知識擴展
7.28 嵌入式產品特點、開發環境、計算機組成、Linux終端初識
1、嵌入式產品。特點:低功耗、根據用戶需求定制。硬件:arm處理器。軟件:Linux操作系統
????????arm架構:精簡指令集、低功耗(移動/嵌入式)。 ????????x86架構:復雜指令集、高功耗。(PC機/服務器)
? ? ? ? Linux操作系統:開源可裁剪。? ????????windows操作系統:非開源不可裁剪。
2、Linux發行版之一:ubantu。即對Linux內核進行封裝和功能完善,形成了一個方便用戶交互的完整操作系統。(詳細見附錄一)
3、C語言:面向過程的編程語言。(詳細介紹見附錄二)
4、? ?計算機基本組成:cpu、ram(內存)。
????????cpu負責控制與運算、存儲器負責數據中轉。
? ? ? ? 存儲器分類:ram(隨機存儲器,掉電數據丟失)、rom(只讀存儲器)
? ? ? ? 計算機存儲最小單元:字節(byte)。1byte = 8bit。每個存儲單元對應一個內存地址。
? ? ? ? (詳細見附錄三)
5、Linux終端:
? ? ? ? 1)linux@ubantu:@前面是用戶名,@后面是主機名
2)相對路徑:相對當前路徑來說的路徑(不包含根目錄)。絕對路徑:從根路徑開始描述(包含根目錄)。
3)~/是家目錄,擴展開是/home/linux。
4)絕對路徑的第一個/就是是linux根目錄,后面/是分隔符。
5) 命令組成:command [-option] [argument]
命令符 ? ?選項 ? ? ? 參數
? ? ? ? 6)permission denied ? ?表示權限不足,要在命令前加sudo,輸入用戶密碼。
7)不要隨意點擊終端、vim界面的窗口關閉(×),容易造成文件內容未保存丟失。
7.29 GPU(顯卡)與cpu(處理器)、大小端存儲、緩沖區
1、計算機的GPU參與浮點數運算、cpu整型運算,所以這兩種數據類型不能混淆。
2、如果vim編輯器有高亮配置,關鍵詞一般會高亮。(關鍵詞見附錄5)
3、在ram中,數據存儲方式包括:
? ? ? ? ? ? ? ? 大端存儲:低地址存儲高位。例如51單片機。
? ? ? ? ? ? ? ? 小端存儲:低地址存儲低位(一個地址對應一個字節,8bit)。例如x86、arm。
0x12345678
小端存儲 大端存儲
地址 數據 地址 數據
2000 78 2000 12
2001 56 2001 34
2002 34 2002 56
2003 12 2003 784、C語言代碼寫完會保存到rom,當運行時會從rom提取代碼到ram運行。
5、gcc編譯器只作類型檢查,所以代碼只要類型匹配,編譯不會報錯,但運行時可能因為其他原因導致程序崩了。
6、緩沖區:當一個高速設備遇到低速設備,高速設備會等低速設備,造成性能損失,這時候就需要緩沖區,例如多字符輸入時,鍵盤敲入的字符先進入緩沖區,是一個隊列數據結構(FIFO先進先出模式),按回車后CPU就會來處理數據,當數據正確,CPU就會取走數據,數據錯誤,數據就不會離開緩沖區。
7.30? C語言函數編寫原則
1、編寫C語言源程序時要保持高內聚低耦合的原則。即不同函數間內容不要重合,單一函數內部功能單一,具體解釋見附錄七。
7.31 內存分區、指針大小與硬件的關系
1、計算機最基本的組成:中央處理器(cpu)和存儲器(ram)。
2、cpu里面有幾個kernel就是幾核處理器。
3、內核(kernel)組成:算術邏輯單元(ALU)、控制單元(CU),寄存器(REG)、緩存(cache)
2、程序運行時,通過PC(程序計數器)當前運行指令的下一條指令、SP(棧指針)指向棧區位置。
3、內存分區:棧區、堆區、靜態區、字符串常量區、代碼區。
棧區(stack):由系統自動分配。存儲函數調用的上下文:局部變量、參數、返回地址(即調用后的下一條指令地址)、保存的寄存器值等。Linux棧區有8M,即主線程棧默認大小。
堆區(heap):動態內存分配(如malloc/new)從堆區獲取空間,需手動釋放(free/delete)。
靜態區(全局區):存儲全局變量和靜態變量(包括static修飾的局部變量)
? ? ? ? ? ? ? ? ? 靜態區細分:
????????.data段:已初始化的全局/靜態變量。
????????.bss段:未初始化的全局/靜態變量(程序加載時置零)。
常量區:.rodata段,存儲常量、const全局變量、字符串等。
代碼區:.text段,存儲可執行指令(機器碼),通常是只讀的。
4、cpu有多少根數據總線,就是多少位cpu,通常有8位、16位、32位、64位,不同cpu對應不同大小的指針1byte、2byte、4byte、8byte。
C語言知識點
7.28 C語言數據類型、數據存儲格式、進制轉化
1、C語言數據類型:
? ? ? ? 1)常量:程序運行過程值不變的量。整型常量、字符常量
? ? ??? ? ? ? 變量:程序運行過程值改變的量。變量可以看成一段內存空間,程序運行結束空間銷毀。
? ? ? ? 2)常量分類:
?????????????整型常量:十進制8、八進制01000、十六進制0x8。
?????????????浮點型常量:1.23、0.123e1 (常量小數默認是雙精度,詳細見附錄四)。
?????????????字符常量(ascll碼):'a'、'\n'、'1'、'!',實際上亦可以看成整型,因為每一個字符都可以轉化為對應整型數字。
? ? ? ? ? ? ?宏常量:#define? N 10;
? ? ? ? 3)變量分類:
??????????????整型變量:(無符號)短整型? ? (unsigned)short:2字節
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (無符號)整型? ? ? ?(unsigned)int? ? ? ? 4字節
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (無符號)長整型? ? (unsigned)long? ? ?8字節
?????????????浮點型變量??:單精度浮點型? ? ? ? float? ? ? ? 4字節
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?雙精度浮點型? ? ? ? double? ? 8字節
?????????????字符變量:? ? ? (unsigned)char? ? ? ? 1字節
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 字符常量用單引號括起來,當單引號里面有多個字符,默認值是最后一個字符。
2、數據存儲格式? ? ??
