1 總體流程
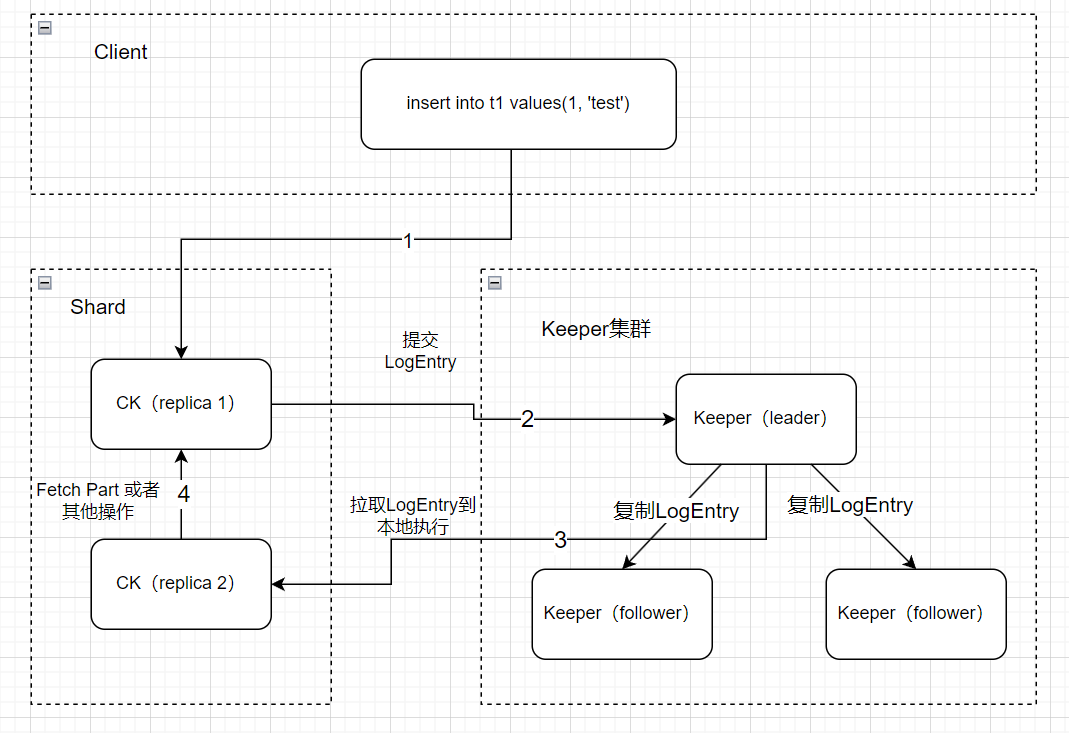
上圖說明了一條insert語句最后如何被副本同步到的流程(圖中ck集群為單shard,雙副本)。
(1)從客戶端發出,寫入ck
(2)ck提交LogEntry到Keeper
(3)另外一個副本從Keeper拉取LogEntry到本地執行
2 參數說明
此部分介紹以下整個鏈路涉及的一些參數。
mergetree settings:
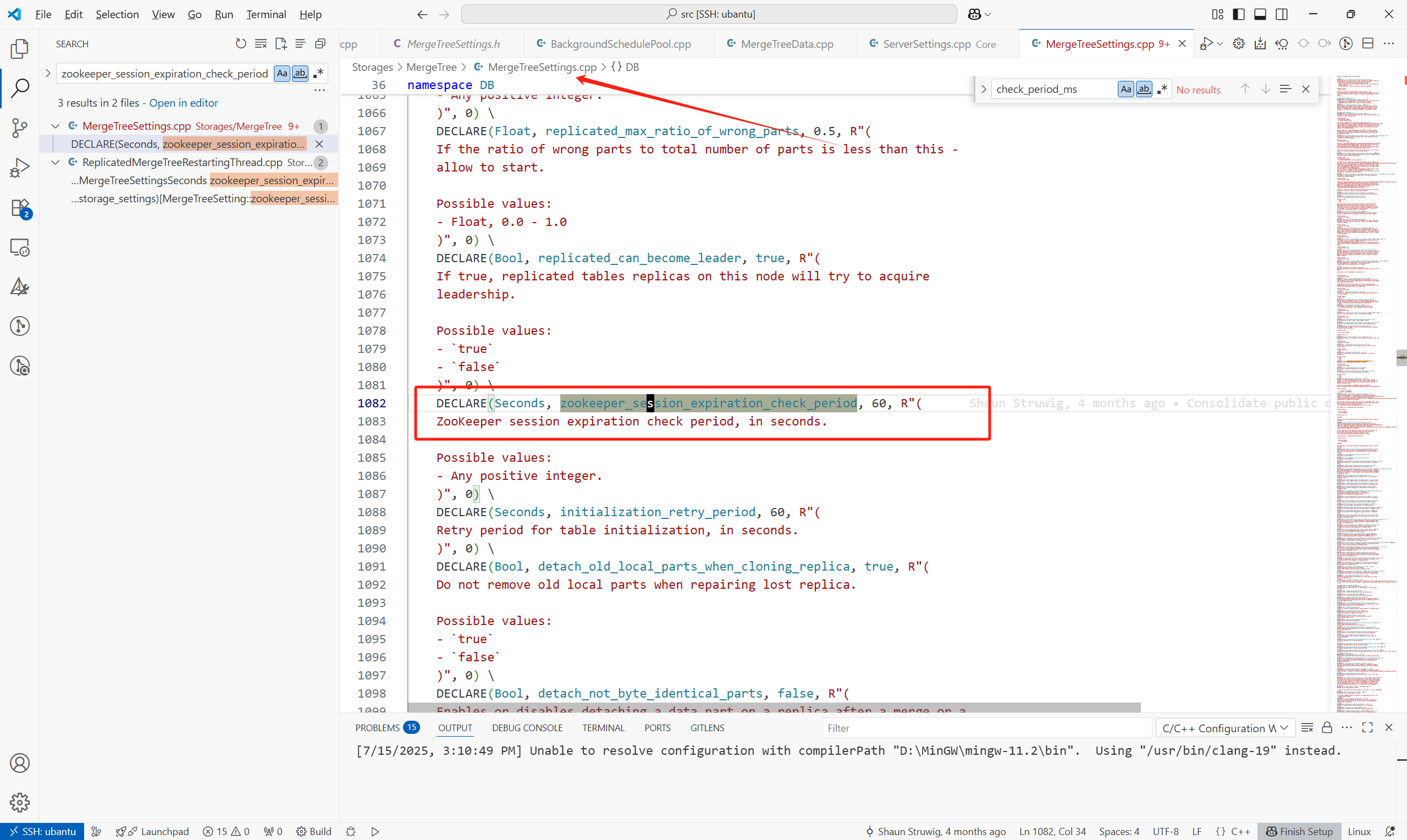
1.zookeeper_session_expiration_check_period
檢查keeper session是否到期,每個以上參數的時間檢查一次,默認為60S:
每個引擎為Replicated的MergeTree表在啟動的時候,會運行以下任務來檢查與keeper 之間的session是否過期。
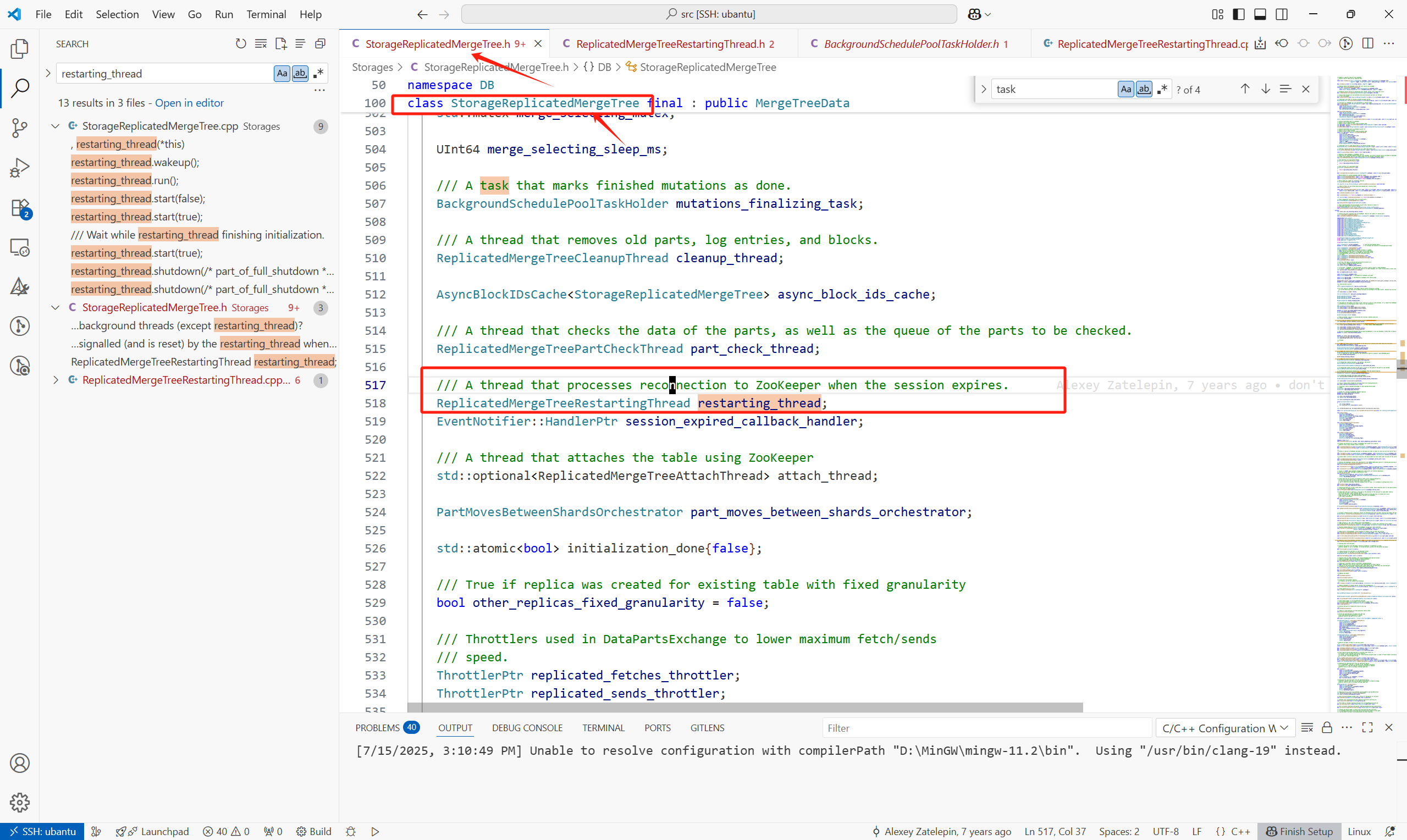
創建復制表時,內核會啟動這個復制表的引擎,
之后在ReplicatedMergeTreeRestartingThread::runImpl()中啟動各種后臺調度任務:
(1)background_operations_assignee:執行merge,fetch操作
(2)merge_selecting_task:主要功能為選擇合并的part
(3)cleanup_thread:線程,清理過期part等
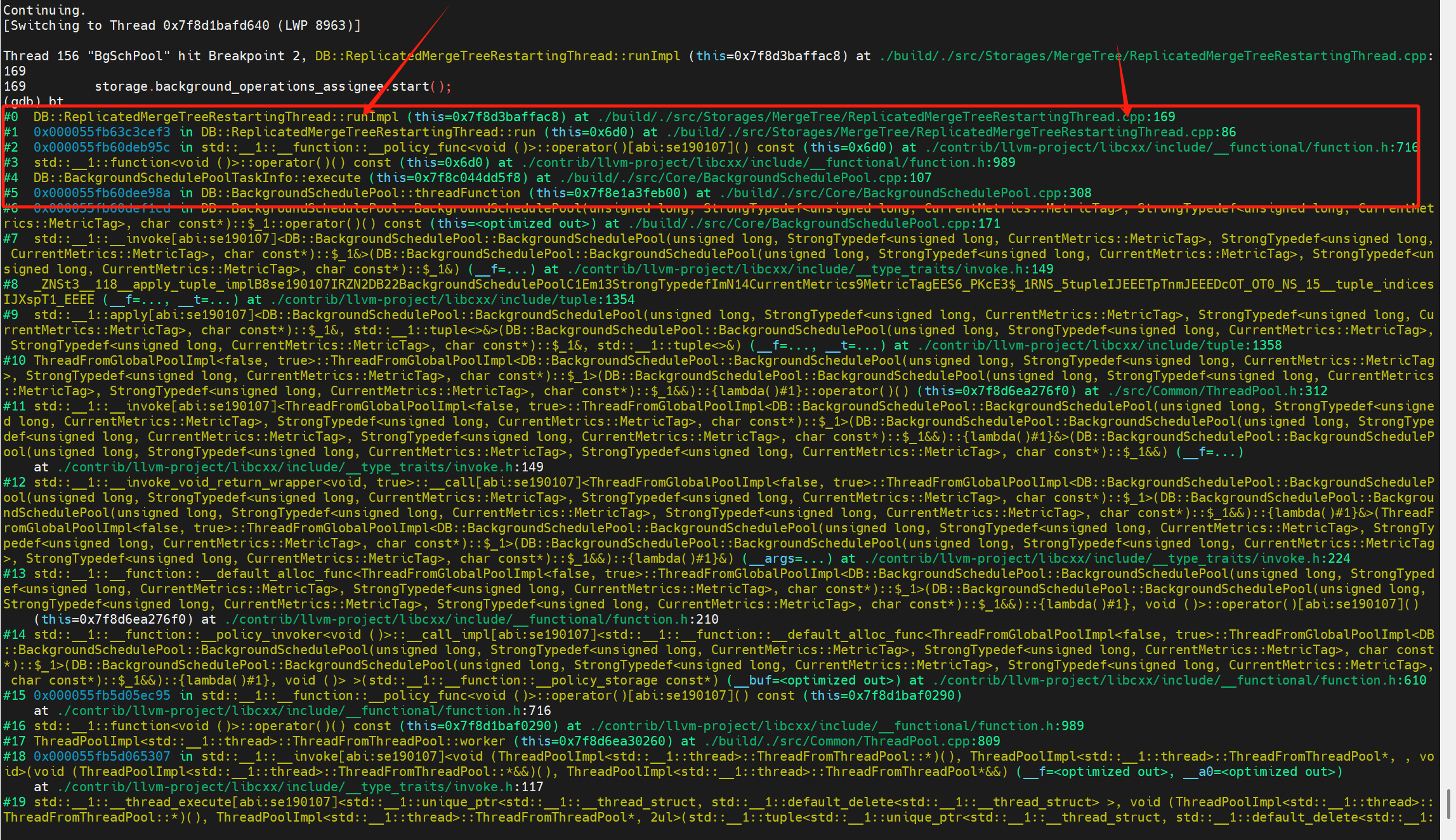
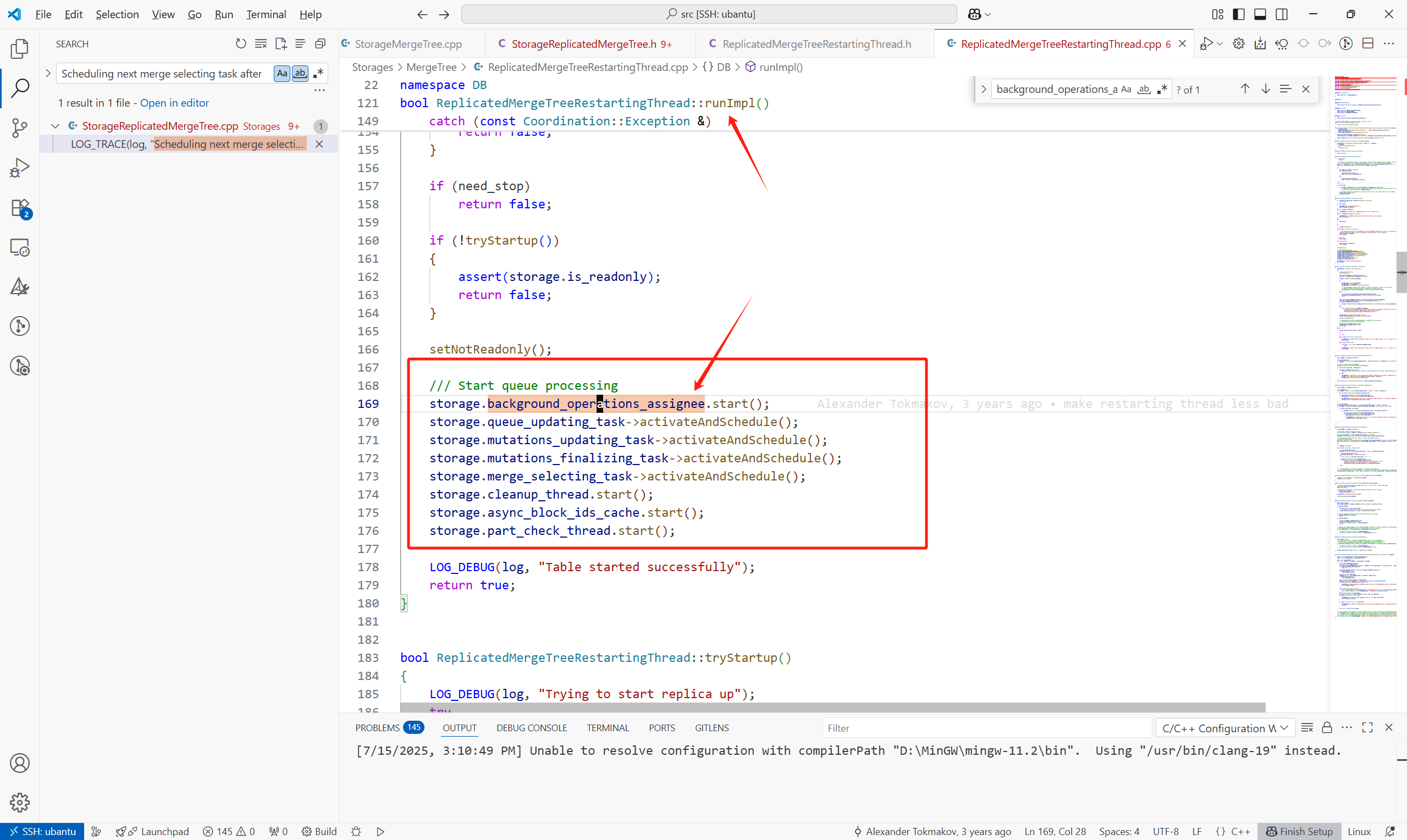
這些任務的調度有點任務內遞歸的感覺:
都是任務執行的最后在繼續重復上個任務(只是任務的內容不一樣)。
2.max_insert_delayed_streams_for_parallel_write
當part所在的存儲系統支持并行寫入時,這個參數默認為100,否則為0。


