目錄
- 1.分組查詢
- (1)聚合函數
- (2)group by子句
- (3)having
- 2.連接查詢
- (1)內連接(笛卡爾積)
- (2)外連接
- (3)內外連接的區別
- (4)自連接
- a.給表取別名
- b.自連接的使用
- 3.合并查詢
- (1)union
- (2)union all
- 4.子查詢(嵌套查詢)
- (1)單行
- (2)多行
- a.in
- b.all
- c.any
- (3)多列單行
- (4)多列多行
- (5)from中使用臨時表
- (6)with的使用
- 5.select各個關鍵字的執行順序
查詢分為簡單和復合查詢,是利用select和各種相關用法通過邏輯連接實現特定的功能,篩選并正確展示數據。 上篇文章講了select的基本用法,所以該部分是對上篇文章的延伸。
1.分組查詢
(1)聚合函數
聚合函數是內置函數的子集,聚合函數多用于對多行數據進行統計等運算
select count(*) from tb; # 統計tb的行數,也可統計指定列不為空的數據個數
select sum(English) from tb; # 統計tb中English列成績總和,自動忽略空值
select avg(Chinese) from tb18; # 統計tb18中Chinese列成績平均值,自動忽略空值
select max(distinct English) from tb18; # 統計tb18中English列成績最大值,自動忽略空值和重復值
select min(distinct Chinese) from tb18; # 統計tb18中Chinese列成績最小值,自動忽略空值和重復值
(2)group by子句
