引言
這里主要是依托于 jackfrued 倉庫 Python-100-Days 進行學習,記錄自己的學習過程和心得體會。
1 文件讀寫和異常處理
實際開發中常常會遇到對數據進行持久化的場景,所謂持久化是指將數據從無法長久保存數據的存儲介質(通常是內存)轉移到可以長久保存數據的存儲介質(通常是硬盤)中。實現數據持久化最直接簡單的方式就是通過文件系統將數據保存到文件中。
計算機的文件系統是一種存儲和組織計算機數據的方法,它使得對數據的訪問和查找變得容易,文件系統使用文件和樹形目錄的抽象邏輯概念代替了硬盤、光盤、閃存等物理設備的數據塊概念,用戶使用文件系統來保存數據時,不必關心數據實際保存在硬盤的哪個數據塊上,只需要記住這個文件的路徑和文件名。在寫入新數據之前,用戶不必關心硬盤上的哪個數據塊沒有被使用,硬盤上的存儲空間管理(分配和釋放)功能由文件系統自動完成,用戶只需要記住數據被寫入到了哪個文件中。
1.1 打開和關閉文件
有了文件系統,我們可以非常方便的通過文件來讀寫數據;在Python中要實現文件操作是非常簡單的。我們可以使用Python內置的open函數來打開文件,在使用open函數時,我們可以通過函數的參數指定文件名、操作模式和字符編碼等信息,接下來就可以對文件進行讀寫操作了。這里所說的操作模式是指要打開什么樣的文件(字符文件或二進制文件)以及做什么樣的操作(讀、寫或追加),具體如下表所示。
| 操作模式 | 具體含義 |
|---|---|
'r' | 讀取 (默認) |
'w' | 寫入(會先截斷之前的內容) |
'x' | 寫入,如果文件已經存在會產生異常 |
'a' | 追加,將內容寫入到已有文件的末尾 |
'b' | 二進制模式 |
't' | 文本模式(默認) |
'+' | 更新(既可以讀又可以寫) |
下圖展示了如何根據程序的需要來設置open函數的操作模式。
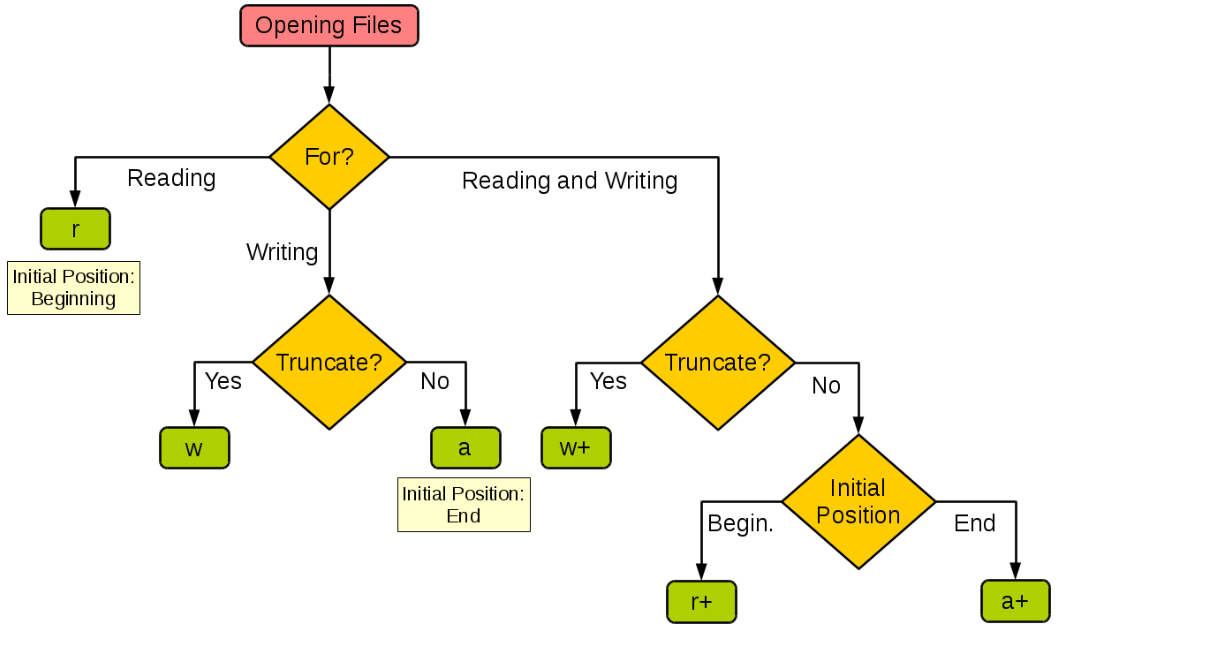
在使用open函數時,如果打開的文件是字符文件(文本文件),可以通過encoding參數來指定讀寫文件使用的字符編碼。如果對字符編碼和字符集這些概念不了解,可以看看《字符集和字符編碼》一文,此處不再進行贅述。
使用open函數打開文件成功后會返回一個文件對象,通過這個對象,我們就可以實現對文件的讀寫操作;如果打開文件失敗,open函數會引發異常,稍后會對此加以說明。如果要關閉打開的文件,可以使用文件對象的close方法,這樣可以在結束文件操作時釋放掉這個文件。
1.2 讀寫文本文件
用open函數打開文本文件時,需要指定文件名并將文件的操作模式設置為'r',如果不指定,默認值也是'r';如果需要指定字符編碼,可以傳入encoding參數,如果不指定,默認值是None,那么在讀取文件時使用的是操作系統默認的編碼。需要提醒大家,如果不能保證保存文件時使用的編碼方式與encoding參數指定的編碼方式是一致的,那么就可能因無法解碼字符而導致讀取文件失敗。
下面的例子演示了如何讀取一個純文本文件(一般指只有字符原生編碼構成的文件,與富文本相比,純文本不包含字符樣式的控制元素,能夠被最簡單的文本編輯器直接讀取)。
file = open('致橡樹.txt', 'r', encoding='utf-8')
print(file.read())
file.close()

說明:《致橡樹》是舒婷老師在1977年3月創建的愛情詩,也是我最喜歡的現代詩之一。
除了使用文件對象的read方法讀取文件之外,還可以使用for-in循環逐行讀取或者用readlines方法將文件按行讀取到一個列表容器中,代碼如下所示。
file = open('致橡樹.txt', 'r', encoding='utf-8')
for line in file:print(line, end='')
file.close()file = open('致橡樹.txt', 'r', encoding='utf-8')
lines = file.readlines()
for line in lines:print(line, end='')
file.close()
如果要向文件中寫入內容,可以在打開文件時使用w或者a作為操作模式,前者會截斷之前的文本內容寫入新的內容,后者是在原來內容的尾部追加新的內容。
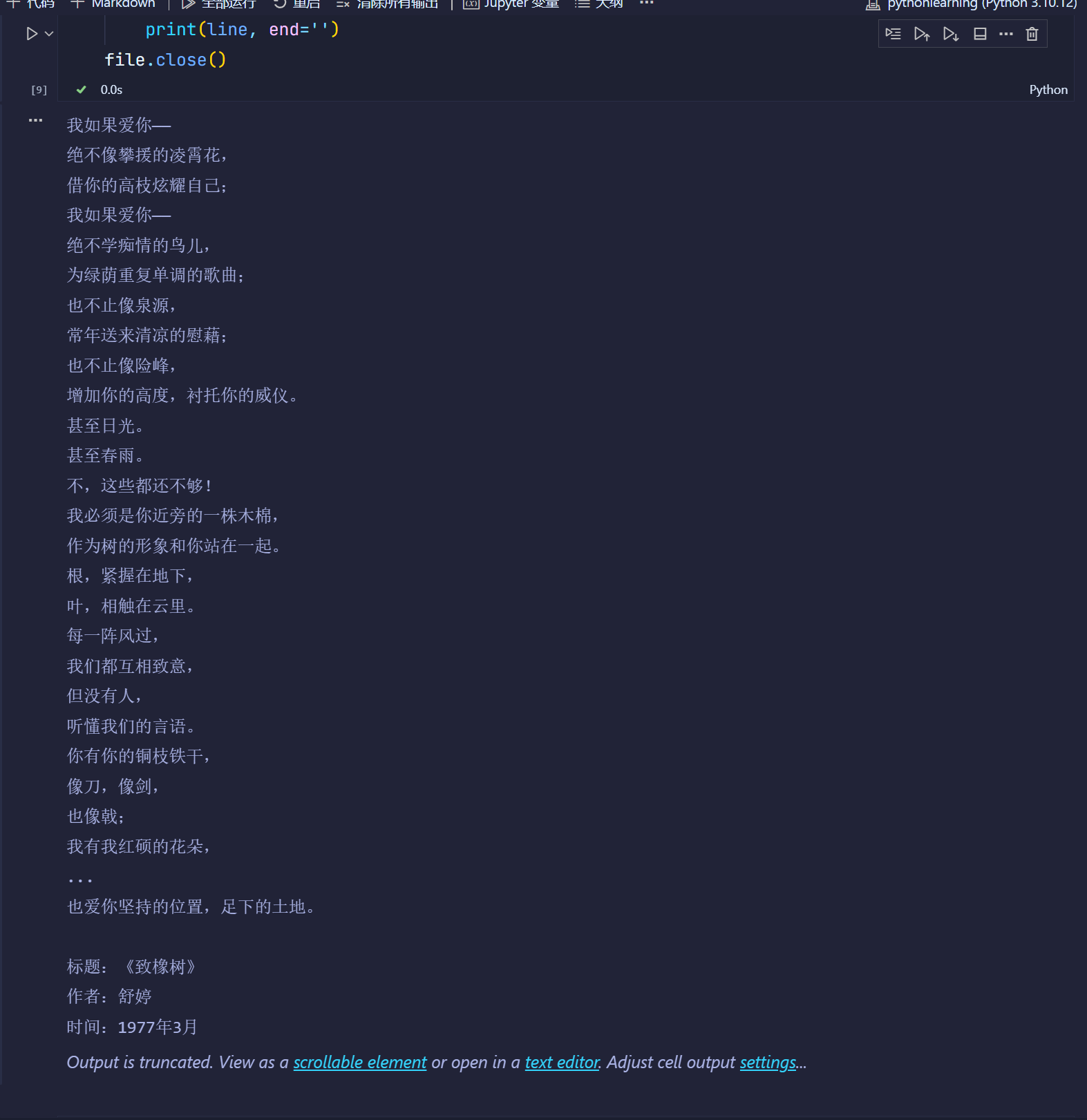
file = open("致橡樹.txt", 'a+', encoding="utf-8")
file.write('\n\n標題:《致橡樹》')
file.write('\n作者:舒婷')
file.write('\n時間:1977年3月')# 關鍵:將文件指針移動到開頭
file.seek(0)lines = file.readlines()
for line in lines:print(line, end='')
file.close()
1.3 異常處理機制
請注意上面的代碼,如果open函數指定的文件并不存在或者無法打開,那么將引發異常狀況導致程序崩潰。為了讓代碼具有健壯性和容錯性,我們可以使用Python的異常機制對可能在運行時發生狀況的代碼進行適當的處理。Python中和異常相關的關鍵字有五個,分別是try、except、else、finally和raise,我們先看看下面的代碼,再來為大家介紹這些關鍵字的用法。
file = None
try:file = open('致橡樹.txt', 'r', encoding='utf-8')print(file.read())
except FileNotFoundError:print('無法打開指定的文件!')
except LookupError:print('指定了未知的編碼!')
except UnicodeDecodeError:print('讀取文件時解碼錯誤!')