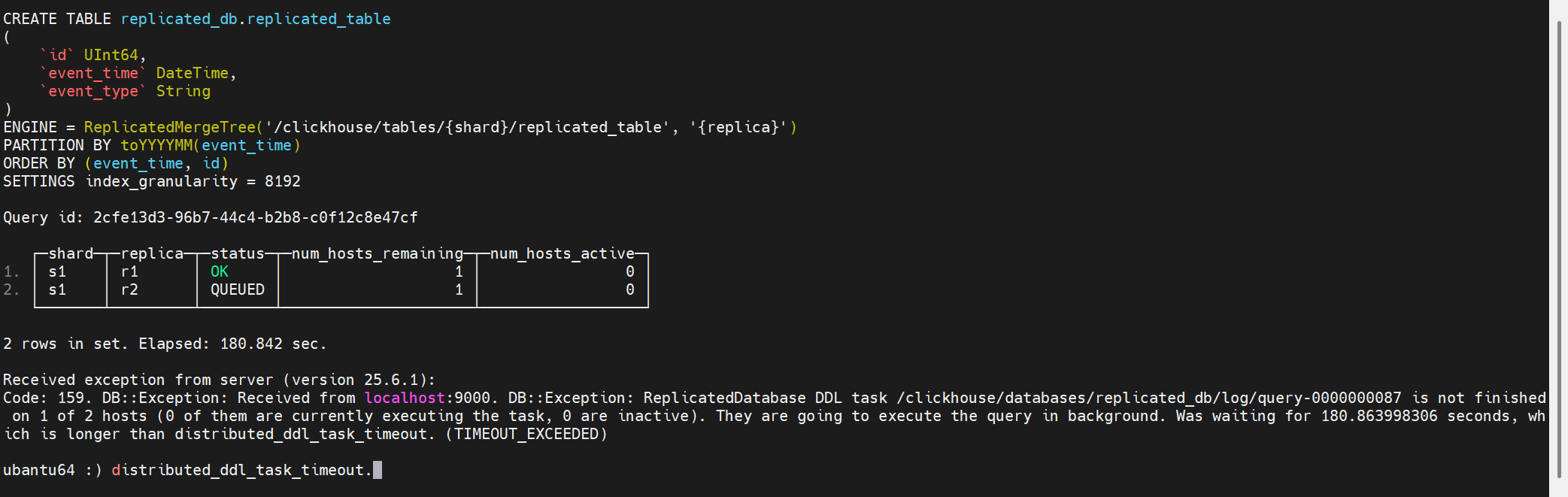
3.distributed_ddl_task_timeout
設置來自集群中所有主機的 DDL 查詢響應的超時時間。如果某個 DDL 請求未能在所有主機上執行完成,響應中將包含一個 timeout 錯誤,并且該請求將以異步模式執行。負值表示無限超時時間。
3 示例表結構
db:
CREATE DATABASE replicated_db
ENGINE = Replicated('/clickhouse/databases/replicated_db', '{shard}', '{replica}')
table:
CREATE TABLE replicated_db.replicated_table
(
`id` UInt64,
`event_time` DateTime,
`event_type` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/replicated_table', '{replica}')
PARTITION BY toYYYYMM(event_time)
ORDER BY (event_time, id)
SETTINGS index_granularity = 8192
1 單節點生成LogEntry
這里我們忽略掉詞語法解析,優化器,計劃生成層以及執行層的部分算子,直接來到寫數據到磁盤以及提交LogEntry的算子 -?ReplicatedMergeTreeSinkImpl。
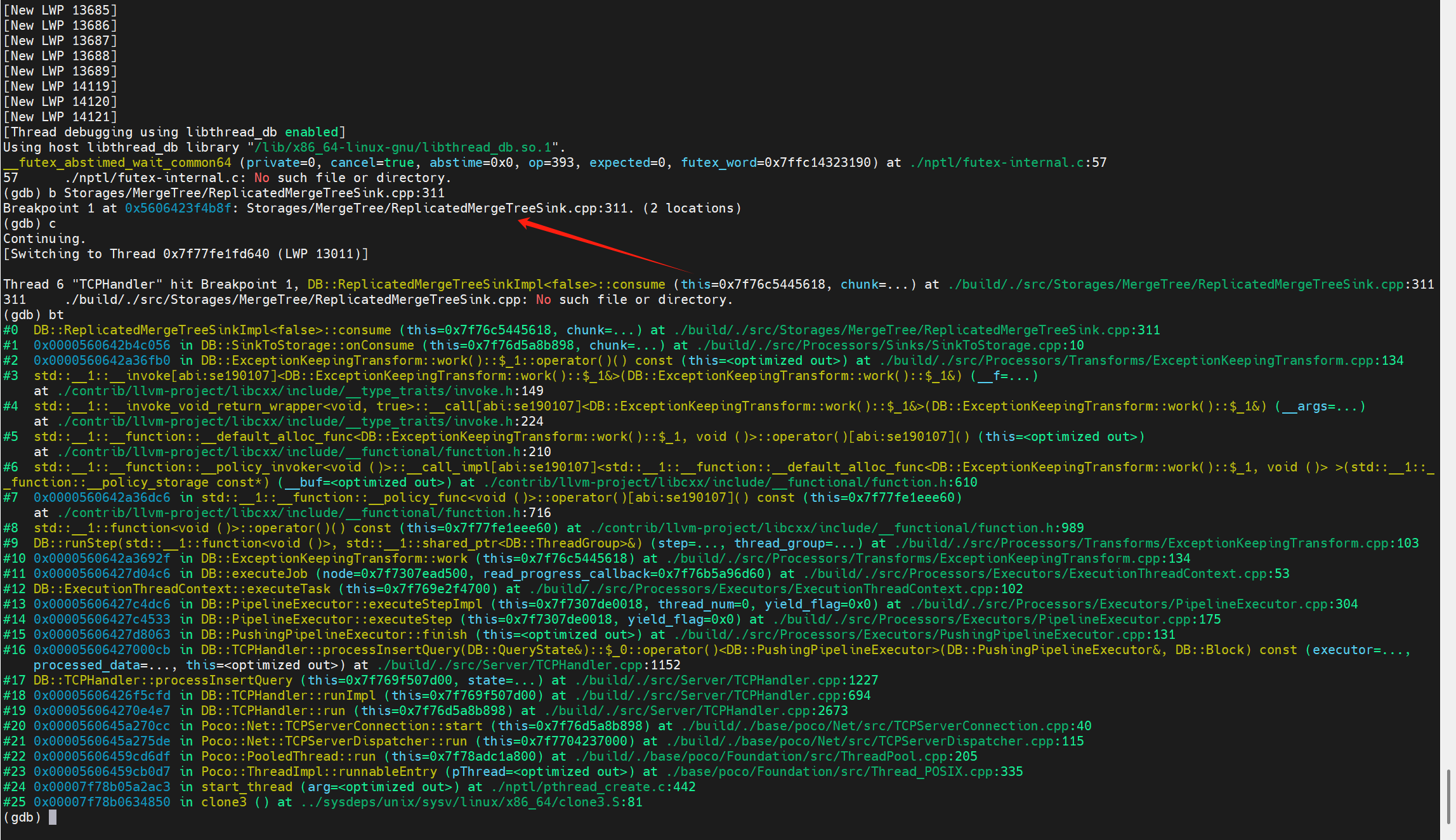
這里的輸入參數chunk就是插入的數據在內存中的組織結構。
在ReplicatedMergeTreeSinkImpl<async_insert>::consume(Chunk & chunk)中,主要有以下步驟:
1.將插入的數據通過分區鍵拆成part,此過程通過MergeTreeDataWriter::splitBlockIntoParts完成

2.遍歷每一個拆分出來的part
(1)通過writeNewTempPart將這個拆分出來的part寫到臨時目錄中。
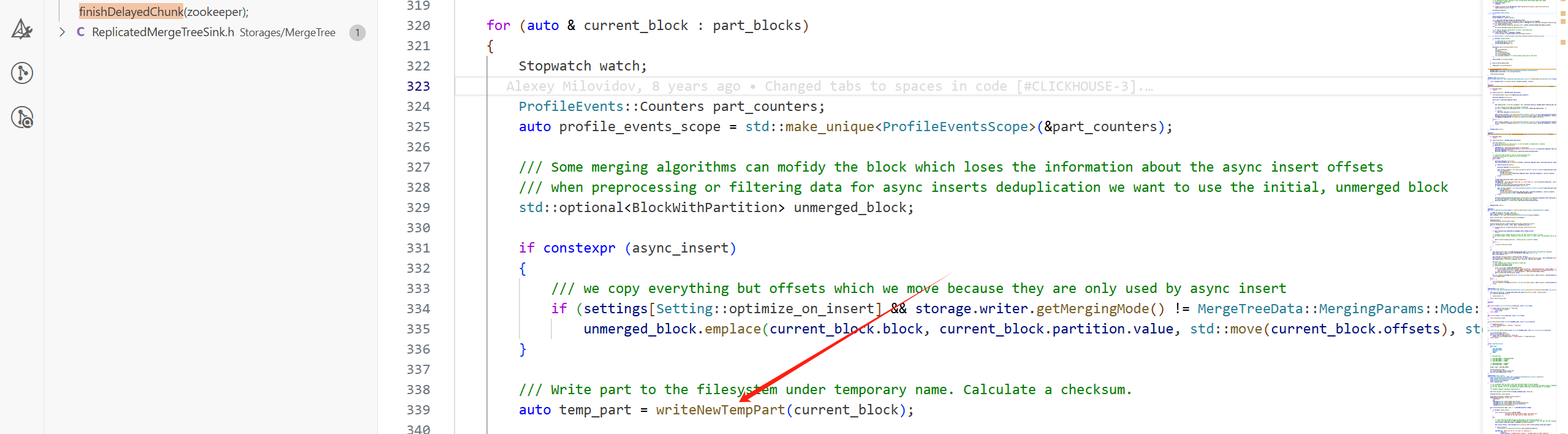
(2)在這個分支,提交寫入的part到keeper中:

如果開啟了并行寫入,part會攢夠一定的數量后,整體提交到Keeper上,這個默認數量為100。
2 提交LogEntry到Keeper
2.1 提交重試的參數控制
1.insert_keeper_max_retries?
insert_keeper_max_retries?參數控制向復制表(Replicated MergeTree)插入數據時,對 ClickHouse Keeper(或 ZooKeeper)請求的最大重試次數。默認值為20。
只有以下三種錯誤會觸發重試:
(1)network error
(2)Keeper session timeout
(3)request timeout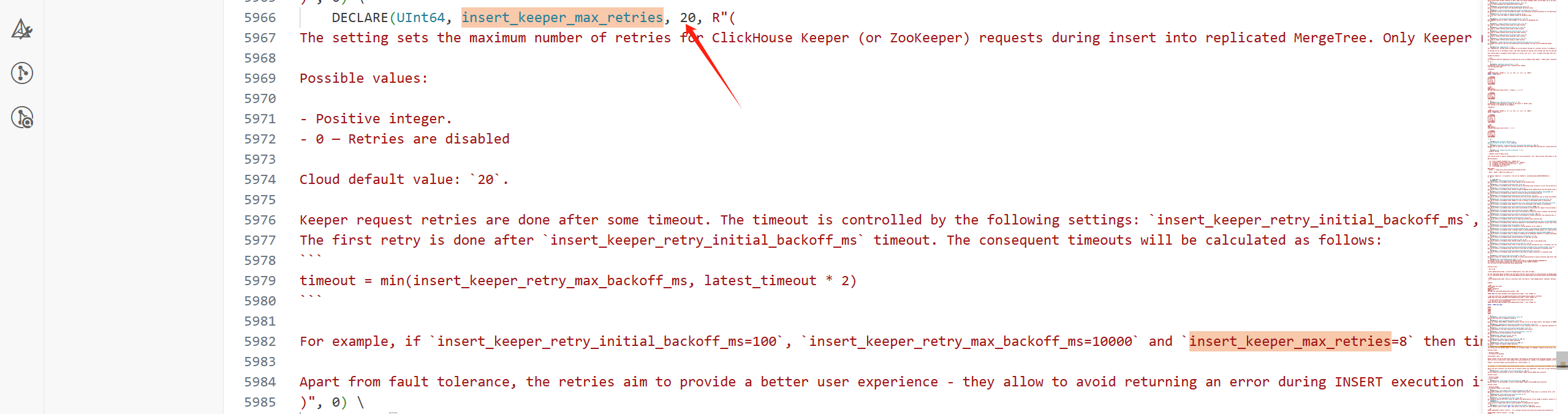
2.insert_keeper_retry_initial_backoff_ms?
insert_keeper_retry_initial_backoff_ms?參數定義了在INSERT執行期間,對失敗的Keeper(ZooKeeper)請求進行重試時的初始退避等待時間(毫秒)。默認值為100ms。

3.insert_keeper_retry_max_backoff_ms?
insert_keeper_retry_max_backoff_ms?參數設定了在 INSERT 查詢執行期間,對失敗的 Keeper/ZooKeeper 請求進行重試時的最大退避等待時間上限(毫秒)。默認值為10s。

2.2 提交流程
注意這里提交的并不是寫入的數據,而是寫入part的元信息。
提交主要通過ReplicatedMergeTreeSinkImpl<async_insert>::commitPart完成。
block_id_path
/clickhouse/tables/s1/replicated_table/blocks/202507_12141418273484448060_16681511374997932159
retries_ctl.retryLoop為提交的驅動:
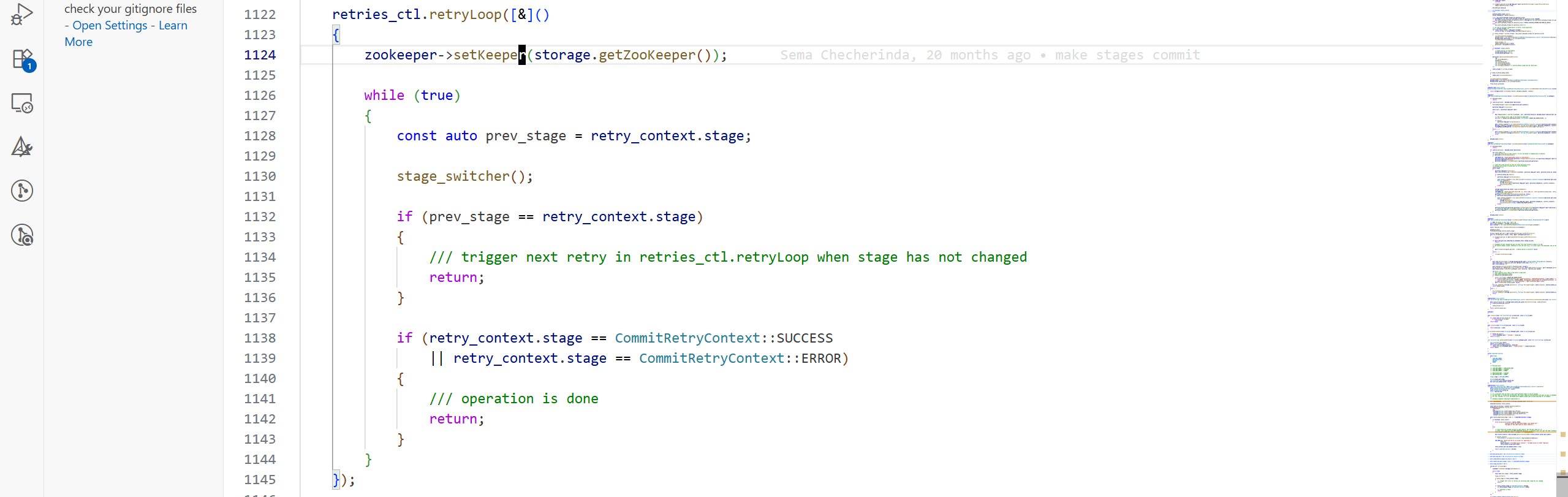
提交的狀態轉化通過stage_switcher這個匿名函數完成:
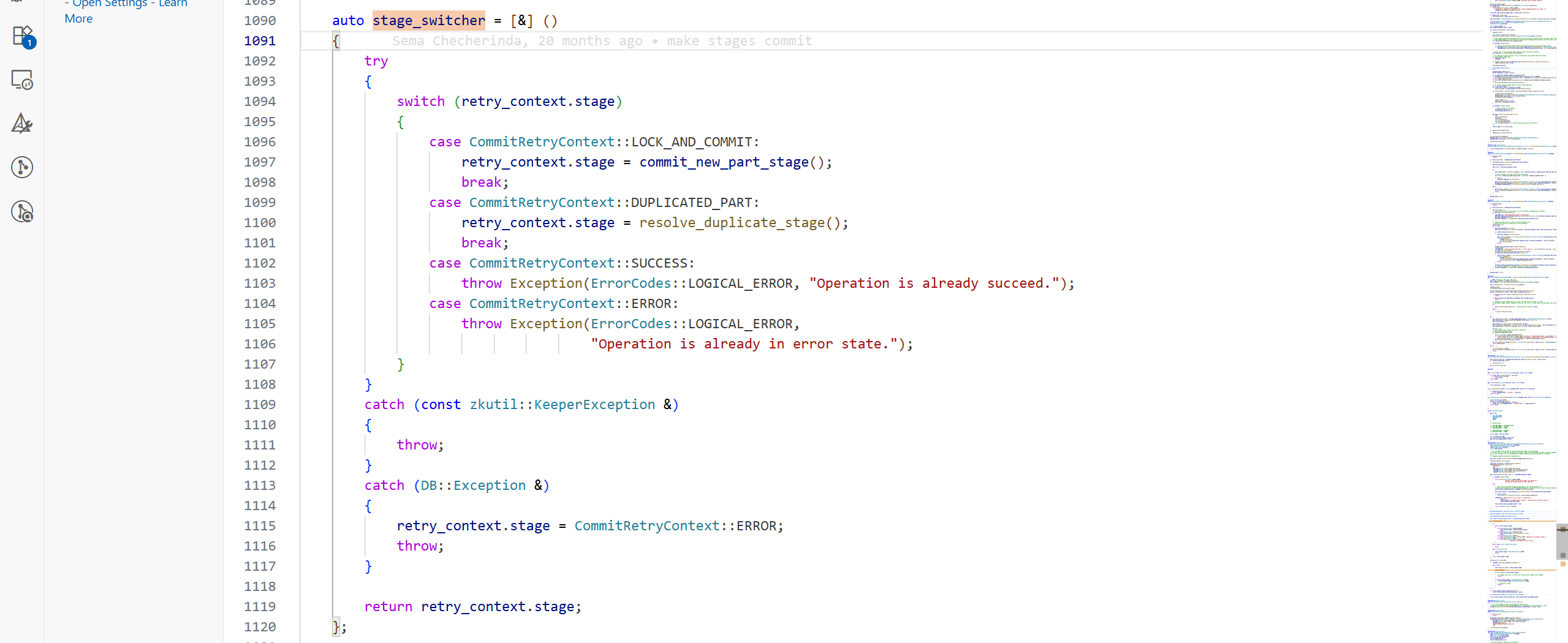
初始時retry_context.stage為LOCK_AND_COMMIT,所以進入commit_new_part_stage:
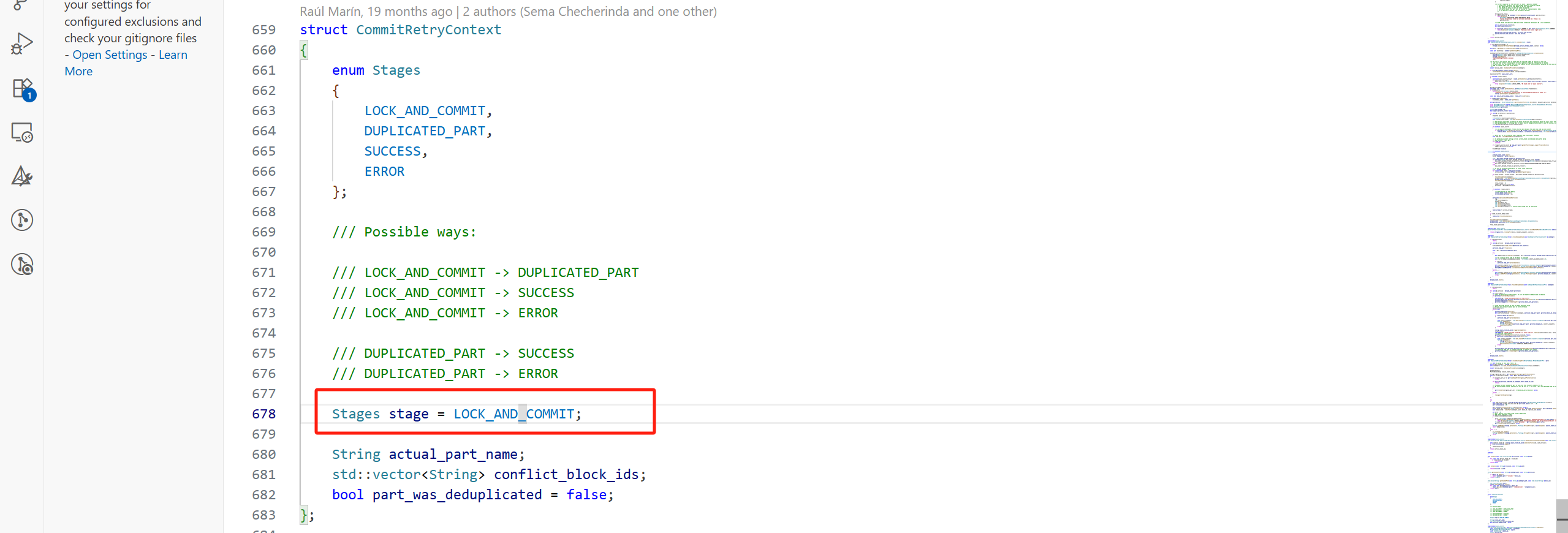
commit_new_part_stage主要做了以下幾件事:
(1)設置要提交part的基本信息,例如block_number,part 名。對于New Part來說,block_number在一個復制表引擎中是全局遞增的。
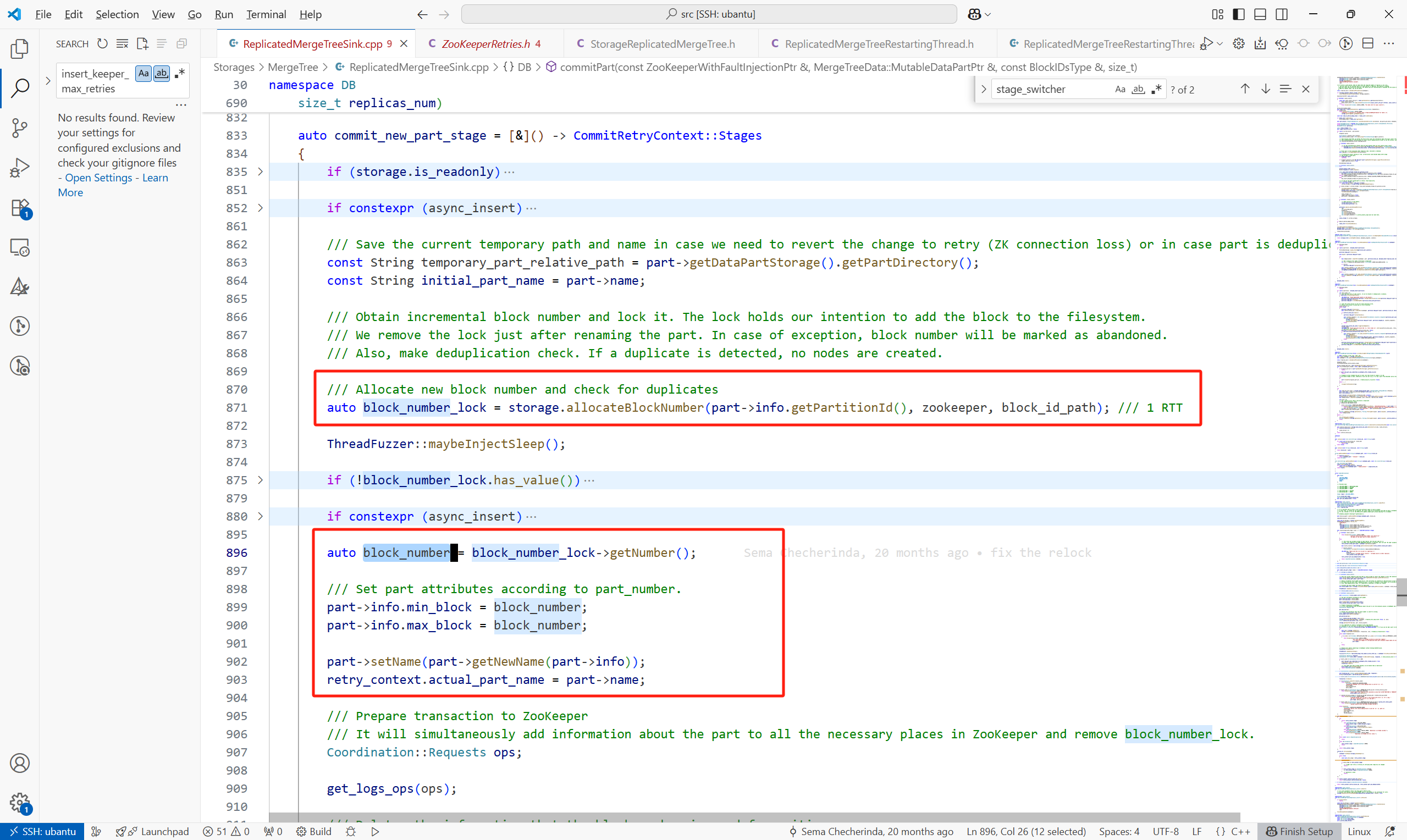
(2)構造要在Keeper上執行的請求,例如
構造在Keeper上創建的LogEntry的請求,通過get_logs_ops完成。對于一個New Part來說,這個LogEntry的type為GET_PART,還包括其他的一些信息,例如:
- create_time:創建時間
source_replica:哪個副本創建的這個part
new_part_name:part名
等等。最后將這個LogEntry封裝為一個CreateRequest。
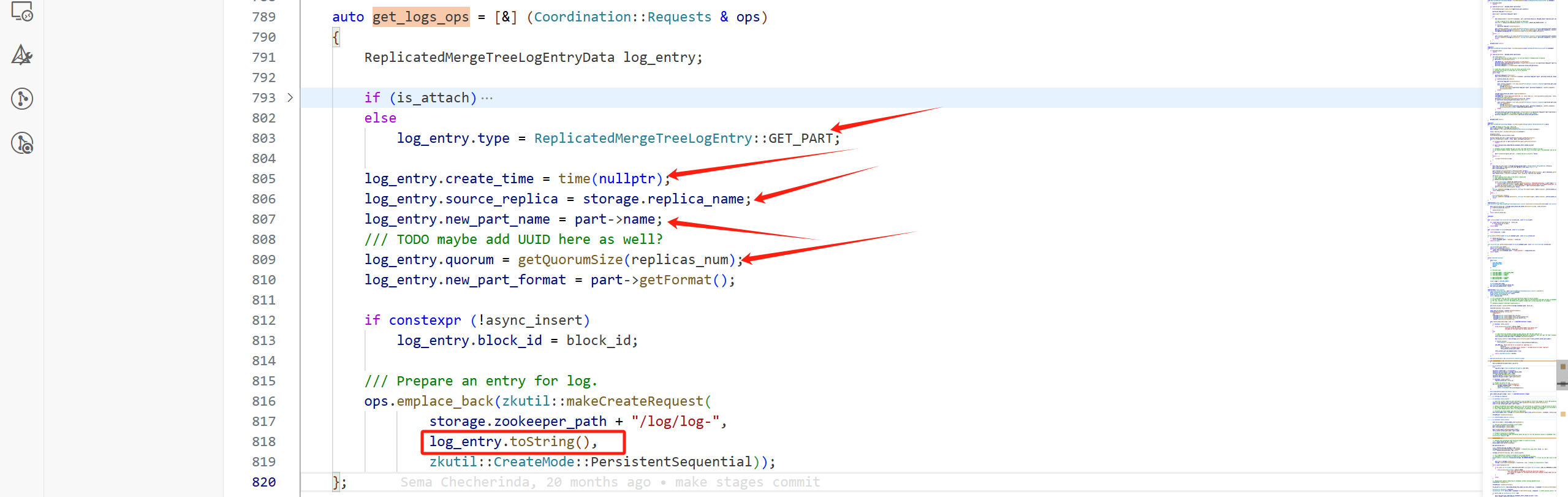
一次Part的提交會帶著很多其他的請求:
RemoveRequest有:
![]()

