
已在GitHub開源與本博客同步的ResNet50v2_RK3588_Classificationt項目,地址:https://github.com/A7bert777/ResNet50v2_RK3588_Classification
詳細使用教程,可參考README.md或參考本博客第八章 模型部署
文章目錄
- 一、項目回顧
- 二、模型選擇介紹
- 三、文件梳理
- 四、文件及環境配置
- 五、模型訓練
- 六、PT轉ONNX
- 七、ONNX轉RKNN
- 八、模型部署
一、項目回顧
博主之前有寫過YOLO11、YOLOv8目標檢測&圖像分割、YOLOv10目標檢測、MoblieNetv2圖像分類的模型訓練、轉換、部署文章,感興趣的小伙伴可以了解下:
【YOLO11部署至RK3588】模型訓練→轉換RKNN→開發板部署
【YOLOv10部署RK3588】模型訓練→轉換rknn→部署流程
【YOLOv8-obb部署至RK3588】模型訓練→轉換RKNN→開發板部署
【YOLOv8-pose部署至RK3588】模型訓練→轉換RKNN→開發板部署
【YOLOv8部署至RK3588】模型訓練→轉換rknn→部署全流程
【YOLOv8seg部署RK3588】模型訓練→轉換rknn→部署全流程
【MobileNetv2圖像分類部署至RK3588】模型訓練→轉換rknn→部署流程
YOLOv8n部署RK3588開發板全流程(pt→onnx→rknn模型轉換、板端后處理檢測)
二、模型選擇介紹
近期需要做一個針對分類圖像的模型,并部署到RK3588公版的開發板上,可選擇的有YOLOv8、ResNet50、MobileNet…
而瑞芯微的部署demo:rknn_model_zoo中可以看到,并沒有yolov8的圖像分類demo,只有ResNet和MobileNet的demo。因此為了省事,就按照瑞芯微的方法來,看了下其官網ONNX模型示例的大小,ResNet比MobileNet大了一個數量級,根據經驗,肯定模型越小運行速度越快,而MobileNet的部署流程已經在之前的博客中展示過了,大家可以去看之前博主的相關文章。最近沒事做了個指示燈亮滅的ResNet50的圖像分類項目,涉及模型訓練、轉ONNX、轉RKNN量化以及RK3588開發板調試部署,查了下CSDN上暫未有關于ResNet在RK系列開發板的免費詳細教程,遂開此文,相互學習。
三、文件梳理
Resnet50的訓練、轉換、部署所需四個項目文件:
第一個:train050.py和pt2onnx.py(下文中會給詳細的腳本內容);
第二個:用于在虛擬機中進行onnx轉rknn的虛擬環境配置項目文件(鏈接在此);
第三個:在開發板上做模型部署的項目文件(鏈接在此)。
注:
1.第三個項目文件中的內容很多,里面涉及到rknn模型轉換以及模型部署的所有內容,所以該文件在模型轉換中也要與第三個文件配合使用。
版本如下:
第二個文件rknn-toolkit2為v2.1.0
第三個文件rknn_model_zoo也用v2.1.0(rknn-toolkit2盡量和rknn_model_zoo版本一致)
如圖所示:
下面進入正題,先開始模型訓練的必要準備。
四、文件及環境配置
由于ResNet50結構較為簡單,且圖像分類也沒有目標檢測的復雜后處理流程,因此訓練ResNet50所需要的文件很少,不同于以前訓練YOLO系列模型的繁瑣流程。
以下是訓練所用腳本:
其中train_050.py的內容如下所示:
import torch # 導入PyTorch庫,用于深度學習
from torchvision import datasets, models, transforms # 導入torchvision中的數據集、模型和圖像轉換模塊
import torch.nn as nn # 導入PyTorch的神經網絡模塊
import torch.optim as optim # 導入PyTorch的優化器模塊
from torch.utils.data import DataLoader # 導入DataLoader,用于批量加載數據
import time # 導入時間模塊,用于計算訓練時間import numpy as np # 導入NumPy庫,用于數值計算
import matplotlib.pyplot as plt # 導入Matplotlib庫,用于繪圖
import os # 導入操作系統模塊,用于處理文件路徑
from tqdm import tqdm # 導入tqdm模塊,用于顯示進度條image_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)), # 隨機裁剪并調整大小為256x256transforms.RandomRotation(degrees=15), # 隨機旋轉15度transforms.RandomHorizontalFlip(), # 隨機水平翻轉#transforms.CenterCrop(size=224), # 中心裁剪為224x224transforms.CenterCrop(size=112),transforms.ToTensor(), # 將圖像轉換為Tensortransforms.Normalize([0.485, 0.456, 0.406], # 歸一化,使用ImageNet的均值和標準差[0.229, 0.224, 0.225]) ]),'valid': transforms.Compose([transforms.Resize(size=256), # 調整大小為256x256#transforms.CenterCrop(size=224), # 中心裁剪為224x224transforms.CenterCrop(size=112),transforms.ToTensor(), # 將圖像轉換為Tensortransforms.Normalize([0.485, 0.456, 0.406], # 歸一化,使用ImageNet的均值和標準差[0.229, 0.224, 0.225])])
}# 三、加載數據
# torchvision.transforms包DataLoader是 Pytorch 重要的特性,它們使得數據增加和加載數據變得非常簡單。
# 使用 DataLoader 加載數據的時候就會將之前定義的數據 transform 就會應用的數據上了。
dataset = 'xxx' # 數據集名稱
train_directory = '/xxx/train' # 訓練集路徑
valid_directory = '/xxx/val' # 驗證集路徑batch_size = 128 # 批量大小
num_classes = 2 #分類種類數
print(train_directory) # 打印訓練集路徑
