第一部分:非阻塞提交的起源:從兩階段提交(2PC)的缺陷到三階段提交(3PC)的構想
在分布式計算領域,確保跨多個獨立節點執行的事務的完整性是一項至關重要的挑戰。這些節點或站點可能在地理上分散,并通過可能出現故障的網絡連接。在這樣的環境中,一個核心的要求是維持事務的原子性(Atomicity),這是ACID屬性的基石。
1.1 分布式系統中的原子性指令
分布式事務涉及在多個站點(節點)上執行的一系列操作,這些操作必須被視為一個單一的、不可分割的工作單元 1。原子性這一屬性確保了一個事務要么在所有參與站點上完全成功(提交),要么在所有站點上完全失敗(中止)4。出現一個站點提交而另一個站點中止的情況是不可接受的,因為它會破壞分布式數據庫的整體一致性和數據完整性 1。原子提交協議(Atomic Commit Protocols, ACPs),如兩階段提交(2PC)和三階段提交(3PC),正是為了強制執行這種“全有或全無”的保證而設計的 4。
1.2 兩階段提交(2PC)協議:簡要回顧
兩階段提交協議是實現分布式事務原子性的經典方法,其結構圍繞一個中心**協調者(Coordinator)和多個參與者(Participants)**展開 7。
階段一:投票/準備階段(Voting/Prepare Phase)
協調者向所有參與者發送一個 VOTE-REQ 或 PREPARE 消息,詢問它們是否能夠提交事務 2。每個參與者在收到請求后,會檢查其本地是否可以執行并提交該事務。如果可以,它會將事務執行所需的所有信息(如重做和撤銷日志)寫入穩定存儲(如磁盤),鎖定相關資源,然后向協調者回復
VOTE-COMMIT或Yes9。如果由于任何原因無法提交,它將回復VOTE-ABORT或No。至關重要的是,一旦參與者投票Yes,它就做出了一個有約束力的承諾:它不能再單方面中止事務,必須等待協調者的最終指令 11。階段二:提交/中止階段(Commit/Abort Phase)
協調者收集所有參與者的投票。如果它收到了所有參與者的 Yes 投票,它就會在其日志中記錄一個全局 COMMIT 的決定,并向所有參與者發送 GLOBAL-COMMIT 消息。反之,只要有任何一個參與者投票 No 或在超時期限內未響應,協調者就會決定中止事務,并向所有參與者發送 GLOBAL-ABORT 消息 2。參與者在收到最終決定后,會相應地完成事務(提交或中止),并釋放它們在準備階段持有的鎖和資源 10。
1.3 2PC的根本性阻塞問題
盡管2PC在理想情況下能夠保證原子性,但其核心弱點在于它是一個阻塞協議(blocking protocol) 13。這種阻塞并非簡單的性能下降,而是一種可能導致整個系統部分或全部停滯的嚴重問題。
關鍵的失敗場景
阻塞問題在以下特定場景中暴露無遺:當協調者在接收到所有參與者的 Yes 投票(此時所有參與者都進入了“準備就緒”或“不確定”狀態)之后,但在成功地將最終的 COMMIT 或 ABORT 決定傳達給所有參與者之前發生崩潰 9。
無限期的僵局
在這種狀態下,所有幸存的參與者都會被阻塞。它們陷入了一個兩難的境地:
它們不能單方面決定中止,因為其他某個參與者(或者協調者在崩潰前)可能已經收到了
COMMIT消息并完成了提交。如果此時中止,將導致數據不一致 9。它們也不能單方面決定提交,因為協調者可能在收集完所有 Yes 投票后,由于某種原因(例如,它自己的日志寫入失敗或一個參與者的 Yes 投票信息在網絡中丟失)決定了中止事務。
