init中的參數的作用
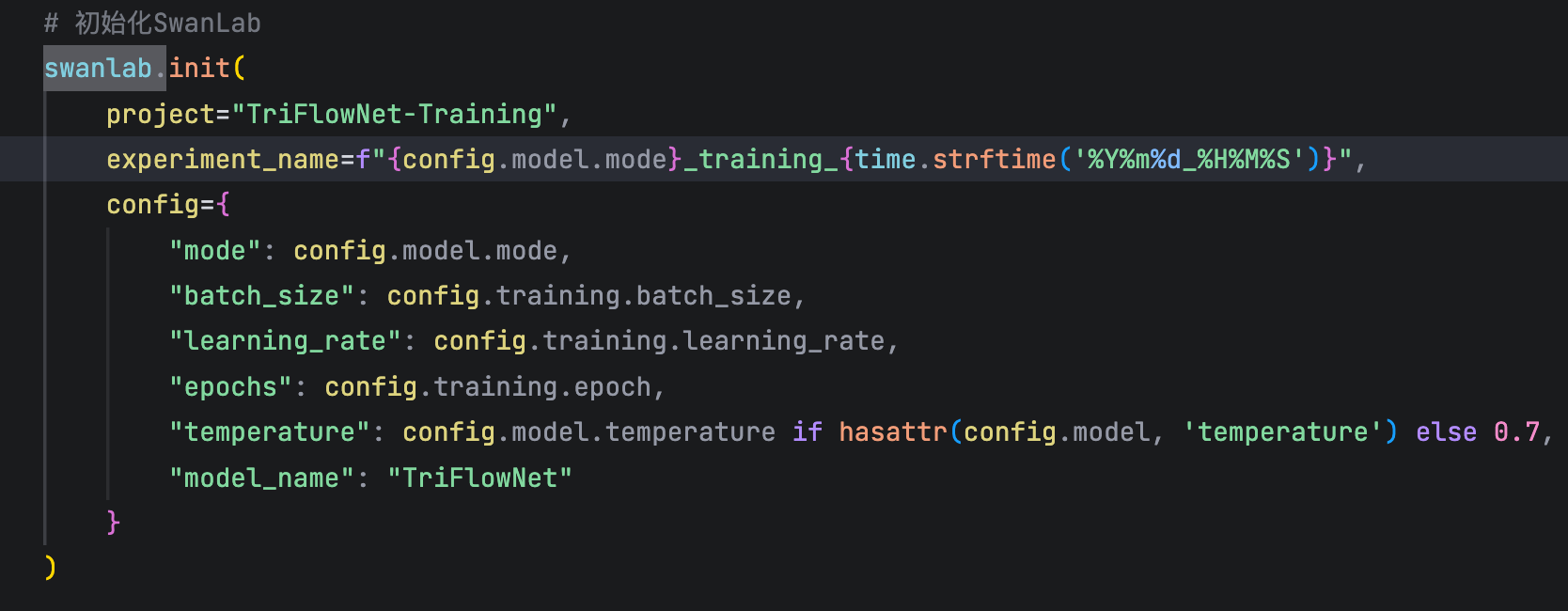
-
project:整個實驗的名字; -
experiment_name:在這個實驗中,你的名字是什么;- 比如說現在我們要進行對比實驗,
PEAN和Triflownet分別是對比方法的名字,這樣的好處是,她們可以出現在一樣的圖中直接進行對比;
- 比如說現在我們要進行對比實驗,
-
config:關于這個實驗,你需要標記的參數名字,如: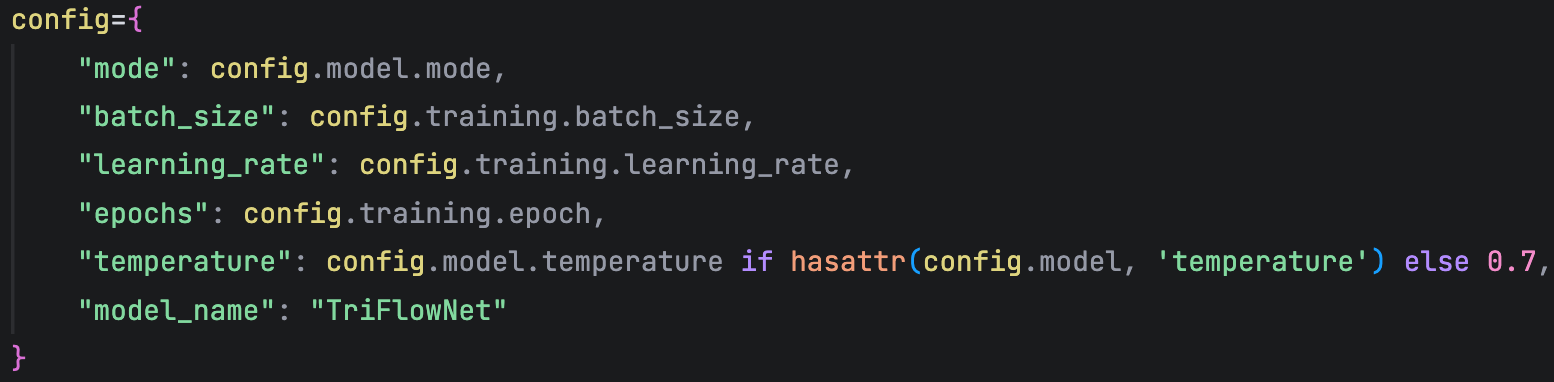