? ? ? ? ? ? ? 整數存儲格式:補碼存儲。
????????????????正數補碼是它本身,負數補碼是原碼取反加一(最高位符號位不變)。
? ? ? ? ? ? ? ? 當存儲時數字超過類型范圍會發生溢出,存儲錯誤的結果(如unsigned char 256,實際存儲0)。
??????????????單精度浮點數存儲格式:符號位1位,階碼8位,尾數23位。計算如下:
? ? ? ? ? ? ???x = (-1)^s × (1.M) × 2^(E-偏移值),其中,s是符號位,M是尾數(不包括隱含的1),E是階碼,偏移值對于32位浮點數是127,對于64位浮點數是1023。
3、進制轉化
??????????????十進制轉二進制:整數部分:除二取余法。小數部分:乘二取整法。
? ? ? ? ? ? ? 二進制轉十進制:按位乘2的n次方再加起來。
? ? ? ? ? ? ? 二進制轉八進制:每三位二進制轉一位八進制。
? ? ? ? ? ? ? ?二進制轉十六進制:沒四位二進制轉一位十六進制
7.29 C語言標識符、#預處理、程序入口、轉義字符、運算符、數據類型轉化、標準輸入輸出
1、C語言標識符(變量名、函數名、標簽等):
? ? ? ? ? ? ? ? 1)由字母、數字、下劃線組成
? ? ? ? ? ? ? ? 2)首字符必須是字母或下劃線
? ? ? ? ? ? ? ? 3)標識符命名不能跟關鍵詞重復
2、C語言帶#都是預處理指令,在編譯前先進行預處理,即文本替換,例如頭文件包含會直接替換成頭文件內容、宏定義直接文本替換、條件編譯直接替換為為真的代碼部分。
3、C語言程序必須有一個main函數作為程序入口,且只能有一個。
4、C語言轉義字符:一些不可見字符,雖然看似兩個字符,實際表示一個字符,仍為char類型。
\n 換行
\t 水平制表(八格制表) 例:abc\tcd,輸出為abc cd,c前共有八格(abc加上5個空格);
\b 退格(左箭頭) 例:Hello\b123輸出hell123,Hello\b\b123輸出Hel123;
\r 回車(光標移到本行開頭) 如hello\r123輸出123lo
\f 換頁
\\ 輸出一個斜杠
\' 輸出單引號
\" 輸出雙引號
\ooo 三個八進制數,輸出Ascll表對應字符
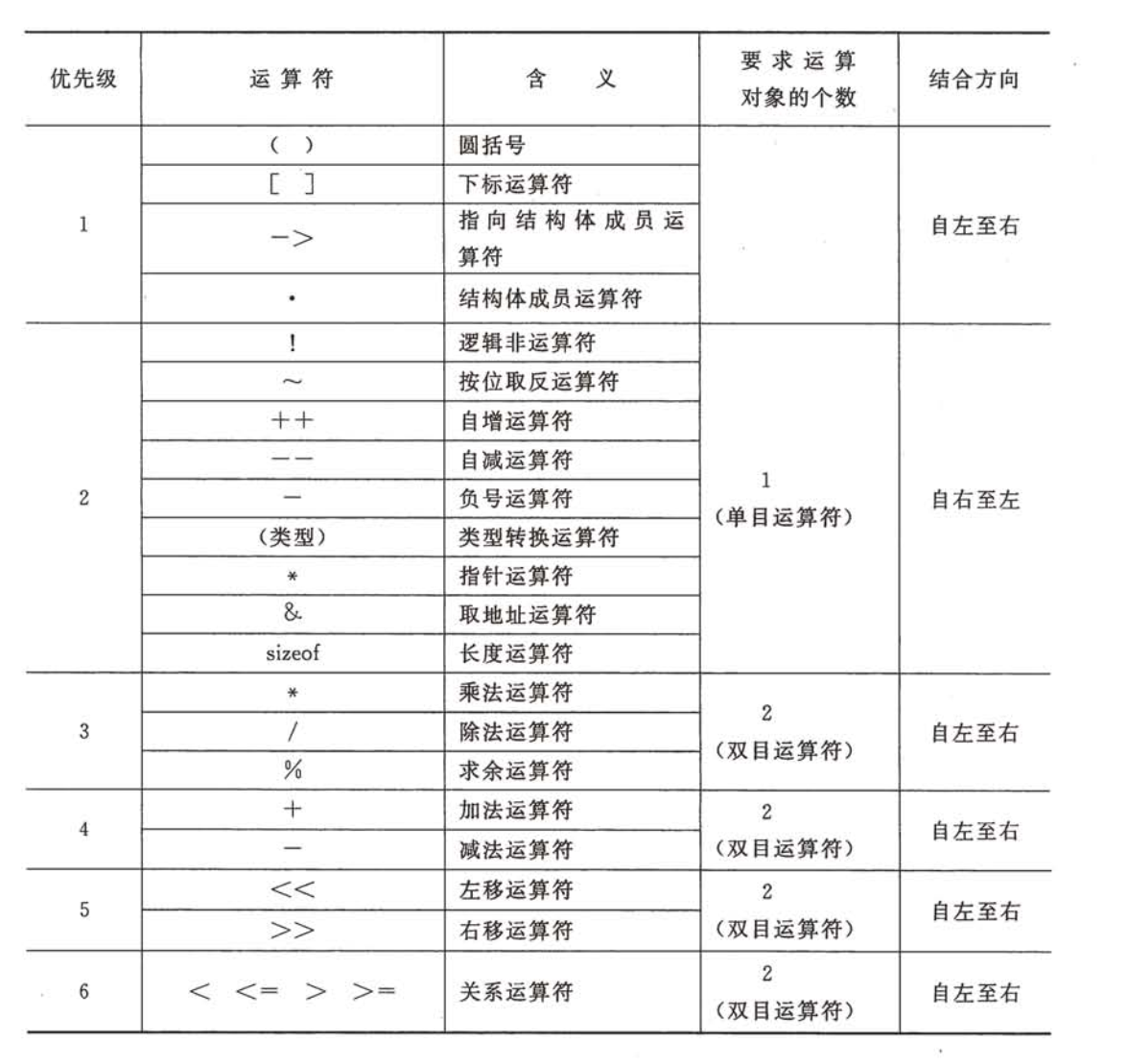
\xhh 兩個十六進制數,輸出Ascll表對應字符?5、C語言運算符(見附錄六):
? ? ? ? ? ? ? ? 優先級排序:自高到低,相同優先級按結合方向排序(只有單目運算符、三目運算符、賦值運算符是自右向左結合)
? ? ? ? ? ? ? ? ?? ? ? 1、 初等運算符:()????????[]????????->????????.
? ? ? ? ? ? ? ? ? ? ? ?2、 單目運算符: !? ? ? ? ~? ? ? ? ++? ? ? ? --? ? ? ? (類型)? ? ? ? *? ? ? ? &? ? ? ? sizeof
???????????????????????3、算數運算符:*? ? ? ? /? ? ? ? %
? ? ? ? ? ? ? ? ? ? ? ? 4、算術運算符:+? ? ? ? -
? ? ? ? ? ? ? ? ? ? ? ? 5、移位運算符:<<? ? ? ? >>
? ? ? ? ? ? ? ? ? ? ? ? 6、關系運算符:<? ? ? ? <=? ? ? ? >? ? ? ? >=
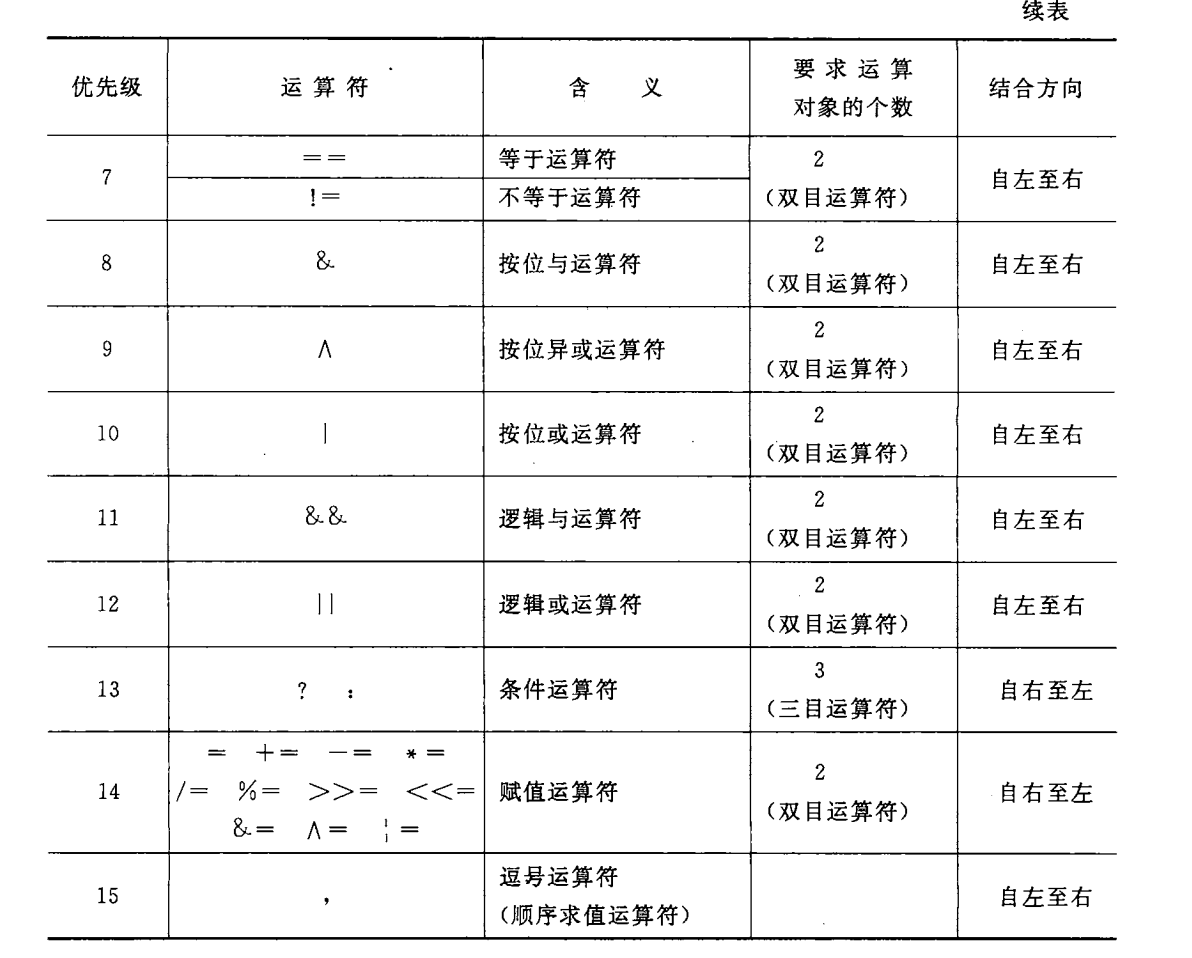
? ? ? ? ? ? ? ? ? ? ? ? 7、關系運算符:==? ? ? ? !=
? ? ? ? ? ? ? ? ? ? ? ? 8、位與:&
? ? ? ? ? ? ? ? ? ? ? ? 9、位異或:^
? ? ? ? ? ? ? ? ? ? ? ? 10、位或:|
? ? ? ? ? ? ? ? ? ? ? ? 11、邏輯與:?&&
? ? ? ? ? ? ? ? ? ? ? ? 12、邏輯或:||
? ? ? ? ? ? ? ? ? ? ? ? 13、條件運算符(唯一三目):? :??