finally:if file:file.close()
在Python中,我們可以將運行時會出現狀況的代碼放在try代碼塊中,在try后面可以跟上一個或多個except塊來捕獲異常并進行相應的處理。例如,在上面的代碼中,文件找不到會引發FileNotFoundError,指定了未知的編碼會引發LookupError,而如果讀取文件時無法按指定編碼方式解碼文件會引發UnicodeDecodeError,所以我們在try后面跟上了三個except分別處理這三種不同的異常狀況。在except后面,我們還可以加上else代碼塊,這是try 中的代碼沒有出現異常時會執行的代碼,而且else中的代碼不會再進行異常捕獲,也就是說如果遇到異常狀況,程序會因異常而終止并報告異常信息。最后我們使用finally代碼塊來關閉打開的文件,釋放掉程序中獲取的外部資源。由于finally塊的代碼不論程序正常還是異常都會執行,甚至是調用了sys模塊的exit函數終止Python程序,finally塊中的代碼仍然會被執行(因為exit函數的本質是引發了SystemExit異常),因此我們把finally代碼塊稱為“總是執行代碼塊”,它最適合用來做釋放外部資源的操作。
Python中內置了大量的異常類型,除了上面代碼中用到的異常類型以及之前的課程中遇到過的異常類型外,還有許多的異常類型,其繼承結構如下所示。
BaseException+-- SystemExit+-- KeyboardInterrupt+-- GeneratorExit+-- Exception+-- StopIteration+-- StopAsyncIteration+-- ArithmeticError| +-- FloatingPointError| +-- OverflowError| +-- ZeroDivisionError+-- AssertionError+-- AttributeError+-- BufferError+-- EOFError+-- ImportError| +-- ModuleNotFoundError+-- LookupError| +-- IndexError| +-- KeyError+-- MemoryError+-- NameError| +-- UnboundLocalError+-- OSError| +-- BlockingIOError| +-- ChildProcessError| +-- ConnectionError| | +-- BrokenPipeError| | +-- ConnectionAbortedError| | +-- ConnectionRefusedError| | +-- ConnectionResetError| +-- FileExistsError| +-- FileNotFoundError| +-- InterruptedError| +-- IsADirectoryError| +-- NotADirectoryError| +-- PermissionError| +-- ProcessLookupError| +-- TimeoutError+-- ReferenceError+-- RuntimeError| +-- NotImplementedError| +-- RecursionError+-- SyntaxError| +-- IndentationError| +-- TabError+-- SystemError+-- TypeError+-- ValueError| +-- UnicodeError| +-- UnicodeDecodeError| +-- UnicodeEncodeError| +-- UnicodeTranslateError+-- Warning+-- DeprecationWarning+-- PendingDeprecationWarning+-- RuntimeWarning+-- SyntaxWarning+-- UserWarning+-- FutureWarning+-- ImportWarning+-- UnicodeWarning+-- BytesWarning+-- ResourceWarning
從上面的繼承結構可以看出,Python中所有的異常都是BaseException的子類型,它有四個直接的子類,分別是:SystemExit、KeyboardInterrupt、GeneratorExit和Exception。其中:
SystemExit表示解釋器請求退出;KeyboardInterrupt是用戶中斷程序執行(按下Ctrl+c);GeneratorExit表示生成器發生異常通知退出,不理解這些異常沒有關系,繼續學習就好了。- 值得一提的是
Exception類,它是常規異常類型的父類型,很多的異常都是直接或間接的繼承自Exception類。
如果Python內置的異常類型不能滿足應用程序的需要,我們可以自定義異常類型,而自定義的異常類型也應該直接或間接繼承自Exception類,當然還可以根據需要重寫或添加方法。
在Python中,可以使用raise關鍵字來引發異常(拋出異常對象),而調用者可以通過try...except...結構來捕獲并處理異常。例如在函數中,當函數的執行條件不滿足時,可以使用拋出異常的方式來告知調用者問題的所在,而調用者可以通過捕獲處理異常來使得代碼從異常中恢復,定義異常和拋出異常的代碼如下所示。
class InputError(ValueError):"""自定義異常類型"""passdef fac(num):"""求階乘"""if num < 0:raise InputError('只能計算非負整數的階乘')if num in (0, 1):return 1return num * fac(num - 1)fac(-1)
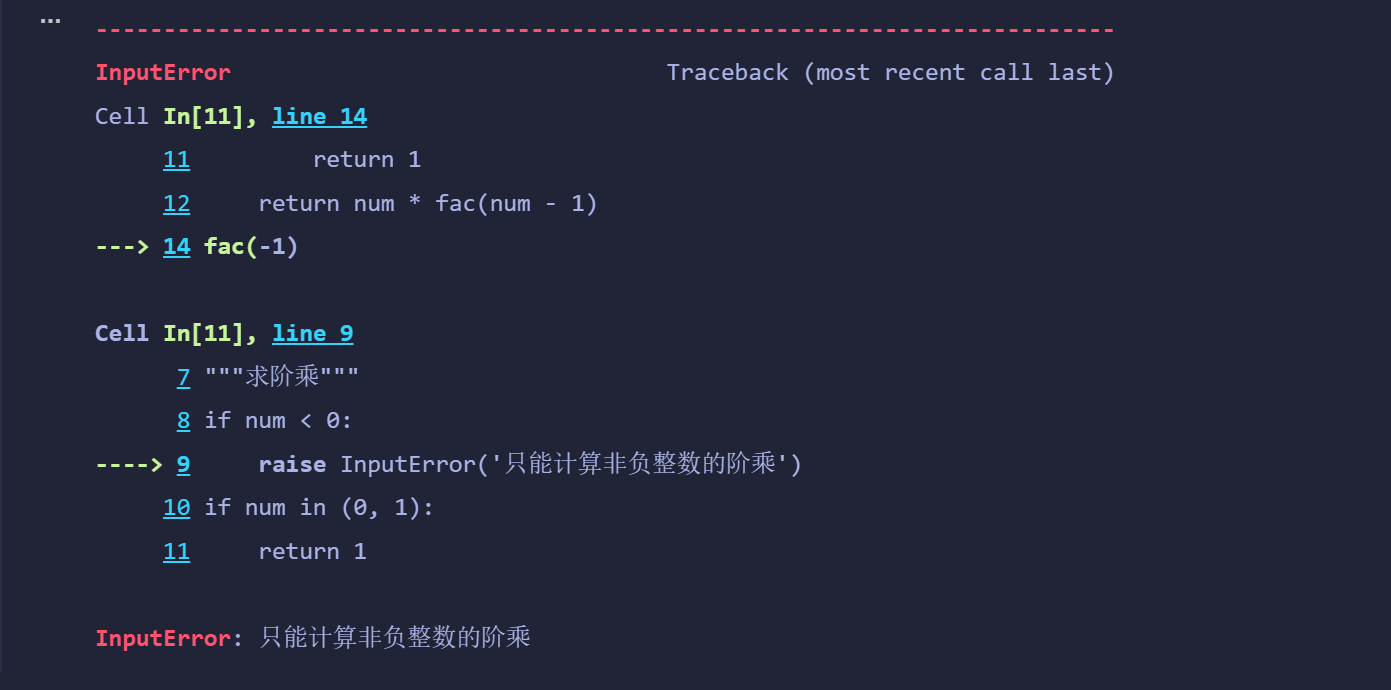
調用求階乘的函數fac,通過try...except...結構捕獲輸入錯誤的異常并打印異常對象(顯示異常信息),如果輸入正確就計算階乘并結束程序。
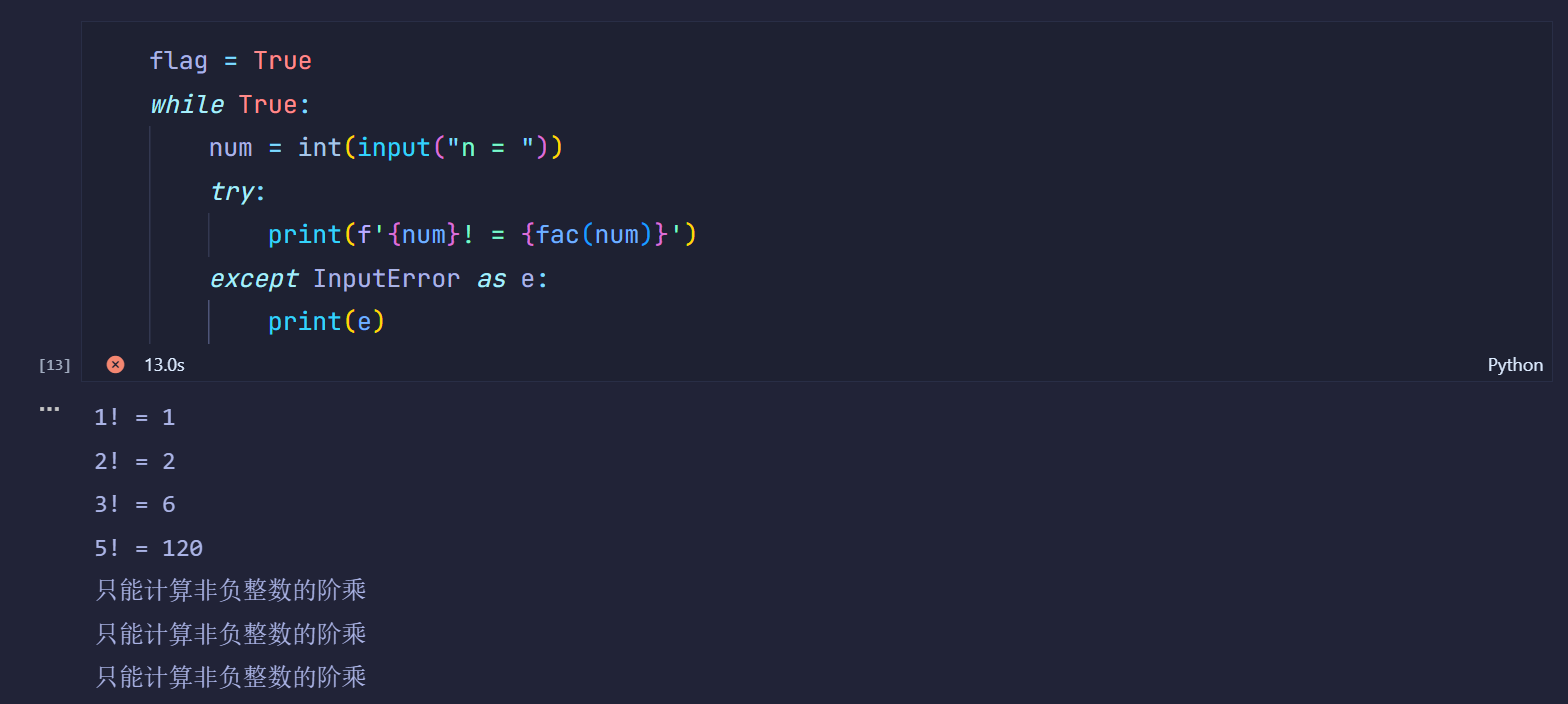
flag = True
while flag:num = int(input('n = '))try:print(f'{num}! = {fac(num)}')flag = Falseexcept InputError as err:print(err)
1.4 上下文管理器語法
對于open函數返回的文件對象,還可以使用with上下文管理器語法在文件操作完成后自動執行文件對象的close方法,這樣可以讓代碼變得更加簡單優雅,因為不需要再寫finally代碼塊來執行關閉文件釋放資源的操作。需要提醒大家的是,并不是所有的對象都可以放在with上下文語法中,只有符合上下文管理器協議(有__enter__和__exit__魔術方法)的對象才能使用這種語法,Python標準庫中的contextlib模塊也提供了對with上下文語法的支持,后面再為大家進行講解。
用with上下文語法改寫后的代碼如下所示。
try:with open('致橡樹.txt', 'r', encoding='utf-8') as file:print(file.read())
except FileNotFoundError:print('無法打開指定的文件!')
except LookupError:print('指定了未知的編碼!')
except UnicodeDecodeError:print('讀取文件時解碼錯誤!')
1.5 讀寫二進制文件
讀寫二進制文件跟讀寫文本文件的操作類似,但是需要注意,在使用open函數打開文件時,如果要進行讀操作,操作模式是'rb',如果要進行寫操作,操作模式是'wb'。還有一點,讀寫文本文件時,read方法的返回值以及write方法的參數是str對象(字符串),而讀寫二進制文件時,read方法的返回值以及write方法的參數是bytes-like對象(字節串)。下面的代碼實現了將當前路徑下名為Penry.jpg的圖片文件復制到BIT.jpg文件中的操作。
try:with open('Penry.jpg', 'rb') as file1:data = file1.read()with open('BIT.jpg', 'wb') as file2:file2.write(data)
except FileNotFoundError:print('指定的文件無法打開.')
except IOError:print('讀寫文件時出現錯誤.')
print('程序執行結束.')
如果要復制的圖片文件很大,一次將文件內容直接讀入內存中可能會造成非常大的內存開銷,為了減少對內存的占用,可以為read方法傳入size參數來指定每次讀取的字節數,通過循環讀取和寫入的方式來完成上面的操作,代碼如下所示。
try:with open('guido.jpg', 'rb') as file1, open('吉多.jpg', 'wb') as file2:data = file1.read(512)while data:file2.write(data)data = file1.read()
except FileNotFoundError:print('指定的文件無法打開.')
except IOError:print('讀寫文件時出現錯誤.')
print('程序執行結束.')
1.6 總結
通過讀寫文件的操作,我們可以實現數據持久化。在Python中可以通過open函數來獲得文件對象,可以通過文件對象的read和write方法實現文件讀寫操作。程序在運行時可能遭遇無法預料的異常狀況,可以使用Python的異常機制來處理這些狀況。Python的異常機制主要包括try、except、else、finally和raise這五個核心關鍵字。try后面的except語句不是必須的,finally語句也不是必須的,但是二者必須要有一個;except語句可以有一個或多個,多個except會按照書寫的順序依次匹配指定的異常,如果異常已經處理就不會再進入后續的except語句;except語句中還可以通過元組同時指定多個異常類型進行捕獲;except語句后面如果不指定異常類型,則默認捕獲所有異常;捕獲異常后可以使用raise要再次拋出,但是不建議捕獲并拋出同一個異常;不建議在不清楚邏輯的情況下捕獲所有異常,這可能會掩蓋程序中嚴重的問題。最后強調一點,不要使用異常機制來處理正常業務邏輯或控制程序流程,簡單的說就是不要濫用異常機制,這是初學者常犯的錯誤。
2 對象的序列化和反序列化
2.1 JSON概述
通過上面的講解,我們已經知道如何將文本數據和二進制數據保存到文件中,那么這里還有一個問題,如果希望把一個列表或者一個字典中的數據保存到文件中又該怎么做呢?在Python中,我們可以將程序中的數據以JSON格式進行保存。JSON是“JavaScript Object Notation”的縮寫,它本來是JavaScript語言中創建對象的一種字面量語法,現在已經被廣泛的應用于跨語言跨平臺的數據交換。使用JSON的原因非常簡單,因為它結構緊湊而且是純文本,任何操作系統和編程語言都能處理純文本,這就是實現跨語言跨平臺數據交換的前提條件。目前JSON基本上已經取代了XML(可擴展標記語言)作為異構系統間交換數據的事實標準。可以在JSON的官方網站找到更多關于JSON的知識,這個網站還提供了每種語言處理JSON數據格式可以使用的工具或三方庫。
{name: "Penry",age: 21,friends: ["Taco", "Cruise"],cars: [{"brand": "BMW", "max_speed": 240},{"brand": "Benz", "max_speed": 280},{"brand": "Audi", "max_speed": 280}]
}
上面是JSON的一個簡單例子,大家可能已經注意到了,它跟Python中的字典非常類似而且支持嵌套結構,就好比Python字典中的值可以是另一個字典。我們可以嘗試把下面的代碼輸入瀏覽器的控制臺(對于Chrome瀏覽器,可以通過“更多工具”菜單找到“開發者工具”子菜單,就可以打開瀏覽器的控制臺),瀏覽器的控制臺提供了一個運行JavaScript代碼的交互式環境(類似于Python的交互式環境),下面的代碼會幫我們創建出一個JavaScript的對象,我們將其賦值給名為obj的變量。
let obj = {name: "Penry",age: 21,friends: ["Taco", "Cruise"],cars: [{"brand": "BMW", "max_speed": 240},{"brand": "Benz", "max_speed": 280},{"brand": "Audi", "max_speed": 280}]
}
上面的obj就是JavaScript中的一個對象,我們可以通過obj.name或obj["name"]兩種方式獲取到name對應的值,如下圖所示。可以注意到,obj["name"]這種獲取數據的方式跟Python字典通過鍵獲取值的索引操作是完全一致的,而Python中也通過名為json的模塊提供了字典與JSON雙向轉換的支持。
我們在JSON中使用的數據類型(JavaScript數據類型)和Python中的數據類型也是很容易找到對應關系的,大家可以看看下面的兩張表。
表1:JavaScript數據類型(值)對應的Python數據類型(值)
| JSON | Python |
|---|---|
object | dict |
array | list |
string | str |
number | int / float |
number (real) | float |
boolean (true / false) | bool (True / False) |
null | None |
表2:Python數據類型(值)對應的JavaScript數據類型(值)
| Python | JSON |
|---|---|
dict | object |
list / tuple | array |
str | string |
int / float | number |
bool (True / False) | boolean (true / false) |
None | null |
2.2 讀寫JSON格式的數據
在Python中,如果要將字典處理成JSON格式(以字符串形式存在),可以使用json模塊的dumps函數,代碼如下所示。
import jsonmy_dict = {'name': 'Penry','age': 21,'friends': ['Taco', 'Cruise'],'cars': [{'brand': 'BMW', 'max_speed': 240},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 280}]
}
print(json.dumps(my_dict))
運行上面的代碼,輸出如下所示,可以注意到中文字符都是用Unicode編碼顯示的。
{"name": "Penry", "age": 21, "friends": ["Taco", "Cruise"], "cars": [{"brand": "BMW", "max_speed": 240}, {"brand": "Audi", "max_speed": 280}, {"brand": "Benz", "max_speed": 280}]}
如果要將字典處理成JSON格式并寫入文本文件,只需要將dumps函數換成dump函數并傳入文件對象即可,代碼如下所示。
import jsonmy_dict = {'name': 'Penry','age': 21,'friends': ['Taco', 'Cruise'],'cars': [{'brand': 'BMW', 'max_speed': 240},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 280}]
}try:with open("data.json", "w") as file:json.dump(my_dict, file)
except Exception as e:print(e)# 驗證json文件
try:with open("data.json", "r") as file:data = json.load(file)print(data)
except Exception as e:print(e)
執行上面的代碼,會創建data.json文件,文件的內容跟上面代碼的輸出是一樣的。
json模塊有四個比較重要的函數,分別是:
dump- 將Python對象按照JSON格式序列化到文件中dumps- 將Python對象處理成JSON格式的字符串load- 將文件中的JSON數據反序列化成對象loads- 將字符串的內容反序列化成Python對象
這里出現了兩個概念,一個叫序列化,一個叫反序列化,維基百科上的解釋是:“序列化(serialization)在計算機科學的數據處理中,是指將數據結構或對象狀態轉換為可以存儲或傳輸的形式,這樣在需要的時候能夠恢復到原先的狀態,而且通過序列化的數據重新獲取字節時,可以利用這些字節來產生原始對象的副本(拷貝)。與這個過程相反的動作,即從一系列字節中提取數據結構的操作,就是反序列化(deserialization)”。
我們可以通過下面的代碼,讀取上面創建的data.json文件,將JSON格式的數據還原成Python中的字典。
import jsonwith open('data.json', 'r') as file:my_dict = json.load(file)print(type(my_dict))print(my_dict)
2.3 包管理工具pip
Python標準庫中的json模塊在數據序列化和反序列化時性能并不是非常理想,為了解決這個問題,可以使用三方庫ujson來替換json。所謂三方庫,是指非公司內部開發和使用的,也不是來自于官方標準庫的Python模塊,這些模塊通常由其他公司、組織或個人開發,所以被稱為三方庫。雖然Python語言的標準庫雖然已經提供了諸多模塊來方便我們的開發,但是對于一個強大的語言來說,它的生態圈一定也是非常繁榮的。
之前安裝Python解釋器時,默認情況下已經勾選了安裝pip,大家可以在命令提示符或終端中通過pip --version來確定是否已經擁有了pip。pip是Python的包管理工具,通過pip可以查找、安裝、卸載、更新Python的三方庫或工具,macOS和Linux系統應該使用pip3。例如要安裝替代json模塊的ujson,可以使用下面的命令。
pip install ujson
在默認情況下,pip會訪問https://pypi.org/simple/來獲得三方庫相關的數據,但是國內訪問這個網站的速度并不是十分理想,因此國內用戶可以使用豆瓣網提供的鏡像來替代這個默認的下載源,操作如下所示。
pip install ujson
可以通過pip search命令根據名字查找需要的三方庫,可以通過pip list命令來查看已經安裝過的三方庫。如果想更新某個三方庫,可以使用pip install -U或pip install --upgrade;如果要刪除某個三方庫,可以使用pip uninstall命令。
搜索ujson三方庫。
pip search ujsonmicropython-cpython-ujson (0.2) - MicroPython module ujson ported to CPython
pycopy-cpython-ujson (0.2) - Pycopy module ujson ported to CPython
ujson (3.0.0) - Ultra fast JSON encoder and decoder for Python
ujson-bedframe (1.33.0) - Ultra fast JSON encoder and decoder for Python
ujson-segfault (2.1.57) - Ultra fast JSON encoder and decoder for Python. Continuing development.
ujson-ia (2.1.1) - Ultra fast JSON encoder and decoder for Python (Internet Archive fork)
ujson-x (1.37) - Ultra fast JSON encoder and decoder for Python
ujson-x-legacy (1.35.1) - Ultra fast JSON encoder and decoder for Python
drf_ujson (1.2) - Django Rest Framework UJSON Renderer
drf-ujson2 (1.6.1) - Django Rest Framework UJSON Renderer
ujsonDB (0.1.0) - A lightweight and simple database using ujson.
fast-json (0.3.2) - Combines best parts of json and ujson for fast serialization
decimal-monkeypatch (0.4.3) - Python 2 performance patches: decimal to cdecimal, json to ujson for psycopg2
查看已經安裝的三方庫。
pip listPackage Version
----------------------------- ----------
aiohttp 3.5.4
alipay 0.7.4
altgraph 0.16.1
amqp 2.4.2
... ...