在這個表下面,如果我們想要得到每個班級的每科成績的平均值,就需要對class分組。
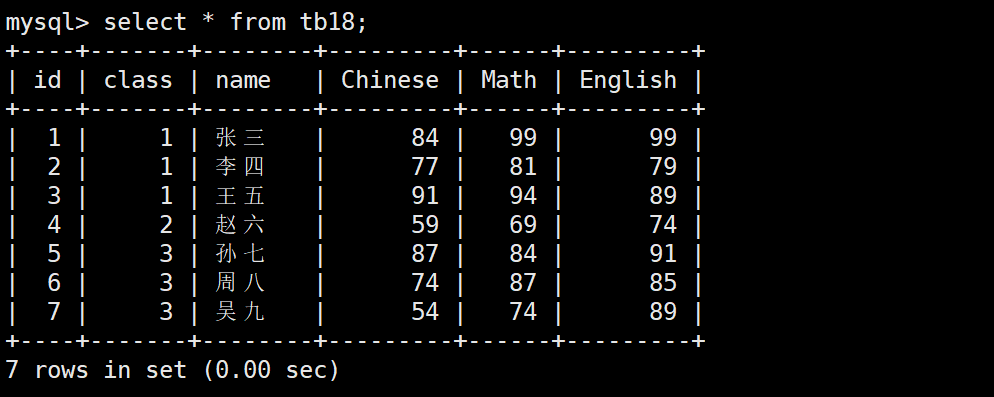
select class, avg(Chinese), avg(Math), avg(English) from tb18 group by class; # 展示的列中只能由聚合函數結果、分組的列組成
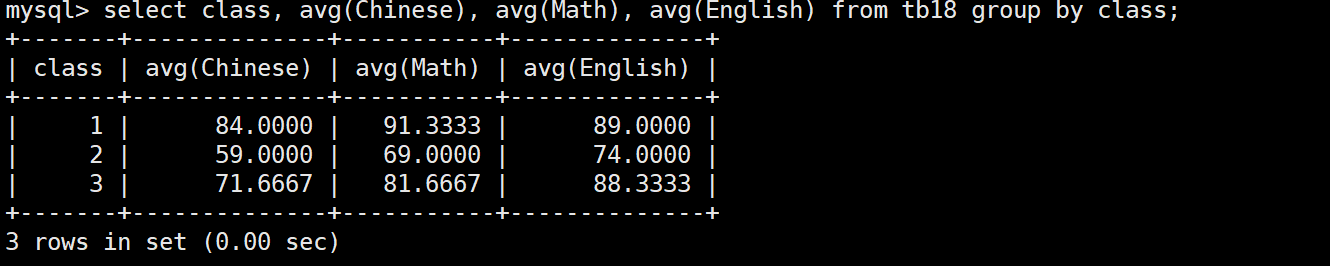
group by按照該列不同的值分組后,聚合函數的計算也會分組。最后select展示時只能由聚合函數、分組的列組成,其它的都沒有意義,也會報錯。
(3)having
having經常和group by子句聯合使用,用于對即將展示的結果進行篩選。它和where的執行順序不同,where在select之前執行,而having在select之后執行,因此你能看到having可以直接使用重命名。
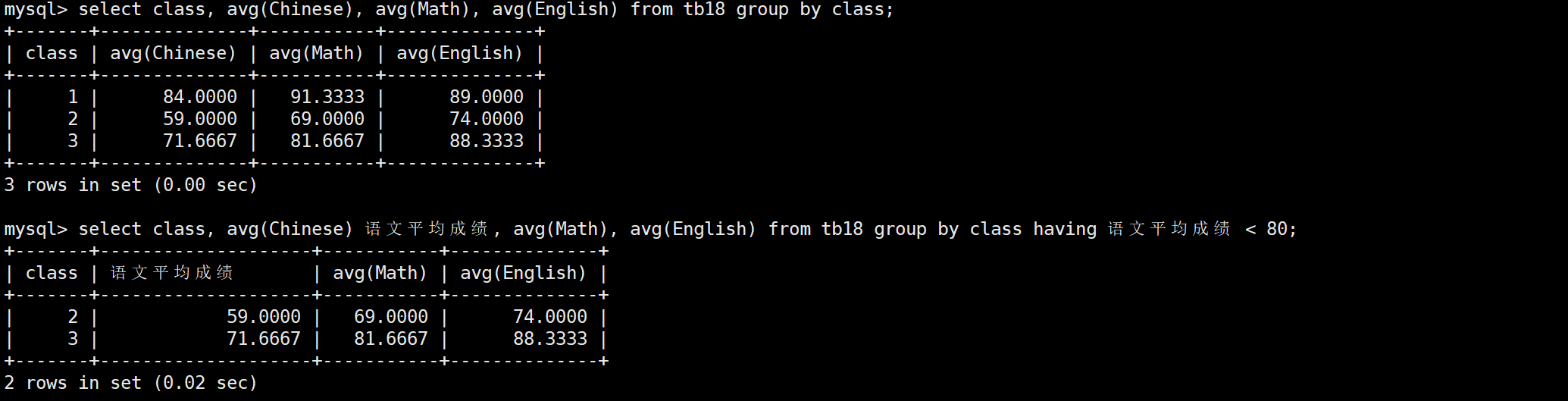
當然,having也可以單獨使用
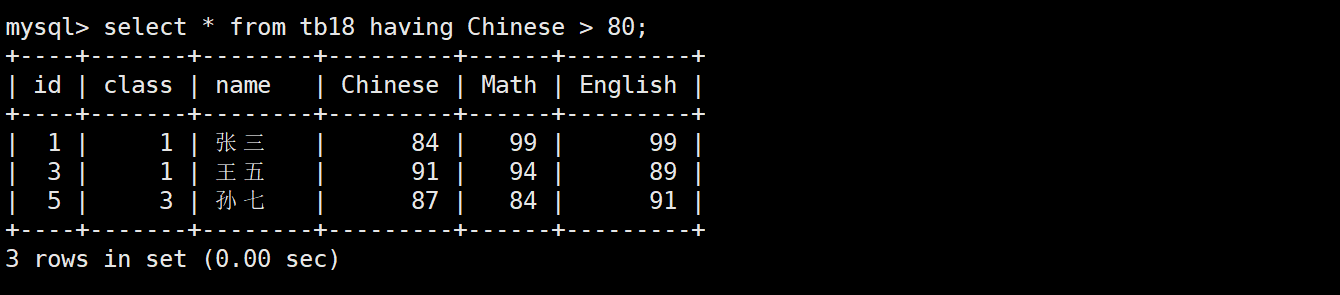
having和where在邏輯上一個是對執行結果做篩選,一個是篩選后執行,因此就只有having可以用在分組后,分組前兩個都可以使用。
2.連接查詢
(1)內連接(笛卡爾積)
有的時候我們想要將兩張表連在一起
如tb18是學生信息表,包括其成績

tb是其老師的信息表
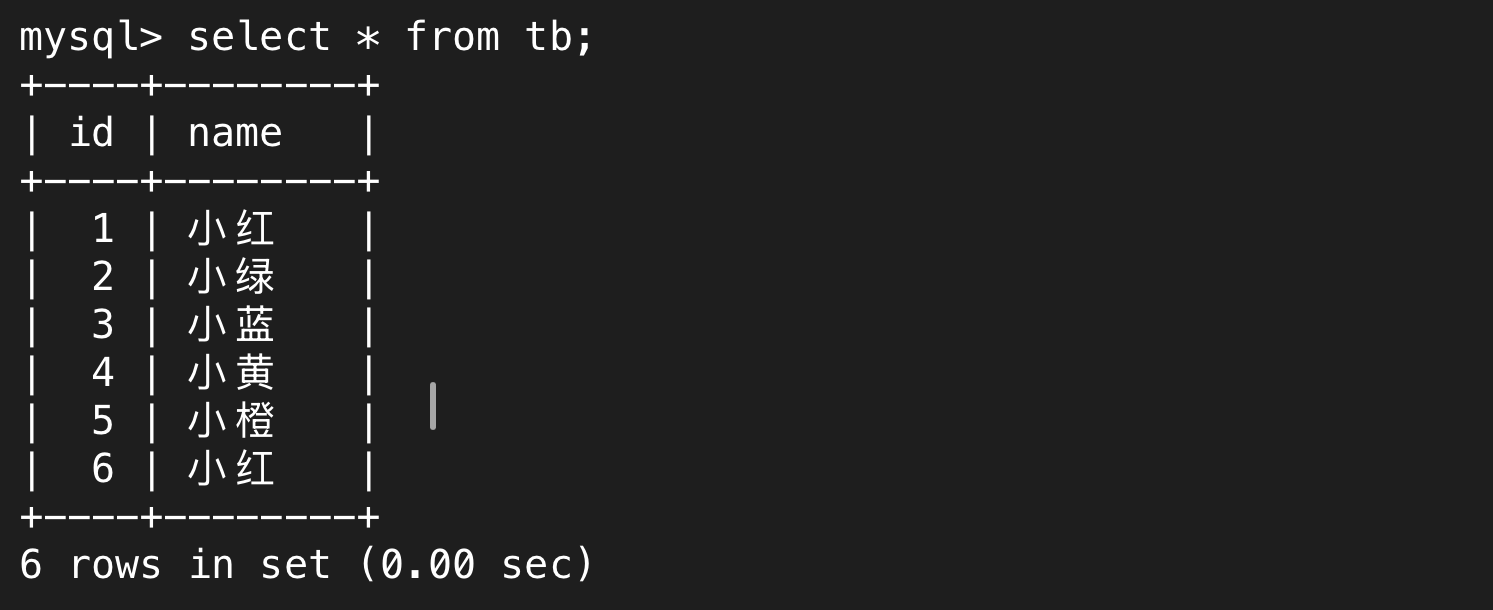
連接起來就是排列組合,以下就是所有學生和所有老師的組合情況
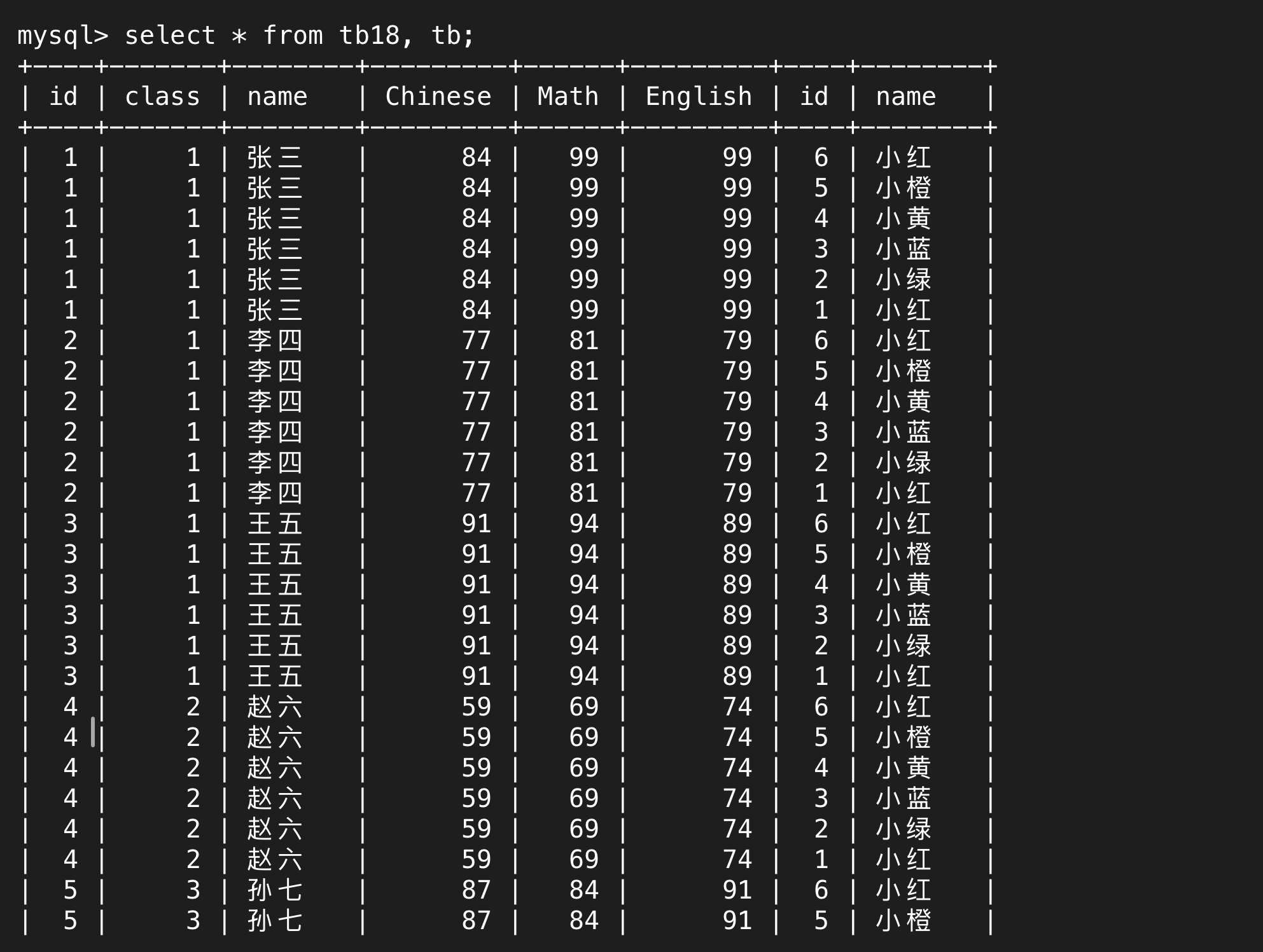