? ? ? ? ? ? ? ? ? ? ? ? 14、賦值運算符:=? ? ? ? +=? ? ? ? -=? ? ? ? *=? ? ? ? /=? ? ? ? %=? ? ? ? >>=? ? ? ? <<=? ? ? ? ?????????????????????????????????????????????????????&=? ? ? ? ^=? ? ? ? |=
? ? ? ? ? ? ? ? ? ? ? ? 15、逗號運算符:,
? ? ? ? 注意:求余運算%:操作數必須是整型,結果正負由左操作數決定,右操作數不能位0。
? ? ? ? ? ? ? ? ? ?++i 跟 i++:二者的i變量值實際都已經加一,但是整個表達式前者已經加一,后者沒有加。前置加加效率高些。
? ? ? ? ? ? ? ? ? ? 逗號表達式:最后一個表達式作為整個表達式的值。
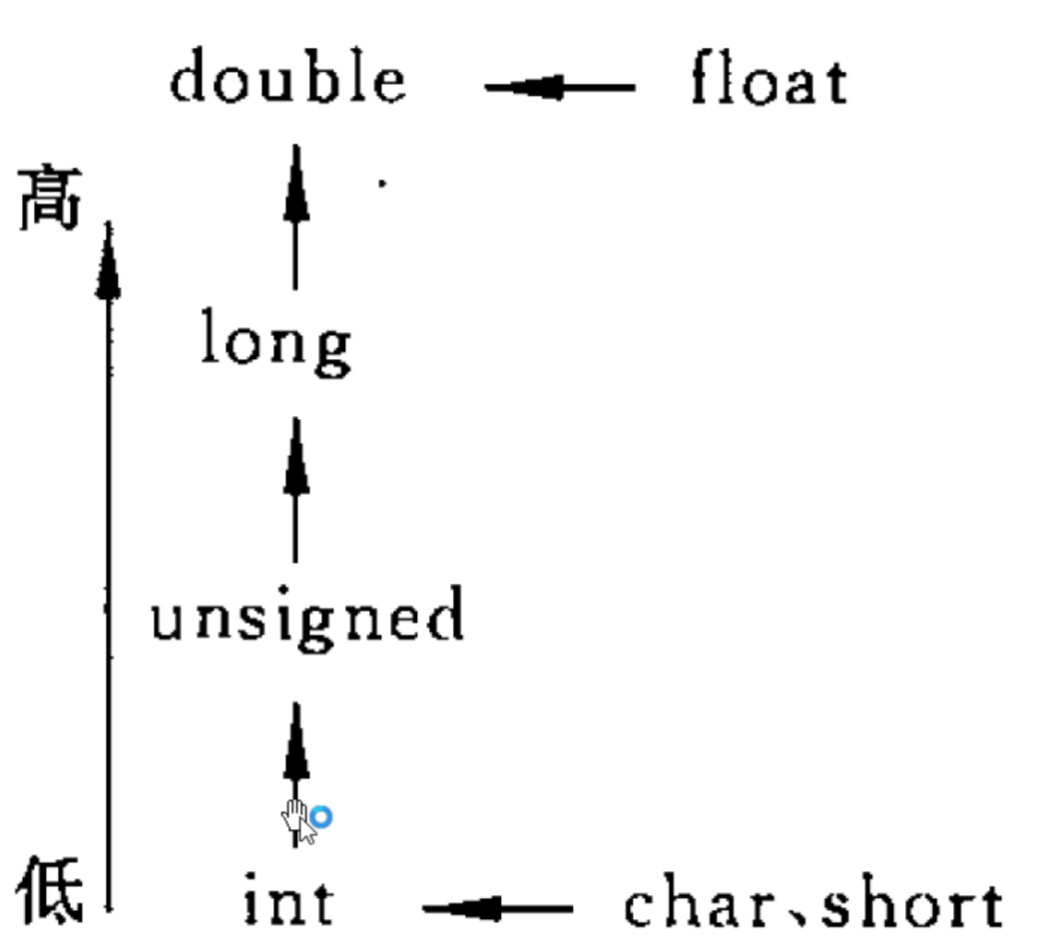
????????????????????賦值運算:把double變量值存到int變量,會造成小數部分截斷,反之沒影響。
??????????????????????????????????????short變量值存到int中,會根據short值的正負進行符號位擴充,負數會在空的高字節補1,正數補0。反之int值存到short會高字節截斷。
?????????????????????????????????????把有符號整型存到無符號中,內存中的值不變,因為存儲空間相同。可以看出,賦值運算就是內存拷貝
6、C語言的變量定義時賦值稱為初始化,定義后賦值稱為賦初值,前者效率高些。
7、C語言的數據類型轉化
????????隱式類型轉換:編譯時自動轉化,按下表進行。例如:表達式'a' + 10,兩個操作數分別是字符型和整型,根據下標,字符型自動轉化為整型,所以表達式的結果是整型。易錯題:
unsigned int a = 5;? ? ? ? a = a+(-2);? a的值應該是7。
????????顯示類型轉化:利用運算符:(類型)
8、C語言的臨時變量(匿名變量):運算過程臨時產生的值,必須為右值。例如表達式的值就是臨時變量,計算完就銷毀。
9、C語言的const關鍵字? :定義變量時前面加上這個關鍵詞,表示該變量只讀類型,后面不能改變其值。
10、C語言程序分為三種結構:順序結構、選擇結構、循環結構????????
? ? ? ??一個C程序包含若干源程序文件,每個源程序文件包括預處理指令、數據聲明和若干函數,每個函數包括函數首部和函數體,函數體包括數據聲明和執行部分。
11、代碼中輸入輸出是相對于計算機說的,從計算機向外部輸出數據稱輸出(如打印機、顯示器),輸入設備指向計算機輸入數據(如鼠標、鍵盤、掃描儀)。C語言本身不包含輸入輸出函數,輸入輸出來自標準輸入輸出庫函數stdio.h。這種方式使得C語言簡單高效。
12、C庫的輸入輸出函數:
? ? ? ? 單字符輸入輸出:?? ?char putchar(int )????????只能輸出一個字符
int getchar()????????????????輸入一個字符,返回字符整型值
getchar是從緩沖區拿走字符。當想要清理緩沖區字符時,可以用這個while(getchar != '\n'){}取出緩沖區字符。
? ? ? ? 多字符輸入輸出:??