print(valid_directory) # 打印驗證集路徑data = { 'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']), # 加載訓練集'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid']) # 加載驗證集
}# 打印訓練集類別及其對應編號
print("訓練集圖片類別及其對應編號(種類名:編號):",data['train'].class_to_idx)
print("測試集圖片類別及其對應編號:",data['valid'].class_to_idx)train_data_size = len(data['train']) # 訓練集大小
valid_data_size = len(data['valid']) # 驗證集大小train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8) # 訓練集DataLoader
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=8) # 驗證集DataLoader# 打印訓練集和驗證集的大小
print("訓練集圖片數量:",train_data_size, "測試集圖片數量:",valid_data_size)# 四、遷移學習
# 這里使用ResNet-50的預訓練模型。
#resnet50 = models.resnet50(pretrained=True) # 舊版加載預訓練模型的方式
resnet50 = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1) # 加載ResNet-50預訓練模型# 在PyTorch中加載模型時,所有參數的‘requires_grad’字段默認設置為true。這意味著對參數值的每一次更改都將被存儲,以便在用于訓練的反向傳播圖中使用。
# 這增加了內存需求。由于預訓練的模型中的大多數參數已經訓練好了,因此將requires_grad字段重置為false。
for param in resnet50.parameters():param.requires_grad = False # 凍結模型參數,不更新梯度# 為了適應自己的數據集,將ResNet-50的最后一層替換為,將原來最后一個全連接層的輸入喂給一個有256個輸出單元的線性層,接著再連接ReLU層和Dropout層,然后是256 x 6的線性層,輸出為6通道的softmax層。
fc_inputs = resnet50.fc.in_features # 獲取全連接層的輸入特征數
resnet50.fc = nn.Sequential(nn.Linear(fc_inputs, 256), # 全連接層,輸入為fc_inputs,輸出為256nn.ReLU(), # ReLU激活函數nn.Dropout(0.4), # Dropout層,丟棄率為0.4nn.Linear(256, num_classes), # 全連接層,輸入為256,輸出為num_classesnn.LogSoftmax(dim=1) # LogSoftmax層,用于多分類任務
)# 用GPU進行訓練。
resnet50 = resnet50.to('cuda:0') # 將模型移動到GPU# 定義損失函數和優化器。
loss_func = nn.NLLLoss() # 負對數似然損失函數
optimizer = optim.Adam(resnet50.parameters()) # Adam優化器# 五、訓練