張三和小紅、小橙……小綠都連在一起了,之后就是李四,又和這6個人連在一起了。笛卡爾積就是取前一張表的每一行,和后面一張表的每一行都連接一次,這就是排列組合,目的是窮舉所有的可能性。
而顯然,笛卡爾積的結果并不是最終我們想要的結果,它只是先為我們提供所有的可能性,我們需要再次篩選得到想要的行。
其中,無論是篩選還是select,只要有重復的列名,都需要用(表名).(列名)來唯一確定。
通過where子句,我們就可以篩選出我們需要的行
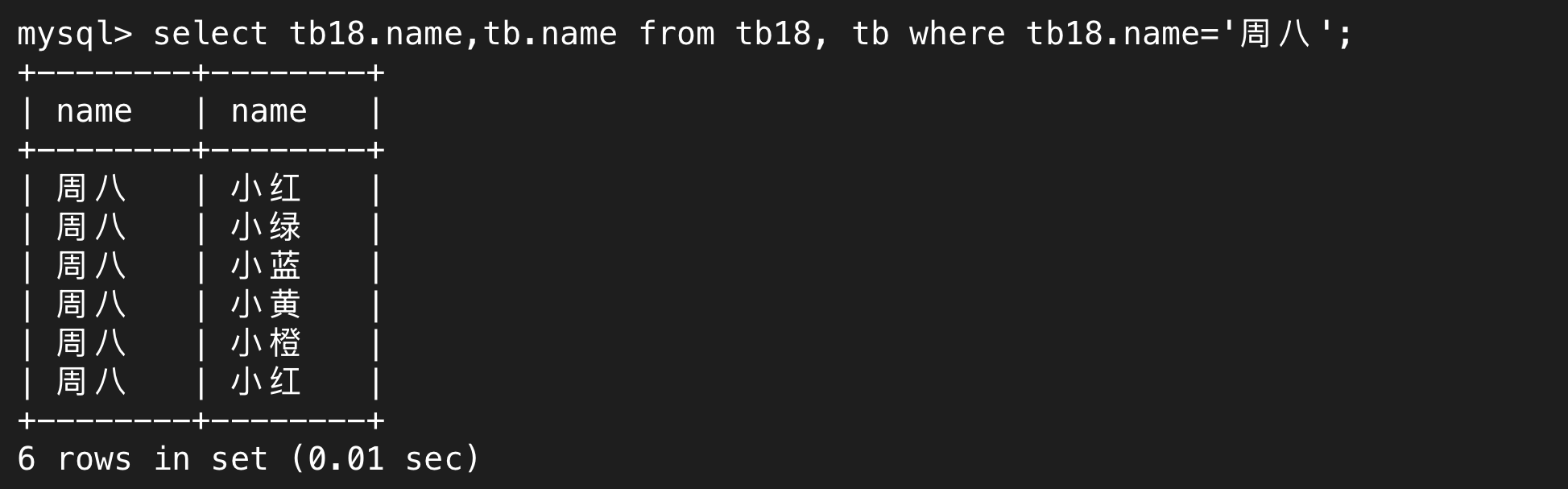
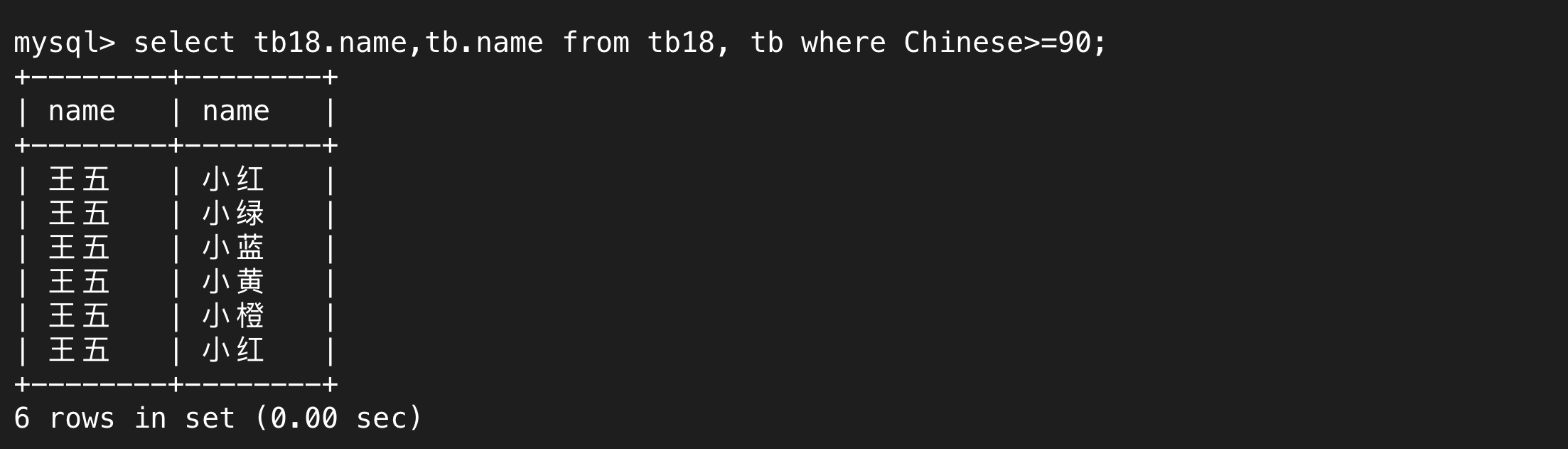
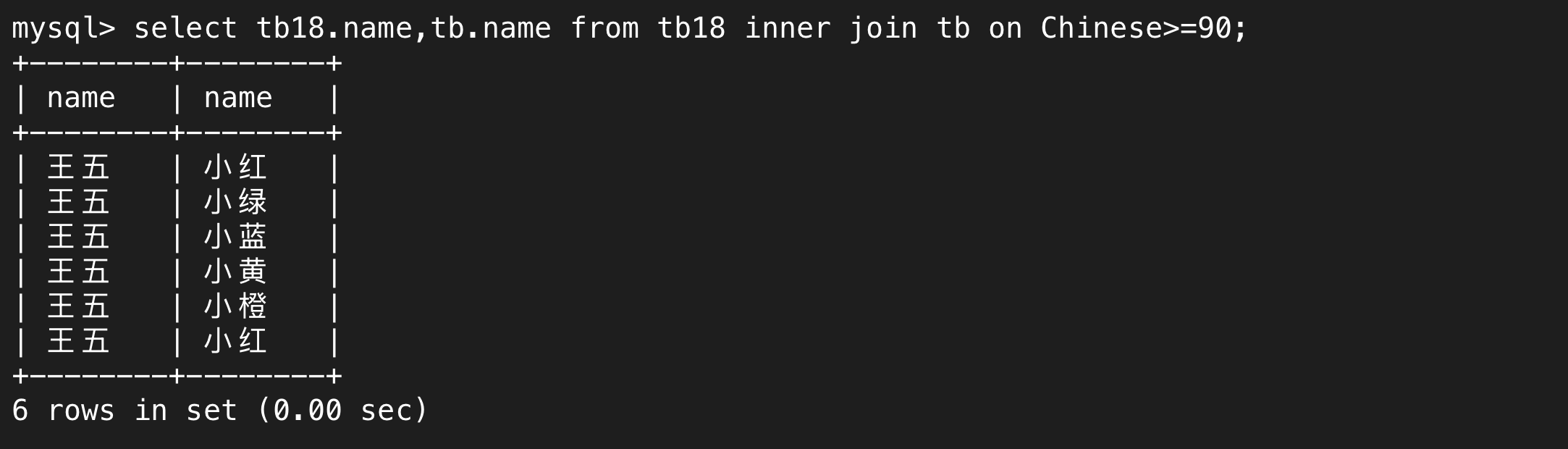
上述講的就是內連接,只不過我們可以省略inner join這個關鍵字。我們還可以寫成join,join默認指的就是內連接,外連接需要完整指定
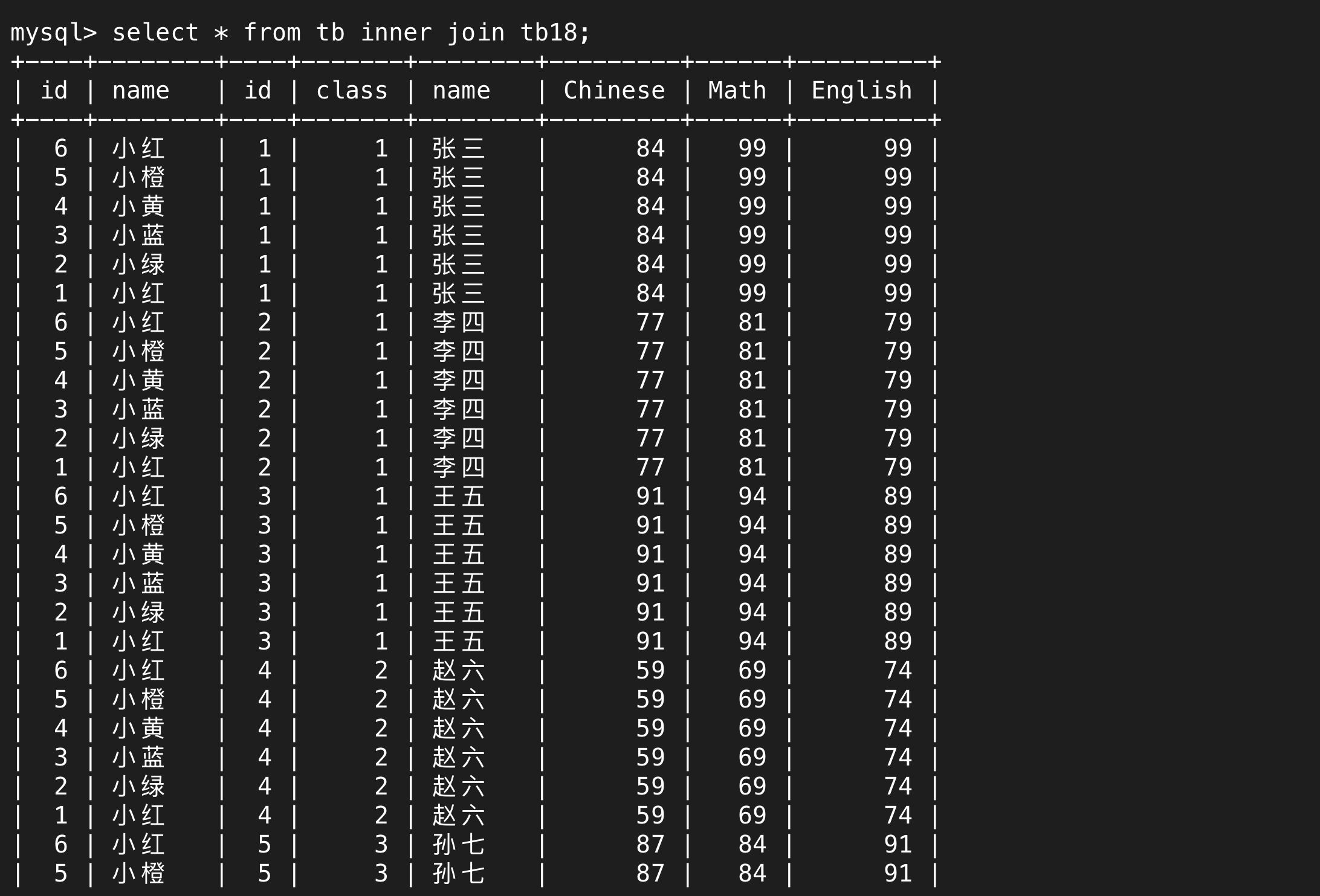
在內外連接且顯式寫了inner join(或left join / right join)的情況下可以用on代替where來進行篩選,on后面就代表關聯條件。
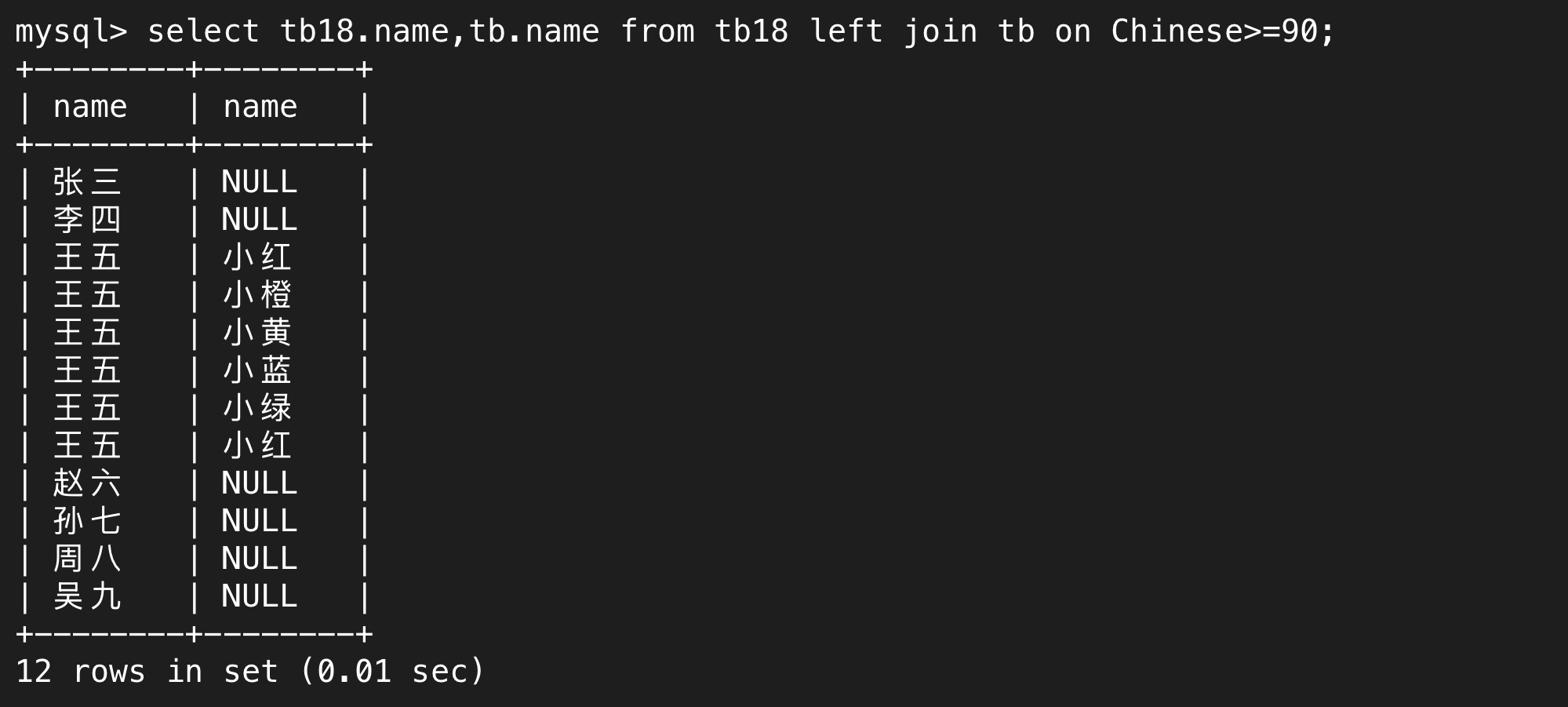
(2)外連接
下面是左外連接,在這張表中,左邊這張表(tb18)相關的信息永遠會完全展示,如張三、李四……吳九,如果滿足篩選條件的會進一步展示,就是圖中的王五,其它的人的右邊表的相關信息都是NULL。
右外連接就是右邊的表一定全部展示完,左邊的不符合要求的會顯示NULL。
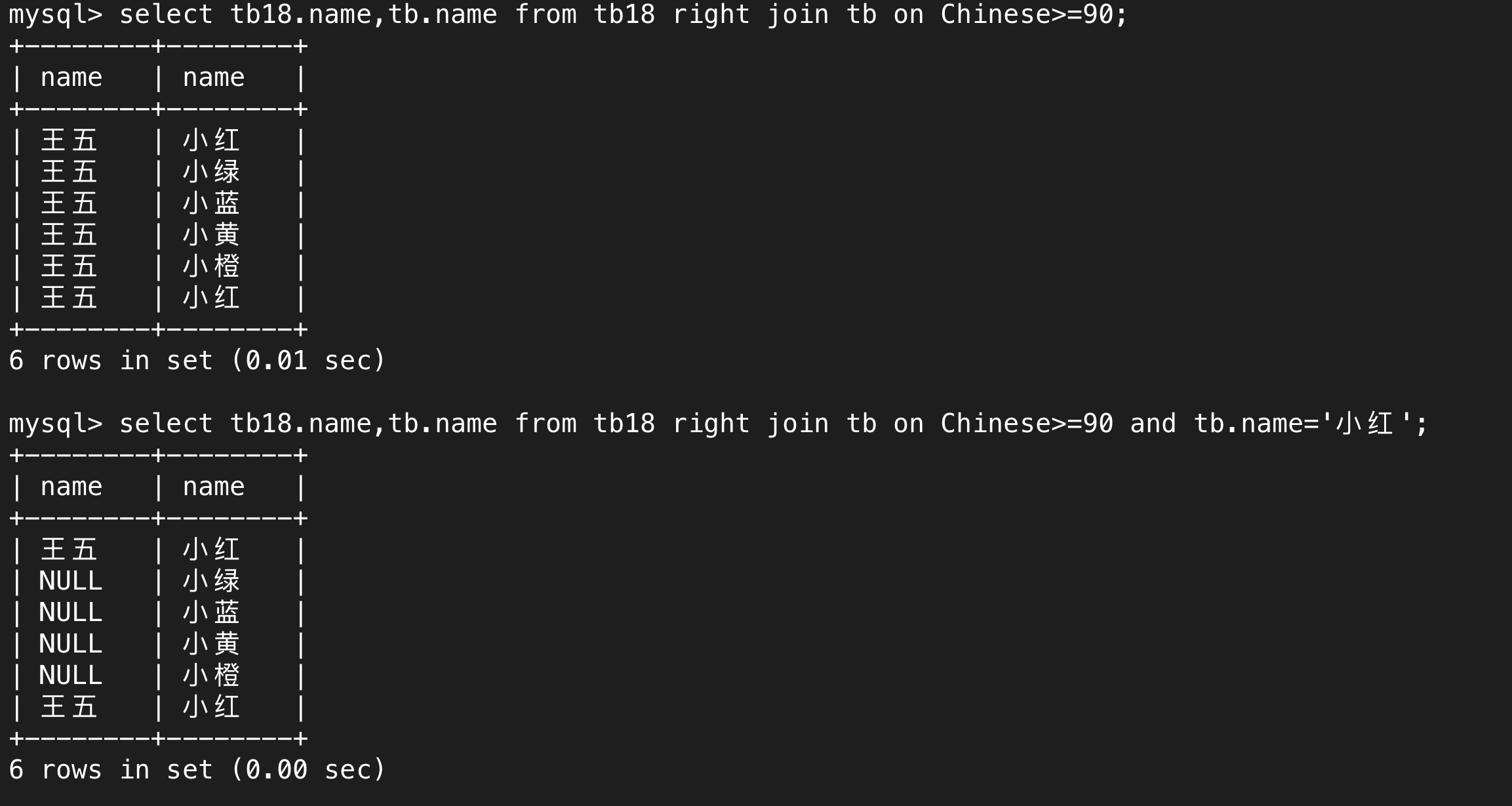