????????int printf (const char*format,...)????????第一個參數是字符串,字符串里可以放占位符,占位符由函數后面的參數代替。 函數返回值是整型,大小為實際字符個數。
????????注意: const char*表示字符串。
????????int scanf(const char*,...) ????????通過鍵盤向計算機輸入數據。第一個參數是字符串,后面的參數放地址。當輸入多個字符時,間隔符可以是空格 tab或者換行符。返回值是個整型,測試得到大小為正確輸入的個數。
? ? ? ? 注意:后面的參數如果不是地址,會出現段錯誤,導致程序運行崩潰segmentation fault(core dumped)。
scanf()函數中的字符串里除了占位符不要加其他東西,否則輸入時還要加上這些東西,最后不要加\n。
輸入函數占位符必須與輸入數據類型一致。因為地址沒有隱式必轉。
? ? ? ? ? ? ? ? ??浮點數輸入不能指定精度、寬度。
? ? ? ? ? ? ? ? ? 輸入遇到空格、tab、換行、到達指定寬度、非法輸入就會結束
格式符
%hd 短整型
%010d 寬度為10,前面補零,只能補零或者空格。
%#o 會輸出0...
%#x 會輸出0x...
%e、%E 科學計數法表示,(如1230.0,表示為1.230000e+3)
%f、%F 十進制表示法,默認保留6位小數。輸出函數單精度也按照雙精度處理(隱式轉換)
%m.nf m是寬度,n是小數位數,寬度不夠默認右對齊補空格,m前加- 表示左邊補空格
%g,G 兩種浮點數表示方法(浮點數、科學計數法)哪個短用哪個表示。
%c 輸出字符
%s 輸出字符串
%p 打印地址,十六進制
%% 輸出%。
%lld 輸出long long整型
%lu 無符號長整型。7.30? ? ?循環結構、選擇結構、數組及排序查找問題、C語言字符數組定義及初始化
1、C語言選擇結構(條件分支結構):
? ? ? ? 1)if? ? ? ? else結構
????????????????if(表達式) {語句}:只有表達式邏輯值為1才執行語句。
????????????????if(表達式){語句一} ? else {語句二}:表達式邏輯值為1執行語句一,否則執行語句二
????????????????if(表達式一){語句一} ? else if(表達式二){語句二} else{語句三}:表達式一成立執行語句一,表達式二成立執行語句二,否則執行語句三。(三個表達式應滿足互斥關系)
? ? ? ? 2)switch結構
????????????????switch(表達式)
{
case 常量表達式1:語句一;break;
case 常量表達式2:語句二;break;
case 常量表達式3:語句三;break;
default:語句四
}
通過表達式與常量表達式等值比較,值為一就執行后面對應語句,break跳出花括號。(表達式需要是整型或者整型相兼容的類型,case后必須是常量表達式)
2、選擇結構判斷會用到關系運算符、邏輯運算符等,
????????1)關系運算符:<= , < , >= , > , == , !=,前四個優先級高一些;
2)關系運算符加操作數就是關系表達式,關系表達式的值是邏輯值(整型,非0即1);
3)邏輯運算符:與&&、或||、非!(!優先級最高,&&優先級比||高);
4)邏輯表達式:邏輯運算符加操作數就是邏輯表達式。(邏輯表達式中按照從左到右執行,在與表達式,只要左值為0,整個表達式值為零,不進行后面表達式的計算,在或表達式中,只要左表達式為1,整個表達式的值就為1,不進行后面的表達式計算
3、條件運算符:
????????????????語句一?語句二 :語句三? ? ? ? 語句一值為真執行語句二,否則執行語句三。
4、C語言循環結構:
????????1)goto循環:給一個語句命名,然后goto 標識符,就可以無條件跳轉到標識符處執行后面的語句。例:
label:
printf("bbb");
????????goto label;
2)while循環:例:
while(1 == a)
{
printf(“k”);
}
當a=1時輸出k。
3)do while循環:例:
do
{
printf("s");
}while(1 == a);
先執行一次循環體,再進行判定語句,符合要求就繼續執行循環體。
4)for循環:例:
for(a = 1; a <= 4; ++a)
{
printf("s");
}
先執行a = 1;當a < 4時,輸出s,然后執行a++,再判斷a<4是否成立,成立則輸出s,再執行a++,再判斷,如此循環。
5、跳出循環語句:
1)break語句:執行后直接跳出所在層的循環。
2)continue語句:執行后結束所在循環的本輪循環,直接執行下輪循環。
6、循環語句三要素:循環變量初始化,循環條件語句,使循環趨于結束的語句。
7、數組:? ?類型? ? ?標識符[數字]? ? ? ? 數組即一段連續的存儲空間。
8、數組相關注意點:
? ? ? ? 1)數組只有在定義時初始化可以整體賦值,之后賦值只能一個個成員賦值
? ? ? ? 2)當在定義時初始化,可以省略成員個數。
? ? ? ? 3)數組成員下標從0開始
? ? ? ? 4)void不能定義數組
? ? ? ? 5)定義數組時的[]是類型說明符,之后是方括號運算符
? ? ? ? 6)數組在內存中存儲元素具有連續性、有序性、單一性。
? ? ? ? 7)數組定義初始化如果花括號元素個數不足時會自動在后面補零。
? ? ? ? 8)數組大小為元素個數乘元素類型大小。
? ? ? ? 9)引用數組元素時要防止數組越界訪問(下標不能超了)
? ? ? ? 10)數組名就是首元素地址
9、實現數組的元素遍歷、排序、查找(下面介紹核心思想,具體實現程序見附錄八)
1)數組元素遍歷
? ? ? ? 直接按照下標一個個成員訪問
2)數組元素排序
????????逆序:把第一個跟最后一個成員換位、然后第二個跟倒數第二個換,,,直到下標為元素個數/2的位置即可。
? ? ? ? 升序:
? ? ? ? ? ? ? ? 1、選擇排序:從第一個元素開始,依次把該元素跟后面所以元素比大小,如果該元素大于后面的元素,就換值(完成所有比較就會把最小的值放當前位置),接著繼續處理下一個,直到處理完倒數第二個元素即可。
? ? ? ? ? ? ? ? 2、冒泡排序:從第一個元素開始,相鄰元素兩兩比較,如果前者大于后者就換值,直到倒數第二個元素(完成所有比較就把最大的值放到最后);接著處理下一個,直到處理完倒數第二個元素即可。
? ? ? ? ? ? ? ? 3、插入排序:從第二個元素開始,跟前面的數一一比較,當遇到第一個小于它的數,把該數后面的數整體后移,然后把它插到第一個小于它的數的后面(這樣就把從第一個元素到該元素的順序先排好了);然后處理下一個,直到最后一個元素即可。
? ? ? ? 數字查找:
? ? ? ? ? ? ? ? 遍歷查找:從第一個數開始,一一比較,直到發現哪個等于要找的數即可。
? ? ? ? ? ? ? ? 二分查找法:先對數組排序,假設為升序,先把要找的數跟中間的數比較,大于中數就在左邊找,小于中數就在右邊找(這樣就縮短了查找區間);然后在新區間繼續處理,直到處理完最后一個數即可。
10、C語言字符數組:char 標識符[數字]
? ? ? ? 初始化:
? ? ? ? ? ? ? ? 方法一:char a[6] = {'h','e','l','l','o','\n'};?