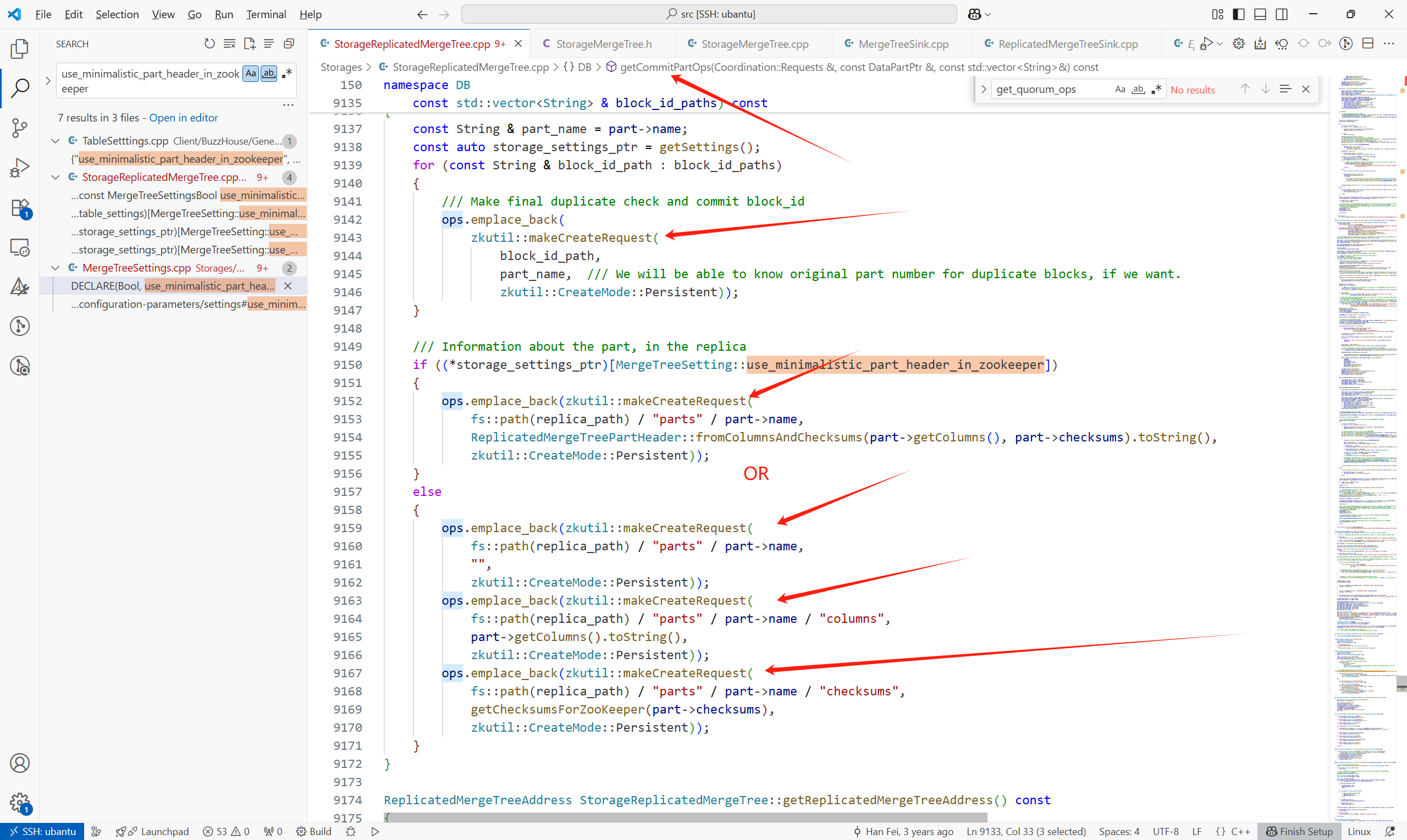
其他的CreateRequest有:
get_quorum_ops只有在副本大于2時,會有攜帶請求。
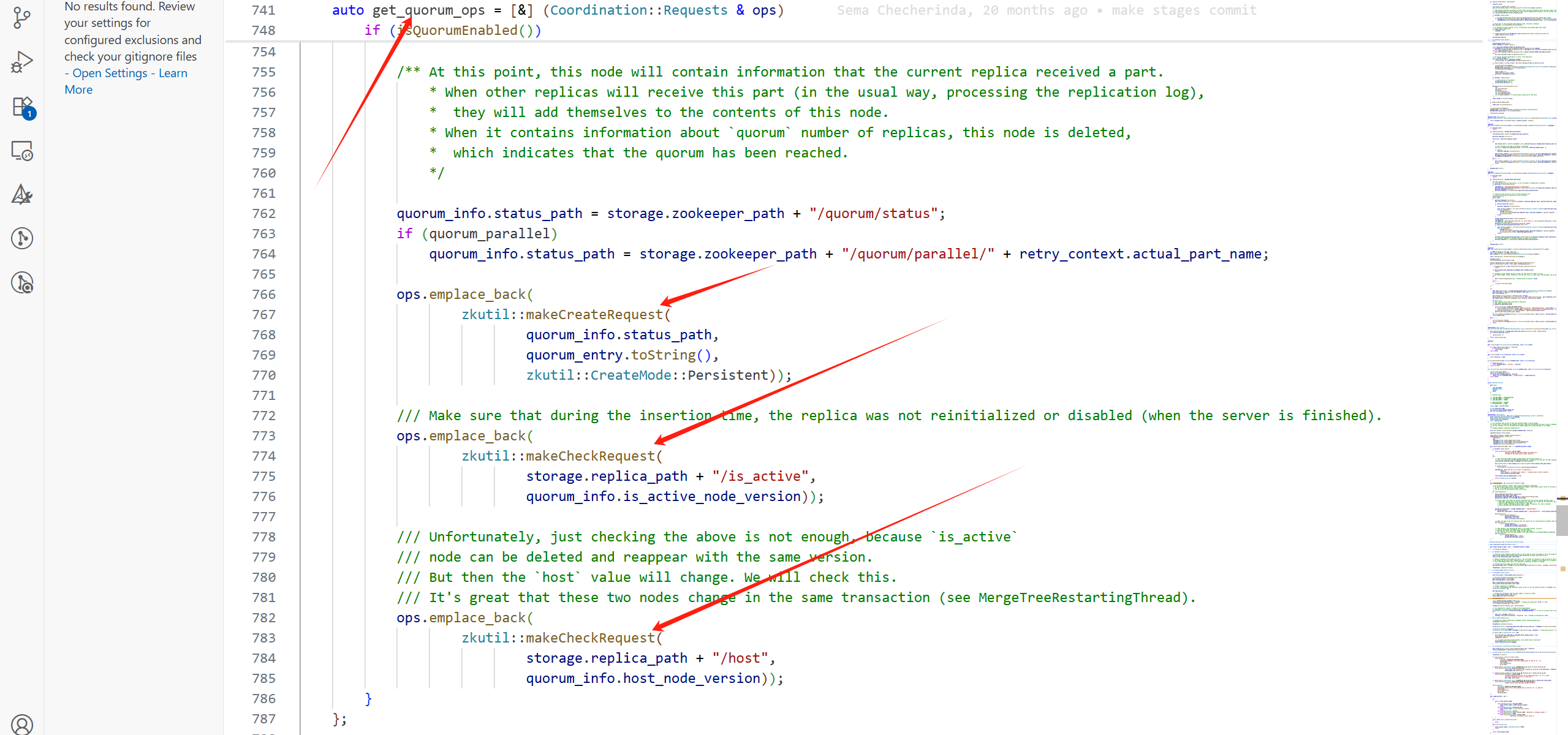
getCommitPartOps中的CreateRequest:
(3)開啟事務,在提交LogEntry到Keeper失敗時,回滾,進行狀態的恢復
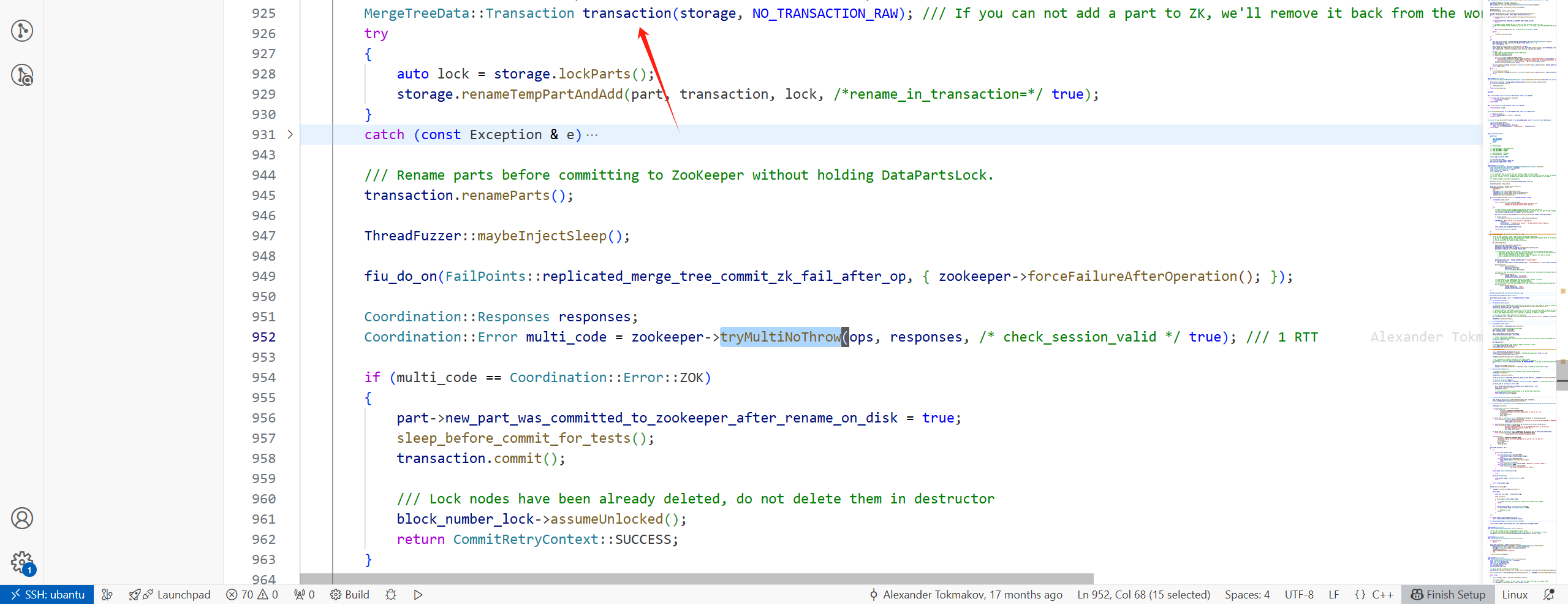
(4)將LogEntry發送到Keeper上

由于是多個請求,所以會調用ZooKeeper::multiImpl

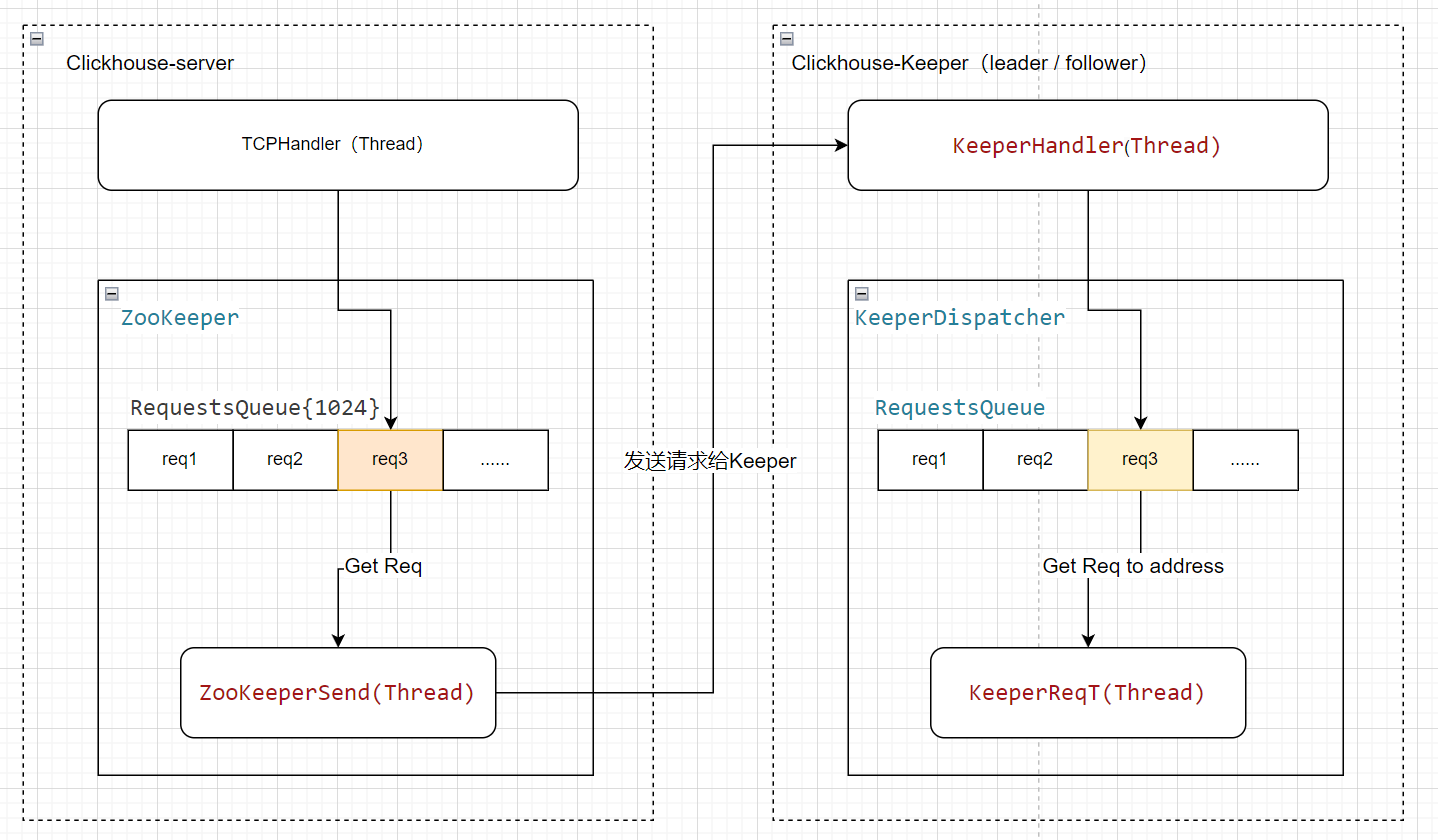
此處流程,可用下圖表示(如果是寫請求達到了follower,follower會轉發給leader):?
非阻塞等待異步操作結果,最大等待時間為args.operation_timeout_ms毫秒
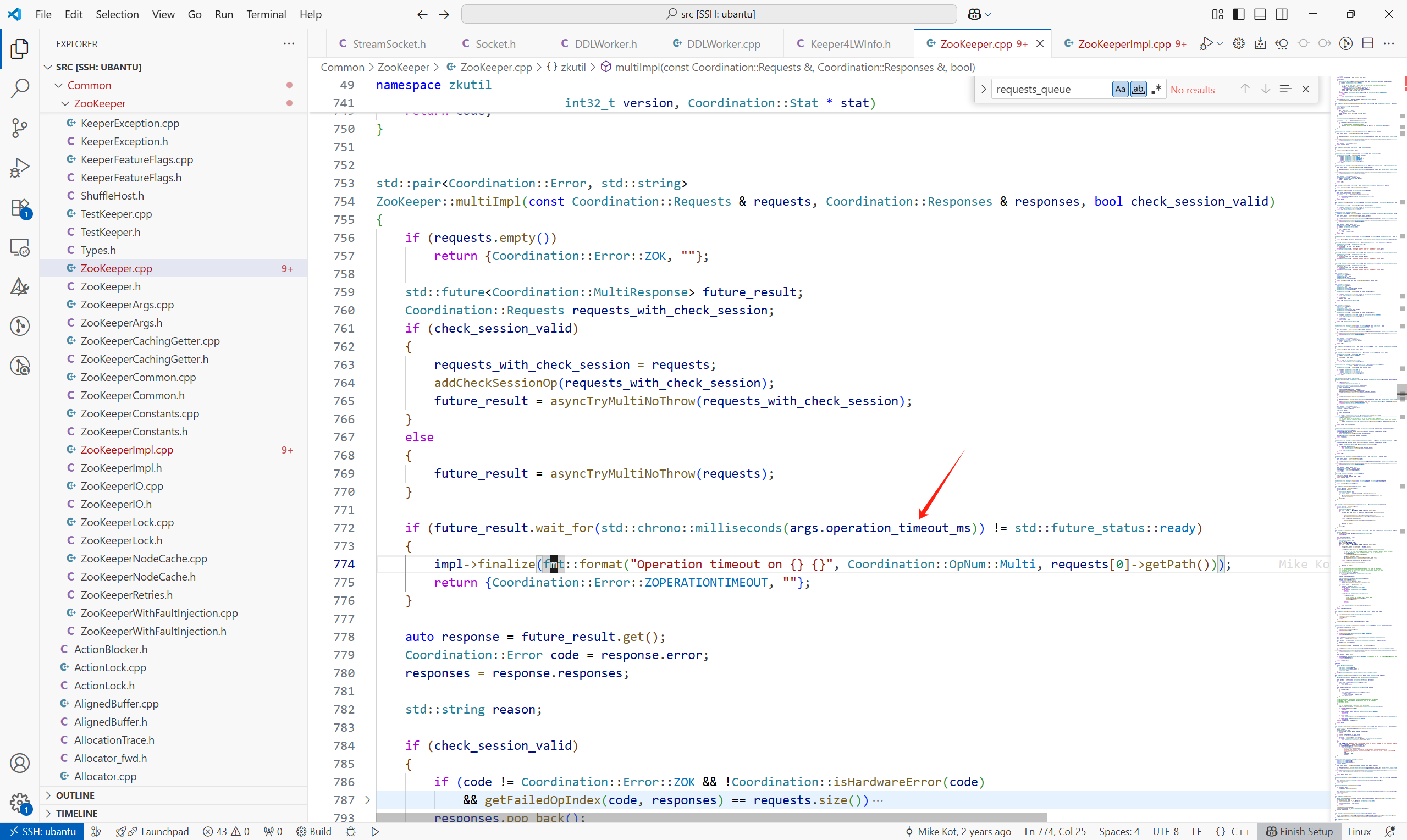
操作超時時間的參數,Coordination/CoordinationSettings.cpp