因此,參與者們別無選擇,只能無限期地等待協調者恢復,并由其重新分發最終的事務決議 14。
資源癱瘓
在被阻塞期間,參與者會繼續持有為該事務所獲取的關鍵數據庫鎖和其他系統資源。這意味著這些資源對于任何其他事務都是不可用的,從而可能引發連鎖反應,導致更大范圍的系統停頓 12。這種嚴重的可用性問題,正是催生像3PC這樣的非阻塞協議的主要動機 6。
“阻塞”一詞在2PC的語境下,其嚴重性遠超字面含義。它不僅僅是單個事務的延遲,而是一種持有資源的死鎖狀態,這種狀態會迅速蔓延。在一個高并發的系統中,比如金融交易系統,一個被阻塞的參與者持有的鎖會阻止其他無關的事務訪問相同的數據,從而形成一個不斷增長的阻塞進程隊列 17。這直接轉化為業務交易的失敗、服務水平協議(SLA)的違背,以及需要昂貴且易錯的人工干預來解決狀態僵局。這種人工干預,即所謂的“啟發式決策”(heuristic decision),本身就帶來了破壞數據一致性的風險 14。因此,設計一個能夠自主恢復并釋放資源而無需人工介入的協議,成為了分布式系統領域一個迫切的需求。3PC正是為了應對這一挑戰而誕生的。
第二部分:三階段提交協議的理論基礎
為了克服2PC的阻塞缺陷,研究人員開始探索新的協議設計。其中,由戴爾·斯基恩(Dale Skeen)提出的三階段提交協議,從理論上為構建非阻塞的原子提交協議奠定了基礎。
2.1 歷史背景與斯基恩的貢獻
三階段提交協議由戴爾·斯基恩在其1981年發表的里程碑式論文《非阻塞提交協議》("Nonblocking commit protocols")中正式提出 19。斯基恩是第一個明確認識到需要一個三階段協議來避免在任意單點故障下發生阻塞的學者 22。他的工作創新性地使用有限狀態自動機(finite state automata)來對提交協議進行建模,從而能夠形式化地推理其正確性和容錯屬性 20。
2.2 核心創新:PreCommit(預提交)狀態
3PC的核心創新在于,它在2PC的兩個階段之間插入了一個額外的“緩沖”階段,即預提交階段(Pre-Commit Phase) 6。這個新增階段的根本目的,是將2PC中那個單一且模糊的
prepared(準備就緒)狀態,分解為兩個界限分明、含義確切的狀態:waiting(等待,或稱 ready)和 pre-commit(預提交)6。
這種狀態分解的精妙之處在于,它確保了當一個參與者處于某個特定狀態時,其未來可能達到的最終結果(提交或中止)集合是確定的且受限的。具體來說:
從
pre-commit狀態出發,唯一可能的最終狀態是commit。從
waiting狀態出發,如果發生故障(如協調者超時),最終狀態將是abort8。
2.3 形式化的非阻塞屬性
斯基恩的論文為“非阻塞”這一特性提供了嚴格的形式化定義。一個協議是非阻塞的,當且僅當它滿足以下兩個條件 25:
不存在任何一個本地狀態
s,從該狀態出發,既可能轉換到commit狀態,也可能轉換到abort狀態。不存在任何一個“非可提交”狀態(non-committable state)
s,從該狀態出發,可能轉換到commit狀態。所謂“可提交狀態”(committable state),是指所有站點都已經投票同意提交事務的狀態。