(3)內外連接的區別
下圖的篩選條件一模一樣,只是內外連接的方式不一樣。
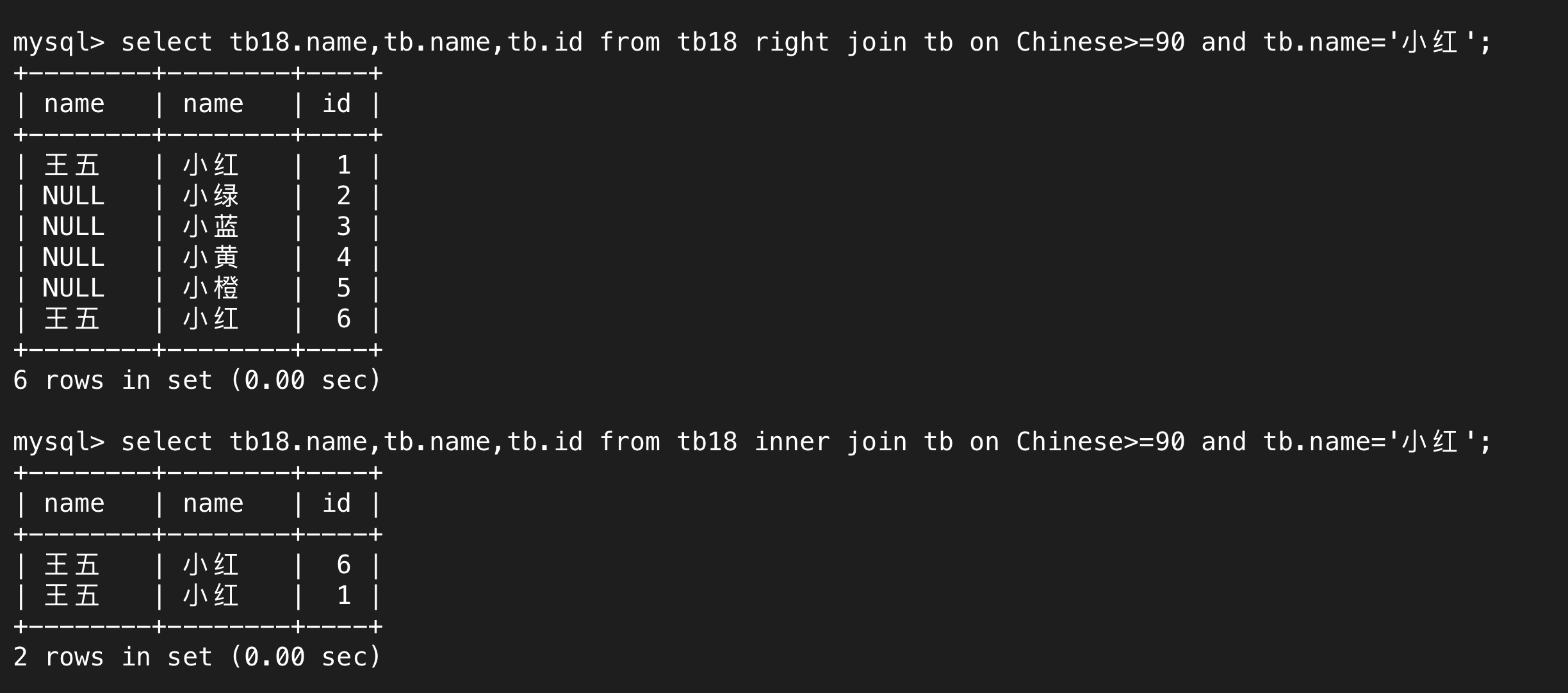
內連接就是先將兩張表進行笛卡爾積,再根據篩選條件展示符合條件的行。外連接就是在內連接的基礎上,根據左外連接和右外連接分別將左邊或右邊表的相關信息展示完全,符合篩選條件的就像內連接那樣正常顯示,不符合要求的行的相關屬性會顯示NULL。
一般情況下使用最多的是內連接,外連接一般在某個表的信息非常關鍵的情況下使用。
(4)自連接
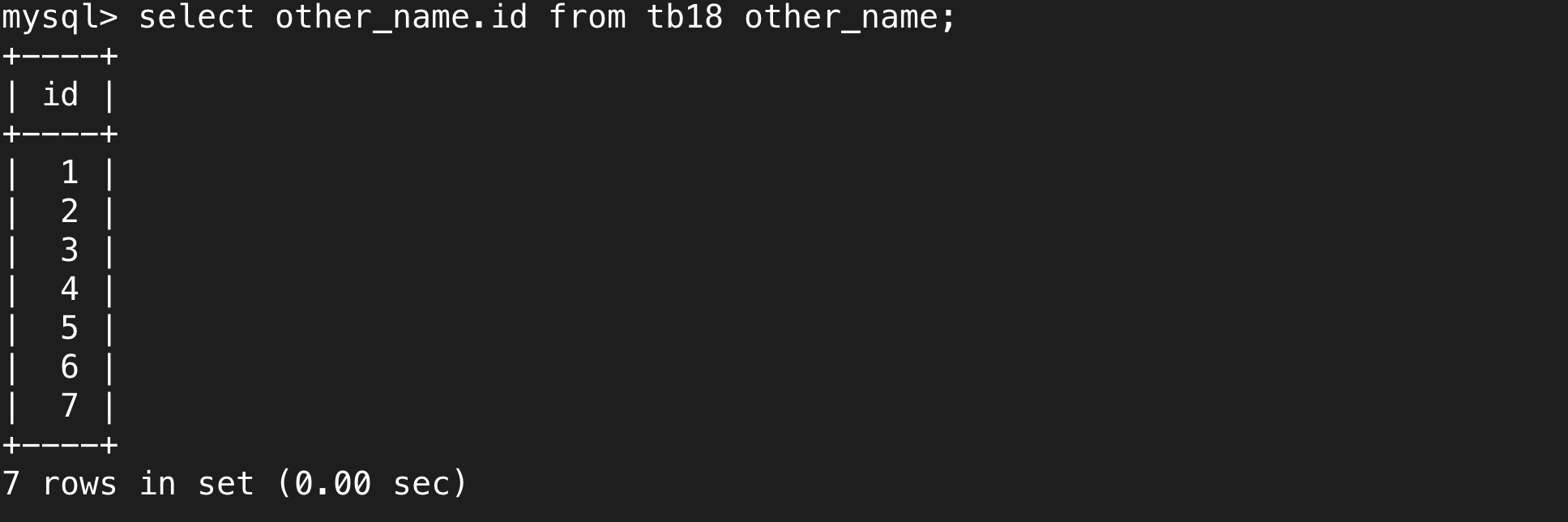
a.給表取別名
下面是對表取別名的用法,根據執行順序,我們可以在select和后面的where中使用新名字。
b.自連接的使用
我們可以內連接兩張表,對每張表取不同的名字,在自連接中,這兩張表是同一張表。
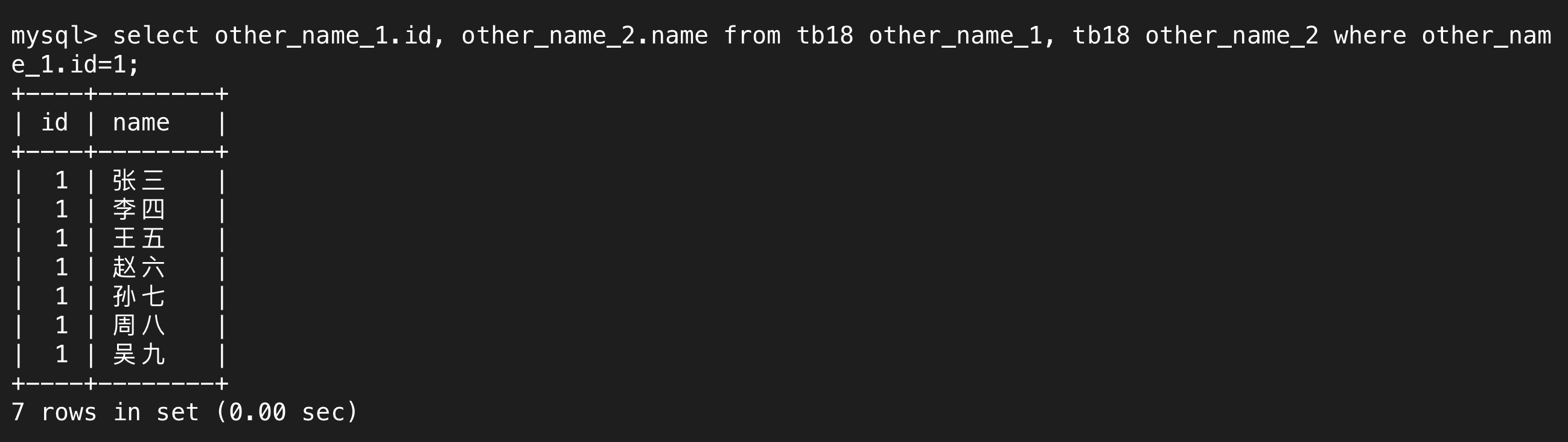
自連接本質上就是內外連接,只不過連接的兩張表是同一張表,然后對每張表取別名用于區分而已。
3.合并查詢
(1)union
union是合并查詢的關鍵字,union前后是兩個獨立的select語句,并且兩個語句的結果取并集,并且兩個語句的結果會被去重,所以下面的語句意思是語文成績>80或者數學成績>70。
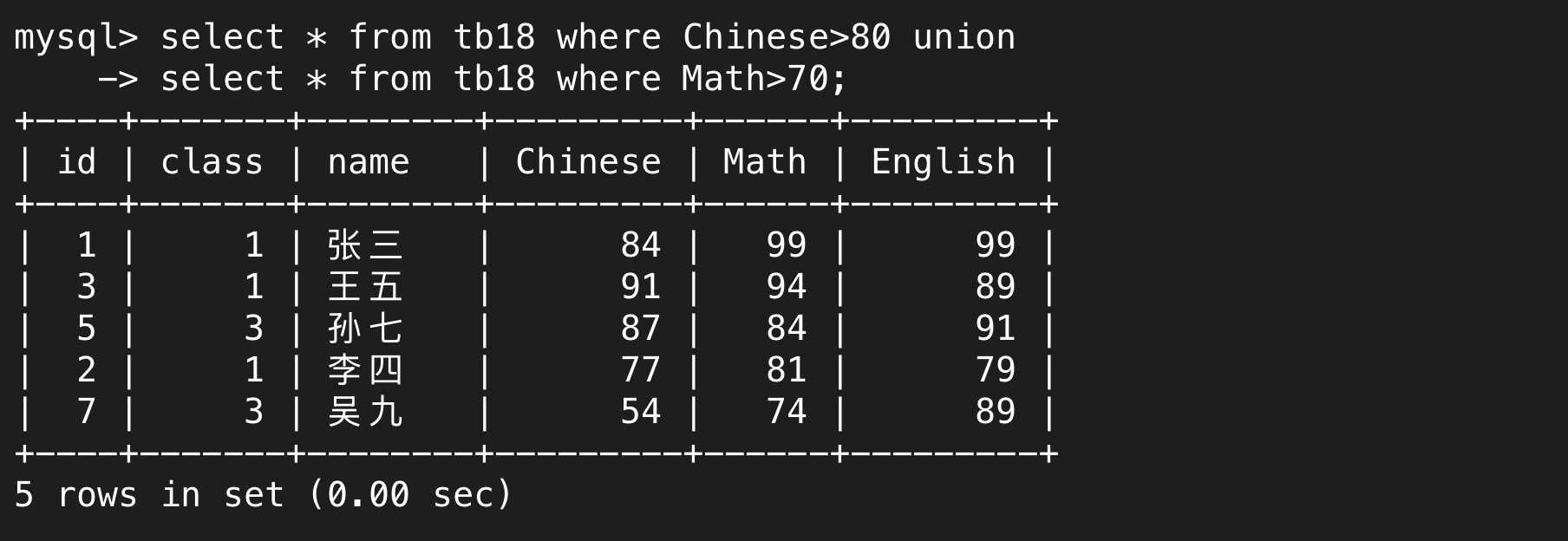
(2)union all
union的基礎上不去重就是union all,也就是說同時滿足union前后兩個語句的結果會出現兩次。
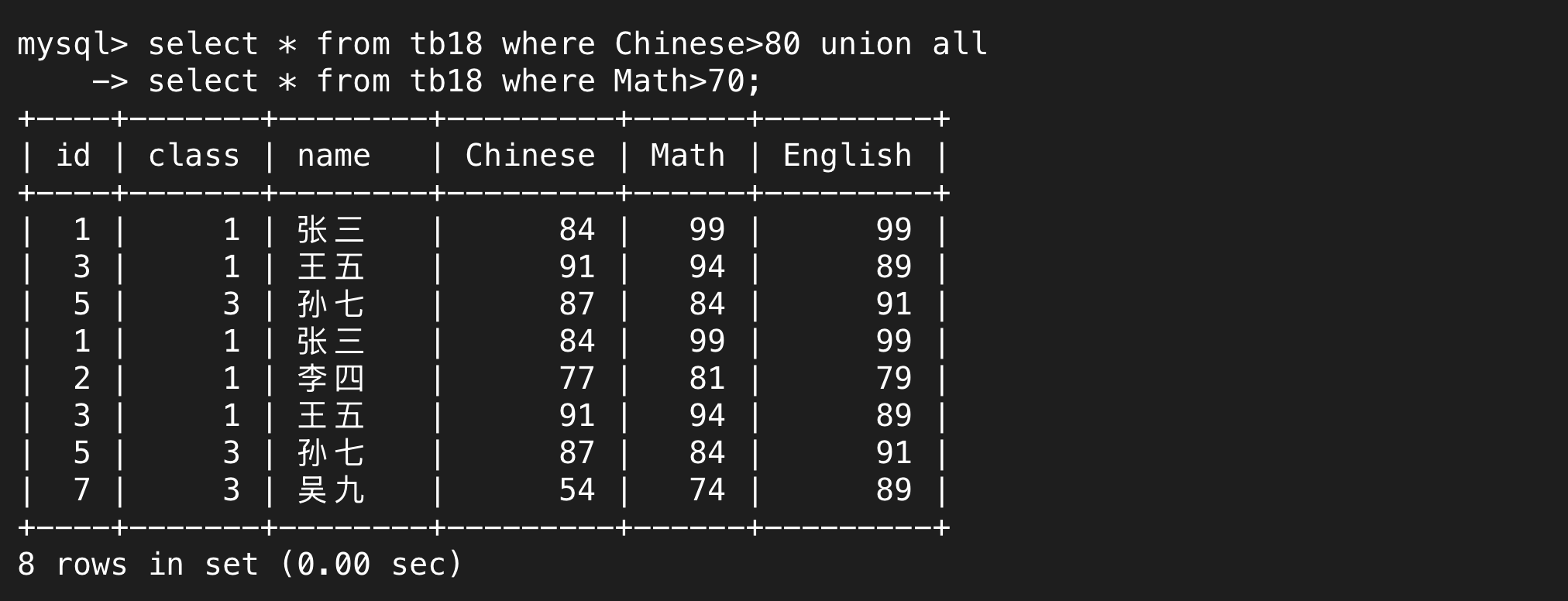
4.子查詢(嵌套查詢)