更新ujson三方庫。
pip install -U ujson
刪除ujson三方庫。
pip uninstall -y ujson
提示:如果要更新
pip自身,對于macOS系統來說,可以使用命令pip install -U pip。在Windows系統上,可以將命令替換為python -m pip install -U --user pip。
2.4 使用網絡API獲取數據
如果想在我們自己的程序中顯示天氣、路況、航班等信息,這些信息我們自己沒有能力提供,所以必須使用網絡數據服務。目前絕大多數的網絡數據服務(或稱之為網絡API)都是基于HTTP或HTTPS提供JSON格式的數據,我們可以通過Python程序發送HTTP請求給指定的URL(統一資源定位符),這個URL就是所謂的網絡API,如果請求成功,它會返回HTTP響應,而HTTP響應的消息體中就有我們需要的JSON格式的數據。關于HTTP的相關知識,可以看看阮一峰的《HTTP協議入門》一文。
國內有很多提供網絡API接口的網站,例如聚合數據、阿凡達數據等,這些網站上有免費的和付費的數據接口,國外的{API}Search網站也提供了類似的功能,有興趣的可以自行研究。下面的例子演示了如何使用requests庫(基于HTTP進行網絡資源訪問的三方庫)訪問網絡API獲取國內新聞并顯示新聞標題和鏈接。在這個例子中,我們使用了名為天行數據的網站提供的國內新聞數據接口,其中的APIKey需要自己到網站上注冊申請。在天行數據網站注冊賬號后會自動分配APIKey,但是要訪問接口獲取數據,需要綁定驗證郵箱或手機,然后還要申請需要使用的接口,如下圖所示。

Python通過URL接入網絡,我們推薦大家使用requests三方庫,它簡單且強大,但需要自行安裝。
pip install requests
獲取國內新聞并顯示新聞標題和鏈接。
import requests
import jsondef fetch_and_save_news():"""獲取新聞數據并保存到data_news.json文件"""print("🚀 開始獲取新聞數據...")try:# 發送API請求# 注意這里參數更換為自己的APIKEYresp = requests.get("https://apis.tianapi.com/guonei/index?key=APIKEY&num=10")if resp.status_code == 200:data_model = resp.json()print("? API請求成功!")# 檢查返回的數據結構if 'result' in data_model and 'newslist' in data_model['result']:news_count = len(data_model['result']['newslist'])print(f"📊 獲取到 {news_count} 條新聞")# 保存完整數據到 data_news.jsontry:with open("data_news.json", "w", encoding="utf-8") as file:json.dump(data_model, file, ensure_ascii=False, indent=4)print("💾 新聞數據已成功保存到 data_news.json")except Exception as e:print(f"? 保存文件時出錯: {e}")return# 顯示新聞標題預覽print("\n📰 新聞列表預覽:")print("=" * 80)for i, news in enumerate(data_model['result']['newslist'], 1):print(f"{i:2d}. 📝 {news['title']}")print(f" ? 時間: {news['ctime']}")print(f" 📺 來源: {news['source']}")if news.get('picUrl'):print(f" 🖼? 圖片: 有")print("-" * 80)# 驗證保存的文件print("\n🔍 驗證保存的文件...")try:with open("data_news.json", "r", encoding="utf-8") as file:saved_data = json.load(file)saved_count = len(saved_data['result']['newslist'])print(f"? 文件驗證成功!保存了 {saved_count} 條新聞")# 顯示文件大小import osfile_size = os.path.getsize("data_news.json")print(f"📁 文件大小: {file_size} 字節 ({file_size/1024:.2f} KB)")except Exception as e:print(f"? 驗證文件時出錯: {e}")else:print("? API返回數據格式異常")print("返回的數據:", data_model)else:print(f"? 請求失敗,狀態碼: {resp.status_code}")print(f"響應內容: {resp.text}")except requests.exceptions.RequestException as e:print(f"? 網絡請求異常: {e}")except json.JSONDecodeError as e:print(f"? JSON解析錯誤: {e}")except Exception as e:print(f"? 發生未知錯誤: {e}")def read_saved_news():"""讀取并顯示保存的新聞數據"""print("\n" + "="*80)print("📖 讀取保存的新聞數據...")print("="*80)try:with open("data_news.json", "r", encoding="utf-8") as file:data = json.load(file)if 'result' in data and 'newslist' in data['result']:newslist = data['result']['newslist']print(f"📊 文件中共有 {len(newslist)} 條新聞")print(f"📅 數據獲取時間: {data.get('msg', '未知')}")# 顯示詳細新聞信息for i, news in enumerate(newslist, 1):print(f"\n📰 新聞 {i}:")print(f"📝 標題: {news['title']}")print(f"? 時間: {news['ctime']}")print(f"📺 來源: {news['source']}")print(f"🔗 鏈接: {news['url']}")if news.get('description'):print(f"📄 描述: {news['description']}")if news.get('picUrl'):print(f"🖼? 圖片: {news['picUrl']}")print("-" * 60)else:print("? 文件格式異常")except FileNotFoundError:print("? 文件 data_news.json 不存在,請先運行獲取新聞的功能")except json.JSONDecodeError:print("? 文件格式錯誤,不是有效的JSON文件")except Exception as e:print(f"? 讀取文件時出錯: {e}")if __name__ == "__main__":# 獲取并保存新聞fetch_and_save_news()# 讀取并顯示保存的新聞read_saved_news()print("\n" + "="*80)print("? 程序執行完成!")print("📁 新聞數據已保存在 data_news.json 文件中")print("="*80)
上面的代碼通過requests模塊的get函數向天行數據的國內新聞接口發起了一次請求,如果請求過程沒有出現問題,get函數會返回一個Response對象,通過該對象的status_code屬性表示HTTP響應狀態碼,如果不理解沒關系,你只需要關注它的值,如果值等于200或者其他2字頭的值,那么我們的請求是成功的。通過Response對象的json()方法可以將返回的JSON格式的數據直接處理成Python字典,非常方便。天行數據國內新聞接口返回的JSON格式的數據(部分)如下圖所示。
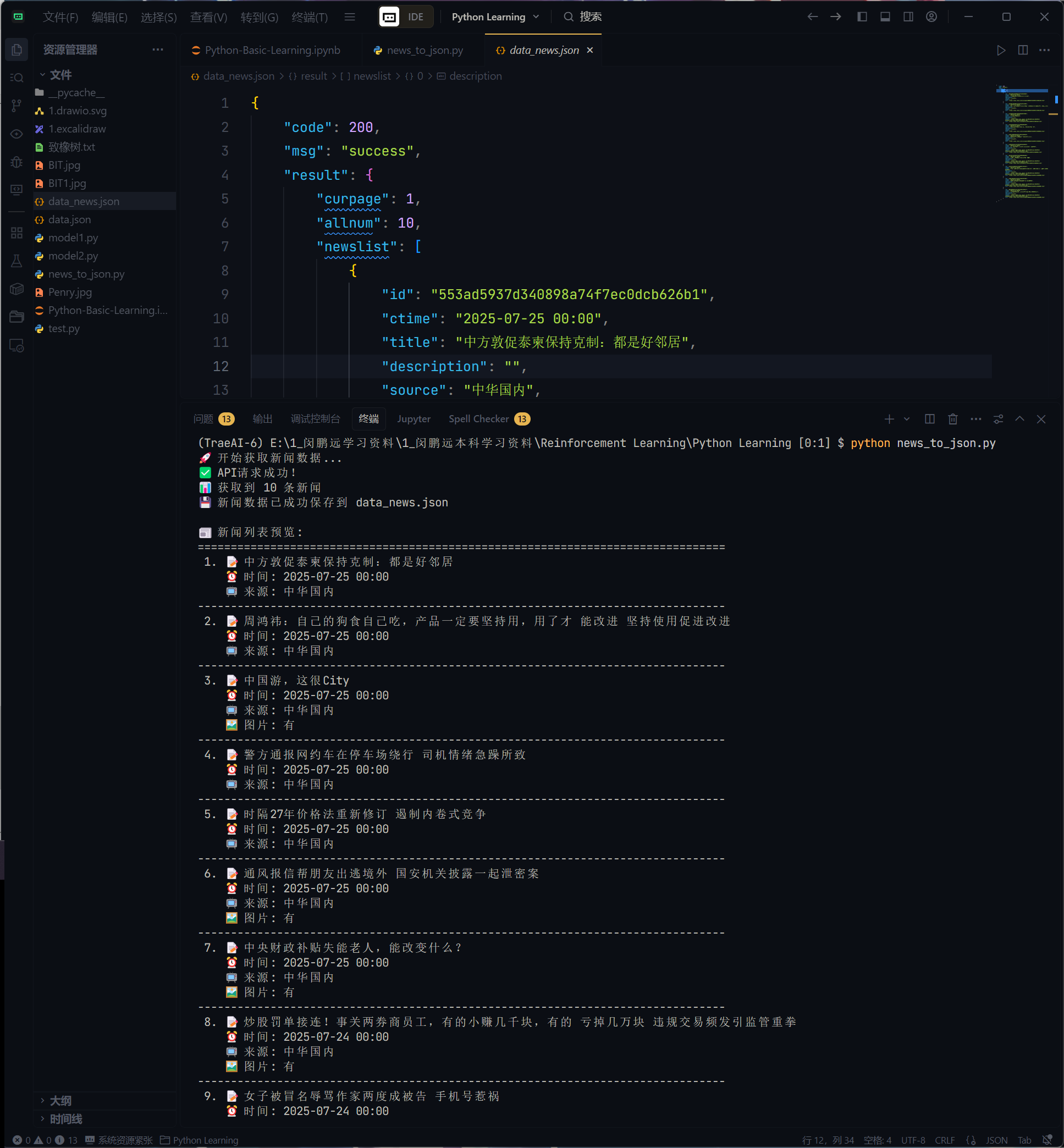
提示:上面代碼中的APIKey需要換成自己在天行數據網站申請的APIKey。天行數據網站上還有提供了很多非常有意思的API接口,例如:垃圾分類、周公解夢等,大家可以仿照上面的代碼來調用這些接口。每個接口都有對應的接口文檔,文檔中有關于如何使用接口的詳細說明。
2.5 總結
Python中實現序列化和反序列化除了使用json模塊之外,還可以使用pickle和shelve模塊,但是這兩個模塊是使用特有的序列化協議來序列化數據,因此序列化后的數據只能被Python識別,關于這兩個模塊的相關知識,有興趣的讀者可以自己查找網絡上的資料。處理JSON格式的數據很顯然是程序員必須掌握的一項技能,因為不管是訪問網絡API接口還是提供網絡API接口給他人使用,都需要具備處理JSON格式數據的相關知識。
3 Python讀寫CSV文件
3.1 CSV文件介紹
CSV(Comma Separated Values)全稱逗號分隔值文件是一種簡單、通用的文件格式,被廣泛的應用于應用程序(數據庫、電子表格等)數據的導入和導出以及異構系統之間的數據交換。因為CSV是純文本文件,不管是什么操作系統和編程語言都是可以處理純文本的,而且很多編程語言中都提供了對讀寫CSV文件的支持,因此CSV格式在數據處理和數據科學中被廣泛應用。
CSV文件有以下特點:
- 純文本,使用某種字符集(如ASCII、Unicode、GB2312)等);
- 由一條條的記錄組成(典型的是每行一條記錄);
- 每條記錄被分隔符(如逗號、分號、制表符等)分隔為字段(列);
- 每條記錄都有同樣的字段序列。
CSV文件可以使用文本編輯器或類似于Excel電子表格這類工具打開和編輯,當使用Excel這類電子表格打開CSV文件時,你甚至感覺不到CSV和Excel文件的區別。很多數據庫系統都支持將數據導出到CSV文件中,當然也支持從CSV文件中讀入數據保存到數據庫中,這些內容并不是現在要討論的重點。
3.2 將數據寫入CSV文件
現有五個學生三門課程的考試成績需要保存到一個CSV文件中,要達成這個目標,可以使用Python標準庫中的csv模塊,該模塊的writer函數會返回一個csvwriter對象,通過該對象的writerow或writerows方法就可以將數據寫入到CSV文件中,具體的代碼如下所示。
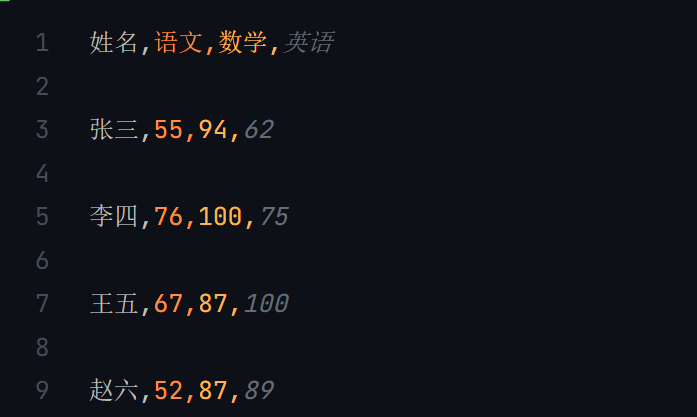