3PC的設計嚴格遵循了這一定理。waiting 狀態與 abort 狀態相鄰(通過超時觸發),但與 commit 狀態不直接相鄰(必須先進入 pre-commit 狀態)。而 pre-commit 狀態是一個可提交狀態,它與 commit 狀態相鄰,但(在沒有網絡分區的情況下)與 abort 狀態不相鄰 8。這種狀態機的結構保證了,只要有幸存的、可通信的站點,它們就永遠不需要因為等待一個故障站點的恢復而被阻塞,因為幸存者群體的集體狀態已經包含了足夠的信息來做出一個全局一致的決定 6。
在事務處理中,“提交點”(commit point)是“不可逆轉點”(point of no return)17。在2PC中,這個提交點是一個脆弱的、集中的時刻:即協調者在其日志中寫入
COMMIT 記錄的那一刻。如果它在此之后立即崩潰,只有恢復后的協調者自己知道最終的決議,從而導致其他所有參與者阻塞。
3PC通過引入 PreCommit 階段,從根本上改變了這一模式。它將“提交點”從一個集中的、單一的事件,轉變為一個分布式的、容錯的狀態。當協調者收到所有 Yes 投票后,它做出了提交的決定。但它并不立即執行,而是通過 PreCommit 消息將這個意圖廣播出去。當一個參與者進入 PreCommit 狀態時,它就確切地知道:所有其他參與者必定已經投票同意了。這種在參與者之間共享的知識,構成了一種關于“提交必然性”的分布式共識,即使最終的 DoCommit 消息尚未到達。通過將決策與最終的執行解耦,3PC實現了其非阻塞設計的核心思想。
第三部分:3PC協議機制深度剖析
本節將詳細、逐步地拆解3PC協議的執行流程,闡明協調者和參與者的狀態、消息傳遞以及在每個階段的具體行為。
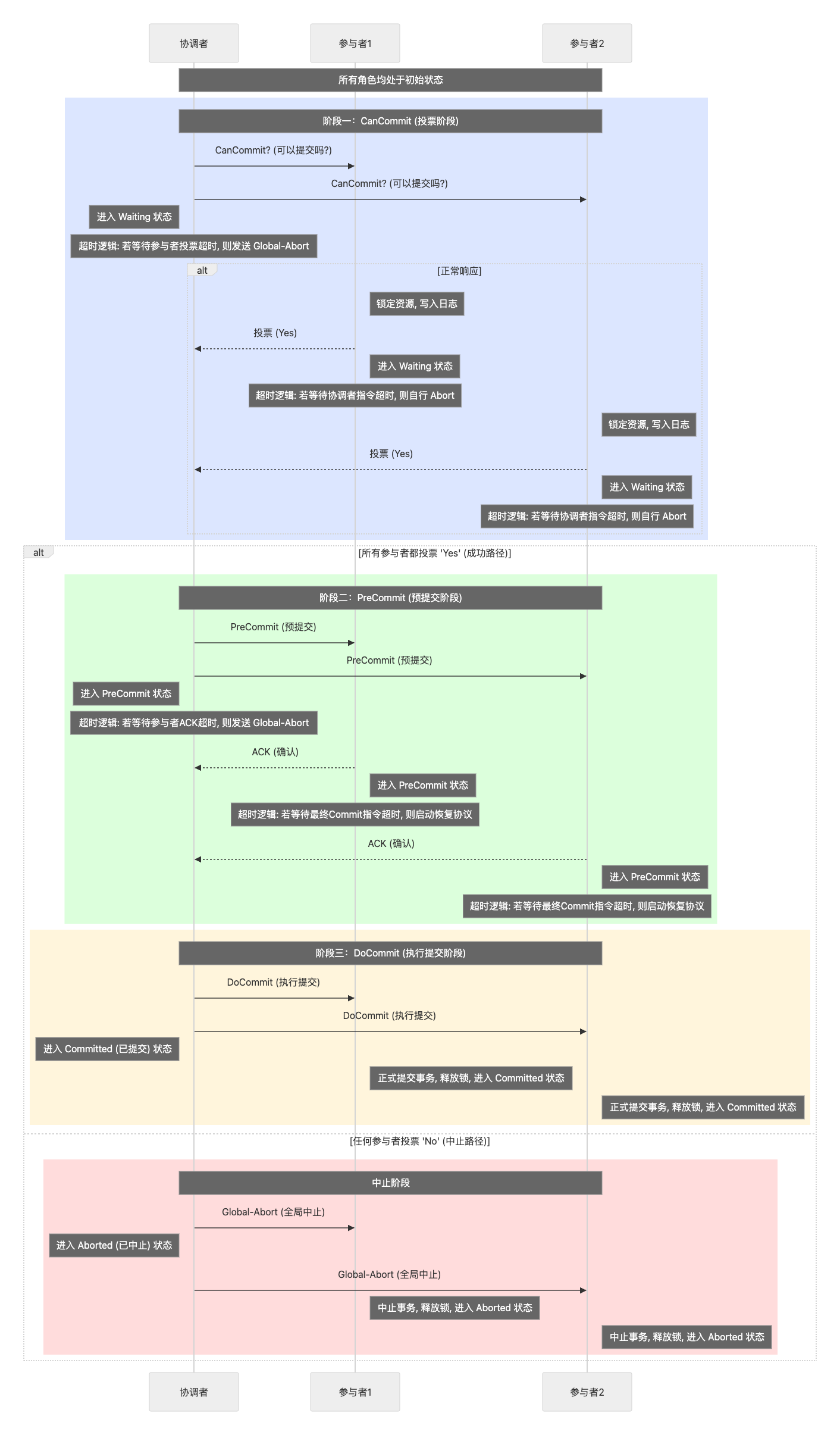
3.1 協議角色與狀態定義
協調者(Coordinator):作為主控進程,負責驅動整個事務協議的流程 8。
狀態集:
Initial(初始)、Waiting(等待投票)、PreCommit(預提交)、Committed(已提交)、Aborted(已中止)。
參與者(Participant):作為從屬進程,負責執行事務的本地部分,并根據協調者的指令行動 8。
狀態集:
Initial(初始)、Waiting(或Ready,已投票等待)、PreCommit(預提交)、Committed(已提交)、Aborted(已中止)8。
3.2 階段一:投票階段 (CanCommit?)
協調者動作:當應用程序請求提交事務時,協調者向所有參與者發送
CanCommit?(或VOTE-REQ)消息,然后自身轉換到Waiting狀態,等待參與者的響應 7。參與者動作:收到
CanCommit?消息后,參與者檢查本地資源和約束,判斷是否能夠提交事務。它會獲取必要的資源鎖,并將準備信息寫入本地事務日志 8。如果可以提交,它向協調者回復
Yes(或VOTE-COMMIT),并進入Waiting/Ready狀態 26。如果不能提交,它回復
No(或VOTE-ABORT),并立即進入Aborted狀態,因為單個No票就足以中止整個事務 26。
3.3 階段二:預提交階段 (PreCommit)
這是3PC區別于2PC的關鍵階段。
協調者動作:
如果在