默認值為10S,Common/ZooKeeper/ZooKeeperConstants.h

3 副本拉取LogEntry
3.1 問題記錄
問題1:創建表報Session was killed
這個問題可以跳過,暫時采用另一種方法解決,在此保留,以后有時間了繼續追。
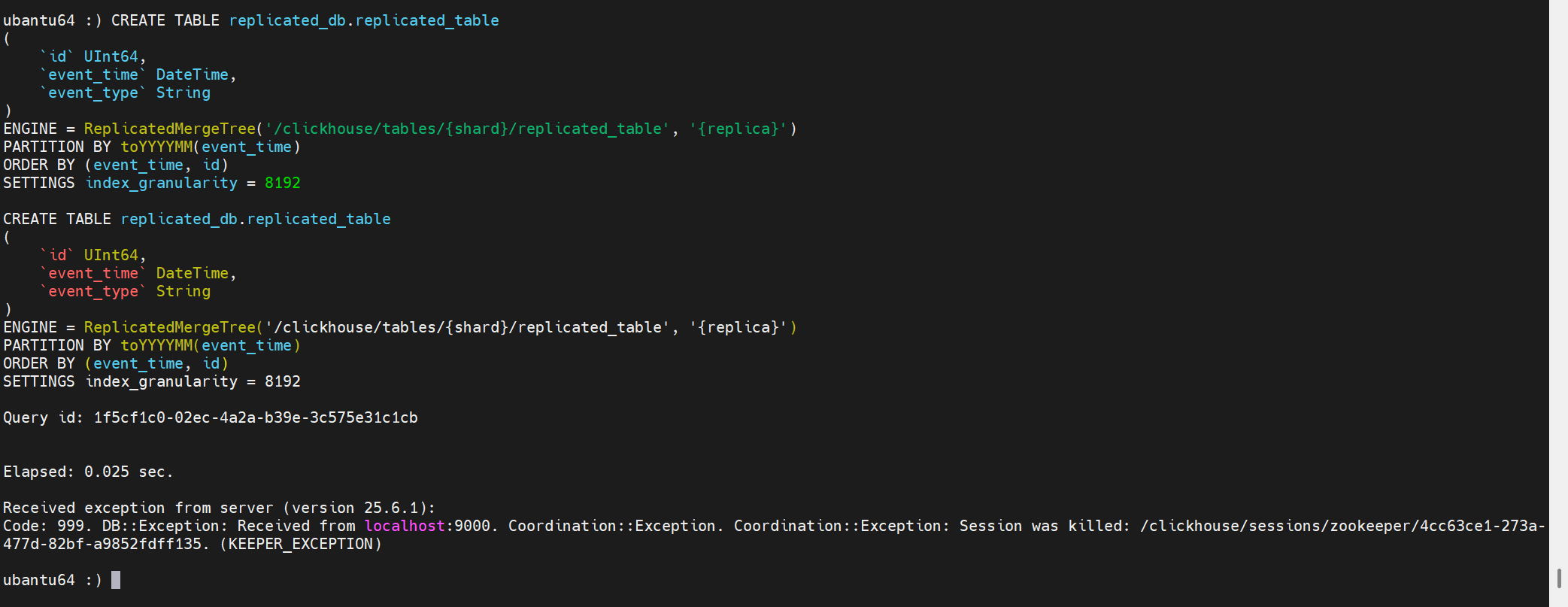
創建表時報錯:Coordination::Exception: Session was killed
原因時,長時間未操作,ch-client與Keeper之間的session斷開。
但是這有一個問題是:雖然創建表失敗,但是建表的元信息可能會提交到Keeper上。

此時你會發現,雖然這個庫并沒有這個表,但是無法創建:

再次創建表報錯如下:
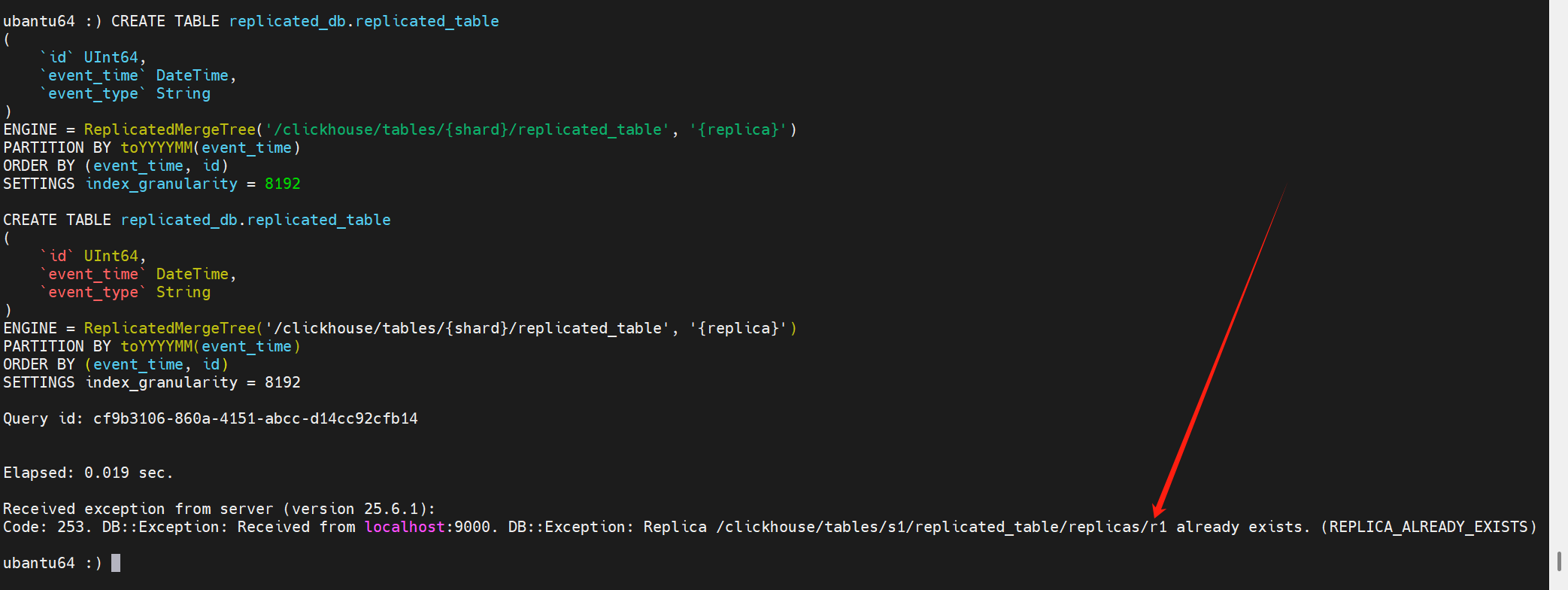
此時可以使用以下語句剔除在keeper上的元信息:
SYSTEM DROP REPLICA 'r1' FROM ZKPATH '/clickhouse/tables/s1/replicated_table';
剔除在keeper上的元信息后,再次創建表,會發現此時會卡在創建這里:
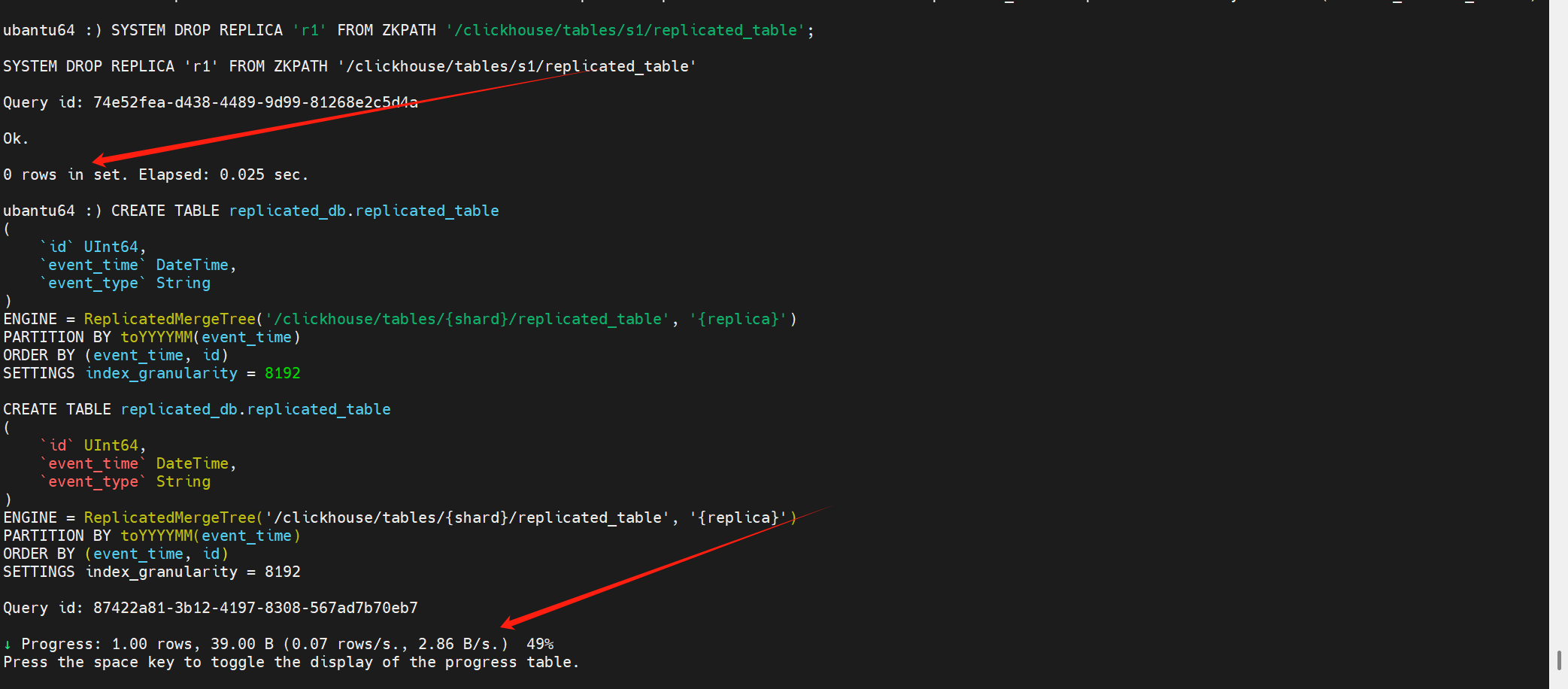
之后翻看副本2的日志,發現副本2之前已經拉到了replicated_table這張表,并為它創建了數據目錄。
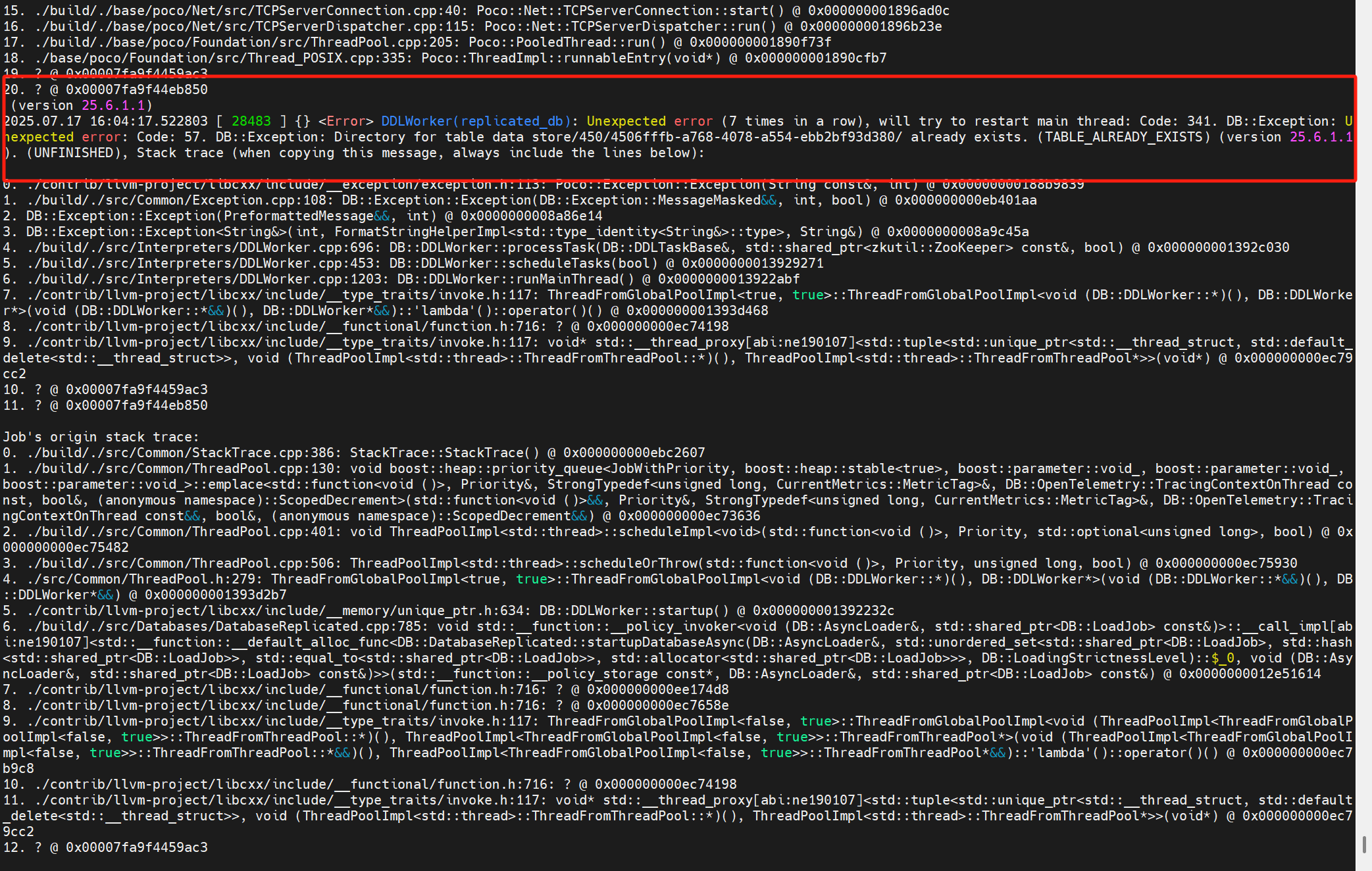
解決:去副本2上刪除對應得表目錄
![]()
此時,會發現replicated_table表已經成功創建。
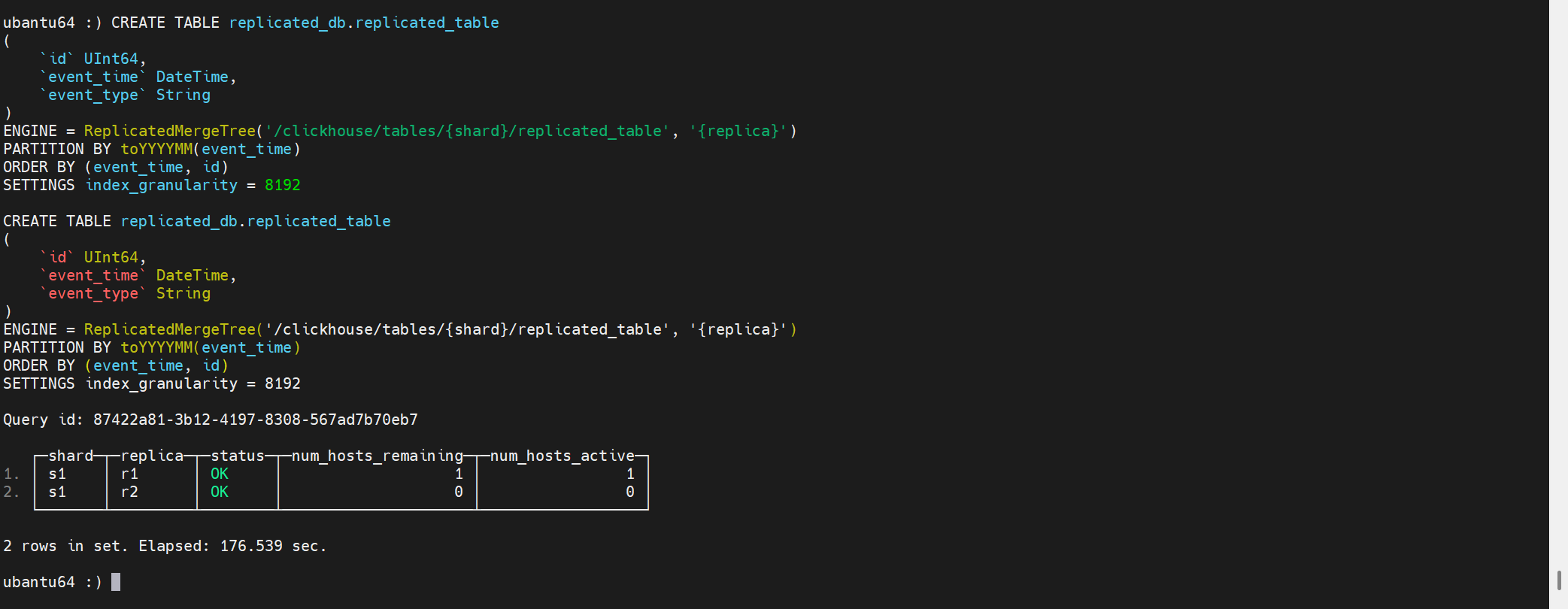
刪除表同樣有這個問題:
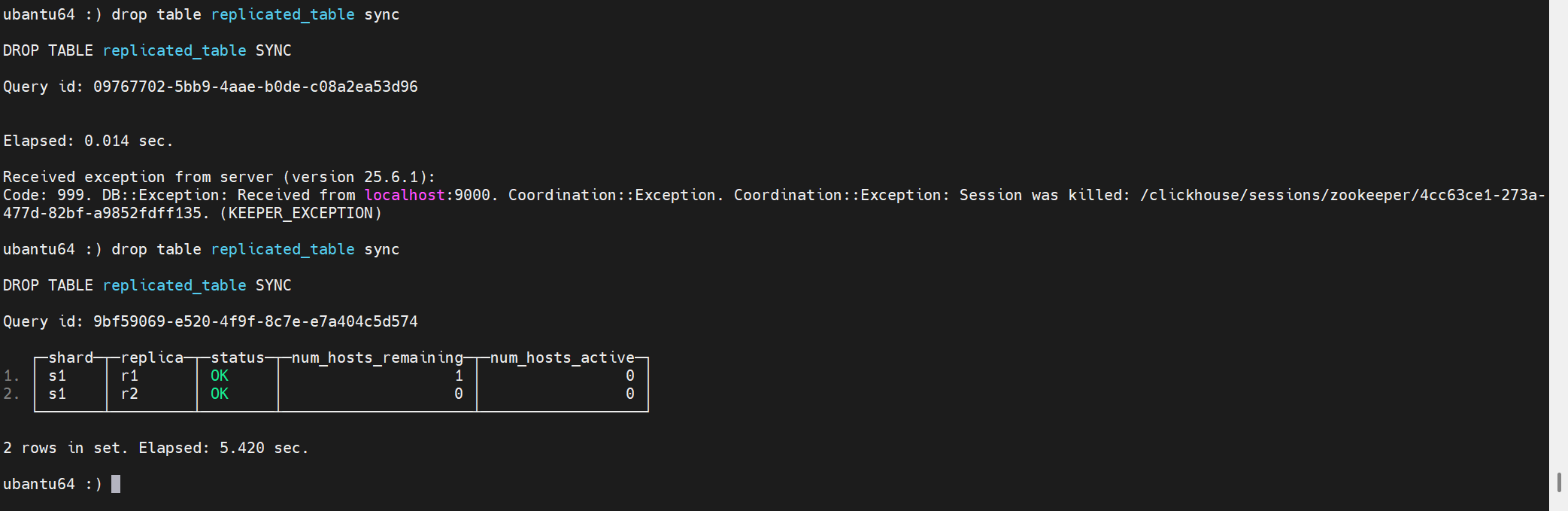
最終解決需要調整session超時時間。根因不是這個參數。以下繼續分析:
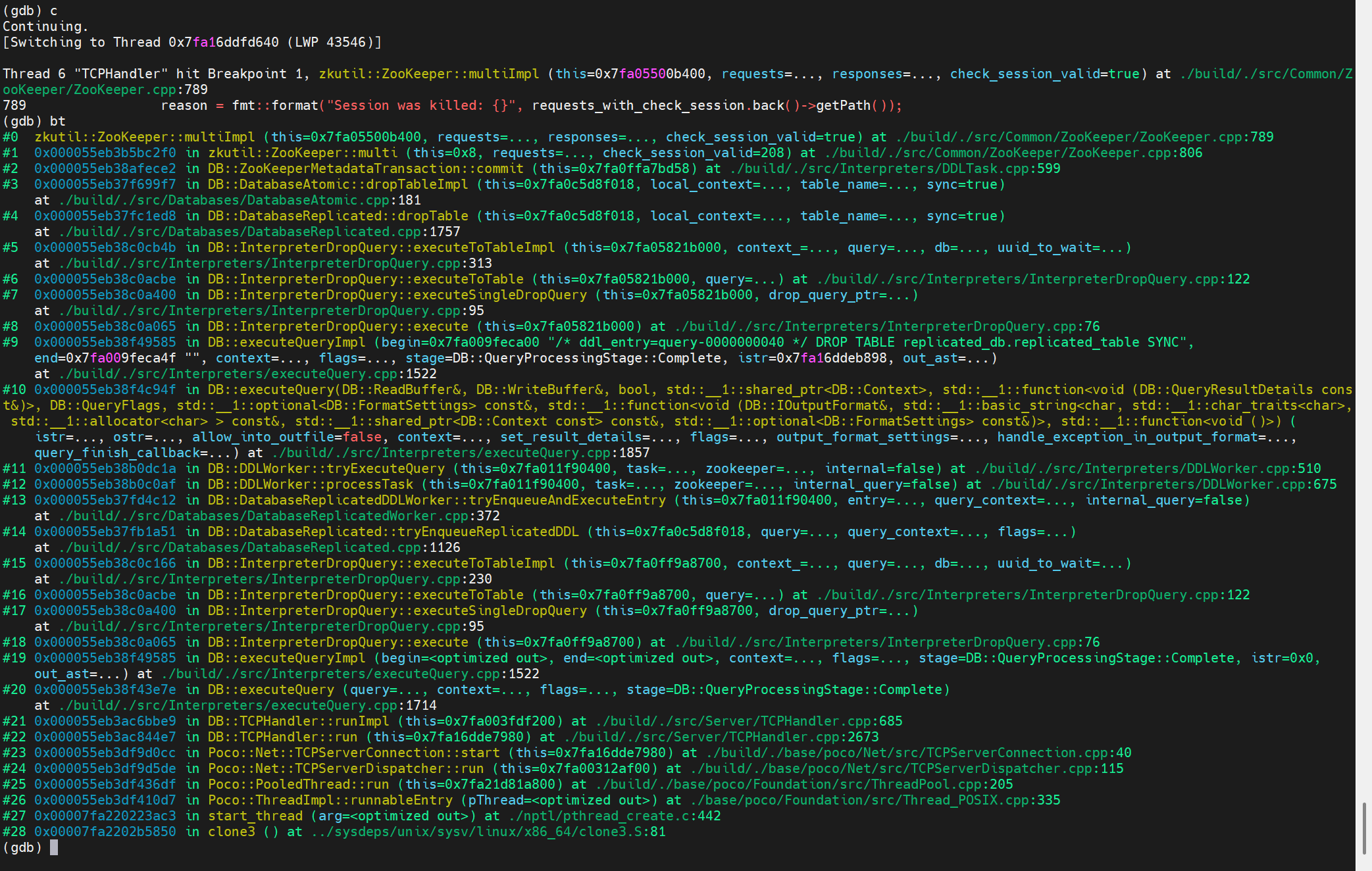
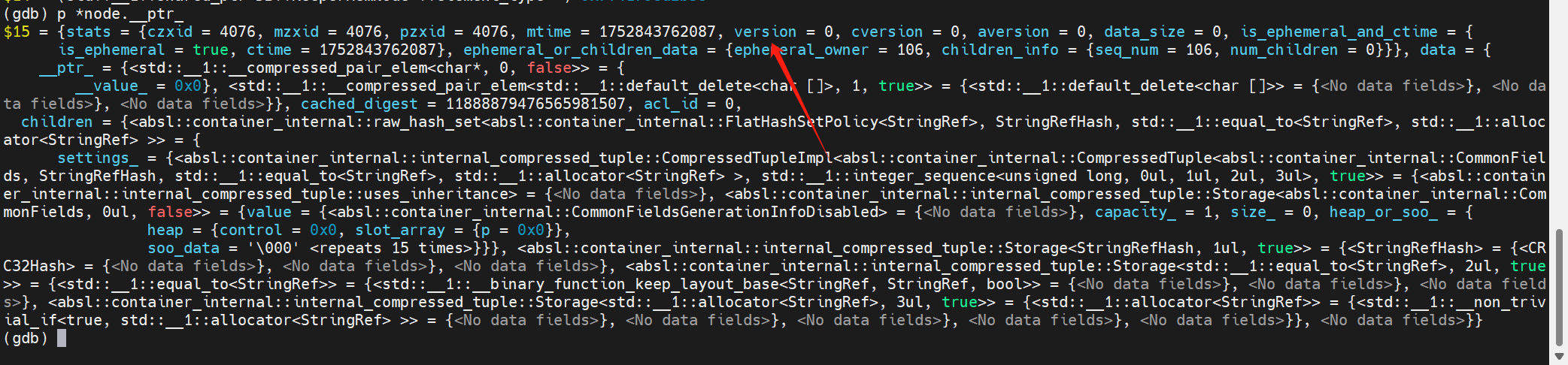
其中code為:
下一步調試Keeper看為什么會有這個錯誤碼。
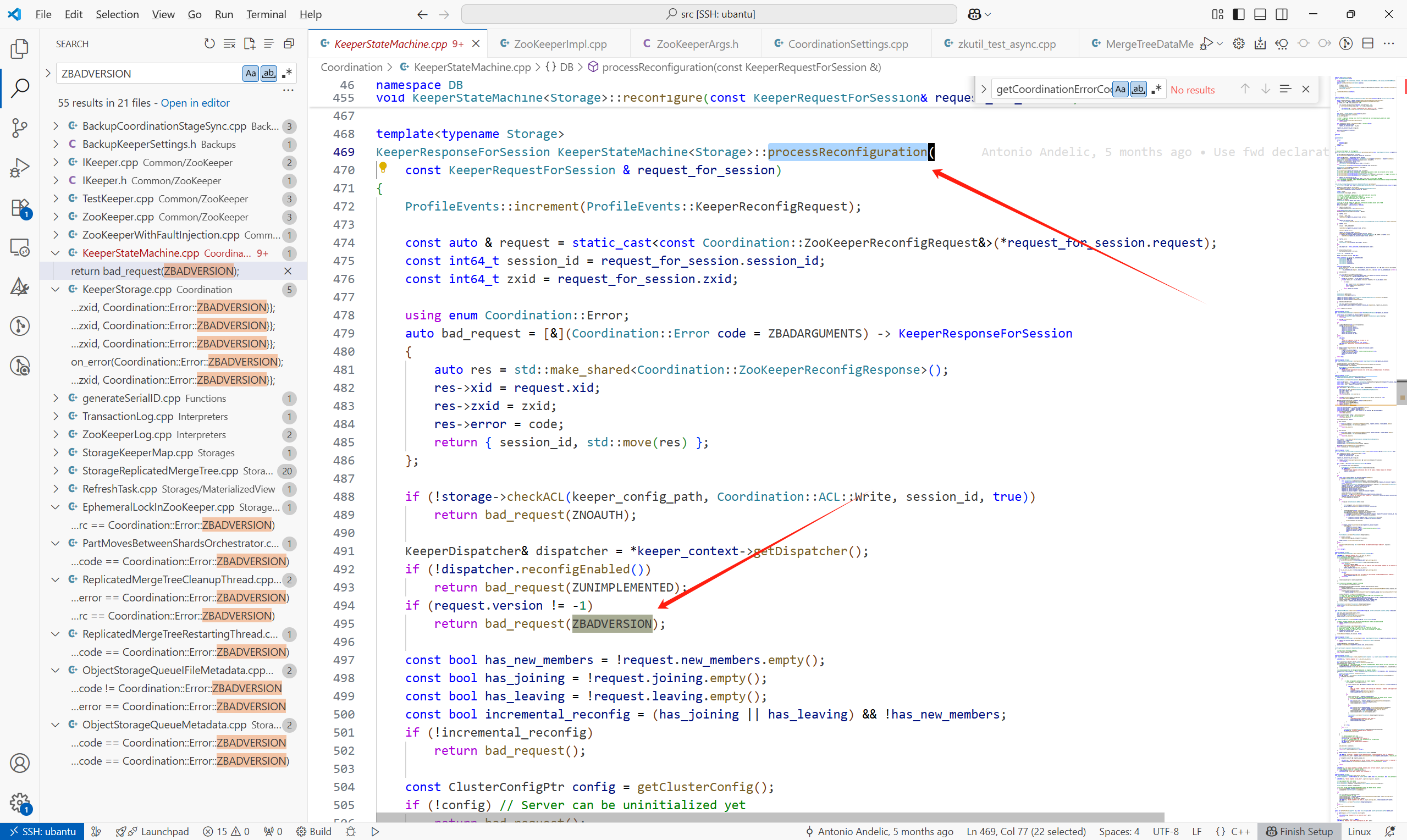
這個錯誤碼的設置位置:
(1)KeeperStateMachine<Storage>::processReconfiguration
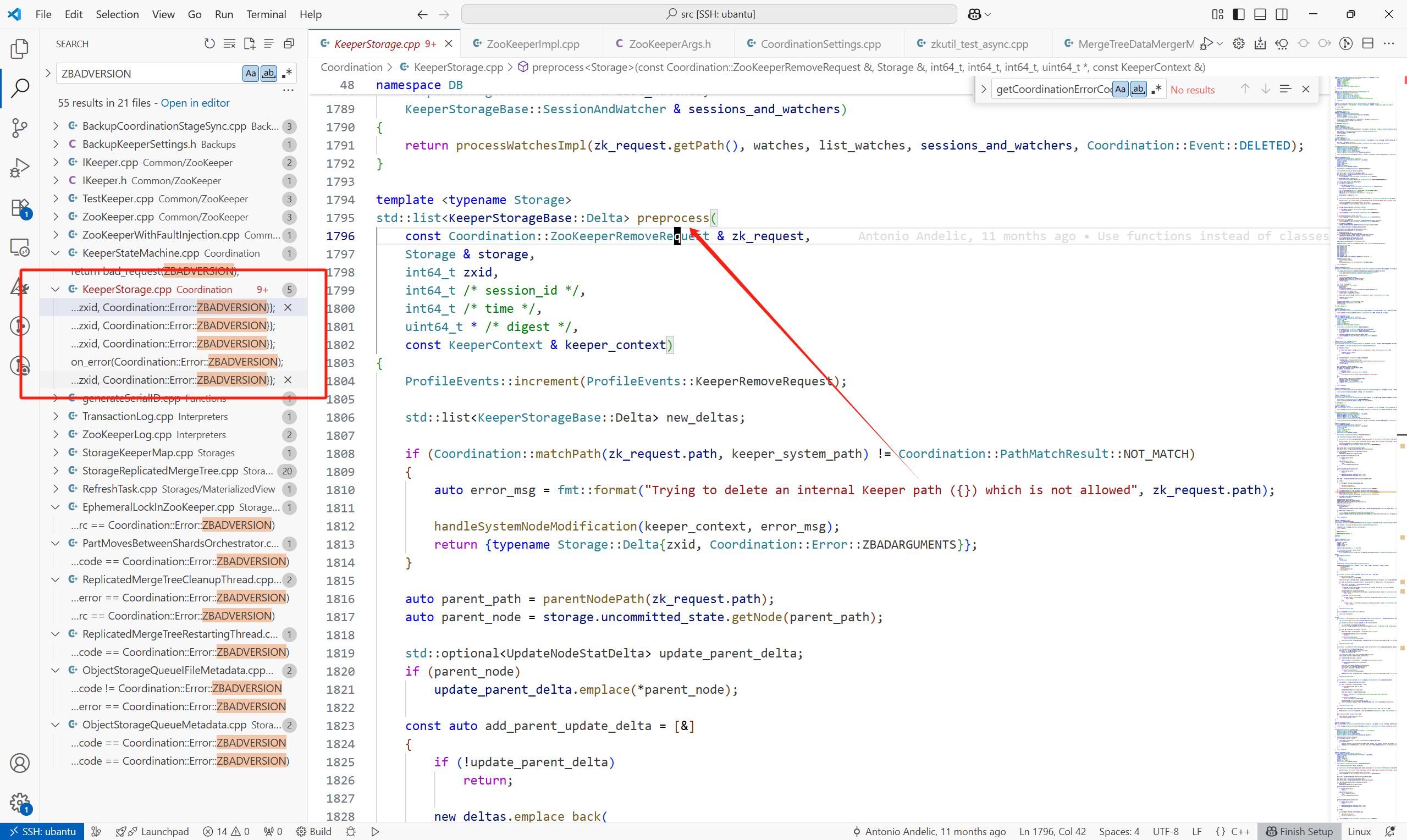
(2)各個預處理不同請求的地方,preprocess
TODO:比較懷疑是不是我的兩個ck使用的是不同版本的問題


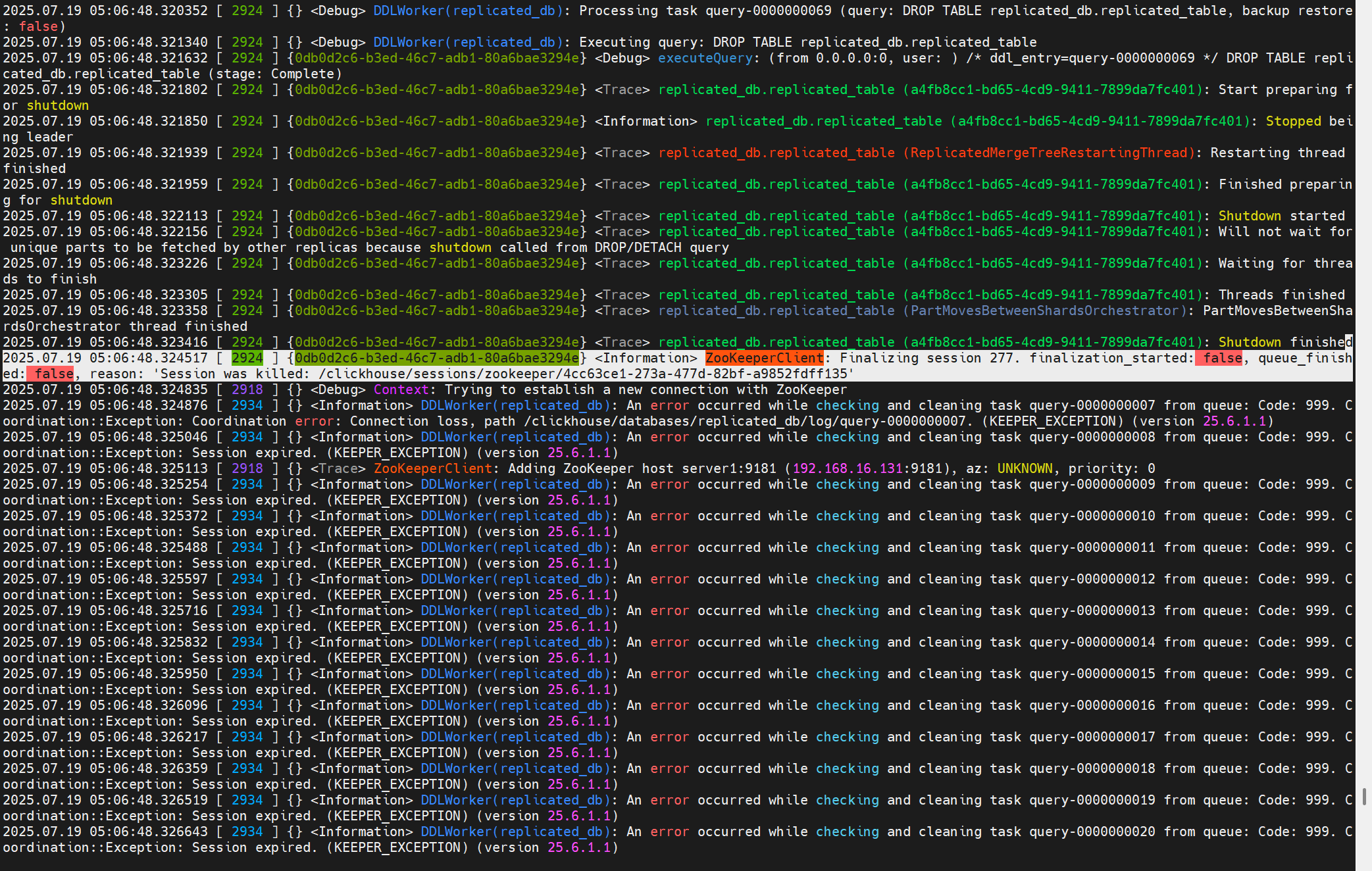
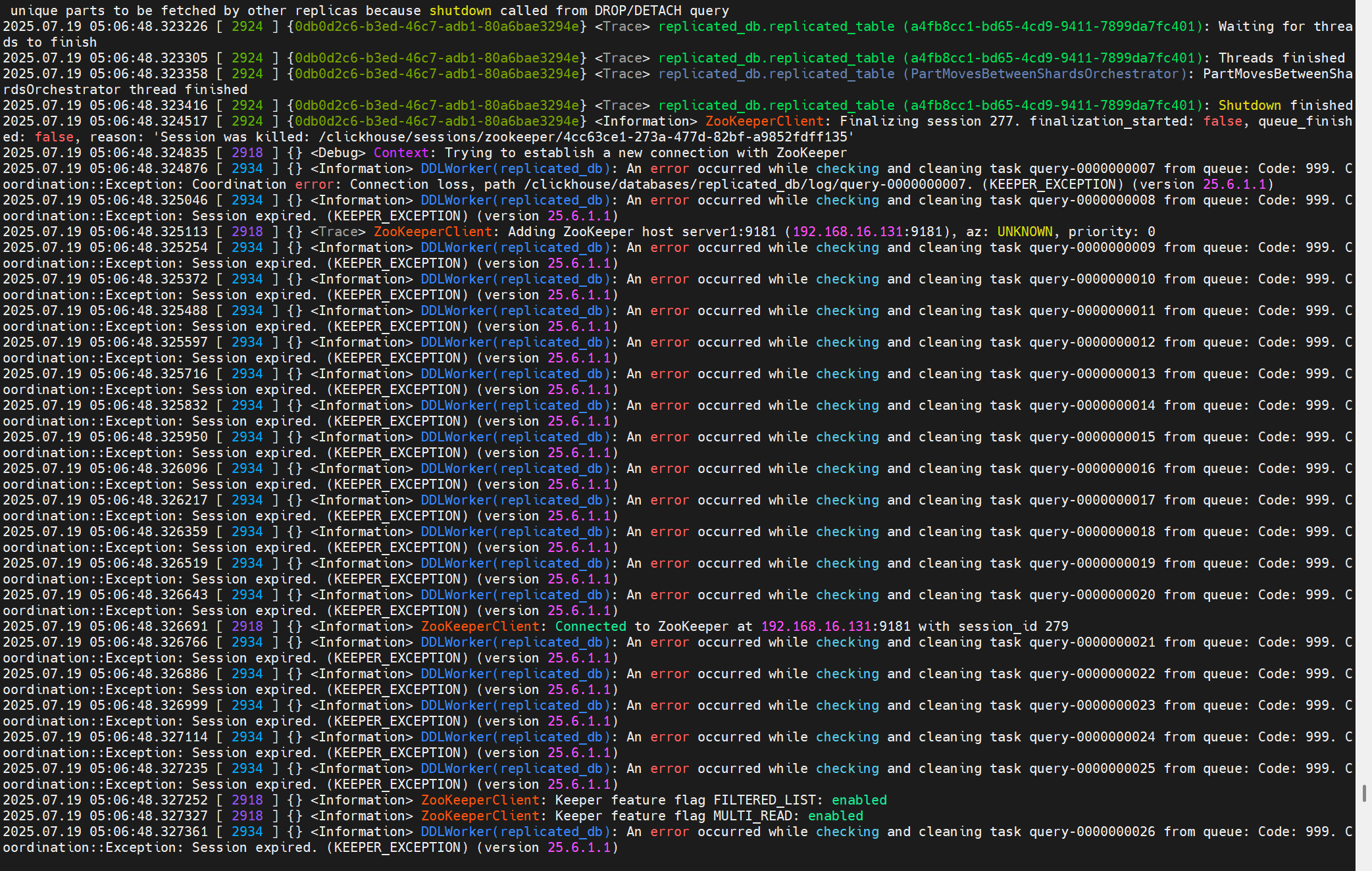