def train_and_valid(model, loss_function, optimizer, epochs=25):device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 設置設備history = [] # 用于存儲訓練和驗證的損失和準確率best_acc = 0.0 # 最佳驗證準確率best_epoch = 0 # 最佳驗證準確率對應的epochfor epoch in range(epochs):epoch_start = time.time() # 記錄epoch開始時間print("Epoch: {}/{}".format(epoch+1, epochs)) # 打印當前epochmodel.train() # 設置模型為訓練模式train_loss = 0.0 # 訓練損失train_acc = 0.0 # 訓練準確率valid_loss = 0.0 # 驗證損失valid_acc = 0.0 # 驗證準確率for i, (inputs, labels) in enumerate(tqdm(train_data)): # 遍歷訓練集inputs = inputs.to(device) # 將輸入數據移動到GPUlabels = labels.to(device) # 將標簽數據移動到GPU#因為這里梯度是累加的,所以每次記得清零optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向傳播,計算輸出loss = loss_function(outputs, labels) # 計算損失#print("標簽值:",labels) # 打印標簽值#print("輸出值:",outputs) # 打印輸出值loss.backward() # 反向傳播,計算梯度optimizer.step() # 更新參數train_loss += loss.item() * inputs.size(0) # 累計訓練損失ret, predictions = torch.max(outputs.data, 1) # 獲取預測結果correct_counts = predictions.eq(labels.data.view_as(predictions)) # 計算正確預測的數量acc = torch.mean(correct_counts.type(torch.FloatTensor)) # 計算準確率train_acc += acc.item() * inputs.size(0) # 累計訓練準確率with torch.no_grad(): # 不計算梯度model.eval() # 設置模型為評估模式for j, (inputs, labels) in enumerate(tqdm(valid_data)): # 遍歷驗證集inputs = inputs.to(device) # 將輸入數據移動到GPUlabels = labels.to(device) # 將標簽數據移動到GPUoutputs = model(inputs) # 前向傳播,計算輸出loss = loss_function(outputs, labels) # 計算損失valid_loss += loss.item() * inputs.size(0) # 累計驗證損失ret, predictions = torch.max(outputs.data, 1) # 