Waiting狀態下收到任何一個參與者的No回復,或者等待某個參與者回復超時,協調者將向所有參與者發送Global-Abort消息,并進入Aborted狀態 7。如果協調者從所有參與者那里都收到了
Yes回復,它就做出了全局提交的決定。此時,它向所有參與者發送PreCommit消息,然后自身轉換到PreCommit狀態 7。
參與者動作:當處于
Waiting/Ready狀態的參與者收到PreCommit消息時,它就確信所有其他參與者都已同意提交。它會將PreCommit狀態持久化到日志中,向協調者發送一個ACK(確認)消息,并轉換到自身的PreCommit狀態 26。在此狀態下,它已準備好提交,但仍未執行任何不可撤銷的操作 7。
3.4 階段三:最終化階段 (DoCommit)
協調者動作:在
PreCommit狀態下,協調者等待所有參與者的ACK消息。一旦收到所有ACK,它就確認提交的決定已在整個系統中安全記錄。此時,協調者進入Committed狀態,記錄最終提交日志,并向所有參與者發送DoCommit(或Global-Commit)消息 8。參與者動作:當處于
PreCommit狀態的參與者收到DoCommit消息時,它將最終執行事務(使更新永久生效),釋放之前獲取的鎖和資源,并轉換到Committed狀態 8。
表1:3PC協議詳細狀態轉換邏輯
為了清晰地呈現3PC協議中復雜的、基于規則的邏輯,下表綜合了多個來源的信息 8,提供了一個權威的狀態轉換視圖。
| 角色 | 當前狀態 | 事件 (消息/超時) | 動作 | 新狀態 |
| 協調者 | Initial | 應用程序請求提交 | 向所有參與者發送 CanCommit? | Waiting |
| 參與者 | Initial | 收到 CanCommit? | 記錄 prepare 日志, 鎖定資源, 發送 Yes | Waiting |
| 參與者 | Initial | 收到 CanCommit? (無法提交) | 發送 No | Aborted |
| 協調者 | Waiting | 收到所有參與者的 Yes | 向所有參與者發送 PreCommit | PreCommit |
| 協調者 | Waiting | 收到任何 No 或超時 | 向所有參與者發送 Global-Abort | Aborted |
| 參與者 | Waiting | 收到 PreCommit | 記錄 pre-commit 日志, 發送 ACK | PreCommit |
| 參與者 | Waiting | 收到 Global-Abort 或超時 | 中止事務, 釋放鎖 | Aborted |
| 協調者 | PreCommit | 收到所有參與者的 ACK | 向所有參與者發送 DoCommit | Committed |
| 協調者 | PreCommit | 等待 ACK 超時 | 向所有參與者發送 Global-Abort | Aborted |
| 參與者 | PreCommit | 收到 DoCommit | 提交事務, 釋放鎖 | Committed |
| 參與者 | PreCommit | 等待 DoCommit 超時 | 啟動恢復協議 | 根據恢復結果而定 |
第四部分:容錯與恢復場景分析(故障-停止模型)
本節將分析3PC協議如何在“故障-停止”(fail-stop)模型下通過處理節點故障來實現其非阻塞特性。該模型假設節點只會因崩潰而失效,并且網絡通信是可靠的,不會發生分區 7。