import csv
import randomwith open("scores.csv", "w") as f:writer = csv.writer(f)writer.writerow(["姓名", "語文", "數學", "英語"])names = ["張三", "李四", "王五", "趙六"]for name in names:scores = [random.randrange(50, 101) for _ in range(3)]scores.insert(0, name)writer.writerow(scores)
生成的CSV文件的內容。
需要說明的是上面的writer函數,除了傳入要寫入數據的文件對象外,還可以dialect參數,它表示CSV文件的方言,默認值是excel。除此之外,還可以通過delimiter、quotechar、quoting參數來指定分隔符(默認是逗號)、包圍值的字符(默認是雙引號)以及包圍的方式。其中,包圍值的字符主要用于當字段中有特殊符號時,通過添加包圍值的字符可以避免二義性。大家可以嘗試下面的代碼,然后查看生成的CSV文件。
import csv
import randomwith open("scores_1.csv", "w") as f:writer = csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)writer.writerow(["姓名", "語文", "數學", "英語"])names = ["張三", "李四", "王五", "趙六"]for name in names:scores = [random.randrange(50, 101) for _ in range(3)]scores.insert(0, name)writer.writerow(scores)生成的CSV文件的內容。

3.3 從CSV文件讀取數據
如果要讀取剛才創建的CSV文件,可以使用下面的代碼,通過csv模塊的reader函數可以創建出csvreader對象,該對象是一個迭代器,可以通過next函數或for-in循環讀取到文件中的數據。
import csvwith open('scores_1.csv', 'r') as f:reader = csv.reader(f, delimiter='|')for data_list in reader:print(reader.line_num, end = '\t')for elem in data_list:print(elem, end = '\t')print()
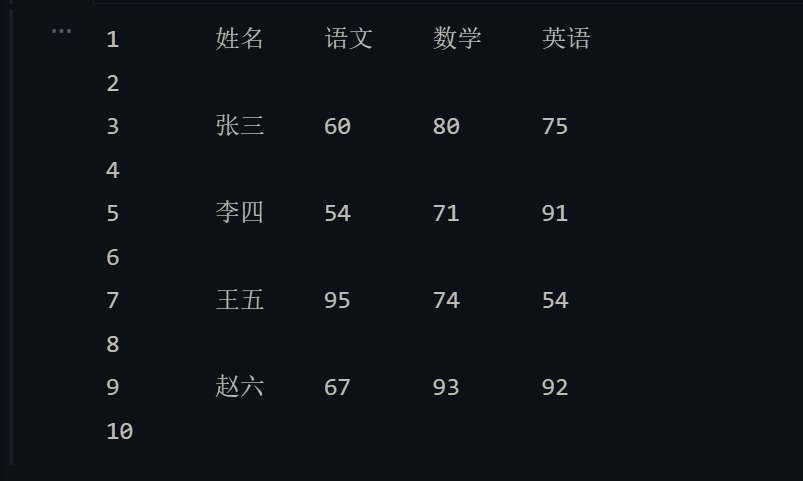
注意:上面的代碼對
csvreader對象做for循環時,每次會取出一個列表對象,該列表對象包含了一行中所有的字段。
3.4 不同引用模式對比
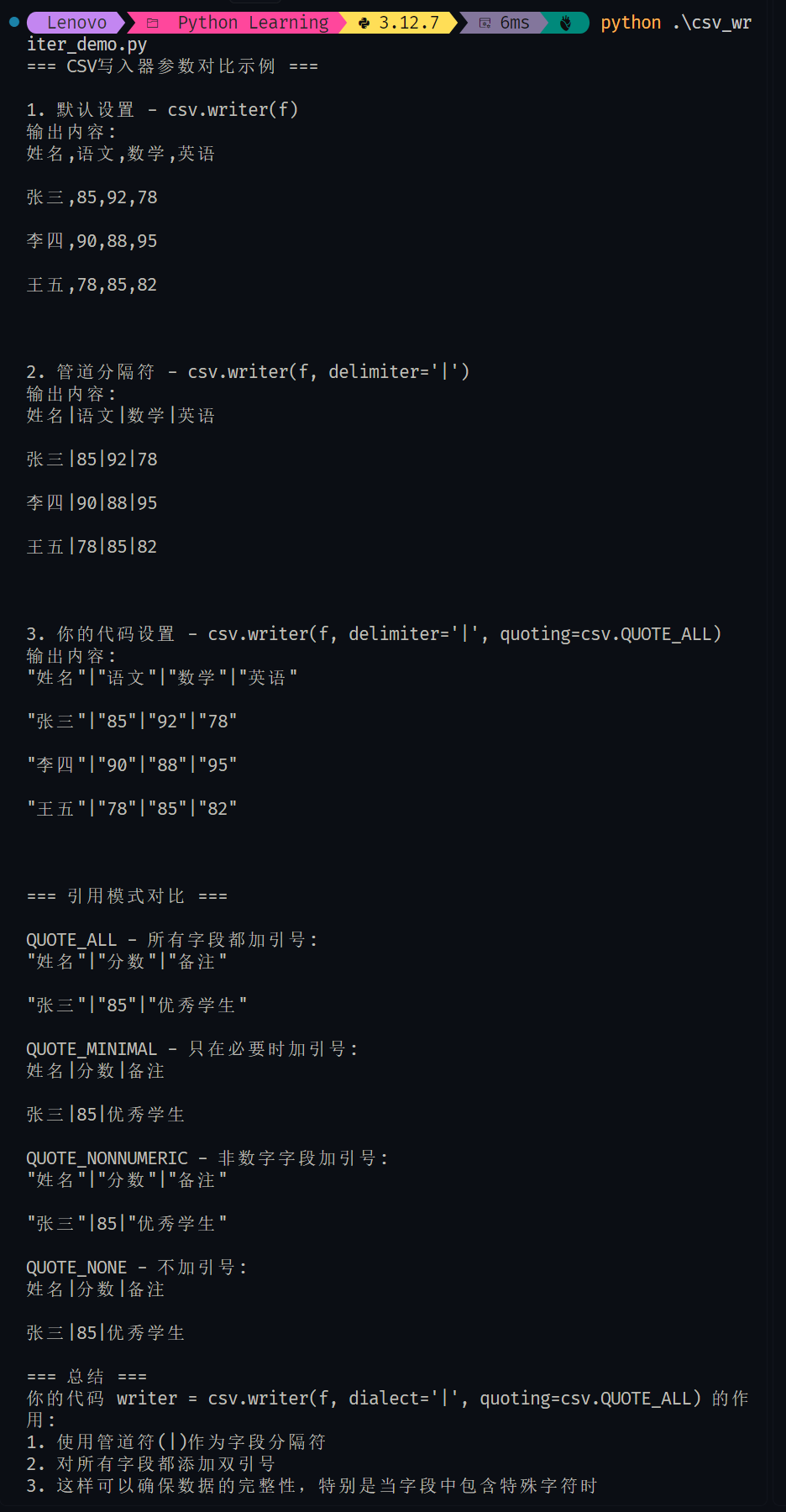
import csv# 示例數據
data = [["姓名", "語文", "數學", "英語"],["張三", 85, 92, 78],["李四", 90, 88, 95],["王五", 78, 85, 82]
]print("=== CSV寫入器參數對比示例 ===\n")# 1. 默認設置(逗號分隔,智能引用)
print("1. 默認設置 - csv.writer(f)")
with open("example_default.csv", "w", encoding="utf-8") as f:writer = csv.writer(f)for row in data:writer.writerow(row)with open("example_default.csv", "r", encoding="utf-8") as f:content = f.read()print("輸出內容:")print(content)# 2. 管道分隔符,默認引用
print("\n2. 管道分隔符 - csv.writer(f, delimiter='|')")
with open("example_pipe.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|')for row in data:writer.writerow(row)with open("example_pipe.csv", "r", encoding="utf-8") as f:content = f.read()print("輸出內容:")print(content)# 3. 管道分隔符 + 全部引用(你的代碼)
print("\n3. 你的代碼設置 - csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)")
with open("example_pipe_quote_all.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|', quoting=csv.QUOTE_ALL)for row in data:writer.writerow(row)with open("example_pipe_quote_all.csv", "r", encoding="utf-8") as f:content = f.read()print("輸出內容:")print(content)# 4. 不同引用模式對比
print("\n=== 引用模式對比 ===")quote_modes = [(csv.QUOTE_ALL, "QUOTE_ALL - 所有字段都加引號"),(csv.QUOTE_MINIMAL, "QUOTE_MINIMAL - 只在必要時加引號"),(csv.QUOTE_NONNUMERIC, "QUOTE_NONNUMERIC - 非數字字段加引號"),(csv.QUOTE_NONE, "QUOTE_NONE - 不加引號")
]for mode, description in quote_modes:print(f"\n{description}:")try:with open(f"example_{mode}.csv", "w", encoding="utf-8") as f:writer = csv.writer(f, delimiter='|', quoting=mode)writer.writerow(["姓名", "分數", "備注"])writer.writerow(["張三", 85, "優秀學生"])with open(f"example_{mode}.csv", "r", encoding="utf-8") as f:content = f.read()print(content.strip())except Exception as e:print(f"錯誤: {e}")print("\n=== 總結 ===")
print("你的代碼 writer = csv.writer(f, dialect='|', quoting=csv.QUOTE_ALL) 的作用:")
print("1. 使用管道符(|)作為字段分隔符")
print("2. 對所有字段都添加雙引號")
print("3. 這樣可以確保數據的完整性,特別是當字段中包含特殊字符時")
3.5 總結
將來如果大家使用Python做數據分析,很有可能會用到名為pandas的三方庫,它是Python數據分析的神器之一。pandas中封裝了名為read_csv和to_csv的函數用來讀寫CSV文件,其中read_CSV會將讀取到的數據變成一個DataFrame對象,而DataFrame就是pandas庫中最重要的類型,它封裝了一系列用于數據處理的方法(清洗、轉換、聚合等);而to_csv會將DataFrame對象中的數據寫入CSV文件,完成數據的持久化。read_csv函數和to_csv函數遠遠比原生的csvreader和csvwriter強大。
4 Python讀寫Excel文件-1
4.1 Excel簡介
Excel 是 Microsoft(微軟)為使用 Windows 和 macOS 操作系統開發的一款電子表格軟件。Excel 憑借其直觀的界面、出色的計算功能和圖表工具,再加上成功的市場營銷,一直以來都是最為流行的個人計算機數據處理軟件。當然,Excel 也有很多競品,例如 Google Sheets、LibreOffice Calc、Numbers 等,這些競品基本上也能夠兼容 Excel,至少能夠讀寫較新版本的 Excel 文件,當然這些不是我們討論的重點。掌握用 Python 程序操作 Excel 文件,可以讓日常辦公自動化的工作更加輕松愉快,而且在很多商業項目中,導入導出 Excel 文件都是特別常見的功能。
Python 操作 Excel 需要三方庫的支持,如果要兼容 Excel 2007 以前的版本,也就是xls格式的 Excel 文件,可以使用三方庫xlrd和xlwt,前者用于讀 Excel 文件,后者用于寫 Excel 文件。如果使用較新版本的 Excel,即xlsx格式的 Excel 文件,可以使用openpyxl庫,當然這個庫不僅僅可以操作Excel,還可以操作其他基于 Office Open XML 的電子表格文件。
本章我們先講解基于xlwt和xlrd操作 Excel 文件,大家可以先使用下面的命令安裝這兩個三方庫以及配合使用的工具模塊xlutils。
pip install xlwt xlrd xlutils
4.2 讀Excel文件
例如在當前文件夾下有一個名為“阿里巴巴2020年股票數據.xls”的 Excel 文件,如果想讀取并顯示該文件的內容,可以通過如下所示的代碼來完成。
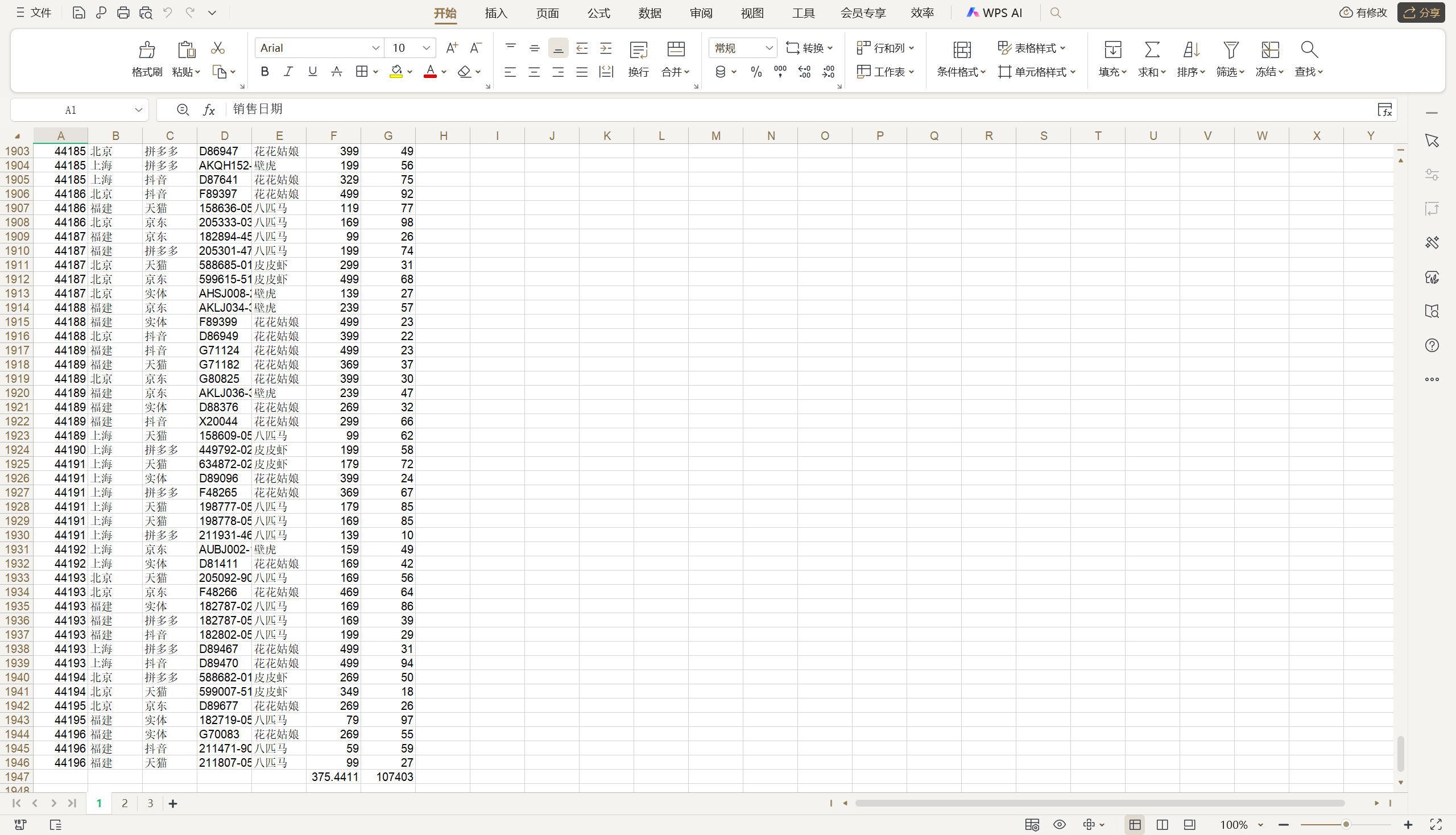
import xlrd# 使用xlrd模塊的open_workbook函數打開指定Excel文件并獲得Book對象(工作簿)
book = xlrd.open_workbook('data/阿里巴巴2020年股票數據.xls')
# 通過Book對象的sheet_names方法可以獲取所有表單名稱
sheet_names = book.sheet_names()
print(sheet_names)
# 通過指定的表單名稱獲取Sheet對象(工作表)
sheet = book.sheet_by_name(sheet_names[0])