? ? ? ? ? ? ? ? 方法二:char a[] = "hello";? ? ? ? 字符串用雙引號括起來,自帶換行符。
? ? ? ? 賦初值:
? ? ? ? ? ? ? ? 方法一:一個一個成員賦值
? ? ? ? ? ? ? ? 方法二:調用函數:scanf("%s",a);????????gets(a);????????fgets(a);
? ? ? ? 輸出:
? ? ? ? ? ? ? ? 方法一:printf("%s",a) ;
? ? ? ? ? ? ? ? 方法二:puts(a);
7.31? 字符串處理函數、二維數組、函數定義、函數調用
1、數組名代表數組首元素地址,是一個定值。
2、C語言字符串相關處理函數(相同功能代碼見附錄九)
? ? ? ? 1)strlen(a);? ? ? ? 獲取字符串的有效字符個數
? ? ? ? 2)strcpy(a1,a2);? ? ? ? 拷貝a1到a2
? ? ? ? 3)strcat(a1,a2);? ? ? ? 拼接a2到a1后面
? ? ? ? 4)strcmp(a1,a2);? ? ? ? 比較a1,a2大小,若a1>a2,返回正數,a1=a2返回0,否則返回負數
3、二維數組:類型? ?標識符[row][col]
? ? ? ? 定義時初始化,可以省略行數row,列數col不可省略
? ? ? ? ? ? ? ? 二維字符數組初始化:char a[][10] = {"aaa","bbb","ccc"};? ? ? ? 注意字符串長度不能超過數組列數。
4、二維數組定義時初始化才可以用花括號整體賦值,之后不能用花括號整體賦值。
5、二維字符數組的相關操作:遍歷、逆序、排序、查找,見附錄
6、函數分類:庫函數(c庫、系統庫函數、第三方庫函數)、自定義函數
7、函數定義:? 函數首部+函數體
? ? ? 函數首部? ? ? ? ? 類型 函數名(形參1類型 形參1標識符,形參2類型 形參2標識符)
??????函數體? ? ? ? ? ? ? {聲明部分;
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 語句部分;}
8、函數相關注意:
? ? ? ? 1)返回值類型要跟函數類型一致,若無返回值,函數類型為void
? ? ? ? 2)函數名不能跟庫函數、其他自定義函數重名
? ? ? ? 3)一個好的函數要保證低耦合高內聚
? ? ? ? 4)函數內部不能定義函數,可以調用函數
? ? ? ? 5)函數遇到return語句,就會結束運行
9、函數調用:函數名(實參)
? ? ? ? 注意:1)實參需要跟形參類型匹配、數量一致
? ? ? ? ? ? ? ? ? ?2)函數可以嵌套調用
? ? ? ? ? ? ? ? ? ?3)函數參數傳遞從右至左進行? ??
10、函數遞歸調用:即在函數內部調用函數本身;
? ? ? ? 相關注意:1)每次函數調用都會保護現場,主要是把返回地址入棧,調用結束出棧
? ? ? ? ? ? ? ? ? ? ? ? ? ?2)可以利用函數遞歸調用完成循環操作,但是效率相較于循環語句會低很多,并且循環次數如果過多,由于多次返回地址入棧,會導致棧空間耗盡。
11、字符串與整型數字之間的轉化(代碼見附錄十一)
????????????????1)字符串轉整型atoi:先單字符轉整,然后乘10的倍數再相加即可
??????????????? 2)整型轉字符串itoa:先拆分單個整數,然后轉化字符再拼接即可
ubantu快捷鍵、終端命令、vim編輯器命令
//ubantu常用快捷鍵、終端命令、vim編輯器命令一、Linux終端命令:
7.28:
ls 列出當前目錄下文件及目錄
ls -a 額外列出隱藏內容。 .是目錄本身,..是上一層目錄,帶點文件是隱藏文件。
ls -l 列出當前目錄下文件,同時顯示文件詳細信息(權限、創建時間、大小等);
ls --help 獲取命令使用方法
pwd 打印當前路徑
cd 回到家目錄。
cd .. 退回上一層目錄
touch 文件名 創建文件
mkdir 目錄名 創建文件夾
rm 文件名 刪除文件
rm 文件夾 -r 刪除文件夾
cp 文件 目錄 文件拷貝至指定目錄
cp 文件夾 目錄 -r 文件夾拷貝
mv 文件 目錄 移動文件
vi/vim 文件名 編輯文件
gcc 文件名(main.c) c程序編譯,生成a.out可執行程序
gcc 文件名 -o 目標名 編譯生成指定目標名
./a.out 可執行程序運行
7.29:
whatis 函數名/系統調用/命令 查看函數簡短描述,可以知道在哪個章節描述
man 章節號 函數名/系統調用/命令 查看詳細介紹
gcc 文件 -lm 編譯時鏈接數學庫
7.30
clear 終端清屏二、vim編輯器命令:
7.28
剛進入默認命令模式,輸入i進入編輯模式(INSERT),按ESC回到命令模式(NORMAL)保存退出: :w保存 :q退出文件 :q!強制退出 :wq保存退出復制粘貼:命令模式下,移動光標到要操作的行: yy 復制1行數字 yy 復制n行(包含當前行)p 粘貼(以光標下1行為粘貼的第1行)dd 剪切1行數字 dd 剪切n行O 在光標下一格開空行進入編輯模式三、ubantu快捷鍵:
7.28:
ctrl alt t 開啟終端
ctrl shift + 終端字體放大
ctrl - 終端字體減小
tab 文件名自動補全
ctrl+alt+fn+f2 回到圖形交互界面(默認開機界面)? ? ?
ctrl+alt+fn+f3 進入文字交互界面(可用于幀緩沖相關程序運行)
7.29:
ctrl shift t 打開另一個終端標簽頁
alt 數字 多標簽頁時頁面切換
7.30
ctrl 空格 顯示或隱藏輸入法提示框
ctrl c 結束程序運行
ctrl L 終端清屏附錄一? ubantu與Linux內核
你的筆記基本正確,但表述可以更嚴謹。以下是綜合搜索結果后的修正與補充說明:
Linux發行版與Ubuntu的關系
核心概念
- Linux內核:由Linus Torvalds維護的操作系統核心,負責管理硬件資源(CPU、內存、設備驅動等)。
- 發行版(Distribution):在內核基礎上集成圖形界面、軟件包管理工具、應用程序等,形成完整的操作系統。
- Ubuntu:是基于Debian的Linux發行版之一,由Canonical公司維護,以用戶友好性和穩定性著稱。
你的筆記修正
- 原句:“對Linux內核進行封裝,形成方便用戶交互的版本”
- 更準確表述:
Ubuntu是基于Linux內核的完整操作系統發行版,不僅封裝內核,還集成了桌面環境(如GNOME)、軟件包管理器(APT/Snap)、系統工具和社區支持,提供開箱即用的用戶體驗。
補充說明
- 封裝內容:除內核外,還包括:
- 桌面環境(如Ubuntu默認的GNOME)
- 軟件倉庫(通過APT管理數千個開源軟件包)
- 系統工具(如防火墻、虛擬化支持)
- 定制優化(如Ubuntu對Debian軟件包的兼容性調整)
- 交互設計:Ubuntu特別注重桌面用戶的易用性,如圖形化安裝界面、Unity/GNOME桌面環境等。
- 封裝內容:除內核外,還包括:
Ubuntu與其他發行版的區別
| 特性 | Ubuntu | 其他發行版(如Fedora、CentOS) |
|---|---|---|
| 基礎 | 基于Debian,但軟件包不完全兼容 | Fedora基于RHEL,CentOS是RHEL的社區版 |
| 更新周期 | 每6個月發布新版本,LTS版支持5-10年 | Fedora更新更快,RHEL/CentOS更注重穩定性 |
| 目標用戶 | 個人桌面、開發者、云計算 | Fedora面向技術愛好者,RHEL面向企業 |
總結與建議
- 筆記修正建議:
- 明確Ubuntu是“基于Linux內核的發行版”,而非單純“封裝內核”,強調其完整操作系統屬性。
- 補充Ubuntu的衍生版本(如Kubuntu、Xubuntu)和特色功能(如Snap包管理)。
- 擴展學習:
- Linux內核與發行版的關系類似“引擎與整車”,內核提供基礎能力,發行版決定用戶體驗。
- 其他主流發行版包括Debian(Ubuntu上游)、Red Hat(企業級)、Arch Linux(極簡主義)等。
如需更詳細的技術對比,可參考Ubuntu官方文檔或Linux內核開發資料。
附錄二? C語言詳細介紹
C語言作為計算機科學領域最具影響力的編程語言之一,自1972年誕生以來,一直是系統編程和底層開發的首選工具。本文將全面介紹C語言的發展歷程、語言特點、標準演進以及廣泛的應用領域。
一、C語言的歷史與發展
C語言的起源可以追溯到1960年代的ALGOL 60語言,經過多個階段的演變才形成今天我們熟知的C語言。
前身語言:
- ALGOL 60(1960年):面向問題的高級語言,但離硬件較遠
- CPL語言(1963年):劍橋大學在ALGOL 60基礎上開發,更接近硬件但過于復雜
- BCPL語言(1967年):Martin Richards簡化CPL而來
- B語言(1970年):Ken Thompson在BCPL基礎上進一步簡化,用于編寫第一個UNIX操作系統
C語言的誕生:
- 1972年,貝爾實驗室的Dennis Ritchie在B語言基礎上設計出C語言(取BCPL的第二個字母)