4.1 處理協調者故障
故障檢測:參與者通過超時機制檢測協調者的故障。如果一個參與者處于
Waiting或PreCommit狀態,并且在預設的時間內沒有收到預期的下一條消息(分別是PreCommit或DoCommit),它就會假定協調者已經崩潰 7。恢復協議:幸存的參與者們會啟動一個恢復協議。這通常涉及從它們中間選舉一個新的恢復協調者(recovery coordinator)。選舉本身的機制是一個獨立的協議,例如可以基于節點ID的大小來決定 8。
恢復協調者的決策邏輯:新的協調者通過查詢所有其他可用參與者的狀態來確定事務的最終命運 7。其決策邏輯如下:
如果查詢到任何一個參與者處于
Committed狀態:新協調者可以斷定,原協調者在崩潰前已經發出了DoCommit指令。因此,它可以安全地向所有參與者廣播DoCommit消息,以確保所有節點都完成提交。如果查詢到有參與者處于
PreCommit狀態(但沒有節點處于Committed狀態):新協調者可以推斷,原協調者成功完成了第一階段(所有人都投了Yes)并啟動了第二階段。這意味著全局的意圖是提交。因此,它可以安全地接管并推動事務完成。它會重新發送PreCommit消息給可能沒收到的節點,等待所有節點的ACK,然后發送DoCommit7。如果所有可達的參與者都處于
Waiting狀態:新協調者可以確定,原協調者不可能已經發出了PreCommit消息(否則至少會有一個參與者處于PreCommit狀態)。既然沒有進入預提交階段,那么全局提交的決定就不可能做出。因此,它可以安全地向所有參與者發送Global-Abort消息 8。如果查詢到任何一個參與者處于
Aborted狀態:這意味著事務必須中止。新協調者會向所有參與者廣播Global-Abort消息。
4.2 處理參與者故障
故障檢測:協調者通過超時機制檢測參與者的故障,例如在等待
Yes/No投票或等待PreCommit的ACK時 7。協調者動作:
如果在
Waiting狀態下(等待投票)發生參與者超時,協調者尚未做出提交決定。它會向所有其他幸存的參與者發送Global-Abort指令 7。如果在
PreCommit狀態下(等待ACK)發生參與者超時,情況則更為復雜。此時,協調者已經向所有參與者發送了PreCommit消息。雖然它知道所有參與者都同意提交,但某個參與者未能確認其已進入PreCommit狀態,這帶來了不確定性。為了保證原子性,最保守也是最安全的選擇是中止整個事務。因此,協調者會向所有幸存者發送Global-Abort指令 8。
4.3 恢復的不對稱性與“故障-恢復”的脆弱性
標準的3PC恢復協議在純粹的“故障-停止”模型下運行良好,但它對于“故障-恢復”(fail-recover)場景卻異常脆弱。在這種場景中,原協調者崩潰后又重新上線,而此時一個恢復協調者已經接管了工作。這可能在沒有網絡分區的情況下導致“腦裂”(split-brain)問題,從而破壞一致性。
這個微妙但致命的場景可以這樣展開 7:
原協調者C1發送
PreCommit消息后,在收到所有ACK之前崩潰。幸存的參與者超時后,選舉出一個新的恢復協調者C2。
C2查詢參與者狀態,發現有節點處于
PreCommit狀態,于是開始引導事務走向Commit狀態。幾乎在同一時間,原協調者C1恢復了。它并不知道C2的存在。它檢查自己的狀態,發現自己仍在等待某些