# 通過Sheet對象的nrows和ncols屬性獲取表單的行數和列數
print(sheet.nrows,sheet.ncols)for row in range(sheet.nrows):for col in range(sheet.ncols):# 通過Sheet對象的cell方法獲取指定Cell對象(單元格)# 通過Cell對象的value屬性獲取單元格中的值value = sheet.cell(row, col).value# 對除首行外的其他行進行數據格式化處理if row > 0:# 第1列的xldate類型先轉成元組再格式化為“年月日”的格式if col == 0:# xldate_as_tuple函數的第二個參數只有0和1兩個取值# 其中0代表以1900-01-01為基準的日期,1代表以1904-01-01為基準的日期value = xlrd.xldate_as_tuple(value, 0)value = f'{value[0]}年{value[1]:>02d}月{value[2]:>02d}日'# 其他列的number類型處理成小數點后保留兩位有效數字的浮點數elif isinstance(value,(int, float)):value = f'{value:.2f}'print(value, end='\t')print()
提示:上面代碼中使用的Excel文件“阿里巴巴2020年股票數據.xls”可以通過后面的百度云盤地址進行獲取。鏈接:https://pan.quark.cn/s/dfbd00457072?pwd=n3uY。
相信通過上面的代碼,大家已經了解到了如何讀取一個 Excel 文件,如果想知道更多關于xlrd模塊的知識,可以閱讀它的官方文檔。
4.3 寫Excel文件
寫入 Excel 文件可以通過xlwt 模塊的Workbook類創建工作簿對象,通過工作簿對象的add_sheet方法可以添加工作表,通過工作表對象的write方法可以向指定單元格中寫入數據,最后通過工作簿對象的save方法將工作簿寫入到指定的文件或內存中。下面的代碼實現了將5 個學生 3 門課程的考試成績寫入 Excel 文件的操作。
import random
import xlwtstudent_names = ['Penry', 'Cruise', 'Taco', 'Ma']
scores = [[random.randrange(60, 101) for _ in range(3)] for _ in range(4)]
# 創建工作簿對象
workbook = xlwt.Workbook()
# 創建工作表對象
worksheet = workbook.add_sheet("239宿舍")
# 添加表頭
titles = ('姓名', '衛生', '健康', '體育')
for index, title in enumerate(titles):worksheet.write(0, index, title)
# 將學生姓名和得分寫入單元格
for row in range(len(scores)):worksheet.write(row + 1, 0, student_names[row])for col in range(len(scores[row])):worksheet.write(row + 1, col + 1, scores[row][col])
# 保存Excel工作簿
workbook.save('data/成績表.xls') 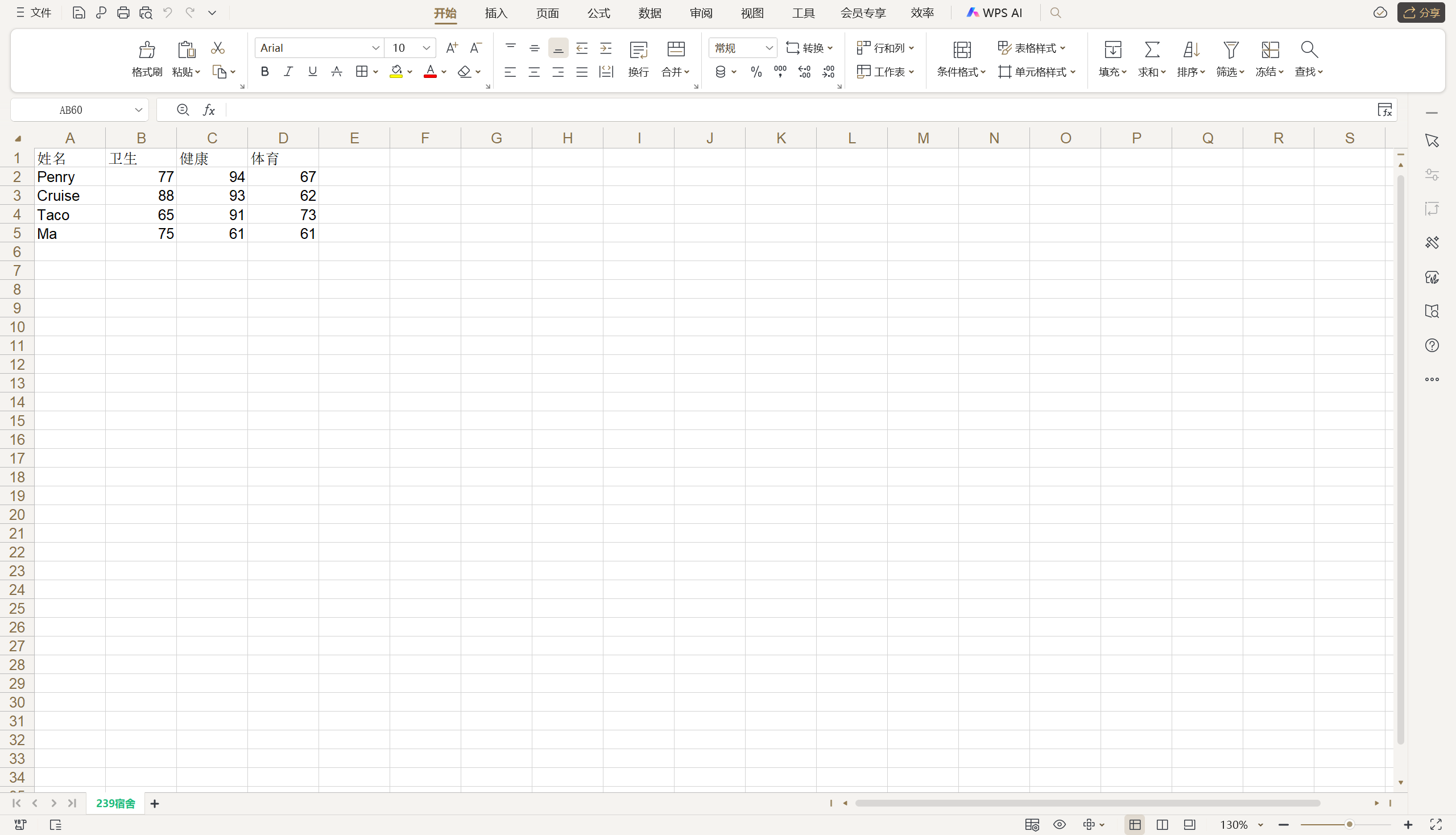
4.4 調整單元格樣式
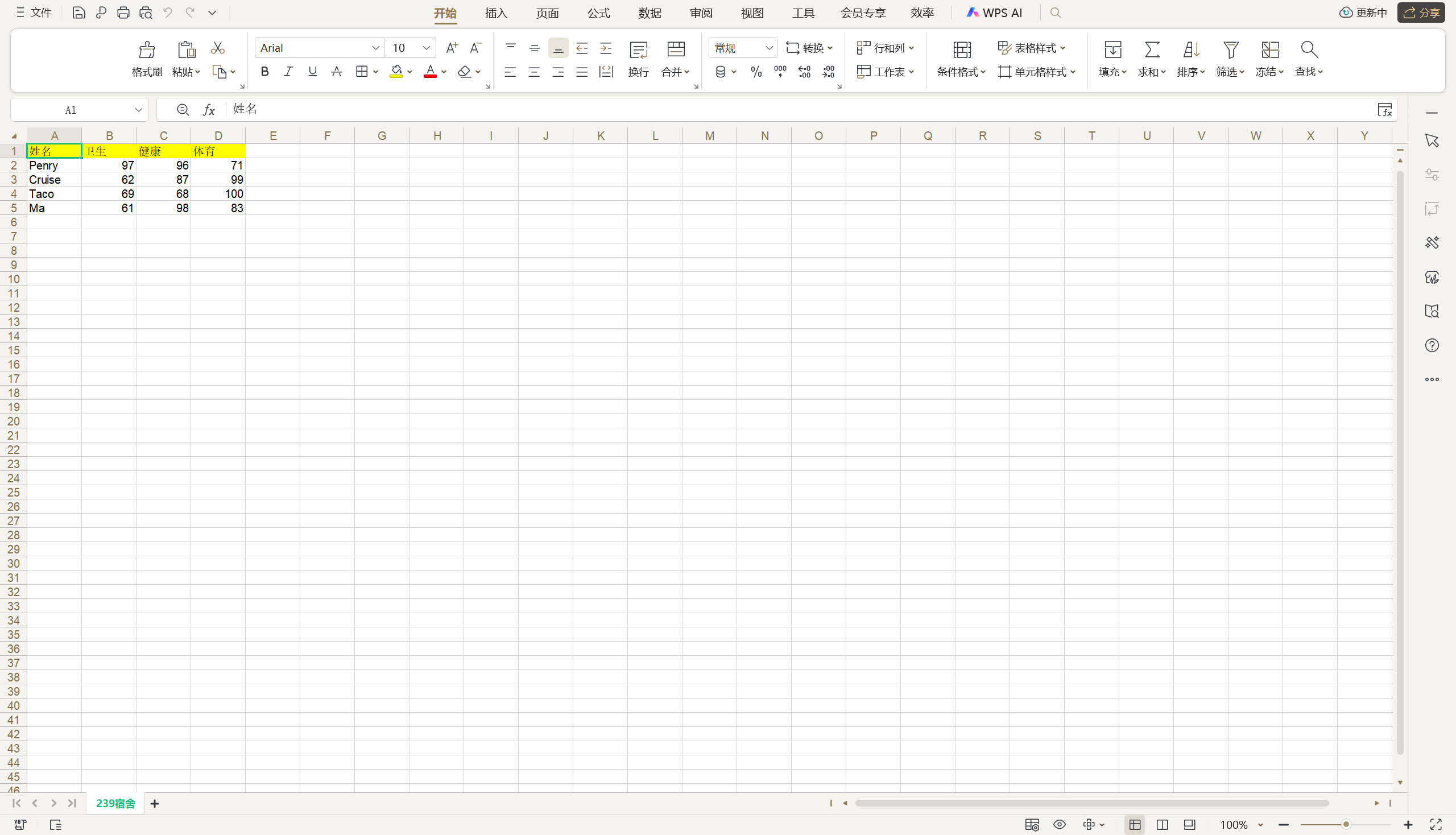
在寫Excel文件時,我們還可以為單元格設置樣式,主要包括字體(Font)、對齊方式(Alignment)、邊框(Border)和背景(Background)的設置,xlwt對這幾項設置都封裝了對應的類來支持。要設置單元格樣式需要首先創建一個XFStyle對象,再通過該對象的屬性對字體、對齊方式、邊框等進行設定,例如在上面的例子中,如果希望將表頭單元格的背景色修改為黃色,可以按照如下的方式進行操作。
header_style = xlwt.XFStyle()
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
# 0 - 黑色、1 - 白色、2 - 紅色、3 - 綠色、4 - 藍色、5 - 黃色、6 - 粉色、7 - 青色
pattern.pattern_fore_colour = 5
header_style.pattern = pattern
titles = ('姓名', '語文', '數學', '英語')
for index, title in enumerate(titles):sheet.write(0, index, title, header_style)
如果希望為表頭設置指定的字體,可以使用Font類并添加如下所示的代碼。
font = xlwt.Font()
# 字體名稱
font.name = '華文楷體'
# 字體大小(20是基準單位,18表示18px)
font.height = 20 * 18
# 是否使用粗體
font.bold = True
# 是否使用斜體
font.italic = False
# 字體顏色
font.colour_index = 1
header_style.font = font
注意:上面代碼中指定的字體名(
font.name)應當是本地系統有的字體,例如在我的電腦上有名為“華文楷體”的字體。
如果希望表頭垂直居中對齊,可以使用下面的代碼進行設置。
align = xlwt.Alignment()
# 垂直方向的對齊方式
align.vert = xlwt.Alignment.VERT_CENTER
# 水平方向的對齊方式
align.horz = xlwt.Alignment.HORZ_CENTER
header_style.alignment = align
如果希望給表頭加上黃色的虛線邊框,可以使用下面的代碼來設置。
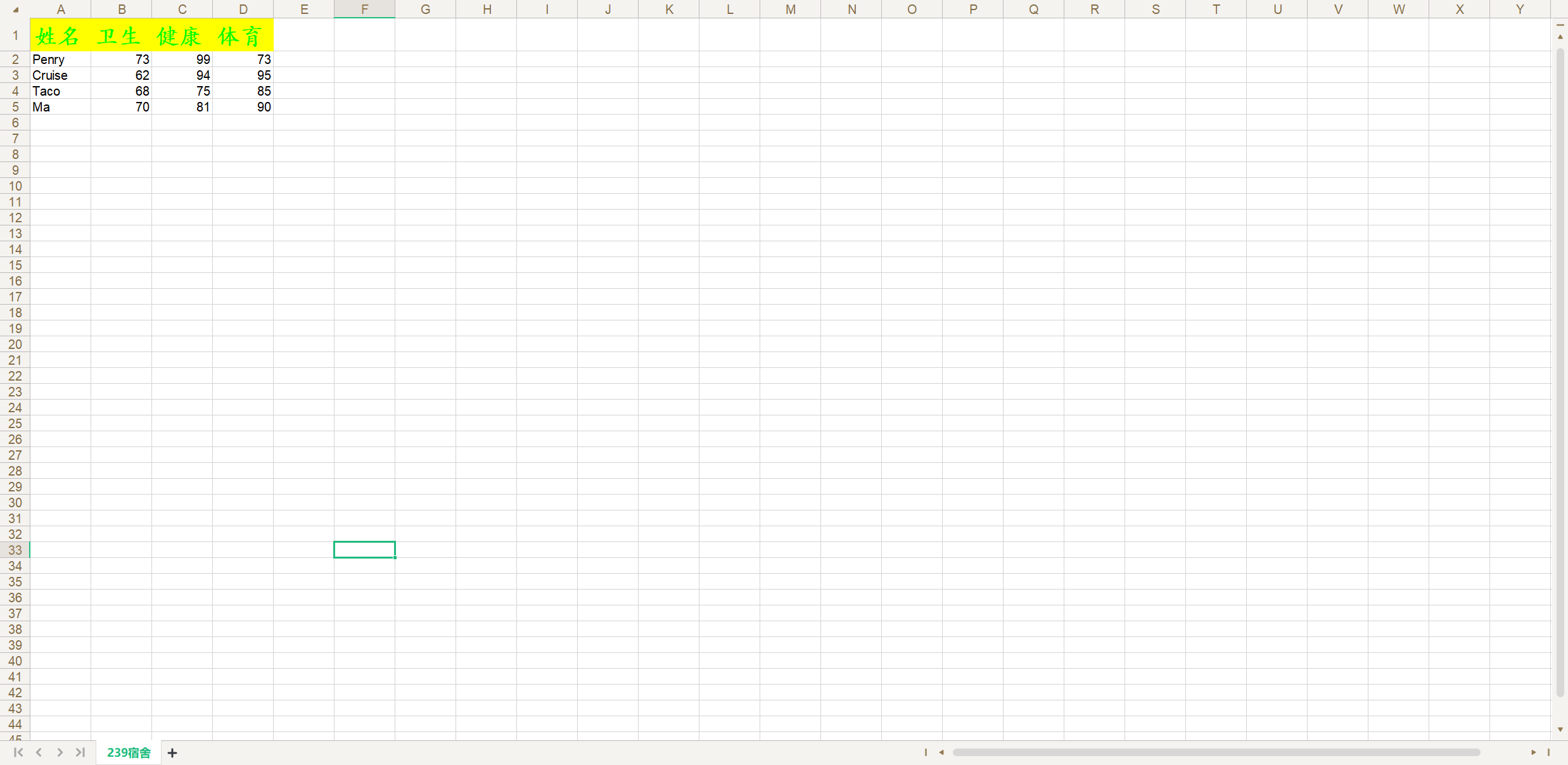
borders = xlwt.Borders()
props = (('top', 'top_colour'), ('right', 'right_colour'),('bottom', 'bottom_colour'), ('left', 'left_colour')
)
# 通過循環對四個方向的邊框樣式及顏色進行設定
for position, color in props:# 使用setattr內置函數動態給對象指定的屬性賦值setattr(borders, position, xlwt.Borders.DASHED)setattr(borders, color, 5)
header_style.borders = borders
如果要調整單元格的寬度(列寬)和表頭的高度(行高),可以按照下面的代碼進行操作。
# 設置行高為40px
sheet.row(0).set_style(xlwt.easyxf(f'font:height {20 * 40}'))
titles = ('姓名', '語文', '數學', '英語')
for index, title in enumerate(titles):# 設置列寬為200pxsheet.col(index).width = 20 * 200# 設置單元格的數據和樣式sheet.write(0, index, title, header_style)
4.5 公式計算
對于前面打開的“阿里巴巴2020年股票數據.xls”文件,如果要統計售價平均值以及銷售數量的總和,可以使用Excel的公式計算即可。我們可以先使用xlrd讀取Excel文件夾,然后通過xlutils三方庫提供的copy函數將讀取到的Excel文件轉成Workbook對象進行寫操作,在調用write方法時,可以將一個Formula對象寫入單元格。
實現公式計算的代碼如下所示。
import xlrd
import xlwt
from xlutils.copy import copywb_for_read = xlrd.open_workbook('阿里巴巴2020年股票數據.xls')
sheet1 = wb_for_read.sheet_by_index(0)
nrows, ncols = sheet1.nrows, sheet1.ncols
wb_for_write = copy(wb_for_read)
sheet2 = wb_for_write.get_sheet(0)
sheet2.write(nrows, 4, xlwt.Formula(f'average(E2:E{nrows})'))
sheet2.write(nrows, 6, xlwt.Formula(f'sum(G2:G{nrows})'))
wb_for_write.save('阿里巴巴2020年股票數據匯總.xls')
說明:上面的代碼有一些小瑕疵,有興趣的讀者可以自行探索并思考如何解決。
4.6 總結
掌握了 Python 程序操作 Excel 的方法,可以解決日常辦公中很多繁瑣的處理 Excel 電子表格工作,最常見就是將多個數據格式相同的 Excel 文件合并到一個文件以及從多個 Excel 文件或表單中提取指定的數據。當然,如果要對表格數據進行處理,使用 Python 數據分析神器之一的 pandas 庫可能更為方便。
5 Python讀寫Excel文件-2
5.1 Excel簡介
Excel 是 Microsoft(微軟)為使用 Windows 和 macOS 操作系統開發的一款電子表格軟件。Excel 憑借其直觀的界面、出色的計算功能和圖表工具,再加上成功的市場營銷,一直以來都是最為流行的個人計算機數據處理軟件。當然,Excel 也有很多競品,例如 Google Sheets、LibreOffice Calc、Numbers 等,這些競品基本上也能夠兼容 Excel,至少能夠讀寫較新版本的 Excel 文件,當然這些不是我們討論的重點。掌握用 Python 程序操作 Excel 文件,可以讓日常辦公自動化的工作更加輕松愉快,而且在很多商業項目中,導入導出 Excel 文件都是特別常見的功能。
本章我們繼續講解基于另一個三方庫openpyxl如何進行 Excel 文件操作,首先需要先安裝它。
pip install openpyxl
openpyxl的優點在于,當我們打開一個 Excel 文件后,既可以對它進行讀操作,又可以對它進行寫操作,而且在操作的便捷性上是優于xlwt和xlrd的。此外,如果要進行樣式編輯和公式計算,使用openpyxl也遠比上一個章節我們講解的方式更為簡單,而且openpyxl還支持數據透視和插入圖表等操作,功能非常強大。有一點需要再次強調,openpyxl并不支持操作 Office 2007 以前版本的 Excel 文件。
5.2 讀取Excel文件
例如在data文件夾下有一個名為“阿里巴巴2020年股票數據.xlsx”的 Excel 文件,如果想讀取并顯示該文件的內容,可以通過如下所示的代碼來完成。
import datetime
import openpyxl# 加載一個工作簿 ---> Workbook
wb = openpyxl.load_workbook('data/阿里巴巴2020年股票數據.xlsx')
# 獲取工作表名稱
print(wb.sheetnames)