獲取預測結果correct_counts = predictions.eq(labels.data.view_as(predictions)) # 計算正確預測的數量acc = torch.mean(correct_counts.type(torch.FloatTensor)) # 計算準確率valid_acc += acc.item() * inputs.size(0) # 累計驗證準確率avg_train_loss = train_loss/train_data_size # 計算平均訓練損失avg_train_acc = train_acc/train_data_size # 計算平均訓練準確率avg_valid_loss = valid_loss/valid_data_size # 計算平均驗證損失avg_valid_acc = valid_acc/valid_data_size # 計算平均驗證準確率# 將結果存入historyhistory.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])# 如果當前驗證準確率大于最佳驗證準確率if best_acc < avg_valid_acc:best_acc = avg_valid_acc # 更新最佳驗證準確率best_epoch = epoch + 1 # 更新最佳驗證準確率對應的epoch# 記錄epoch結束時間epoch_end = time.time()# 打印當前epoch的訓練和驗證結果print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start))# 打印最佳驗證準確率及其對應的epochprint("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))# 保存模型torch.save(model, 'models/'+dataset+'_model_'+str(epoch+1)+'.pt')# 返回訓練好的模型和historyreturn model, historynum_epochs = 100 #訓練周期數
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, num_epochs) # 訓練模型
torch.save(history, 'models/'+dataset+'_history.pt') # 保存訓練歷史history = np.array(history) # 將history轉換為NumPy數組
plt.plot(history[:, 0:2]) # 繪制訓練和驗證損失曲線
plt.legend(['Tr Loss', 'Val Loss']) # 設置圖例
plt.xlabel('Epoch Number') # 設置x軸標簽
plt.ylabel('Loss') # 設置y軸標簽
plt.ylim(0, 1) # 設置y軸范圍
plt.savefig(dataset+'_loss_curve.png') # 保存損失曲線圖
plt.show() # 顯示損失曲線圖plt.plot(history[:, 2:4]) # 繪制訓練和驗證準確率曲線
plt.legend(['Tr Accuracy', 'Val Accuracy']) # 設置圖例
plt.xlabel('Epoch Number') # 設置x軸標簽