- 1973年,C語言主體完成,并用它重寫了UNIX操作系統(90%以上代碼)
- 1978年,AT&T貝爾實驗室正式發表C語言,同時Kernighan和Ritchie合著《The C Programming Language》(簡稱K&R)
標準化進程:
- K&R C:1978-1989年間事實上的標準
- ANSI C(C89):1989年美國國家標準學會制定,1990年被ISO采納為ISO C(C90)
- C99:1999年ISO發布,增加新特性
- C11:2011年發布,支持漢字函數名和標識符
- C18:2018年發布,主要是對C11的修正
- C23:最新的C語言標準(2023年發布)
二、C語言的核心特點
C語言之所以能經久不衰,得益于其獨特的設計理念和語言特性:
高效性與低級控制:
- 直接訪問內存物理地址,進行位一級操作
- 代碼效率高,通常只比匯編語言低10%-20%
- 不需要運行環境支持,編譯后可直接運行
結構化與模塊化:
- 層次清晰,便于按模塊化方式組織程序
- 易于調試和維護
- 豐富的運算符和數據類型,便于實現復雜數據結構
可移植性強:
- 標準規格寫的程序可在多種平臺編譯運行
- 從嵌入式處理器到超級計算機都支持
- 與特定硬件架構解耦
兼具高級與低級語言特性:
- 具有高級語言的抽象能力
- 保留低級語言的硬件操作能力
- 既適合系統軟件開發,也適合應用軟件開發
豐富的表達能力:
- 處理能力極強,可處理各類復雜問題
- 繪圖能力強,適合圖形和動畫開發
- 支持多重編程范式(過程式、數據抽象等)
三、C語言的版本與編譯器
主要版本:
- Microsoft C(MS C)
- Borland Turbo C
- AT&T C
- GNU C(GCC)
現代常用編譯器:
- GCC:GNU組織開發的開源免費編譯器,支持多平臺
- Clang:基于LLVM的開源編譯器,BSD協議
- Visual C++:微軟開發的Windows平臺編譯器
- MinGW:Windows下的GCC移植版
- Xcode:macOS上的開發環境,使用Clang
集成開發環境(IDE):
- Windows:Visual Studio、Dev-C++、Code::Blocks
- Linux:Eclipse CDT、KDevelop
- 跨平臺:CLion、VS Code(配合插件)
四、C語言的應用領域
C語言因其獨特的優勢,在計算機科學的多個領域都有廣泛應用:
系統軟件開發:
- 操作系統內核(UNIX、Linux、Windows)
- 編譯器(如GCC)、解釋器
- 設備驅動程序
- 文件系統和存儲管理
嵌入式系統:
- 單片機開發(裸機或RTOS)
- 智能家居設備(空調、洗衣機控制器)
- 汽車電子(ECU、BCU)
- 醫療設備(監護儀、血糖儀)
高性能計算:
- 游戲引擎開發(Unity、Unreal)
- 圖形渲染和3D建模
- 科學計算和數值分析
- 信號處理(DSP)
網絡與安全:
- 網絡協議棧實現(TCP/IP)
- Web服務器(Apache)
- 加密算法和安全系統
- 防火墻和入侵檢測
數據庫系統:
- MySQL
- SQLite
- PostgreSQL
- Oracle和SQL Server的核心組件
工具鏈開發:
- 開發其他編程語言(Python、PHP等的解釋器)
- 構建系統和版本控制工具
- 性能分析工具
多媒體處理:
- 音視頻編解碼(FFmpeg)
- 圖像處理(OpenCV)
- 語音識別和合成
五、C語言的職業方向
掌握C語言可開啟多種職業路徑:
- 系統軟件工程師:開發操作系統、編譯器、工具鏈等系統軟件
- 嵌入式系統工程師:設計嵌入式軟件,應用于智能設備、汽車電子等領域
- 游戲引擎開發工程師:開發高性能游戲引擎和圖形渲染系統
- 網絡安全工程師:開發安全系統和加密算法,保護系統安全
- 數據庫開發工程師:設計和優化數據庫管理系統
- 物聯網(IoT)開發工程師:開發智能設備和物聯網解決方案
- 自動化測試工程師:開發底層測試框架和工具
六、C語言的影響與未來
對后續語言的影響:
- 直接催生了C++、Objective-C、C#等語言
- 影響了Java、JavaScript、Python等語言的語法設計
- 成為許多新語言的學習參考
在現代開發中的地位:
- 仍然是系統編程和性能敏感領域的首選
- 在物聯網和邊緣計算時代獲得新的應用場景
- 作為計算機科學教育的基石語言
未來展望:
- 隨著C23標準的發布,語言持續現代化
- 在安全性和并發支持方面不斷改進
- 仍將是底層開發和系統編程的核心工具
七、學習C語言的建議
- 從基礎開始:掌握數據類型、控制結構、函數等基本概念
- 深入理解指針:這是C語言最強大也最容易出錯的部分
- 實踐項目驅動:通過實際項目(如小型操作系統、游戲等)鞏固知識
- 閱讀優秀代碼:學習Linux內核等開源項目的代碼風格和設計
- 關注現代特性:了解C11、C17和C23引入的新特性
C語言作為一門接近50年歷史的語言,依然活躍在技術前沿,其設計理念和哲學影響了幾代程序員。無論是想深入理解計算機系統,還是從事底層開發工作,C語言都是不可或缺的核心技能。
附錄三? ?計算機基本組成
你的筆記基本正確,但部分表述可以更嚴謹,以下是補充和修正后的版本,結合了搜索結果中的權威信息:
計算機基本組成
CPU(中央處理器)
- 功能:
- 控制:作為計算機的"指揮中心",通過控制器(CU)從內存取指令、譯碼并生成控制信號。
- 運算:通過算術邏輯單元(ALU)執行算術(如加減乘除)和邏輯運算(如與、或、非)。
- 組成:
- 運算器(ALU) + 控制器(CU) = CPU核心。
- 寄存器:高速暫存指令和數據(如程序計數器PC、指令寄存器IR)。
- 緩存(Cache):分L1/L2/L3三級,緩解CPU與內存速度差異。
- 功能:
RAM(隨機存儲器)
- 功能:臨時存儲CPU正在處理的程序和數據,斷電后丟失(易失性)。
- 分類:
- DRAM:動態RAM,需刷新(如內存條),成本低但速度較慢。
- SRAM:靜態RAM,無需刷新(如CPU緩存),速度快但成本高。
存儲器分類與特性
| 類型 | 特性 | 用途 |
|---|---|---|
| RAM | - 可讀寫,速度快 - 易失性(斷電數據丟失) | 臨時存儲運行中的程序和數據 |
| ROM | - 通常只讀,寫入需特殊操作(如固件升級) - 非易失性(斷電保留數據) | 存儲BIOS、嵌入式系統固件 |
注:ROM演進類型包括PROM(一次性寫入)、EPROM(紫外線擦除)、EEPROM(電擦除)和閃存(如SSD)。
存儲單元與尋址
- 最小單元:
- 字節(Byte) = 8 比特(bit),是數據存儲的基本單位。
- 內存地址:每個字節對應唯一地址,CPU通過地址訪問數據。
- 擴展概念:
- 字(Word):CPU一次處理的數據長度(如32位系統為4字節)。
- 存儲字長:存儲單元中二進制代碼的位數(如64位系統的字長為64bit)。
修正建議
- CPU部分:
- 補充控制器(CU)和運算器(ALU)的協同關系。
- 增加寄存器組的作用(如PC、IR)。
- 存儲器分類:
- 明確ROM的"只讀"是歷史名稱,現代ROM(如EEPROM)支持有限寫入。
- 存儲單元:
- 區分"字節"與"字"的概念,避免混淆。
馮·諾依曼體系結構
計算機硬件五大核心組件:控制器、運算器(合為CPU)、存儲器、輸入設備、輸出設備,通過總線連接。你的筆記中"存儲器負責數據中轉"可更精確為"存儲器(內存+外存)存儲程序和數據,供CPU直接訪問"。
附錄四? 小數在C語言默認雙精度類型。
在Linux系統中,浮點數常量的默認類型是雙精度浮點數(double)。這一規則不僅適用于Linux系統,也是C/C++語言標準的通用規范。以下是具體分析:
1. 語言標準與默認類型
C/C++標準規定:根據C語言標準(如C18)和C++標準,未添加后綴的浮點數常量(如
3.14、1.23e-5)默認類型為double。- 若需指定為單精度(
float),需顯式添加后綴f或F(如3.14f)。 - 后綴
l或L表示long double(更高精度)。
- 若需指定為單精度(
示例代碼:
double a = 3.14; // 默認double類型 float b = 3.14f; // 顯式聲明為float
2. 硬件與系統實現
- IEEE 754標準:Linux系統遵循IEEE 754浮點數標準,
double類型通常占用64位(8字節),提供約15-17位有效數字,而float為32位(4字節),僅6-7位有效數字。 - 性能與精度權衡:現代處理器(如x86、ARM)對雙精度運算有硬件優化,默認使用
double可減少精度損失,但可能增加內存和計算開銷。
3. 實際應用中的注意事項
- 隱式轉換風險:將
double常量賦給float變量時,編譯器會自動截斷,可能導致精度損失或警告。 - 科學計算與嵌入式場景:
- 科學計算優先使用
double以保證精度。 - 嵌入式系統(如ARM Cortex-M)可能因資源限制選擇
float,需顯式加后綴。
- 科學計算優先使用
4. 為什么默認是double而非float?