# 獲取工作表 ---> Worksheet
sheet = wb.worksheets[0]
# 獲取單元格范圍
print(sheet.dimensions)
# 獲取行數和列數
print(sheet.max_row, sheet.max_column)# 獲取指定單元格的值
print(sheet.cell(3, 3).value)
print(sheet['C3'].value)
print(sheet['G255'].value)# 獲取多個單元格(嵌套元組)
print(sheet['A2:C5'])# 讀取所有單元格的數據
for row_ch in range(2, sheet.max_row + 1):for col_ch in 'ABCDEFG':value = sheet[f'{col_ch}{row_ch}'].valueif type(value) == datetime.datetime:print(value.strftime('%Y年%m月%d日'), end='\t')elif type(value) == int:print(f'{value:<10d}', end='\t')elif type(value) == float:print(f'{value:.4f}', end='\t')else:print(value, end='\t')print()
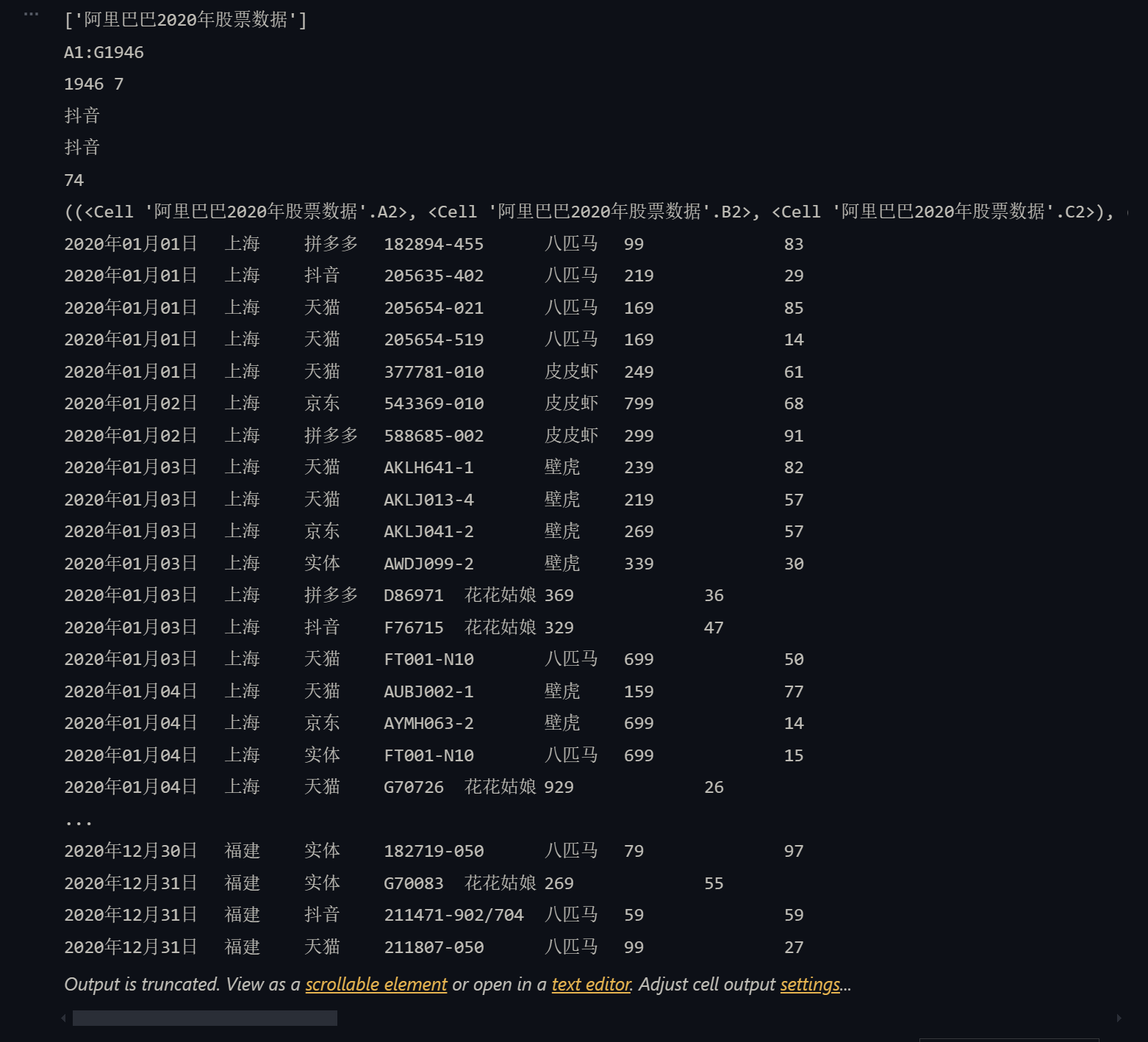
需要提醒大家一點,openpyxl獲取指定的單元格有兩種方式,一種是通過cell方法,需要注意,該方法的行索引和列索引都是從1開始的,這是為了照顧用慣了 Excel 的人的習慣;另一種是通過索引運算,通過指定單元格的坐標,例如C3、G255,也可以取得對應的單元格,再通過單元格對象的value屬性,就可以獲取到單元格的值。通過上面的代碼,相信大家還注意到了,可以通過類似sheet['A2:C5']或sheet['A2':'C5']這樣的切片操作獲取多個單元格,該操作將返回嵌套的元組,相當于獲取到了多行多列。
5.3 寫Excel文件
下面我們使用openpyxl來進行寫 Excel 操作。
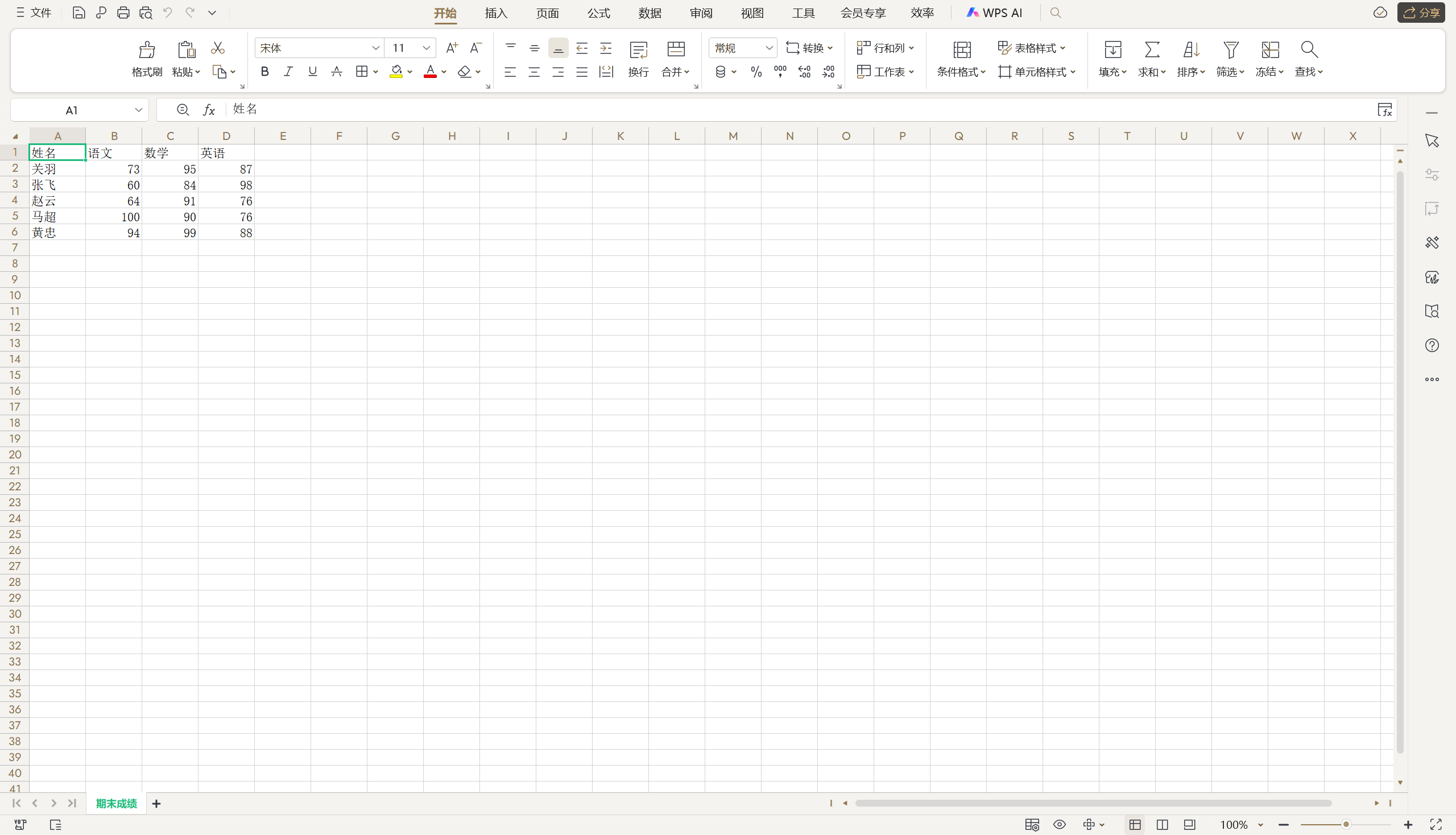
import openpyxl
import random# 第一步:創建工作簿(Workbook)
wb = openpyxl.Workbook()# 第二步:添加工作表(Worksheet)
sheet = wb.active
sheet.title = '期末成績'# 第三步:寫入數據titles = ('姓名', '語文', '數學', '英語')
for col_index, title in enumerate(titles):sheet.cell(1, col_index+1, title)names = ('關羽', '張飛', '趙云', '馬超', '黃忠')
for row_index, name in enumerate(names):sheet.cell(row_index+2, 1, name)for col_index in range(2, 5):sheet.cell(row_index+2, col_index, random.randrange(60, 101))# 第四步:保存工作簿
wb.save('data/期末成績.xlsx')
5.4 調整樣式和公式計算
在使用openpyxl操作 Excel 時,如果要調整單元格的樣式,可以直接通過單元格對象(Cell對象)的屬性進行操作。單元格對象的屬性包括字體(font)、對齊(alignment)、邊框(border)等,具體的可以參考openpyxl的官方文檔。在使用openpyxl時,如果需要做公式計算,可以完全按照 Excel 中的操作方式來進行,具體的代碼如下所示。
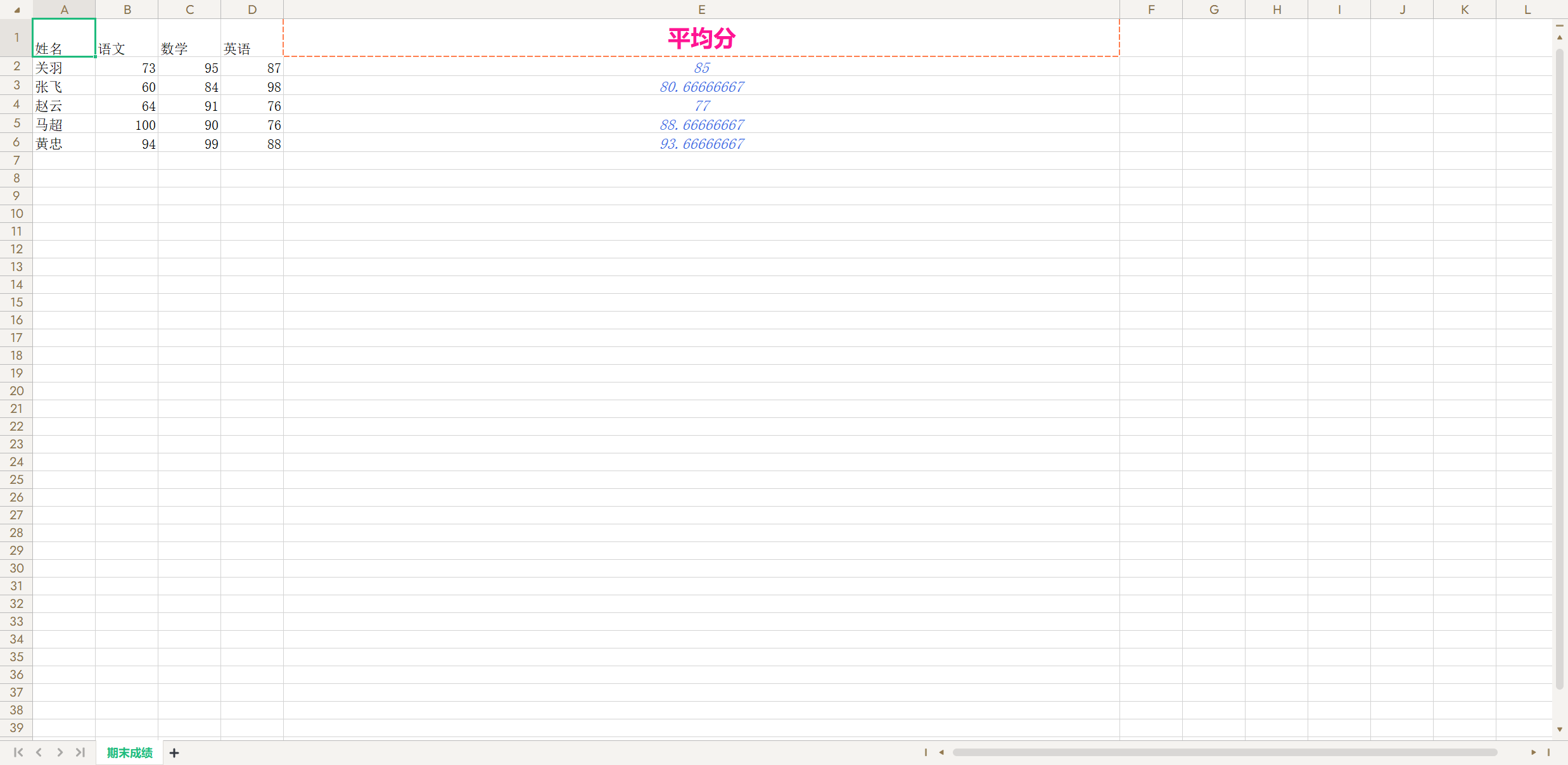
import openpyxl
from openpyxl.styles import Font, Alignment, Border, Side# 對齊方式
alignment = Alignment(horizontal='center', vertical='center')
# 邊框線條
side = Side(style='mediumDashed', color='ff7f50')wb = openpyxl.load_workbook('data/期末成績.xlsx')
sheet = wb.worksheets[0]# 調整行高和行寬
sheet.row_dimensions[1].height = 30
sheet.column_dimensions['E'].width = 120sheet['E1'] = '平均分'# 設置字體
sheet.cell(1, 5).font = Font(name='微軟雅黑', size=18, bold=True, color='ff1493')
# 設置對齊方式
sheet.cell(1, 5).alignment = alignment
# 設置單元格邊框
sheet.cell(1, 5).border = Border(left=side, top=side, right=side, bottom=side)
for i in range(2, 7):# 公式計算每個學生的平均分sheet[f'E{i}'] = f'=average(B{i}:D{i})'sheet.cell(i, 5).font = Font(size=12, color='4169e1', italic=True)sheet.cell(i, 5).alignment = alignmentwb.save('data/考試成績表.xlsx')
5.5 生成統計圖表
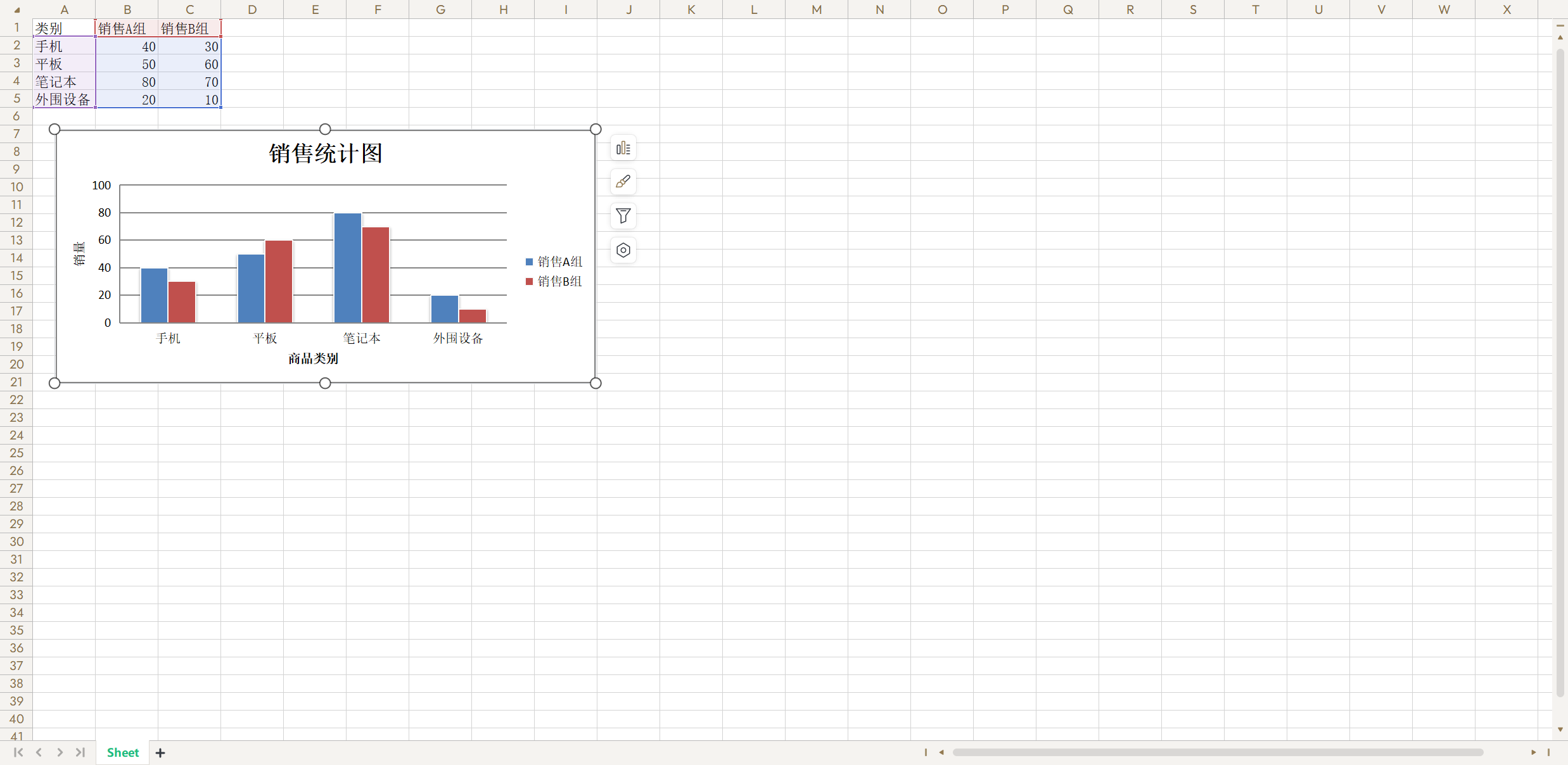
通過openpyxl庫,可以直接向 Excel 中插入統計圖表,具體的做法跟在 Excel 中插入圖表大體一致。我們可以創建指定類型的圖表對象,然后通過該對象的屬性對圖表進行設置。當然,最為重要的是為圖表綁定數據,即橫軸代表什么,縱軸代表什么,具體的數值是多少。最后,可以將圖表對象添加到表單中,具體的代碼如下所示。
from openpyxl import Workbook
from openpyxl.chart import BarChart, Referencewb = Workbook(write_only=True)
sheet = wb.create_sheet()rows = [('類別', '銷售A組', '銷售B組'),('手機', 40, 30),('平板', 50, 60),('筆記本', 80, 70),('外圍設備', 20, 10),
]# 向表單中添加行
for row in rows:sheet.append(row)# 創建圖表對象
chart = BarChart()
chart.type = 'col'
chart.style = 10
# 設置圖表的標題
chart.title = '銷售統計圖'
# 設置圖表縱軸的標題
chart.y_axis.title = '銷量'
# 設置圖表橫軸的標題
chart.x_axis.title = '商品類別'
# 設置數據的范圍
data = Reference(sheet, min_col=2, min_row=1, max_row=5, max_col=3)
# 設置分類的范圍
cats = Reference(sheet, min_col=1, min_row=2, max_row=5)
# 給圖表添加數據
chart.add_data(data, titles_from_data=True)
# 給圖表設置分類
chart.set_categories(cats)
chart.shape = 4
# 將圖表添加到表單指定的單元格中
sheet.add_chart(chart, 'A10')wb.save('demo.xlsx')
運行上面的代碼,打開生成的 Excel 文件,效果如下圖所示。
5.6 總結
掌握了 Python 程序操作 Excel 的方法,可以解決日常辦公中很多繁瑣的處理 Excel 電子表格工作,最常見就是將多個數據格式相同的Excel 文件合并到一個文件以及從多個 Excel 文件或表單中提取指定的數據。如果數據體量較大或者處理數據的方式比較復雜,我們還是推薦大家使用 Python 數據分析神器之一的 pandas 庫。
6 Python操作Word和PowerPoint文件
在日常工作中,有很多簡單重復的勞動其實完全可以交給 Python 程序,比如根據樣板文件(模板文件)批量的生成很多個 Word 文件或 PowerPoint 文件。Word 是微軟公司開發的文字處理程序,相信大家都不陌生,日常辦公中很多正式的文檔都是用 Word 進行撰寫和編輯的,目前使用的 Word 文件后綴名一般為.docx。PowerPoint 是微軟公司開發的演示文稿程序,是微軟的 Office 系列軟件中的一員,被商業人士、教師、學生等群體廣泛使用,通常也將其稱之為“幻燈片”。在 Python 中,可以使用名為python-docx 的三方庫來操作 Word,可以使用名為python-pptx的三方庫來生成 PowerPoint。
6.1 操作Word文檔
我們可以先通過下面的命令來安裝python-docx三方庫。
pip install python-docx
按照官方文檔的介紹,我們可以使用如下所示的代碼來生成一個簡單的 Word 文檔。
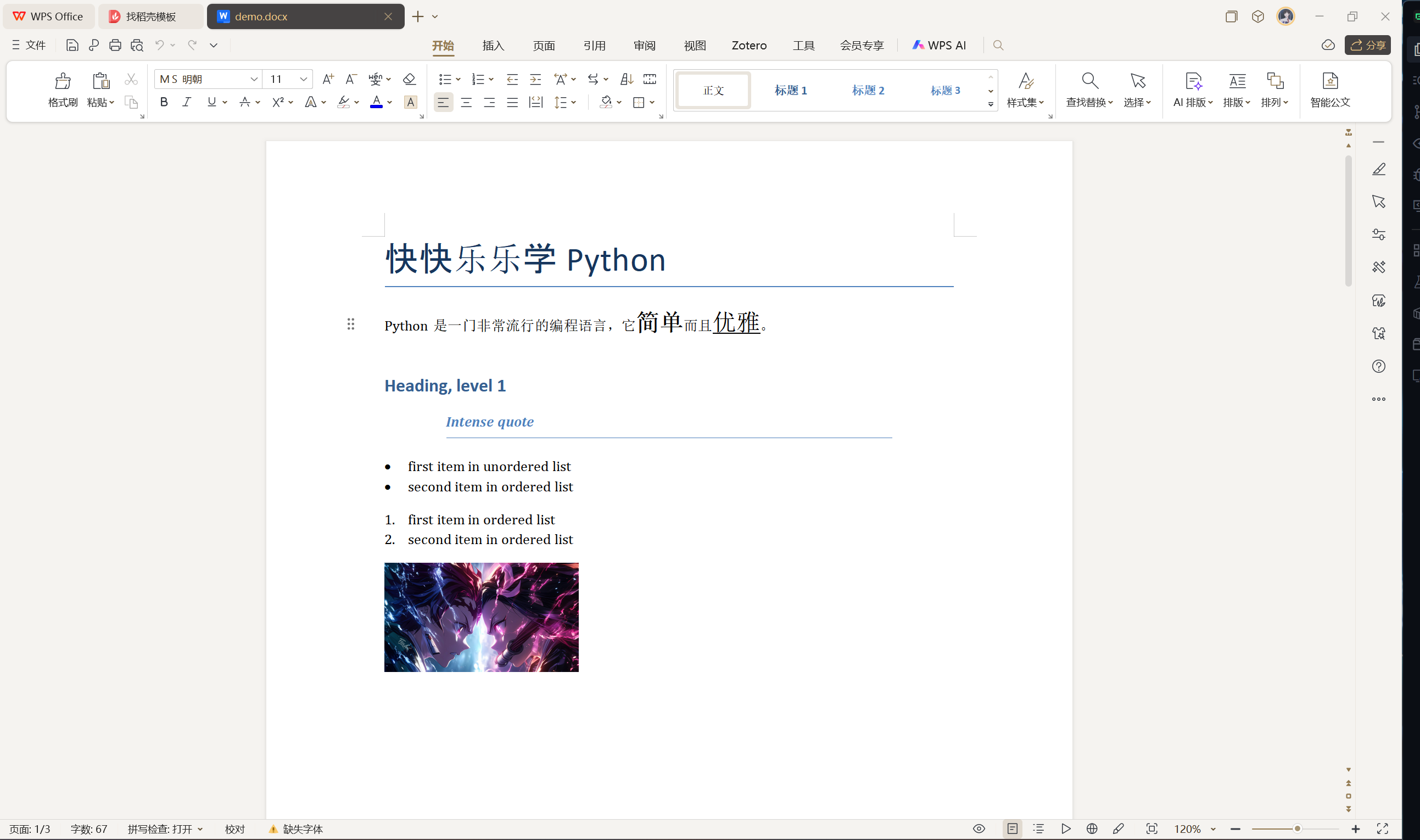
from docx import Document
from docx.shared import Cm, Ptfrom docx.document import Document as Doc# 創建代表Word文檔的Doc對象
document = Document() # type: Doc
# 添加大標題
document.add_heading('快快樂樂學Python', 0)
# 添加段落
p = document.add_paragraph('Python是一門非常流行的編程語言,它')
run = p.add_run('簡單')
run.bold = True
run.font.size = Pt(18)
p.add_run('而且')
run = p.add_run('優雅')
run.font.size = Pt(18)
run.underline = True
p.add_run('。')# 添加一級標題
document.add_heading('Heading, level 1', level=1)
# 添加帶樣式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
# 添加無序列表
document.add_paragraph('first item in unordered list', style='List Bullet'