子查詢指的是在where子句中使用select語句的結果作為值,即select * from tb where name=(select……)形式,看上去就是在一個select語句里面嵌套另一個select語句,以達到查詢的目的。
(1)單行
單行子查詢中“單行”指的是返回的結果是一行,單行結果中列名不占一行。
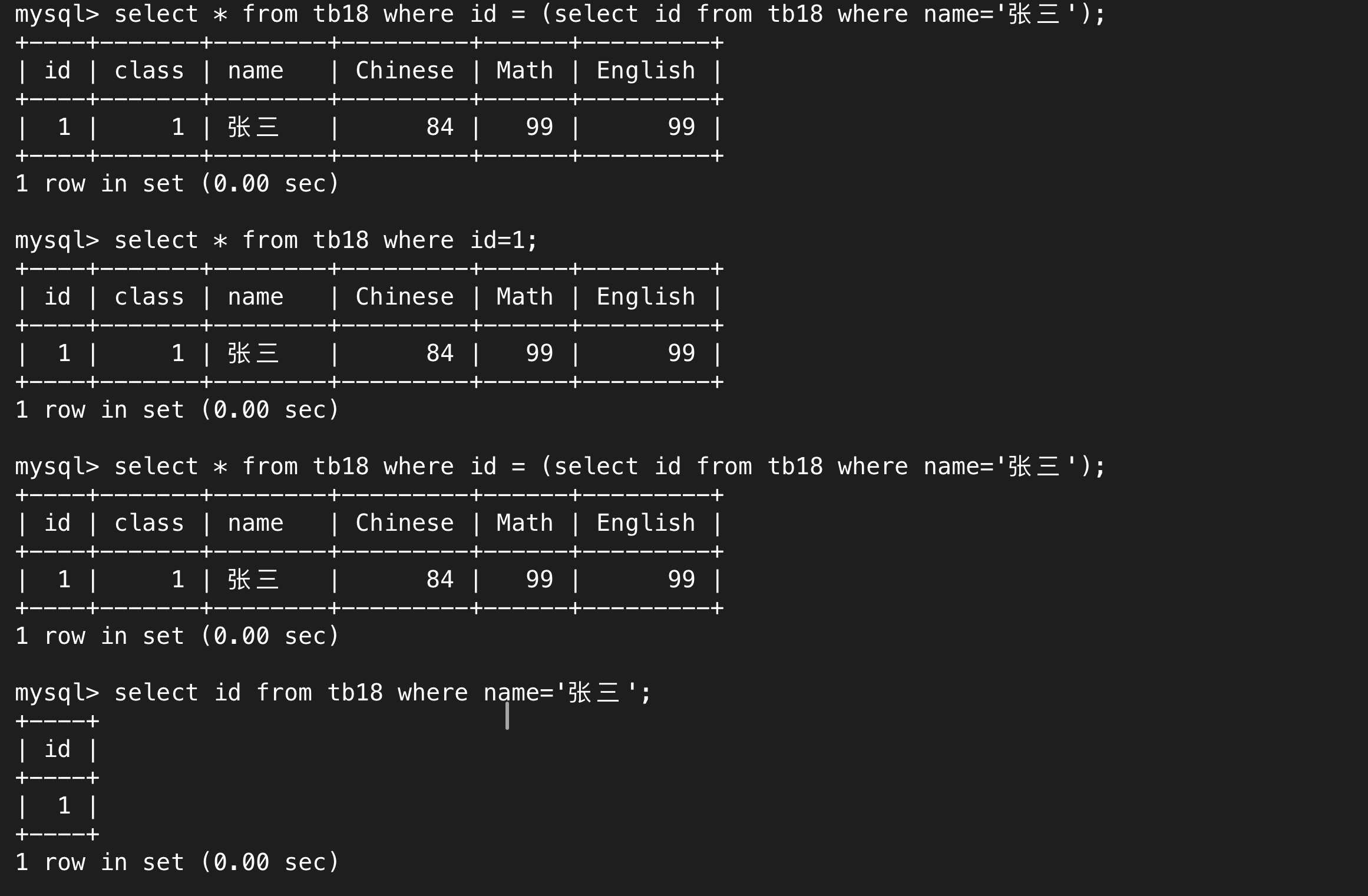
(2)多行
多行子查詢指的是返回結果是多行的。
a.in
select 得到的多行的結果,直接用=接收顯然是不夠的,用in就可以接受多行數據,在下圖中指的就是id在selcet語句的執行結果中就符合條件,這個子select的執行結果是多個數字,在這里指的就是大于3的數字。
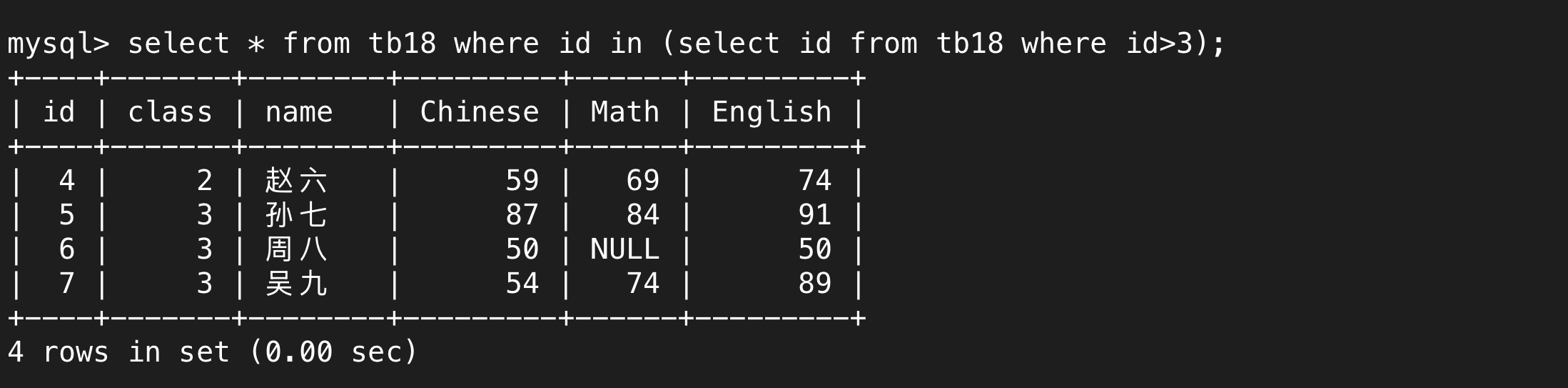
b.all
在這里id > all(select……)指的是select返回多行數據,再拿著多行數據中的每個數據對匹配id > 該數據,最后取交集就是結果

下面的語句中,是對select中的每個數據單獨比較id <= 該數據,再取交集。上一張圖中相當于和最大值進行比較,這里是對最小值進行比較。

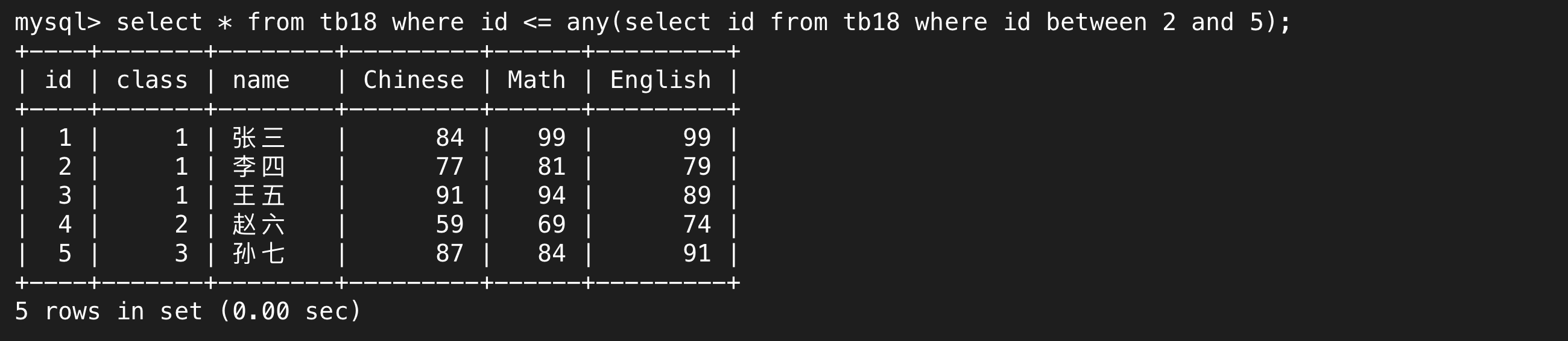
c.any
和all不同,all表示的是和所有數據單獨比較,最后取一個交集;any也是和所有數據單獨做比較,最后取并集。
體現在語句中,id > all表示比select結果中最大的還要大,id > any表示比select結果中最小的還要大;id < all中表示比select結果中最小的還要小,id < any表示比select結果中最大的還要小,分清這個邏輯是最重要的。