這個問題最后沒追下去,暫時只知道報錯大概位置。
問題2:關于副本同步part失敗的問題記錄
此時在副本r1上的replicated_table有一個part為202507_0_9_3。
在副本2在同步這個part的過程中,雖然它從keeper上取到了這個LogEnetry:
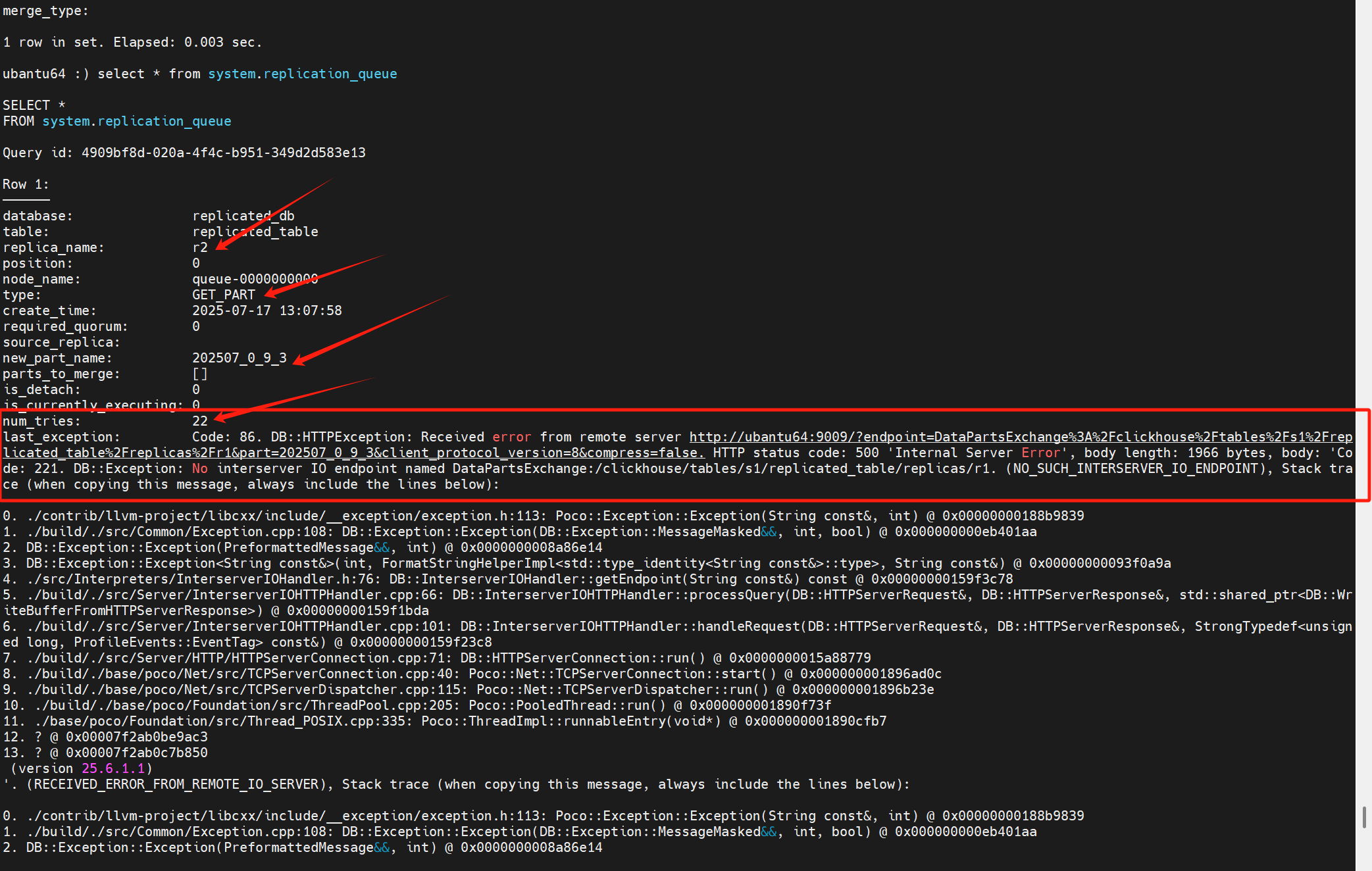
但是一直報錯,并且從num_tries可以得知,這個任務已經重試了22次了。
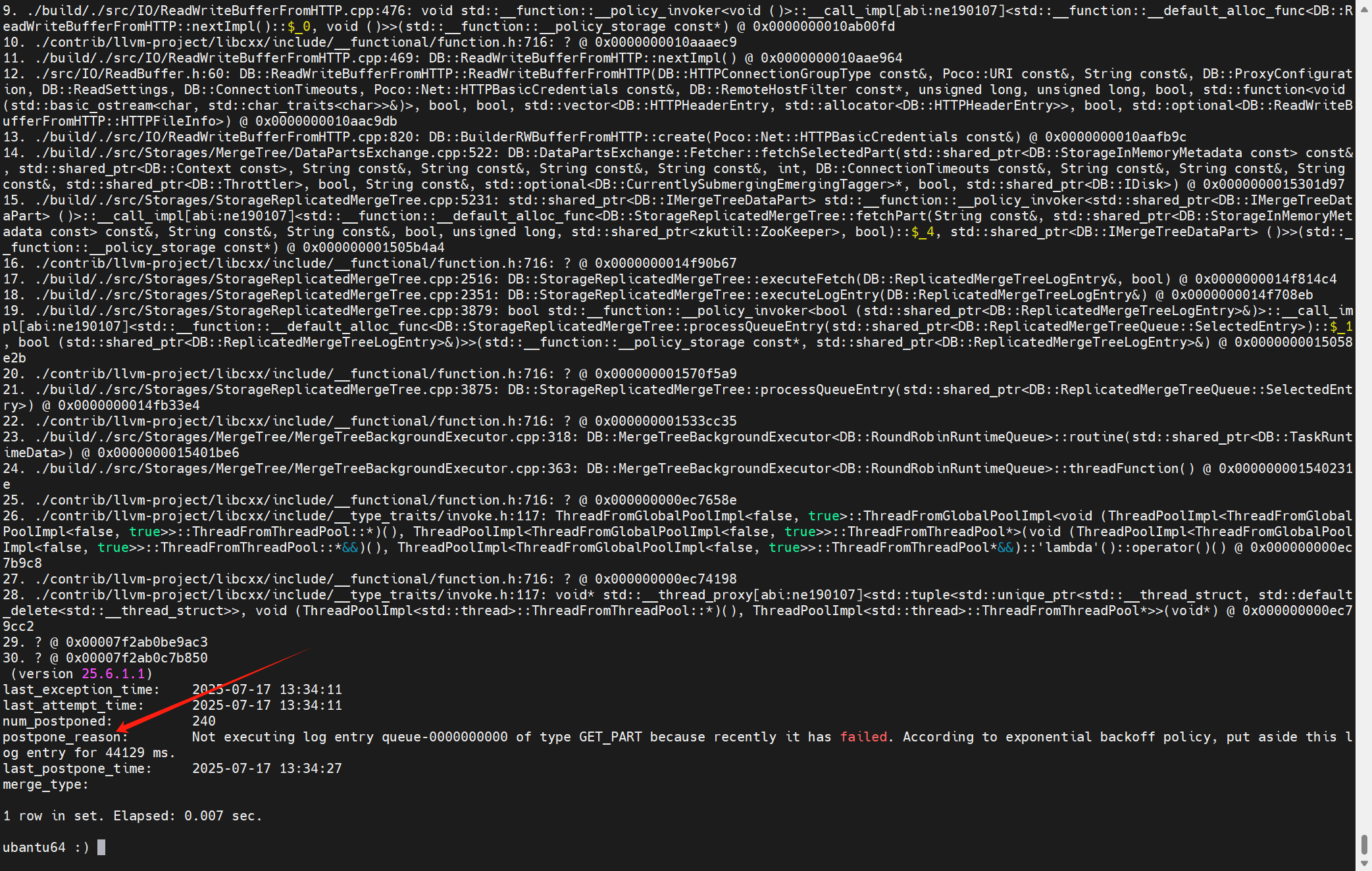
日志中的報錯提示:
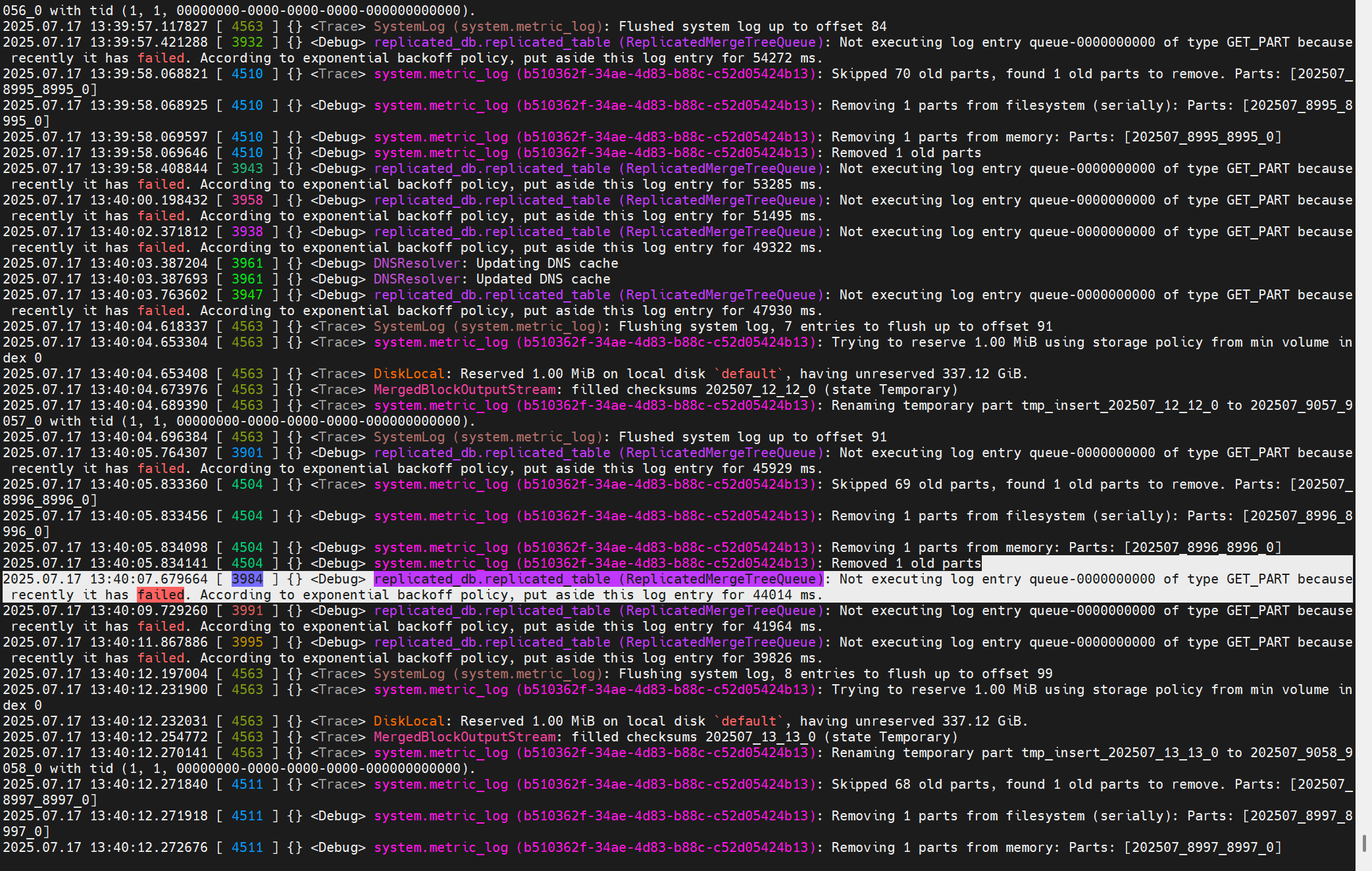
沒有配置這個參數interserver_http_host
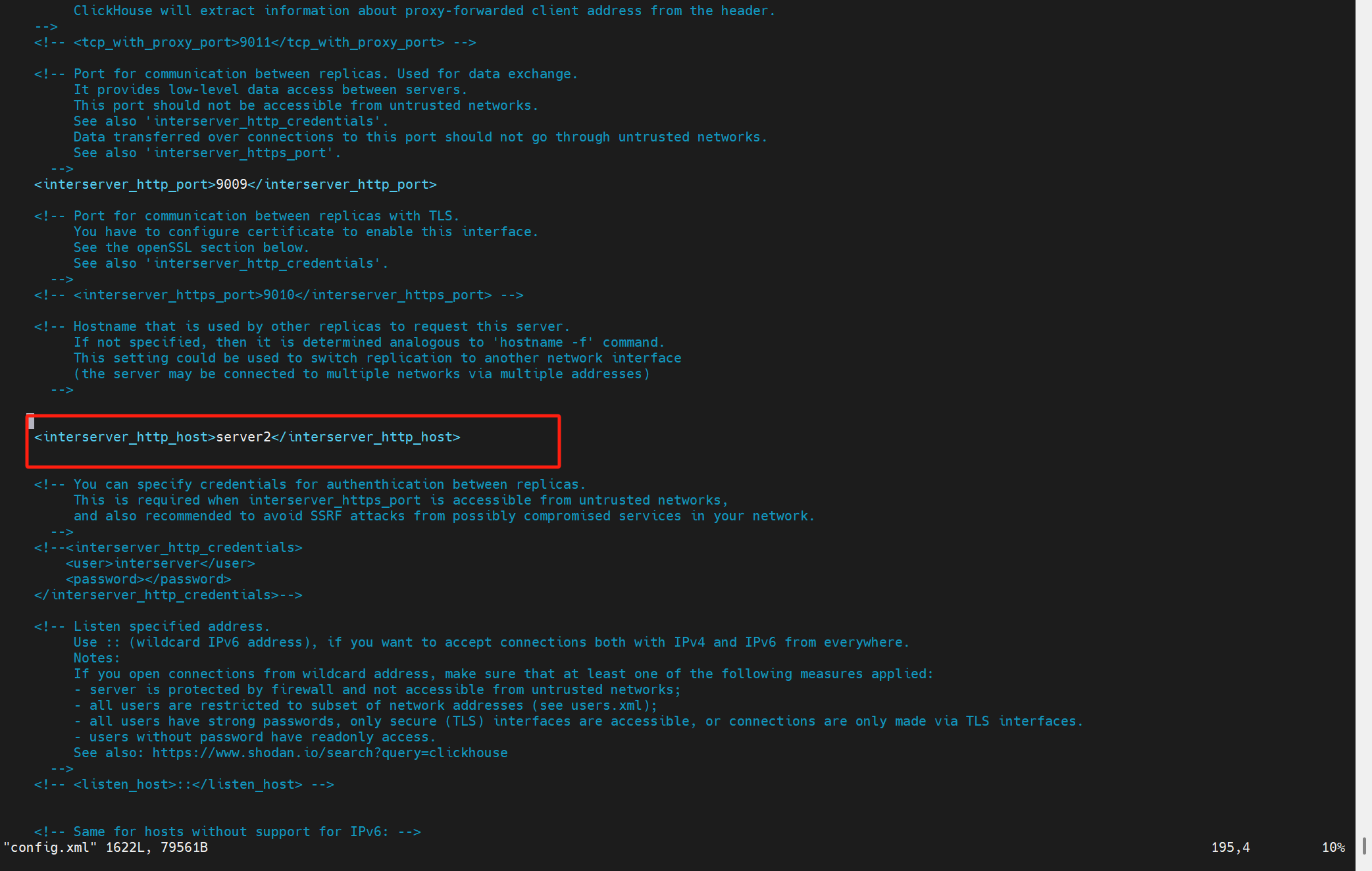
keeper上存副本1的replicated_table這個表的part的地方:/clickhouse/tables/s1/replicated_table/replicas/r1/parts
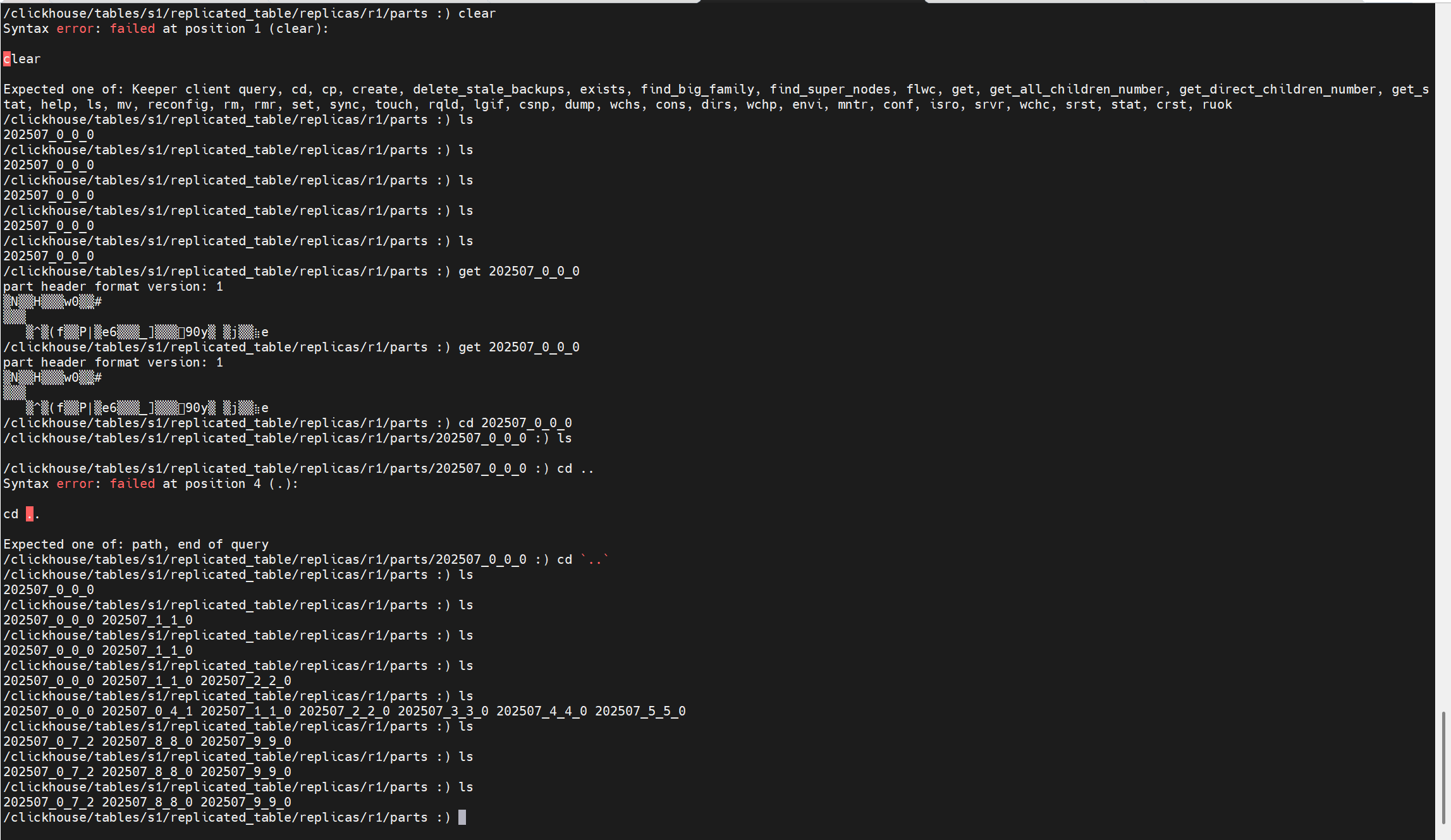
調整完之后,兩個副本的parts目錄下內容一致:


3.2 拉取LogEntry任務啟動
一段核心注釋:(Storages\StorageReplicatedMergeTree.h)
/** The replicated tables have a common log (/log/log-...).
? * Log - a sequence of entries (LogEntry) about what to do.
? * Each entry is one of:
? * - normal data insertion (GET),
? * - data insertion with a possible attach from local data (ATTACH),
? * - merge (MERGE),
? * - delete the partition (DROP).
? *
? * Each replica copies (queueUpdatingTask, pullLogsToQueue) entries from the log to its queue (/replicas/replica_name/queue/queue-...)
? * ?and then executes them (queueTask).
? * Despite the name of the "queue", execution can be reordered, if necessary (shouldExecuteLogEntry, executeLogEntry).
? * In addition, the records in the queue can be generated independently (not from the log), in the following cases:
? * - when creating a new replica, actions are put on GET from other replicas (createReplica);
? * - if the part is corrupt (removePartAndEnqueueFetch) or absent during the check
? * ? (at start - checkParts, while running - searchForMissingPart), actions are put on GET from other replicas;
? *
? * The replica to which INSERT was made in the queue will also have an entry of the GET of this data.
? * Such an entry is considered to be executed as soon as the queue handler sees it.
? *
? * The log entry has a creation time. This time is generated by the clock of server that created entry
? * - the one on which the corresponding INSERT or ALTER query came.
? *
? * For the entries in the queue that the replica made for itself,
? * as the time will take the time of creation the appropriate part on any of the replicas.
? */
解釋如下:
所有副本共享一個日志目錄 /log/log-...,每個日志項(LogEntry)描述一項操作。
這個“日志”是指 ZooKeeper 中的節點
/log/log-0000001,/log/log-0000002等。所有的副本會從這個共享日志中拉取操作(如插入、合并、刪除等)。
日志項類型包括:(定義在Storages\MergeTree\ReplicatedMergeTreeLogEntry.h)
GET:常規插入數據;
ATTACH:插入數據時可能會使用本地已有的數據;
MERGE:后臺合并多個 part;
DROP:刪除某個分區的數據。
每個副本會把這些日志項復制到自己的執行隊列中(
/replicas/<replica_name>/queue/queue-00000...),通過:
queueUpdatingTask(周期性任務)
pullLogsToQueue()(從/log/拉取 log 到/queue/)
副本隨后會啟動后臺線程執行隊列里的任務(queueTask())。
雖然叫“隊列”,但實際上執行順序可以根據依賴進行重排(由
shouldExecuteLogEntry()控制依賴,決定某 entry 是否可執行)。
舉個例子,如果 MERGE 依賴的 part 還沒拉取完成,就會延后執行。
某些隊列任務并非從日志而來,而是副本本地生成的,比如:
創建新副本時,會向隊列中加入從其他副本
GET所有已有 part 的任務;
如果發現某個 part 損壞(removePartAndEnqueueFetch)或缺失(啟動時用 checkParts(),運行時用 searchForMissingPart()),
也會生成 GET 請求從其他副本拉取缺失的 part。
即使某個副本自己是寫入的目標,它也會有一個 GET 類型的 entry 表示這次插入。
這類 entry 在隊列中會立即視為“已完成”,因為本地已經有數據,不需要再拉取。
日志項有創建時間戳,這個時間由“發起該寫入的server”產生(即 INSERT / ALTER 語句在哪個副本執行)。
對于某個副本自己給自己生成的隊列項(比如 GET 缺失 part),會使用已有副本上該 part 的創建時間作為時間戳。
正如前文提到的當創建一個引擎為Replicated族的表時,內核會啟動這個復制表引擎,之后在ReplicatedMergeTreeRestartingThread::runImpl()中啟動各種后臺任務,拉取LogEntry的任務也在這個地方調度:
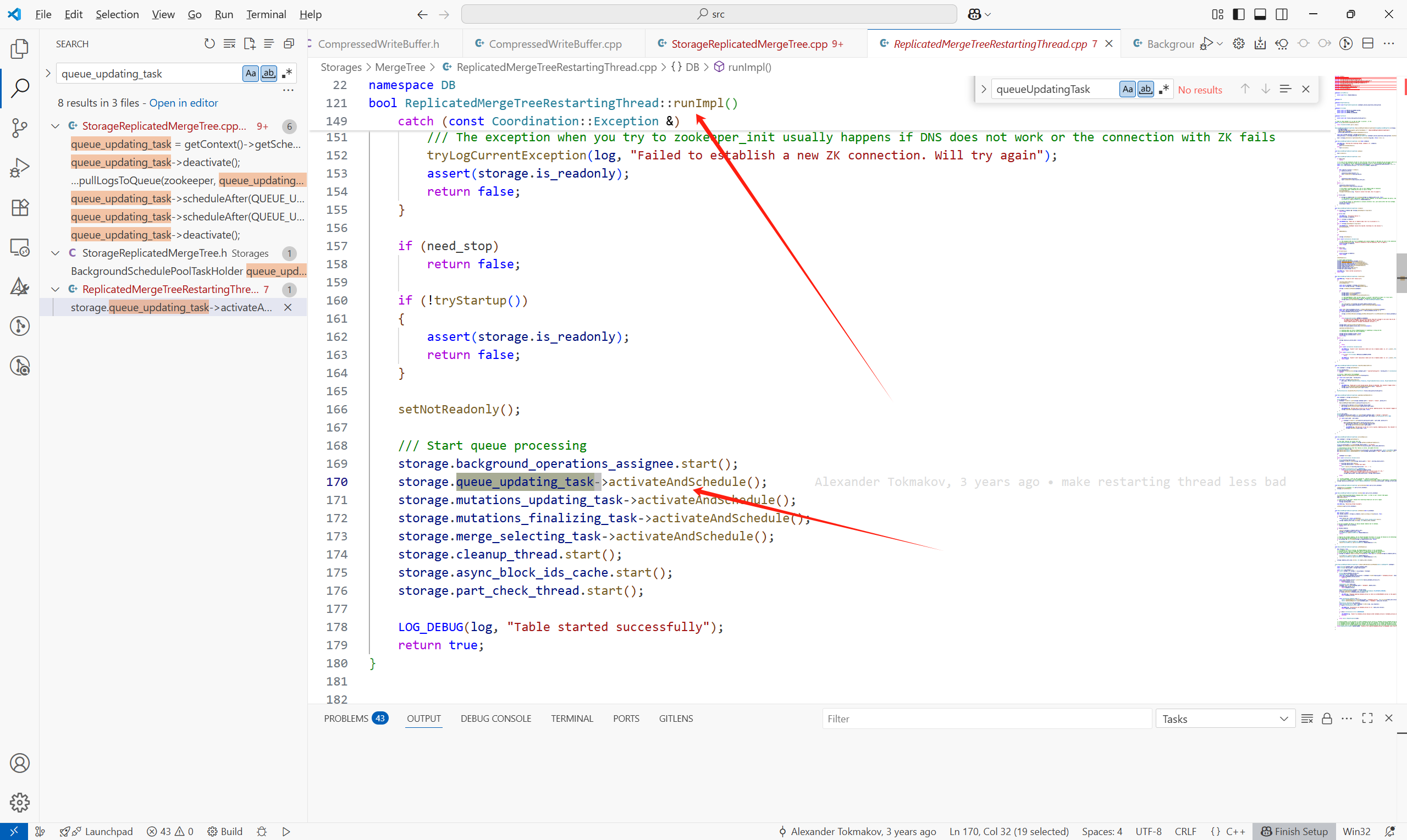
這個任務的主要內容如下所示:(核心為queue.pullLogsToQueue)
void StorageReplicatedMergeTree::queueUpdatingTask()
{
? ? if (!queue_update_in_progress)
? ? {
? ? ? ? last_queue_update_start_time.store(time(nullptr));
? ? ? ? queue_update_in_progress = true;
? ? }
? ? try
? ? {
? ? ? ? auto zookeeper = getZooKeeperAndAssertNotStaticStorage();
? ? ? ? if (is_readonly)
? ? ? ? {
? ? ? ? ? ? /// Note that we need to check shutdown_prepared_called, not shutdown_called, since the table will be marked as readonly
? ? ? ? ? ? /// after calling StorageReplicatedMergeTree::flushAndPrepareForShutdown().
? ? ? ? ? ? if (shutdown_prepared_called)
? ? ? ? ? ? ? ? return;
? ? ? ? ? ? throw Exception(ErrorCodes::TABLE_IS_READ_ONLY, "Table is in readonly mode (replica path: {}), cannot update queue", replica_path);
? ? ? ? }
? ? ? ? queue.pullLogsToQueue(zookeeper, queue_updating_task->getWatchCallback(), ReplicatedMergeTreeQueue::UPDATE);
? ? ? ? last_queue_update_finish_time.store(time(nullptr));
? ? ? ? queue_update_in_progress = false;
? ? }
? ? ? ?......
}
3.3 日志同步位點(log-pointer)
首先創建一個復制表之后,它在Keeper上的元數據都有哪些呢?
例如:
CREATE TABLE my_db.my_table ( ... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/my_table', '{replica}') ORDER BY ...
其中:
{shard} ? = s1
{replica} = r1
所以表的 ZooKeeper 路徑會解析為:/clickhouse/tables/s1/my_table
副本路徑為:/clickhouse/tables/s1/my_table/replicas/r1
ZooKeeper 路徑結構圖:
/clickhouse/
└── tables/
└── s1/ ? ? ? ? ? ? ? ? ? ? ?← shard = s1
└── my_table/ ? ? ? ? ? ← 表名
├── log/ ? ? ? ? ? ?← 主日志目錄(所有副本共享)
│ ? ├── log-0000000000
│ ? ├── log-0000000001
│ ? └── ...
├── replicas/
│ ? ├── r1/ ? ? ? ? ← 當前副本,replica = r1
│ ? │ ? ├── queue/ ? ? ? ? ? ? ?← 待處理的日志操作隊列
│ ? │ ? │ ? ├── queue-0000000000
│ ? │ ? │ ? └── ...
│ ? │ ? ├── log_pointer ? ? ? ? ← 當前副本已同步日志的游標
│ ? │ ? ├── host ? ? ? ? ? ? ? ?← 當前副本的主機地址信息
│ ? │ ? ├── is_active ? ? ? ? ? ← 當前副本是否存活
│ ? │ ? └── ...
│ ? ├── r2/ ? ? ? ? ← 其他副本(如果有)
│ ? └── ...
├── mutations/ ? ? ← 所有的 mutation 操作
├── block_numbers/ ← 每個分區的最大 block number
├── temp/ ? ? ? ? ?← 臨時節點
└── ...
在 ClickHouse Keeper中,log_pointer 是 每個副本(replica)維護的一個游標(cursor),它的作用是在分布式表(如 ReplicatedMergeTree)中 記錄該副本已經處理到哪個日志 entry。
3.4 拉取LogEntry流程
明白了log-pointer(日志同步位點)之后,再看看Keeper是如何具體拉取LogEntry的。
流程如下:
1.主表路徑: /clickhouse/tables/{shard}/{table}/log/ 存放主日志(所有副本共享)。
2.每個副本路徑: /clickhouse/tables/{shard}/{table}/replicas/{replica}/log_pointer 存儲該副本處理進度。
3.副本執行拉取任務:
獲取當前副本的 log_pointer
讀取 /log 目錄下的所有日志節點
過濾日志列表,刪除所有索引小于當前 log_pointer 指向的日志條目。
如果過濾后log_entries不為空,先sort
for循環邏輯:
批次劃分,以
current_multi_batch_size(初始較小)為批大小,從log_entries中取一段連續日志作為本批處理目標。last指向本批最后一個日志條目。更新循環索引和批大小。
entry_idx指向下批次起點,批大小指數級增長(最多增長到MAX_MULTI_OPS),加速同步過程。生成 ZooKeeper 路徑列表,批量讀取日志數據
for (auto it = begin; it != end; ++it)get_paths.emplace_back(fs::path(zookeeper_path) / "log" / *it); auto get_results = zookeeper->get(get_paths);構造 ZooKeeper 操作列表,準備批量寫入 queue 和更新指針
for (size_t i = 0; i < get_num; ++i) {// 解析日志數據,構造 LogEntry 對象copied_entries.emplace_back(LogEntry::parse(res.data, res.stat, format_version));// 創建 queue 節點的請求(持久順序節點)ops.emplace_back(zkutil::makeCreateRequest(fs::path(replica_path) / "queue/queue-", res.data, zkutil::CreateMode::PersistentSequential));// 處理 create_time,更新 min_unprocessed_insert_time(用于后續處理優先級等) }更新 log_pointer 和 min_unprocessed_insert_time 的請求。更新本副本的日志處理進度指針,指向最后處理的日志后一個索引。如果有最早插入時間更新,同步寫入。
使用 ZooKeeper
multi()提交以上所有操作auto responses = zookeeper->multi(ops, /* check_session_valid */ true);將LogEntry加到復制表queue中
insertUnlocked(copied_entries[copied_entry_idx], unused, state_lock);
喚醒表的后臺任務執行線程去執行LogEntry任務
storage.background_operations_assignee.trigger();
注意點:
//這只是讀到所有的任務的名字,不讀具體的內容
Strings log_entries = zookeeper->getChildrenWatch(fs::path(zookeeper_path) / "log", nullptr, watch_callback);
//讀到log的具體內容
auto get_results = zookeeper->get(get_paths);
4 副本執行LogEntry
拉取到LogEntry到queue中后,最后會通過storage.background_operations_assignee.trigger()調度執行LogEntry的線程。
調度任務的內容為:
bool StorageReplicatedMergeTree::scheduleDataProcessingJob(BackgroundJobsAssignee & assignee)
{cleanup_thread.wakeupEarlierIfNeeded();/// If replication queue is stopped exit immediately as we successfully executed the taskif (queue.actions_blocker.isCancelled())return false;/// This object will mark the element of the queue as running.ReplicatedMergeTreeQueue::SelectedEntryPtr selected_entry = selectQueueEntry();if (!selected_entry)return false;auto job_type = selected_entry->log_entry->type;/// Depending on entry type execute in fetches (small) pool or big merge_mutate poolif (job_type == LogEntry::GET_PART || job_type == LogEntry::ATTACH_PART){assignee.scheduleFetchTask(std::make_shared<ExecutableLambdaAdapter>([this, selected_entry] () mutable{return processQueueEntry(selected_entry);}, common_assignee_trigger, getStorageID()));return true;}if (job_type == LogEntry::MERGE_PARTS){auto task = std::make_shared<MergeFromLogEntryTask>(selected_entry, *this, common_assignee_trigger);assignee.scheduleMergeMutateTask(task);return true;}if (job_type == LogEntry::MUTATE_PART){auto task = std::make_shared<MutateFromLogEntryTask>(selected_entry, *this, common_assignee_trigger);assignee.scheduleMergeMutateTask(task);return true;}assignee.scheduleCommonTask(std::make_shared<ExecutableLambdaAdapter>([this, selected_entry]() mutable { return processQueueEntry(selected_entry); }, common_assignee_trigger, getStorageID()),/* need_trigger */ true);return true;
}這里主要說明任務的選擇和執行:
1.從隊列中選擇一個待處理任務
ReplicatedMergeTreeQueue::SelectedEntryPtr selected_entry = selectQueueEntry();
if (!selected_entry)return false;
2.根據任務類型選擇線程池調度
- ?類型:
GET_PART/ATTACH_PART
if (job_type == LogEntry::GET_PART || job_type == LogEntry::ATTACH_PART)
{assignee.scheduleFetchTask(...);return true;
}
類型:
MERGE_PARTS
if (job_type == LogEntry::MERGE_PARTS)
{auto task = std::make_shared<MergeFromLogEntryTask>(...);assignee.scheduleMergeMutateTask(task);return true;
}
等等。
以下我們聚焦于GET_PART任務的執行邏輯:
processQueueEntry? ? ? ? ->
????????executeLogEntry? ? ? ? ->
????????????????executeFetch
????????的核心流程為:
1.找到擁有 entry.new_part_name 或覆蓋它的 part 的 其它副本(replica)??????
/// Looking for covering part. After that entry.actual_new_part_name may be filled.String replica = findReplicaHavingCoveringPart(entry, true);- 獲取所有副本名,并隨機打亂(防止偏好某個副本)
Strings replicas = zookeeper->getChildren(...); std::shuffle(replicas.begin(), replicas.end(), thread_local_rng);
- 遍歷所有副本,跳過自身和不活躍副本