plt.ylabel('Accuracy') # 設置y軸標簽
plt.ylim(0, 1) # 設置y軸范圍
plt.savefig(dataset+'_accuracy_curve.png') # 保存準確率曲線圖
plt.show() # 顯示準確率曲線圖
pt2onnx.py的完整內容如下所示:
'''
該腳本功能為將訓練好的ResNet50圖像分類模型(PyTorch .pt格式)轉換為ONNX格式(opset_version=12)
在腳本末尾的main函數中直接配置輸入模型路徑、輸出路徑和參數
'''
import torch
import torch.onnxdef convert_pt_to_onnx(pt_model_path, onnx_model_path, input_size=(112, 112), opset_version=12):"""將PyTorch模型轉換為ONNX格式參數:pt_model_path: PyTorch模型文件路徑(.pt)onnx_model_path: 輸出ONNX模型文件路徑(.onnx)input_size: 模型輸入尺寸 (H, W)opset_version: ONNX opset版本"""# 1. 加載PyTorch模型device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = torch.load(pt_model_path, map_location=device)model.eval() # 設置為評估模式# 2. 準備虛擬輸入 (batch_size固定為1)batch_size = 1channels = 3dummy_input = torch.randn(batch_size, channels, *input_size).to(device)# 3. 導出ONNX模型(使用靜態batch_size)torch.onnx.export(model, # 要導出的模型dummy_input, # 模型輸入onnx_model_path, # 輸出文件路徑export_params=True, # 導出模型參數opset_version=opset_version, # 指定opset版本do_constant_folding=True, # 優化常量折疊input_names=['input'], # 輸入節點名稱output_names=['output'], # 輸出節點名稱# 移除dynamic_axes參數以固定batch_size為1)print(f"[成功] 模型已導出到: {onnx_model_path}")print(f"輸入尺寸: {batch_size}x{channels}x{input_size[0]}x{input_size[1]} (靜態batch_size)")print(f"輸出尺寸: {batch_size}x2 (靜態batch_size)")print(f"ONNX opset版本: {opset_version}")if __name__ == "__main__":# 直接配置參數(無需命令行參數)pt_model_path = "./xxx.pt"onnx_model_path = "./xxx.onnx"input_height = 112input_width = 112opset_version = 12# 執行轉換convert_pt_to_onnx(pt_model_path=pt_model_path,onnx_model_path=onnx_model_path,input_size=(input_height, input_width),opset_version=opset_version)