(3)多列單行
在上面的例子中,最大的特點就是子select中只顯示一列數據,我們也可以設定成多列的。

在上面的這個例子中,是根據兩列單行的值進行篩選的,篩選時要使用(列名1, 列名2)和等號來進行匹配。
(4)多列多行
mysql也支持多列多行的子查詢,其含義和單列的一樣

不過mysql不支持在多列多行中使用any和all,需要我們自己拆分成單列的情況才行。

(5)from中使用臨時表
經過這么久的學習,我們需要意識到每一次操作返回的結果本質上都是一張表,無論是單列也好還是多列也好,單行還是多行,都是這樣。每一個select語句執行的結果就是一張表,所以我們可以將select執行的結果放進from語句后面。
我們還可結合對表取別名的用法,簡化書寫。
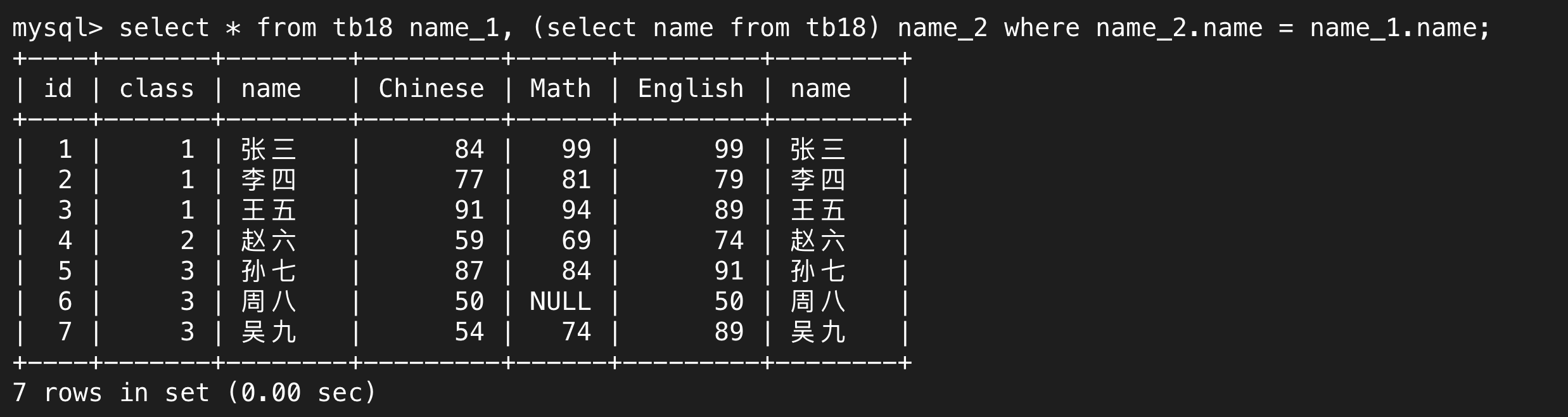
單獨使用select name from tb18;得到的就是個完整的表,只不過這個表是臨時的,我們要仔細體會MySQL中的每一步操作本質上都是生成一張表這個道理。
(6)with的使用
with的作用和from后面跟select語句的作用一樣,都是構建一個臨時表進行使用,只不過如果要更多的使用臨時表,可以統一提到最前面用with來提高易讀性。
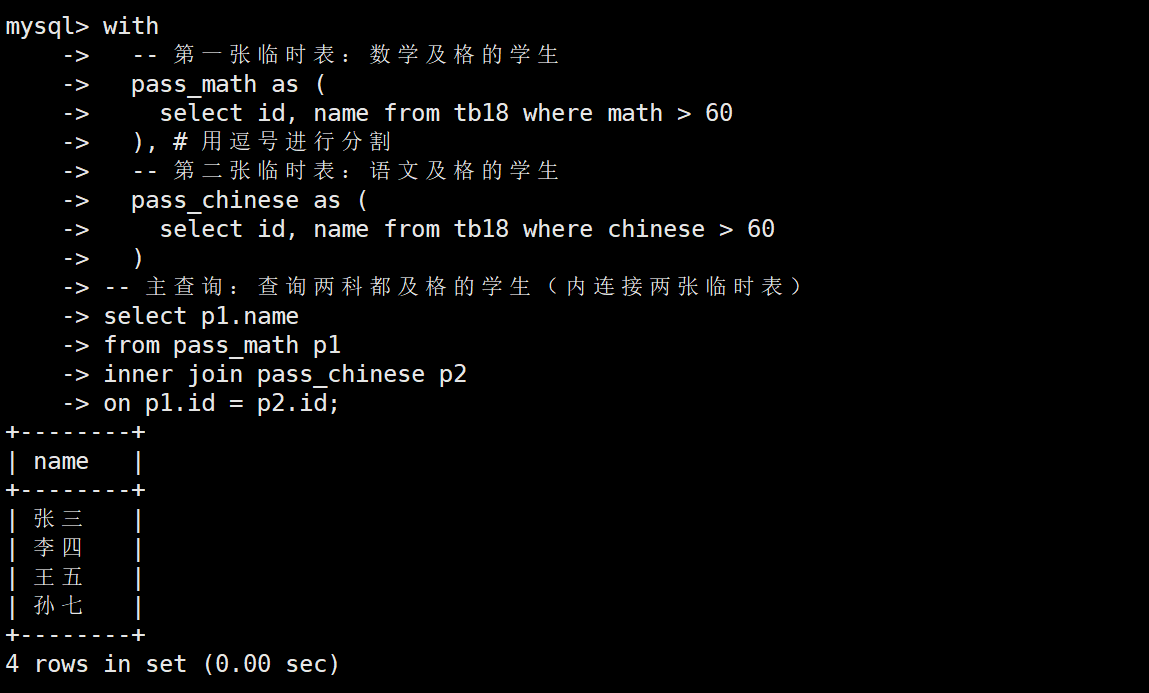
下面這個例子要實現的功能是找到數學、語文都及格的學生
with -- 第一張臨時表:數學及格的學生pass_math as (select id, name from tb18 where math > 60), # 用逗號進行分割-- 第二張臨時表:語文及格的學生pass_chinese as (select id, name from tb18 where chinese > 60)
