繼續遍歷
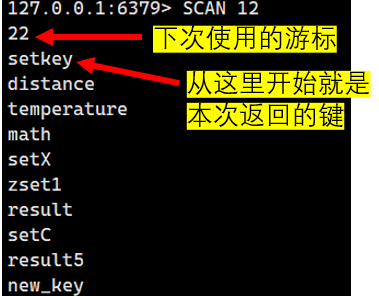
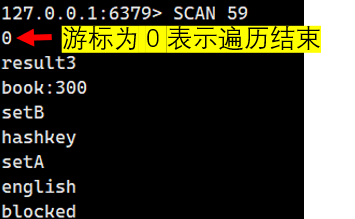
我們一直這樣子執行下去,就會看到下次使用的游標為0,這代表著遍歷結束了
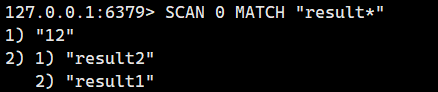
示例 2:匹配特定前綴的鍵(MATCH)
查找所有以 "result" 開頭的鍵
示例 3:控制返回數量(COUNT)
# 每次嘗試返回最多 3 個鍵
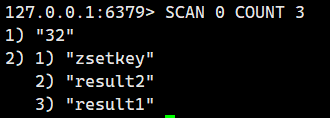
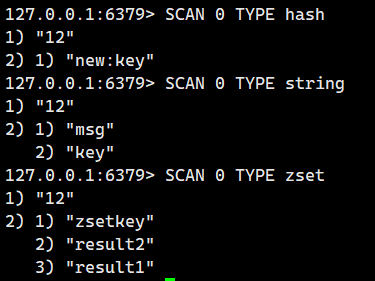
示例 4:按數據類型過濾(TYPE,Redis 6.0+)
示例 5:組合使用(生產環境常用)
# 查找所有以 "cache_" 開頭的 String 類型鍵,每次取 100 個
127.0.0.1:6379> SCAN 0 MATCH cache_* TYPE string COUNT 100
# 用新游標繼續...
127.0.0.1:6379> SCAN 168 MATCH cache_* TYPE string COUNT 100
(分組查詢、連接查詢、合并查詢、子查詢))



協議的全面解析:理論、機制與實踐局限性)


![[SC]SystemC 常見的編譯/語法錯誤與解法(三)](http://pic.xiahunao.cn/[SC]SystemC 常見的編譯/語法錯誤與解法(三))



)



)