PreCommit的ACK。C1等待超時后,按照其協議邏輯,決定中止事務,并向所有參與者發送
Global-Abort消息。結果,一些參與者可能從C2那里收到
DoCommit消息,而另一些參與者則從C1那里收到Global-Abort消息,導致最終狀態不一致。
這個例子揭示了3PC的正確性在很大程度上依賴于一個干凈的“故障-停止”模型和一個強大的機制來防止“僵尸協調者”(zombie coordinator)的出現。這種額外的復雜性,是其在工程實踐中難以被正確實現和部署的重要原因之一。
第五部分:致命缺陷:3PC對網絡分區的脆弱性
這是本報告最關鍵的部分,它詳細闡述了為何3PC盡管解決了2PC的阻塞問題,卻未能在實際系統中得到應用。其非阻塞的保證是以在網絡分區下犧牲原子性為代價的。
5.1 超越故障-停止模型:異步網絡
原始的3PC協議是在一個同步網絡模型的假設下設計的,該模型認為超時可以可靠地指示節點崩潰 7。然而,現實世界中的網絡本質上是異步的。一次超時事件的含義是模糊的:它可能意味著對方節點已經崩潰,也可能意味著網絡鏈路中斷(即網絡分區),或者僅僅是消息被嚴重延遲 1。3PC協議對于網絡分區是
不具彈性的,這是其致命缺陷 7。
5.2 “腦裂”不一致場景
網絡分區(network partition)可以將系統中的節點分割成兩個或多個相互隔離的組,這些組內部的節點可以正常通信,但組與組之間無法通信 1。這種情況可能導致“腦裂”(split-brain),即不同的分區對同一個事務做出了相互沖突的決定 32。
以下是導致數據不一致的詳細場景演練:
初始設置:一個協調者(C)和四個參與者(P1, P2, P3, P4)。
階段一和階段二開始:C發送
CanCommit?,所有參與者回復Yes。隨后,C向所有參與者發送PreCommit消息。網絡分區發生:在所有
PreCommit消息到達或被確認之前,網絡發生分區,將節點分為兩個隔離的組:分區A = {C, P1, P2} 和分區B = {P3, P4}。我們假設P1和P2成功收到了PreCommit消息,而P3和P4沒有。分區A的決策(提交):在分區A內部,C可能收到了P1和P2的
ACK。此時,C等待P3和P4的ACK超時。根據某些3PC變種的實現,如果一個分區內包含了協調者和多數參與者,它可能會繼續推進。為了說明問題,我們假設分區A的協議(由C領導)最終決定提交。于是,C、P1和P2提交了事務。分區B的決策(中止):在分區B內部,參與者P3和P4等待C的
PreCommit消息超時。它們假定C已經失敗,于是啟動恢復協議,選舉出一個新的恢復協調者(例如P3)。P3查詢P4的狀態,發現其處于Waiting狀態。由于在它們這個分區內,沒有任何參與者進入了PreCommit狀態,P3根據其有限的世界觀,正確地推斷出原協調者不可能做出提交決定,因此事務應該中止。于是,P3和P4中止了事務 7。不一致的后果:一段時間后,網絡分區愈合。此時,系統已經處于一個嚴重不一致的狀態:P1和P2已經提交了事務,而P3和P4卻中止了同一個事務。這直接違反了原子性,而原子性正是該協議本應保證的核心屬性 7。
5.3 失敗分析
PreCommit 狀態之所以無法解決網絡分區問題,是因為每個分區內的決策過程都是基于不完整的信息。分區B中的恢復協議,根據其所能觀察到的信息做出了“正確”的本地決策,但它的信息是過時且不完整的。