-- 主查詢:查詢兩科都及格的學生(內連接兩張臨時表)
select p1.name
from pass_math p1
inner join pass_chinese p2
on p1.id = p2.id;
5.select各個關鍵字的執行順序
with > from + join + on > where > select + distinct > group by + having > order by + limit
上述關鍵詞都已經介紹過了,下面將舉一個完整的例子來說明其執行順序。
-- 目的是獲得一張成績全部都有效的學生表
with stu as (select # 最后執行 select,是對臨時表的結果進行展示id as stu_id,class as class_id,name as stu_namefrom tb18 # 先執行 from,意味從 tb18 中獲得原始數據where Math is not null and # 再執行 where,是對原始數據進行行篩選Chinese is not null andEnglish is not null
)
-- 主查詢會使用臨時表
select distinct stu.stu_id as id, teacher.name as teacher_name, stu.stu_name as student_name
from stu inner join tb as teacher on stu.stu_id = teacher.id # 將臨時學生表和教師表按照關聯條件連接在一起形成原始數據,在這個例子中認為學生id和教師id一一對應
where stu.stu_id > 2 # 在原始數據之上用where進行行篩選
group by id # 根據教師的編號進行分組
having id > 1 # 對分組后的數據進行篩選
order by id desc
limit 2;
以下是執行的結果
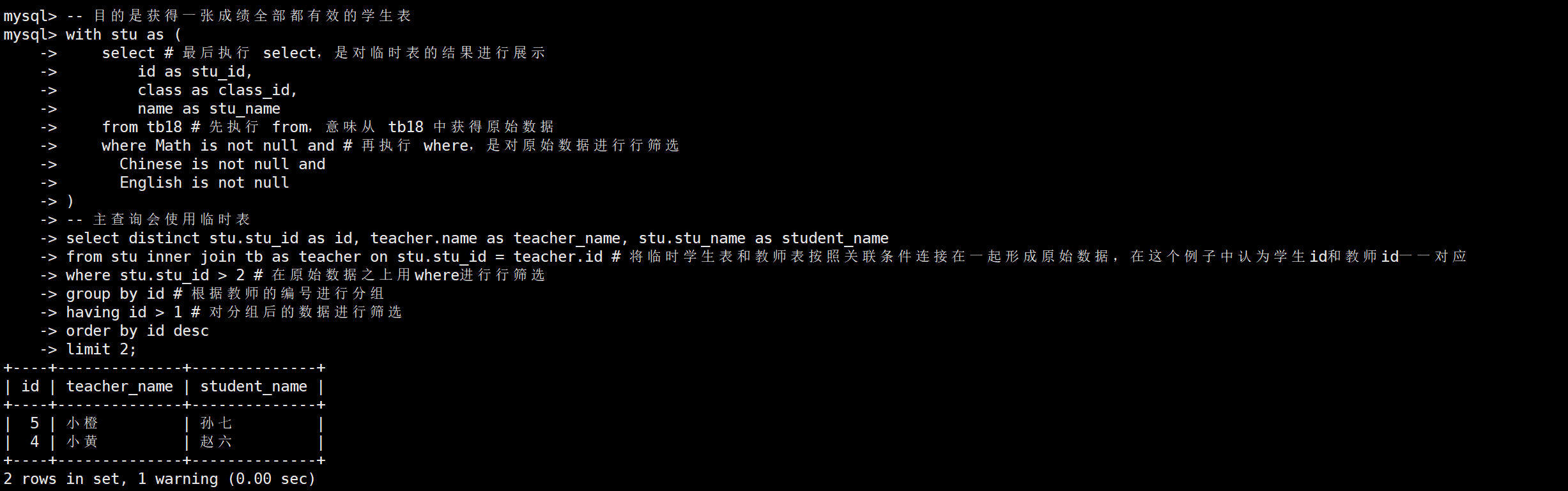
首先,with是最先執行的,用于提供臨時表數據,以便后續和from進行連接。
其次,from、join、on是緊挨著執行的,on必須跟在join后面才行,作為關聯條件。這三個關鍵詞是將我們需要的表按照on關聯規則連接起來形成一個原始數據表,后續的所有操作都是在這個原始數據表上進行的。我們對表取的別名可以用在后面語句上。
然后,就是where子句,是對原始數據進行行篩選,在這里可以用上表的別名了。
之后,在MySQL中執行select并對列明取別名,這個語句執行完就有初步的結果了,distinct會對這個結果根據需要展示的列進行去重,不展示的列不在去重考慮范圍內。有的SQL中select是在分組后進行的,這導致那種情況下分組時無法使用列的別名。
之后,便是分組,根據分組參照對象值的不同分成不同組,使用它需要我們使用聚合函數或者能和分組參照對象的值形成一一對應的列來作為select的列,having就是在分組之后進行進一步篩選。
最后用order by和limit進行展示上的限制。



協議的全面解析:理論、機制與實踐局限性)


![[SC]SystemC 常見的編譯/語法錯誤與解法(三)](http://pic.xiahunao.cn/[SC]SystemC 常見的編譯/語法錯誤與解法(三))



)



)