if (replica == replica_name) continue; if (active && !zookeeper->exists(.../replica/is_active)) continue;
- 獲取該副本上的所有 part,并檢查是否包含所需 part 或其覆蓋 part
- 如果找到完全一致的 part,直接接受;
- 如果是覆蓋的 part,則選覆蓋面最大的那個(如
all_0_0_10優于all_0_0_3); MergeTreePartInfo::contains判斷某個 part 是否邏輯上包含另一個。Strings parts = zookeeper->getChildren(.../replica/parts);for (const String & part_on_replica : parts) {if (part_on_replica == part_name || MergeTreePartInfo::contains(part_on_replica, part_name, format_version)){if (largest_part_found.empty() || MergeTreePartInfo::contains(part_on_replica, largest_part_found, format_version)){largest_part_found = part_on_replica;}} }
- 如果找到了覆蓋的 part,還要做一個額外檢查-queue.addFuturePartIfNotCoveredByThem,這個函數暫未細看
2.確定 fetch 的 part 名稱
String part_name = entry.actual_new_part_name.empty() ? entry.new_part_name : entry.actual_new_part_name;if (!entry.actual_new_part_name.empty())LOG_DEBUG(log, "Will fetch part {} instead of {}", entry.actual_new_part_name, entry.new_part_name);
如果
findReplicaHavingCoveringPart選中的 replica 擁有 更大的覆蓋 part,比如:你需要的是part_0_1_1, 它有的是part_0_3_1,則entry.actual_new_part_name會被設置成那個覆蓋的部分。然后將其作為 fetch 的目標
3.拼接 source_replica 的 ZooKeeper 路徑
String source_replica_path = fs::path(zookeeper_path) / "replicas" / replica;
構造這個副本在 ZooKeeper 中的路徑,例如:
/clickhouse/tables/s1/my_table/replicas/r2
4.執行 fetchPart
該函數會嘗試將 part 拉取到本地,執行以下操作:
1. 前置檢查與準備工作
- 如果是靜態只讀表,禁止 fetch 操作。
?if (isStaticStorage())throw Exception(ErrorCodes::TABLE_IS_READ_ONLY, "Table is in readonly mode due to static storage");?- 如果不是 fetch 到
detached目錄,先檢查是否已有舊的同名 part(可能是上次拉取失敗的殘留),如有,則觸發后臺清理線程。
if (!to_detached) {if (auto part = getPartIfExists(...)) {cleanup_thread.wakeup();return false;}
}
- 檢查是否有其它線程正在拉取這個 part。?????
std::lock_guard lock(currently_fetching_parts_mutex);
if (!currently_fetching_parts.insert(part_name).second) {return false; // 已在拉取中,避免重復工作
}
2. 日志記錄,可以看到副本拉取過來的part,對應的類型為DOWNLOAD_PART
/// LoggingStopwatch stopwatch;MutableDataPartPtr part;DataPartsVector replaced_parts;ProfileEventsScope profile_events_scope;auto write_part_log = [&] (const ExecutionStatus & execution_status){writePartLog(PartLogElement::DOWNLOAD_PART, execution_status, stopwatch.elapsed(),part_name, part, replaced_parts, nullptr,profile_events_scope.getSnapshot());};3.決定拉取方式:clone or fetch
如果目標 part 是一個 part mutation 的結果,嘗試查找其 source part,并將其 checksums 與目標 part 的 checksums 進行比較。如果兩者一致,則可以直接 clone 本地的 part。
DataPartPtr part_to_clone;{/// If the desired part is a result of a part mutation, try to find the source part and compare/// its checksums to the checksums of the desired part. If they match, we can just clone the local part./// If we have the source part, its part_info will contain covered_part_info.auto covered_part_info = part_info;covered_part_info.mutation = 0;auto source_part = getActiveContainingPart(covered_part_info);/// Fetch for zero-copy replication is cheap and straightforward, so we don't use local clone hereif (source_part && !is_zero_copy_part(source_part)){auto source_part_header = ReplicatedMergeTreePartHeader::fromColumnsAndChecksums(source_part->getColumns(), source_part->checksums);String part_path = fs::path(source_replica_path) / "parts" / part_name;String part_znode = zookeeper->get(part_path);std::optional<ReplicatedMergeTreePartHeader> desired_part_header;if (!part_znode.empty()){desired_part_header = ReplicatedMergeTreePartHeader::fromString(part_znode);}else{String columns_str;String checksums_str;if (zookeeper->tryGet(fs::path(part_path) / "columns", columns_str) &&zookeeper->tryGet(fs::path(part_path) / "checksums", checksums_str)){desired_part_header = ReplicatedMergeTreePartHeader::fromColumnsAndChecksumsZNodes(columns_str, checksums_str);}else{LOG_INFO(log, "Not checking checksums of part {} with replica {}:{} because part was removed from ZooKeeper",part_name, source_zookeeper_name, source_replica_path);}}/// Checking both checksums and columns hash. For example we can have empty part/// with same checksums but different columns. And we attaching it exception will/// be thrown.if (desired_part_header&& source_part_header.getColumnsHash() == desired_part_header->getColumnsHash()&& source_part_header.getChecksums() == desired_part_header->getChecksums()){LOG_TRACE(log, "Found local part {} with the same checksums and columns hash as {}", source_part->name, part_name);part_to_clone = source_part;}}}遠程 fetch:獲取源副本的 host 地址和端口信息,準備 HTTP 拉取所需的認證信息和參數,構造 get_part(),使用 fetcher.fetchSelectedPart()。
接下來看一下遠程拉取,在fetchSelectedPart中:
數據在構造HttpReadBuffer中已經獲取到。
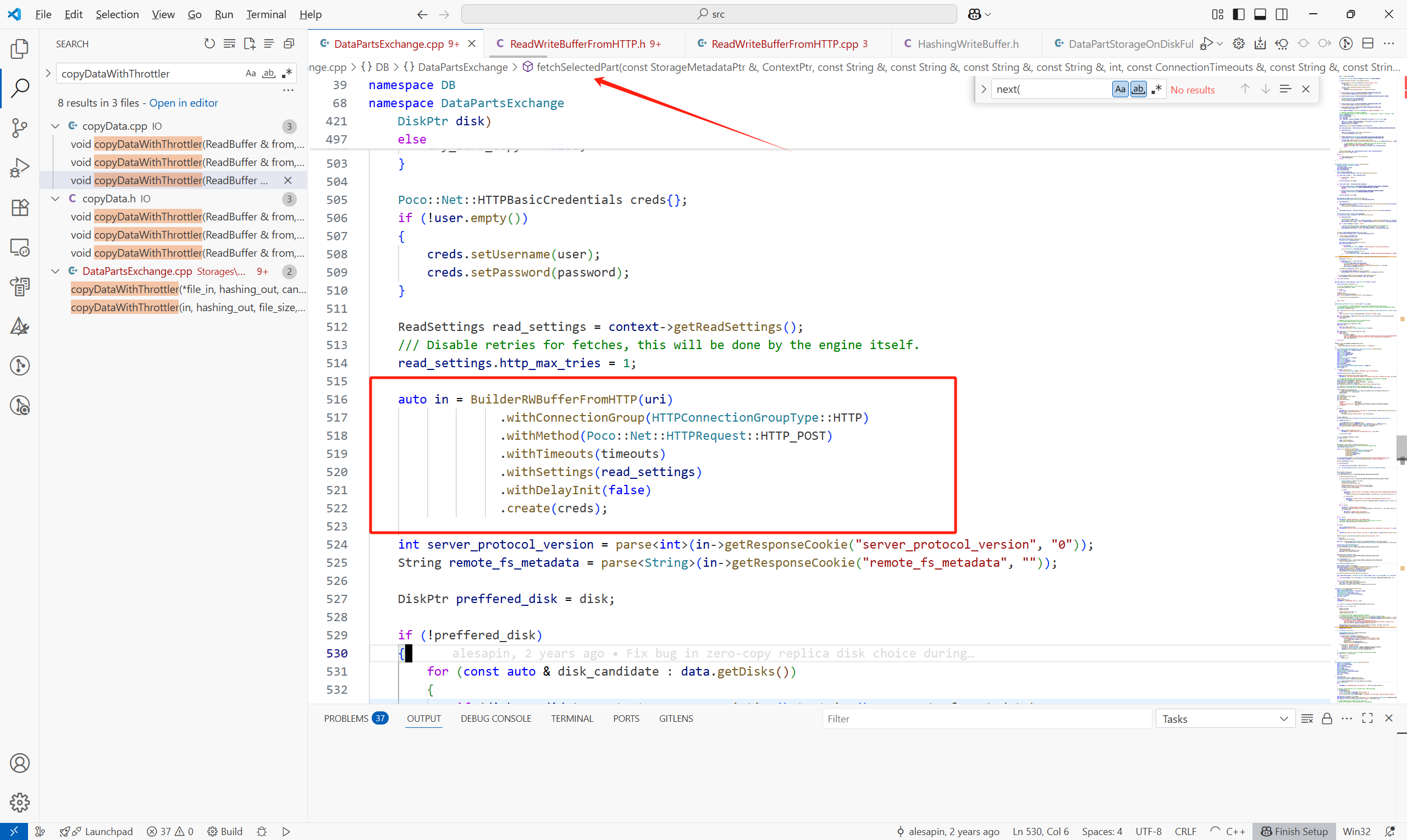
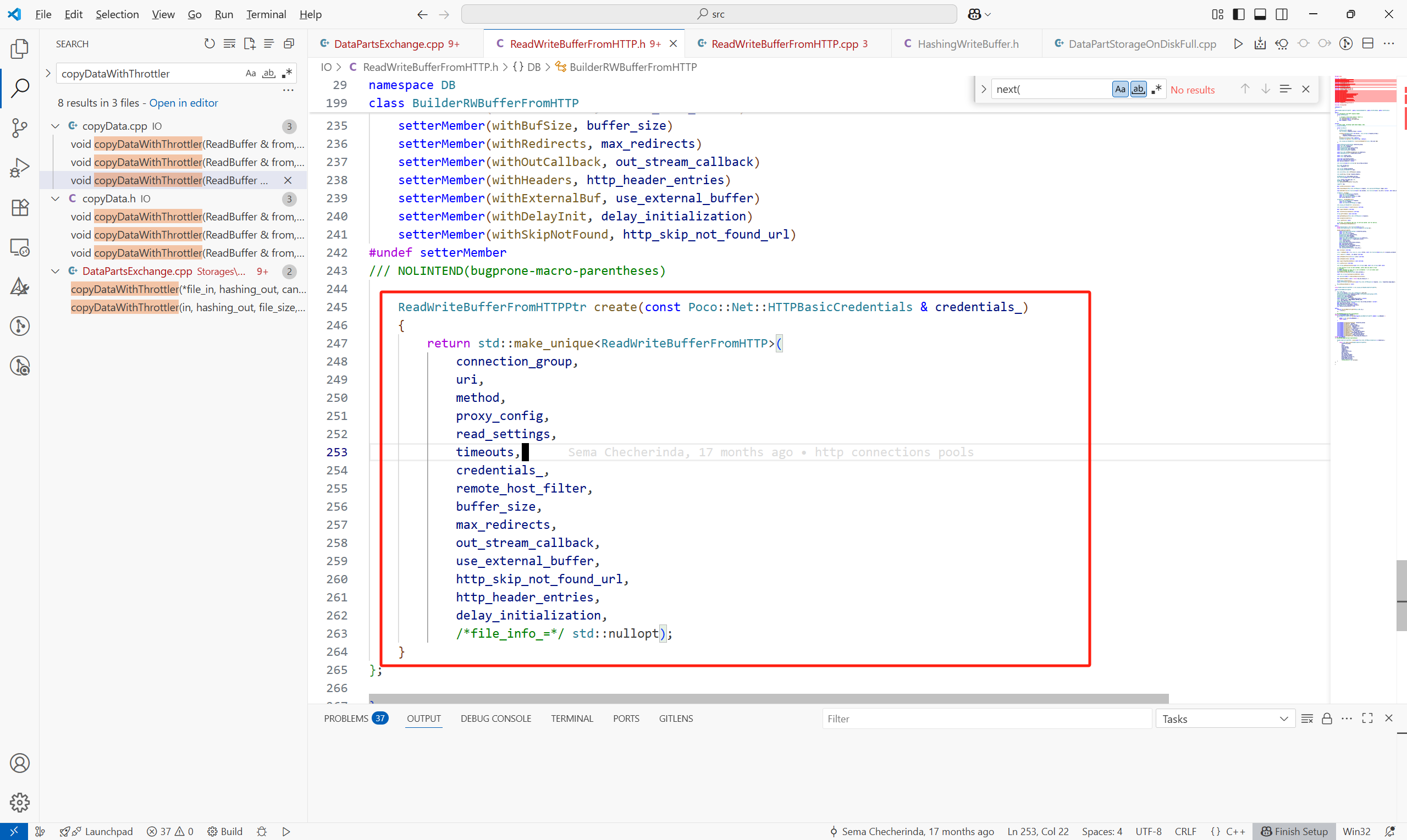
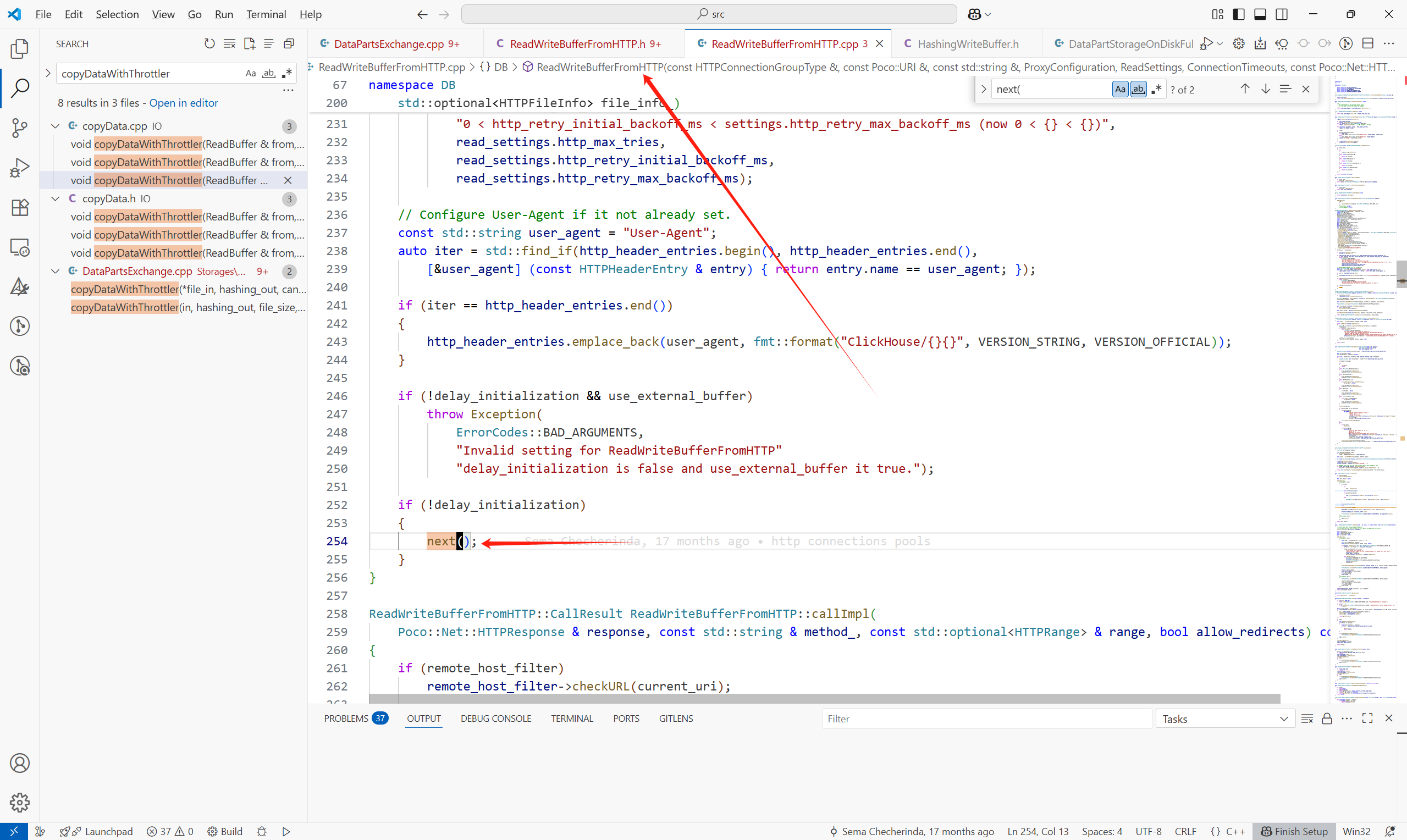
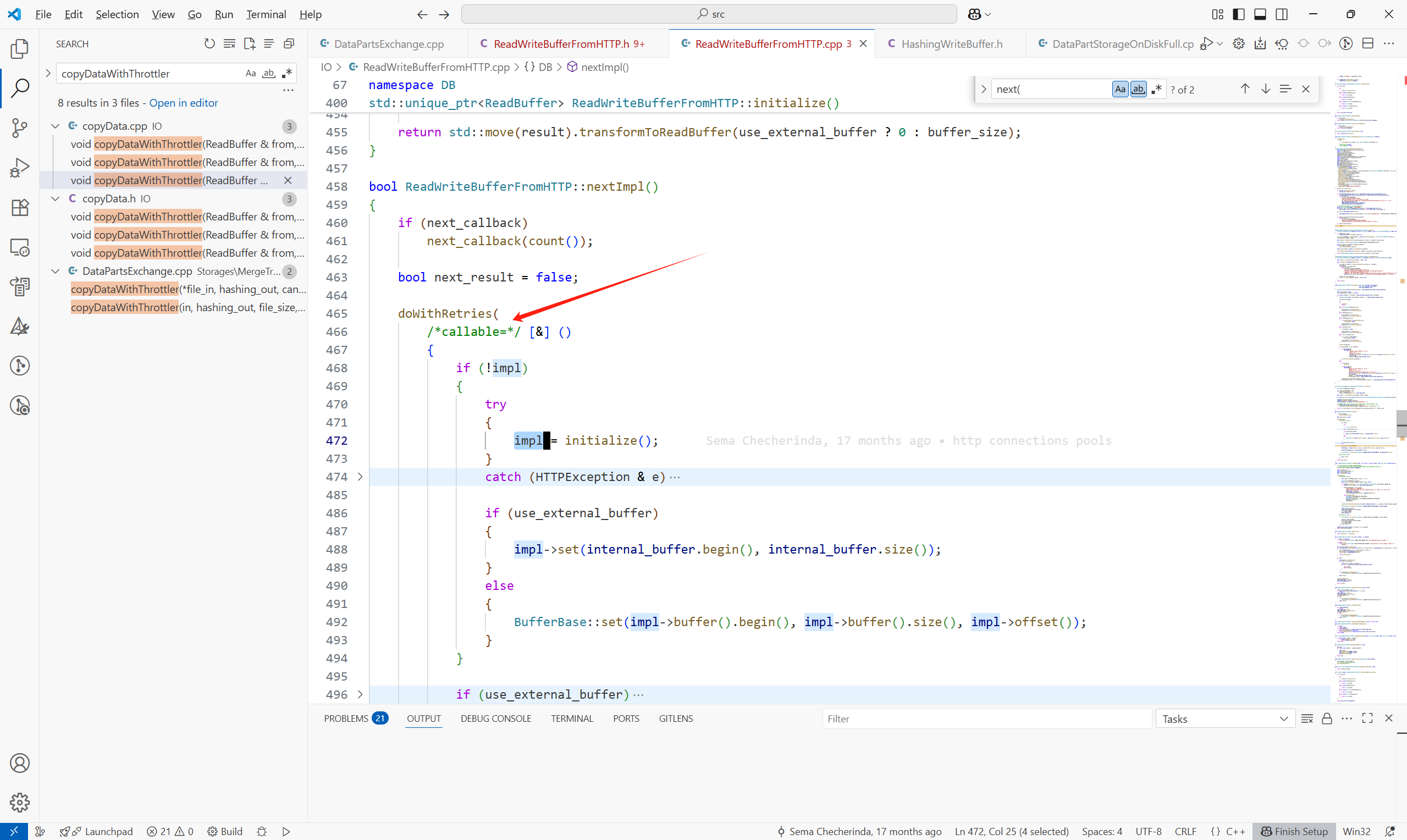
主體流程如下:
1.準備臨時下載目錄(如 tmp-fetch_<part_name>),用于避免寫入中直接影響數據目錄,后續成功后才正式提交。
static const String TMP_PREFIX = "tmp-fetch_";String tmp_prefix = tmp_prefix_.empty() ? TMP_PREFIX : tmp_prefix_;2.傳統 Fetch 分支 -?downloadPartToDisk
downloadPartToDisk中調用downloadBaseOrProjectionPartToDisk來取Part或者是Projection的Part:
try{for (size_t i = 0; i < projections; ++i){String projection_name;readStringBinary(projection_name, in);MergeTreeData::DataPart::Checksums projection_checksum;auto projection_part_storage = part_storage_for_loading->getProjection(projection_name + ".proj");projection_part_storage->createDirectories();downloadBaseOrProjectionPartToDisk(replica_path, projection_part_storage, in, output_buffer_getter, projection_checksum, throttler, sync);data_checksums.addFile(projection_name + ".proj", projection_checksum.getTotalSizeOnDisk(), projection_checksum.getTotalChecksumUInt128());}downloadBaseOrProjectionPartToDisk(replica_path, part_storage_for_loading, in, output_buffer_getter, data_checksums, throttler, sync);}downloadBaseOrProjectionPartToDisk中,遍歷part中的每一個文件,例如.bin , .mrk等等
for (size_t i = 0; i < files; ++i){String file_name;UInt64 file_size;readStringBinary(file_name, in);readBinary(file_size, in);/// File must be inside "absolute_part_path" directory./// Otherwise malicious ClickHouse replica may force us to write to arbitrary path.String absolute_file_path = fs::weakly_canonical(fs::path(data_part_storage->getRelativePath()) / file_name);if (!startsWith(absolute_file_path, fs::weakly_canonical(data_part_storage->getRelativePath()).string()))throw Exception(ErrorCodes::INSECURE_PATH,"File path ({}) doesn't appear to be inside part path ({}). ""This may happen if we are trying to download part from malicious replica or logical error.",absolute_file_path, data_part_storage->getRelativePath());written_files.emplace_back(output_buffer_getter(*data_part_storage, file_name, file_size));HashingWriteBuffer hashing_out(*written_files.back());copyDataWithThrottler(in, hashing_out, file_size, blocker.getCounter(), throttler);hashing_out.finalize();if (blocker.isCancelled()){/// NOTE The is_cancelled flag also makes sense to check every time you read over the network,/// performing a poll with a not very large timeout./// And now we check it only between read chunks (in the `copyData` function).throw Exception(ErrorCodes::ABORTED, "Fetching of part was cancelled");}MergeTreeDataPartChecksum::uint128 expected_hash;readPODBinary(expected_hash, in);if (expected_hash != hashing_out.getHash())throw Exception(ErrorCodes::CHECKSUM_DOESNT_MATCH,"Checksum mismatch for file {} transferred from {} (0x{} vs 0x{})",(fs::path(data_part_storage->getFullPath()) / file_name).string(),replica_path,getHexUIntLowercase(expected_hash),getHexUIntLowercase(hashing_out.getHash()));if (file_name != "checksums.txt" &&file_name != "columns.txt" &&file_name != IMergeTreeDataPart::DEFAULT_COMPRESSION_CODEC_FILE_NAME &&file_name != IMergeTreeDataPart::METADATA_VERSION_FILE_NAME)checksums.addFile(file_name, file_size, expected_hash);}之后將Part涉及的文件寫到磁盤:
/// Call fsync for all files at once in attempt to decrease the latencyfor (auto & file : written_files){file->finalize();if (sync)file->sync();}5 擴展
如何判斷一個Part是否包含另一個Part通過這個函數完成:
bool contains(const MergeTreePartInfo & rhs) const{/// Containing part may have equal level iff block numbers are equal (unless level is MAX_LEVEL)/// (e.g. all_0_5_2 does not contain all_0_4_2, but all_0_5_3 or all_0_4_2_9 do)bool strictly_contains_block_range = (min_block == rhs.min_block && max_block == rhs.max_block) || level > rhs.level|| level == MAX_LEVEL || level == LEGACY_MAX_LEVEL;return partition_id == rhs.partition_id /// Parts for different partitions are not merged&& min_block <= rhs.min_block&& max_block >= rhs.max_block&& level >= rhs.level&& mutation >= rhs.mutation&& strictly_contains_block_range;}同步刪除表:
DROP DATABASE IF EXISTS my_database SYNC;
刪database目錄的信息:
system drop database replica '分片名|副本名' from database db_name;刪replica下信息:
system drop replica '副本名' from database db_name;剔除表的元信息:
SYSTEM DROP REPLICA 'r1' FROM ZKPATH '/clickhouse/tables/s1/replicated_table5';
在集群中創建表:
CREATE TABLE replicated_db.replicated_table ON CLUSTER my_cluster
(
`id` UInt64,
`event_time` DateTime,
`event_type` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/replicated_table', '{replica}')
PARTITION BY toYYYYMM(event_time)
ORDER BY (event_time, id)
SETTINGS index_granularity = 8192












)



kafka講解及實踐-第2次作業指導)