3PC的非阻塞特性恰恰是導致這種失敗的根源。它允許一個節點子集為了避免阻塞而做出決策,但由于缺乏一個能夠確保該決策全局一致的機制,它為了活性(liveness)而犧牲了一致性(consistency)26。
5.4 CAP定理的實踐例證
3PC在網絡分區期間的失敗,是CAP定理的一個經典教科書式例證。通過在分區期間試圖保持可用(即非阻塞),它犧牲了系統的一致性。
CAP定理指出,任何一個分布式系統在以下三個保證中,最多只能同時滿足兩個:一致性(Consistency)、可用性(Availability)和分區容錯性(Partition Tolerance)17。當網絡分區(P)發生時,系統設計者必須在C和A之間做出選擇。
2PC的選擇:2PC選擇了一致性。它通過阻塞(犧牲可用性)來避免在分區期間做出可能導致不一致的決策。
3PC的選擇:3PC試圖在分區期間保持非阻塞(追求可用性),但這允許了不同分區獨立推進并做出決策,最終導致了不一致的結果,即犧牲了一致性。
這就是為什么3PC雖然在理論上解決了2PC的阻塞問題,但在實踐中卻被認為是不可用的。對于要求數據強一致性的原子提交場景,任何犧牲一致性的行為都是不可接受的。
第六部分:比較分析與向現代共識的演進
本節將3PC置于更廣闊的分布式協議領域中,將其與2PC進行直接對比,并解釋為何現代系統已經轉向了如Paxos和Raft等更為強大的解決方案。
6.1 3PC vs. 2PC:明確的權衡分析
3PC的優勢:在故障-停止模型下,它對于協調者或參與者的單點故障是非阻塞的,解決了2PC最主要的痛點 6。
3PC的劣勢:
更高的延遲和開銷:即使在沒有任何故障的“晴天”場景下,3PC也需要額外一輪的消息交互(
PreCommit和ACK),這增加了每個事務的延遲 7。更高的復雜性:協議的邏輯,特別是涉及超時和選舉的恢復部分,在實現和維護上要復雜得多 34。
在網絡分區下失效:如前所述,它無法在網絡分區的情況下保證原子性,這對任何嚴肅的分布式系統來說都是一個致命的缺陷 15。
6.2 范式轉移:Paxos和Raft
現代的容錯分布式系統,絕大多數都選擇了像Paxos及其更易于理解的變體Raft這樣的共識算法,而不是3PC 13。這些是通用的共識算法,旨在讓一組節點能夠在出現包括網絡分區在內的各種故障時,就某個值(例如,事務的最終結果)達成一致 36。
6.3 法定人數原則:為何Paxos/Raft成功而3PC失敗
核心差異:與通常需要全體一致同意的2PC/3PC不同,Paxos和Raft基于**多數派投票(majority vote)或法定人數(quorum)**的原則來運作 18。
防止腦裂:一個決議只有在被多數節點接受后才能被最終確定。法定人數的數學特性保證了任意兩個多數派集合(quorum)之間至少會有一個共同的節點。這個重疊的節點充當了信息傳遞的橋梁,從根本上防止了兩個被隔離的分區做出相互沖突的決定 39。如果發生網絡分區,且沒有任何一個分區能夠包含多數節點,那么系統將安全地阻塞(選擇一致性而非可用性),但絕不會出現不一致的狀態。與3PC那種可能導致數據損壞的“不安全”推進相比,這是一種安全且可預測的行為。
6.4 案例研究 - Google Spanner:現代方法