給相同屬性的變量分組
如:
# 記錄epoch指標到SwanLabswanlab.log({"loss/avg_train_loss": avg_train_loss,"accuracy/avg_train_accuracy": avg_train_acc,"loss/avg_dev_loss": dev_loss,"accuracy/avg_dev_accuracy": dev_acc,"learning_rate": optimizer.param_groups[0]['lr'],"epoch_time": epoch_time})
如果都是loss就都分到loss組,效果如下,這樣看起來不會那么混亂:
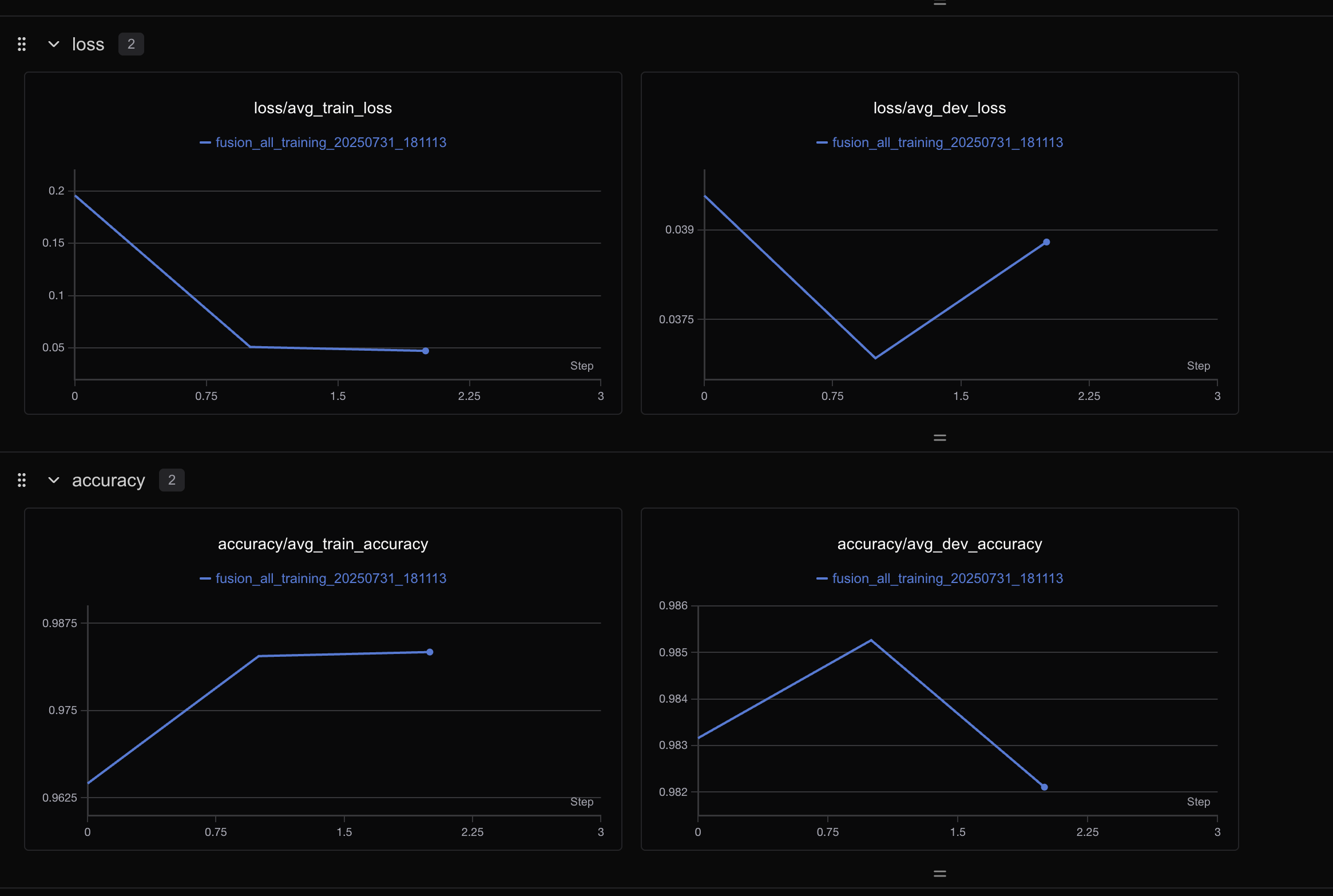
不同模型方法對比實驗
-
project:整個實驗的名字; -
experiment_name:相應模型的名字; -
config:關于這個實驗,你需要標記的參數名字; -
swanlab.log:swanlab.log({"loss/avg_train_loss": avg_train_loss,"accuracy/avg_train_accuracy": avg_train_acc,"loss/avg_dev_loss": dev_loss,"accuracy/avg_dev_accuracy": dev_acc,"learning_rate": optimizer.param_groups[0]['lr'],"epoch_time": epoch_time})其中每個參數都會產生一個圖,如:avg_train_loss,圖中有每個方法的折線,可以清晰展示不同方法之間的區別;
容器與模塊化工作原理)
:文法+單詞)


)


)
)




)