)
document.add_paragraph('second item in ordered list', style='List Bullet'
)
# 添加有序列表
document.add_paragraph('first item in ordered list', style='List Number'
)
document.add_paragraph('second item in ordered list', style='List Number'
)# 添加圖片(注意路徑和圖片必須要存在)
document.add_picture('resources/dm10.jpg', width=Cm(5.2))# 添加分節符
document.add_section()records = (('Penry', '男', '2004-05'),('Doudou', '女', '2005-05')
)
# 添加表格
table = document.add_table(rows=1, cols=3)
table.style = 'Dark List'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '姓名'
hdr_cells[1].text = '性別'
hdr_cells[2].text = '出生日期'
# 為表格添加行
for name, sex, birthday in records:row_cells = table.add_row().cellsrow_cells[0].text = namerow_cells[1].text = sexrow_cells[2].text = birthday# 添加分頁符
document.add_page_break()# 保存文檔
document.save('Intermediate file/demo.docx')
提示:上面代碼第7行中的注釋
# type: Doc是為了在PyCharm中獲得代碼補全提示,因為如果不清楚對象具體的數據類型,PyCharm 無法在后續代碼中給出Doc對象的代碼補全提示。
執行上面的代碼,打開生成的 Word 文檔,效果如下圖所示。
對于一個已經存在的 Word 文件,我們可以通過下面的代碼去遍歷它所有的段落并獲取對應的內容。
from docx import Document
from docx.document import Document as Docdoc = Document('resources/離職證明.docx') # type: Doc
for no, p in enumerate(doc.paragraphs):print(no, p.text)
提示:如果需要上面代碼中的 Word 文件,可以通過下面的百度云盤地址進行獲取。鏈接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g 提取碼:e7b4。
讀取到的內容如下所示。
0 快快樂樂學Python
1 Python是一門非常流行的編程語言,它簡單而且優雅。
2 Heading, level 1
3 Intense quote
4 first item in unordered list
5 second item in ordered list
6 first item in ordered list
7 second item in ordered list
8
9
10
講到這里,相信很多讀者已經想到了,我們可以把離職證明制作成一個模板文件,把姓名、身份證號、入職和離職日期等信息用占位符代替,這樣通過對占位符的替換,就可以根據實際需要寫入對應的信息,這樣就可以批量的生成 Word 文檔。
按照上面的思路,我們首先編輯一個離職證明的模板文件,如下圖所示。

接下來我們讀取該文件,將占位符替換為真實信息,就可以生成一個新的 Word 文檔,如下所示。
from docx import Document
from docx.document import Document as Doc# 將真實信息用字典的方式保存在列表中
employees = [{'name': '趙云','id': '100200198011280001','sdate': '2008年3月1日','edate': '2012年2月29日','department': '產品研發','position': '架構師','company': '成都華為技術有限公司'},{'name': '王大錘','id': '510210199012125566','sdate': '2019年1月1日','edate': '2021年4月30日','department': '產品研發','position': 'Python開發工程師','company': '成都谷道科技有限公司'},{'name': '李元芳','id': '2102101995103221599','sdate': '2020年5月10日','edate': '2021年3月5日','department': '產品研發','position': 'Java開發工程師','company': '同城企業管理集團有限公司'},
]
# 對列表進行循環遍歷,批量生成Word文檔
for emp_dict in employees:# 讀取離職證明模板文件doc = Document('resources/離職證明模板.docx') # type: Doc# 循環遍歷所有段落尋找占位符for p in doc.paragraphs:if '{' not in p.text:continue# 不能直接修改段落內容,否則會丟失樣式# 所以需要對段落中的元素進行遍歷并進行查找替換for run in p.runs:if '{' not in run.text:continue# 將占位符換成實際內容start, end = run.text.find('{'), run.text.find('}')key, place_holder = run.text[start + 1:end], run.text[start:end + 1]run.text = run.text.replace(place_holder, emp_dict[key])# 每個人對應保存一個Word文檔doc.save(f'{emp_dict["name"]}離職證明.docx')
執行上面的代碼,會在當前路徑下生成三個 Word 文檔。
6.2 生成PowerPoint
首先我們需要安裝名為python-pptx的三方庫,命令如下所示。
pip install python-pptx
用 Python 操作 PowerPoint 的內容,因為實際應用場景不算很多,我不打算在這里進行贅述,有興趣的讀者可以自行閱讀python-pptx的官方文檔,下面僅展示一段來自于官方文檔的代碼。
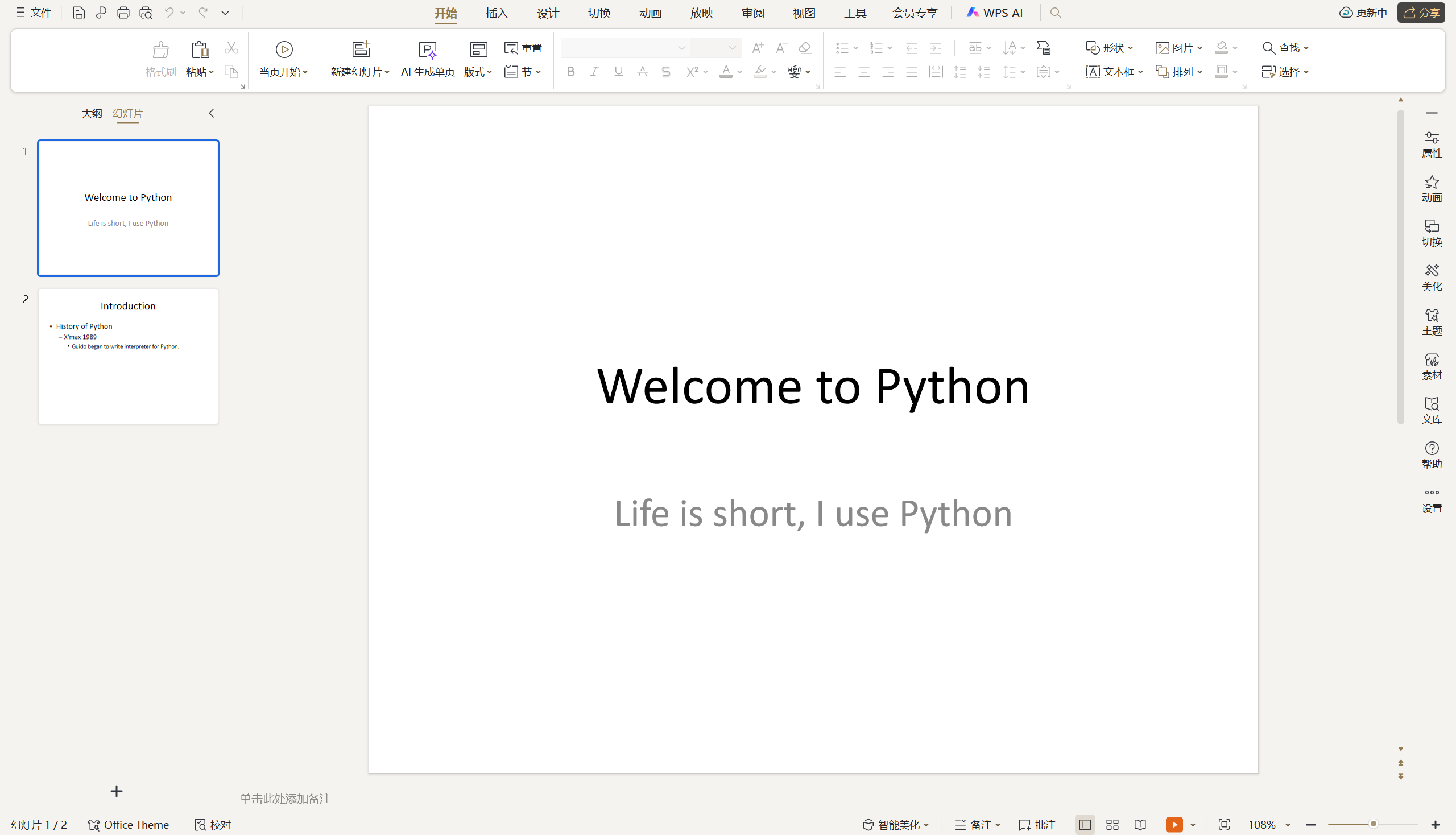
from pptx import Presentation# 創建幻燈片對象
pres = Presentation()# 選擇母版添加一頁
title_slide_layout = pres.slide_layouts[0]
slide = pres.slides.add_slide(title_slide_layout)
# 獲取標題欄和副標題欄
title = slide.shapes.title
subtitle = slide.placeholders[1]
# 編輯標題和副標題
title.text = "Welcome to Python"
subtitle.text = "Life is short, I use Python"# 選擇母版添加一頁
bullet_slide_layout = pres.slide_layouts[1]
slide = pres.slides.add_slide(bullet_slide_layout)
# 獲取頁面上所有形狀
shapes = slide.shapes
# 獲取標題和主體
title_shape = shapes.title
body_shape = shapes.placeholders[1]
# 編輯標題
title_shape.text = 'Introduction'
# 編輯主體內容
tf = body_shape.text_frame
tf.text = 'History of Python'
# 添加一個一級段落
p = tf.add_paragraph()
p.text = 'X\'max 1989'
p.level = 1
# 添加一個二級段落
p = tf.add_paragraph()
p.text = 'Guido began to write interpreter for Python.'
p.level = 2# 保存幻燈片
pres.save('test.pptx')
運行上面的代碼,生成的 PowerPoint 文件如下圖所示。
6.3 總結
用 Python 程序解決辦公自動化的問題真的非常酷,它可以將我們從繁瑣乏味的勞動中解放出來。寫這類代碼就是去做一件一勞永逸的事情,寫代碼的過程即便不怎么愉快,使用這些代碼的時候應該是非常開心的。
7 正則表達式的應用
7.1 正則表達式相關知識
在編寫處理字符串的程時,經常會遇到在一段文本中查找符合某些規則的字符串的需求,正則表達式就是用于描述這些規則的工具,換句話說,我們可以使用正則表達式來定義字符串的匹配模式,即如何檢查一個字符串是否有跟某種模式匹配的部分或者從一個字符串中將與模式匹配的部分提取出來或者替換掉。
舉一個簡單的例子,如果你在 Windows 操作系統中使用過文件查找并且在指定文件名時使用過通配符(*和?),那么正則表達式也是與之類似的用 來進行文本匹配的工具,只不過比起通配符正則表達式更強大,它能更精確地描述你的需求,當然你付出的代價是書寫一個正則表達式比使用通配符要復雜得多,因為任何給你帶來好處的東西都需要你付出對應的代價。
再舉一個例子,我們從某個地方(可能是一個文本文件,也可能是網絡上的一則新聞)獲得了一個字符串,希望在字符串中找出手機號和座機號。當然我們可以設定手機號是 11 位的數字(注意并不是隨機的 11 位數字,因為你沒有見過“25012345678”這樣的手機號),而座機號則是類似于“區號-號碼”這樣的模式,如果不使用正則表達式要完成這個任務就會比較麻煩。最初計算機是為了做數學運算而誕生的,處理的信息基本上都是數值,而今天我們在日常工作中處理的信息很多都是文本數據,我們希望計算機能夠識別和處理符合某些模式的文本,正則表達式就顯得非常重要了。今天幾乎所有的編程語言都提供了對正則表達式操作的支持,Python 通過標準庫中的re模塊來支持正則表達式操作。