然后是訓練環境:
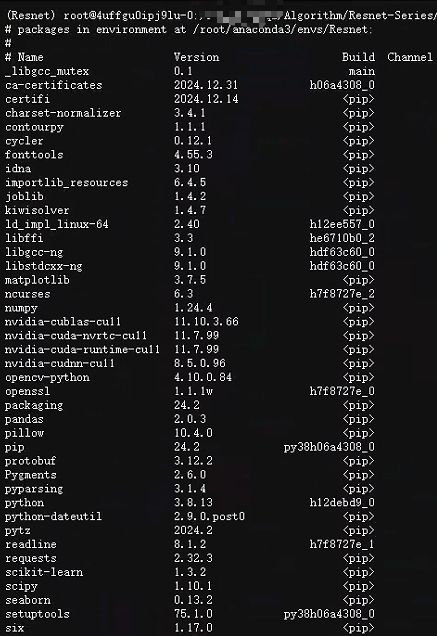
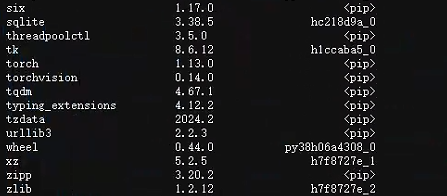
大家可以按照圖中版本自行pip或conda安裝。
五、模型訓練
激活并配置好環境后,直接執行腳本:
python train_050.py
如下所示:

訓練完成后,就能在當前目錄下的model文件夾下看到我們各個epoch得到的模型了:
六、PT轉ONNX
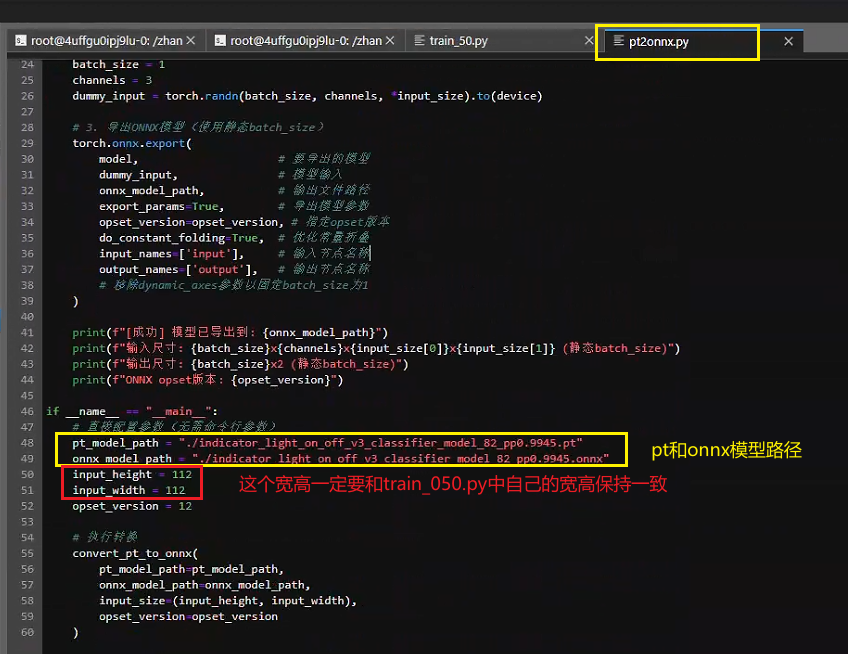
然后根據終端顯示的最優epoch的模型拿出來,使用pt2onnx.py對其進行轉換,注意,要在pt2onnx.py腳本中修改你的pt模型路徑和轉出的onnx模型的保存路徑,如下所示:
然后執行腳本:
python pt2onnx.py
執行后,在終端得到轉換后的onnx模型,onnx模型可用netron工具打開,如下所示:
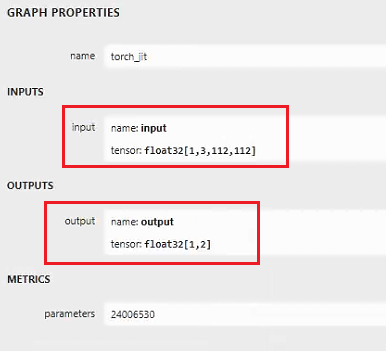
因為我只有兩個類別:on、off,所以輸出就是1,2(1是輸出的batchsize)
七、ONNX轉RKNN
在進行這一步的時候,如果你是在云服務器上運行,請先確保你租的卡能支持RKNN的轉換運行。博主是在自己的虛擬機中進行轉換。
先安裝轉換環境
這里我們先創建環境:
conda create -n rknn210 python=3.8
創建完成如下所示:

現在需要用到rknn-toolkit2-2.1.0文件。
進入rknn-toolkit2-2.1.0\rknn-toolkit2-2.1.0\rknn-toolkit2\packages文件夾下,看到如下內容:

在終端激活環境,在終端輸入
pip install -r requirements_cp38-2.1.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
然后再輸入
pip install rknn_toolkit2-2.1.0+708089d1-cp38-cp38-linux_x86_64.whl
然后,我們的轉rknn環境就配置完成了。
現在要進行模型轉換,其實大家可以參考rknn_model_zoo-2.1.0\examples\ResNet下的README指導進行轉換,先打開rknn_model_zoo下的resnet.py:
進行如下修改:
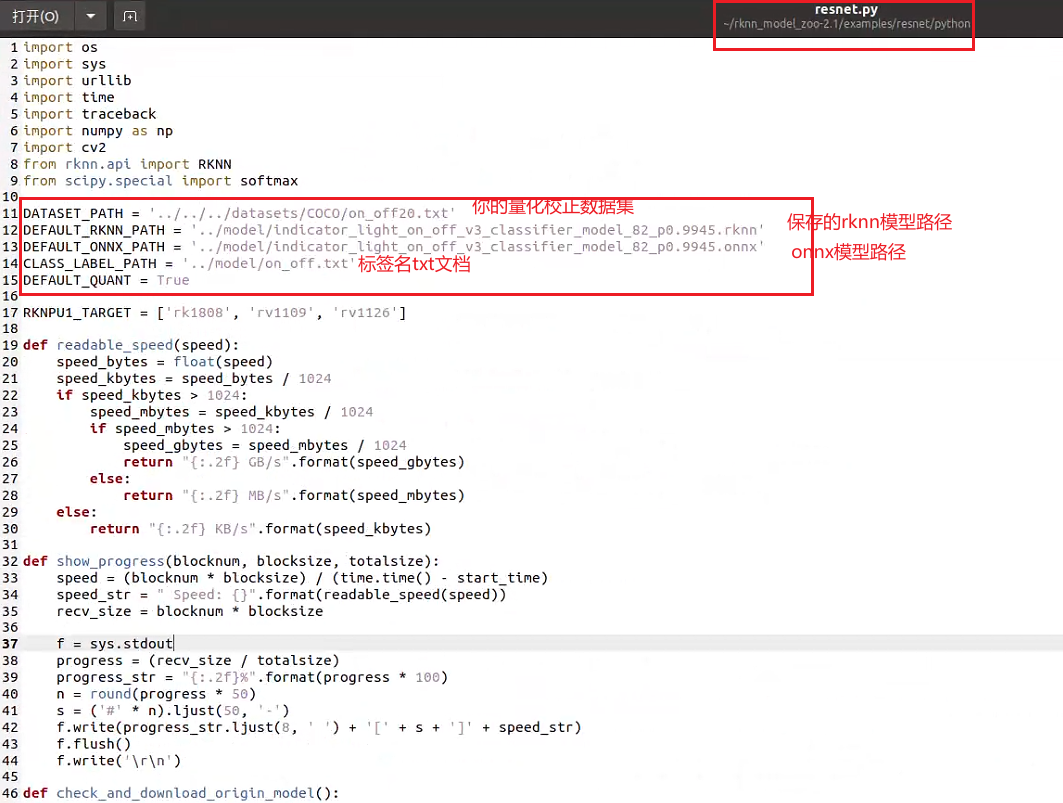
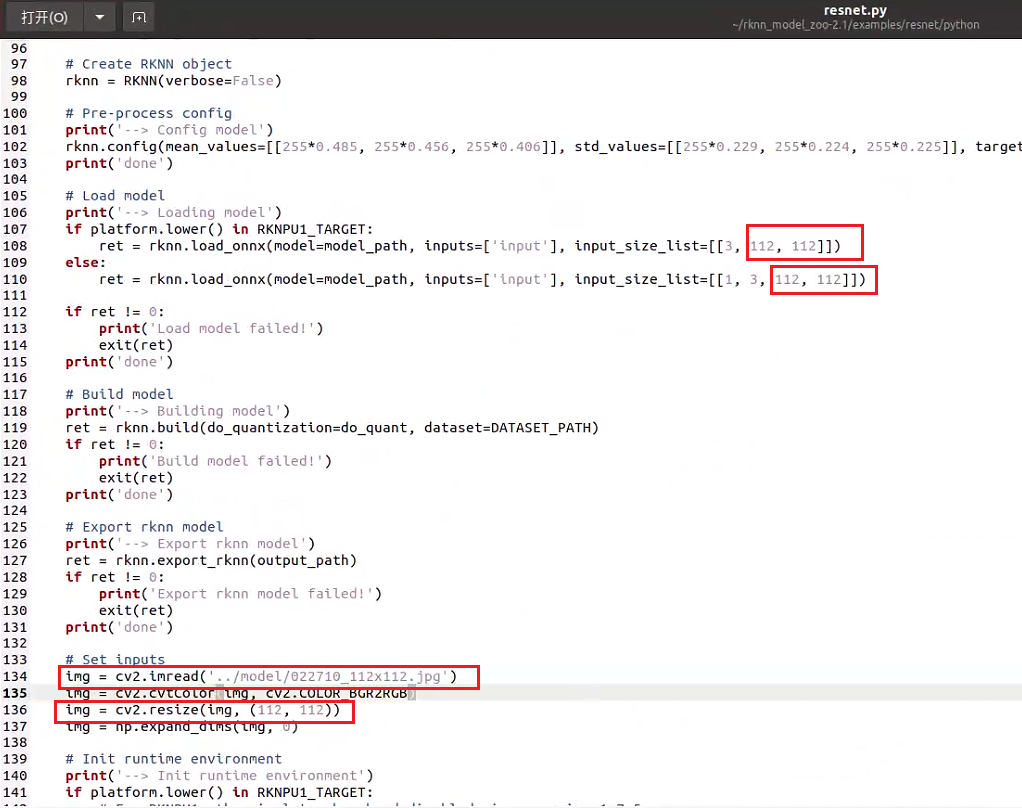
↑注意要把輸入從默認的224改成你自己的size,另外可以在model文件夾下放一張自己的數據集圖片,用來測量量化后的推理效果。
然后在終端執行rknn轉換命令:
python resnet.py ../model/indicator_light_on_off_v3_classifier_model_82_p0.9945.onnx rk3588
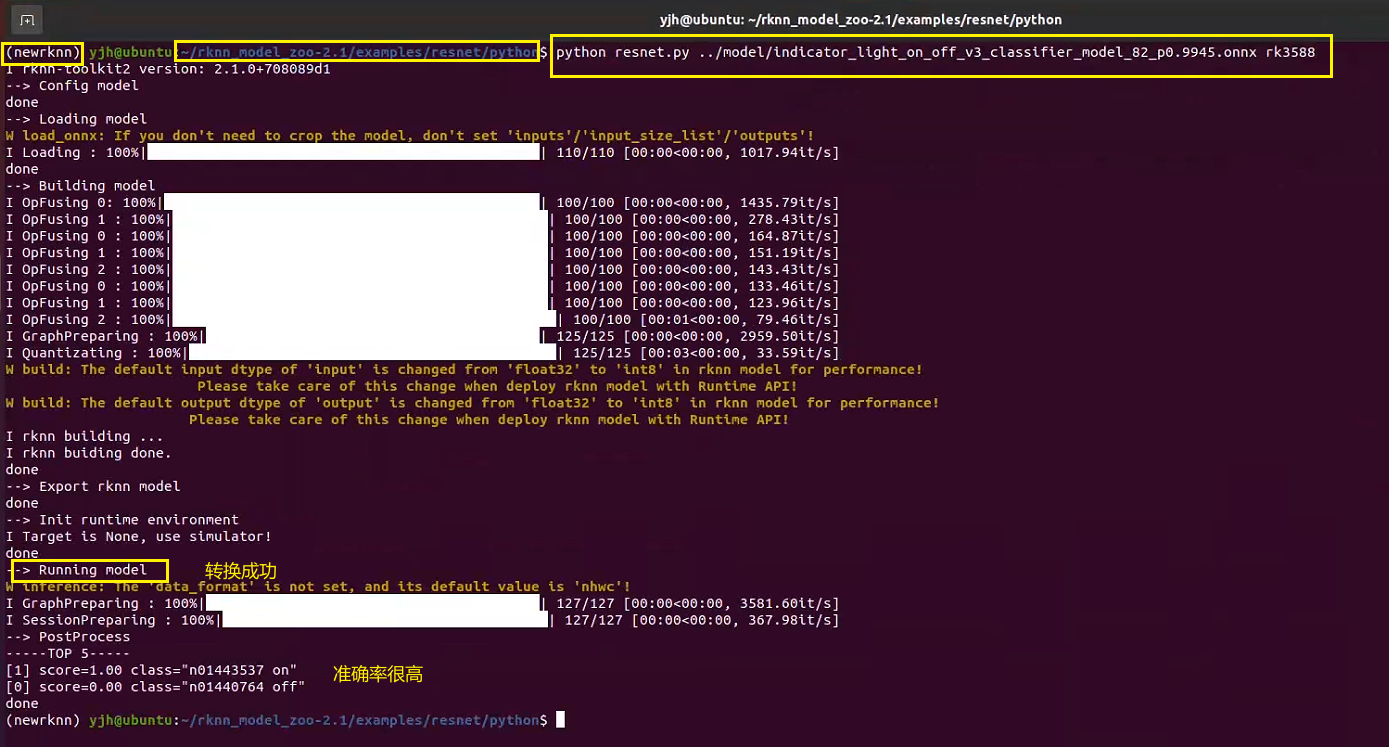
然后在model文件夾下就能看到我們轉換得到的rknn模型了:
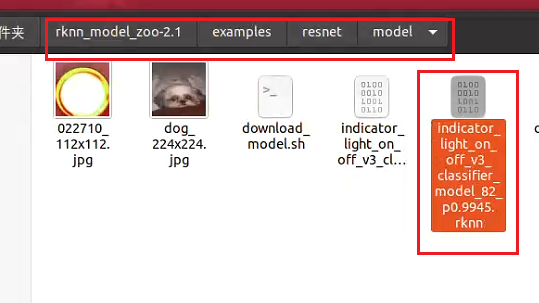
然后將rknn模型復制到win下,用netron打開,如下所示:
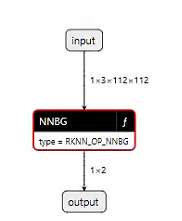
可以看到,模型很簡潔,輸入輸出和onnx是一樣的。
另外可以看到,fp32的onnx模型在轉換成int8的rknn模型后,對比如下所示,模型體積只有單精的四分之一:

八、模型部署
如果前面流程都已實現,模型的結構也沒問題的話,則可以進行最后一步:模型端側部署。
我已經幫大家做好了所有的環境適配工作,科學上網后訪問博主GitHub倉庫:ResNet50v2_RK3588_Classification ,進行簡單的路徑修改就即可編譯運行。
統一聲明:
1、這個倉庫的項目只能做圖片檢測,不支持視頻流檢測,沒時間做這個,有需要的自己修改代碼。
2、從GitHub的README.md中加QQ后直接說問題和小星星截圖,對于常見的相同問題,很多都已在CSDN博客中提到了(RKNN轉換流程是統一的,可去博主所有的RKNN相關博客下去翻評論),已在評論中詳細解釋過的問題,不予回復。
重點:請大家舉手之勞,幫我的倉庫點個小星星
點了小星星的同學可以免費幫你解決轉模型與部署過程中遇到的問題。
注:保密原因,博主此博客的PT、ONNX、RKNN模型均保密不予提供,請大家拿自己的模型進行測試
git clone后把項目復制到開發板上,按如下流程操作:
①:cd build,刪除所有build文件夾下的內容
②:cd src 修改main.cc,修改main函數中的如下四個內容:
把標簽名的txt的路徑改成你自己的路徑:
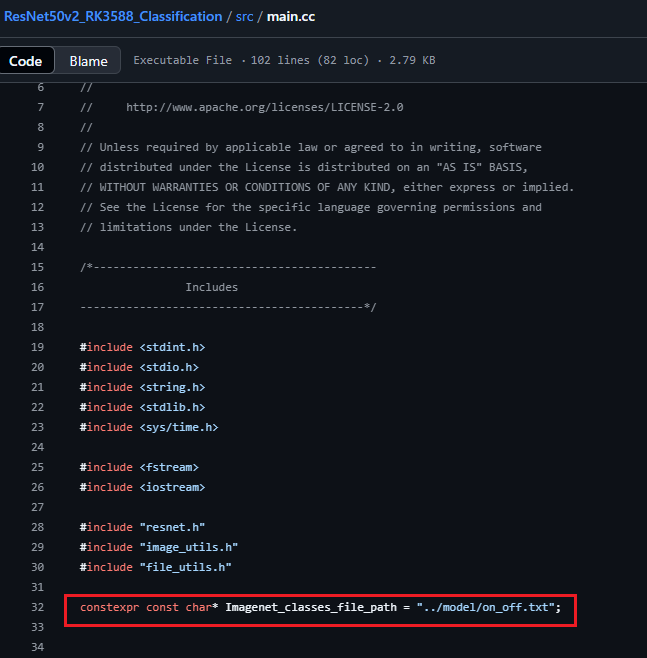
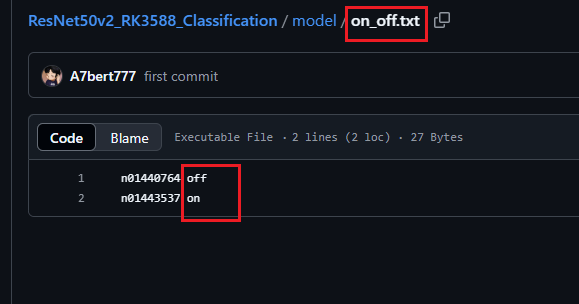
其中txt文檔的內容如下所示,其實就是你在訓練ResNet50v2分類模型時的那幾個類別名(即文件夾名,注意要按個按照文件夾名的先后順序來,不然即便推理得分很高,但類名是錯的)
③:把你之前訓練好并已轉成RKNN格式的模型放到ResNetv2_RK3588_Classification/model文件夾下,然后把你要檢測的所有圖片都放到ResNetv2_RK3588_Classification/inputimage下。
④:進入build文件夾進行編譯
cd build
cmake ..
make
在build下生成可執行文件文件:rknn_resnet50_demo
完整流程如下所示,執行完后即可在build文件夾下看到生成的可執行文件:
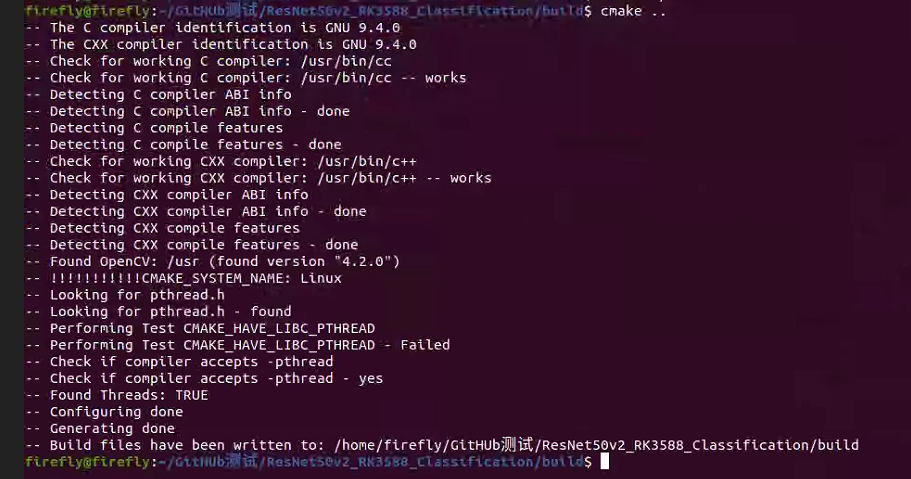
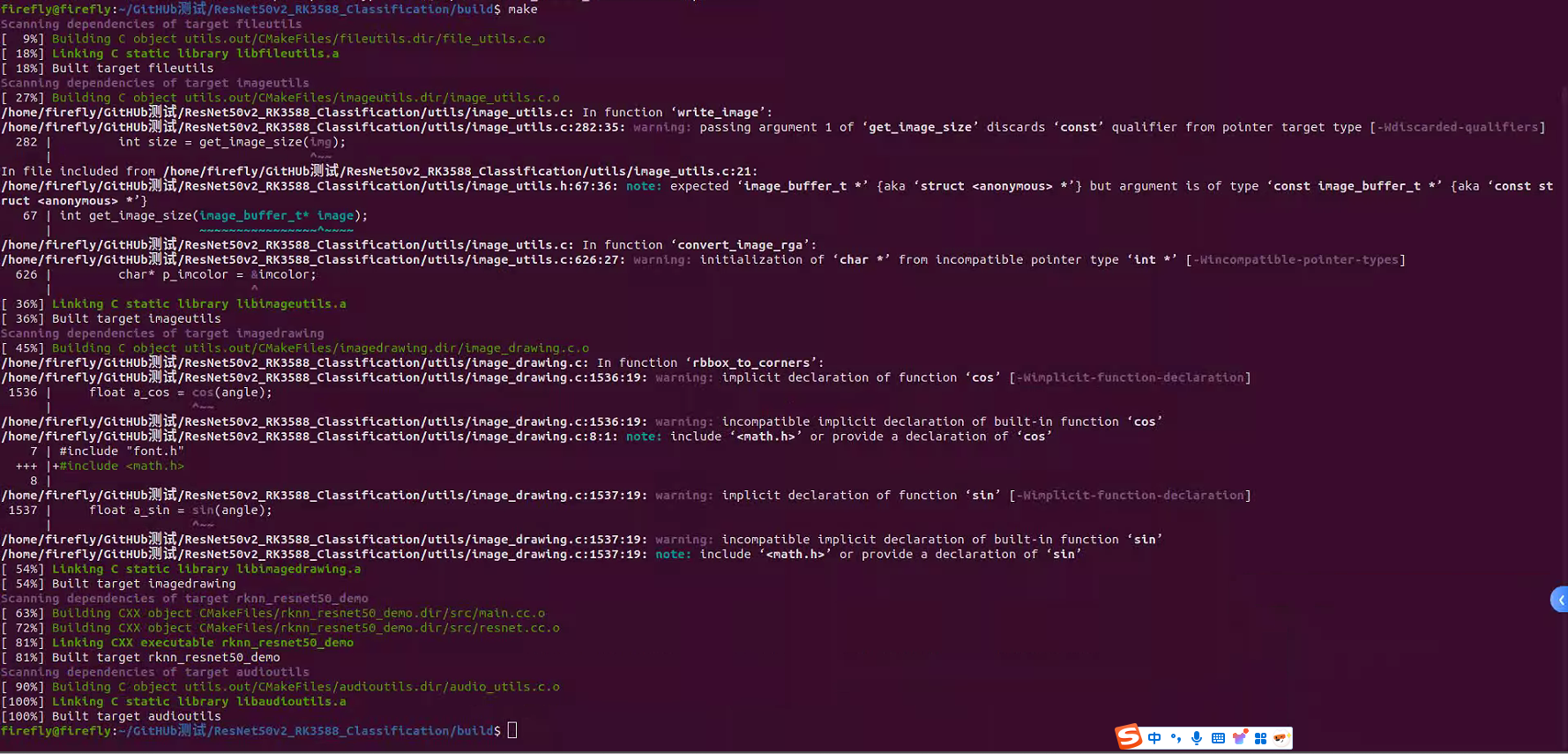
拿出一個圖片進行測試:
然后在build下打開終端輸入如下命令(可執行文件 模型路徑 輸入圖片路徑):
./rknn_resnet50_demo ../model/indicator_light_on_off_v3_classifier_model_82_p0.9945.rknn ../inputimage/022684.png
終端結果如下所示:
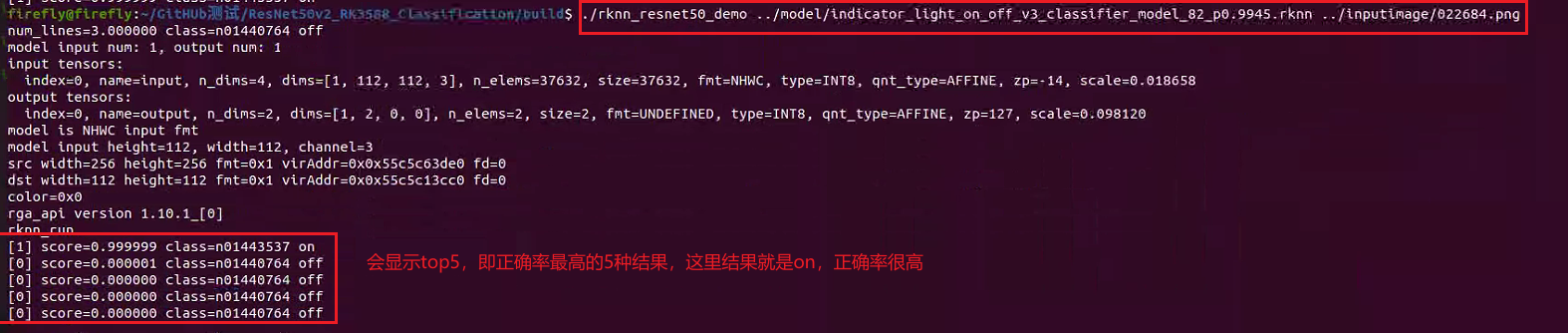
總體來說,推理得分還是很高的,ResNetv2在各項任務上足以勝任,以上即為MobileNetv2圖像分類任務部署至RK3588的全流程。
















)