像Google Spanner這樣的生產級全球分布式數據庫,展示了解決分布式事務問題的最前沿方案 40。Spanner并
沒有使用3PC。取而代之的是,它將2PC協議構建在Paxos共識算法之上 40。
架構:在Spanner中,一個2PC事務的“協調者”和“參與者”不再是單個服務器,而是本身就由Paxos管理的復制狀態機(replicated state machines)。每個組件(協調者或參與者)都是一個由多個副本組成的Paxos組 41。
優勢:這種復合架構集兩家之長。它利用2PC相對簡單的邏輯來協調跨越不同數據分片(shards)的事務。同時,它利用Paxos來確保事務中的每個組件都具有高可用性和分區容錯性。如果一個充當協調者領導者(leader)的節點失敗,其所在的Paxos組會迅速選舉出一個新的領導者,2PC協議可以繼續進行,從而解決了2PC的阻塞問題,同時又避免了3PC在網絡分區下的不一致風險 40。
表2:原子提交與共識協議的比較分析
下表為一個高層次的戰略總結,旨在幫助架構師和決策者理解不同協議之間的核心權衡。
| 特性 | 兩階段提交 (2PC) | 三階段提交 (3PC) | Paxos / Raft |
| 消息輪次 | 2 | 3+ | 2+ (在基于領導者的變體中) |
| 延遲 | 較低 | 較高 | 較高 |
| 協調者故障時是否阻塞? | 是 (無限期阻塞) | 否 (在故障-停止模型中) | 否 (只要多數派存活) |
| 是否容忍網絡分區? | 否 (會阻塞) | 否 (會產生不一致) | 是 (保持一致性) |
| 復雜性 | 中等 | 高 | 非常高 |
| 實踐應用 | 廣泛使用,常與共識算法結合 (如Spanner) | 實踐中不使用 | 工業界共識標準 |
第七部分:結論:3PC的理論遺產與實踐的無關性
本報告的最后部分將綜合所有分析,為三階段提交協議下一個明確的定論。
7.1 一個具有學術重要性的協議
3PC在分布式系統理論史上占有重要地位。它是第一個為創建非阻塞原子提交協議所做的嚴謹嘗試,并為分析此類協議提供了形式化的狀態機框架 20。學習3PC對于理解阻塞、活性和一致性之間微妙的關系至關重要,它也是理解為何需要像Paxos這樣更強大協議的一個完美的教學跳板 4。
7.2 為何3PC在實踐中不被使用
結論是明確且不容置疑的:3PC在現代生產系統中不被使用 4。
最主要的原因是它在網絡分區下的災難性故障模式。對于任何要求高可靠性的系統來說,數據損壞和狀態不一致的風險都是不可接受的 15。
次要原因包括其相對于2PC更高的延遲和消息開銷,以及顯著增加的實現復雜性 34。它所提供的有限好處(在受限的故障-停止模型中解決阻塞問題)完全無法抵消其帶來的巨大風險和成本。
7.3 最終裁決:一塊有益的墊腳石
總而言之,3PC應被理解為分布式共識發展道路上一個重要但最終被證明存在缺陷的演化步驟。工業界已經轉向了更健壯、數學上更完備的解決方案,主要是通過將2PC的事務邏輯與Paxos/Raft的分區容錯共識保證相結合。3PC作為一個案例研究,仍然是揭示分布式系統設計中那些微妙且往往反直覺的挑戰的寶貴教材。


![[SC]SystemC 常見的編譯/語法錯誤與解法(三)](http://pic.xiahunao.cn/[SC]SystemC 常見的編譯/語法錯誤與解法(三))



)



)








