????????CLIP 和 SIGLIP 的核心區別在于損失函數的設計:CLIP 使用基于 softmax 的對比損失(InfoNCE),強制正樣本在全局對比中壓倒所有負樣本,計算成本高且受限于負樣本數量;SIGLIP 改用基于 sigmoid 的二元分類損失,獨立判斷每個樣本對的匹配概率,無需全局歸一化,計算更高效、內存占用低,尤其適合超大規模負采樣(如百萬級)和多標簽場景。簡言之,CLIP 強調“最優匹配”,適合小規模精準檢索;SIGLIP 側重“靈活匹配”,更適合開放域、大規模數據下的高效訓練。
CLIP(Softmax + 對比損失)
????????CLIP 使用?對稱對比學習損失(InfoNCE loss),通過 softmax 計算概率分布,強制正樣本對的相似度遠高于所有負樣本對。CLIP的損失函數為
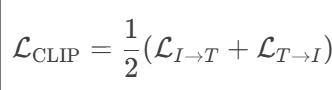
?其中,
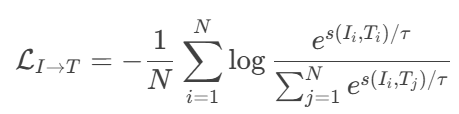 為圖像到文本的損失
為圖像到文本的損失
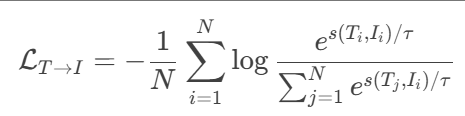 為文本到圖像的損失
為文本到圖像的損失
?為什么使用兩種損失:
增強模型的雙向對齊能力
單一損失的局限性:如果僅用?
I→T?損失(例如僅讓圖像匹配正確文本),模型可能忽略反向的文本特征優化(如文本編碼器未充分學習區分圖像)。對稱損失的作用:
I→T?損失:強制圖像特征靠近對應文本特征。T→I?損失:強制文本特征靠近對應圖像特征。雙向約束?確保視覺和語言特征在共享嵌入空間中全面對齊。
避免模態偏差(Modality Bias)
問題:若僅用單向損失,模型可能偏向某一模態(例如圖像編碼器主導,文本編碼器弱化),導致跨模態檢索時性能不均衡。
對稱損失的平衡性:
例如,在圖文搜索中,用戶可能輸入文本搜圖(T→I),也可能上傳圖搜文(I→T),雙向訓練保證兩種任務均表現良好。
SigLIP
????????SIGLIP 將圖文匹配視為?二元分類問題,采用成對Sigmoid損失,允許模型獨立地對每個圖像-文本對進行操作,而無需對批次中的所有對進行全局查看,獨立判斷每個圖像-文本對是否匹配。損失函數為
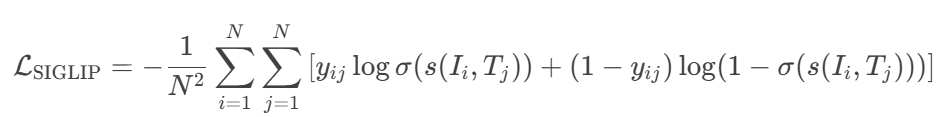
其中,
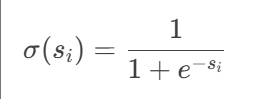 代表圖像與文本匹配使用sigmod函數
代表圖像與文本匹配使用sigmod函數
CLIP 的損失函數基于?softmax + 對比損失(InfoNCE),其計算效率受限于以下問題:
(1) 分母的全局求和:softmax 的分母需要對所有負樣本的指數項求和,損失需要一個全局歸一化因子(突出顯示的分母),這會引入二次內存復雜性。
(2) 梯度計算的依賴性:softmax 的梯度依賴于所有樣本的 logits,導致反向傳播時必須維護整個相似度矩陣。
(3) 內存消耗高:存儲所有負樣本的 logits 和中間結果(如?esjesj?)需要大量 GPU 內存,限制 batch size。
SIGLIP 使用?sigmoid + 二元交叉熵損失,其優勢在于:
(1) 獨立計算,無需全局歸一化:Sigmoid 對每個 logit 獨立計算,不需要計算所有樣本的和,每個樣本的處理是獨立的。
(2) 損失函數的分解性:二元交叉熵損失對每個樣本單獨計算,僅依賴當前樣本的 logit 和標簽,無需其他樣本參與。
(3) 內存友好:只需存儲當前樣本的 logit 和標簽,每個圖像-文本對(正或負)都單獨評估,無需維護全局歸一化相似度矩陣。適合分布式訓練,可輕松擴展到超大規模負采樣(如百萬級)。
總結
CLIP:
使用?softmax + 對比損失,強調?全局最優匹配。
適合小規模負樣本(如 batch size=512),但對超參數敏感。
SIGLIP:
使用?sigmoid + 二元分類損失,獨立判斷每個樣本。
優勢:
計算高效(適合超大規模負采樣,如 1M)。
梯度穩定(不受負樣本數量影響)。
支持多標簽(如一張圖對應多個描述)。
訓練更魯棒(對超參數不敏感)。


)



kafka講解及實踐-第2次作業指導)



機器學習小白入門 YOLOv:YOLOv8-cls 模型評估實操)