關于正則表達式的相關知識,大家可以閱讀一篇非常有名的博文叫《正則表達式30分鐘入門教程》,讀完這篇文章后你就可以看懂下面的表格,這是我們對正則表達式中的一些基本符號進行的扼要總結。
| 符號 | 解釋 | 示例 | 說明 |
|---|---|---|---|
. | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 |
\w | 匹配字母/數字/下劃線 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t |
\s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you |
\d | 匹配數字 | \d\d | 可以匹配01 / 23 / 99等 |
\b | 匹配單詞的邊界 | \bThe\b | |
^ | 匹配字符串的開始 | ^The | 可以匹配The開頭的字符串 |
$ | 匹配字符串的結束 | .exe$ | 可以匹配.exe結尾的字符串 |
\W | 匹配非字母/數字/下劃線 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 |
\S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you |
\D | 匹配非數字 | \d\D | 可以匹配9a / 3# / 0F等 |
\B | 匹配非單詞邊界 | \Bio\B | |
[] | 匹配來自字符集的任意單一字符 | [aeiou] | 可以匹配任一元音字母字符 |
[^] | 匹配不在字符集中的任意單一字符 | [^aeiou] | 可以匹配任一非元音字母字符 |
* | 匹配0次或多次 | \w* | |
+ | 匹配1次或多次 | \w+ | |
? | 匹配0次或1次 | \w? | |
{N} | 匹配N次 | \w{3} | |
{M,} | 匹配至少M次 | \w{3,} | |
{M,N} | 匹配至少M次至多N次 | \w{3,6} | |
| | 分支 | foo|bar | 可以匹配foo或者bar |
(?#) | 注釋 | ||
(exp) | 匹配exp并捕獲到自動命名的組中 | ||
(?<name>exp) | 匹配exp并捕獲到名為name的組中 | ||
(?:exp) | 匹配exp但是不捕獲匹配的文本 | ||
(?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I’m dancing中的danc |
(?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一個ing |
(?!exp) | 匹配后面不是exp的位置 | ||
(?<!exp) | 匹配前面不是exp的位置 | ||
*? | 重復任意次,但盡可能少重復 | a.*ba.*?b | 將正則表達式應用于aabab,前者會匹配整個字符串aabab,后者會匹配aab和ab兩個字符串 |
+? | 重復1次或多次,但盡可能少重復 | ||
?? | 重復0次或1次,但盡可能少重復 | ||
{M,N}? | 重復M到N次,但盡可能少重復 | ||
{M,}? | 重復M次以上,但盡可能少重復 |
說明: 如果需要匹配的字符是正則表達式中的特殊字符,那么可以使用
\進行轉義處理,例如想匹配小數點可以寫成\.就可以了,因為直接寫.會匹配任意字符;同理,想匹配圓括號必須寫成\(和\),否則圓括號被視為正則表達式中的分組。
7.2 Python對正則表達式的支持
Python 提供了re模塊來支持正則表達式相關操作,下面是re模塊中的核心函數。
| 函數 | 說明 |
|---|---|
compile(pattern, flags=0) | 編譯正則表達式返回正則表達式對象 |
match(pattern, string, flags=0) | 用正則表達式匹配字符串 成功返回匹配對象 否則返回None |
search(pattern, string, flags=0) | 搜索字符串中第一次出現正則表達式的模式 成功返回匹配對象 否則返回None |
split(pattern, string, maxsplit=0, flags=0) | 用正則表達式指定的模式分隔符拆分字符串 返回列表 |
sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替換原字符串中與正則表達式匹配的模式 可以用count指定替換的次數 |
fullmatch(pattern, string, flags=0) | match函數的完全匹配(從字符串開頭到結尾)版本 |
findall(pattern, string, flags=0) | 查找字符串所有與正則表達式匹配的模式 返回字符串的列表 |
finditer(pattern, string, flags=0) | 查找字符串所有與正則表達式匹配的模式 返回一個迭代器 |
purge() | 清除隱式編譯的正則表達式的緩存 |
re.I / re.IGNORECASE | 忽略大小寫匹配標記 |
re.M / re.MULTILINE | 多行匹配標記 |
說明: 上面提到的
re模塊中的這些函數,實際開發中也可以用正則表達式對象(Pattern對象)的方法替代對這些函數的使用,如果一個正則表達式需要重復的使用,那么先通過compile函數編譯正則表達式并創建出正則表達式對象無疑是更為明智的選擇。
下面我們通過一系列的例子來告訴大家在Python中如何使用正則表達式。
例子1:驗證輸入用戶名和QQ號是否有效并給出對應的提示信息。
"""
要求:用戶名必須由字母、數字或下劃線構成且長度在6~20個字符之間,QQ號是5~12的數字且首位不能為0
"""
import reusername = input('請輸入用戶名: ')
qq = input('請輸入QQ號: ')
# match函數的第一個參數是正則表達式字符串或正則表達式對象
# match函數的第二個參數是要跟正則表達式做匹配的字符串對象
m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)
if not m1:print('請輸入有效的用戶名.')
# fullmatch函數要求字符串和正則表達式完全匹配
# 所以正則表達式沒有寫起始符和結束符
m2 = re.fullmatch(r'[1-9]\d{4,11}', qq)
if not m2:print('請輸入有效的QQ號.')
if m1 and m2:print('你輸入的信息是有效的!')
提示: 上面在書寫正則表達式時使用了“原始字符串”的寫法(在字符串前面加上了
r),所謂“原始字符串”就是字符串中的每個字符都是它原始的意義,說得更直接一點就是字符串中沒有所謂的轉義字符啦。因為正則表達式中有很多元字符和需要進行轉義的地方,如果不使用原始字符串就需要將反斜杠寫作\\,例如表示數字的\d得書寫成\\d,這樣不僅寫起來不方便,閱讀的時候也會很吃力。
例子2:從一段文字中提取出國內手機號碼。
下面這張圖是截止到 2017 年底,國內三家運營商推出的手機號段。

import re# 創建正則表達式對象,使用了前瞻和回顧來保證手機號前后不應該再出現數字
pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')
sentence = '''重要的事情說8130123456789遍,我的手機號是13512346789這個靚號,
不是15600998765,也不是110或119,王大錘的手機號才是15600998765。'''
# 方法一:查找所有匹配并保存到一個列表中
tels_list = re.findall(pattern, sentence)
for tel in tels_list:print(tel)
print('--------華麗的分隔線--------')# 方法二:通過迭代器取出匹配對象并獲得匹配的內容
for temp in pattern.finditer(sentence):print(temp.group())
print('--------華麗的分隔線--------')# 方法三:通過search函數指定搜索位置找出所有匹配
m = pattern.search(sentence)
while m:print(m.group())m = pattern.search(sentence, m.end())
說明: 上面匹配國內手機號的正則表達式并不夠好,因為像 14 開頭的號碼只有 145 或 147,而上面的正則表達式并沒有考慮這種情況,要匹配國內手機號,更好的正則表達式的寫法是:
(?<=\D)(1[38]\d{9}|14[57]\d{8}|15[0-35-9]\d{8}|17[678]\d{8})(?=\D),國內好像已經有 19 和 16 開頭的手機號了,但是這個暫時不在我們考慮之列。
例子3:替換字符串中的不良內容
import resentence = 'Oh, shit! 你是傻逼嗎? Fuck you.'
purified = re.sub('fuck|shit|[傻煞沙][比筆逼叉缺吊碉雕]','*', sentence, flags=re.IGNORECASE)
print(purified) # Oh, *! 你是*嗎? * you.
說明:
re模塊的正則表達式相關函數中都有一個flags參數,它代表了正則表達式的匹配標記,可以通過該標記來指定匹配時是否忽略大小寫、是否進行多行匹配、是否顯示調試信息等。如果需要為flags參數指定多個值,可以使用按位或運算符進行疊加,如flags=re.I | re.M。
例子4:拆分長字符串
import repoem = '窗前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。'
sentences_list = re.split(r'[,。]', poem)
sentences_list = [sentence for sentence in sentences_list if sentence]
for sentence in sentences_list:print(sentence)
7.3 總結
正則表達式在字符串的處理和匹配上真的非常強大,通過上面的例子相信大家已經感受到了正則表達式的魅力,當然寫一個正則表達式對新手來說并不是那么容易,但是很多事情都是熟能生巧,大膽的去嘗試就行了,有一個在線的正則表達式測試工具相信能夠在一定程度上幫到大家。



的安裝過程以及GD32的IAR工程模板搭建)

 鑰匙串信息)
)

 配置IP封禁(防暴力破解))









——變量操作)
![[Linux入門] 初學者入門:Linux DNS 域名解析服務詳解](http://pic.xiahunao.cn/[Linux入門] 初學者入門:Linux DNS 域名解析服務詳解)