- 歷史與兼容性:早期C語言設計時,
double因其更高的精度和范圍被選為默認類型,延續至今。 - 避免意外截斷:默認
double可減少因隱式轉換導致的精度問題,尤其在復雜表達式中。
總結
在Linux系統中,浮點數常量默認類型為double,這是由語言標準、硬件支持及精度需求共同決定的。開發者應根據場景選擇是否顯式指定類型(如float或long double),以平衡性能與精度需求。
附錄五·? ? ? ?C語言關鍵詞介紹

以下是基于圖片內容的 C語言關鍵詞分類與功能解析,結合標準C11規范進行說明:
1. 數據類型相關關鍵字
| 關鍵字 | 作用 |
|---|---|
int | 聲明整型變量(通常占4字節,范圍依賴平臺) |
char | 聲明字符型變量(1字節),也可用于小整數(-128~127) |
float | 單精度浮點數(4字節,約6-7位有效數字) |
double | 雙精度浮點數(8字節,約15位有效數字) |
short | 短整型(通常2字節) |
long | 長整型(通常4或8字節),如long double擴展精度浮點 |
unsigned | 修飾整型,表示無符號(如unsigned int范圍0~4294967295) |
signed | 顯式聲明有符號類型(默認行為,通常省略) |
void | 表示無類型(用于函數返回值或指針泛型) |
注意:sizeof是運算符而非類型,用于計算對象/類型所占字節數(編譯時確定)。
2. 流程控制關鍵字
| 類別 | 關鍵字 | 典型用法示例 |
|---|---|---|
| 條件分支 | if/else | if (x>0) { ... } else { ... } |
| 多路選擇 | switch/case/default | switch(n) { case 1: ...; break; default: ... } |
| 循環 | for/while/do | for(int i=0; i<10; i++) / while(1) { ... } |
| 跳轉 | break/continue/goto | break;(跳出循環) / goto label;(慎用) |
3. 存儲類別與作用域
| 關鍵字 | 作用 |
|---|---|
auto | 自動局部變量(C99后默認,極少顯式使用) |
register | 建議編譯器將變量存入寄存器(現代編譯器自動優化,已棄用) |
static | 靜態變量(局部變量持久化/全局變量文件內可見)或靜態函數 |
extern | 聲明外部定義的變量/函數(跨文件引用) |
volatile | 防止編譯器優化(用于硬件寄存器或多線程共享變量) |
const | 定義只讀變量(實際可通過指針修改,但行為未定義) |
4. 復合類型與自定義類型
| 關鍵字 | 作用 |
|---|---|
struct | 定義結構體(成員內存連續,可能存在對齊填充) |
union | 定義聯合體(所有成員共享同一內存空間) |
enum | 定義枚舉類型(本質是整型常量) |
typedef | 類型別名(如typedef int MyInt;) |
5. 其他重要說明
- 重復項:圖片中
struct和while在第五列重復列出,實際為排版錯誤。 - C標準差異:
- C99新增
_Bool、_Complex等,C11新增_Generic等,但圖中未包含。 goto雖合法,但易破壞代碼結構,應避免使用。
- C99新增
- 常見誤用:
const int* pvsint* const p(前者指針可變,后者指向不可變)。register在C++17中被移除,C語言中仍保留但無效。
完整關鍵詞列表(按字母排序)
auto break case char const continue default do double else enum extern
float for goto if int long register return short signed sizeof static
struct switch typedef union unsigned void volatile while
建議通過實際代碼練習(如用switch實現狀態機、union解析二進制數據)加深理解。
附錄六 C語言運算符與優先級、結合方向
附錄七? 高內聚低耦合
你的筆記基本正確,但可以結合搜索結果中的專業定義和示例進一步細化和完善。以下是針對“高內聚低耦合”原則的詳細解釋與補充建議:
1. 高內聚(High Cohesion)
- 定義:內聚指一個模塊(如函數)內部各元素(代碼邏輯)圍繞同一功能的緊密程度。高內聚要求函數功能單一且明確,所有代碼均服務于同一目標。
- 你的筆記:提到“一個函數的功能盡量單一”,這是正確的,但需補充內聚的層次劃分:
- 功能內聚(最佳):函數僅完成一個獨立功能(如計算平方數或格式化輸出)。
- 反例:
- 偶然內聚:函數內代碼無邏輯關聯(如同時計算面積和打印歡迎語)。
- 邏輯內聚:函數通過參數選擇不同功能(如
print_info(type)同時處理學生和教師信息)。
- 判斷標準:刪除函數中的某行代碼后,若原功能無法完成,則內聚度高;否則可能存在冗余代碼。
2. 低耦合(Low Coupling)
- 定義:耦合指模塊間依賴關系的強度。低耦合要求函數間接口簡單、依賴最少,避免相互影響。
- 你的筆記:提到“不同函數間的功能盡量不用重合”,需更準確表述為**“減少函數間的直接依賴”**,具體表現為:
- 數據耦合(推薦):通過參數傳遞簡單數據(如值傳遞),函數獨立性最強。
- 反例:
- 外部耦合(最差):函數共享全局變量,導致調試困難(如多個函數修改同一全局變量)。
- 特征耦合:通過指針或文件等共享復雜數據,增加依賴風險。
- 實現技巧:使用接口(如回調函數)或封裝(如面向對象設計)降低耦合。
3. 你的筆記改進建議
- 明確術語:區分“功能不重合”(避免重復代碼)與“依賴關系簡化”(低耦合的核心)。
- 補充示例:
- 高內聚示例:將“計算平方數”和“格式化輸出”拆分為兩個函數。
- 低耦合示例:用參數傳遞替代全局變量。
- 強調設計階段:高內聚低耦合需在編碼前規劃模塊職責,而非事后調整。
4. 實際應用場景
- 簡單任務:若功能單一(如輸出200以內平方數),單函數實現可能已滿足高內聚。
- 復雜任務:按“輸入-計算-輸出”拆分模塊,確保各模塊功能獨立且接口簡潔。
總結
你的筆記抓住了核心思想,但需更精準地定義“功能單一性”和“依賴關系”,并輔以具體示例。高內聚低耦合的本質是模塊職責清晰化和交互最小化,通過合理設計提升代碼的可維護性和可重用性。
附錄八 數組的遍歷、排序、查找相關問題
#include<stdio.h>
void Array_traversal(int *array)//數組遍歷
{int i;for(i = 0; i < 10;++i){printf("%d\n",array[i]);}return;
}int select_sort(int *a,int len)//選擇排序
{int i,j;//int len = sizeof(a) / sizeof(a[0]);for(i = 0; i < len - 1;++i){for(j = i + 1; j < len;++j){if(a[i] > a[j]){int t = a[i];a[i] = a[j];a[j] = t;}}}return 0;
}int reverse_sort(void)//逆序
{int i;int a[10] = {1,0,2,9,3,8,4,7,5,6};int len = sizeof(a) / sizeof(a[0]);select_sort(a,len);for(i = 0;i < len / 2;++i){int t = a[i];a[i] = a[len - i - 1];a[len - i - 1] = t;}Array_traversal(a);
}int bubble_sort(void)//冒泡排序
{int i,j;int a[10] = {1,0,2,9,3,8,4,7,5,6};int len = sizeof(a) / sizeof(a[0]);for(i = len; i > 0; --i){for(j = 0;j < i - 1; ++j){if(a[j] > a[j + 1]){int t = a[j];a[j] = a[j + 1];a[j + 1] = t;}}}Array_traversal(a);
};int insert_sort(int *a,int len)//插入排序
{int i,j;for(i = 1; i < len; ++i){int t = a[i];j = i;while(a[j - 1] > t && j > 0){a[j] = a[j - 1];--j;}a[j] = t;}//Array_traversal(a);return 0;
}int binary_search()//二分查找
{ int i,j;int a[10] = {1,0,2,9,3,8,4,7,5,6};int len = sizeof(a) / sizeof(a[0]);int end = len - 3;int head = 0;int mid;insert_sort(a,len);int num = 6;while(head <= end){mid = (head + end) / 2;if(num > a[mid]){head = mid + 1;}else if(num < a[mid]){end = mid - 1;}else{break;}}if(head <= end){printf("%d\n",a[mid]);}else{puts("not found");}return 0;
}int main()
{ int i,j;int a[10] = {1,0,2,9,3,8,4,7,5,6};int len = sizeof(a) / sizeof(a[0]);}?附錄九? ? ? ? 字符串處理函數功能代碼
#include<stdio.h>
int mystrlen()
{char a[] = "hello";int len = 0;while(a[len] != '\0'){++len;}printf("%d\n",len);return 0;
}int mystrcpy()
{char a1[] = "hello";char a2[10] = {0};int i = 0;while(a1[i] != '\0'){a2[i] = a1[i];++i;}printf("%s\n",a2);
}int mystrcat()
{char a1[11] = "hello";char a2[] = "hi";int i = 0,j = 0;while(a1[i] != '\0'){++i;}while(a2[j] != '\0'){a1[i] = a2[j];++i;++j;}a1[i] = 0;printf("%s\n",a1);return 0;
}int mystrcmp()
{char a1[] = "hello";char a2[] = "helloa";int i = 0;while(a1[i] == a2[i] && a1[i] != '\0' && a2[i] != '\0'){++i;}printf("%d\n",a1[i] - a2[i]);return 0;
}
附錄十? ?二維字符數組的遍歷、排序、查找
#include<stdio.h>
#include<string.h>
int palindromic_judge()//回文判斷
{char a[] = "2abcba2";int len = strlen(a);char b[len + 1];strcpy(b,a);for(int i = 0;i < len / 2;++i){char t = a[i];a[i] = a[len - i - 1];a[len - i - 1] = t;}if(strcmp(a,b) == 0){puts("is palindromic number");}else{puts("not is palindromic number");}return 0;
}int frame_print()//邊框打印
{int a[][4] = {1,1,1,1,1,2,2,1,1,1,1,1};int row = sizeof(a)/sizeof(a[0]);int col = sizeof(a[0]) / sizeof(a[0][0]);int i,j;for(i = 0;i < row;++i){for(j = 0;j < col;++j){if(i == 0 || i == row - 1 || j == 0 || j == col - 1){printf("%-2d",a[i][j]);}}puts("");}return 0;
}int reverse_double_array()//二維數組垂直逆序
{char a[][4] = {"111","222","333"};int row = sizeof(a) / sizeof(a[0]);int col = sizeof(a[0]) / sizeof(a[0][0]);int i;for(i = 0;i < row / 2; ++i){char tmp[col];strcpy(tmp,a[i]);strcpy(a[i],a[row - i - 1]);strcpy(a[row - i - 1],tmp);}for(i = 0; i < row; ++i){puts(a[i]);}return 0;
}int select_sort()//選擇排序
{char a[][4] = {"ccc","aaa","bbb"};int row = sizeof(a) / sizeof(a[0]);int col = sizeof(a[0]) / sizeof(a[0][0]);int i,j;for(i = 0; i < row - 1; ++i){for(j = i + 1; j < row; ++j){if(strcmp(a[i],a[j]) > 0){char tmp[col];strcpy(tmp,a[i]);strcpy(a[i],a[j]);strcpy(a[j],tmp);}}}for(i = 0; i < row; ++i){puts(a[i]);}return 0;
}int bubble_sort()//冒泡排序
{char a[][4] = {"ccc","aaa","bbb"};int row = sizeof(a) / sizeof(a[0]);int col = sizeof(a[0]) / sizeof(a[0][0]);int i,j;for(i = row;i > 0; --i){for(j = 0;j < i - 1;++j){if(strcmp(a[j], a[j + 1]) > 0){char tmp[col];strcpy(tmp,a[j]);strcpy(a[j],a[j+1]);strcpy(a[j+1],tmp); }}}for(i = 0; i < row; ++i){puts(a[i]);}return 0;
}int insert_sort(char a[][4],int row)//插入排序
{//char a[][4] = {"ccc","aaa","bbb"};//int row = sizeof(a) / sizeof(a[0]);//int col = sizeof(a[0]) / sizeof(a[0][0]);int i,j;for(i = 1;i < row;++i){char tmp[4];strcpy(tmp,a[i]);j = i;while(strcmp(a[j],a[j - 1]) < 0 && j > 0){strcpy(a[j],a[j - 1]);--j;}strcpy(a[j],tmp);}/*for(i = 0; i < row; ++i){puts(a[i]);}*/return 0;
}int binary_find_the_temporary()//二分查找
{char tem[4] = "bbb1";char a[][4] = {"ccc","aaa","bbb"};int row = sizeof(a) / sizeof(a[0]);int col = sizeof(a[0]) / sizeof(a[0][0]);insert_sort(a,row); int head = 0;int end = row - 1;while(head <= end){int mid = (head + end) / 2;if(strcmp(tem,a[mid]) > 0){head = mid + 1;}else if(strcmp(tem,a[mid]) < 0){end = mid - 1;}else{break;}}if(head <= end){printf("find the temporary\n");}else{printf("not found temporary\n");}return 0;
}?附錄十一? atoi 與 itoa
#include<stdio.h>
int itoa()
{int a = 1234;char b[1024] = {0};int i,j;i = 0;while(a != 0){b[i] = a % 10 + '0';a /= 10;++i;}for(j = 0;j < i / 2;++j){int t = b[j];b[j] = b[i - j - 1];b[i - j - 1] = t;}puts(b);return 0;
}int atoi()
{char a[] = "12340";int i,sum = 0;for(i = 0;a[i] != '\0';++i){sum += a[i] - '0';sum *= 10;}printf("%d\n",sum / 10);return 0;
}








委托詳解)

)
)


![[mind-elixir]Mind-Elixir 的交互增強:單擊、雙擊與鼠標 Hover 功能實現](http://pic.xiahunao.cn/[mind-elixir]Mind-Elixir 的交互增強:單擊、雙擊與鼠標 Hover 功能實現)




